Ces derniers jours, un petit modèle de 3B a fait sensation sur X, car dans certaines tâches de raisonnement à difficulté vérifiable (comme la programmation), il est entré dans la fourchette de performance de modèles de pointe tels que Gemini 3 Pro, GPT-5 high, Claude Opus 4.5, GLM-5, Kimi K2.5, alors que sa taille est bien inférieure à celle de ces modèles.

Ce modèle s'appelle VibeThinker-3B, un modèle de raisonnement dense à 3 milliards de paramètres, visant à explorer jusqu'où l'on peut pousser les capacités de raisonnement vérifiable dans le cadre strict d'une petite échelle de modèle.
Après la publication du modèle, beaucoup ont été impressionnés par ses résultats, exprimant leur envie de l'essayer eux-mêmes.


Il est à noter qu'il s'agit également d'un modèle chinois, développé par l'équipe de Weibo (Sina Weibo).
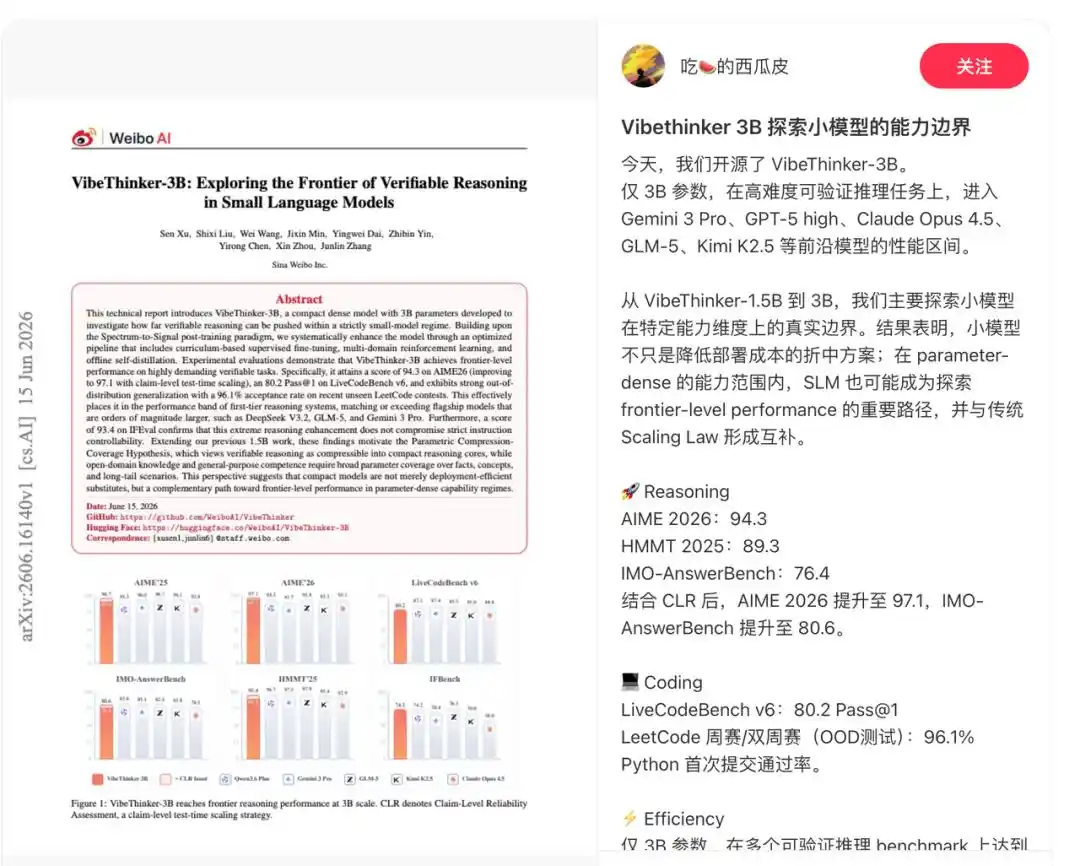
Le rapport technique montre que le modèle est conçu spécifiquement pour des tâches ayant des signaux de vérification fiables, incluant le raisonnement mathématique, la programmation compétitive, le raisonnement STEM, ainsi que l'exécution d'instructions avec des contraintes claires.
C'est pourquoi il obtient d'excellents résultats dans les divers benchmarks. Il a obtenu un score de 94,3 au test AIME26, 89,3 au test HMMT25, 80,2 (Pass@1) au test LiveCodeBench v6, et a atteint un taux de réussite de 96,1% lors des concours hebdomadaires et bimensuels les plus récents et non publics de LeetCode entre le 25 avril et le 31 mai 2026.

Comment ce modèle a-t-il été entraîné ? Le rapport technique révèle certains détails.
Tout d'abord, il est construit sur la base de Qwen2.5-Coder-3B et utilise un processus amélioré "Spectrum-to-Signal" pour l'entraînement ultérieur. Ce processus renforce la synthèse des données, le filtrage de qualité et l'apprentissage par curriculum dans le réglage fin supervisé (SFT), étend l'apprentissage par renforcement de style MGPO à plusieurs domaines vérifiables, conserve les trajectoires complètes de raisonnement en contexte long, et consolide les capacités grâce à l'autodistillation hors ligne et l'apprentissage par renforcement par instruction (Instruct RL).
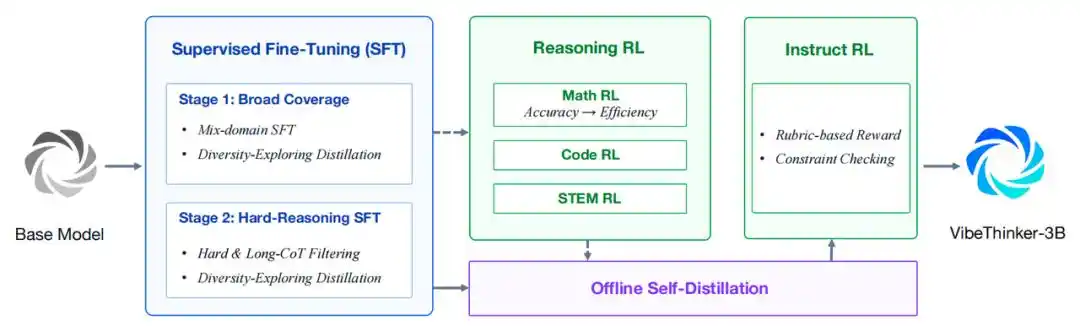
Processus d'entraînement global de VibeThinker-3B
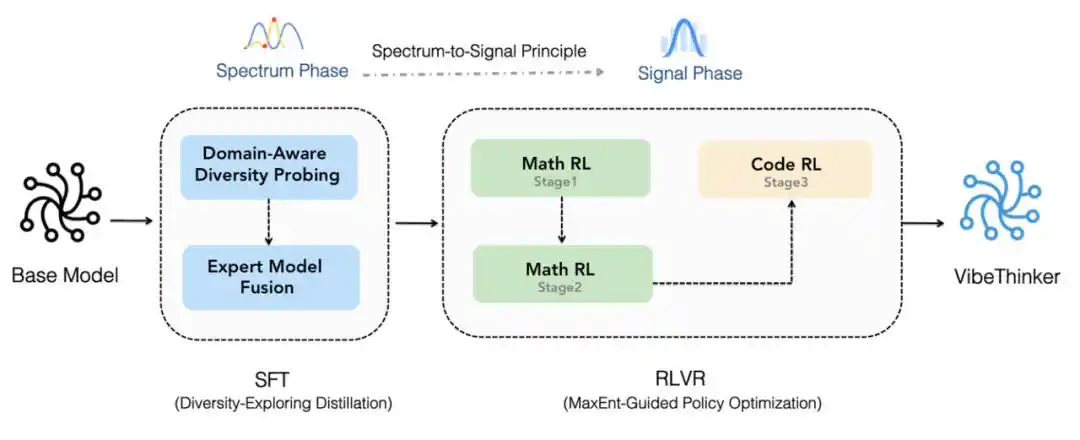
Processus "Spectrum-to-Signal".
De plus, VibeThinker-3B introduit l'évaluation de fiabilité au niveau des assertions (Claim-Level Reliability - CLR), une stratégie de mise à l'échelle (scaling) au moment du test pour le raisonnement vérifiable orienté réponse. La CLR améliore encore les performances sur les benchmarks mathématiques, faisant passer AIME26 de 94,3 à 97,1, HMMT25 de 89,3 à 95,4, et BruMO25 à 99,2.
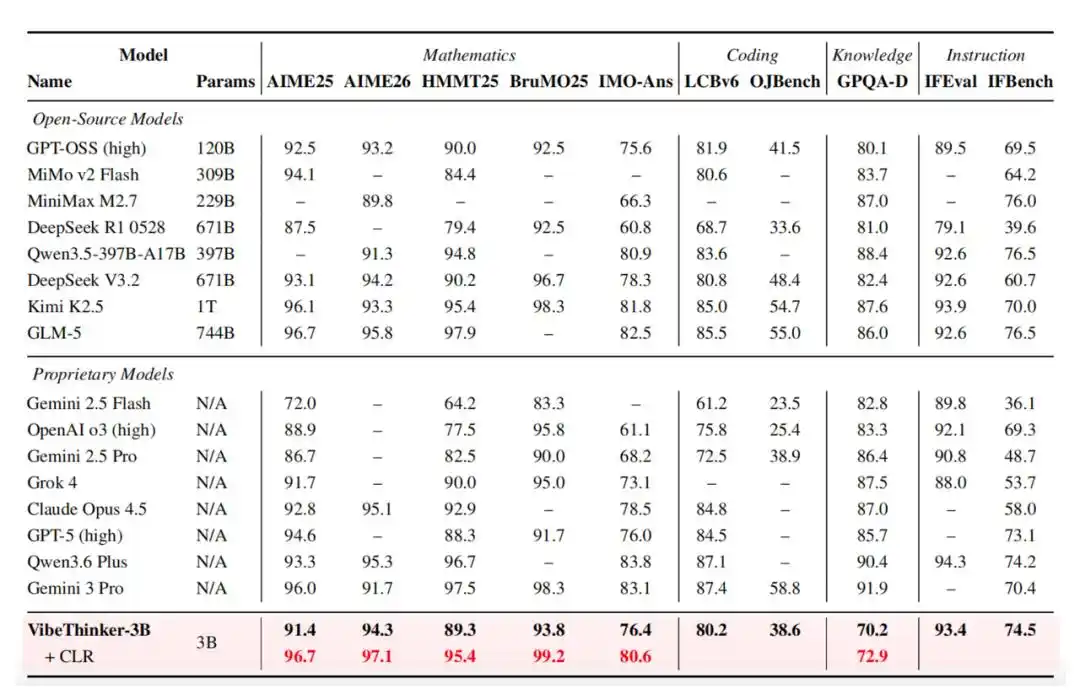
Son processus d'entraînement spécifique est le suivant :
- SFT en deux phases basé sur un curriculum. La première phase se concentre sur une large couverture des capacités en mathématiques, programmation, raisonnement STEM, dialogue général et suivi d'instructions. La deuxième phase passe à des échantillons de raisonnement plus difficiles et à l'horizon plus large. La distillation par exploration de la diversité est utilisée pour conserver plusieurs chemins de solution valides.
- Apprentissage par renforcement pour le raisonnement multi-domaines. VibeThinker-3B réutilise le MGPO. L'apprentissage par renforcement est appliqué successivement aux tâches de raisonnement mathématique, de programmation et STEM. L'entraînement utilise une fenêtre de contexte long unique de 64K pour conserver les trajectoires complètes de raisonnement à long terme.
- Autodistillation hors ligne. Filtrage et distillation des trajectoires de haute qualité à partir des points de contrôle du raisonnement mathématique, de la programmation et STEM, pour finalement former un modèle étudiant unifié. Un score de potentiel d'apprentissage est utilisé pour prioriser les trajectoires correctes mais que l'étudiant n'a pas encore bien imitées.
- Instruct RL. La phase finale améliore la contrôlabilité face aux invites orientées utilisateur. Pour les données d'instruction sensibles au format et de type ouvert, des validateurs basés sur des règles et des modèles de récompense basés sur des critères sont utilisés.
Dans un récent post, le chercheur et blogueur IA renommé Sebastian Raschka a systématiquement résumé les points clés divulgués dans le rapport technique de VibeThinker-3B, incluant les suivants :

Si ces contenus vous intéressent, vous pouvez consulter leur rapport technique en détail. Actuellement, le modèle est également téléchargeable publiquement.

Titre du rapport : VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
Lien vers le rapport : https://arxiv.org/pdf/2606.16140
Lien HuggingFace : https://huggingface.co/WeiboAI/VibeThinker-3B
Cependant, le champ d'application de ce modèle est clairement limité, car il ne brille pas dans les domaines nécessitant des connaissances générales.
Les auteurs l'ont également clairement indiqué et ont proposé l'« hypothèse de couverture par compression de paramètres » : différentes capacités dépendent des paramètres du modèle de manières très distinctes. Le raisonnement vérifiable se rapproche davantage d'une capacité hautement compressible et dense en paramètres, dont le cœur réside dans le raisonnement multi-étapes, la satisfaction de contraintes, l'autocorrection et la vérification des réponses. Lorsque la structure de l'espace des tâches est suffisamment claire et que les signaux de retour sont suffisamment fiables, des modèles compacts peuvent également posséder des capacités de raisonnement proches de l'état de l'art. En comparaison, les connaissances en domaine ouvert, le dialogue général et la compréhension de scénarios à longue traîne dépendent davantage de paramètres à grande échelle pour couvrir largement les faits, concepts et connaissances du monde. Cette hypothèse est très stimulante. VentureBeat écrit dans son reportage : « Elle révèle qu'il existe un découplage partiel entre les capacités de raisonnement et les connaissances factuelles, et que les premières peuvent être comprimées plus efficacement qu'on ne le pensait auparavant — une perspicacité qui a des implications profondes sur la façon dont l'industrie perçoit la conception des modèles, les coûts de déploiement et l'accessibilité des fonctionnalités avancées de l'intelligence artificielle. »

Les auteurs indiquent que leur objectif n'est pas de créer un petit modèle alternatif aux modèles à grande échelle, mais plutôt, en suivant une dimension de capacité spécifique, d'examiner les véritables limites des petits modèles. Avec VibeThinker-3B, ils espèrent montrer que les petits modèles ne doivent pas être considérés uniquement comme un compromis pour réduire les coûts de déploiement. Dans les domaines de capacité ayant des mécanismes clairs de retour et de vérification, les petits modèles linguistiques révèlent une voie de recherche prometteuse, susceptible d'atteindre des performances de niveau avancé, et de former une relation complémentaire fondamentale avec le paradigme traditionnel d'extension par l'échelle des paramètres.
Actuellement, le modèle fait également face à certaines critiques dans la communauté. Si ce modèle vous intéresse, pourquoi ne pas l'essayer vous-même.

Liens de référence :
https://x.com/orcus108/status/2066876960073281582
Cet article provient du compte officiel WeChat « Machine Heart » (ID : almosthuman2014), auteur : Zhang Qian





