Por | Estrella de Silicio
El famoso meme de Sam Altman, esta vez se cumplió para todos.
El año pasado, al promocionar GPT-5, el CEO de OpenAI dijo una frase que luego se volvió viral: "Esa sensación es como ver explotar una bomba atómica, mareado y desplomado". Desde entonces, cada vez que el círculo de IA lanza un nuevo producto con textos exagerados, este meme es sacado para ser ridiculizado repetidamente.

Pero anteanoche, quien se mareó y se desplomó no fue Altman. Esta vez fueron todos los usuarios que miraban la pantalla esperando la jugada de OpenAI.
Altman, como de costumbre,故作神秘, publicó un tuit: "Tenemos preparadas algunas cosas interesantes."
Para las tres de la madrugada, GPT-Image 2 llegó. La comunidad global de IA estalló directamente.
"Las imágenes son un lenguaje, no una decoración."
Esta es la primera frase que OpenAI escribió en la página de lanzamiento. Traducido, significa una cosa: a partir de hoy, la imagen ya no es un elemento decorativo, es en sí misma un lenguaje. Esta es una declaración de salto generacional para toda la industria de la visión por computadora.
Durante todo el año pasado, el dibujo con IA aún estaba atrapado en el pantano estético de "si se parece o no". Con la aparición de GPT-Image 2, se presionó directamente el botón de cambio: la generación de imágenes por IA entró formalmente en el examen intelectual de "si la lógica es correcta o no".
La precisión de este modelo no es exagerado形容con "aterradora".
Encabezó la lista de generación de imágenes a partir de texto y edición de imágenes de Artificial Analysis, y su rendimiento práctico fue aplastante.
Esa sensación fue como cuando Seedance 2.0 llegó al campo de generación de video, ya no es una herramienta auxiliar para los humanos, está definiendo nuevos estándares de la industria.
Nota: Las imágenes de este artículo fueron generadas en su totalidad por GPT-Image 2, el contenido de las imágenes es pura ficción.
01 El despertar del motor de pensamiento
En el pasado, el primer criterio para juzgar si un modelo de imagen era bueno era si se parecía a una persona real o a un objeto de referencia.
Ante este monstruo que es GPT-Image 2, este estándar está obsoleto. Completamente obsoleto.
El punto de avance más central del nuevo modelo está aquí: es un modelo de imagen que admite un modo de pensamiento.
¿Qué significa? Después de que el usuario ingresa el prompt, el modelo ya no simplemente elimina ruido o une píxeles. Primero completa un modelado de pensamiento en segundo plano, y luego dibuja.
Una imagen de prueba filtrada por la comunidad Linux.do ilustra mejor el problema. El modelo simuló una transmisión en vivo de Lei Jun corriendo:
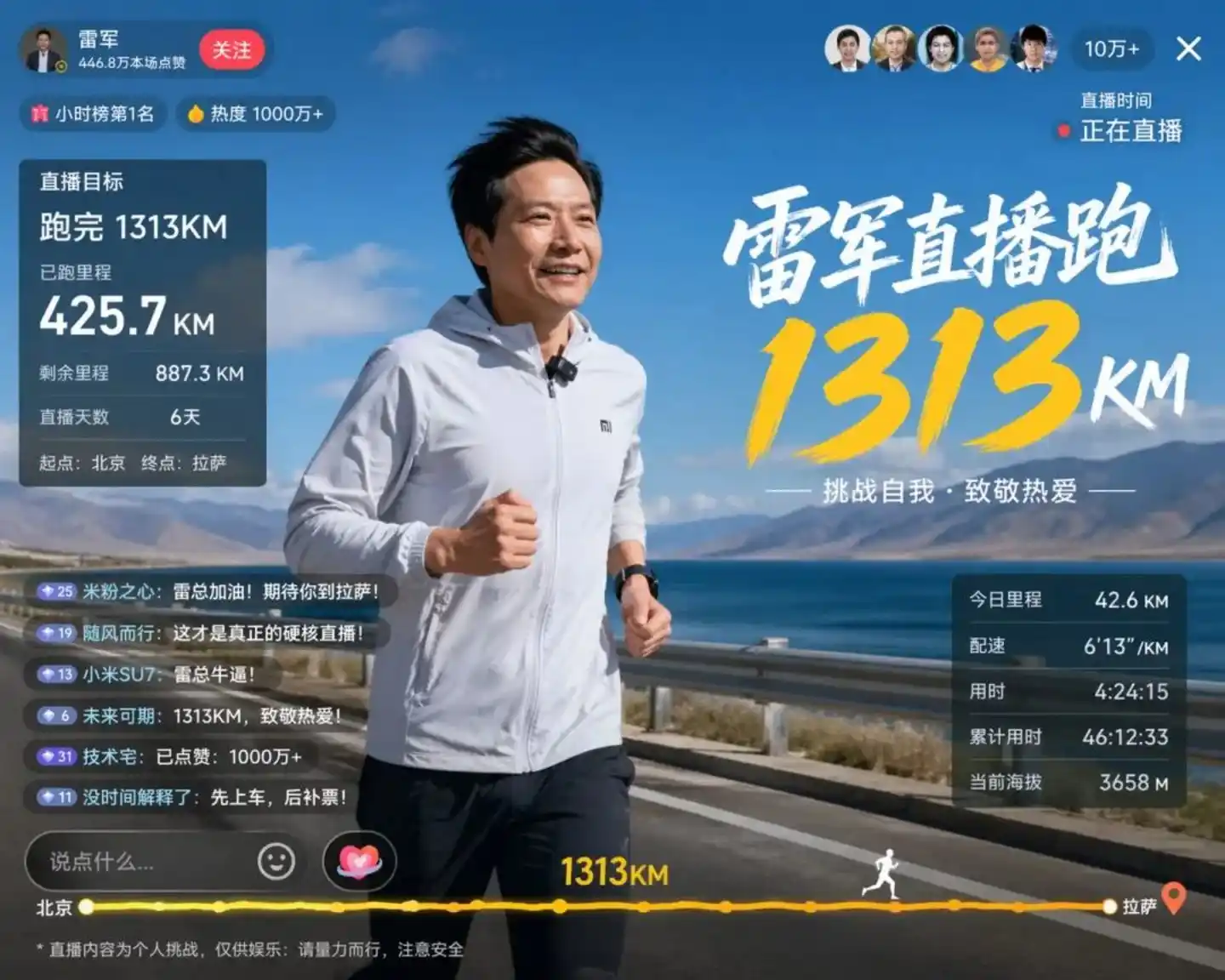
Fuente de la imagen: https://cdn3.linux.do/original/4X/0/f/3/0f37c8bc968e3d563cc6100d8e7f80ee305661ff.jpeg
Esta imagen hizo que muchos desarrolladores se quedaran boquiabiertos. Los rasgos faciales del CEO Lei se reproducen con precisión (casi como una foto). La imagen muestra claramente: objetivo de la transmisión en vivo 1313 km, distancia recorrida 425.7 km, distancia restante 887.3 km. Y aún más increíble, la altitud actual marca 3658 m.
¿Qué significa 3658 m? De Beijing a Lhasa, la altitud típica al entrar en la región tibetana es precisamente este número.
Para los ojos humanos, esto no es más que simples operaciones aritméticas y conocimiento geográfico básico. Pero piensen: ¿Qué significa para un modelo de imagen la triple unificación de lógica matemática + conocimiento geográfico + especificaciones de UI?
La conclusión es directa: antes de generar el primer píxel, GPT-Image 2 ya completó una ronda de razonamiento. Comprendió el significado de "distancia", entendió la relación lógica de sumas y restas, y también entendió las características visuales de las regiones de gran altitud.
Esto no es dibujar. Esto es pensar.
02 De juguete a herramienta de productividad
Frente a esta capacidad, la actitud de todos hacia los modelos de imagen debe cambiar.
Ya no es un juguete para dibujar avatares o hacer fondos de pantalla. Dio un paso más allá del umbral de "utilizable" y se adentró directamente en la zona "fácil de usar": una herramienta que puede lanzarse directamente a escenarios comerciales para trabajar.
Tomemos el diseño de carteles, por ejemplo. La estética de composición, el manejo de la luz y las sombras, y la captación del tono de la marca de GPT-Image 2毫无疑问alcanzaron alturas que la gran mayoría de los diseñadores humanos comunes difícilmente pueden alcanzar.

Fuente de la imagen: https://cdn3.linux.do/original/4X/7/a/1/7a12ccd6b745be5ad8828eb0ac225d218fb43cbc.jpeg
En la sociedad humana, contratar a un artista gráfico senior para diseñar un cartel a nivel comercial, con costos de comunicación, costos de tiempo y una remuneración de diseño de miles de yuanes, a menudo es una carga pesada para las pequeñas y medianas empresas.
Sin embargo, con GPT-Image 2, incluso si el resultado no es satisfactorio y se ajusta docenas de veces, el costo será de apenas unos pocos dólares.
En áreas como diseño de carteles, materiales de marketing, ilustraciones e imágenes complementarias, a los usuarios no les importa "si es real", les importa "si es bonito, si es preciso". Precisamente por eso, la eficiencia de reemplazo de la IA es devastadora.
En la documentación para desarrolladores actualizada simultáneamente, también se esconde un detalle emocionante: en el código de ejemplo apareció frecuentemente model: "gpt-5.4".
El modo de pensamiento más el modelo insignia, esta combinación insinúa una cosa: GPT-Image 2 no es un producto aislado. Está destinado a ser un terminal visual para la próxima generación de modelos de lenguaje grande.
A través de la nueva API de Respuestas, el proceso de generación de imágenes interactuará tan naturalmente como charlar con un modelo de lenguaje grande. El modelo añadió una función que permite modificaciones en múltiples turnos de conversación. Después de la generación inicial de la imagen, los usuarios pueden dar varias instrucciones que harían subir la presión arterial a los diseñadores de la parte B.
A través de la nueva API de Respuestas, el proceso de generación de imágenes interactuará tan naturalmente como una charla con un modelo de lenguaje grande. El modelo añadió la función de modificación mediante diálogo multi-turno. Después de la primera versión generada, los usuarios pueden proponer varias instrucciones que harían subir la presión arterial a los diseñadores de la parte B: "Un poco más oscuro el fondo." "Mueve el logo unos píxeles a un lado."
Estas necesidades de modificación interactiva en tiempo real son precisamente la parte más tediosa y que consume más paciencia en el trabajo diario de un diseñador. Ahora, se resuelven sin problemas.
03 La cúspide del renderizado de chino
Aunque GPT-Image 2 es un modelo extranjero, los usuarios nacionales lo aplaudieron abrumadoramente.
La razón es solo una: su soporte para caracteres chinos es prácticamente perfecto.
En las imágenes de prueba devueltas por la comunidad, se puede ver el famoso debate entre Luo Yonghao y Wang Ziru:
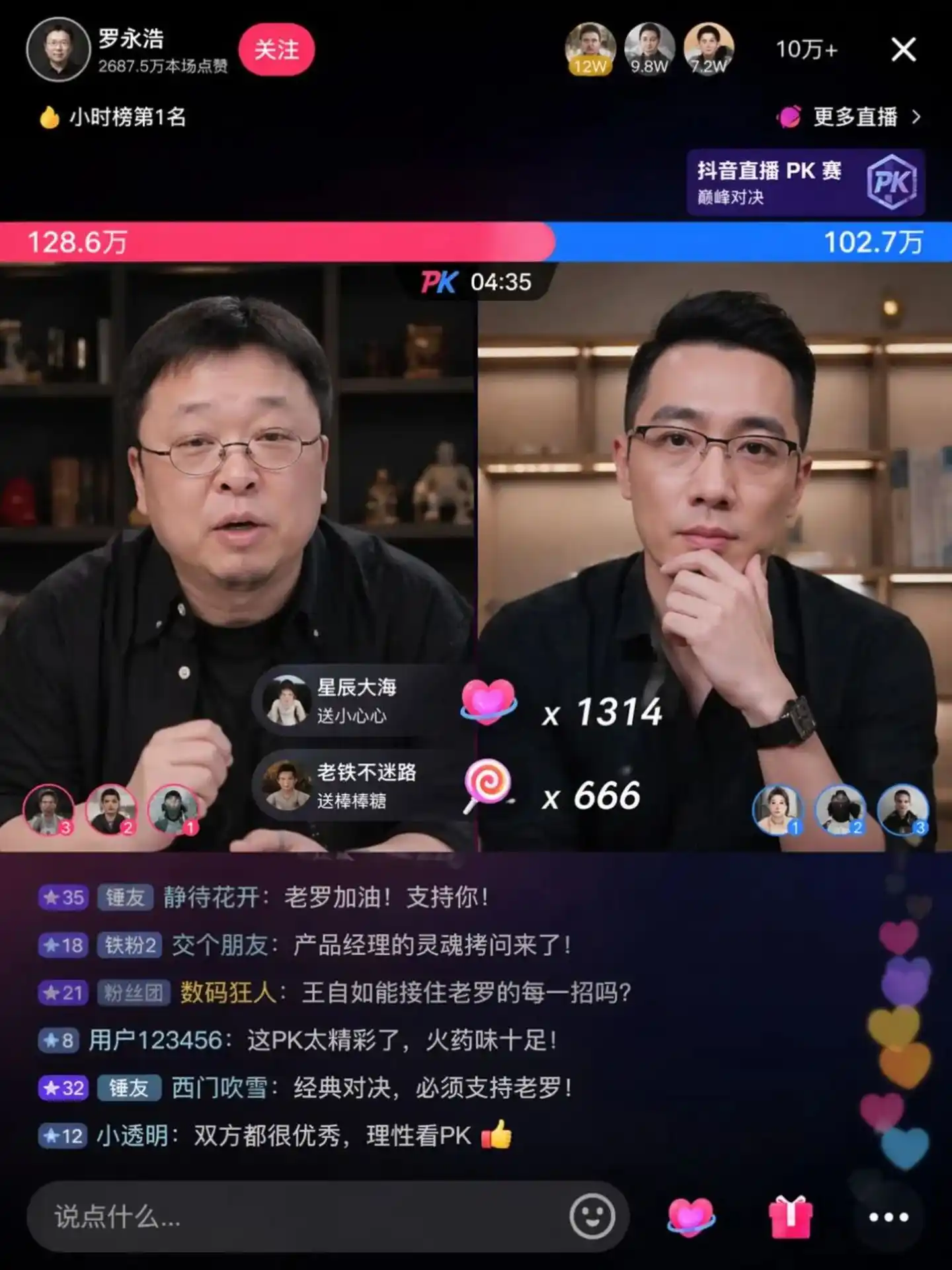
Fuente de la imagen: https://cdn3.linux.do/original/4X/0/9/7/097ed46991d2464442aebc6b1076a292cc839fec.jpeg
Se puede ver a Elon Musk vendiendo en vivo Lao Gan Ma:

Fuente de la imagen: https://cdn3.linux.do/original/4X/2/f/a/2fa77cf040e6337643829df4ec5ca6467d2866b2.jpeg
Incluso se puede ver una receta médica escrita por un doctor:

Fuente de la imagen: https://cdn3.linux.do/original/4X/9/f/f/9ffeab83675648b43116cd0763f6c8b560611ae6.jpeg
El texto en estas imágenes ya no son "pseudo-caracteres chinos" torcidos y amontonados al azar, sino diseños maduros que poseen encanto caligráfico, sentido de niveles tipográficos y arte de maquetación.
Evidentemente, OpenAI incorporó una gran cantidad de imágenes de corpus en chino en el conjunto de entrenamiento y realizó un entrenamiento intensivo específico.
En comparación con el modelo anterior, la potencia de GPT-Image 2 se manifiesta de manera aún más vívida.
En pruebas comparativas, el modelo anterior, versión 1.5, aunque podía dibujar algo que se parecía a una receta, al mirar de cerca, el texto era casi todo ilegible.

Fuente de la imagen: https://cdn3.linux.do/optimized/4X/2/b/3/2b38f3c1a134515d564f07f81661c0bd9578c6b9_2_750x750.jpeg
Pero la misma receta generada por GPT-Image 2 mostró una claridad en el texto y una estética que ya representan un avance里程碑.
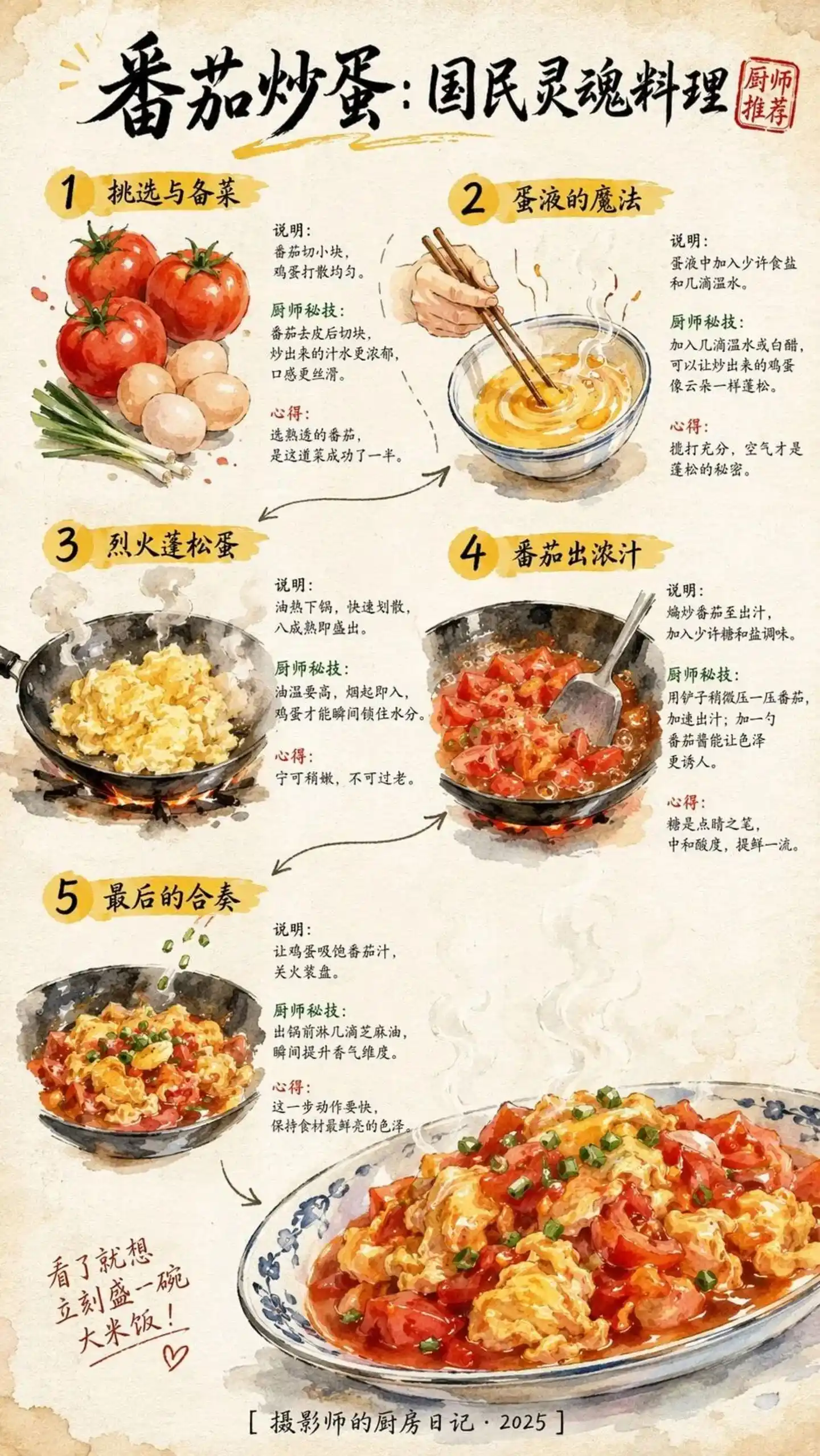
Fuente de la imagen: https://cdn3.linux.do/original/4X/0/2/5/02513b10135d824ccb1c22bd0c7eb441f1e34455.jpeg
Para prompts de más de cien caracteres chinos, los cinco pasos siguen siendo claramente visibles, y la coherencia entre texto e imagen es satisfactoria. Esto no es solo una imagen, es un plan operativo reproducible.
Sin embargo, esto también plantea una pregunta técnica interesante: ¿los modelos de imagen han resuelto completamente el problema del texto ilegible?
Mi juicio es: probablemente no.
Los modelos de lenguaje grande generan tokens basándose en lógica semántica. La etapa de aprendizaje por refuerzo se basa en probabilidades; a mayor cantidad de corpus de alta calidad, más lógica es la lógica. Pero la esencia de los modelos de imagen, después de todo, es la generación de píxeles. La relación lógica entre píxeles y la relación lógica entre palabras no son para nada lo mismo.
En otras palabras, por poderoso que sea GPT-Image 2, en realidad no "comprende" las reglas de la escritura. Simplemente memorizó mecánicamente la apariencia de los textos a nivel de píxel.
Una imagen de una conversación de negocios con Altman expuso este punto: en dos cajas de bebidas, los grandes caracteres "Mengniu" y "Wang Lao Ji" estaban escritos perfectamente, pero el texto pequeño debajo seguía siendo bloques de color borrosos.

Fuente de la imagen: https://cdn3.linux.do/original/4X/d/7/c/d7c4fb063202bcbf56b9ca0623aa0ce6fc26e542.jpeg
Bajo el paradigma técnico actual, la lógica de generación sigue siendo "disponer por disposición de píxeles", distando un paso esencial de "renderizar por caracteres". Es posible que el texto ilegible en detalles extremadamente finos nunca pueda erradicarse por completo.
Pero dicho esto, para más del 90% de los escenarios de aplicación comercial, esto ya es suficiente.
04 Defectos y límites aún no divinos
Aunque ya se sienta en el trono número uno del mundo, GPT-Image 2 también tiene su lado torpe.
En pruebas prácticas se descubrió que, dado que el modo de pensamiento llama a búsquedas en línea y realiza推理lógico, al procesar tareas de ficción extremadamente complejas, el modelo ocasionalmente puede caer en un círculo lógico: después de pensar durante casi 40 minutos, todavía no puede responder.
Al mismo tiempo, el soporte API declarado para resoluciones de 2K甚至4K, implica un consumo de tokens extremadamente alto y una latencia significativa.
Para los usuarios comunes, cómo lograr un equilibrio entre la calidad de imagen极致y la velocidad de respuesta será una lección obligatoria en el uso futuro.
En el campo tecnológico, una capacidad poderosa siempre es un arma de doble filo.
Tanto los modelos de imagen como los de video, inevitablemente deben enfrentar el desafío ético de la falsificación profunda (deepfake).
En la mayoría de los casos de prueba actuales, la IA genera personajes famosos, pero si se cambian por personas comunes que han publicado fotos en varias redes sociales, en casos donde no se conoce a la persona, ya es extremadamente difícil distinguir lo real de lo falso.
Excepto por el texto ilegible que ocasionalmente aparece en el fondo y que podría delatar a la IA, el cuerpo humano en sí mismo ya no tiene falla alguna.
Por lo tanto, aquellos campos que antes debían ser completados por personas reales, están enfrentando una crisis de confianza sin precedentes.
El lanzamiento de GPT-Image 2 llevó a los modelos de generación de imágenes de ser juguetes a herramientas de productividad.
En el pasado, la gente usaba la IA para proporcionar inspiración, pero ahora la IA está comenzando a intentar hacerse cargo de todo el flujo, desde la concepción, el cálculo, el diseño hasta el producto final.
Para los profesionales del diseño, esta es una era llena de FOMO (miedo a perderse algo).
Pero para aquellos que son buenos usando herramientas, poseen estética de producto y pensamiento lógico, esta es también la mejor era.
Las imágenes comenzaron a aprender a pensar, el texto ya no es ruido de píxeles.
La humanidad puede estar realmente a solo un paso de ese punto奇点visual de "lo que piensas es lo que obtienes".







