Titre original : DeepSeek's 10 trillion USD grand strategy
Auteur original : @bookwormengr
Traduction originale : Peggy, BlockBeats
Note de la rédaction : Au cours de la dernière année, les discussions autour de DeepSeek se sont principalement concentrées sur les performances du modèle, la stratégie open source et la guerre des prix. Mais si l'on comprend DeepSeek uniquement en termes de « vente d'abonnements », de « multimodalité » ou de « capacité d'agent de codage », on risque de sous-estimer ce qu'il cherche vraiment à changer.
Cet article avance un jugement plus radical : l'objectif de DeepSeek n'est peut-être pas de monétiser à court terme au niveau applicatif, mais plutôt, grâce à une série d'innovations architecturales fondamentales, de remodeler la structure des coûts de l'entraînement et de l'inférence en IA, et de contribuer indirectement à la formation d'un nouvel écosystème matériel. De MoE, MLA à DSA, CSA, mHC, Engram, en passant par Dual Path et TileLang, la feuille de route technologique de DeepSeek tourne toujours autour d'une question centrale : dans un contexte de limitations concernant la HBM, les procédés avancés, l'emballage et l'écosystème CUDA, comment obtenir des modèles plus performants avec moins de puissance de calcul haut de gamme.
Ce qui mérite le plus d'attention dans cet article, ce n'est pas de savoir « si DeepSeek peut gagner quelques milliards de dollars grâce à ses API ou ses abonnements », mais s'il est en train de lier les capacités des modèles, les architectures mémoire et l'écosystème matériel national. La compression du KV Cache réduit la dépendance à la HBM, la NAND et les SSD peuvent gérer la mise en cache à long terme, la LPDDR peut être utilisée pour le chargement en flux des poids et le stockage Engram, tandis que TileLang tente d'affaiblir l'avantage compétitif de CUDA. Si ces innovations continuent de se diffuser, les bénéficiaires ne seront pas seulement DeepSeek lui-même, mais aussi les acteurs du stockage, des ASIC, des GPU, des puces réseau et de toute la chaîne d'infrastructure IA.
Bien sûr, les affirmations concernant un « écosystème industriel de 10 000 milliards de dollars » et une « valorisation de 1 000 milliards de dollars » dans l'article relèvent encore largement de la spéculation. Mais elles offrent une voie importante pour comprendre DeepSeek : l'open source ne signifie pas nécessairement renoncer à la commercialisation, et les bas prix ne sont pas forcément qu'une subvention du marché. Pour DeepSeek, la vraie affaire n'est peut-être pas au niveau applicatif, mais dans l'aide apportée pour rendre plus de matériels utilisables et permettre une offre d'IA à moindre coût. Autrement dit, ce qu'il vend n'est peut-être pas le modèle lui-même, mais la faisabilité de la prochaine génération d'infrastructure IA.
Voici l'article original :

Avez-vous déjà pensé à la façon dont DeepSeek compte réellement gagner de l'argent, et potentiellement beaucoup d'argent ?
Il n'a pas lancé d'offre d'abonnement compétitive pour le codage comme GLM, MoonShot et MiniMax ; il n'a pas de modèle multimodal, audio ou vidéo. Jusqu'à présent, il n'a même pas son propre « harness », c'est-à-dire un cadre d'exécution externe pour l'appel de modèles, l'intégration d'outils et l'exécution de tâches – bien qu'ils aient récemment commencé à recruter pour des postes liés, se préparant à construire ce système.
Dans le même temps, DeepSeek semble rester fermement et durablement du côté de l'open source, et n'hésite même pas à partager publiquement ses « secrets ». N'est-ce pas fou ? Ne s'agit-il pas de brûler de l'argent gratuitement ? Les investisseurs prêts à lui injecter 100 milliards de dollars jettent-ils leur argent par les fenêtres ?
Je pense personnellement que la réponse est exactement l'inverse.
Je vais maintenant, sur la base de ce que DeepSeek a déjà fait jusqu'à présent, avancer quelques observations et analyser la stratégie qu'il semble suivre. L'objectif du PDG de DeepSeek, Liang Wenfeng, pourrait être bien plus grand que la simple concurrence actuelle entre modèles. Il vise peut-être un prix beaucoup plus important : DeepSeek a l'opportunité d'atteindre une valorisation de 1 000 milliards de dollars, tout en favorisant la création d'une nouvelle industrie d'une valeur de 10 000 milliards de dollars.

Article de TechInAsia sur le dernier tour de table de DeepSeek
Revisiter le « voyage du héros » de DeepSeek
DeepSeek a toujours navigué à contre-courant. Il n'a pas choisi de lancer continuellement des modèles légèrement plus performants pour ensuite se précipiter à les commercialiser sous forme d'applications directement monétisables, comme des abonnements pour le codage. Le 27 janvier 2025, j'avais posté un tweet très partagé racontant ce que je voyais comme le « voyage du héros » de DeepSeek. Aujourd'hui, cette histoire est devenue encore plus intéressante.
Lorsque d'autres essayaient encore de construire des modèles denses, DeepSeek a choisi le Mixture of Experts (MoE), plus difficile à entraîner.
Ils ont adopté une approche de « premier principe », inventant le nouvel algorithme GRPO pour remplacer l'algorithme dominant mais plus coûteux en mise en œuvre, le PPO, en apprentissage par renforcement.
Ils ont découvert que le Reinforcement Learning from Verified Rewards (RLVR) était une stratégie clé pour améliorer les capacités de raisonnement des modèles.
Ils ont également proposé une stratégie simple de décodage spéculatif via la « prédiction multi-token » (Multi Token Prediction), tout en densifiant le signal d'entraînement.
Ils ont perfectionné le pipeline « ZERO bubble » pour améliorer l'efficacité d'utilisation des ressources GPU limitées.
Ils ont publié un équilibreur de charge d'experts, rendant le déploiement des modèles MoE plus accessible à tous. Grâce notamment à la stratégie « Wide Expert Parallel », les modèles peuvent servir avec des batchs plus importants, réduisant ainsi considérablement les coûts d'inférence.
Ils ont inventé les mécanismes MLA, DSA, CSA, HCA, etc., pour réduire les besoins en KV Cache et maintenir la demande de calcul, qui augmente avec la longueur du contexte, aussi proche que possible d'un niveau constant.
Ils ont inventé Engram, échangeant de la mémoire contre de l'efficacité de calcul.
Ils ont également inventé le mHC, permettant un entraînement stable même lors de l'augmentation de la taille des modèles. Et il y a bien d'autres exemples.
Dans la structure narrative la plus universelle du « voyage du héros », le héros ne décide jamais dès le début où son périple le mènera. Il découvre peu à peu sa véritable et grande mission en apprenant tout au long du chemin, et l'accomplit face à de nombreux obstacles. Il rencontre de nombreux détracteurs, mais choisit de les ignorer. Il rencontre également de nombreux acteurs malveillants. Il a des faiblesses ou des lacunes évidentes, mais finit par les surmonter pour accomplir sa mission. Il fait face à des défis apparemment insurmontables, mais trouve des moyens de s'allier et apprend à utiliser judicieusement des ressources limitées et précieuses. C'est ce qui fait que le public veut encourager le héros. C'est aussi pourquoi DeepSeek a gagné des adeptes, le respect mondial et des opposants.
Comme je vais l'expliquer en détail, DeepSeek est sur cette voie depuis longtemps et a progressivement découvert sa destinée ultime : son objectif n'est pas de vendre des abonnements pour le codage, mais de stimuler un écosystème matériel d'IA chinois d'une valeur de 10 000 milliards de dollars, tout en atteignant pour lui-même une valorisation de 1 000 milliards de dollars. Dans ce processus, il créera également des opportunités pour de nombreux nouveaux entrants dans l'écosystème matériel occidental.

Commençons par quelques calculs intéressants sur le KV Cache
Voyez ce tweet très opportun de @SemiAnalysis_ récemment :
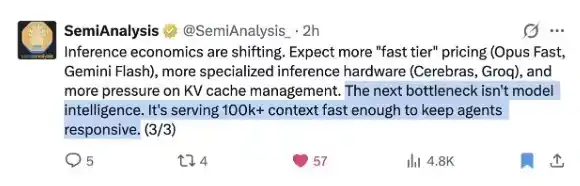
DeepSeek a mieux résolu ce problème que quiconque !
Faisons d'abord quelques calculs intéressants sur le KV Cache. Ne vous inquiétez pas, même si vous n'aimez pas les maths. Nous utiliserons le calculateur de KV Cache récemment publié pour voir combien d'économies de KV Cache apporte DeepSeek V4 Pro, et le comparer aux derniers modèles GLM et Qwen.
Ici, je calcule pour une longueur de contexte de 1 million, en supposant une précision KV de 8 bits et une précision d'indexeur de 16 bits. Vous pouvez également essayer vous-même ce calculateur : https://kvcache.ai/tools/kv-cache-calculator/
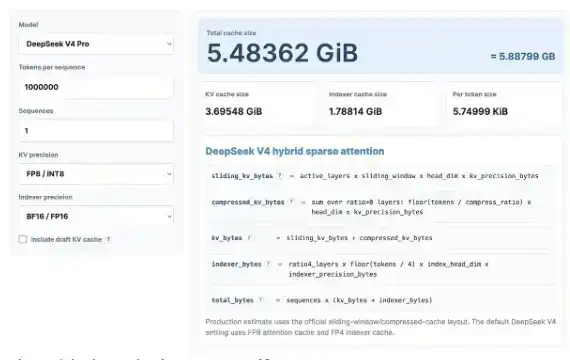
Vous pouvez aussi essayer le calculateur vous-même !
Avec une longueur de contexte de 1 million :
· DeepSeek V4 ne nécessite que 5,48 Go de HBM ;
· GLM-5 nécessite 60 Go de HBM ;
· Qwen3-235B-A22B nécessite jusqu'à 89 Go de HBM.
Il est important de noter que :
· DeepSeek est un modèle de 1,6 trillion de paramètres ;
· GLM-5 fait environ 700 milliards de paramètres et a déjà adopté MLA et DSA de DeepSeek, mais pas encore le dernier mécanisme d'attention compressée ;
· Qwen3-235B-A22B fait environ 235 milliards de paramètres et utilise le mécanisme d'attention GQA.
DeepSeek a apporté des contributions fondamentales à l'atténuation de la pression sur la mémoire. Si ces innovations sont largement adoptées, elles réduiront considérablement les coûts d'exécution des agents à long cycle et débloqueront la prochaine vague de nouvelles applications.
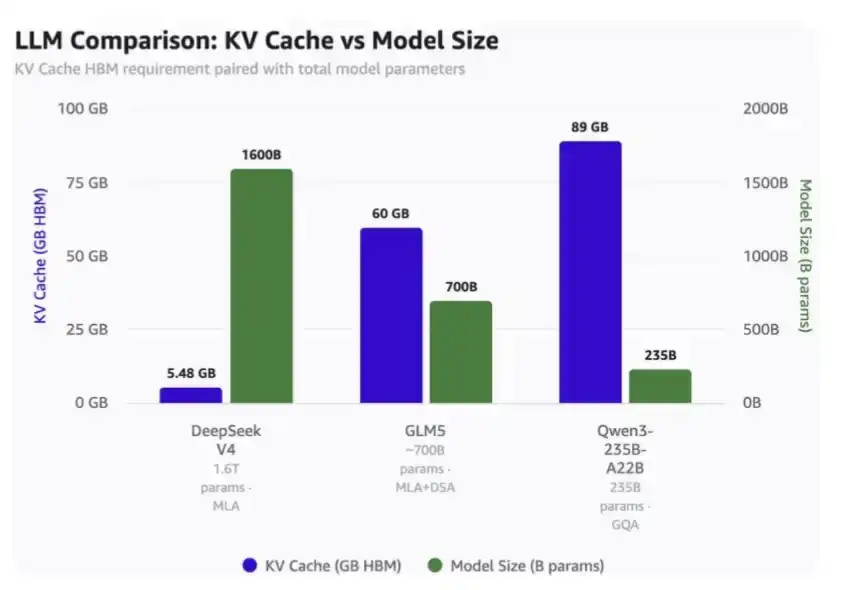
Comparaison de l'occupation du KV Cache pour un contexte de 1 million de tokens et différentes tailles de modèles
La méthodologie derrière la « folie »
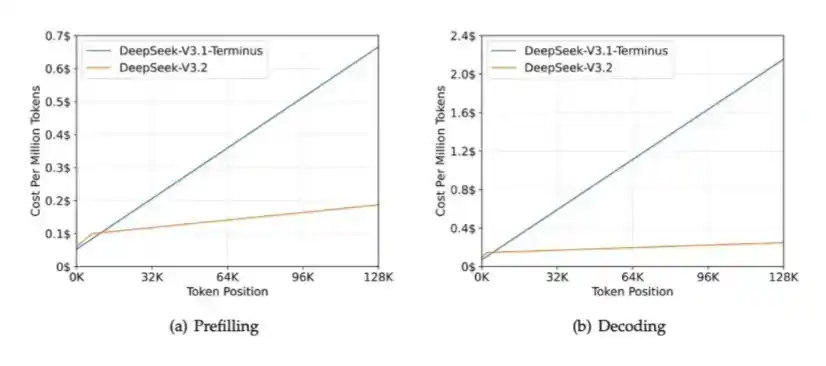
Le fait que la taille du KV Cache puisse être si petite sans sacrifier la qualité du modèle est précisément la raison pour laquelle DeepSeek peut offrir une mise en cache longue durée à un prix extrêmement bas – moins de 3% du prix du cache hit de Sonnet 4.6, et DeepSeek peut conserver le cache pendant plusieurs heures.
Pour les tâches à long cycle, un KV Cache plus petit signifie qu'il peut être déchargé de manière plus économique sur un SSD et rechargé si nécessaire. Cela réduit ainsi la dépendance à la HBM. Du point de vue de l'industrie matérielle chinoise d'IA, la HBM est non seulement rare, mais aussi l'un des types de mémoire les plus difficiles à fabriquer.
De plus, DeepSeek a développé des techniques pour charger le KV Cache plus rapidement depuis un SSD, comme décrit dans son article Dual Path.
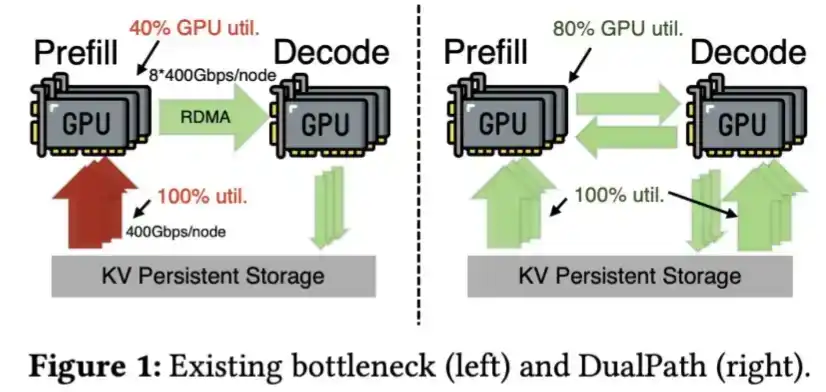
DeepSeek V4 compresse tellement le KV Cache que cette étape pourrait même ne plus être nécessaire.
Alors, qui bénéficie le plus directement de la compression du KV Cache ?
Qui fournit des SSD à grande échelle ? N'oubliez pas que YMTC (Yangtze Memory Technologies Co.) est en train de devenir un géant dans le domaine de la 3D NAND. La NAND peut aider DeepSeek à éviter le recalcul du KV. En retour, DeepSeek crée un énorme marché pour la NAND et les SSD – ce qui profitera non seulement à YMTC, mais aussi à d'autres acteurs concernés.

Cependant, il ne s'agit pas seulement de NAND et de SSD.
La mémoire LPDDR a également un énorme potentiel. Elle peut servir d'espace de stockage pour les poids des modèles et les transmettre en flux continu vers la HBM lorsque nécessaire, atténuant ainsi la pression sur la demande en HBM. L'équipe SGLang a publié un bon blog à ce sujet. L'image ci-dessous montre comment ce schéma fonctionne.
Bien que DeepSeek n'ait pas conçu spécifiquement pour ce schéma, son architecture MoE, le fait qu'il possède lui-même de nombreux modèles experts, et ses poids 4 bits facilitent la mise en œuvre de ce schéma.
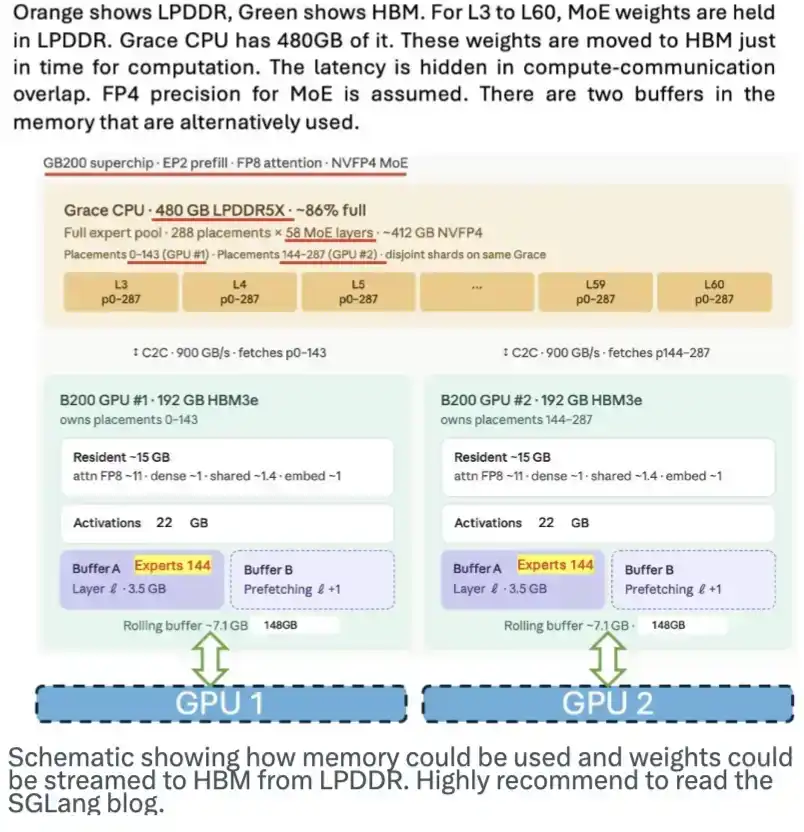
Cette illustration montre comment la mémoire pourrait être utilisée et comment les poids du modèle pourraient être transmis en flux continu de la LPDDR vers la HBM. Je vous recommande vivement de lire le blog de SGLang.
Cette innovation, combinée à un KV Cache extrêmement compact et sans perte, réduirait considérablement la demande en HBM.
Alors, qui produit de la LPDDR en Chine ? La réponse est CXMT, ChangXin Memory Technologies. Ils ne sont en retard que d'environ une demi-génération en vitesse LPDDR et d'une génération en densité, l'écart n'est pas énorme.
En plus d'avoir suffisamment de NAND, l'écosystème chinois d'IA aura également un approvisionnement suffisant en LPDDR dans un avenir proche. Cela peut-il soulager la pression sur la puissance de calcul ? Réponse : Oui. Continuez à lire.

Une utilisation intelligente de la mémoire peut également soulager la pression sur les GPU/ASIC
L'utilisation de la NAND pour stocker le KV Cache est assez simple à comprendre : elle permet de conserver le KV Cache plus longtemps, réduit la pression sur la HBM, évite de recalculer le KV Cache, et allège ainsi la charge de calcul des GPU et ASIC.
La LPDDR peut-elle jouer un rôle similaire ? Outre le fait de servir d'espace de stockage permettant de transmettre les poids « à la demande » vers la HBM, peut-elle également réduire davantage la pression de calcul ?
Réponse : Oui.
La LPDDR peut être utilisée pour stocker une grande quantité de ce qu'on appelle Engram. Dans l'article d'Engram de DeepSeek, ils soulignent que le MoE peut étendre la capacité du modèle par calcul conditionnel, mais le Transformer lui-même manque d'un mécanisme natif de « recherche de connaissances ». Par conséquent, le Transformer a tendance à simuler de manière inefficace le processus de récupération par le calcul.
Pour résoudre ce problème, DeepSeek a proposé le module Engram. Il modernise l'embedding N-gram classique en le transformant en un mécanisme de recherche basé sur le hachage en O(1), créant ainsi une voie d'éparsification complémentaire qu'ils appellent la mémoire conditionnelle (conditional memory).
Cette méthode peut économiser des calculs, mais nécessite également de la mémoire pour porter la table d'embedding, qui peut elle-même être très volumineuse.
Fondamentalement, il s'agit d'un schéma classique d'« échange mémoire contre calcul ». Mais l'idée clé est que, du point de vue du coût de lecture par bit, le côté « mémoire » est beaucoup moins cher – une recherche en LPDDR est bien moins coûteuse qu'un passage complet des données à travers plusieurs couches de Transformer pour un calcul direct. Par conséquent, à grande échelle, c'est un échange très rentable.
C'est ainsi que DeepSeek échange une partie de la mémoire contre des économies de calcul.
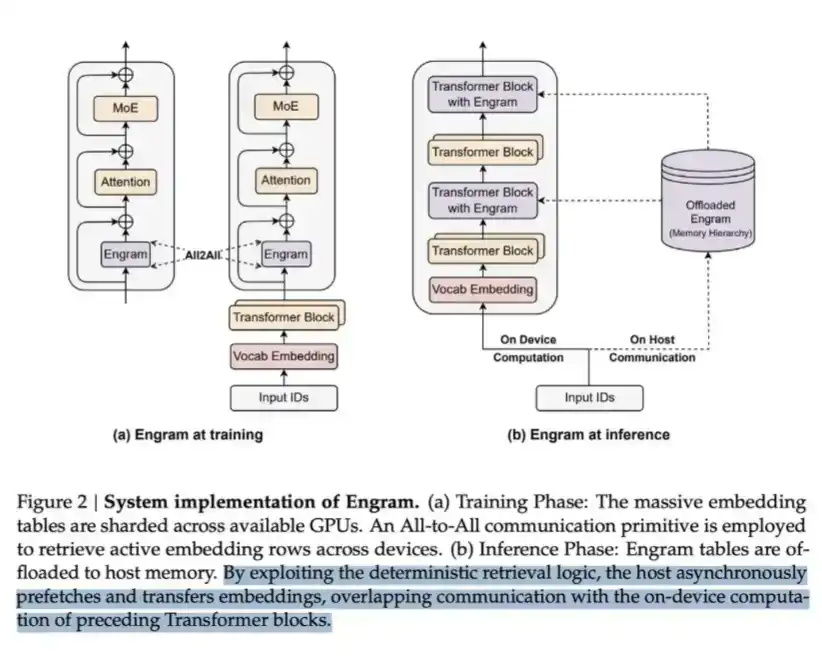
Un compromis qui en vaut la peine
N'ayant pas la même densité de transistors sur puce, ni l'EUV, les GPU et ASIC chinois seront probablement en retard sur les GPU occidentaux en termes de puissance FLOPs brute sur le long terme. Ils ont également un retard notable en matière d'emballage avancé. Par conséquent, ce type de compromis en vaut vraiment la peine, surtout si la Chine peut produire de la mémoire NAND et LPDDR en grande quantité.
Revenons sur la stratégie à long terme de DeepSeek
À la lumière de ces innovations, l'objectif de DeepSeek ne semble pas être de réaliser quelques milliards de dollars de profit à court terme. Beaucoup de ses choix passés le démontrent : pas de multimodalité à ce jour, pas de modèle vocal, encore moins de modèle vidéo.
Il participe en réalité à un jeu à long terme, patient, qui pourrait atteindre 10 000 milliards de dollars : favoriser la formation d'un écosystème matériel d'IA alternatif.
Cela ne vise pas seulement à permettre aux fabricants de mémoire chinois de devenir des acteurs clés sur le marché matériel chinois et mondial de l'IA, mais aussi à réduire fondamentalement les besoins en ressources, rendant l'entraînement et le service des modèles d'IA plus rentables. Ainsi, de nombreux fabricants de GPU, d'ASIC et de puces réseau pourraient devenir des options viables.
Dans le même temps, ces innovations profiteront également à l'écosystème open source occidental et aux nouveaux fabricants de matériel.
Tous les signes sont déjà là. Revisitons en détail les innovations proposées par DeepSeek jusqu'à présent :
1. Le Mixture of Experts (MoE) et le MLA introduits dans DeepSeek V2
DeepSeek a introduit le MoE et le MLA dans V2. Le MoE a réduit la quantité de calcul nécessaire pour entraîner des modèles très intelligents d'environ 40 à 50 % ; le MLA a réduit le KV Cache de 90 %.
Cela a rendu très efficace le déchargement du KV Cache sur un SSD.
Ces idées sont apparues pour la première fois dans l'article DeepSeek V2 publié par DeepSeek en mai 2024. Elles ont ensuite posé les bases de l'entraînement de DeepSeek V3. À l'époque, DeepSeek a réussi à entraîner un système performant proche des modèles propriétaires en utilisant seulement 2 048 GPU H800 aux performances réduites.
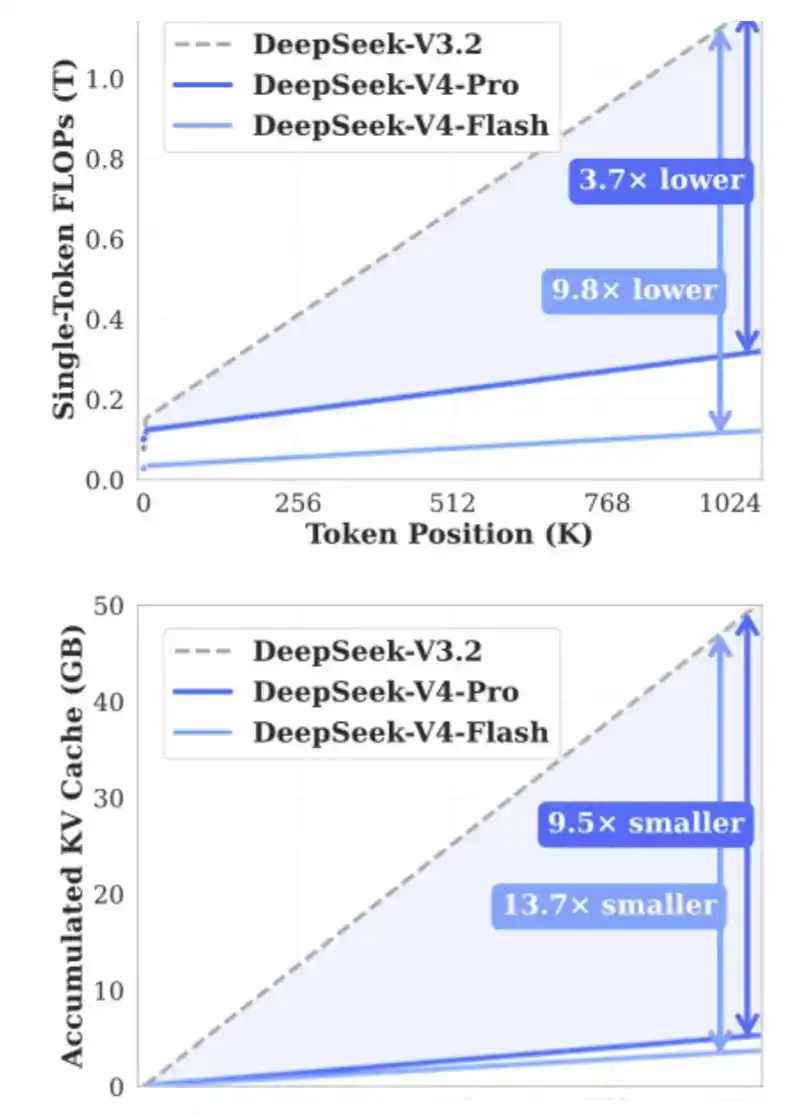
2. DSA : Introduit dans DeepSeek V3.2 Exp pour réduire les coûts de calcul dans les scénarios à contexte long et atténuer la pression sur la bande passante HBM.
Le rôle central de DSA est de s'assurer que la quantité de calcul n'augmente pas continuellement avec la longueur du contexte. Regardez le graphique ci-dessous : le temps de traitement de DeepSeek-V3.2 reste fondamentalement stable à mesure que la longueur du contexte augmente.
3. mHC : Proposé par DeepSeek en décembre 2025 dans l'article « mHC : Manifold-Constrained Hyper-Connections ».
Le mHC est une innovation de DeepSeek au niveau de l'architecture macroscopique, qui reconçoit la façon dont l'information circule entre les couches du Transformer.
Depuis ResNet, les modèles utilisaient généralement des connexions résiduelles standard, c'est-à-dire x + F(x). L'approche mHC consiste à étendre le flux résiduel en plusieurs canaux d'information parallèles et à permettre au modèle de les mélanger de manière apprenable. La clé est qu'il contraint la matrice de mélange à être une matrice doublement stochastique, c'est-à-dire qu'elle est limitée au polyèdre de Birkhoff via une projection Sinkhorn-Knopp. Mathématiquement, cela garantit que l'amplitude du signal reste stable, quelle que soit la profondeur de l'empilement du modèle.
Cela résout le problème d'instabilité catastrophique rencontré par les Hyper-Connections non contraintes. Les Hyper-Connections ont été initialement proposées par ByteDance, mais sans contraintes, l'amplification du signal explosait jusqu'à 3 000 fois à une échelle de 27 milliards de paramètres, conduisant finalement à un échec complet de l'entraînement.
Le coût de calcul du mHC est faible : il n'entraîne qu'une augmentation d'environ 6,7 % du temps d'entraînement réel, car il ne modifie pas les FLOPs des couches d'attention ou FFN, mais seulement la façon dont les sorties de ces couches sont acheminées entre les couches.
Mais les gains de performance sont assez nets : à l'échelle de 27 milliards de paramètres, mHC améliore de 7,2 points sur les tâches de raisonnement BIG-Bench Hard, de 3,2 points sur DROP, de 2,8 points sur la tâche mathématique GSM8K et de 1,4 point sur la tâche de connaissances générales MMLU. Et ces gains sont obtenus avec la même taille de modèle et un budget de calcul presque identique.
Fondamentalement, le mHC offre au réseau une topologie de routage de l'information inter-couches plus riche et plus expressive, permettant une intelligence par paramètre plus élevée sans ajouter de FLOPs significatifs.
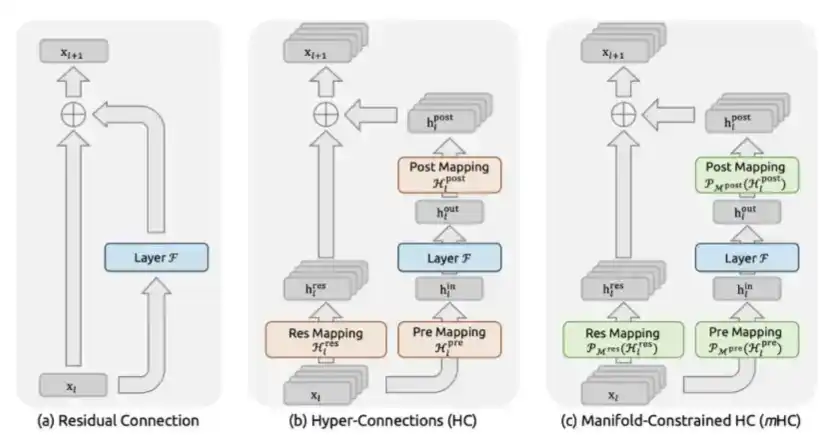
Le mHC est une conception architecturale complexe, mais il permet un entraînement plus stable et une intelligence par paramètre plus élevée.
4. CSA, HSA : Introduits par DeepSeek en avril 2026 dans V4.
L'objectif de CSA et HSA est de réduire encore de 90 % les besoins en KV Cache en compressant les tokens KV, tout en réduisant considérablement les FLOPs nécessaires, atténuant ainsi simultanément la pression sur la HBM et les GPU/ASIC.
5. Engram : Introduit par DeepSeek au premier trimestre 2026, consistant essentiellement à échanger de la mémoire, c'est-à-dire de la mémoire LPDDR, contre de l'efficacité de calcul.
Comme le montre le graphique détaillé ci-dessous, pour un budget total de paramètres identique, Engram apporte une amélioration notable des performances.
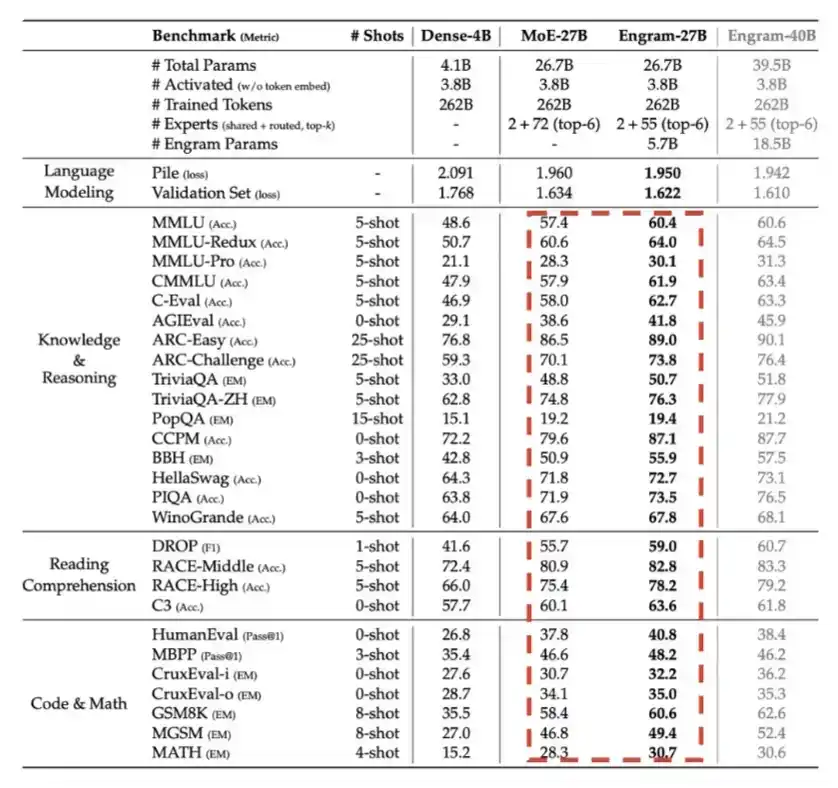
6. Engram : Introduit par DeepSeek au premier trimestre 2026, consistant essentiellement à échanger de la mémoire, c'est-à-dire de la mémoire LPDDR, contre de l'efficacité de calcul.
Comme le montre le graphique détaillé ci-dessous, pour un budget total de paramètres identique, Engram apporte une amélioration notable des performances.

Ce sont les recommandations que DeepSeek partage avec les fabricants de matériel dans son article V4. Je suis sûr que, dans les échanges en privé, ils donnent encore plus de retours.
7. L'investissement dans TileLang pointe également dans la même direction : DeepSeek ne résout pas seulement ses propres goulots d'étranglement en matière de calcul, mais favorise la capacité de l'écosystème matériel chinois à rivaliser avec l'écosystème occidental.
Avec TileLang, les développeurs peuvent écrire le kernel (le code de bas niveau pour les calculs) une seule fois, puis le faire fonctionner avec succès sur plusieurs plateformes matérielles, à condition qu'un backend TileLang correspondant existe.
Je m'attends à ce que d'autres laboratoires d'IA chinois se joignent progressivement à cet effort. Cela aidera les fabricants de matériel chinois à faire face indirectement au soi-disant « avantage compétitif de CUDA ». En même temps, cela libérera également le potentiel de plus de matériel occidental, comme AMD.
Il convient de noter que de nombreuses plateformes matérielles d'IA chinoises offrent déjà une compatibilité CUDA ou une couche de traduction CUDA. Par exemple, Moore Threads, MetaX, Biren et Tianshu Zhixin sont des fabricants de puces chinois offrant un degré élevé de compatibilité CUDA via des couches de traduction. Théoriquement, ils n'ont donc pas nécessairement besoin de TileLang.

Apprentissage par renforcement à grande échelle et RSI
À mesure que DeepSeek obtient plus de sources de puissance de calcul, c'est-à-dire plus d'options matérielles, et que les besoins en ressources de calcul des modèles eux-mêmes diminuent, il pourra avancer des projets d'entraînement plus ambitieux, en particulier l'entraînement postérieur par renforcement.
L'apprentissage par renforcement nécessite de générer un grand nombre de trajectoires, c'est-à-dire des billions de tokens. Ce processus devient rapidement extrêmement coûteux. De plus, pour entraîner des modèles avec un contexte de 1 million de tokens, il faut générer des trajectoires de même longueur. Ce n'est qu'en entraînant des modèles sur ces trajectoires ultra-longues que l'on peut vraiment soutenir les tâches à long cycle.
De plus, avec l'augmentation des options matérielles, les ressources matérielles que DeepSeek peut mobiliser augmenteront également, ce qui stimulera la recherche automatisée, c'est-à-dire la RSI. La RSI fait référence à l'IA qui conçoit et exécute elle-même des expériences. Cette méthode implique beaucoup d'essais et d'erreurs, et les coûts augmentent rapidement. Mais la RSI est cruciale pour explorer l'espace complet de conception des modèles. Avant de progresser vers l'AGI, puis vers l'ASI, DeepSeek doit posséder des capacités RSI.
Ce que DeepSeek fait aujourd'hui, toute l'industrie le fera demain
Les innovations de DeepSeek autour du MoE, du MLA, du DSA, etc., ont déjà été adoptées progressivement par d'autres laboratoires d'IA dans le monde et en Chine.
Par exemple, ZAI, le développeur de la série de modèles GLM, utilise le MLA et le DSA. Kimi, c'est-à-dire Moonshot, a également adopté le MLA et n'a pas hésité à déclarer que son architecture était basée sur la conception de l'architecture DeepSeek. Réciproquement, DeepSeek utilise l'optimiseur Muon, qui a été initialement adopté à grande échelle par Kimi (Moonshot) pour l'entraînement.
Il est important de noter que :
Le MoE a été initialement proposé par Google en 2017, l'auteur clé étant Noam Shazeer. La contribution de DeepSeek a été de l'appliquer à grande échelle et d'inventer ses propres astuces associées.
Muon, l'optimiseur MomentUm Orthogonalized by Newton-Schulz, a été proposé par le chercheur en apprentissage automatique Keller Jordan fin 2024. L'équipe Kimi (Moonshot) a été la première à l'utiliser pour l'entraînement à grande échelle.
Et la question de gagner de l'argent ?
Nous pouvons regarder l'exemple intéressant d'OpenAI.
OpenAI a obtenu des bons de souscription/options pour acheter des actions AMD et Cerebras à un prix bas, ces droits étant liés à l'atteinte de jalons de consommation de puissance de calcul. Pour AMD et Cerebras, c'était une affaire très rentable. Parce qu'une fois qu'OpenAI s'engage à utiliser leur matériel, leurs chances de succès à long terme augmentent considérablement.
Il y a ce passage dans l'annonce d'AMD :
« Dans le cadre de l'accord, et pour mieux aligner les intérêts stratégiques des deux parties, AMD a émis à OpenAI des bons de souscription pour acheter jusqu'à 160 millions d'actions ordinaires d'AMD, qui seront attribués progressivement en fonction de l'atteinte de jalons spécifiques. Le premier lot sera attribué lors du déploiement initial de 1 gigawatt, et les lots suivants le seront à mesure que les achats s'étendront jusqu'à 6 gigawatts. Les conditions d'attribution sont également liées à l'atteinte par AMD d'objectifs de cours boursiers spécifiques, ainsi qu'à l'atteinte par OpenAI de jalons technologiques et commerciaux nécessaires pour permettre un déploiement à grande échelle par AMD. »

Je m'attends à ce que DeepSeek conclue des accords similaires avec plusieurs fabricants chinois de mémoire, d'ASIC, de CPU et de piles technologiques réseau, et collabore étroitement avec eux pour que leurs piles matérielles puissent prendre en charge les charges de travail d'IA de pointe.
Étant donné que la capitalisation boursière totale des actions d'IA occidentales, y compris les alliés d'Asie de l'Est, dépasse déjà largement 10 000 milliards de dollars, cette approche de « rémunération par actions via la coopération » donnera à DeepSeek l'opportunité d'aider la Chine à construire une industrie tout aussi vaste et d'en tirer sa part, atteignant finalement sa propre valorisation de 1 000 milliards de dollars.
Cela permettra non seulement à DeepSeek de gagner beaucoup plus d'argent que les activités traditionnelles d'abonnement applicatif, mais aussi de réaliser son objectif déclaré de « rendre l'AGI bénéfique pour tous ». Liang Wenfeng est un grand admirateur de Jim Simons et un joueur de capitaux suffisamment intelligent pour ne pas manquer cela.
Si vous regardez en arrière tout ce que DeepSeek a fait jusqu'à présent, c'est la seule explication qui a vraiment du sens.
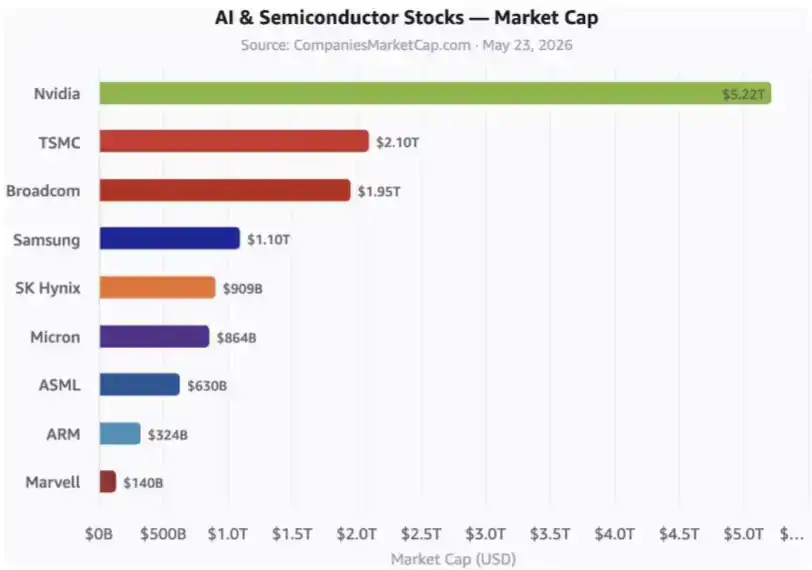
Il s'agit des actions clés de l'IA. Le graphique n'inclut pas encore les hyperscalers (fournisseurs de cloud à très grande échelle) ni de nombreuses autres sociétés connexes.
Lien vers l'article original







