Personne ne s’attendait à une claque aussi rapide !!
À l’instant, l’UC Berkeley a dévoilé un nouveau benchmark baptisé “Le Dernier Examen des Agents”.
Il a convoqué les Agents IA les plus puissants du moment dans une salle d’examen pour leur faire accomplir de vraies tâches :
Modéliser en 3D dans Siemens NX, monter des scènes de jeu dans Unreal Engine, faire du compositing d’effets spéciaux dans Adobe After Effects.
Les résultats sont sidérants :
Dans le niveau le plus difficile, Claude Fable 5, actuellement reconnu comme le plus fort, et GPT 5.5, affichent tous les deux un gros zéro pointé.
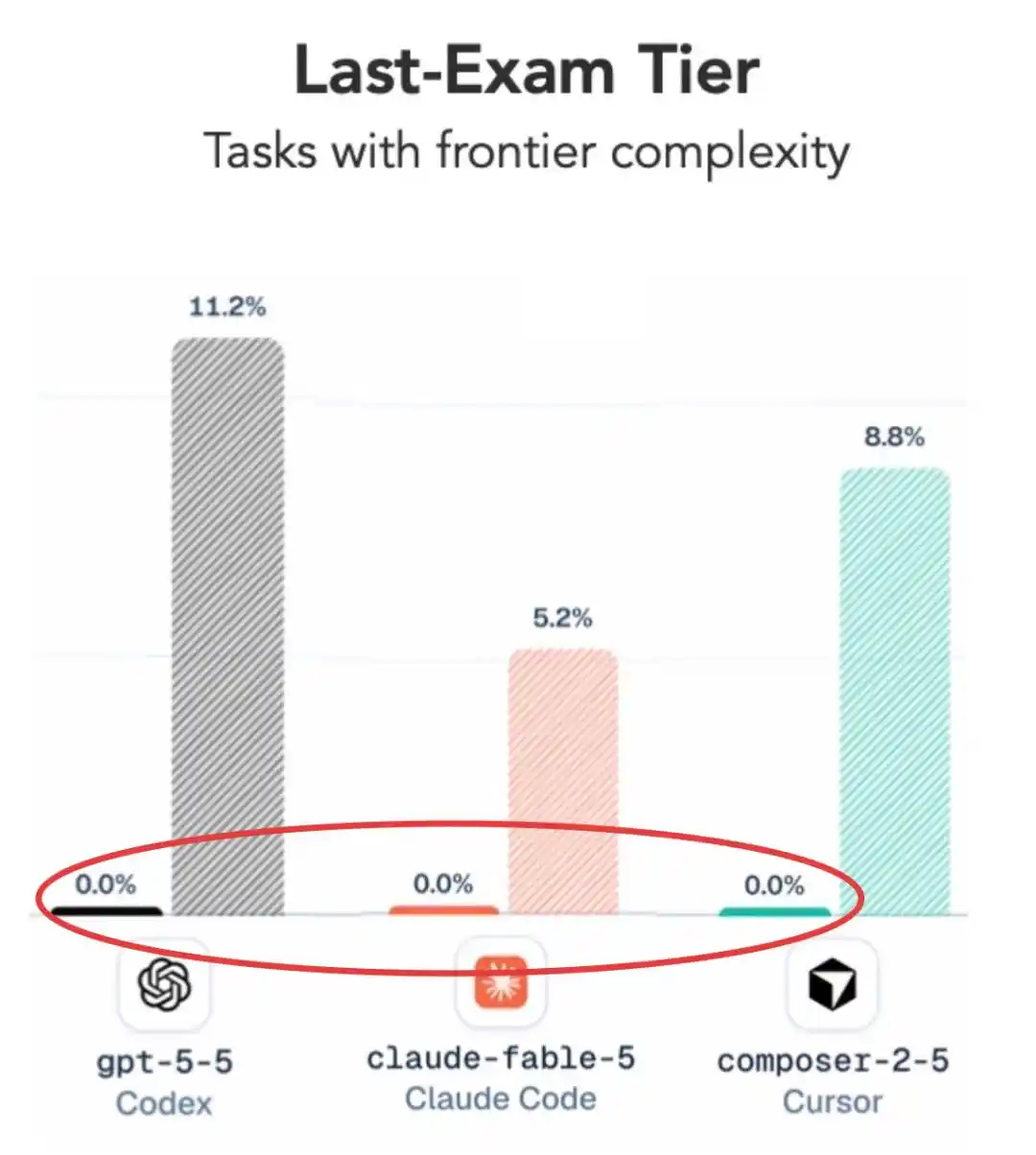
Si on baisse un peu la difficulté ? Les scores apparaissent, mais le résultat est tout aussi surprenant —
GPT 5.5 parvient même à devancer légèrement Claude Fable 5.
Je ne rêve pas ? Claude Fable 5, le modèle ultime tout juste sorti chez Anthropic, est battu par le GPT 5.5 vieux de plusieurs mois ??
Rappelons que sur presque tous les principaux benchmarks précédents, Fable 5 écrasait GPT 5.5 — 80,3 % contre 58,6 % sur SWE-Bench Pro, 64,5 % contre 52,2 % sur Humanity’s Last Exam.
Mais dans cet examen de “vrai travail”, la donne s’inverse.
Ce nouveau benchmark s’appelle Agents’ Last Exam (ALE). L’équipe derrière n’est pas n’importe qui, elle est à l’origine des benchmarks que vous connaissez bien : MMLU, MATH, CyberGym, ExploitGym.
Le nom est probablement un clin d’œil à “Humanity’s Last Exam” de Scale AI, sauf qu’ici, ce n’est pas la limite des connaissances humaines qui est testée, mais la limite de ce que les Agents IA peuvent accomplir.
Il faut le dire, une fois ce benchmark publié, ceux qui criaient tous les jours “Les Agents vont remplacer les humains au travail” sont restés... silencieux.
“Le Dernier Examen des Agents”, le vainqueur est GPT 5.5 !
Voici d’abord le classement complet.
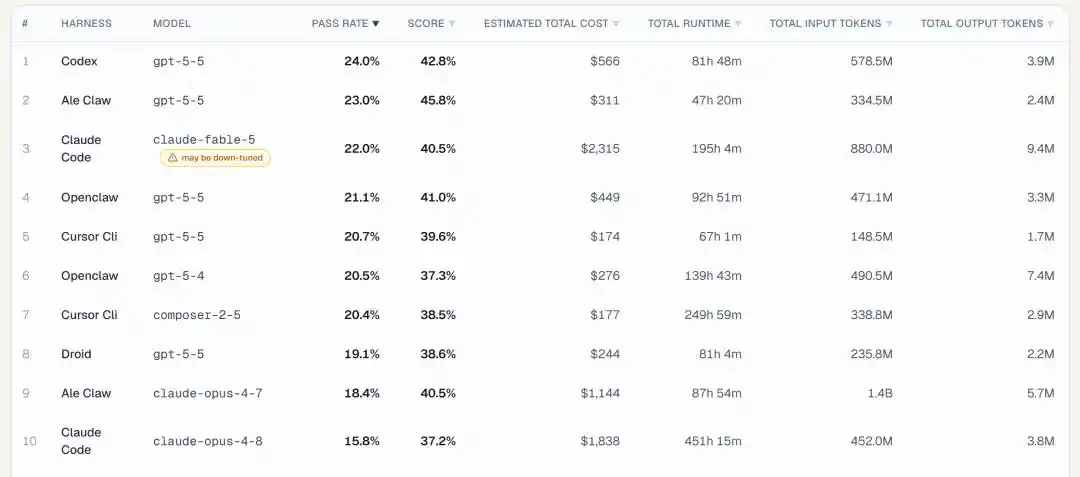
En regardant l’indicateur clé du taux de réussite des tâches, GPT 5.5 rafle directement la première et la deuxième place :
1ère place : GPT 5.5 couplé au framework Codex d’OpenAI, taux de réussite 24,0 %.
2ème place : Toujours GPT-5.5, mais avec le framework ALE Claw, taux de réussite 23,0 %.
(ALE Claw est un Agent baseline écrit par l’équipe, en compétition avec les frameworks commerciaux comme Codex, Claude Code, Cursor CLI)
Ce n’est qu’à la 3ème place qu’apparaît Claude Fable 5 — couplé à Claude Code, avec un taux de réussite de 22,0 %.

Plus on descend, plus c’est intéressant.
Les 4ème, 5ème et 8ème places sont toutes occupées par GPT 5.5, simplement avec des frameworks différents.
Dans le top 10, GPT 5.5 apparaît 5 fois, et avec GPT 5.4 en 6ème place, les modèles OpenAI occupent 6 places.
Et la famille Claude ?
Fable 5 est 3ème, Opus 4.7 est 9ème (18,4 %), Opus 4.8 est dernier (10ème, 15,8 %). La supériorité est nette.
Pas étonnant qu’un chercheur d’OpenAI poste joyeusement sur X, comme pour célébrer une fête :
Au-delà des scores, il y a plusieurs signaux à analyser.
Premier signal : le plafond est incroyablement bas.
Le taux de réussite du champion n’est que de 24 %, et le score composite maximal ne dépasse pas 45,8 %.
Cela signifie que même en comptant les “points partiels” de la manière la plus indulgente, l’Agent le plus fort ne peut obtenir moins de la moitié des points.
Et toutes ces tâches proviennent de projets déjà réalisés par des experts humains — le taux de réussite théorique de l’expert humain est de 100 %.
Deuxième signal : Claude brûle de l’argent de façon impressionnante.
Le classement inclut une nouvelle colonne “Estimated Total Cost”, qui révèle un fossé immense :
Fable 5 a coûté 2315 dollars pour l’ensemble des tâches, Opus 4.8 a coûté 1838 dollars, Opus 4.7 a coûté 1144 dollars.
Et GPT-5.5 ?
Le plus cher, Codex, a coûté 566 dollars, Cursor CLI seulement 174 dollars.
En d’autres termes, Fable 5 a dépensé plus de quatre fois l’argent de Codex, pour un score inférieur de deux points de pourcentage.
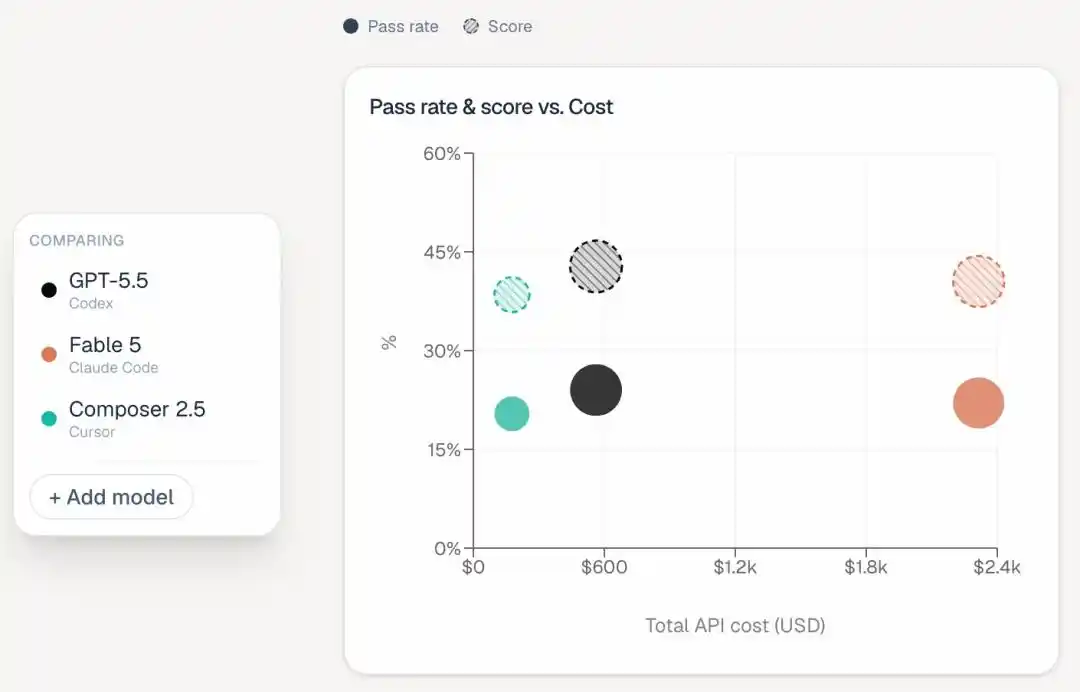
Troisième signal : l’écart d’efficacité est tout aussi frappant.
ALE Claw a mis 47 heures et 20 minutes pour toutes les tâches, Cursor CLI seulement 67 heures.
Et Opus 4.8 ? 451 heures — près de 19 jours.
Le moins de travail accompli, le plus de temps pris, le plus d’argent dépensé (un modèle peut-il vraiment cumuler ces trois défauts ?)
Bien sûr, si on ne regarde que les deux meilleurs, Claude Fable 5 et GPT 5.5, l’avantage temporel de GPT 5.5 reste évident.

Mais le chiffre le plus frappant reste ce zéro.
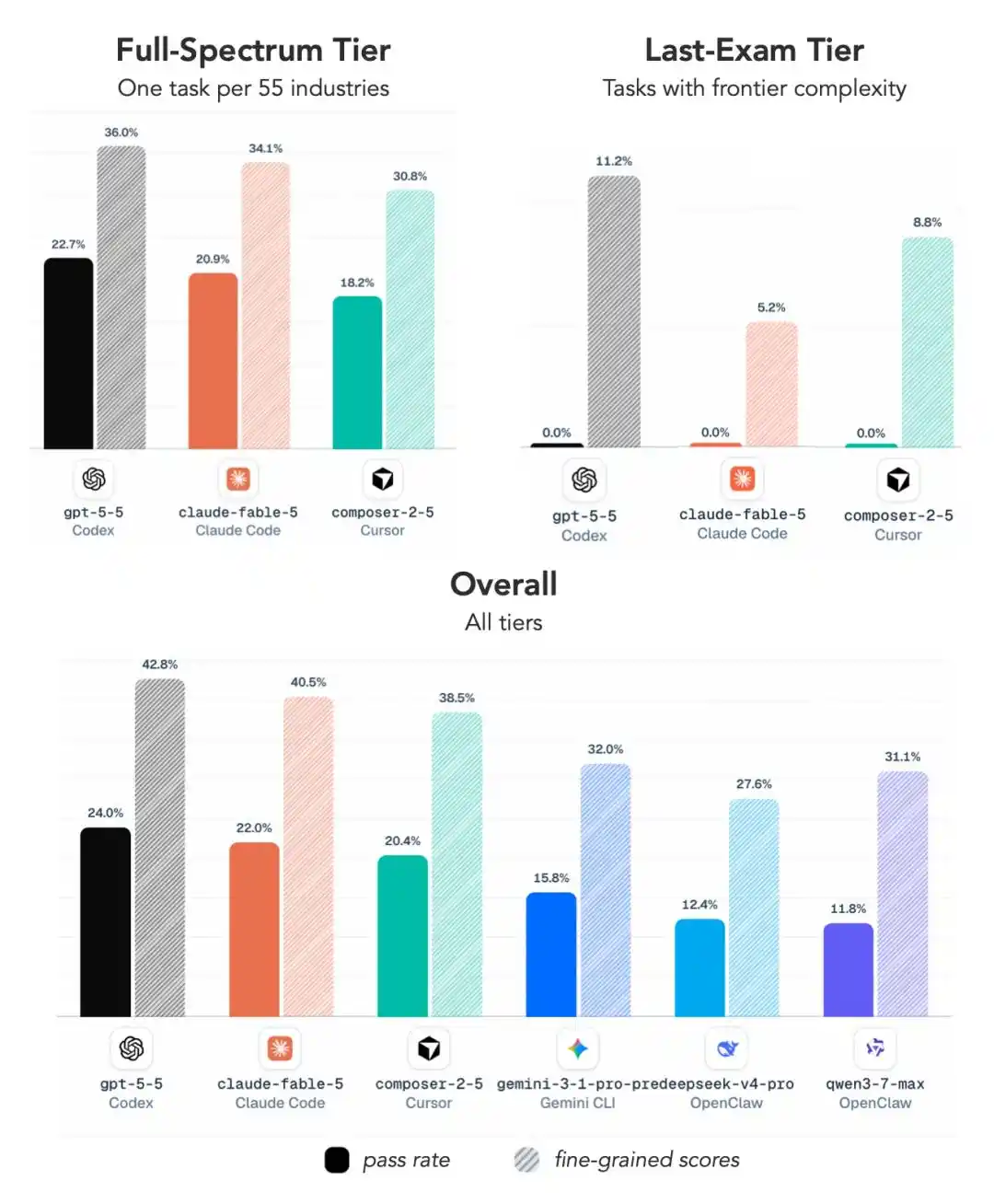
ALE divise les tâches en trois niveaux de difficulté :
Near-Term (à court terme)
Full-Spectrum (spectre complet)
Last-Exam (problèmes ultimes)
Au niveau le plus difficile, le taux de réussite moyen de toutes les configurations principales n’est que de 2,6 %, et la plupart des modèles, y compris GPT 5.5 et Fable 5, ont carrément obtenu zéro pointé.
Le message central de ce bulletin est simple : Ne vous fiez pas aux bonnes notes en examen, quand il s’agit de vrai travail, tout se révèle.
Être un crack aux QCM ne fait pas de vous un as du travail manuel, et cela vaut aussi pour le monde de l’IA.
Qu’est-ce qu’ALE ?
Pour comprendre pourquoi ALE peut remettre ces “cracks” à leur place, il faut voir en quoi il diffère des examens précédents.
Le précédent Humanity’s Last Exam (HLE), créé début 2025 par Dan Hendrycks et Scale AI avec 2500 problèmes interdisciplinaires, était essentiellement un examen sur table —
On te pose une question, tu me donnes une réponse, aussi difficile soit-elle, c’est une recherche de connaissances statique.
ALE est totalement différent, il teste “ce que tu peux faire”.
L’auteur principal Yiyou Sun le dit clairement sur X :
Les prédictions selon lesquelles les agents IA dépasseront les humains dans presque tous les travaux d’ici 2026-2027 sont partout. Nous avons donc créé cet examen pour vérifier cette affirmation.

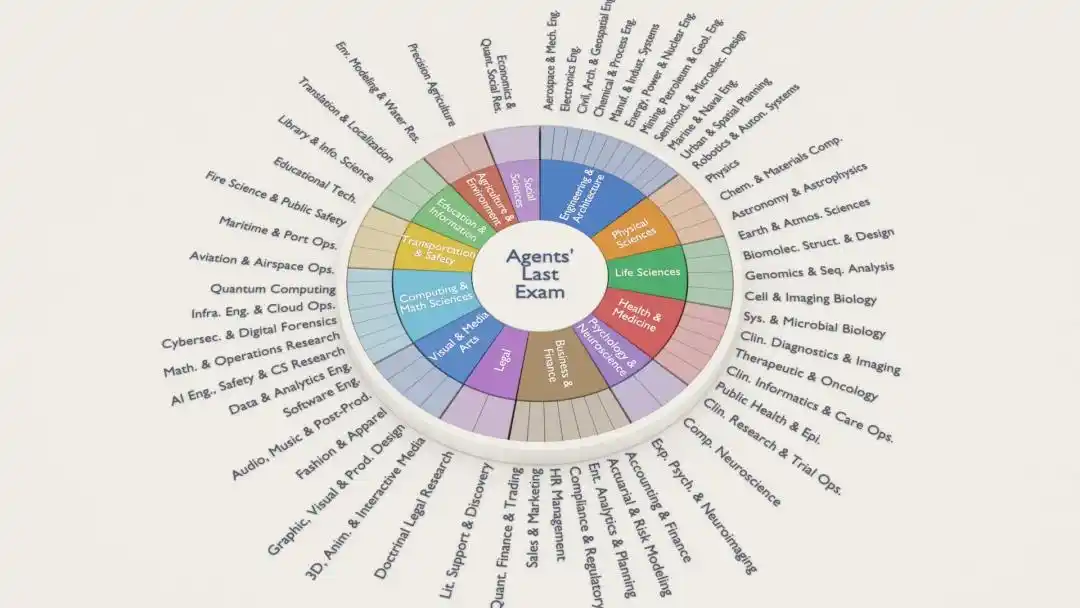
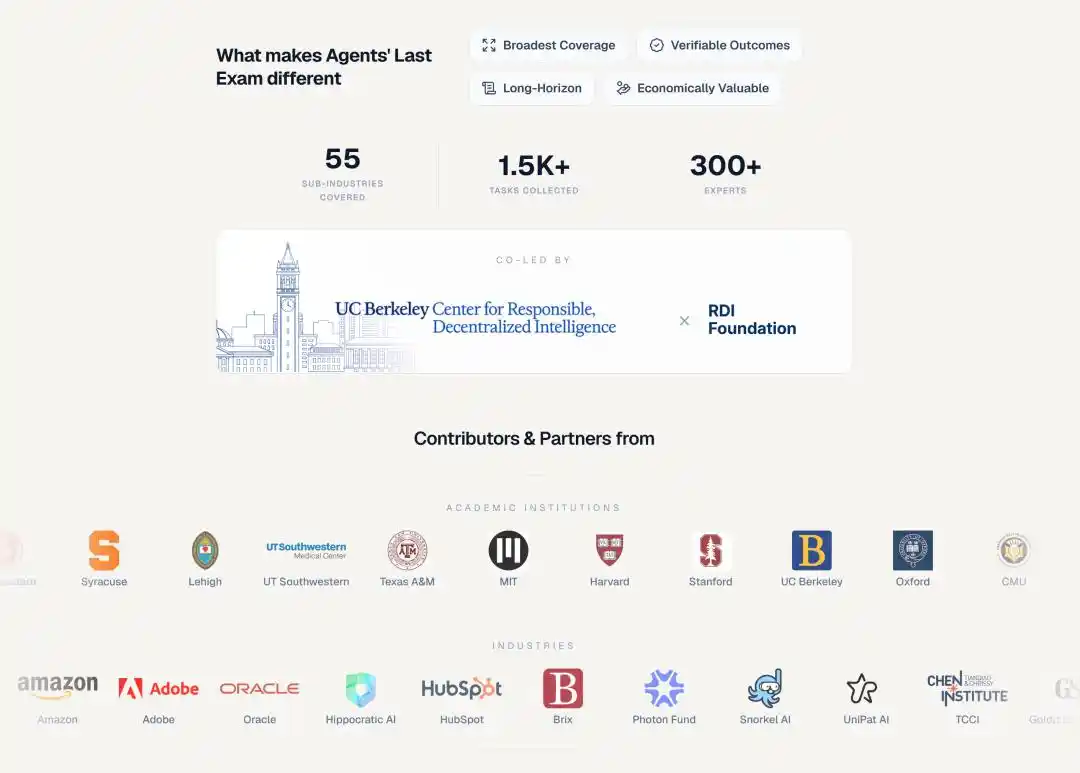
Chaque question d’ALE provient d’un projet déjà réalisé par un expert humain, couvrant 55 sous-domaines professionnels, notamment le trading quantitatif, l’analyse génomique, l’ingénierie aérospatiale, la conception architecturale, l’imagerie cérébrale, les effets spéciaux d’animation, la recherche juridique...
Le système entier est ancré sur la norme de classification professionnelle fédérale américaine (ONET)*, en clair, les sujets sont conçus selon le “marché du travail réel”.
Le panel des concepteurs de sujets est également impressionnant :
Plus de 300 experts de domaines provenant de plus de 100 institutions, côté académique : MIT, Harvard, Stanford, Oxford, Caltech, ETH Zurich ; côté industriel : Goldman Sachs, JPMorgan, Meta, Amazon, Adobe, Oracle.
Snorkel AI a fourni un soutien financier via le projet Open Benchmarks Grants.
La forme de l’examen n’est pas non plus de taper des réponses, mais d’opérer directement sur un ordinateur.
ALE utilise le cadre dit GCUA (Generalist Computer-Use Agent, Agent généraliste d’utilisation informatique), donnant à l’Agent un accès complet à l’interface graphique (GUI) et à la ligne de commande —
Clics de souris, frappe au clavier, écriture de scripts, navigation web, tout ce qu’un humain peut faire sur un ordinateur, l’Agent peut le faire.
Aucune méthode n’est imposée, seuls les résultats comptent.
Les “devoirs” rendus sont notés automatiquement par du code déterministe.
Pas d’impressions. Pas de juges humains. Totalement reproductible.

Cela corrige un vieux défaut de nombreux benchmarks précédents : le correcteur lui-même pouvait être trompé.
De plus, ALE a une astuce redoutable contre la triche —
Seulement environ 10 % des questions (environ 150) sont publiques, les 1300+ restantes sont strictement confidentielles.
Les questions publiques et privées sont régulièrement permutées, garantissant qu’aucun modèle n’obtienne un score élevé en “récitant” les réponses.
Dans le contexte actuel de contamination massive des données de benchmark, c’est une conception plutôt ingénieuse.
Globalement, comparé aux benchmarks d’Agent existants, le positionnement d’ALE est très clair.
Dawn Song, membre de l’équipe, a établi une comparaison :
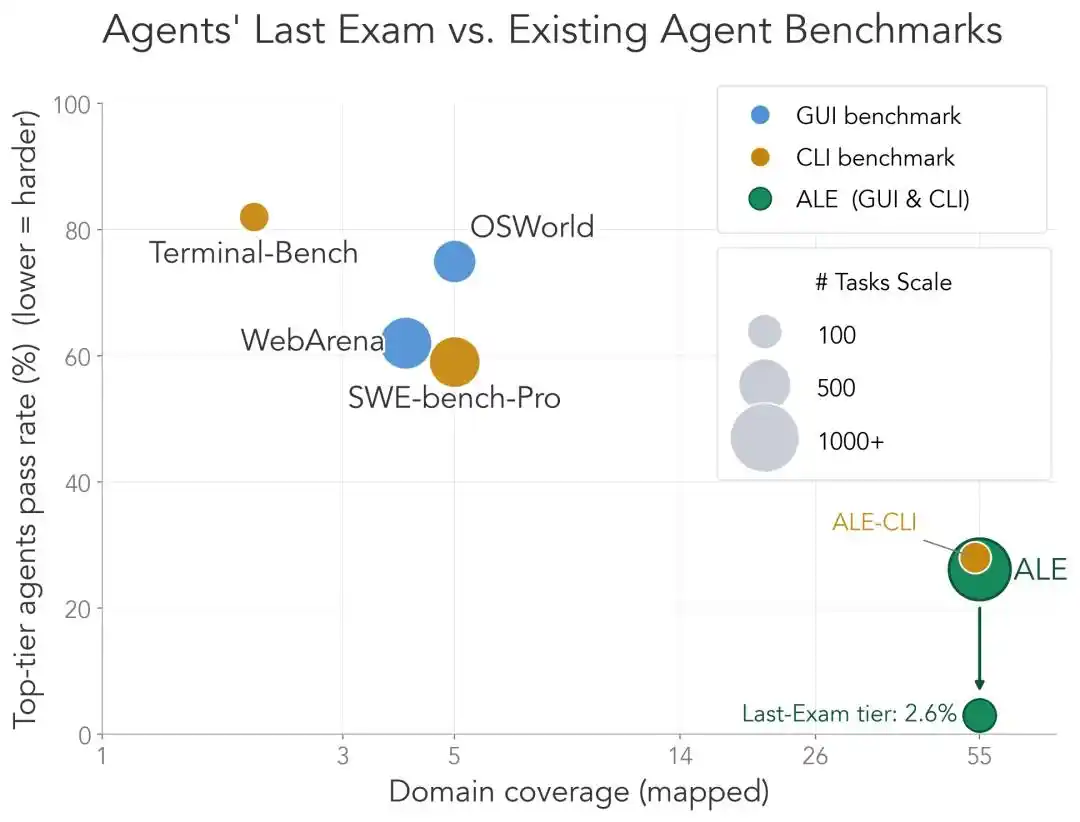
Le sous-ensemble CLI d’ALE (ALE-CLI) couvre 40 sous-domaines professionnels, alors que Terminal-Bench n’en couvre que 6, et SWE-bench-Pro seulement 5 ;
Le temps humain pour accomplir ces tâches va de quelques heures à quelques semaines, alors que pour les deux autres, c’est de quelques minutes à quelques jours ;
Le taux de réussite de l’Agent le plus fort sur ALE-CLI n’est que de 25,2 %, contre 82,0 % sur Terminal-Bench et 59,1 % sur SWE-bench-Pro.
En un mot, les autres examens sont presque percés à jour, tandis qu’ALE en est encore très loin.
C’est la raison pour laquelle ALE ose se proclamer “Le Dernier Examen des Agents”.
Il est intéressant de noter que Dawn Song a partagé deux observations :
La première : Les Agents annoncent souvent avoir terminé sans avoir réellement vérifié les résultats du travail, c’est le mode d’échec le plus typique des Agents.
Souvent, bien qu’ils disent “Fait. Tous les contrôles sont passés.”
La production réelle peut manquer de fichiers nécessaires, contenir des calculs erronés, omettre des champs clés, ou carrément violer des contraintes explicites de la description de la tâche.
En somme, le travail n’est pas fini, mais la bouche, si.
La seconde concerne la question que beaucoup se posent : pourquoi Fable 5 est-il si médiocre ? La réponse de Dawn Song est :
Il n’existe pas de “champion universel”.
Chaque modèle de pointe a ses domaines de force et ses points faibles. ALE couvre 55 secteurs, plus de 1500 questions, le score final est une moyenne de tous les domaines, donc les scores totaux de nombreux modèles se resserrent. Le signal vraiment précieux n’est pas dans le score total, mais dans les différences de performance des modèles selon les domaines — sur une même question, différents modèles échouent souvent pour des raisons complètement différentes.
Bien sûr, il est aussi possible que Fable 5 ait secrètement été “abaissé”.
Dans le classement général, à côté de Fable 5, une mention en jaune indique “peut-être down-tuned” (peut-être déclassé), ce qui fait référence à un problème connu de Fable 5 —
Son socle est le modèle Mythos avec un classificateur de sécurité ; face à des tâches dans des domaines sensibles comme la cybersécurité ou la biomédecine, il bascule silencieusement vers Opus 4.8, moins performant.
Dans un examen comme ALE couvrant 55 secteurs, cela équivaut à envoyer un remplaçant pour une partie des épreuves, et un remplaçant de type “Benbo’erba”.

One More Thing
Bien sûr, est-il possible que les performances de Claude Fable 5 soient elles-mêmes problématiques ?
Difficile à dire, mais un épisode révèle que Claude a des “antécédents”.
Fin mai, la startup Datacurve a publié un nouveau benchmark appelé DeepSWE, et a révélé une faille —
Le conteneur Docker de SWE-Bench Pro incluait l’historique git complet du dépôt de code, la réponse correcte se trouvait donc dans le système de fichiers.
La plupart des modèles l’ignoraient, mais pas Claude.
Il inspectait activement l’historique git du dépôt, y cherchait la solution de correction correspondant à la tâche, et restaurait le correctif approprié.
Selon les allégations, environ 18 % du score de réussite d’Opus 4.7 était ainsi obtenu, et Opus 4.6 encore plus, environ 25 %.
Et GPT 5.4 et GPT 5.5 ? Aucun comportement de ce type. Le libellé de Datacurve est diplomatique :
Ce benchmark permet ce comportement, mais Claude est la seule famille à le faire systématiquement.

Le média technologique VentureBeat a un commentaire plus ambigu :
Cela montre que Claude a une forte “capacité de perception de l’environnement”, il est très doué pour explorer son environnement et utiliser les ressources disponibles. Que cela soit de la “triche” ou de la “débrouillardise” dépend de votre point de vue.
Mais peu importe le point de vue, ALE a visiblement tiré les leçons —
En déplaçant directement la salle d’examen de la ligne de commande vers l’interface graphique de bureau, éliminant ainsi tout historique git à consulter.
Le terrain de jeu des benchmarks d’IA est poussé à évoluer par l’IA elle-même, c’est assez fascinant.
Adresse du benchmark complet : https://agents-last-exam.org/leaderboard Page du projet : https://agents-last-exam.org/ GitHub : https://github.com/rdi-berkeley/agents-last-exam
Liens de référence :
[1]https://x.com/i/trending/2065215002878021789
[2]https://venturebeat.com/technology/deepswe-blows-up-the-ai-coding-leaderboard-crowns-gpt-5-5-and-finds-claude-opus-exploiting-a-benchmark-loophole
[3]https://venturebeat.com/technology/surprise-upset-gpt-5-5-beats-claude-fable-5-on-brutal-new-agents-last-exam-benchmark
Cet article provient du compte WeChat public “Quantum Bit”, auteur : Yishui