A solo developer actually fought their way to the top of the Hugging Face Models Trending list, standing tall among major tech companies?!
It was an ordinary day, and I was casually browsing the Trending list on Hugging Face as usual.
First place was GLM-5.2, Zhipu AI's latest open-source model, an old acquaintance with over 60k downloads—nothing surprising.
Second was Baidu's Unlimited-OCR, recently quietly open-sourced, capable of parsing over 40 pages of documents in one go, downloads also reaching 70k.
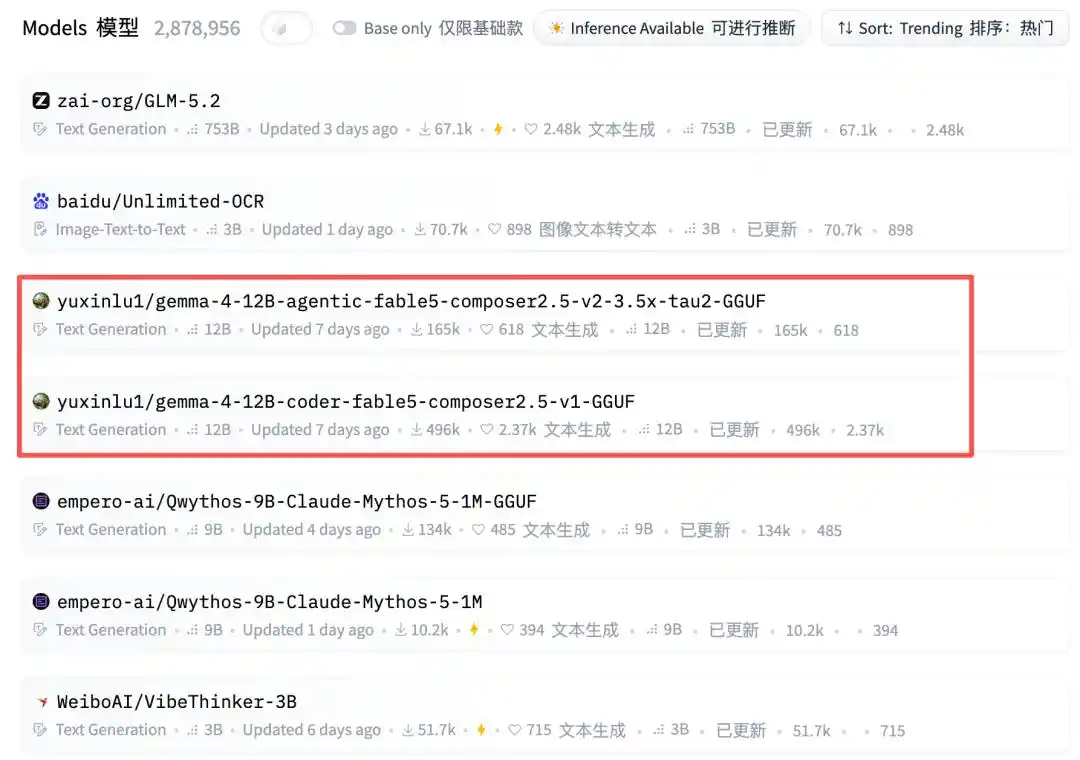
Looking further down, a personal account suddenly appeared: yuxinlu1.
Hmm...... Huh?!
And it occupied two spots at once.
Looking at the download counts—latest figures are a staggering 207k and 536k. Wow, what kind of magical model is this?
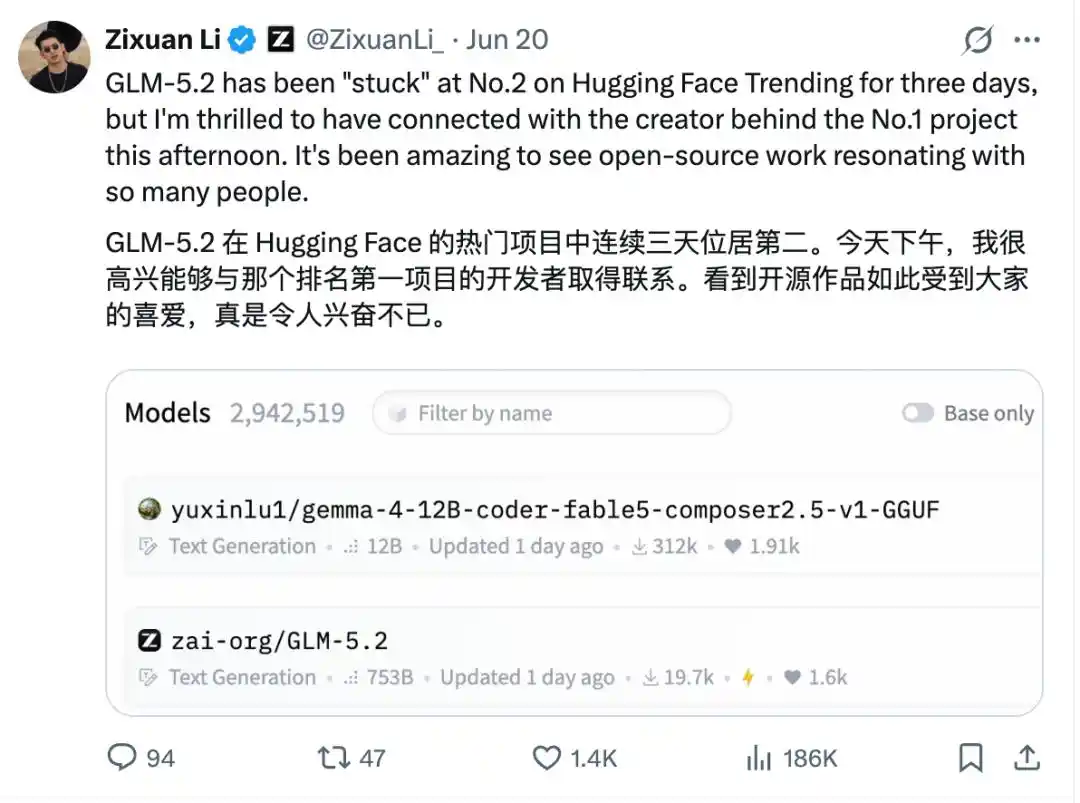
Even the week before, this solo developer's models had once dominated the Hugging Face charts, even surpassing GLM-5.2, with the head of Zhipu AI publicly recommending it on X:
So, among names like Zhipu AI, Baidu, Qwen, NVIDIA... a solo developer account squeezed into the TOP rankings, and with such high download counts.
This naturally raises curiosity: Who is luyuxin? How can they have so much influence?
"Amateur Model" Rushes Up the Hugging Face Hot List
On this wave of the Hugging Face hot list, the top spots are mostly held by major companies, star teams, and hot sectors.
For example, Zhipu AI's GLM-5.2, a massive 753B parameter count, a domestic star large model; Baidu's Unlimited-OCR, riding the recent wave of OCR and document understanding.
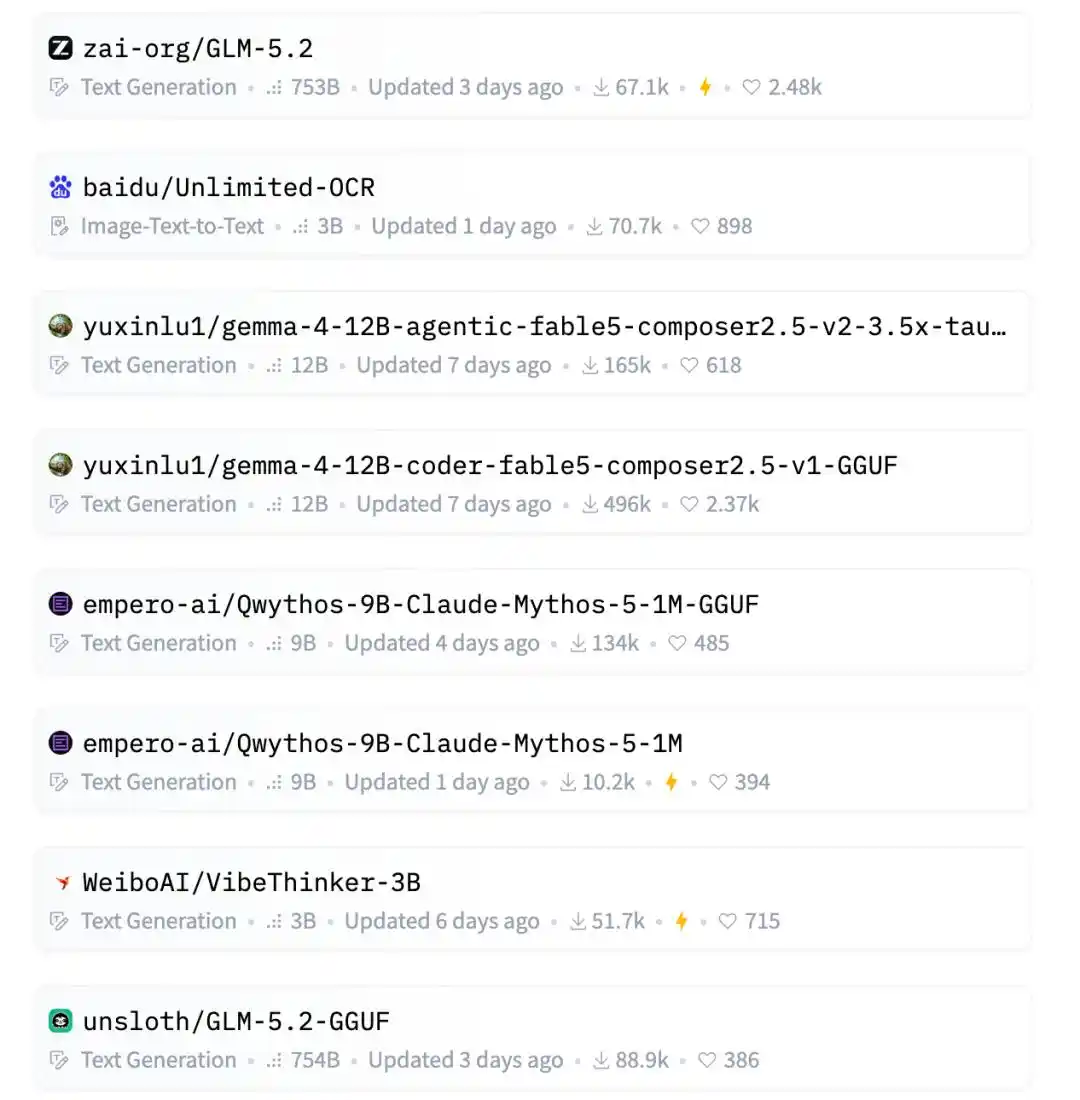
Further down are Qwen's AgentWorld, NVIDIA's LocateAnything, Microsoft's FastContext.
Familiar faces of domestic open-source large models are also there: MiniMax M3, Kimi-K2.7-Code, DeepSeek-V4-Pro.
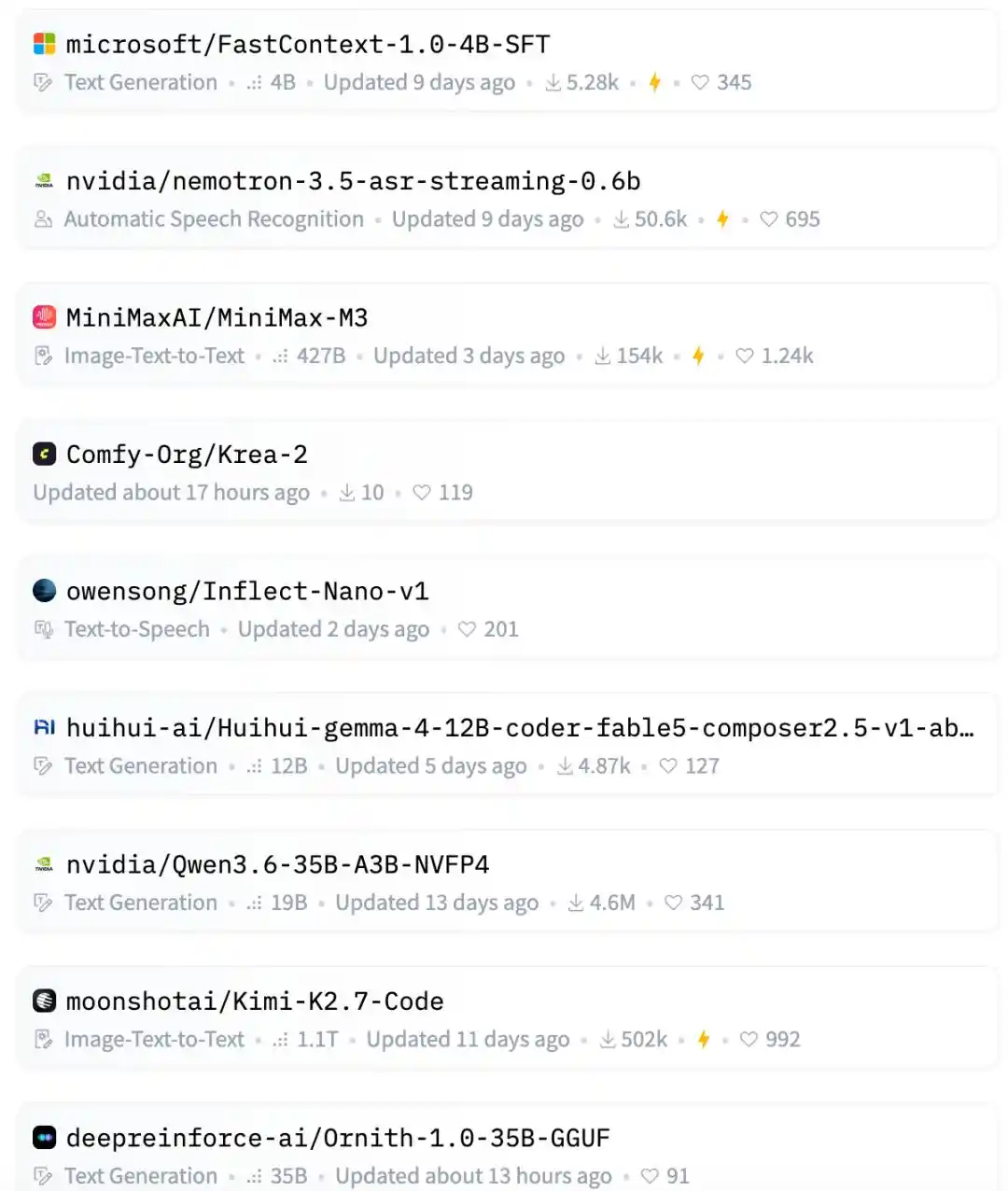
The image generation direction also has Krea, with new models Krea-2-Turbo and Krea-2-Raw on the list.
And sandwiched in between are two of luyuxin's 12B GGUF models.
Nah... luyuxin, you stand out too much...
Looking closer, these two new models mainly distilled the programming and reasoning capabilities of Fable 5 into a small, locally runnable Gemma4-12B model.
It runs on just 4.5GB of VRAM, local, offline, zero API cost. An average user with a consumer-grade GPU, or even a Mac with unified memory, can run it.
The two models have different focuses.
V1 is the Coder version, focused on writing code, solving problems, generating executable code.

According to the model card, its training data consists of "verifiable" code reasoning: each reasoning chain's corresponding code had to actually run tests and pass before being kept.
Teacher data mainly came from Cursor's Composer 2.5, plus Fable 5—problems Composer 2.5 got wrong were re-reasoned by Fable 5 to generate new reasoning chains and correct code.
After V1's release, it topped the Hugging Face Trending list for multiple consecutive days.
V2 is the agentic version, adding multi-step tool-calling capability, usable as a local Agent, able to read, reason, act, and verify on its own.
The author also ran benchmarks—on the telecom subset of the tau2-bench, the base gemma-4-12B scored 15%, while the V2 model scored 55%, roughly 3.5 times the base performance.

However, the author also noted this is a relative value from local self-testing, a single domain, 20 tasks, and shouldn't be directly compared to official leaderboards. He candidly admitted there's still a significant gap compared to frontier large models.
The author also mentioned: Fable 5 was later taken offline, and only his own dataset still retains the "original" reasoning process from Fable 5.
For the missing reasoning portions in the community-contributed data, he used Claude Opus 4.8 (xhigh) to regenerate them, piece by piece, and filled them back in.
He also admitted the reconstructed trajectories "might differ from the original Fable 5," but it was the only feasible solution at the time.
He revealed in the discussion that this fine-tuning dataset actually only has about 10k examples. He emphasized that dataset size isn't as important as everyone thinks; what truly matters is quality, filtering, and verification.
Another very practical reason these models gained such high popularity on Hugging Face is: they can run locally.
Both models are in GGUF quantized format.
GGUF is a common local model format in the llama.cpp ecosystem. Users can load them directly with tools like llama.cpp, Ollama, LM Studio, Jan, etc.
This is especially attractive for coding scenarios. After all, writing code, browsing repositories, running commands, debugging often involve private projects and local environments. Being able to run on your own machine means not having to upload code to the cloud or pay API costs each time.
More importantly, the barrier to entry isn't too high.
The V1 model card states that the smallest Q2_K version is about 4.5GB. With just about 4.5GB of VRAM or unified memory, you can run a private, offline programming assistant.
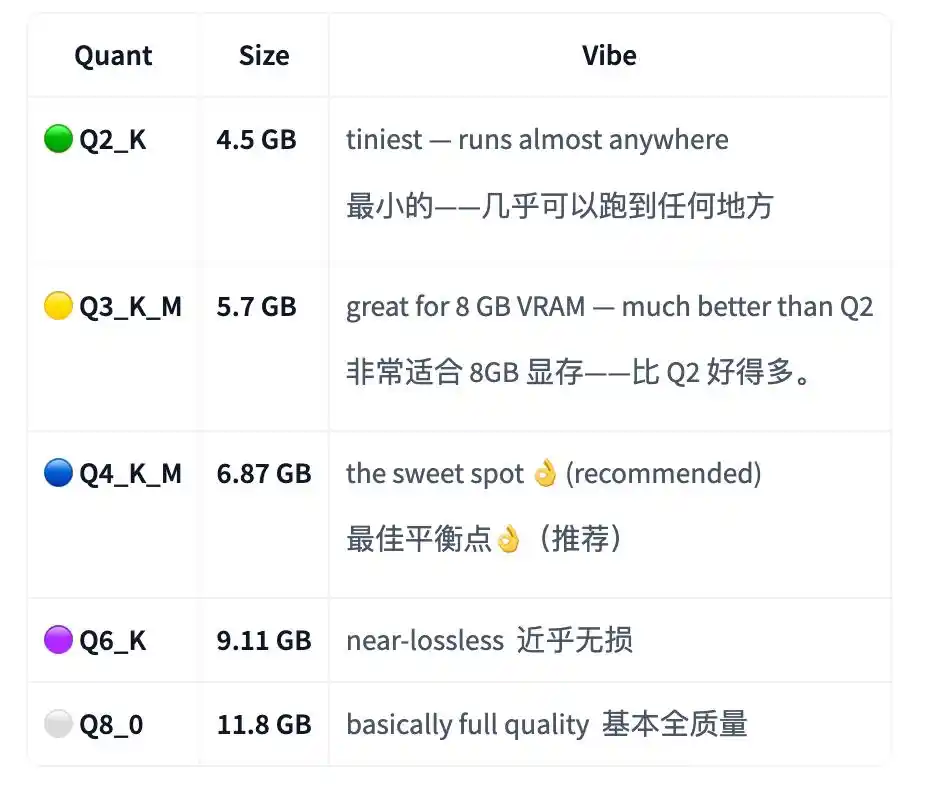
The author's recommended sweet spot is Q4_K_M, about 6.87GB; the higher-quality Q8_0 is about 11.8GB.
For V2, being more agentic, the author didn't release a Q2_K version. The reason given is it failed stress tests and wasn't reliable enough.
So V2's smallest reliable version starts from Q3_K_M, about 5.7GB; the recommended Q4_K_M is still about 6.87GB.
The author also teased future plans—V3 is already on the way.
He said V3 will continue along the 12B path in the coding+agentic direction. The author admitted he didn't expect the performance gains from this post-training to be so significant, so he'll keep pushing forward.
Especially on the tau2-bench telecom subset, V2 still has some issues with "over-attempting, repeated retries," which V3 will aim to improve with more training.
On another front, he's also working on a larger version: Qwen3.6-27B. This essentially applies the same coding+agentic recipe to a larger base model, for users with more generous VRAM.
One Person, 40 Hours, Breaking into the Major Players' Midst
To single-handedly charge up the Hugging Face hot list, with combined downloads exceeding 700k, carving out a place among major companies and institutions...
Who exactly is this author?
After reaching out to the author, we also learned his story.
His name is Lu Yuxin, currently a graduate student in AI at a US university. His undergraduate degree was in Data and Business Analytics, and in between, he specifically studied full-stack development, learning front-end, back-end, software development, and data processing.
These two trending models are not his main focus; they are purely self-funded personal projects.
"Open source is actually just spending money; it doesn't bring you any income." He's very clear about this. His initial motivation for making V1 was actually "self-improvement":
University-taught knowledge updates too slowly. During his graduate studies, professors were still teaching content from two or three years ago, while AI evolves daily. So he used this project to force himself to catch up with the latest developments.

To create these models, he burned through an entire Claude Max 20× subscription. V2 alone took over 40 hours.
Synthesizing data piece by piece, manual cleaning, training, evaluation, re-training—almost all done alone.
For hardware, he used an RTX 5090 with 32GB VRAM; plus about 96GB of local SSD resources available. The actual usable resource scale was around 128GB.
Not bad for a solo developer, but completely incomparable to the compute pools of major companies and AI labs.
He told us that the most time-consuming part of the entire process wasn't training, but data processing.
Especially agentic data; real conversations are often long, with a task potentially having dozens of steps, thousands or even tens of thousands of tokens. But limited by VRAM, he could only feed 2048 tokens at a time during training.
So he did something like a "sliding window" process: within each multi-turn session, using the latest user message as an anchor point, centering around one tool call, and trimming the context to fit the budget.
Both V1 and V2 use Gemma 4-12B as the base. It wasn't chosen because it was easy; on the contrary, Gemma 4's format and tool protocols are quite special, making adaptation troublesome, and even many client-side supports aren't perfect.
Lu Yuxin said it was partly to challenge himself; on the other hand, because the 12B size is very attractive.
He calculated that if quantized to around 3-bit, many Mac users with 8GB unified memory could also run it, with some context window remaining.
I now know many people are still using computers with around 8GB of unified memory. So I wanted to make it usable for as many people as possible within the maximum feasible parameter count.
Lu Yuxin summarized the value of local models in two words:
Privacy, free.
He thinks many people just want AI to help them organize files, process data, make PPTs, or experience an agent, and aren't necessarily willing to pay monthly for Claude or GPT.
People might just want to play around, why does it have to be paid?
After releasing V1, he didn't pay much attention to the rankings at first, just stating in the model card as usual: if people liked it, and downloads and likes were high, he'd continue with V2.
Unexpectedly, two or three days later, the model suddenly jumped from an unknown rank to eighth; after sleeping, it surged to first.
Then, comments and issues flooded in.
He read almost every one. At most, he spent three to four hours a day reading Hugging Face comments, replying to questions, testing user feedback, and then informing the users of the results.
He said: "The community has needs, and I'm genuinely acting on them. That's the most crucial part."
Turns out, he's also a fan of web novels...
On HF, Lu Yuxin has released 9 public models in total. Besides the two trending models, he also made models that "directly distilled Claude."
For example, gemma-4-12B-it-Claude-4.6-4.8-Opus-GGUF can be understood as a general-purpose distilled version of Gemma4-12B.
It's not limited to programming; it's more about compressing Claude Opus's answer style, reasoning habits, and thinking capabilities into this 12B local model.
Another model simply uses JetBrains's programming model Mellum2 as the base, specifically for reasoning distillation.
Looking further down...
Wait, there are even fine-tuned models for web novels?

Wow, and they're divided into four genres, all Chinese web novel LoRAs, and all based on Qwen3.6.
Lu Yuxin told us this was actually his entry point into making Hugging Face models.
Because he personally enjoys reading novels. When chasing an unfinished novel, readers get anxious; authors also work hard writing daily updates.
So, he wanted to create a complete free novel generation pipeline, using different styles of Chinese novel LoRAs, allowing authors to speed up with AI, and readers to see content faster.
But Chinese novel LoRAs aren't that popular on HF. Later, he found users were more interested in coding and agentic models, so his direction gradually shifted to the current path.
When asked what advice he had for other solo developers, Lu Yuxin said: Honesty and persistence are most important.
Honesty means not exaggerating model capabilities. Be clear about what's strong and what's weak.
You have to tell everyone truthfully. If I lie to you about how strong my model is, but in actual use many problems arise, the next time I release something, you won't believe me.
Persistence means open-source authors must accept this: you will inevitably encounter negative voices.
After the models gained popularity, Lu Yuxin also faced skepticism, but he decided to persist.
In his view, the open-source path is inherently difficult.
Even topping the Hugging Face hot list doesn't directly bring income. More often, it's spending your own money on compute, time processing data, replying to comments, fixing bugs, and then facing a few negative voices.
What supported him along the way was also a very personal work rhythm.
Lu Yuxin mentioned he has ADHD.
In the past, this might have meant difficulty following a long-term, step-by-step schedule. But in the rapidly changing field of AI, quickly switching interests and rapidly entering hyperfocus has instead become an advantage.
He even believes: "The AI era belongs to those with ADHD." Because when one direction cools down, if you keep drilling into it, by the time you switch to learning something new, it might already be too late.
Towards the end of the conversation, we posed the initial question:
As a solo developer, how can you squeeze into the front row among major companies?
Lu Yuxin's answer was very balanced.
He believes major companies can certainly do better, with more researchers and stronger compute.
But when major companies release open-source small models, they often also bear goals like brand promotion, API traffic diversion, etc.; whereas solo developers don't have these burdens and can focus more on solving a specific pain point.
I'm happy, but it's not that I've completely defeated them. It's just that I might be a bit more dedicated.
In his view, this is precisely the opportunity for solo open-source authors: not needing to create a jack-of-all-trades model, but making a sufficiently specific problem work well.
If you also want to try this local model, the link is provided below.
Friendly reminder: Currently, the most compatible platform is llama.cpp, which is highly recommended for use~
HF Address: https://huggingface.co/yuxinlu1
This article is from the WeChat public account "QbitAI" (ID: QbitAI), author: Following Frontier Technology