Note de la rédaction : Cet article présente un système de connaissances personnel basé sur Claude Code et Obsidian, dont le noyau n'est plus l'usage traditionnel du RAG « recherche temporaire à chaque requête », mais tente plutôt de permettre à l'IA de construire et de maintenir continuellement une base de connaissances (Wiki) évolutive.
Structurellement, ce système peut être décomposé en trois couches :
· Premièrement, la couche de données brutes, comprenant les notes, articles, transcriptions et autres sources d'entrée non modifiables ;
· Deuxièmement, la base de connaissances structurée maintenue par l'IA, qui réalise des références croisées et construit des relations grâce à des mises à jour continues ;
· Troisièmement, la couche de règles Schema, utilisée pour normaliser la manière d'organiser les connaissances et la logique opérationnelle du système.
Autour de cette structure, le système fonctionne via trois opérations centrales : Ingest (Ingestion), pour intégrer continuellement des informations externes ; Query (Requête), pour permettre une invocation immédiate des connaissances ; et Lint (Vérification), utilisée pour vérifier la cohérence structurelle et corriger les problèmes potentiels.
Grâce à ce mécanisme, la connaissance ne restent pas un simple résultat de conversation ponctuelle, mais, à travers un cycle « écriture - organisation - réutilisation », se sédimentent progressivement en un actif réutilisable à long terme. L'auteur suggère ainsi que ce modèle confère aux connaissances un effet d'accumulation similaire aux « intérêts composés » : d'une part, il allège la charge cognitive individuelle, et d'autre part, il améliore la précision et la cohérence contextuelle des sorties du modèle.
Cependant, le fonctionnement efficace de ce système repose sur une condition préalable – un apport et une maintenance continus des données. Sans injection stable de données et mise à jour de la structure, ce « deuxième cerveau » aura du mal à former un véritable effet d'accumulation, et ses avantages diminueront par conséquent.
Voici l'article original :
Claude Code + Obsidian est la combinaison d'IA la plus puissante que j'aie jamais utilisée.
J'ai presque construit un « deuxième cerveau IA », intégrant toutes mes réflexions, lectures, écrits, recherches en ligne, etc. Cela inclut mes plans commerciaux, toutes mes vidéos YouTube publiées, les articles que j'ai écrits, et tout ce qui est important pour moi.
Claude Code + Obsidian devient rapidement viral sur diverses plateformes, et ce n'est pas un hasard.
Personnellement, ce système d'IA a considérablement réduit ma charge cognitive, me permettant de concentrer mon énergie sur ce qui compte vraiment – que ce soit mes affaires ou ma vie personnelle.

Ce système peut sembler un peu complexe, mais en réalité, sa mise en place ne prend que 5 minutes. Plus important encore, il intègre un mécanisme de mémoire qui s'optimise continuellement avec l'usage.
Ensuite, je vais vous guider étape par étape pour reproduire ce système de « deuxième cerveau IA », qui peut réellement booster votre efficacité.
Je vous conseille de lire jusqu'à la fin – j'y joins un aide-mémoire complet pour Claude Code + Obsidian, ainsi que toutes les ressources mentionnées (toutes gratuites).
Avant de commencer
Ce système n'est pas entièrement mon idée originale, son inspiration vient d'un tweet viral d'Andrej Karpathy il y a quelques jours concernant les « bases de connaissances LLM ».
Lecture connexe : https://x.com/karpathy/status/2039805659525644595
Ce tweet est devenu viral rapidement car il propose une solution à un point de douleur clé du développement actuel de l'IA.
Ce problème est le suivant : chaque fois que vous commencez une nouvelle conversation, ou changez d'outil d'IA, vous devez ressaisir les prompts, ajouter du contexte, recommençant presque de zéro.
En combinant ce prompt système avec Obsidian et Claude Code, ce problème peut être résolu complètement, tout en améliorant significativement la qualité des sorties de l'IA.
Comment fonctionne ce système ?
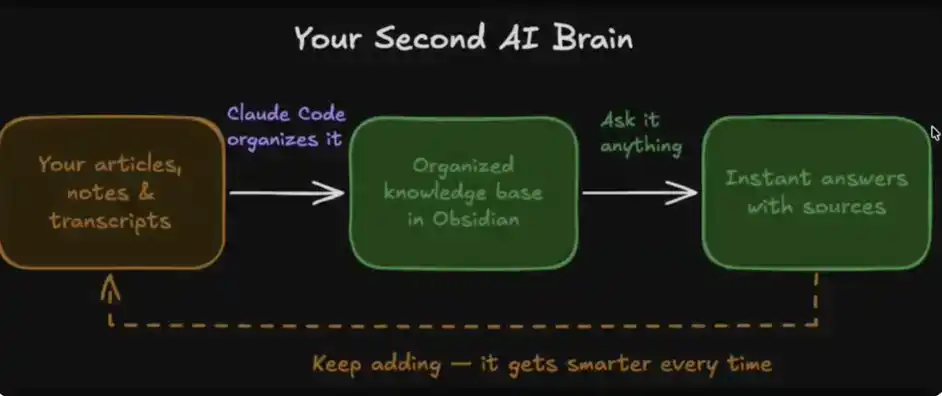
L'ensemble du système est constitué de quatre modules clés :
1. Vos données : incluant articles, notes, transcriptions, idées, etc.
2. Mode d'organisation : réalisé automatiquement par Claude Code dans Obsidian
3. Invocation immédiate : Vous pouvez interroger cette « base de données » à tout moment pour obtenir des réponses
4. Mémoire évolutive : Le système devient plus intelligent avec l'usage
Où réside la véritable puissance de ce système ?
En tant qu'humains, notre bande passante cognitive est limitée. Nous oublions, il nous est parfois difficile de connecter différentes idées, et nous avons une limite à l'information que nous pouvons suivre et traiter simultanément.
En utilisant ce système à quatre modules, vous libérez en réalité votre charge cognitive, confiant le travail de « connexion, organisation et compréhension de l'information » à Obsidian et Claude Code.
Vos idées commencent à être systématiquement reliées, une note peut automatiquement être liée à une autre, et vous pouvez à tout moment extraire, combiner et invoquer ces contenus via Claude.
Dans cette structure, vos connaissances ne sont plus éparses, mais forment un réseau qui peut être continuellement invoqué et réorganisé – presque sans limite.
Comment construire votre cerveau IA en 5 minutes
1. Téléchargez Obsidian
Site officiel : https://obsidian.md/
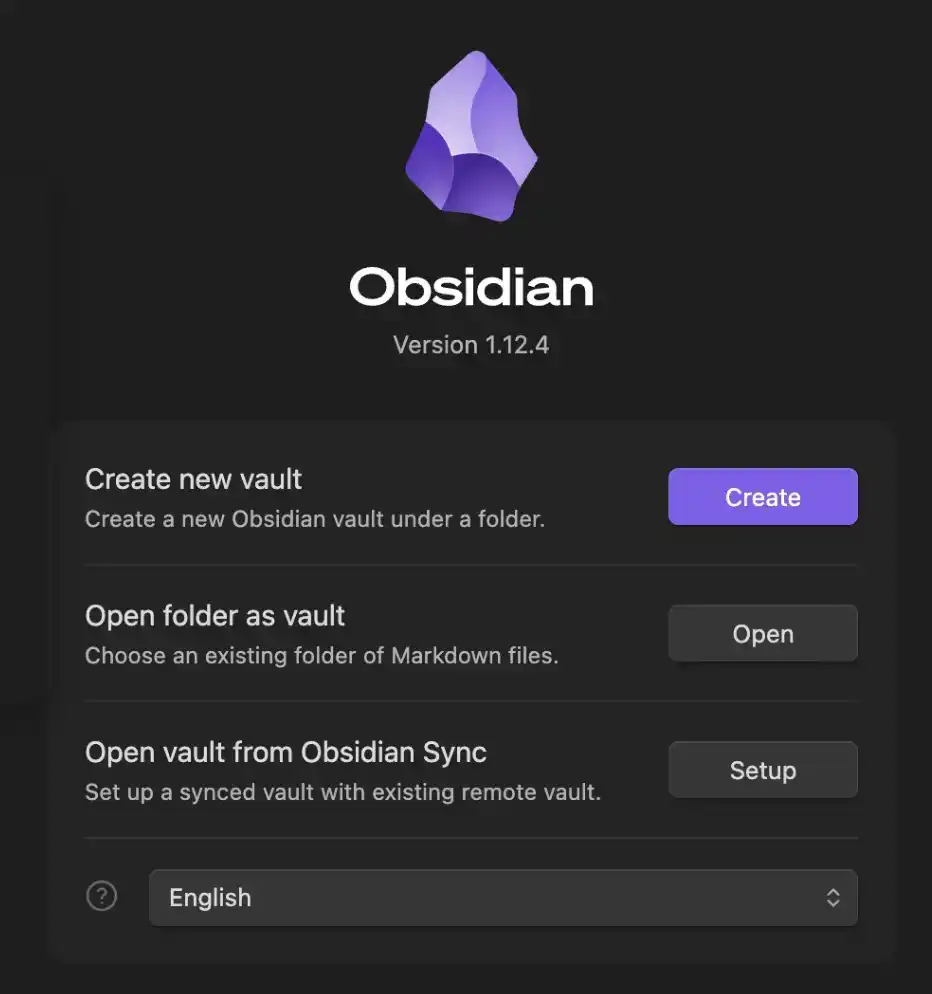
2. Créez votre Coffre-fort (Vault)
Une fois le téléchargement terminé, Obsidian vous invitera à créer un « Vault » (Coffre-fort).
Vous pouvez le comprendre comme un dossier sur votre ordinateur, où nous stockerons tout le contenu, et permettrons à Claude Code d'accéder et de gérer ces données.
Le nom de ce Vault peut être choisi librement – personnellement, je l'ai nommé « Obsidian Vault ».
Ce Vault est l'endroit où Obsidian stocke toutes vos données et notes, tout le contenu sera sauvegardé sous forme de fichiers MD (Markdown).
3. Configurez Claude Code
Ensuite, vous devez configurer un moyen d'accéder à Claude Code. Pour moi (et probablement pour la plupart des gens), la méthode la plus simple est d'utiliser directement le client desktop.
Dans l'interface principale de chat, cliquez sur « Select Folder (Sélectionner un dossier) », puis trouvez et sélectionnez le Obsidian Vault que vous venez de créer.
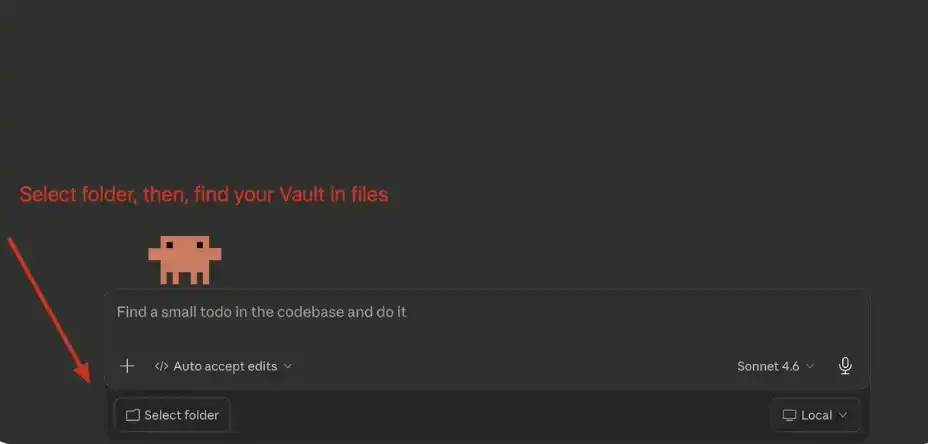
4. Configurez le Prompt Système (System Prompt)
Une fois le dossier sélectionné, l'étape suivante est de coller le prompt système d'Andrej Karpathy dans la boîte de chat principale.
Vous pouvez copier ce prompt ici : https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f

Votre saisie devrait ressembler à ceci :
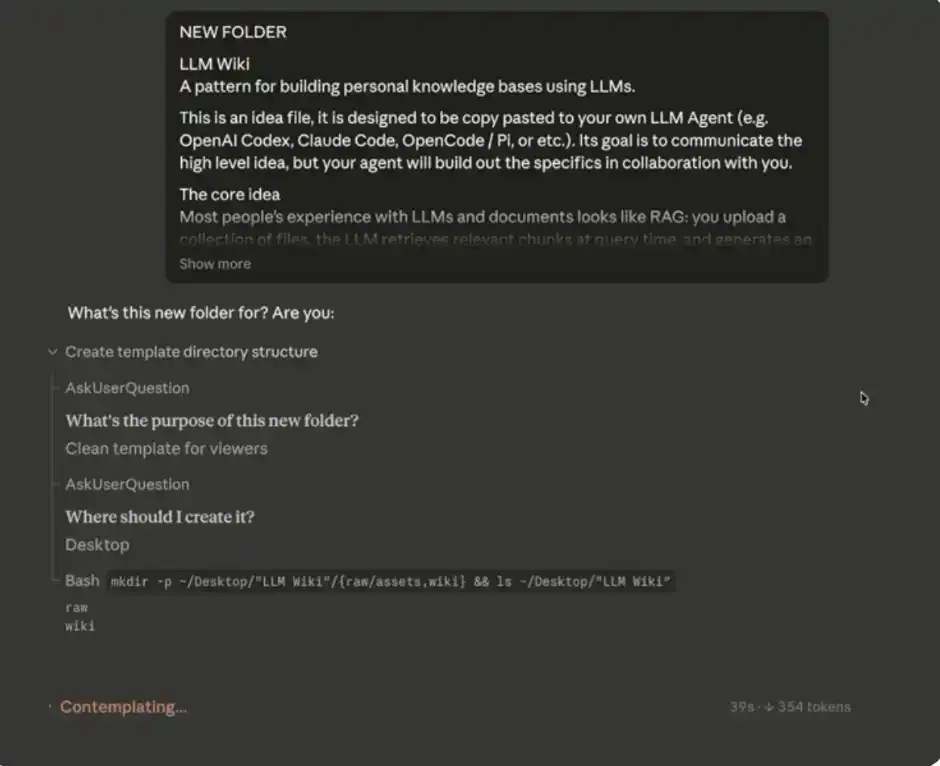
Petite astuce : Si vous ne le souhaitez pas, vous n'êtes pas obligé d'ouvrir Obsidian manuellement. Il suffit de donner le dossier MD (votre Vault) et les données associées à Claude Code, il pourra directement lire, écrire et modifier ces fichiers – et ce contenu sera automatiquement synchronisé avec votre « deuxième cerveau » Obsidian.
5. Construisez votre base de données
Après avoir saisi le prompt système ci-dessus, Claude Code commencera à vous demander quelques sources de données, pour initialiser et progressivement remplir votre « deuxième cerveau ».
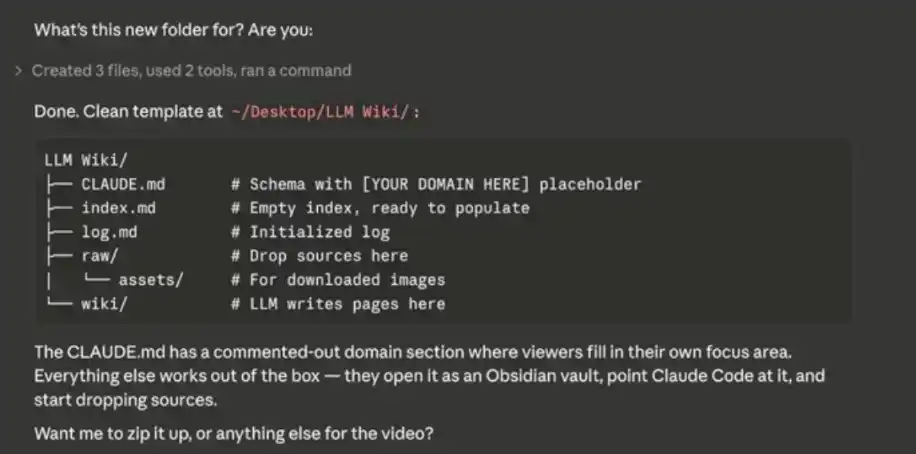
Vous pouvez imaginer Obsidian comme un « cahier vierge » – au début, vous devez saisir activement du contenu pour que la base de données se construise progressivement. Les contenus pouvant être importés incluent : notes, fichiers CSV, fichiers Markdown / texte, etc.
Quelques conseils pratiques :
· Exportez les données de votre outil de notes existant
· Si vous utilisez Notion, vous pouvez exporter en CSV
· Demandez à Claude (ou un autre grand modèle) de préparer un résumé d'informations vous concernant, pour initialiser votre « deuxième cerveau »
· Importez en une fois vos articles existants, favoris, idées, etc. – c'est le meilleur moment pour établir les données initiales, vous pourrez compléter plus tard
Il est important de noter qu'une base de données avec autant de données que la mienne ne se construit pas du jour au lendemain, mais s'accumule progressivement avec le temps grâce à des apports continus.

Voilà, votre « deuxième cerveau IA » est configuré et opérationnel. Ensuite, je partage quelques astuces avancées pour l'utiliser plus efficacement.
Astuces avancées (Pro Tips)
1. Extension Chrome Obsidian
Si vous voulez ajouter des données plus facilement, il suffit d'installer l'extension Chrome d'Obsidian. Elle vous permet, lors de la navigation, de cliquer directement sur « Add to Obsidian (Ajouter à Obsidian) » pour sauvegarder le contenu dans votre base de connaissances. Cela rend le processus de construction de votre « deuxième cerveau » très fluide.
J'utilise moi-même souvent cette fonctionnalité pour collecter des articles, des données web, des documents de recherche, etc.
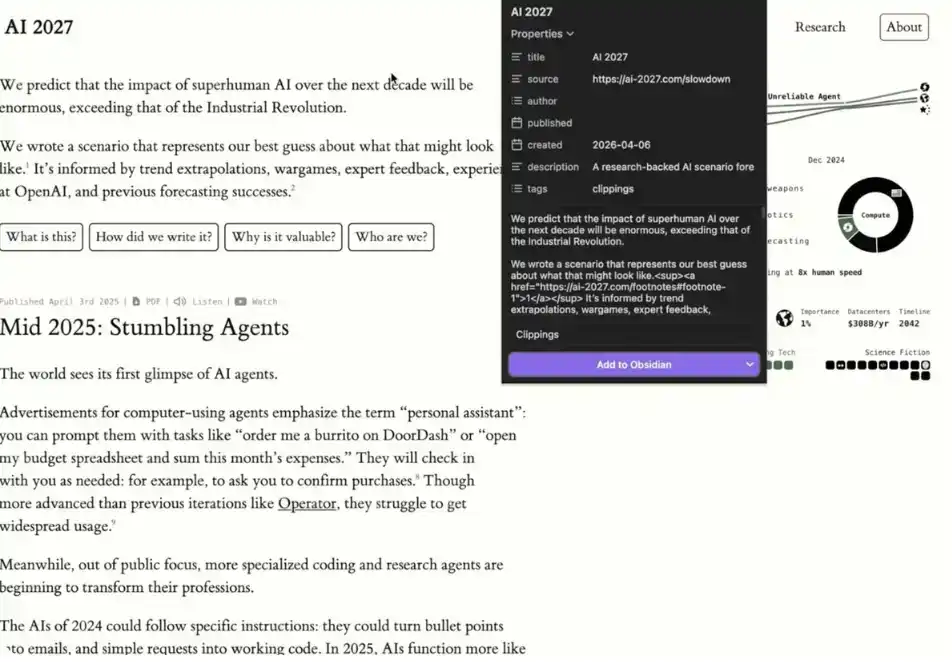
Notez que les données ajoutées via l'extension sont, au départ, juste une « source de données isolée ».
Vous pouvez ensuite dire à Claude Code : « Je viens d'ajouter [x] dans Obsidian, please intègre ces contenus dans mon Wiki. »
Claude Code établira automatiquement des liens entre ces nouvelles données et le contenu existant, les intégrant véritablement à votre « deuxième cerveau ». C'est aussi pourquoi cette combinaison d'outils est si puissante.
2. Créez des Coffres-forts (Vaults) séparés
Andrej Karpathy recommande d'utiliser deux Coffres-forts (Vaults) indépendants :
· Un pour le travail / le contenu commercial
· Un pour la vie personnelle / la gestion des objectifs
Mon expérience personnelle confirme que cette structure est la plus claire et la plus efficace.
3. Utilité pratique
L'usage le plus précieux de ce système que j'ai trouvé est en fait très simple : rendre vos prompts LLM plus précis.
Lorsque le modèle a accès à l'intégralité de vos informations personnelles, plans commerciaux, contexte d'écriture, etc., il peut générer des prompts plus « sur mesure », de meilleure qualité et plus proches de la réalité (voire des « super Prompt »).
Bien sûr, les usages de ce système vont bien au-delà, mais si vous voulez commencer par un scénario très pratique, je vous recommande fortement de commencer par « améliorer la qualité des Prompt ».
4. Orphelins (Orphans)
Dans Obsidian, les « Orphelins » (Orphans) désignent les points de données qui ne sont pas connectés à d'autres notes.
Cette fonctionnalité est utile car elle peut vous aider à :
· Trouver des idées pas encore intégrées
· Découvrir les « zones faibles » de votre base de données
· Identifier quels contenus méritent d'être développés ou approfondis
En d'autres termes, c'est non seulement un outil d'organisation, mais aussi un mécanisme vous aidant à découvrir vos angles morts de réflexion.

Vous pouvez cliquer sur les « trois points » en haut à droite, trouver et activer le switch Orphans, pour voir quels contenus ne sont pas encore liés.
Les inconvénients potentiels de ce système
Nous avons beaucoup parlé des avantages, des cas d'usage et des méthodes d'optimisation, mais quels sont ses défauts ? Dans quels cas ce système ne vous conviendrait-il pas ?
1. Les personnes peu à l'aise avec la visualisation
Un avantage clé de ce système est sa capacité à présenter visuellement les données. Si vous ne dépendez pas ou n'êtes pas habitué à ce type de visualisation, son aide pourrait être limitée.
2. Un certain coût de maintenance requis
Si vous n'êtes pas disposé à maintenir continuellement une base de données, ce système n'est probablement pas pour vous. Bien que le coût de maintenance ne soit pas élevé, sans apport continu de données dans le « deuxième cerveau », il aura du mal à démontrer sa valeur.
3. Occupation de l'espace de stockage
Tout le contenu est stocké localement sous forme de fichiers Markdown, ce qui occupe un certain espace sur votre appareil. Ce point doit également être considéré à l'avance.





