Một nhà phát triển cá nhân, lại có thể vượt lên hàng đầu trong bảng Trending Models của Hugging Face giữa một loạt ông lớn?!
Đây là một ngày bình thường, tôi cũng bình thường lướt qua bảng Trending của Hugging Face.
Thứ nhất là GLM-5.2, mô hình mới nhất mã nguồn mở của Zhipu, người quen cũ rồi, lượng tải xuống hơn 60 nghìn, không có gì lạ.
Thứ hai là Unlimited-OCR của Baidu, vừa mở mã nguồn gần đây, một hơi có thể phân tích hơn 40 trang tài liệu, lượng tải xuống cũng đạt tới 70 nghìn.
Nhìn xuống tiếp, đột nhiên xuất hiện một tài khoản cá nhân: yuxinlu1.
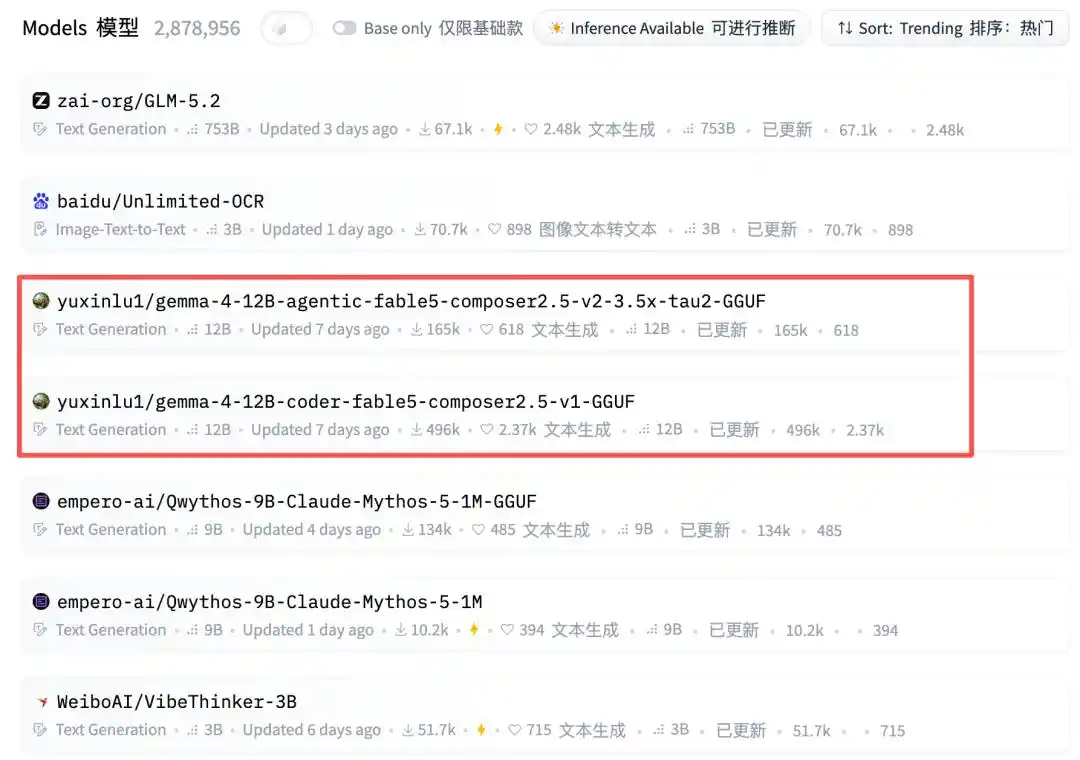
Hmm... Hả?!
Và còn chiếm luôn hai vị trí.
Nhìn lại lượng tải xuống – dữ liệu mới nhất đã lên tới 20.7 vạn và 53.6 vạn. Trời ơi, đây là loại mô hình thần thánh nào vậy?
Thậm chí trong tuần trước đó, mô hình của nhà phát triển cá nhân này từng một thời độc chiếm bảng xếp hạng Hugging Face, vượt qua cả GLM-5.2, ngay cả trưởng nhóm Zhipu cũng công khai giới thiệu trên X:
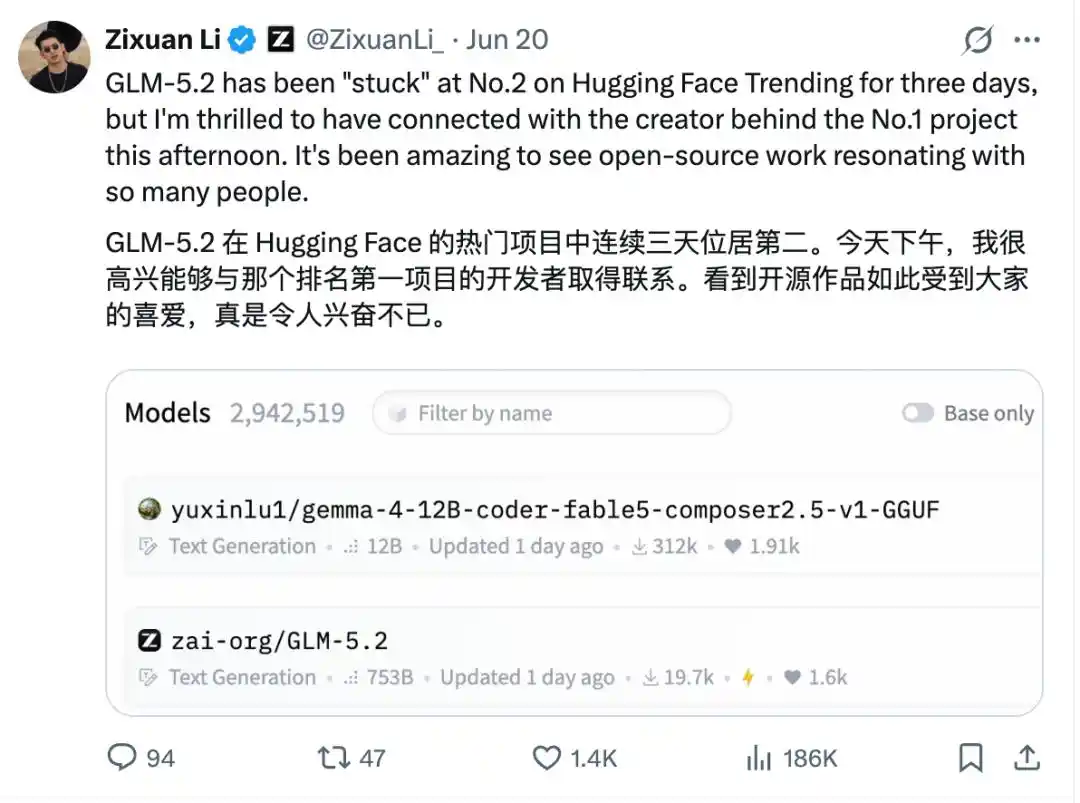
Tức là, giữa những cái tên như Zhipu, Baidu, Qwen, NVIDIA... một tài khoản nhà phát triển cá nhân đã cứng cổ chèn vào TOP, và lượng tải xuống lại còn cao như vậy.
Không khỏi khiến người ta tò mò: luyuxin rốt cuộc là ai? Sao năng lực lớn vậy?
"Mô hình tay ngang" vọt lên bảng xếp hạng hot Hugging Face
Làn sóng bảng hot Hugging Face lần này, hàng đầu cơ bản là các ông lớn, đội ngũ ngôi sao và các lĩnh vực hot đang chiếm vị.
Ví dụ như Zhipu GLM-5.2, tham số siêu lớn 753B, mô hình lớn ngôi sao trong nước; Baidu Unlimited-OCR, đạp trúng hướng OCR và hiểu tài liệu đang rất hot gần đây.
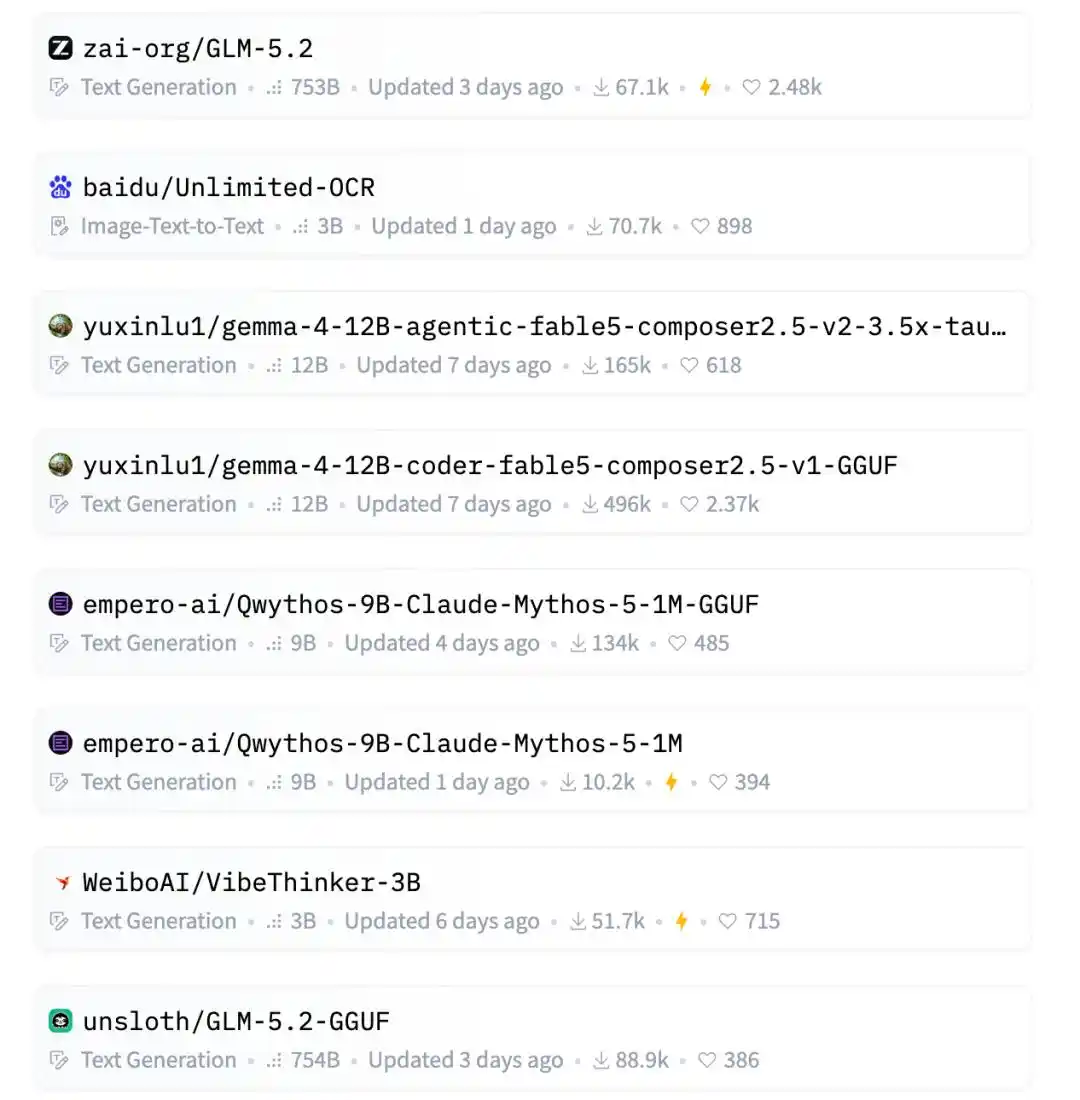
Nhìn xuống tiếp còn có AgentWorld của Qwen, LocateAnything của Nvidia, FastContext của Microsoft.
Những gương mặt quen thuộc của mô hình lớn mã nguồn mở trong nước cũng đều có mặt: MiniMax M3, Kimi-K2.7-Code, DeepSeek-V4-Pro.
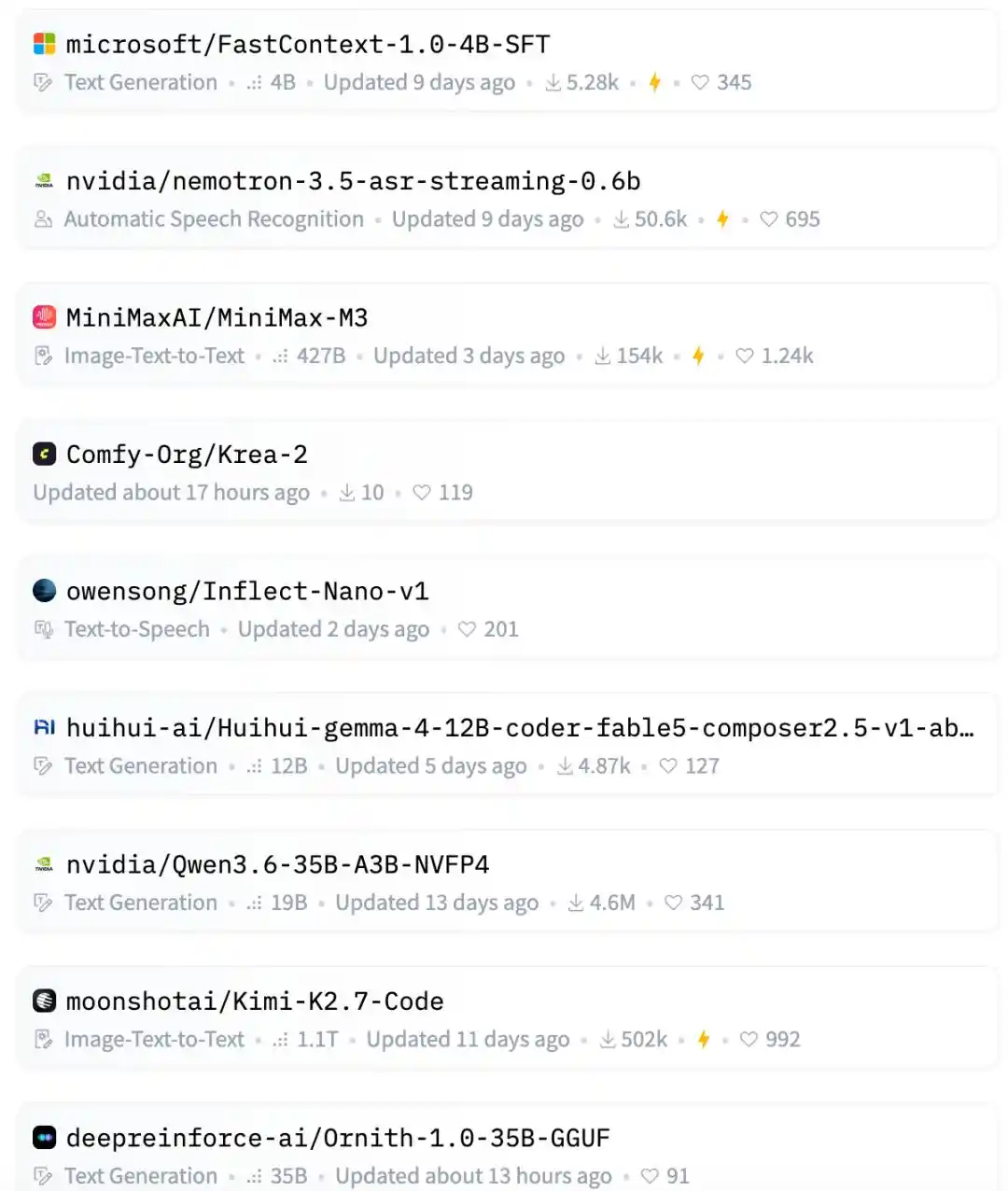
Hướng sinh ảnh cũng có Krea, mô hình mới Krea-2-Turbo và Krea-2-Raw đều trên bảng.
Kết quả trong đó còn kẹp hai mô hình GGUF 12B của luyuxin.
Không... luyuxin, anh cũng nổi bật quá đi...
Xem kỹ lại, hai mô hình mới này, chủ yếu đã chưng cất khả năng lập trình suy luận của Fable 5, vào một mô hình nhỏ Gemma4-12B có thể chạy được cục bộ.
Chỉ cần 4.5GB VRAM là chạy được, cục bộ, ngoại tuyến, chi phí API bằng không. Người dùng phổ thông một card đồ họa cấp tiêu dùng, thậm chí một chiếc Mac với bộ nhớ thống nhất, là có thể chạy nó.
Hai mô hình cũng có sự phân công khác nhau.
V1 là phiên bản Coder, chủ đạo viết code, giải bài, sinh code có thể chạy.

Theo mô tả mô hình, dữ liệu huấn luyện của nó là suy luận code "có thể kiểm chứng": mỗi chuỗi suy nghĩ tương ứng với code, đều phải thực sự chạy qua test, pass mới giữ lại.
Dữ liệu giáo viên chủ yếu đến từ Composer 2.5 của Cursor, cộng thêm Fable 5 – những bài Composer 2.5 làm sai, sẽ giao cho Fable 5 suy luận lại một lần, sinh ra chuỗi suy luận và code đúng mới.
Sau khi V1 phát hành, từng liên tục nhiều ngày độc chiếm vị trí đầu bảng Trending Hugging Face.
V2 là phiên bản agentic, thêm khả năng gọi công cụ nhiều bước, có thể dùng làm Agent cục bộ, biết tự đọc, suy luận, thao tác, rồi kiểm chứng.
Tác giả còn chạy benchmark – trên tập con telecom của tau2-bench, mô hình nền gemma-4-12B đạt 15%, mô hình phiên bản V2 đạt 55%, khoảng 3.5 lần hiệu năng cơ bản.

Tuy nhiên tác giả cũng nói, đây là giá trị tương đối tự test cục bộ, lĩnh vực đơn nhất, chạy 20 nhiệm vụ, không thể so sánh trực tiếp với bảng xếp hạng chính thức, anh ấy cũng thừa nhận vẫn còn khoảng cách không nhỏ so với các mô hình lớn frontier.
Tác giả còn đề cập: Fable 5 sau đó đã bị gỡ xuống, chỉ có bộ dữ liệu của anh ấy còn lưu giữ quá trình suy luận "nguyên bản" của Fable 5.
Còn phần reasoning thiếu trong dữ liệu đóng góp cộng đồng, anh ấy đổi sang dùng Claude Opus 4.8(xhigh) để sinh lại, bổ sung từng dòng một.
Anh ấy cũng thừa nhận, các quỹ đạo được xây dựng lại "có thể có sự khác biệt so với phiên bản Fable 5 gốc", nhưng đây là phương án khả thi duy nhất lúc đó.
Anh ấy còn tiết lộ trong discussion, bộ dữ liệu fine-tune này thực ra chỉ có khoảng 10 nghìn examples. Anh ấy nhấn mạnh, số lượng dữ liệu không quan trọng như mọi người tưởng tượng, cái thực sự quan trọng là chất lượng, sàng lọc và kiểm chứng.
Bộ mô hình này có thể có độ hot cao như vậy trên Hugging Face, còn có một lý do rất thực tế: Có thể chạy cục bộ.
Hai mô hình này đều là phiên bản lượng tử hóa GGUF.
GGUF là định dạng mô hình cục bộ phổ biến trong hệ sinh thái llama.cpp, người dùng có thể dùng các công cụ như llama.cpp, Ollama, LM Studio, Jan để tải trực tiếp.
Điều này đặc biệt hấp dẫn với các kịch bản coding. Xét cho cùng, viết code, xem kho, chạy lệnh, sửa bug, thường liên quan đến dự án riêng tư và môi trường cục bộ. Có thể chạy trên máy của mình, có nghĩa là không cần chuyển code lên đám mây, cũng không cần mỗi lần trả chi phí gọi API.
Quan trọng hơn, ngưỡng vào không cao lắm.
Trong mô tả mô hình V1 có viết, phiên bản Q2_K nhỏ nhất khoảng 4.5GB, chỉ cần có khoảng 4.5GB VRAM hoặc bộ nhớ thống nhất, là có thể chạy một trợ lý lập trình riêng tư, ngoại tuyến.
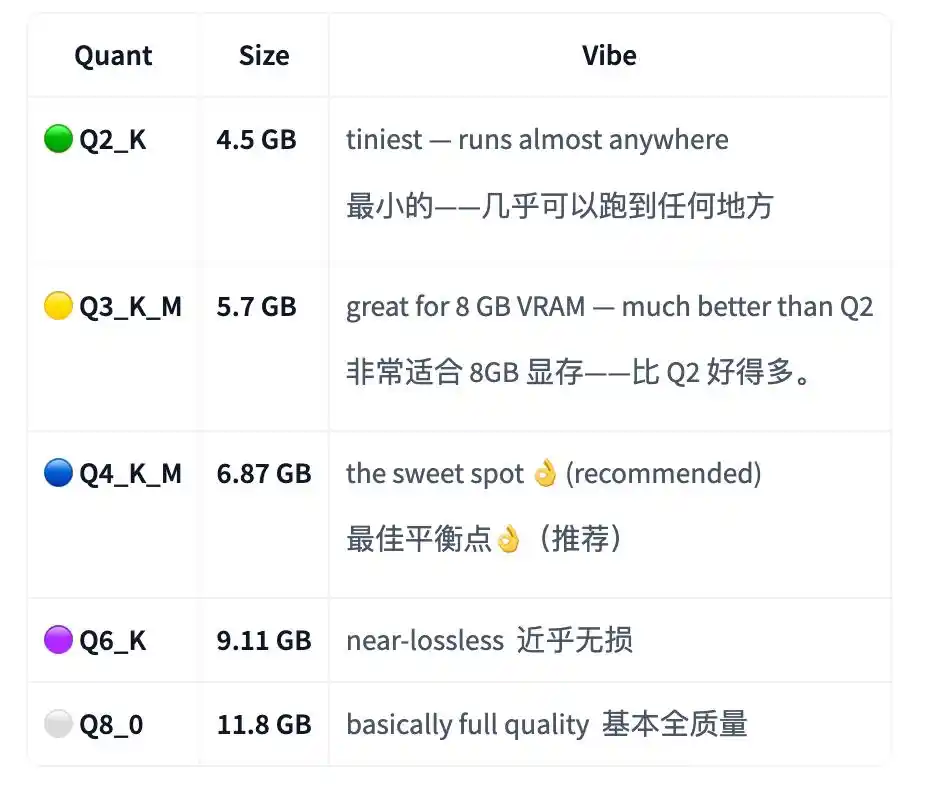
Điểm ngọt mà tác giả đề xuất là Q4_K_M, kích thước khoảng 6.87GB; chất lượng cao hơn Q8_0 thì khoảng 11.8GB.
V2 vì thiên về agentic hơn, tác giả không đưa ra Q2_K. Lý do là chưa qua kiểm tra áp lực, không đủ tin cậy.
Vì vậy phiên bản tin cậy tối thiểu của V2 bắt đầu từ Q3_K_M, khoảng 5.7GB; phiên bản được đề xuất Q4_K_M vẫn là khoảng 6.87GB.
Tác giả còn tiết lộ trước kế hoạch tiếp theo – V3 đang trên đường tới.
Anh ấy nói, V3 vẫn sẽ tiếp tục đi theo hướng coding+agentic dọc theo tuyến 12B này. Tác giả nói, bản thân cũng không nghĩ rằng lần cải thiện sau huấn luyện này lại lớn như vậy, nên tiếp theo sẽ tiếp tục đẩy về phía trước.
Đặc biệt là trên tau2-bench telecom, V2 vẫn còn một số vấn đề "cố gắng quá mức, retry lặp lại", V3 sẽ tiếp tục cải thiện thông qua nhiều huấn luyện hơn.
Mặt khác, anh ấy còn đang làm một phiên bản lớn hơn: Qwen3.6-27B. Tương đương với việc đặt cùng công thức coding+agentic lên nền tảng lớn hơn, cho người dùng có VRAM dư dả hơn sử dụng.
Một người, 40 giờ, xông vào giữa các ông lớn
Có thể đơn thương độc mã xông lên bảng hot Hugging Face, tổng lượng tải xuống vượt quá 70 vạn, giành được một chỗ đứng giữa hàng loạt công ty, tổ chức lớn.
Tác giả này rốt cuộc là cao thủ phương nào?
Sau khi liên hệ với tác giả, chúng tôi cũng biết được câu chuyện của anh ấy.
Anh ấy tên là Lộ Vũ Tân, hiện là nghiên cứu sinh về hướng AI tại một trường đại học ở Mỹ, đại học học về Dữ liệu và Phân tích Kinh doanh, giữa chừng còn chuyên đi học thêm một vòng phát triển full-stack, học cả frontend backend, phát triển phần mềm, xử lý dữ liệu.
Hai mô hình bùng nổ này, không phải là công việc chính của anh ấy, mà là dự án cá nhân hoàn toàn tự túc tài chính.
"Mã nguồn mở thực ra chỉ là tiêu tiền, sẽ không mang lại cho bạn bất kỳ thu nhập nào." Anh ấy hiểu rõ điều này, vì vậy động cơ ban đầu của anh ấy khi làm V1, ngược lại là "tự nâng cao":
Kiến thức trường dạy cập nhật quá chậm, khi học cao học giáo sư giảng vẫn là nội dung từ hai ba năm trước, mà AI thay đổi từng ngày, anh ấy quyết định lấy dự án này để ép bản thân đuổi kịp những thứ mới nhất.

Để làm những mô hình này, anh ấy đốt hết một gói Claude Max 20×, riêng V2 đã tốn hơn 40 tiếng.
Từng dòng tổng hợp dữ liệu, làm sạch thủ công, huấn luyện, đánh giá, huấn luyện lại, gần như toàn bộ một người gánh vác.
Về phần cứng, anh ấy dùng một chiếc RTX 5090, VRAM là 32GB; ngoài ra còn có khoảng 96GB tài nguyên SSD cục bộ có thể sử dụng kết hợp. Quy mô tài nguyên có thể huy động thực tế khoảng 128GB.
Đối với nhà phát triển cá nhân thì không tệ, nhưng hoàn toàn không cùng một tầm với hồ tính toán của các ông lớn và AI Lab.
Anh ấy nói với chúng tôi, trong toàn bộ quá trình, thứ tốn thời gian nhất thực ra không phải là huấn luyện, mà là xử lý dữ liệu.
Đặc biệt là dữ liệu agentic, các cuộc đối thoại thực tế thường rất dài, một nhiệm vụ có thể có hàng chục bước, hàng nghìn thậm chí hàng vạn token. Nhưng bị giới hạn bởi VRAM, khi huấn luyện một lần anh ấy chỉ có thể đưa vào tối đa 2048 token.
Vì vậy anh ấy đã xử lý kiểu "cửa sổ trượt": trong mỗi đoạn hội thoại nhiều lượt, lấy tin nhắn người dùng gần nhất làm điểm neo, xoay quanh một lần gọi công cụ, cắt ngữ cảnh trong phạm vi ngân sách.
V1 và V2 đều lấy Gemma 4-12B làm nền tảng. Chọn nó không phải vì dễ làm, mà ngược lại, định dạng và giao thức công cụ của Gemma 4 đều tương đối đặc biệt, thích ứng rất phiền phức, thậm chí nhiều client hỗ trợ không hoàn thiện.
Lộ Vũ Tân nói, một mặt là thử thách bản thân; mặt khác, là vì kích thước 12B này rất hấp dẫn.
Anh ấy tính toán, nếu lượng tử hóa xuống khoảng 3bit, nhiều người dùng Mac có bộ nhớ thống nhất 8GB cũng có thể chạy được, vẫn còn để lại một cửa sổ ngữ cảnh nhất định.
Tôi hiện tại biết, nhiều người sử dụng máy tính vẫn là bộ nhớ thống nhất khoảng 8GB. Vì vậy tôi muốn ở số tham số lớn nhất có thể, để nhiều người hơn sử dụng được.
Lộ Vũ Tân tổng kết giá trị của mô hình cục bộ thành hai từ:
Riêng tư, miễn phí.
Anh ấy cảm thấy, nhiều người chỉ muốn để AI giúp mình sắp xếp tệp, xử lý dữ liệu, làm PPT, hoặc trải nghiệm agent, không nhất định sẵn lòng mỗi tháng trả tiền cho Claude, GPT.
Con người có thể chỉ muốn chơi một chút, tại sao nhất định phải thu phí chứ?
Sau khi V1 phát hành, lúc đầu anh ấy không quá chú ý đến bảng xếp hạng, chỉ như thường lệ nói trong mô tả mô hình: nếu mọi người thích, lượng tải xuống và likes nhiều, anh ấy sẽ tiếp tục làm V2.
Không ngờ hai ba ngày sau, mô hình đột nhiên từ thứ hạng không biết bao nhiêu nhảy lên thứ tám; ngủ một giấc, lại vọt lên thứ nhất.
Sau đó, bình luận và issue tràn vào ồ ạt.
Anh ấy gần như xem từng dòng. Nhiều nhất, mỗi ngày dành ba bốn tiếng xem bình luận Hugging Face, trả lời câu hỏi, test phản hồi người dùng, rồi nói kết quả cho đối phương.
Anh ấy nói: "Cộng đồng có nhu cầu, tôi thực sự đang đi làm, đây mới là điều quan trọng nhất."
Hóa ra còn là một người thích đọc tiểu thuyết mạng...
Trên HF, Lộ Vũ Tân tổng cộng đã phát hành 9 mô hình công khai, ngoài hai mô hình bùng nổ, anh ấy còn làm qua mô hình "chưng cất trực tiếp Claude".
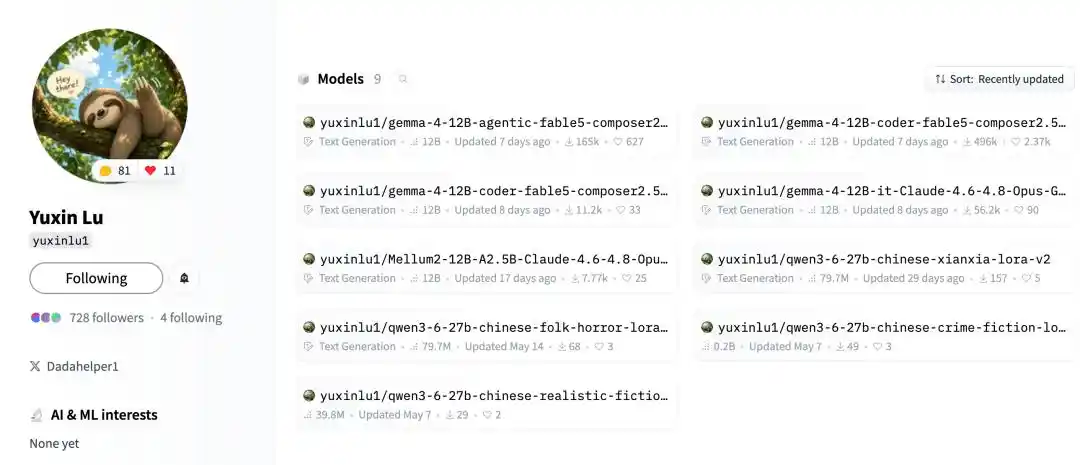
Ví dụ gemma-4-12B-it-Claude-4.6-4.8-Opus-GGUF, có thể hiểu là mô hình chưng cất Gemma4-12B phiên bản thông dụng.
Nó không giới hạn lập trình, mà giống như đang nén phong cách trả lời, thói quen suy luận, khả năng thinking của Claude Opus, vào mô hình cục bộ 12B này.
Một mô hình khác thì đơn giản đổi lấy mô hình lập trình Mellum2 của JetBrains làm nền tảng, chuyên làm chưng cất suy luận.
Tiếp tục nhìn xuống...
Khoan đã, sao còn có mô hình fine-tune tiểu thuyết mạng nữa vậy?

Trời ơi, còn chia thành bốn thể loại, đều là LoRA tiểu thuyết mạng tiếng Trung, và đều dựa trên Qwen3.6.
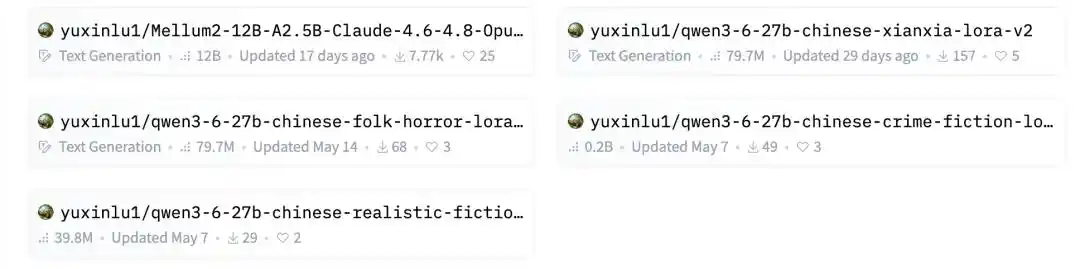
Lộ Vũ Tân nói với chúng tôi, đây thực ra là điểm bắt đầu làm mô hình Hugging Face sớm nhất của anh ấy.
Vì bản thân anh ấy vốn đã thích đọc tiểu thuyết. Khi theo dõi một cuốn tiểu thuyết chưa hoàn, độc giả lo lắng; tác giả ngày ngày gõ chữ cũng rất vất vả.
Vì vậy, anh ấy muốn làm một pipeline sinh tiểu thuyết miễn phí toàn bộ, dùng các LoRA tiểu thuyết Trung văn phong cách khác nhau, để tác giả có thể dùng AI tăng tốc, độc giả cũng có thể xem nội dung nhanh hơn.
Nhưng LoRA tiểu thuyết Trung văn trên HF không quá hot, sau đó anh ấy phát hiện người dùng quan tâm hơn đến coding và agentic, nên hướng đi dần dần chuyển sang tuyến đường hiện tại.
Khi được hỏi anh ấy có lời khuyên gì cho các nhà phát triển cá nhân khác, Lộ Vũ Tân nói: Chân thành và kiên trì là quan trọng nhất.
Chân thành, là không phóng đại năng lực mô hình. Chỗ nào mạnh, chỗ nào yếu, đều nói rõ.
Bạn phải nói thật với mọi người. Tôi lừa bạn nói của tôi mạnh thế này, nhưng sử dụng thực tế xuất hiện nhiều vấn đề, lần sau tôi đăng thứ gì, bạn sẽ không tin tôi nữa.
Kiên trì, thì là tác giả mã nguồn mở phải chấp nhận việc này: bạn chắc chắn sẽ gặp phải những ý kiến không hay.
Mô hình hot lên sau đó, Lộ Vũ Tân cũng gặp phải nghi ngờ, nhưng anh ấy vẫn quyết định kiên trì.
Theo quan điểm của anh ấy, con đường mã nguồn mở vốn dĩ rất khó.
Cho dù lên đỉnh bảng hot Hugging Face, cũng sẽ không trực tiếp mang lại thu nhập. Nhiều lúc, là tự mình tiêu tiền mua sức tính toán, dành thời gian xử lý dữ liệu, trả lời bình luận, sửa bug, rồi còn phải đối mặt với một số ít ý kiến tiêu cực.
Mà thứ chống đỡ anh ấy làm đến cùng, còn có một nhịp làm việc rất cá nhân.
Lộ Vũ Tân đề cập, bản thân mắc chứng ADHD.
Trước đây điều này có thể có nghĩa là rất khó thúc đẩy một việc theo trình tự trong thời gian dài, nhưng trong lĩnh vực AI thay đổi cực nhanh này, chuyển đổi sở thích nhanh chóng, nhanh chóng vào trạng thái hyperfocus, ngược lại trở thành một lợi thế nào đó.
Anh ấy thậm chí cho rằng: "Thời đại AI là của ADHD." Bởi vì một hướng nguội đi sau đó, nếu vẫn tiếp tục chăm chú vào trong đó, chờ chuyển sang học thứ mới, có lẽ đã muộn.
Nói chuyện đến cuối cùng, chúng tôi cũng ném ra câu hỏi ban đầu đó:
Là nhà phát triển cá nhân, dựa vào gì có thể chèn vào hàng đầu giữa các ông lớn?
Câu trả lời của Lộ Vũ Tân rất trung thực.
Anh ấy cho rằng các ông lớn tất nhiên có thể làm tốt hơn, có nhiều researcher hơn, cũng có sức tính toán mạnh hơn.
Nhưng các ông lớn phát hành mô hình nhỏ mã nguồn mở, thường còn đảm đương mục tiêu tuyên truyền thương hiệu, dẫn lưu lượng API; còn nhà phát triển cá nhân không có những gánh nặng này, ngược lại có thể tập trung hơn giải quyết một điểm đau cụ thể.
Tôi rất vui, nhưng không phải nói tôi thực sự đánh bại toàn diện họ, chỉ là có lẽ nghiêm túc hơn một chút.
Theo quan điểm của anh ấy, đây chính là cơ hội của tác giả mã nguồn mở cá nhân: không cần làm mô hình toàn năng, mà là đưa một vấn đề đủ cụ thể làm đến mức dễ dùng.
Nếu bạn cũng muốn trải nghiệm mô hình cục bộ này, liên kết đã được đặt ở bên dưới.
Nhắc nhở thân thiện: Hiện tại nền tảng thích ứng nhất là llama.cpp, ưu tiên giới thiệu mọi người sử dụng~
Địa chỉ HF: https://huggingface.co/yuxinlu1
Bài viết này đến từ tài khoản WeChat công chúng "量子位" (ID: QbitAI), tác giả: Quan tâm công nghệ tiền tuyến