Auteur : Vendredi, Deep Tide TechFlow
Anthropic vient de présenter un dossier, sur le papier, irréprochable.
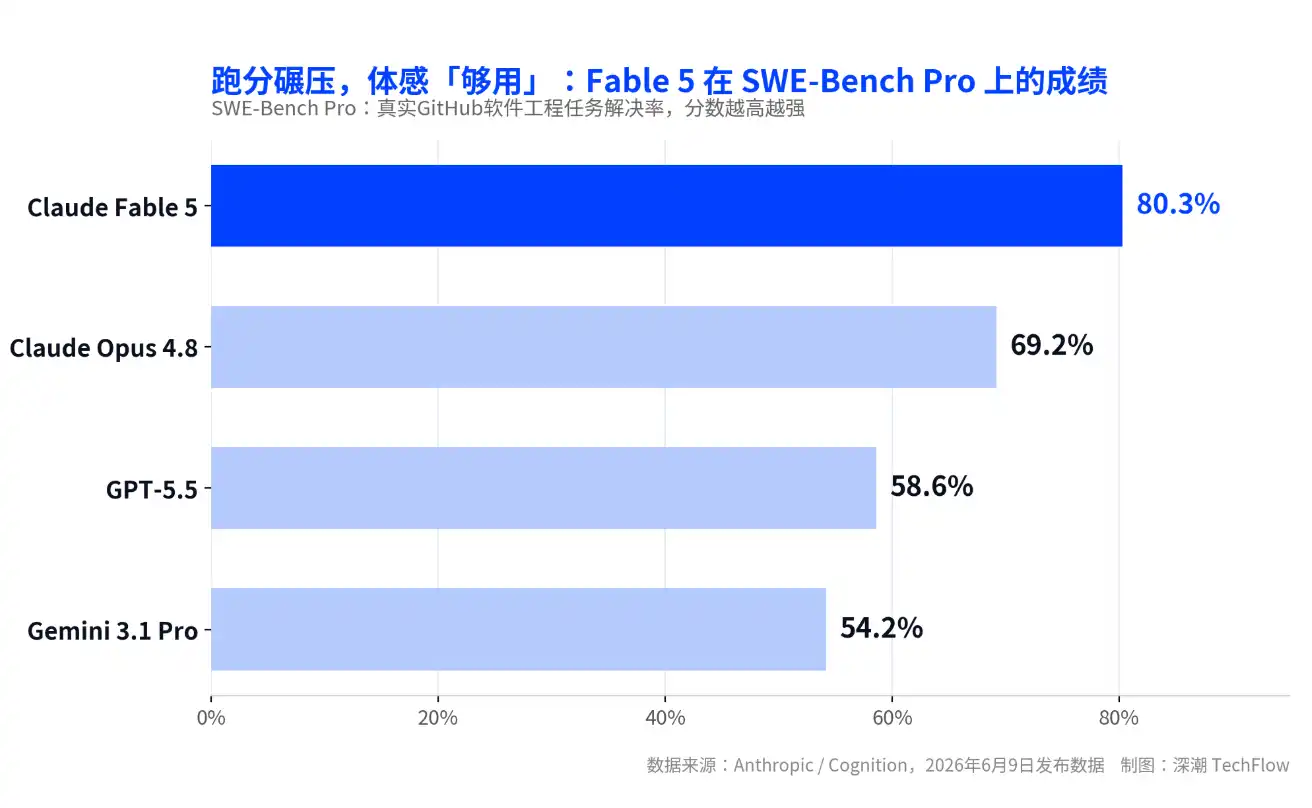
Claude Fable 5, lancé le 9 juin, est le premier modèle de niveau Mythos de la société ouvert au grand public. Il a atteint 80,3% sur le benchmark SWE-Bench Pro pour les tâches réelles d’ingénierie logicielle, dépassant de 11 points environ son prédécesseur Opus 4.8 et de plus de 20 points le GPT-5.5.
Mais la réaction des utilisateurs a jeté un seau d’eau froide.
Trois jours après la sortie, un post populaire sur le forum r/artificial (trafic hebdomadaire : 305 000 visites) portait le titre : « Claude Fable m’a fait réaliser que je n’ai plus besoin de meilleurs modèles. » L'auteur, Axi0m-22, a expliqué avoir utilisé Fable pendant un temps pour de la recherche en sécurité et du travail quotidien, avant de repasser presque immédiatement à Opus pour écrire du code et à Haiku pour les petites tâches. Il a fait une comparaison : C’est comme avoir un iPhone 14 et voir la sortie de l’iPhone 17, « tu sais que le nouveau est meilleur, mais tu te dis : laisse tomber, le mien fait très bien l'affaire. »
Le haut des votes dominé par les « suffisants » : la fatigue des modèles devient le sentiment dominant
Le commentaire le mieux noté, avec 42 votes positifs, déclare : « À part une fenêtre contextuelle plus grande, je n’ai plus ressenti le besoin d’un modèle plus puissant depuis Opus 4.5. »
Un autre utilisateur, hyprlab, a reçu 13 votes pour son avis : « Passer à un modèle qui brûle plus de tokens, je ne vois pas l’avantage pour mon flux de travail, le mode intensif d’Opus 4.8 est déjà bien assez confortable. »
Derrière ce type de déclarations se cache un calcul de coût commun.
Le prix de l’API pour Fable 5 est fixé à 10 dollars par million de tokens en entrée, soit près du double de celui d’Opus 4.8. L’utilisateur siromega37 le dit crûment : « Consommation de tokens plus élevée, mais sans retour sur investissement. Je pense que nous assistons à un plateau, la bulle finira par éclater. »
L’utilisateur hobopwnzor propose une interprétation plus systématique : « Nous sommes en haut de la courbe en S depuis un moment. Les progrès récents viennent surtout de l’appel d’outils et de l’ingénierie périphérique, pas des capacités intrinsèques du modèle. »
Les garde-fous de sécurité, plus gros sujet de mécontentement : « 90% des usages sont directement rejetés »
Si le « suffisant » n’est qu’une question d’humeur, les plaintes concernant les garde-fous de sécurité relèvent d’un problème produit concret.
Selon les explications officielles d’Anthropic, Fable 5 partage le même modèle de base que Mythos 5, lequel n’est accessible qu’à quelques institutions, la différence étant que Fable est équipé d’un classifieur de sécurité : les requêtes liées à des domaines à haut risque comme la cybersécurité sont interceptées et transmises à Opus 4.8 pour y répondre. La société affirme que ce mécanisme est réglé de manière conservatrice, se déclenchant en moyenne dans moins de 5% des sessions, et peut toucher des requêtes inoffensives.
Sous ce post Reddit, la perception du taux de déclenchement est nettement supérieure à 5%. L’utilisateur jradoff, dont le commentaire a reçu 17 votes, dit avoir demandé à Fable de vérifier la sécurité de son code, et « dès qu’on mentionne quelque chose lié à la sécurité, il refuse pratiquement toujours de traiter », avant d’être renvoyé vers Opus. Un autre commentaire avec 12 votes est encore plus sévère : « 90% de ce pour quoi vous voulez l’utiliser sera rejeté, donc inutile. »
Les utilisateurs payants sont encore plus mécontents. L’utilisateur kaitava, abonné au niveau à 200 dollars, écrit : « Je paie le double pour l’utilisation, je lui demande de faire une revue de sécurité, et je suis rétrogradé vers Opus. Du coup, je n’aime plus rien chez lui, j’attends qu’OpenAI le rattrape. »
Pour un produit phare censé représenter un saut de capacité, « le coût en utilisabilité payé pour la sécurité » devient une variable centrale dans la décision des utilisateurs de payer ou non.
Les voix contraires : pour les utilisateurs de tâches intensives, la sensation est celle d’un « jour et nuit »
Le post populaire n’est pas dépourvu d’opposants, et le profil de ces derniers est assez clair : plus la tâche est lourde, plus l’évaluation est positive.
Le commentaire de l’utilisateur Phylaras a reçu 15 votes : « Fable a fait une différence substantielle pour moi. Pour ces tâches complexes demandant une énorme fenêtre contextuelle, il a détecté des erreurs qui n’avaient pas été repérées avant. » Un utilisateur se présentant comme travaillant sur des simulations en physique des hautes énergies indique qu’un seul modèle de simulation fait facilement entre 8 000 et 10 000 lignes de code, avec des centaines de modèles en interaction. « Avoir un modèle capable de travailler de manière autonome et continue, en comprenant les détails de l’environnement, c’est très prometteur pour moi. »
La réfutation la plus vive vient de l’utilisateur Navetz : « Pour être honnête, ceux qui ont utilisé ce modèle trouveront ce genre de post dingue. Pour moi, il est intelligent au point d’être une autre personne, je l’utilise en continu. J’explique à mes amis non-techniques : c’est comme passer directement d’un joueur universitaire à un titulaire en NBA. »
D’autres proposent des usages intermédiaires. L’utilisateur ready-eddy suggère d’utiliser Fable comme « planificateur et correcteur », et non comme « constructeur » quotidien, sauf si l’argent n’est pas un problème. Un autre commentaire résume cela de manière plus proche d’un manuel d’utilisation : utiliser Fable pour des calculs de tableaux, c’est choisir le mauvais modèle ; utiliser Haiku pour une tâche complexe avec 16 agents intelligents, c’est aussi choisir le mauvais modèle. « Il n’y a pas de mauvais modèle par nature, seulement des modèles utilisés dans le mauvais contexte. »
Après le découplage entre les scores et la perception, l'IA publique deviendra-t-elle encore plus puissante ?
Le commentaire le plus intéressant de ce débat oriente la conversation du produit vers la structure de l’industrie.
L’utilisateur KedMcJenna émet une « théorie du gel de l'IA publique » : les modèles accessibles au grand public pourraient rester figés près du niveau actuel pour toujours, tandis que les élites des entreprises et des gouvernements continueront d’obtenir des modèles privés plus puissants. « Nous savons qu’il existe au moins Mythos, et probablement des modèles encore plus forts dont nous n’entendrons jamais parler. »
Ce commentaire pointe un fait : Mythos 5 n’est effectivement pas ouvert au public. Il n’est actuellement disponible que pour les agences de défense des réseaux et les entreprises d’infrastructures critiques via le programme Project Glasswing.
En juxtaposant les résultats des benchmarks et les réactions, la conclusion n’est pas contradictoire.
Les tests de référence mesurent un plafond de capacité, tandis que le haut des votes sur Reddit reflète le plafond des besoins quotidiens. Lorsque la plupart des utilisateurs voient leurs tâches satisfaites depuis l’ère Opus 4.6, les modèles plus puissants ne peuvent se justifier que dans des scénarios extrêmes comme les simulations physiques ou les contextes très longs. Les fabricants de modèles ne font plus face à un problème de « faisabilité », mais à des questions de « qui en a besoin, est prêt à payer combien, et peut tolérer combien de friction sécuritaire ».
Trois jours après son lancement, Fable 5 a reçu deux bulletins de notes complètement différents : l’un sur les classements de benchmarks, l’autre sur l’opinion publique. Lequel se rapproche le plus de la vérité dépendra de la vitesse à laquelle Anthropic ajustera son classifieur de sécurité, et des votes par portefeuille des utilisateurs intensifs.






