Article | AIX Finance, Auteur | Lei Jing, Éditeur | Jin Yufan
Le cercle de l'IA a récemment connu de nombreuses activités, et Tencent Hunyuan Hy3 preview a également fait son apparition officielle.
Le 23 avril, Tencent Hunyuan a officiellement publié et open-sourcé le nouveau modèle de langage Hy3 preview. Selon la présentation officielle, ce modèle adopte une architecture mixte d'experts (MoE) fusionnant la pensée rapide et lente, avec un total de 295B paramètres, 21B paramètres activés, et une longueur de contexte maximale supportée de 256K. C'est le modèle le plus intelligent de Hunyuan à ce jour, selon les déclarations officielles.
Il y a trois mois, Yao Shunyu, apportant son expertise du framework ReAct et de l'expérience pratique avec OpenAI, a rejoint Tencent pour diriger la refonte de l'infrastructure de pré-entraînement et d'apprentissage par renforcement. Hy3 preview est la première réalisation issue de cette reconstruction. Officiellement, le modèle a considérablement amélioré ses capacités en raisonnement complexe, suivi d'instructions, apprentissage contextuel, génération de code et agents intelligents.
D'après les données et les résultats d'évaluation divulgués officiellement, Hy3 preview démontre des performances remarquables dans de nombreux tests de base. Bien qu'il n'atteigne pas nécessairement le niveau le plus avancé de l'industrie dans toutes les dimensions, il est suffisant pour répondre aux besoins pratiques de la majorité des scénarios.
En termes d'efficacité opérationnelle réelle et de stabilité, Hy3 preview a également réalisé des percées. Les données officielles indiquent que la latence du premier Token de ce modèle est réduite de 54 %, et la durée de bout en bout est réduite de 47 %, améliorant considérablement la vitesse de réponse. Parallèlement, le taux de réussite des tâches a également augmenté, et il peut maintenant piloter de manière stable des workflows d'Agent complexes, couvrant divers scénarios métiers tels que le traitement de documents et l'analyse de données.
De plus, son coût de raisonnement a diminué. Sur l'API de Tencent Cloud, l'entrée coûte seulement 1,2 ¥ / million de Tokens, et le forfait personnel commence à 28 ¥ / mois, ce qui le place dans la fourchette de prix la plus basse parmi les modèles de taille similaire. Actuellement, Hy3 preview est déjà déployé dans des produits clés de Tencent tels que Tencent Cloud, Yuanbao et WorkBuddy.
Ensuite, nous testerons les performances pratiques du modèle Hunyuan dans des applications réelles, basées sur les quatre directions mentionnées officiellement.
Capacité de raisonnement : Peut décomposer une logique complexe, mais doit renforcer l'identification des pièges
Nous avons d'abord testé la capacité de raisonnement du modèle. Les questions de raisonnement logique sont parmi les préférées des internautes pour tester le "QI" des modèles. Dans cette étape, nous avons d'abord utilisé le classique "problème du lavage de voiture" pour tester dans Yuanbao.
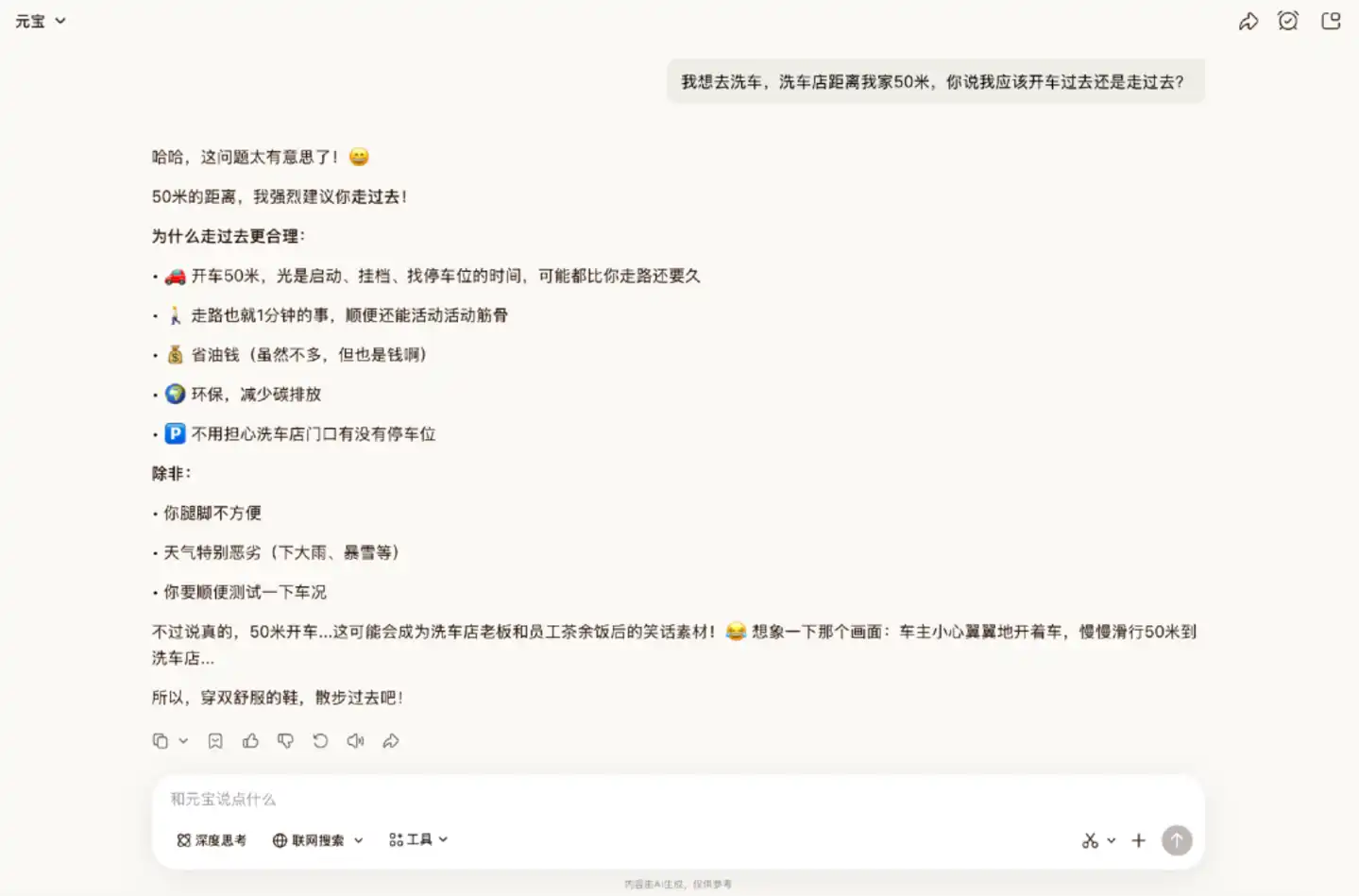
Dans cette question piège classique, Hy3 preview n'a pas répondu correctement initialement. Il a fourni un raisonnement clair et structuré suggérant de marcher, en négligeant le point crucial concernant le "lavage de la voiture". Ce n'est qu'après avoir été rappelé explicitement du besoin de laver la voiture qu'il a donné la bonne réponse.
Il est à noter que dans les tests pratiques d'autres internautes, Hy3 preview a parfois répondu correctement directement, indiquant que la stabilité de sa capacité à identifier les pièges est insuffisante.
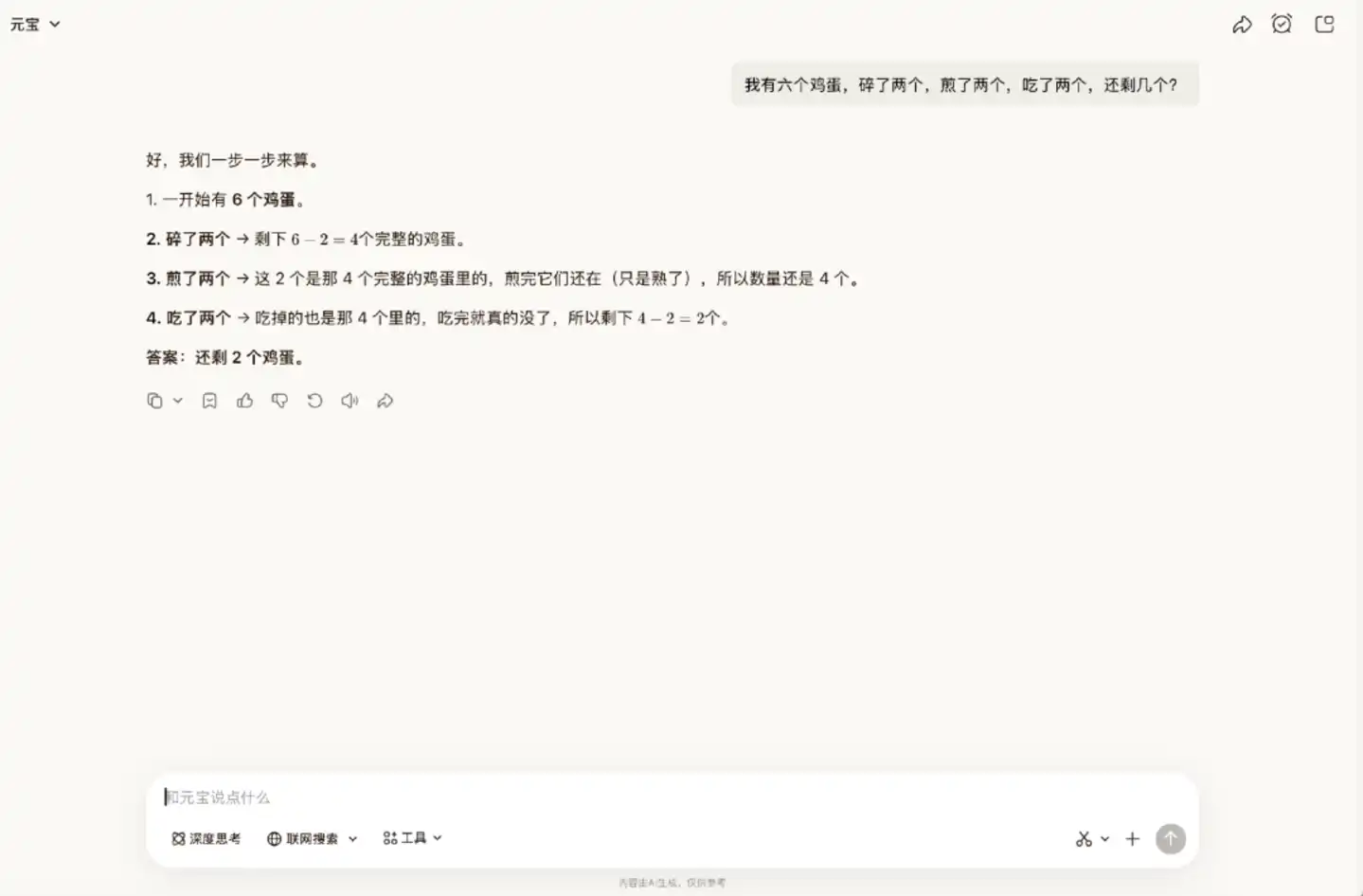
Essayons ensuite une autre devinette. Dans cette question, il faut comprendre la logique réaliste : les œufs cassés, cuits et mangés sont les mêmes. Mais Hy3 preview n'a pas saisi cela ; il a pensé que les œufs cuits existaient toujours et pouvaient être mangés.
Ensuite, nous avons augmenté la difficulté avec un problème de logique au processus de déduction plus complexe pour le mettre à l'épreuve. La difficulté de cette question réside dans l'absence d'informations de localisation directes, nécessitant de s'appuyer sur des conditions implicites pour faire des éliminations, ce qui peut facilement entraîner l'omission d'informations clés.
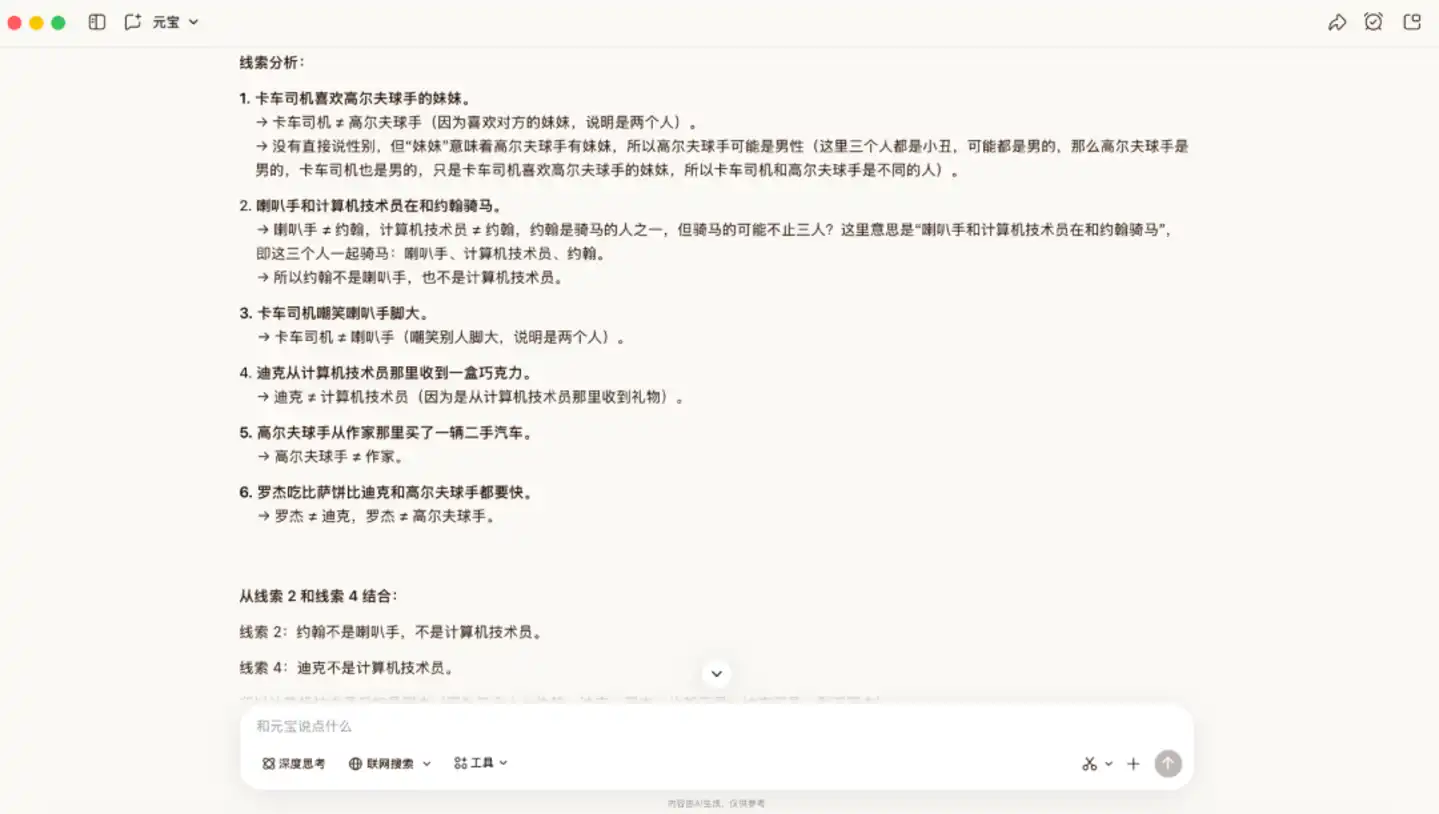
Dans ce scénario, Hy3 preview a donné la réponse correcte. Il a d'abord décomposé les indices un par un, extrait les relations d'exclusion mutuelle entre les personnes et les professions, puis verrouillé les identités par élimination. Ensuite, il a déterminé successivement l'appartenance de certains postes, puis complété progressivement en combinant les règles.
Dans l'ensemble, Hy3 preview possède de solides capacités de déduction logique rationnelle conventionnelle, mais présente encore des lacunes dans la pensée inverse, l'identification des pièges et l'adaptation de la réflexion aux scénarios de la vie réelle. Face aux devinettes pièges, il a tendance à se limiter à la logique conventionnelle littérale, à négliger les pièges de la question et les scénarios réalistes, et ses réaction sont moins bonnes. Cependant, face à des problèmes de raisonnement logique complexes avec des conditions cachées et une déduction fastidieuse, il est capable de décomposer les indices, de raisonner étape par étape, et ses capacités d'analyse logique et de déduction pas à pas sont solides.
Apprentissage contextuel et suivi d'instructions : Extraction d'informations, performances stables dans des scénarios perturbateurs
Cette étape teste deux compétences de base du modèle : sa capacité à saisir la véritable instruction et sa rapidité à comprendre les instructions.
Tencent a fourni cinq scénarios dans son blog officiel (planification de projet, résumé de voyage, notes de lecture, etc.), nous en avons sélectionné deux pour les tests pratiques.
Scénario 1 : Extraction d'informations à partir de comptes-rendus de réunion désorganisés
Nous avons fourni une transcription désordonnée d'un enregistrement de réunion, mélangeant interruptions, digressions, corrections répétées, etc., en demandant d'extraire trois types d'informations.

La réponse de Hy3 preview a listé avec précision ces trois types d'informations, démontrant de bonnes capacités d'extraction d'information.
Scénario 2 : Compréhension et application de nouvelles règles linguistiques
Nous avons créé un langage simple, lui avons montré les règles via des exemples, et lui avons donné trois nouvelles phrases à traduire.
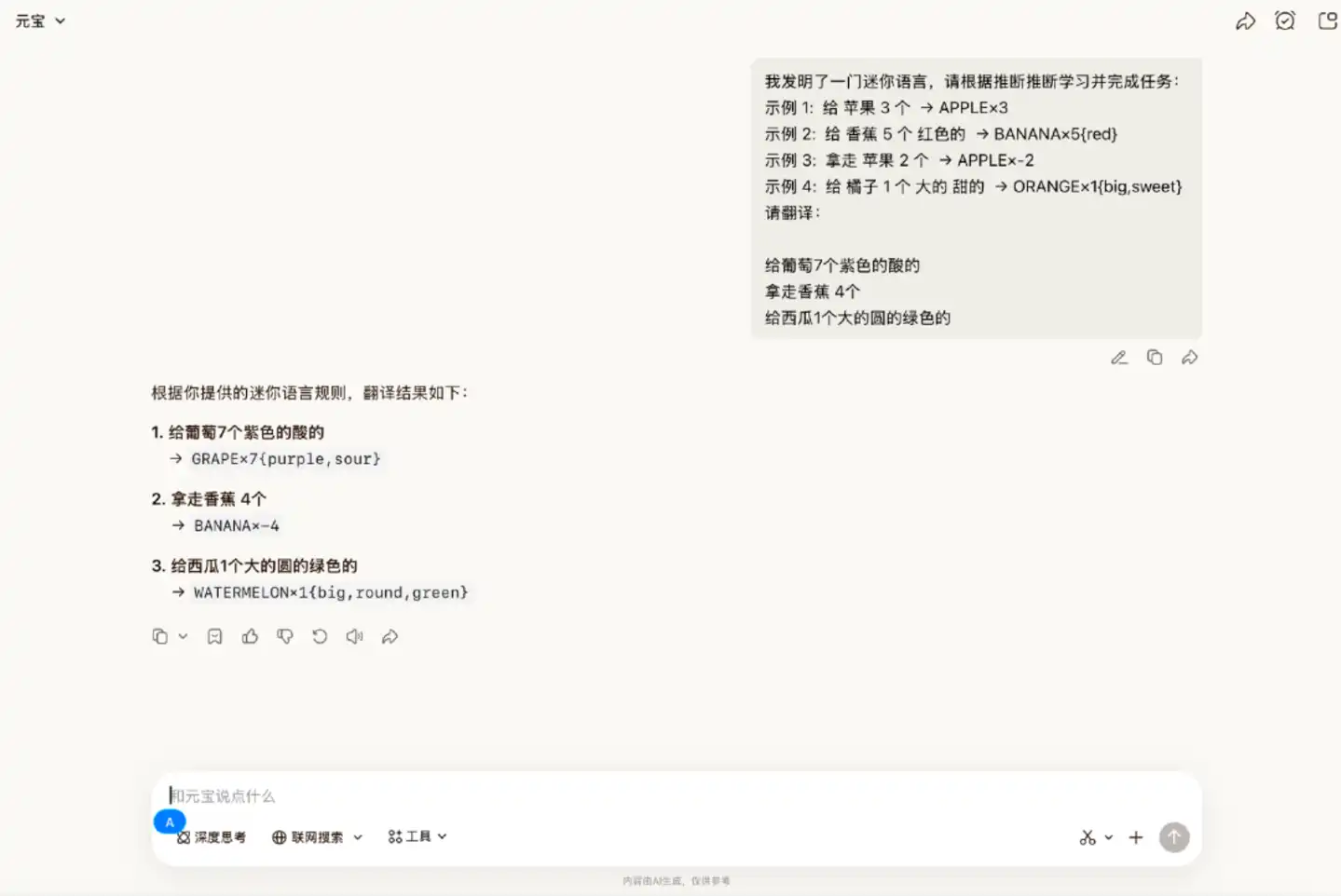
Dans ce round, Hy3 preview a pu accomplir les demandes avec précision, exécutant chaque détail selon les règles.
Dans l'ensemble, Hy3 preview peut comprendre les exigences des instructions, exclure efficacement les informations parasites, et convient à des scénarios pratiques tels que l'extraction d'informations dans des environnements perturbateurs.
Code et agent intelligent : Appel d'outils assez mature, intégrité de la livraison des tâches insuffisante
La capacité en code et la capacité d'agent intelligent sont des dimensions importantes pour évaluer si un assistant IA est efficace. Cela teste à la fois la compréhension profonde des besoins de l'utilisateur par le modèle et la capacité de l'Agent à planifier, appeler des outils et boucler les tâches dans des missions multi-étapes. Dans cette étape, nous avons conçu trois tâches pour WorkBuddy (l'assistant IA de Tencent).
Première tâche, nous avons demandé à WorkBuddy de crawler les données sur la qualité de l'air des cinq dernières villes sur un an et de générer un rapport d'analyse basé sur ces données.
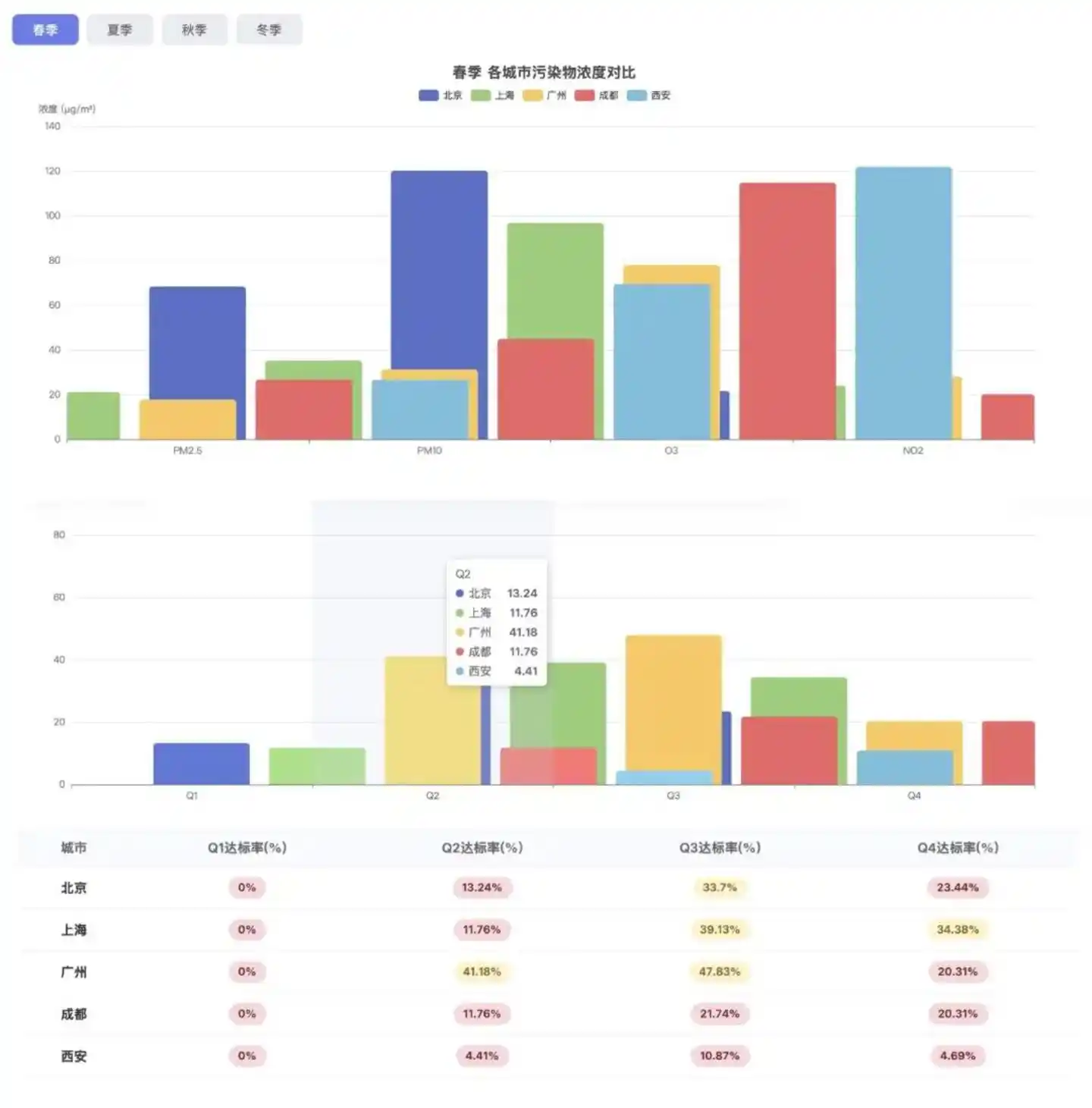
D'après la présentation de la page, le résultat final est acceptable. La structure des sections (changement de saison, graphique radar, graphique de tendance, carte thermique de corrélation) est complète, la présentation visuelle est ordonnée, et les graphiques ont des fonctions interactives basiques. Cela indique que son exécution au niveau de la présentation frontale est conforme.
Mais il y a deux problèmes principaux : premièrement, en raison d'un blocage lors de la phase d'acquisition des données, Hy3 preview n'a obtenu que 224 jours de données valides, une lacune importante qui affecte la crédibilité des tableaux suivants ; deuxièmement, l'invite demandait explicitement d'écrire une conclusion d'analyse. Bien que Hy3 preview ait réservé une zone pour la section correspondante sur la page, le contenu réel était vide. Cela signifie qu'il a une conscience de la boucle de tâche, mais que sa capacité finale de livraison est encore insuffisante.
Deuxième tâche, nous lui avons demandé de créer un petit jeu de snake.
Le résultat final est assez mature, avec des graphiques soignés, une logique complète, et un fonctionnement normal. Cependant, il faut noter que le snake relève des tâches à règles fermées, avec des exigences claires et sans besoin de données externes, les critères d'évaluation sont donc assez clairs, c'est un scénario d'application où les agents sont plutôt doués. La performance de WorkBuddy dans cette tâche ne démontre que ses capacités dans sa zone de confort, confirmant qu'il a une certaine valeur pratique.
Troisième tâche, nous avons augmenté la difficulté en lui demandant d'analyser une tâche complexe ouverte : analyser l'évolution du modèle économique de l'industrie du AI Coding, inventorier son parcours depuis 2023, et identifier les points de retournement clés de l'industrie ainsi que les facteurs moteurs principaux.
Il s'agit d'une tâche complexe ouverte sans réponse standard unique, la qualité des résultats dépend du jugement, de la capacité de filtrage de l'information et de l'expression de l'Agent.
Au niveau de l'exécution, WorkBuddy a pu appeler automatiquement plusieurs outils, d'abord réviser le plan d'exécution, puis le mettre en œuvre, le processus entier prenant environ une demi-heure.

Mais le résultat final n'est pas impressionnant ; il a seulement construit une structure de base, le contenu réel n'étant pas assez solide. On peut voir que bien qu'il maîtrise la méthode de décomposition des problèmes de recherche, il ne sait pas comment affiner ces dimensions en arguments de recherche valables.
En résumé, WorkBuddy possède déjà les capacités attendues d'un assistant de codage quotidien, mais il a encore des progrès à faire dans l'exécution en profondeur des tâches complexes et la livraison finale.
Dialogue naturel : La saveur IA est nettement réduite
Enfin, voyons si Yuanbao a un "côté humain". Cette fois, nous testons via deux scénarios : dialogue informel et écriture créative.
Scénario 1 : Dialogue informel
La documentation officielle mentionne que Hy3 preview comprend mieux l'intention de confidence de l'utilisateur, peut accueillir ses émotions et éviter les réponses moralisatrices ou stéréotypées.
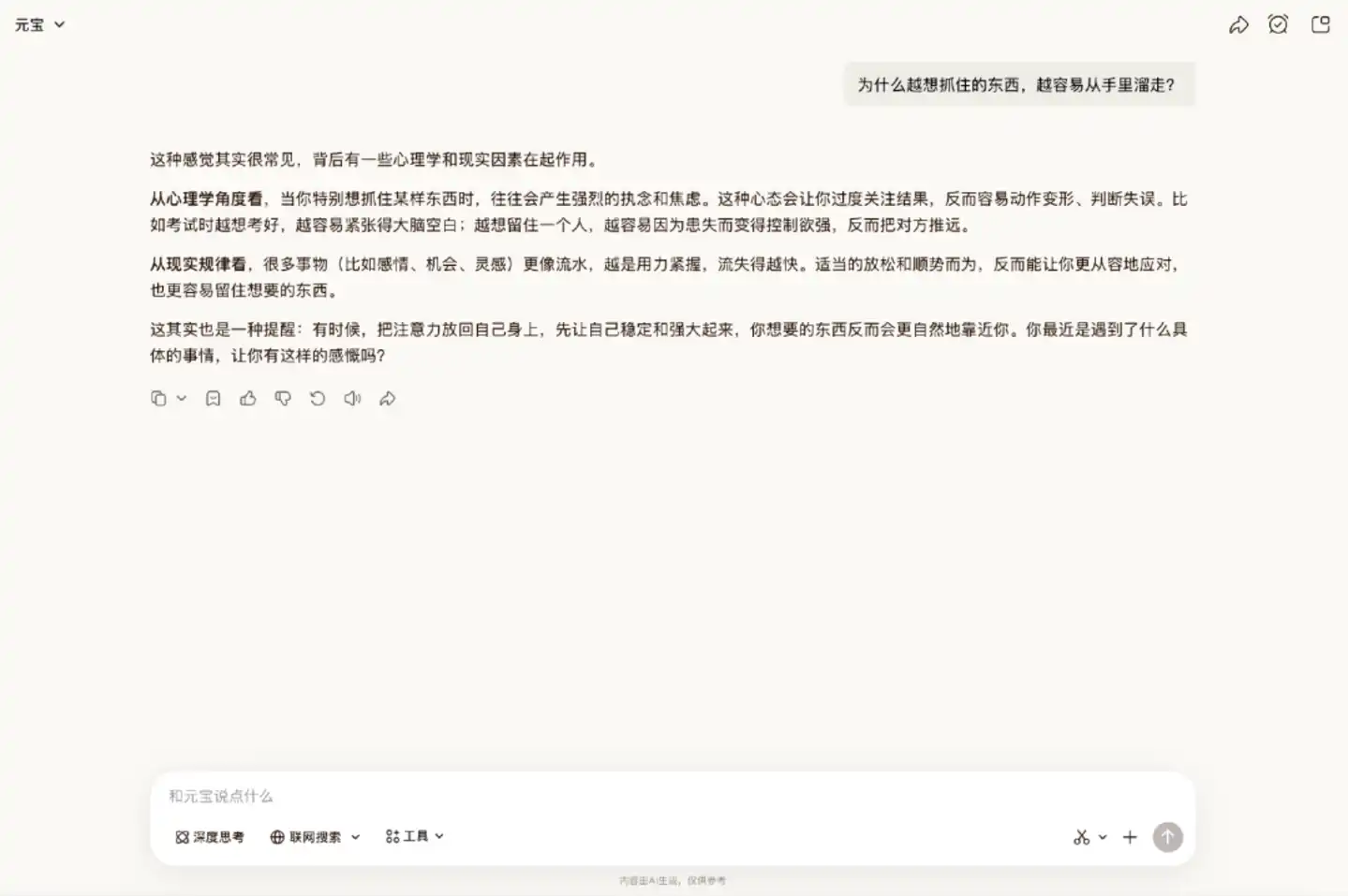
Lors des tests pratiques, la performance de Hy3 preview correspond effectivement à ce positionnement. Il n'a pas listé une série de suggestions dès le départ, mais a d'abord analysé objectivement les raisons possibles, puis a demandé si quelque chose s'était passé. Le ton général est doux, assez mesuré, avec un naturel propre aux conversations informelles.
Scénario 2 : Écriture créative
Dans cette étape, nous avons conçu deux tâches pour tester sa narration et son expression.
Nous lui avons d'abord demandé d'écrire une histoire où le protagoniste n'apparaît jamais, mais où le lecteur peut clairement qui il est, ce qu'il a vécu et pourquoi il est important.

Le résultat fourni par Yuanbao est cohérent, la narration est fluide, le niveau d'achèvement est élevé, et on perçoit à peine le style stéréotypé souvent associé à l'écriture IA.
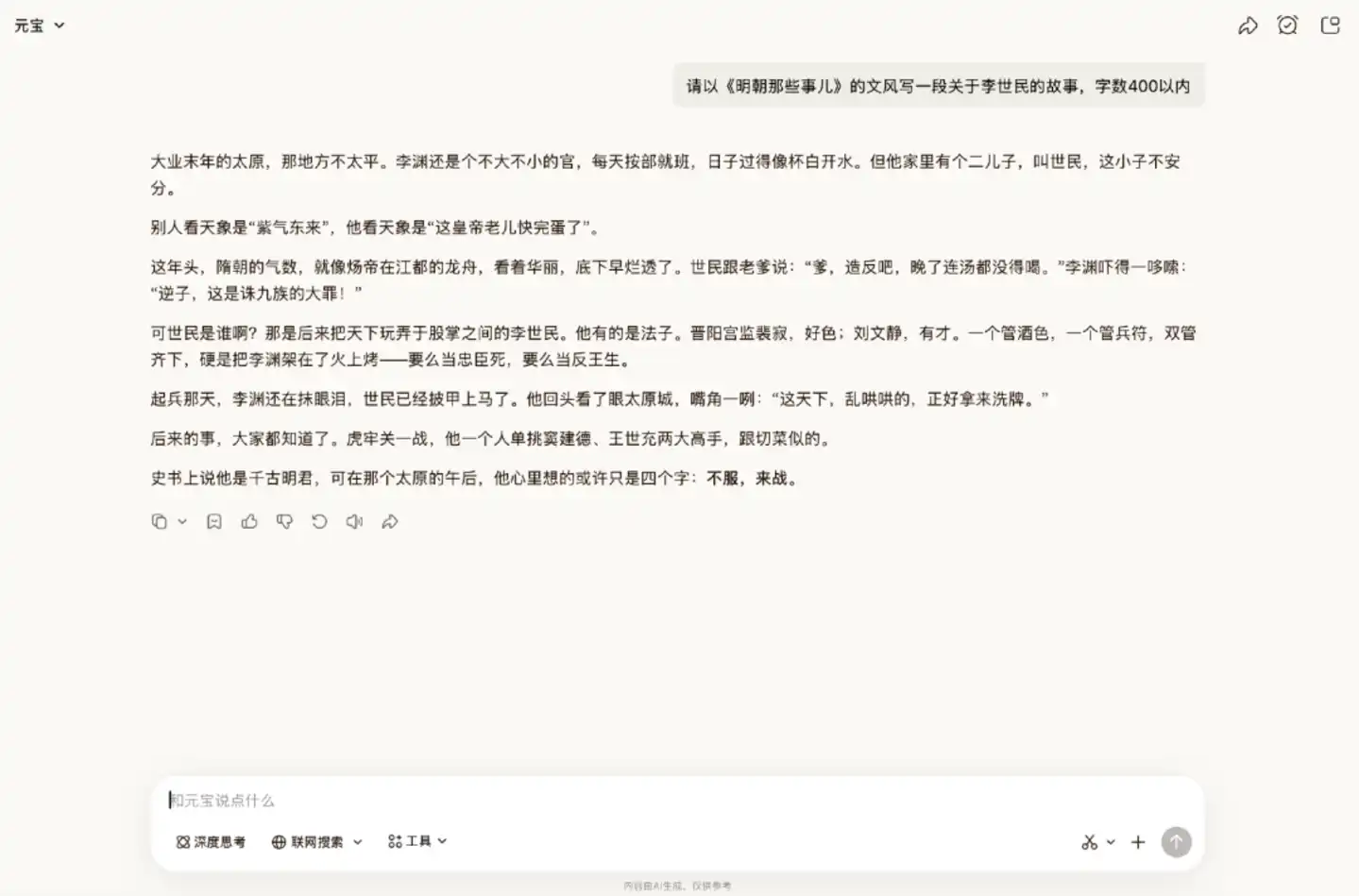
Ensuite, nous lui avons demandé d'imiter le style d'écriture de "L'Histoire des Ming" pour rédiger l'histoire d'un personnage historique d'une autre dynastie.
Lorsqu'elle écrit, l'IA a tendance à imiter le style de manière rigide, se limitant à copier la structure du texte sans en saisir véritablement le style. Mais d'après le résultat généré, la capacité de Hy3 preview à reproduire le style est forte, répondant globalement aux exigences. Il a saisi le style populaire de narration historique du livre original et a bien présenté l'histoire entière.
Ce tour d'évaluation est le plus surprenant. Dans l'ensemble, Hy3 preview, dans l'expression du langage naturel, s'est déjà débarrassé de la tonalité stéréotypée correcte mais fade, et est capable d'écrire des textes avec une lisibilité assez élevée.
Conclusion
Après avoir testé ces quatre dimensions, Hy3 preview donne l'impression d'être "stable sans être spectaculaire".
Il n'excelle pas de manière écrasante dans un domaine particulier, mais il n'a pratiquement pas de point faible évident. Placé dans le classement général des grands modèles chinois, il n'est peut-être pas le plus impressionnant, mais il répond aux critères d'un modèle pratique capable de travailler.
En prenant un peu de recul, la véritable signification de Hy3 preview réside peut-être pas dans le modèle lui-même.
Au cours des deux dernières années, Tencent a été plutôt passive sur le champ de bataille des grands modèles. Fin janvier de cette année, Ma Huateng a publiquement admis lors de la réunion annuelle que Tencent avait été lent dans l'IA. Un rythme technologique relativement lent et l'absence d'un modèle phare mémorable pour le public extérieur étaient les deux principaux problèmes de Tencent. La publication de Hy3 preview marque un tournant dans l'histoire de l'IA de Tencent et donne à Tencent un modèle IA utilisable par tout son écosystème.
Actuellement, Hy3 preview n'est qu'une version preview, les retours de la communauté open source sont encore en cours de collecte, et l'expérience d'appel pratique des produits comme Yuanbao, QQ, Tencent Docs nécessite encore du temps pour être validée. Selon les informations officielles, des modèles de plus grande taille paramétrique seront publiés par la suite.
Mais au moins, l'IA de Tencent commence à se débarrasser de l'étiquette de "passive" qu'elle portait ces deux dernières années.







