一位个人开发者,竟然在一众大厂中,杀进了抱抱脸Models Trending榜的前排?!
这是普通的一天,我也普通地刷着抱抱脸的Trending榜。
第一是GLM-5.2,智谱最新开源模型,老熟人了,下载量6万多,不足为奇。
第二是百度的无限OCR,最近悄悄开源的,一口气能解析40多页文档,下载量也来到了7万。
再往下看,突然出现了一个个人账号:yuxinlu1。
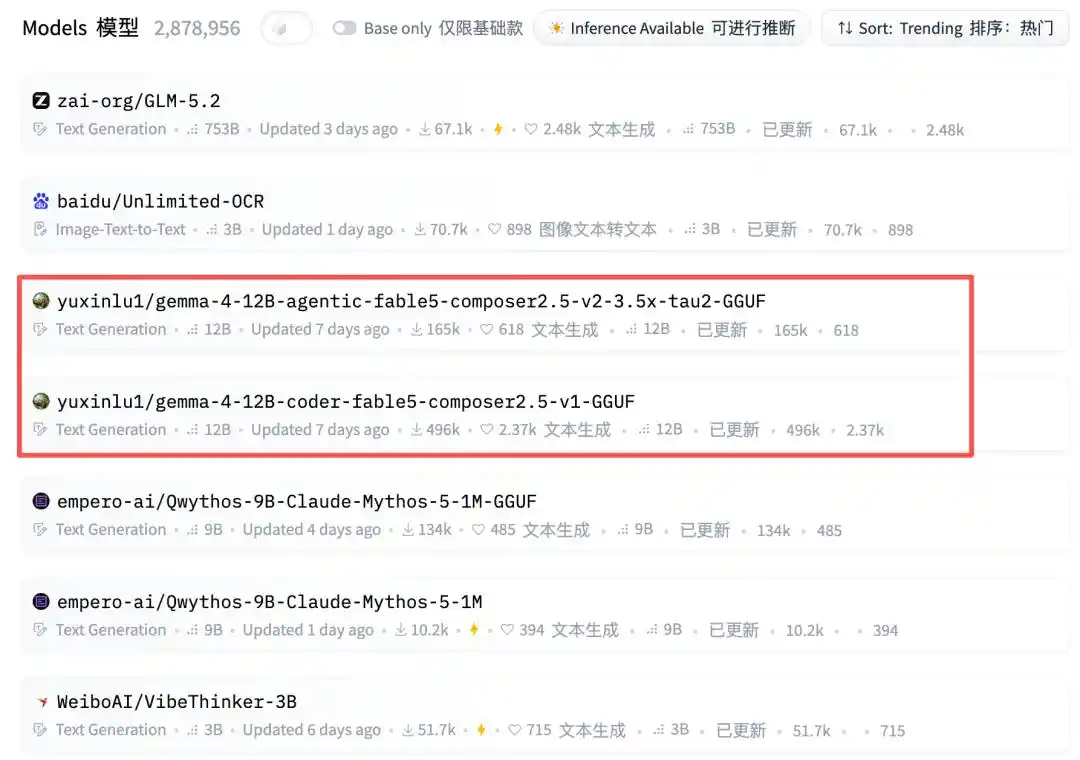
嗯......嗯?!
而且一占就是两个位置。
再一看下载量——最新数据已高达20.7万和53.6万。好家伙,这是什么神仙模型来了?
甚至在此前一周,这位个人开发者的模型一度霸榜抱抱脸,力压GLM-5.2一头,连智谱负责人都在X上公开推荐:
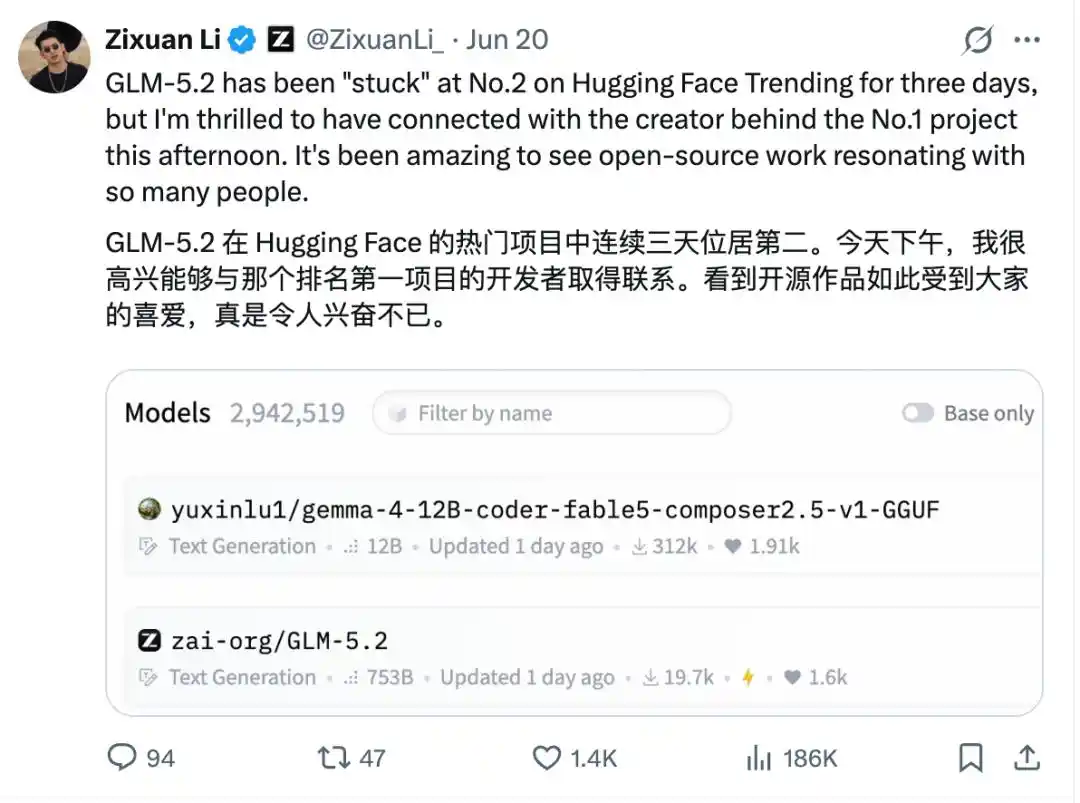
也就是说,在智谱、百度、Qwen、NVIDIA...这些名字中间,一个个人开发者账号硬生生挤进了TOP,而且下载量还这么高。
不禁令人好奇:luyuxin究竟是谁?怎么能量这么大?
“素人模型”冲上抱抱脸热榜
这波Hugging Face热榜,前排基本是大厂、明星团队和热门赛道在卡位。
比如智谱GLM-5.2,753B超大参数,国产明星大模型;百度Unlimited-OCR,踩中了最近很火的OCR和文档理解方向。
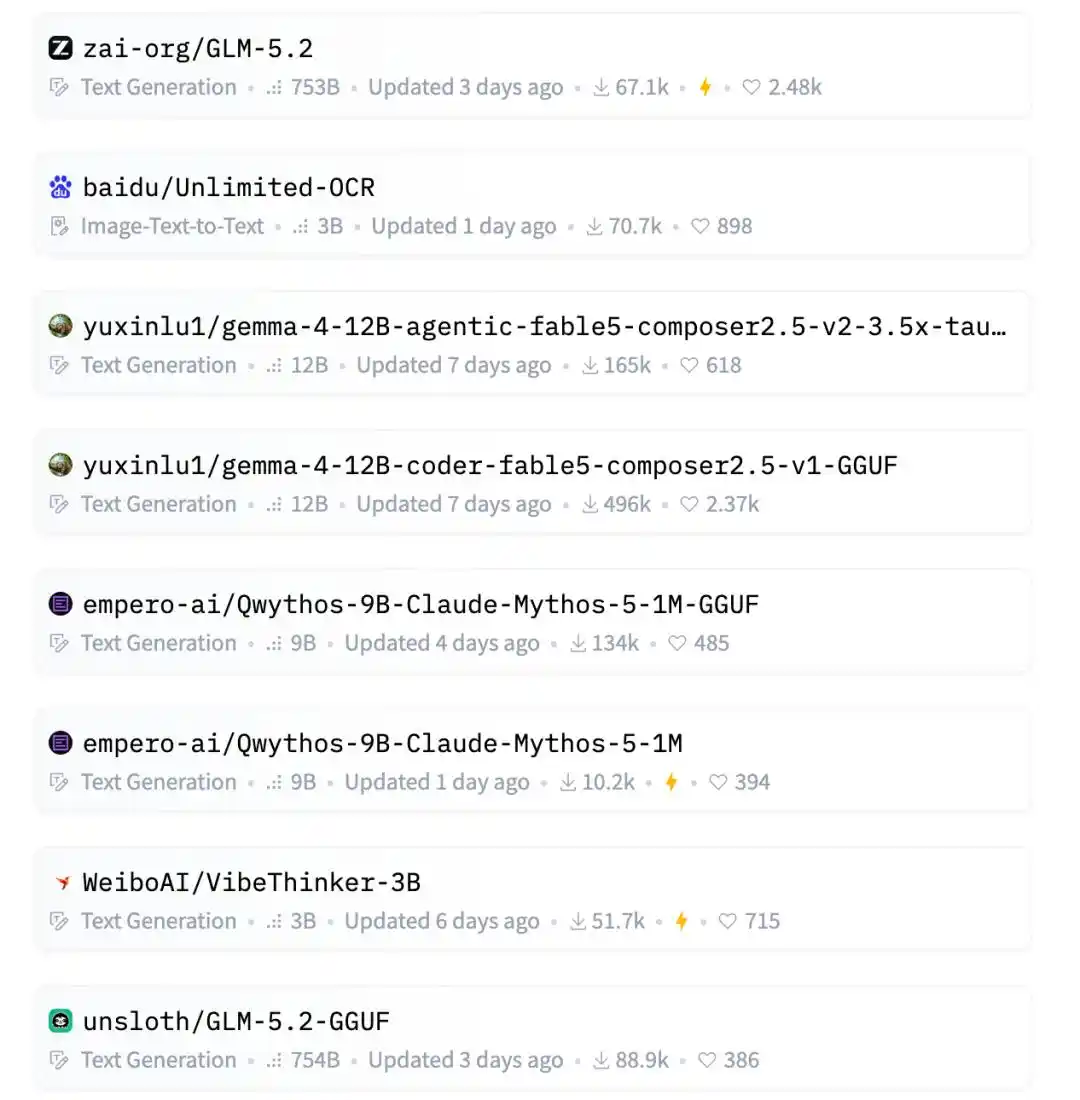
再往下还有Qwen的AgentWorld、英伟达的 LocateAnything、微软的FastContext。
国产开源大模型的熟面孔也都在列:MiniMax M3、Kimi-K2.7-Code、DeepSeek-V4-Pro。
图像生成方向也有Krea,新模型Krea-2-Turbo和Krea-2-Raw都在榜上。
结果里面还夹了两个luyuxin的12B GGUF模型。
不er...luyuxin你也太醒目了吧...
仔细一看,这两个新模型,主要把Fable 5的编程推理能力,蒸进了一个本地能跑的Gemma4-12B小模型里。
4.5GB显存就能跑,本地、离线、零API成本。普通玩家一张消费级显卡,甚至一台带统一内存的Mac,就能把它跑起来。
两个模型的分工也不同。
V1是Coder版,主打写代码、解题、生成可运行代码。

据模型卡,它的训练数据是“可验证”的代码推理:每条思维链对应的代码,都得真跑过测试、通过了才留下。
教师数据主要来自Cursor的Composer 2.5,外加Fable 5——Composer 2.5做错的题,会交给Fable 5重新推一遍,生成新的推理链和正确代码。
V1发布后,曾连续多日霸榜抱抱脸Trending榜榜首。
V2是agentic版,加了多步工具调用能力,能当本地Agent用,会自己读、推理、动手、再验证。
作者还跑了benchmark——在tau2-bench的telecom子集上,基座gemma-4-12B得分15%,V2版模型得分55%,大概是基础性能的3.5倍。

不过作者也表示,这是本地自测、单一领域、20个任务跑出来的相对值,不能跟官方榜直接比,他也坦白跟frontier大模型还有不小差距。
作者还提到:Fable 5后来被下线了,只有他自己的数据集还保留着Fable 5“原始”的那份推理过程。
而社区贡献数据里缺失的那部分reasoning,他改用Claude Opus 4.8(xhigh)重新生成、一条条补了回来。
他也承认,重建出来的轨迹“可能和原版Fable 5有出入”,但这是当时唯一可行的方案。
他还在discussion里透露,这套微调数据其实只有约1万条examples。他强调,数据量没有大家想象得那么重要,真正关键的是质量、筛选和验证。
这套模型之所以能在抱抱脸上有这么高的热度,还有一个很现实的原因:本地能跑。
这两个模型都是GGUF量化版。
GGUF是llama.cpp生态里常见的本地模型格式,用户可以用llama.cpp、Ollama、LM Studio、Jan等工具直接加载。
这对coding场景尤其有吸引力。毕竟写代码、看仓库、跑命令、调bug,经常涉及私有项目和本地环境。能在自己机器上跑,就意味着不用把代码传到云端,也不用每次都付API调用成本。
更关键的是,它门槛不算高。
V1模型卡里写到,最小的Q2_K版本约4.5GB,只要有约4.5GB显存或统一内存,就能跑一个私有、离线的编程助手。
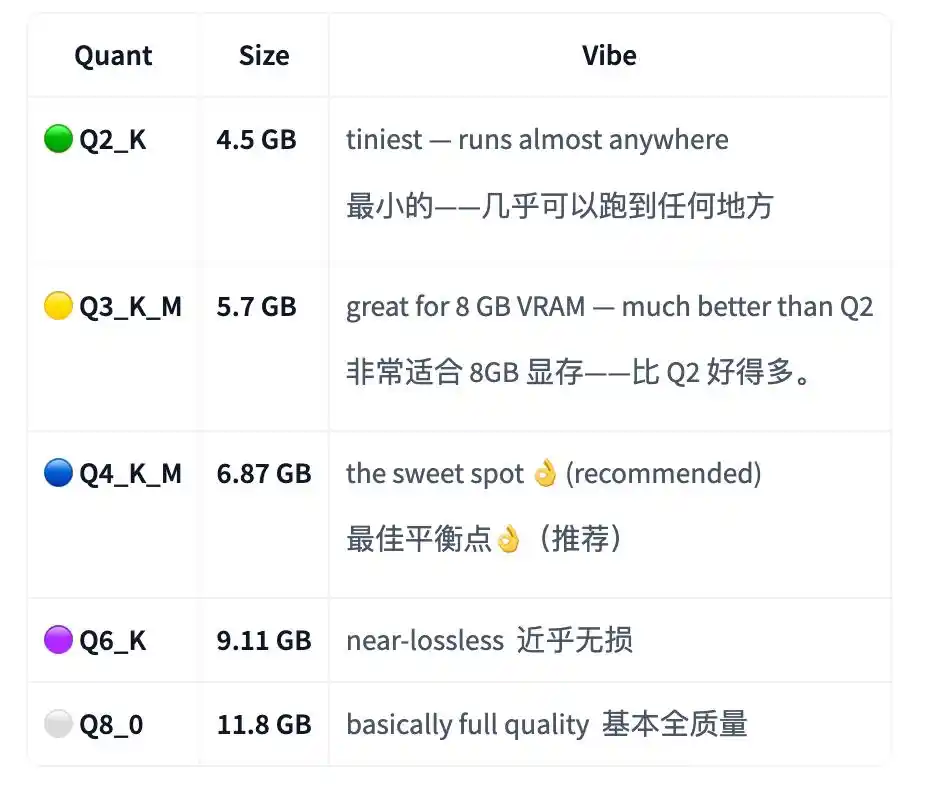
作者推荐的甜点位是Q4_K_M,大小约6.87GB;更高质量的Q8_0则约11.8GB。
V2因为更偏agentic,作者没有放Q2_K。理由是压力测试没过,不够可靠。
所以V2的最小可靠版本从Q3_K_M开始,约5.7GB;推荐的Q4_K_M依然是约6.87GB。
作者还提前剧透了后续计划——V3已经在路上。
他表示,V3仍然会沿着12B这条线继续做coding+agentic方向。作者说,自己也没想到这次后训练的提升会这么大,所以接下来会继续往前推。
尤其是在tau2-bench telecom上,V2还有一些“过度尝试、反复retry”的问题,V3会继续通过更多训练来改。
另一方面,他还在做一个更大的版本:Qwen3.6-27B。相当于把同一套coding+agentic配方放到更大的底座上,给显存更宽裕的用户用。
一个人,40小时,杀进大厂中间
能单枪匹马冲上抱抱脸热榜,下载量加起来超70万,在一众大厂机构间杀出一席之地。
这位作者究竟是何方神圣?
量子位与作者取得联系后,也得知了他的故事。
他叫逯雨鑫,目前是美国一所高校在读的AI方向研究生,本科念的是数据与商业分析,中间还专门去补过一轮全栈开发,把前后端、软件开发、数据处理都学了。
这两个爆火模型,并不是他的主业,而是纯自费的个人项目。
“开源这东西其实只是花钱,并不会让你有任何收入。”他很清楚这一点,因此他做V1的最初动机,反而是“自我提升”:
学校教的知识更新太慢,他读研时教授讲的还是两三年前的内容,而AI日新月异,他干脆拿这个项目来逼自己追上最新的东西。

为了做这些模型,他烧掉了整整一个Claude Max 20×套餐,单是V2就花了40多个小时。
一条条合成数据、手动清洗、训练、评测、再训练,几乎全是一个人扛下来的。
硬件上,他用的是一张RTX 5090,显存为32GB VRAM;另外还有约96GB的本地SSD资源可配合使用。实际能调动的资源规模大约在128GB左右。
对个人开发者来说不算差,但跟大厂和AI Lab的算力池完全不是一个量级。
他告诉量子位,整个过程里最耗时的其实不是训练,而是数据处理。
尤其是agentic数据,真实对话往往很长,一个任务可能有十几步,几千甚至几万个token。但受限于显存,他训练时一次最多只能喂2048 token。
所以他做了类似“滑动窗口”的处理:在每段多轮会话里,以最近一次用户消息为锚点,围绕一次工具调用,把上下文裁到预算以内。
V1和V2都以Gemma 4-12B为底座。选它不是因为好做,恰恰相反,Gemma 4的格式和工具协议都比较特殊,适配起来很麻烦,甚至很多客户端支持并不完善。
逯雨鑫表示,一方面是挑战自己;另一方面,是因为12B这个尺寸很有吸引力。
他算过,如果量化到3bit左右,很多8GB统一内存的Mac用户也能跑起来,还能留出一定上下文窗口。
我现在知道,很多人使用的电脑还是8GB左右的统一内存。所以我想在最大可能的参数量下,让更多人使用到。
逯雨鑫把本地模型的价值总结成两个词:
隐私,免费。
他觉得,很多人只是想让AI帮自己整理文件、处理数据、做PPT,或者体验一下agent,并不一定愿意每个月为Claude、GPT付费。
人可能就是想玩一玩,为什么非得要收费呢?
V1发布后,他一开始没太关注榜单,只是像往常一样在模型卡里说:如果大家喜欢、下载量和likes多,他就继续做V2。
没想到两三天后,模型突然从不知道多少名跳到第八;睡了一觉,又冲到第一。
随后,评论和issue大量涌进来。
他几乎每条都看。最多的时候,每天花三四个小时看Hugging Face评论、回复问题、测试用户反馈,再把结果告诉对方。
他表示:“社区有需求,我是真的在去做,这才是最关键的。”
原来还是个爱看网文的...
在HF上,逯雨鑫总共发布了9个公开模型,除了两个爆火模型,他还做过“直接蒸Claude”的模型。
比如gemma-4-12B-it-Claude-4.6-4.8-Opus-GGUF,可以理解成通用版Gemma4-12B蒸馏模型。
它不只限定编程,更像是在把Claude Opus的回答风格、推理习惯、thinking能力,往这个12B本地模型里压。
另一个模型则干脆换上JetBrains的编程模型Mellum2当底座,专做推理蒸馏。
再继续往下看...
等等,怎么还有网文的微调模型啊?

好家伙,还分了四个题材,都是中文网文LoRA,而且全都基于Qwen3.6。
逯雨鑫告诉量子位,这其实是他最早开始做Hugging Face模型的入口。
因为他自己本来就喜欢看小说。追一本没完结的小说时,读者焦虑;作者日更码字也很辛苦。
于是,他想做一整套免费的小说生成pipeline,用不同风格的中文小说LoRA,让作者能用AI提速,读者也能更快看到内容。
但中文小说LoRA在HF上并不算热门,后来他发现用户更关注coding和agentic,于是方向慢慢转到了现在这条线上。
当问及他对其他个人开发者有什么建议时,逯雨鑫说:真诚和坚持最重要。
真诚,是不要夸大模型能力。哪里强,哪里弱,都说清楚。
你要如实告诉大家。我骗你说我这有多强,但真实使用下来出现很多问题,下次我一发东西,你就不相信我了。
坚持,则是开源作者必须接受这件事:你一定会遇到不好的声音。
模型火了以后,逯雨鑫也遇到过质疑,但他还是决定坚持下去。
在他看来,开源这条路本来就很难。
就算登顶Hugging Face热榜,也不会直接带来收入。更多时候,是自己花钱买算力、花时间处理数据、回复评论、修bug,然后还要面对少数负面声音。
而支撑他一路做下来的,还有一种很个人的工作节奏。
逯雨鑫提到,自己患有ADHD。
过去这可能意味着很难长期按部就班推进一件事,但在AI这个变化极快的领域,快速切换兴趣、迅速进入hyperfocus,反而成了某种优势。
他甚至认为:“AI时代是ADHD的天下。”因为一个方向凉下来后,如果还一直钻在里面,等再转去学新的东西,可能已经晚了。
聊到最后,我们也抛出了那个最初的问题:
作为个人开发者,凭什么能在大厂中间挤进前排?
逯雨鑫的回答很中肯。
他认为大厂当然能做得更好,有更多researcher,也有更强算力。
但大厂发布开源小模型,往往还承担品牌宣传、API引流等目标;而个人开发者没有这些包袱,反而可以更专注地解决一个具体痛点。
我很高兴,但不是说我真的全面打败了他们,只是可能更认真一些。
在他看来,这正是个人开源作者的机会:不必做全能模型,而是把一个足够具体的问题做到好用。
如果你也想体验一下这款本地模型,链接已经放在下方。
温馨提示:目前最适配的平台是llama.cpp,优先推荐大家使用~
HF地址:https://huggingface.co/yuxinlu1
本文来自微信公众号 “量子位”(ID:QbitAI),作者:关注前沿科技






