Redacción de Machine Heart
El nuevo modelo de código abierto de Google, Gemma 4, presentado hace unos días, dio una gran sorpresa a la industria.
Utiliza una arquitectura técnica de la misma fuente que Gemini 3, es compatible con modalidades completas nativas, obtuvo el tercer lugar global en el ranking Arena AI, y hay varios modelos para elegir. Varios modelos más pequeños — E2B (2.3B de parámetros efectivos) y E4B (4.5B de parámetros efectivos) — se pueden implementar y ejecutar localmente en dispositivos móviles, con una ventana de contexto de 128K, lo que podríamos llamar un "reemplazo de Gemini que cabe en el bolsillo".
Como era de esperar, el modelo se convirtió rápidamente en el nuevo juguete de los usuarios de teléfonos.
Entre ellos, una publicación de un usuario de X fue vista cientos de miles de veces. En la publicación, compartió un video mostrando cómo ejecuta Gemma 4 localmente en su iPhone, incluyendo el procesamiento de imágenes, audio y el control del encendido y apagado de la linterna. Mencionó que Gemma 4 es increíblemente rápido, se siente como magia.

Alguien cuantificó esta velocidad en un iPhone 17 Pro, señalando que si el teléfono utiliza un chip Apple, entonces con la ayuda de MLX (el framework de aprendizaje automático de Apple) optimizado para este chip, la velocidad de inferencia del modelo puede superar los 40 tokens por segundo.

También se lograron velocidades similares en un Samsung Galaxy, incluso con el modo de pensamiento activado. Esto hizo que la gente exclamara "demasiado rápido para ser real".
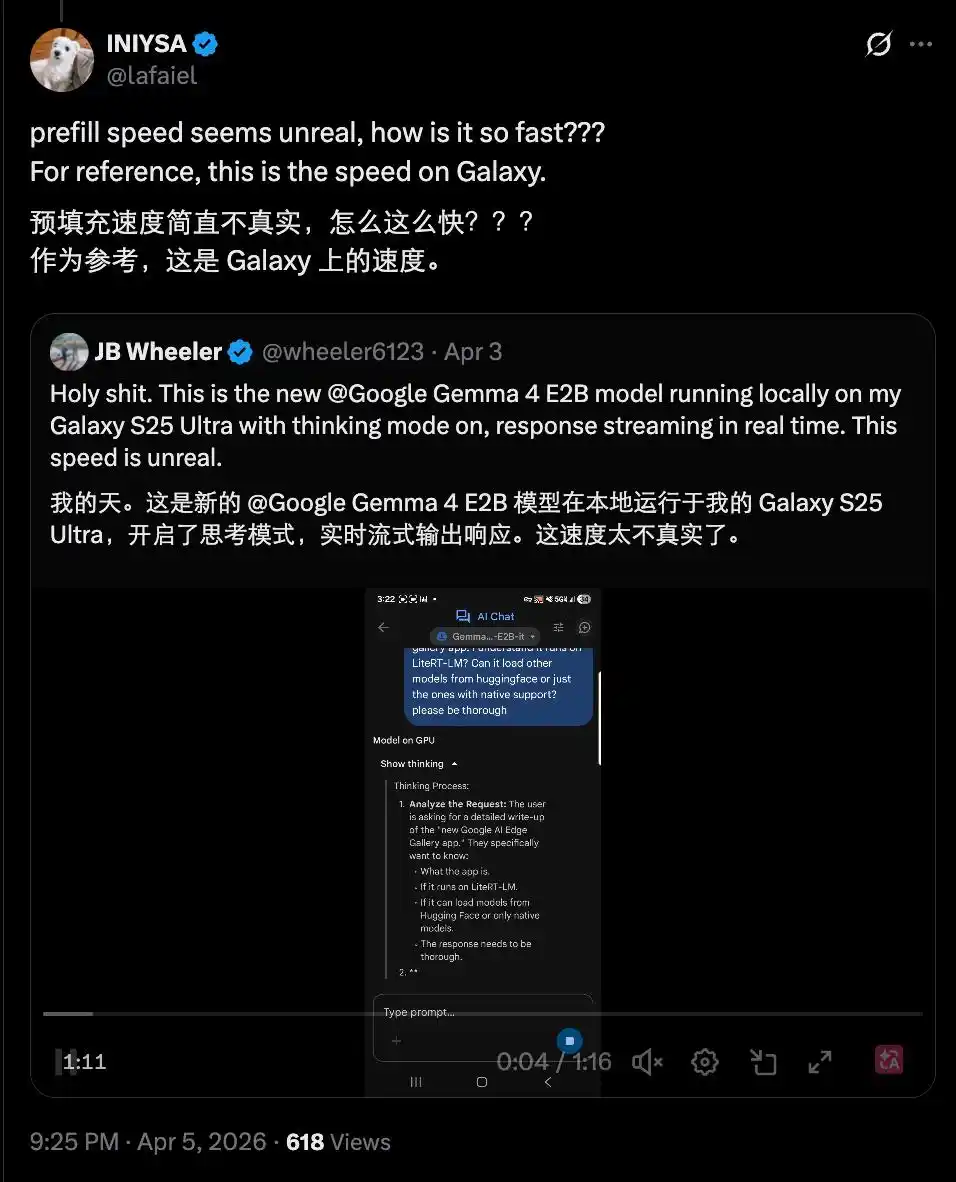
Estas velocidades convierten la ejecución de modelos de IA en dispositivos móviles en una opción viable para el futuro, y son muy útiles en escenarios sensibles como la atención médica.
La ventana de contexto de 128k también hace que estos modelos pequeños sean más atractivos.
¿Y cómo se ejecuta? En realidad, es muy simple, no es exclusivo para geeks, porque Google lanzó una aplicación oficial: Google AI Edge Gallery. Quienes quieran experimentar en sus teléfonos pueden descargar esta aplicación directamente, luego descargar la versión del modelo que deseen ejecutar, y abrirla para comenzar.

Además, al ser un lanzamiento oficial de Google, naturalmente no hay que preocuparse demasiado por la seguridad.
Además de estos modelos pequeños que se ejecutan en dispositivos móviles, algunos han probado versiones más grandes de Gemma 4 en hardware más potente, como ejecutar Gemma 4 Mixture-of-Experts 26B en una MacBook Pro con chip M5 Pro.

Si es para diálogo directo, la velocidad de este modelo sigue siendo rápida, la generación de texto y la explicación de código son fluidas.

Pero cuando realmente usó Gemma 4 como un agente de codificación, surgieron problemas. Porque ejecutar un agente requiere un contexto grande (Gemma 4 26B tiene una ventana de contexto de 256k), prompts complejos y una invocación de herramientas estable. Gemma 4 claramente no pudo soportar esto, a menudo se trababa, generaba errores o producía una estructura de salida incorrecta.

El punto de inflexión ocurrió cuando cambió el modelo a qwen3-coder. En el mismo entorno, la creación de archivos, la ejecución de comandos y las tareas de múltiples pasos funcionaban normalmente. Considera que el problema no está en el framework del agente, sino en si el modelo en sí ha sido optimizado para "invocación de herramientas + salida estructurada". En este aspecto, Gemma 4 podría no haberlo hecho lo suficiente, o quizás este desarrollador aún no ha encontrado la forma correcta de usarlo.

Además, algunos dicen que el nivel intelectual de Gemma 4 todavía es un poco limitado.
Aun así, la aparición de este "pequeño cañón de rendimiento" que es Gemma 4 no debe subestimarse. Si en el futuro una gran cantidad de consultas diarias, chats, razonamientos simples, generación de código y tareas de comprensión de imágenes se pueden ejecutar localmente, sin necesidad de comprar tokens, ¿no estarán en una situación incómoda los fabricantes que venden tokens?
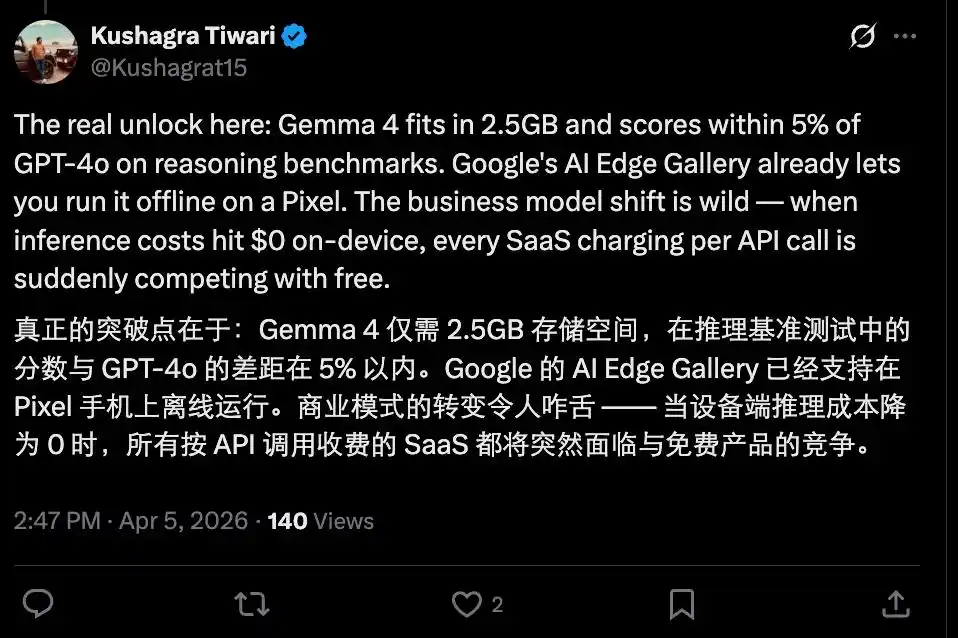
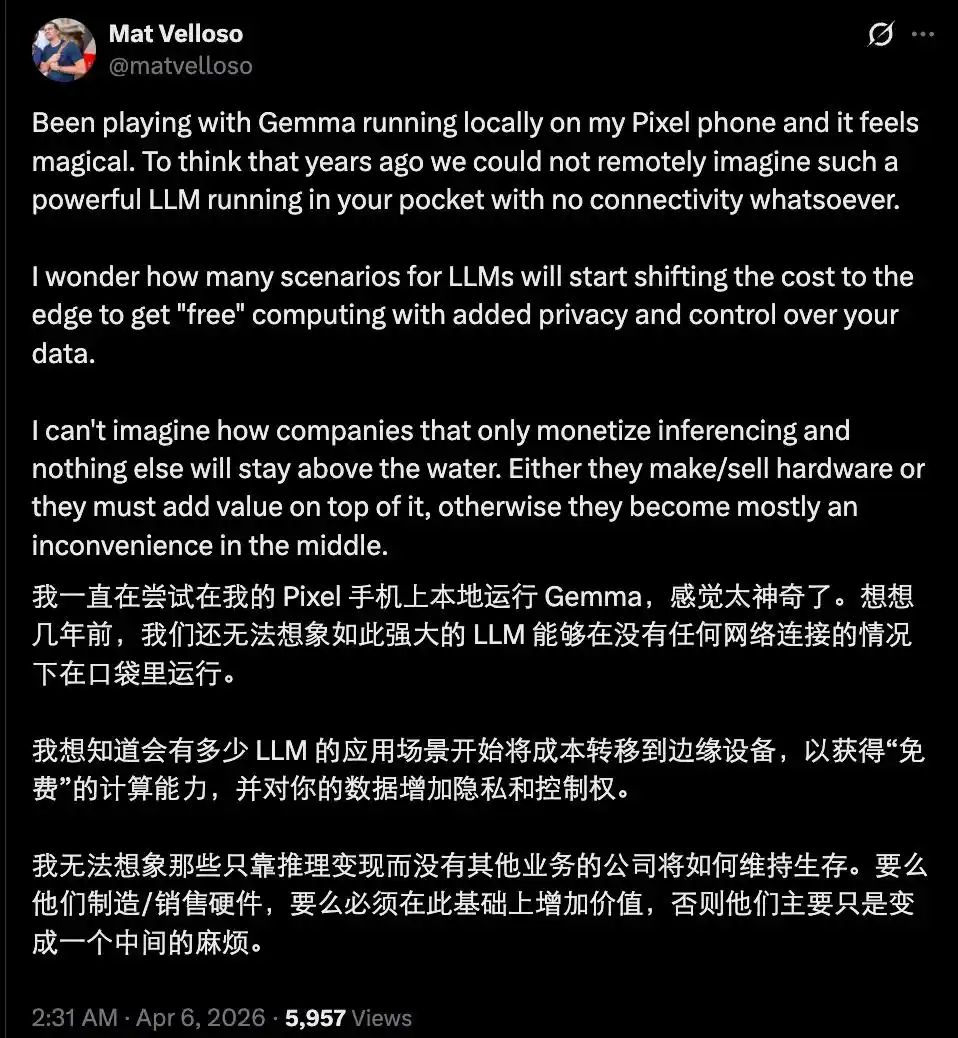
Por supuesto, la situación actual no es tan pesimista, después de todo, todavía existe una brecha entre los modelos de código abierto disponibles y los modelos cerrados de vanguardia, y la mayoría de los modelos de código abierto potentes todavía están limitados por la capacidad del hardware, y temporalmente no pueden alcanzar un nivel utilizable en el edge.
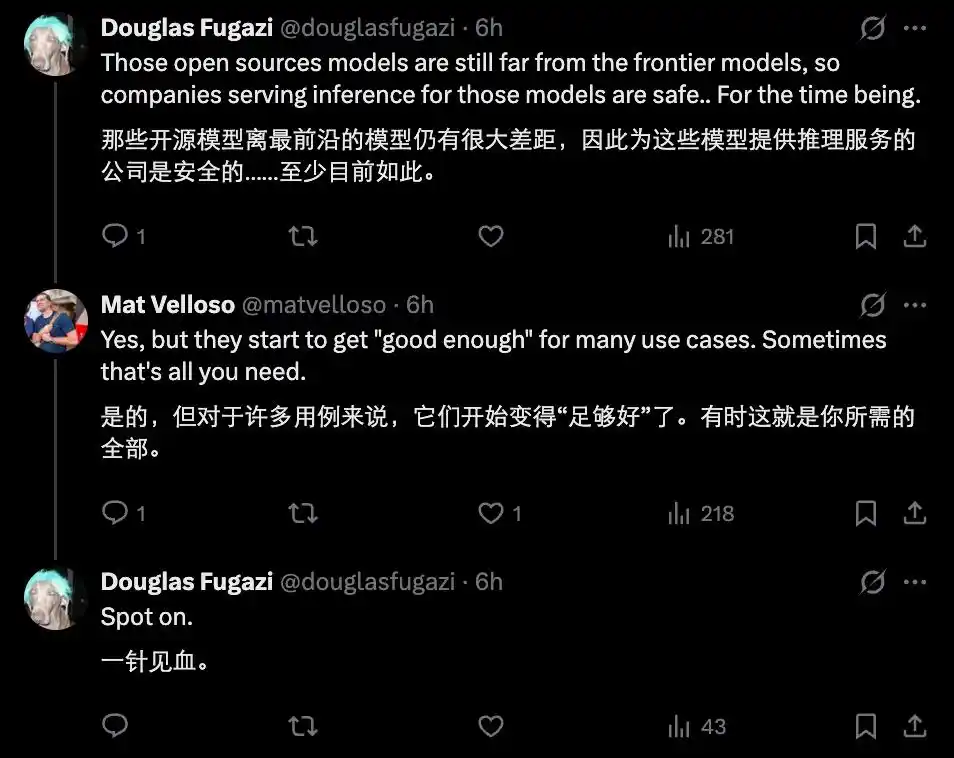
Pero la tendencia futura es clara. A corto plazo, los modelos cerrados en la nube aún lideran en el razonamiento complejo más avanzado y la colaboración a超大规模超大规模 (gran escala) multiagente; pero a largo plazo, a medida que el hardware continúa avanzando y las técnicas de cuantización continúan optimizándose, los modelos en el edge erosionarán gradualmente las tareas simples y de alta frecuencia de la nube.
Aquellos fabricantes que solo dependen de vender tokens, vender suscripciones API, se verán obligados a competir más ferozmente en las partes "realmente difíciles" — Agentes súper potentes, contextos largos y confiables, y capacidades especializadas que requieren cantidades masivas de datos en tiempo real.
Gemma 4 es solo el comienzo. La siguiente sorpresa podría ser que algún modelo en el edge haga que los usuarios no perciban la diferencia entre "local" y "en la nube" en el uso diario. Cuando llegue ese día, todo el modelo comercial de la industria de la IA experimentará una verdadera reestructuración.
Este artículo proviene del WeChat público "Machine Heart" (ID: almosthuman2014), autor: Machine Heart






