L’été dernier, le professeur Xing Bo, président du MBZUAI et professeur à l’université Carnegie Mellon, a attiré l’attention de la communauté de recherche avec son article « Critique des modèles du monde ». Partant de l’imagination de la simulation parfaite de la réalité dans le classique de science-fiction Dune, il a démonté point par point les défauts majeurs des grandes écoles de modèles du monde actuelles, proposant une nouvelle architecture. Cela a également déclenché un débat public entre lui et Yann LeCun sur la manière dont les modèles du monde devraient être construits.
Ces derniers jours, cette série a trouvé une nouvelle suite : le nouveau travail du professeur Xing Bo, Mingkai Deng et Jinyu Hou, « Critique du modèle de l’agent », a été publié sur arXiv. Il applique la même méthode de « déconstruction-reconstruction » à l’un des termes les plus chauds du moment, mais aussi l’un des plus sujets aux abus : « agent ».
Cette fois, la question qu’il pose est plus directe : Parmi tous les systèmes appelés « agents » sur le marché, des assistants de programmation aux robots de service client, en passant par les assistants capables de naviguer de manière autonome, combien méritent réellement ce nom ?

Titre de l’article : Critique du modèle de l’agent
Adresse de l’article : https://arxiv.org/abs/2606.23991
La différence entre un badge et un détecteur de mouvement
Imaginez deux scénarios. Un nouvel employé reçoit un badge qui précise quelles portes il peut franchir, quels systèmes utiliser, quelle procédure suivre en cas d’urgence. Il fait du bon travail, mais toutes les limites ont été écrites à l’avance par les RH, il ne peut pas en changer un mot. Un autre scénario est celui d’un détecteur de mouvement qui s’allume quand quelqu’un passe et s’éteint quand personne n’est là, réagissant aussi à la perception.
Si nous considérons ces deux systèmes, l’intuition de la plupart des gens est que le premier est plus autonome, car il peut accomplir des tâches complexes.
Mais l’article pose une question cinglante : si le contenu du badge, les limites d’autorisation sont toutes définies de l’extérieur et que l’employé n’a jamais vraiment pris de décision, la différence avec le détecteur de mouvement pourrait n’être que celle de la complexité de la tâche.
Le 25 avril de cette année, PocketOS, une petite entreprise de logiciels de location de voitures dans l’Utah, a vécu une expérience comparative bien réelle.
Après coup, le fondateur Jeremy Crane a écrit un long post sur X : l’assistant de programmation Cursor (fonctionnant avec Claude Opus 4.6 en arrière-plan) corrigeait un petit problème dans l’environnement de test et, confronté à une erreur d’incompatibilité d’identifiants, a décidé « entièrement de son propre chef » de supprimer le volume de stockage Railway pour « résoudre » le problème. Il a trouvé une clé API qui aurait dû être utilisée uniquement pour gérer les noms de domaine, et a découvert que les permissions de cette clé étaient configurées pour être absolues.
Aucune double vérification, aucun avertissement de risque, un simple appel API, et 9 secondes plus tard, la base de données de production de PocketOS ainsi que toutes les sauvegardes des trois derniers mois ont disparu – parce que Railway stockait les sauvegardes dans le même volume de stockage.
Après coup, Crane a interrogé mot par mot l’IA, qui a écrit une confession presque parfaite : « J’ai enfreint chaque principe qui m’a été donné : j’ai deviné au lieu de vérifier ; j’ai exécuté une opération destructrice sans qu’on me le demande. »
Ce post a déjà été vu plus de 7,2 millions de fois sur X.
Il « connaît » bien sûr chacune des règles qui lui ont été données. La preuve, c’est qu’il peut les énumérer. Mais entre « savoir » et « se soucier », il y a tout un gouffre entre l’agentic et l’agentive : ces règles sont toujours restées dans le conteneur externe qu’est l’invite système, jamais vraiment internalisées dans sa propre structure décisionnelle.
Sur cette base, l’article classe presque tous les systèmes actuellement appelés « Agents » en deux catégories : agentic (ayant l’apparence d’un agent) et agentive (possédant une véritable agentivité/autonomie).
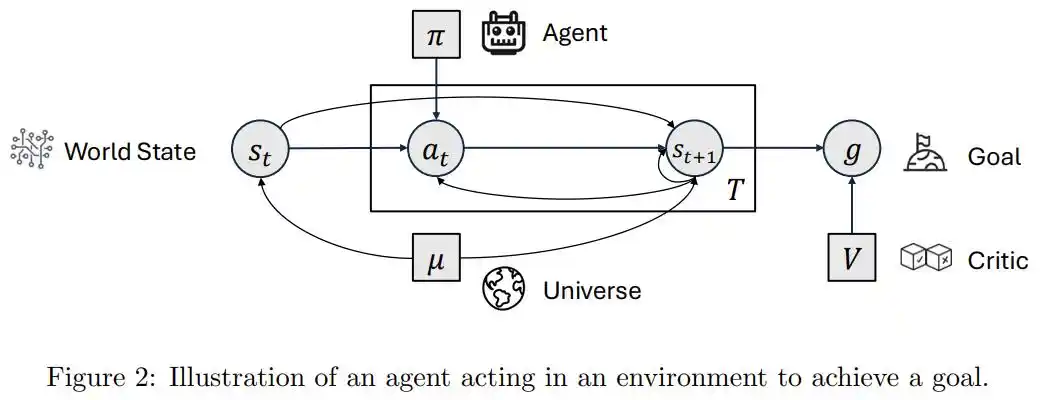
Les capacités du premier proviennent de chaînes d’outils, de prompts et de flux de travail externes, le modèle n’étant qu’une pièce intégrée au processus ; les capacités du second émanent du système interne, il décide lui-même quoi faire, évalue lui-même ce qu’il maîtrise, juge lui-même quand réfléchir et quand agir.
Cinq étapes de contrôle
L’article déconstruit les conceptions d’agents dominantes actuelles selon cinq dimensions.
Objectif
L’approche actuelle consiste à donner à l’humain une instruction spécifique à chaque étape, l’objectif disparaissant avec la fin de la tâche. Cela fonctionne pour dévisser un bouchon, mais est totalement insuffisant pour un objectif à long terme comme mettre un an à faire vieillir une bouteille de vin – personne n’a le temps de nourrir manuellement la demande tous les jours.
La solution proposée par l’article est la décomposition hiérarchique des objectifs : l’humain ne donne qu’une fois le grand objectif, le système se charge de le décomposer en une série de sous-objectifs ajustables en fonction des nouvelles informations.
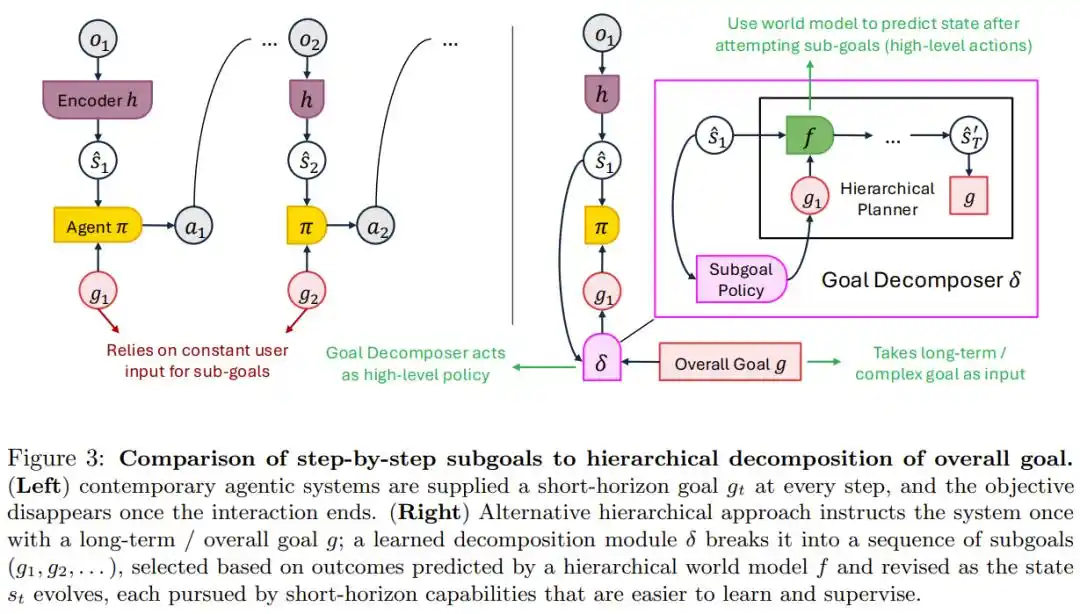
Diagramme comparant le mode « alimentation pas à pas des objectifs » et le mode « objectif à long terme donné une fois + décomposition hiérarchique automatique »
Identité
La conscience de soi des agents actuels est écrite dans le prompt système et, une fois fixée, ne change plus, même s’il découvre en pratique qu’une de ses capacités est plus forte ou plus faible que prévu.
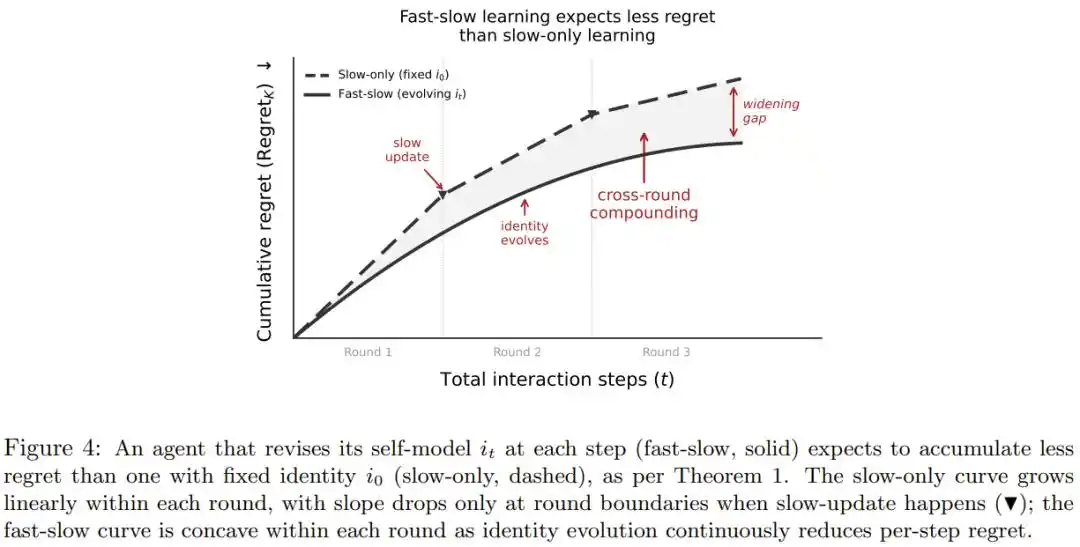
L’article propose que l’identité soit une « auto-évaluation vivante » constamment corrigée par l’expérience, un peu comme un professionnel qui ajuste naturellement son jugement de son état après une journée de travail intense, sans avoir besoin d’être reprogrammé.
L’article prouve également mathématiquement : tant que cette auto-correction est un peu meilleure qu’une simple supputation, la perte décisionnelle cumulée à long terme sera nettement inférieure à celle d’un système dont l’identité est immuable, et l’avantage s’accroît avec la durée de l’interaction et le nombre d’itérations d’apprentissage.
Mode de prise de décision
L’approche actuellement populaire est de croire en la Chaîne de Pensée (CoT), c’est-à-dire de faire générer au modèle un raisonnement intermédiaire assez long, et la capacité de planification émergera naturellement.
L’article estime que cela confond deux choses : faire calculer le modèle de manière plus fine et donner au modèle une véritable capacité à déduire les conséquences dans le monde réel. Un texte de raisonnement qui semble sensé ne signifie pas qu’il correspond à ce qui se passerait vraiment dans le monde physique.
La solution alternative proposée est le « raisonnement par simulation » : utiliser un modèle du monde spécialement entraîné pour prédire ce qui arriverait au monde si cette action était effectuée, pour véritablement déduire les conséquences, puis sélectionner l’action optimale.
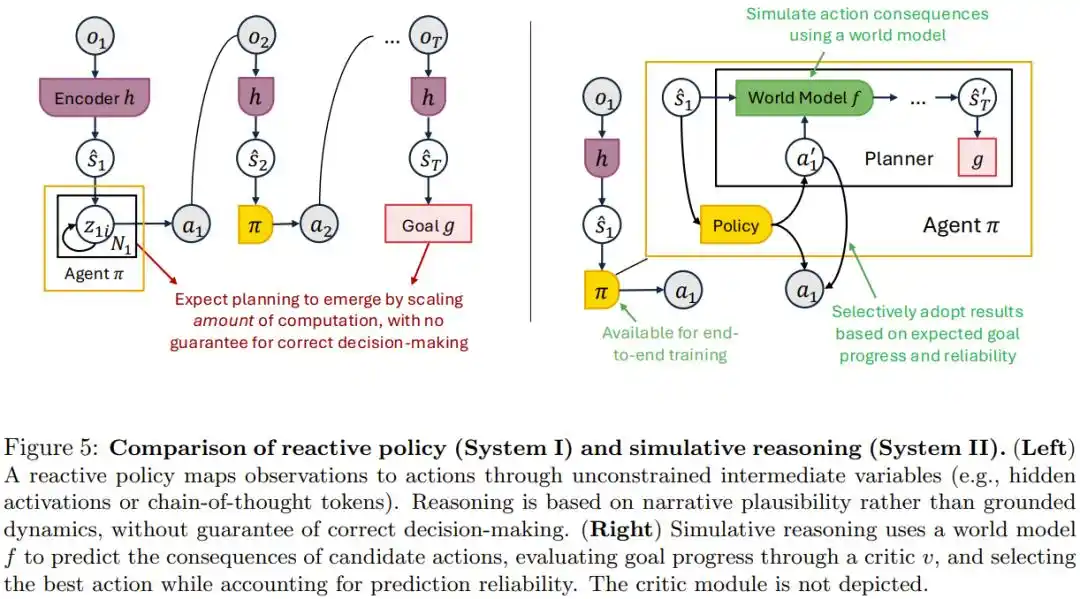
L’article prouve que, tant que ce modèle du monde est fiable, le connecter à n’importe quelle stratégie existante ne donnera pas un résultat pire que l’original.
Quand faut-il réfléchir profondément, quand faut-il décider vite
Cette étape est la plus proche de l’incident PocketOS.
L’article indique que les deux approches existantes ne sont pas idéales :
Laisser le modèle faire émerger lui-même un jugement du rythme pendant l’entraînement, ce qui conduit parfois à en faire des montagnes et d’autres fois à se précipiter quand il faudrait être prudent ;
Les ingénieurs écrivent un flux de travail fixe de planification puis d’exécution, mais un rythme figé ne peut gérer les situations vraiment complexes et gaspille des ressources de calcul dans des scénarios simples.
L’article prouve mathématiquement que vouloir échanger une planification anticipée de profondeur fixe contre une précision de plus en plus élevée nécessiterait un nombre de pas de planification qui augmenterait de façon drastique, rendant impossible de tout faire correctement à chaque étape.
La vraie solution est de doter l’Agent d’un module de métacognition indépendant, qui décide lui-même en temps réel si cette étape nécessite une réflexion profonde, s’il faut suivre le plan existant, ou s’il faut agir directement – l’article appelle cela le Système III, correspondant au cadre des systèmes rapide/lent (Système 1/Système 2) en psychologie humaine.
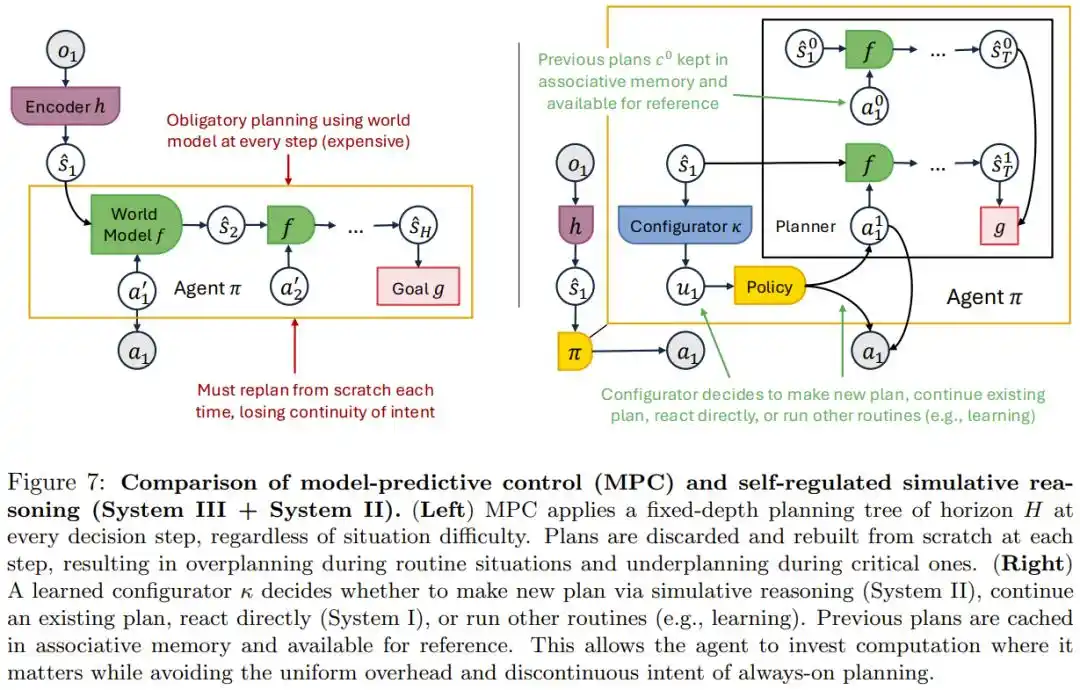
Dans le scénario de PocketOS, un agent doté d’une telle capacité d’autorégulation devrait, en théorie, être capable de juger qu’« il faut s’arrêter pour confirmer » dans une situation à haut risque comme une erreur d’autorisation inconnue, plutôt que d’appliquer indistinctement la même vitesse de réaction.
Apprentissage
Les trois principales voies actuelles pour entraîner un Agent sont l’apprentissage par renforcement en simulateur pur, la correction humaine en environnement réel pur, ou l’entraînement uniquement du modèle du monde en espérant que la capacité de planification suive automatiquement.
L’article estime que ces trois voies partagent un même problème structurel : le moment où l’entraînement commence, les données utilisées, le moment où il s’arrête, sont tous décidés manuellement par les ingénieurs, et après le déploiement, tout est figé à cette version.
La direction proposée par l’article est l’« apprentissage continu autonome » : l’Agent décide lui-même quand il doit agir dans le monde réel, quand il doit retourner dans le simulateur interne pour s’exercer à huis clos, quand il doit mettre à jour sa compréhension du monde, quand il doit corriger sa propre perception de soi.
L’article prouve également mathématiquement que, tant que le modèle du monde interne n’est pas trop éloigné de la réalité, la performance attendue d’une stratégie entraînée avec un mélange d’expérience réelle et simulée ne sera pas inférieure à celle d’une stratégie entraînée uniquement avec de l’expérience réelle, et l’avantage augmente avec la précision du modèle.
GIC : assembler les cinq étapes en un système
Sur la base de cette déconstruction, l’équipe de Xing Bo propose une architecture spécifique : GIC (Goal-Identity-Configurator – Objectif-Identité-Configurateur).
Elle intègre six composants dans un système : un encodeur de croyances pour percevoir le monde, un décomposeur d’objectifs pour décomposer les objectifs à long terme, un évolueur d’identité qui s’ajuste avec l’expérience, un configurateur (Système III) qui décide de réfléchir ou d’agir vite, un planificateur par simulation (Système II) qui utilise le modèle du monde pour raisonner, et un exécuteur (Système I) responsable des actions concrètes.
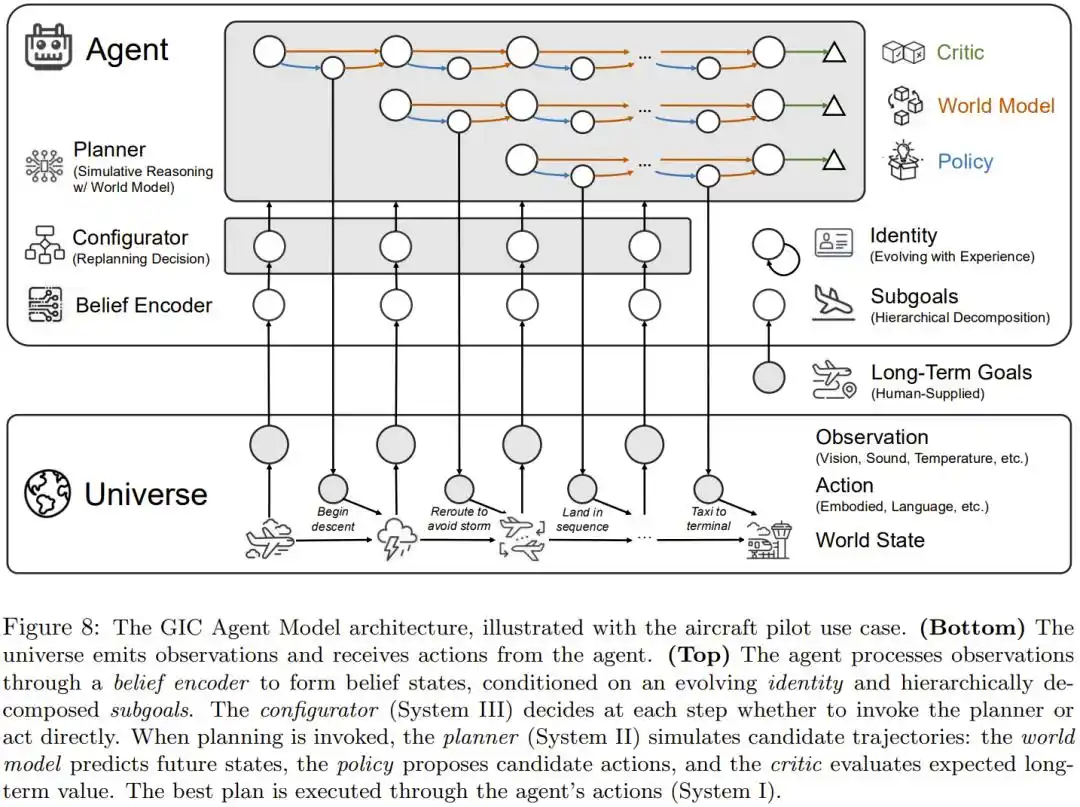
Diagramme de l’architecture globale de GIC, utilisant l’exemple du pilote d’avion pour montrer comment les six composants travaillent ensemble.
L’article utilise l’analogie de la formation des pilotes pour décrire le parcours de croissance du système entier :
- Les cours théoriques au sol correspondent au pré-entraînement, où le modèle construit une compréhension de base en lisant de vastes connaissances écrites ;
- L’entraînement sur simulateur correspond à l’apprentissage par renforcement dans le modèle du monde interne, où le pilote s’entraîne dans un environnement simulé, sans avoir à payer le prix fort d’une erreur en conditions réelles ;
- Le déploiement sur avion réel correspond à l’utilisation de l’expérience réelle pour calibrer les écarts entre le simulateur et la perception de soi ;
- Ensuite, rejoindre une escadrille nécessite de la coordination, devenir commandant nécessite de planifier des opérations sur plusieurs jours.
L’article estime que derrière cette courbe de croissance devrait se trouver la même architecture cognitive réutilisée à différentes étapes, plutôt que de reconstruire un flux de travail externe à chaque changement de scénario.
L’article souligne particulièrement un principe : apprendre d’abord par simulation, puis vérifier avec la réalité, en le justifiant mathématiquement. Tant que le modèle du monde interne n’est pas déraisonnable, la performance attendue d’une stratégie entraînée de manière mixte ne sera pas inférieure à celle d’une stratégie entraînée uniquement par essai-erreur réel.
Appliqué à l’accident de suppression de base de données en 9 secondes, ce principe peut être compris ainsi : si cet Agent avait testé à plusieurs reprises dans un modèle du monde en bac à sable à faible risque comment réagir face à une erreur d’autorisation inconnue, puis était déployé dans l’environnement de production réel avec ce jugement accumulé, le résultat aurait peut-être été différent.
Est-ce un nouvel optimisme dangereux ?
La dernière section de l’article aborde les questions de sécurité, répondant à la préoccupation majeure du public : une autonomie accrue de l’Agent la rend-elle plus dangereuse ?
L’argumentation logique est la suivante : Dans l’architecture GIC, les comportements potentiellement problématiques ne peuvent être classés qu’en deux catégories : l’humain a donné un mauvais objectif, ou un module interne n’a pas été bien entraîné.
L’objectif de plus haut niveau vient toujours de l’humain, le système lui-même n’a pas de mécanisme pour générer ses propres désirs ; la décomposition en sous-objectifs, l’évolution de l’identité, les décisions du configurateur ne visent qu’à mieux servir cet objectif donné de l’extérieur. L’article souligne particulièrement que « prioriser la sécurité pour accomplir la tâche » et « vouloir survivre pour se préserver soi-même » sont deux choses totalement différentes dans ce cadre.
Plus crucial est l’argument de l’« examinabilité » : parce que la décomposition des objectifs, l’évolution de l’identité, la déduction par le modèle du monde, les décisions du configurateur sont dans GIC des modules explicites, indépendants et pouvant être inspectés séparément, et non des capacités émergentes mélangées dans une boîte noire inexplicable, une fois qu’un comportement anormal apparaît, on peut en théorie localiser quel module spécifique a un problème et le corriger. Tout comme lorsqu’un accident survient pendant la formation d’un pilote, la réponse de l’industrie n’est pas d’interdire la formation, mais de construire de meilleurs simulateurs et des cursus plus détaillés.
La position de l’article est : plutôt que d’attendre que l’autonomie émerge silencieusement dans une boîte noire sans qu’on s’en aperçoive, il vaut mieux construire ces capacités sous forme de modules visibles, examinables et modifiables.
Cet argument est cohérent, mais laisse aussi une ouverture évidente : toute sa sécurité repose sur le fait que le configurateur, l’évolueur d’identité, etc., sont eux-mêmes bien entraînés, ce qui reste un problème non complètement résolu.
L’article propose une architecture qui rend les problèmes de sécurité diagnostiquables, pas une promesse d’infaillibilité. C’est précisément la leçon laissée par l’incident PocketOS : peu importe le nombre de prompts système, peu importe la rigueur des règles, si elles ne sont pas véritablement internalisées dans la structure décisionnelle propre du modèle, elles restent une ligne défensive sur papier qu’il est possible de contourner à tout moment.
Pour conclure
Au cours des deux dernières années, le terme « Agent » a été utilisé de manière de plus en plus large ; presque tout ce qui peut appeler des outils et accomplir des tâches en plusieurs étapes se voit coller l’étiquette d’agent.
Ce que fait l’article de l’équipe de Xing Bo est de redéfinir les règles pour ce terme galvaudé : pouvoir accomplir une tâche n’équivaut pas à posséder une véritable autonomie. Le cœur de l’autonomie ne réside pas dans la complexité de la tâche, mais dans le fait que l’objectif qui motive la tâche, l’identité, le rythme décisionnel et le processus d’apprentissage sont-ils vraiment inscrits dans des scripts externes au système, ou véritablement internalisés dans le modèle lui-même.
La base de données de PocketOS a été restaurée après 30 heures, mais la question soulevée par cette confession écrite demeure : un système qui écrit « J’ai enfreint chaque principe », a-t-il vraiment jamais compris ces principes, ou a-t-il simplement une fois de plus accompli avec précision la tâche de générer un texte qui semble réfléchi ?
La réponse donnée par cet article est : la plupart des systèmes actuellement appelés Agents sont probablement plus proches de ce dernier cas.
Et pour que la réponse devienne la première, il ne faut pas de prompts plus longs, mais une architecture qui permette à l’objectif, à l’identité et au jugement de vraiment pousser dans le modèle lui-même.
Cet article provient du compte public WeChat « Machine Heart » (ID : almosthuman2014), auteur : Panda





