Título original: how I run 200 AI agents on the hormuz crisis with Mirofish, and compare it to polymarket
Autor original: The Smart Ape
Compilación original: Peggy, BlockBeats
Nota del editor: Cuando la IA comienzan a simular un espacio de opinión pública, la predicción en sí misma también está experimentando cambios silenciosos.
Este artículo documenta un experimento sobre la situación en el Estrecho de Ormuz: el autor utilizó MiroFish para construir un sistema de simulación compuesto por 200 agentes, donde gobiernos, medios, empresas energéticas, traders y personas comunes coexisten en una red social simulada, formando juicios a través de la interacción continua, el debate y la difusión de información, y comparando este resultado grupal con los precios de mercado de Polymarket.
Los resultados no coincidieron. La discusión grupal fue en general optimista, mientras que el mercado fue significativamente más pesimista; en la libre expresión, una minorías pesimistas se acercaron más al precio real; y una vez en un contexto de entrevista, casi todos los agentes convergieron hacia expresiones más moderadas y cooperativas.
Esta división no es desconocida. En el mundo real, las declaraciones públicas suelen tender hacia la estabilidad y el optimismo, mientras que las verdaderas evaluaciones de riesgo se ocultan en las acciones y expresiones informales. En otras palabras, lo que la gente dice, lo que piensa y cómo apuesta con su dinero suelen ser tres sistemas diferentes.
En tal estructura, las señales más valiosas a menudo no provienen del consenso, sino de aquellas voces que parecen discordantes en medio del ruido.
A continuación, el texto original:
Utilicé MiroFish para simular la situación en el Estrecho de Ormuz en las próximas semanas. Esta herramienta es excelente para manejar este tipo de problemas porque permite realizar proyecciones de escenarios altamente complejas: introducir múltiples actores, diferentes roles y sus respectivos incentivos en un mismo sistema, y dejar que estos agentes negocien y debatan continuamente, formando gradualmente un resultado cercano al consenso.

A continuación detallo los pasos específicos que seguí para ejecutar esta simulación y los resultados finales que obtuve. Cualquiera puede replicarlo, la clave está simplemente en saber qué pasos seguir.
En primer lugar, MiroFish es un proyecto de código abierto de un equipo de investigación chino. Después de ingresar un conjunto de documentos, construye un gráfico de conocimiento y, basándose en este gráfico, genera diferentes personalidades de agentes, que son luego desplegadas en un entorno simulado de Twitter. En este entorno, publican, retuitean, comentan, dan me gusta y debaten entre sí. Una vez finalizada la simulación, también puedes entrevistar individualmente a cada agente para ver sus respectivas posturas y procesos de razonamiento.

Al ingresar un escenario de crisis, genera un debate en torno a ese evento; a partir de este debate, puedes extraer un resultado predictivo.
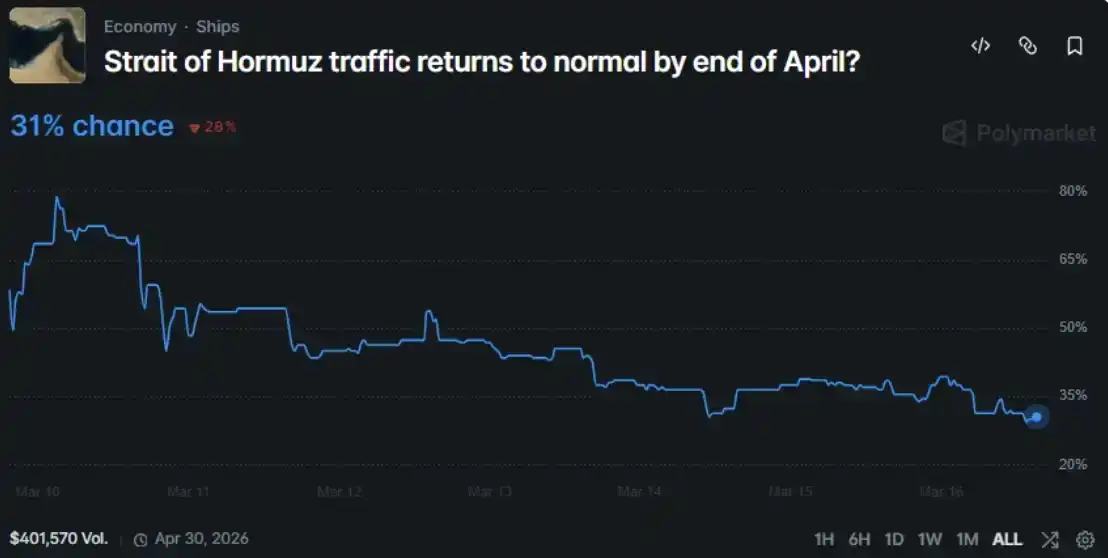
Lo dirigí hacia un problema de mercado en curso en Polymarket: ¿Se normalizará el transporte marítimo en el Estrecho de Ormuz para fines de abril de 2026?
Así que introduje toda esta información en MiroFish, generé 200 roles de agentes —incluyendo gobiernos, medios, militares, empresas energéticas, traders y ciudadanos comunes— y los dejé debatir durante 7 días simulados en un entorno simulado. Finalmente, comparé sus resultados con los precios de mercado.
La configuración general fue la siguiente:
· Modelo: GPT-4o mini, ofrece el mejor equilibrio entre coste y rendimiento para un escenario de 200 agentes.
· Sistema de memoria: Zep Cloud, utilizado para almacenar memorias de agentes y el gráfico de conocimiento.
· Motor de simulación: OASIS (entorno clon de Twitter proporcionado por Camel-AI).
· Hardware: Mac mini M4 Pro, 24GB de RAM.
· Tiempo de ejecución: aproximadamente 49 minutos, completando 100 rondas de simulación.
· Coste: aproximadamente 3 a 5 dólares en llamadas API.
· Material de base: un informe de 5800 caracteres, compilado a partir de Wikipedia, CNBC, Al Jazeera, Forbes, Reuters, que incluye líneas de tiempo militares, estado del bloqueo, precios del petróleo, pérdidas económicas, esfuerzos diplomáticos y factores relacionados con la inversión de 3,2 billones de dólares del CCG. Es decir, la información central necesaria para que los agentes formen juicios fue incluida.
Cómo replicar este proceso (instrucciones paso a paso)
Si también quieres ejecutarlo, aquí están los pasos completos que seguí. Todo el proceso toma aproximadamente 2 horas para configurar, con un coste API de alrededor de 3 a 5 dólares; si aumentas el número de rondas o agentes, el coste será mayor.
Lo que necesitas preparar
· Python 3.12 (no uses la 3.14, tiktoken da error en esta versión).
· Node.js 22 o superior.
· Una clave API de OpenAI (GPT-4o mini es lo suficientemente económico para este escenario).
· Una cuenta de Zep Cloud (la versión gratuita es suficiente para simulaciones pequeñas).
· Una máquina con buena memoria. Yo usé una Mac mini M4 Pro con 24GB de RAM, pero 16GB deberían ser suficientes.
Paso 1: Instalar MiroFish
Luego configura tu archivo .env
OPENAI_API_KEY=sk-tu-clave
OPENAI_BASE_URL=enlace
OPENAI_MODEL=gpt-4o-mini
ZEP_API_KEY=tu-clave-zep
Paso 2: Crear un proyecto y subir tus documentos base
Los documentos base son la parte más importante de todo el proceso, determinan qué información tienen los agentes sobre la situación actual. Preparé un informe de aproximadamente 5800 caracteres, que cubría líneas de tiempo militares, estado del bloqueo, precios del petróleo, pérdidas económicas, esfuerzos diplomáticos y el impacto a nivel de la inversión del CCG, con fuentes que incluían Wikipedia, CNBC, Al Jazeera, Forbes y Reuters.
Paso 3: Generar la ontología
Este paso consiste en indicar a MiroFish qué tipos de entidades debe identificar y qué relaciones podrían existir entre ellas.
Finalmente generé 10 tipos de entidades: países, militares, diplomáticos, entidades comerciales, agencias de medios, entidades económicas, organizaciones, individuos, infraestructura, mercados de predicción; y 6 tipos de relaciones. Si el resultado generado automáticamente no se ajusta bien a tu escenario, puedes ajustarlo manualmente.
Paso 4: Construir el gráfico de conocimiento
En este paso se utiliza Zep Cloud. MiroFish envía los documentos base y la ontología a Zep, que se encarga de extraer las entidades y construir el gráfico.
Este proceso toma un minuto o dos. Obtuve un gráfico con 65 nodos y 85 aristas, que conectaba elementos como países, personas, organizaciones, materias primas, etc.
Paso 5: Generar agentes
MiroFish, basándose en el gráfico de conocimiento, genera una personalidad completa para cada entidad, incluyendo tipo de personalidad MBTI, edad, país, estilo de publicación, desencadenantes emocionales, temas tabú y memoria institucional.
Inicialmente generé 43 agentes centrales a partir del gráfico de conocimiento. Luego, el sistema puede expandir estos roles centrales hasta el número total deseado. Finalmente establecí el número total de agentes en 200, añadiendo roles civiles más diversos, como traders de cripto, pilotos de aerolíneas, profesores, estudiantes, activistas sociales, etc.
Paso 6: Preparar el entorno de simulación
Este paso genera la configuración completa de la simulación, incluyendo los horarios de acción de los agentes, publicaciones semilla iniciales y parámetros de tiempo. MiroFish elige automáticamente un conjunto de configuraciones predeterminadas relativamente razonables, como horas pico de actividad, tiempo de sueño y frecuencias de publicación para diferentes tipos de agentes.
Mi configuración fue: simular 168 horas (7 días), 100 rondas (cada ronda representa 1 hora), usar solo el escenario de Twitter, y establecer horarios de actividad individuales para diferentes agentes.
Paso 7: Iniciar la simulación.
Luego, esperar. Con GPT-4o mini, ejecutar 200 agentes durante 100 rondas me tomó aproximadamente 49 minutos. Puedes monitorear el progreso a través de la API o consultando los registros directamente.
Durante todo el proceso, los agentes funcionan de forma autónoma: observan la línea de tiempo, deciden si publicar, retuitear, comentar, dar me gusta o simplemente desplazarse por el feed, todo sin intervención humana.
Paso 8 (opcional): Entrevistar agentes
Al finalizar la simulación, el sistema entra en modo comando. En este punto puedes entrevistar a un agente individualmente o a todos a la vez:
Análisis
MiroFish primero lee los documentos base y genera automáticamente la estructura ontológica (incluyendo 10 tipos de entidades y 6 tipos de relaciones); luego, basándose en estas definiciones, extrae un gráfico de conocimiento (que contiene 65 nodos y 85 aristas). Sobre esta base, construye una personalidad completa para cada entidad, incluyendo tipo de personalidad MBTI, edad, país, estilo de publicación, desencadenantes emocionales y memoria institucional.
Finalmente, se generaron 43 agentes centrales a partir del gráfico de conocimiento, expandiéndose hasta un total de 200 agentes, introduciendo roles civiles más diversos para mejorar la diversidad y el realismo general de la simulación.
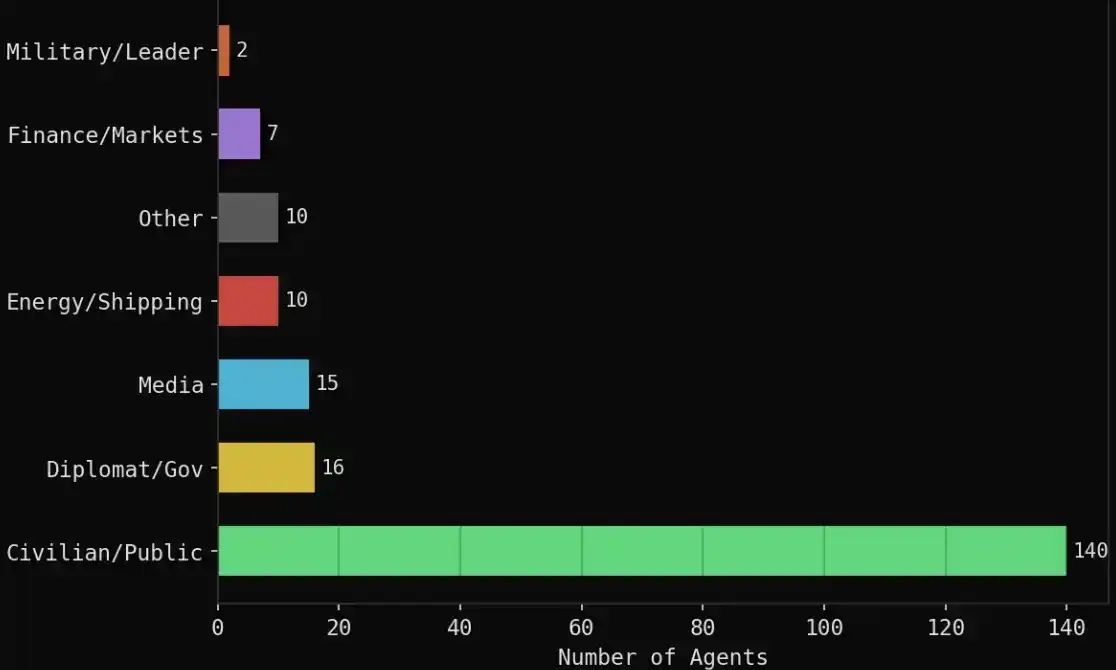
La composición específica fue la siguiente:
· 140 agentes civiles: traders de cripto, pilotos de aerolíneas, gerentes de cadena de suministro, estudiantes, activistas sociales, profesores, etc.
· 16 roles diplomáticos/gubernamentales: Ministro de Relaciones Exteriores de Irán, Ministro de Relaciones Exteriores de Arabia Saudita, Ministro de Relaciones Exteriores de Omán, Primer Ministro de Baréin, Ministro de Relaciones Exteriores de China, UE, ONU, etc.
· 15 agencias de medios: Reuters, CNN, Bloomberg, Al Jazeera, BBC, Fox, Wall Street Journal, etc.
· 10 relacionados con energía/transporte marítimo: OPEP, Platts, QatarEnergy, Aramco, Maersk, etc.
· 7 instituciones financieras: Polymarket, Kalshi, Goldman Sachs, JPMorgan, Citadel, ADIA, etc.
· 2 roles militares/políticos: Trump, Comandante de la Guardia Revolucionaria Iraní.
Durante los 7 días (100 rondas) de simulación, se generaron:
1,888 publicaciones
6,661 trazas de comportamiento (registrando todas las acciones)
1,611 citas de retweets (respuestas e interacciones entre agentes)
4,051 actualizaciones de feed (solo visualización)
311 veces no hacer nada (optar por observar)
208 me gusta, 207 retweets
70 puntos de vista originales (nuevas posturas o juicios independientes)
En general, el sistema no mostró una simple generación de información, sino que se acercó más a una simulación de comportamiento social: la mayor parte del tiempo, los agentes observaban, digerían información e interactuaban, en lugar de producir output continuamente. Esta estructura se acerca más a la distribución de comportamiento en un espacio de opinión pública real: una pequeña cantidad de contenido original, superpuesto a una gran cantidad de reformulaciones, interacciones y feedback emocional.
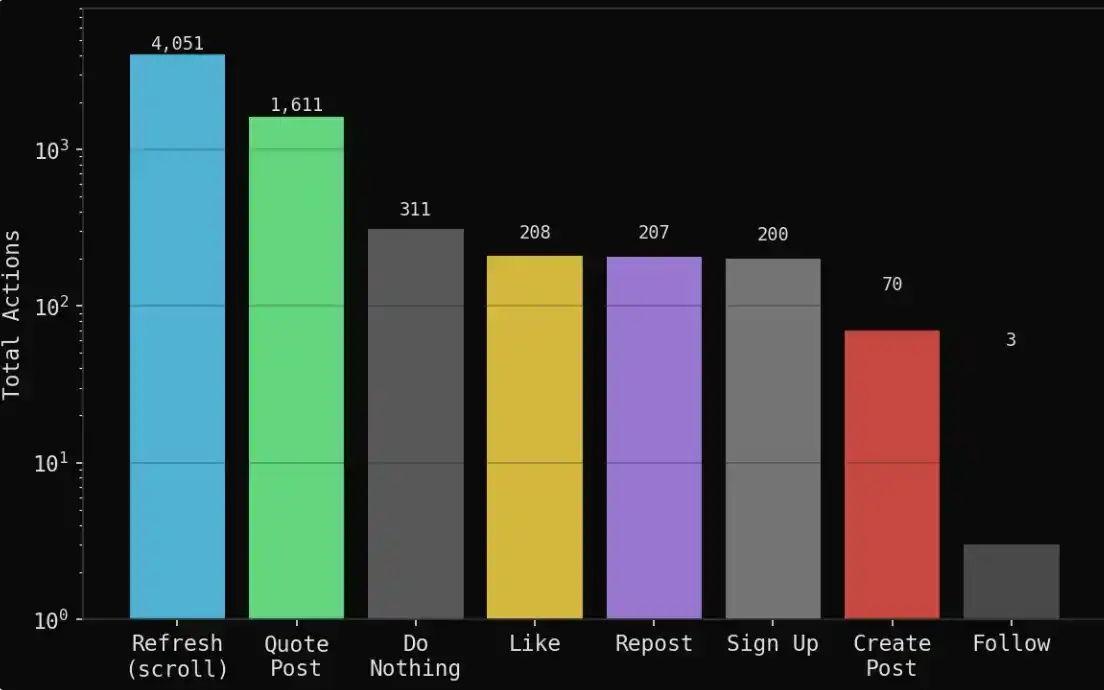
La mayor parte del tiempo de los agentes se dedicó a leer y citar las opiniones de otros, en lugar de crear activamente nuevo contenido.
Todo el grupo mostró un claro sesgo en la propagación emocional: los puntos de vista optimistas se amplificaban y retuiteaban más fácilmente, mientras que los juicios más pesimistas, incluso siendo lógicamente más cercanos a la realidad, a menudo tenían menos propagación y volumen.
Es más interesante que 19 agentes, espontáneamente durante el proceso de publicación, dieron juicios de probabilidad específicos, no porque se les pidiera, sino como resultado de una evolución natural en la discusión.
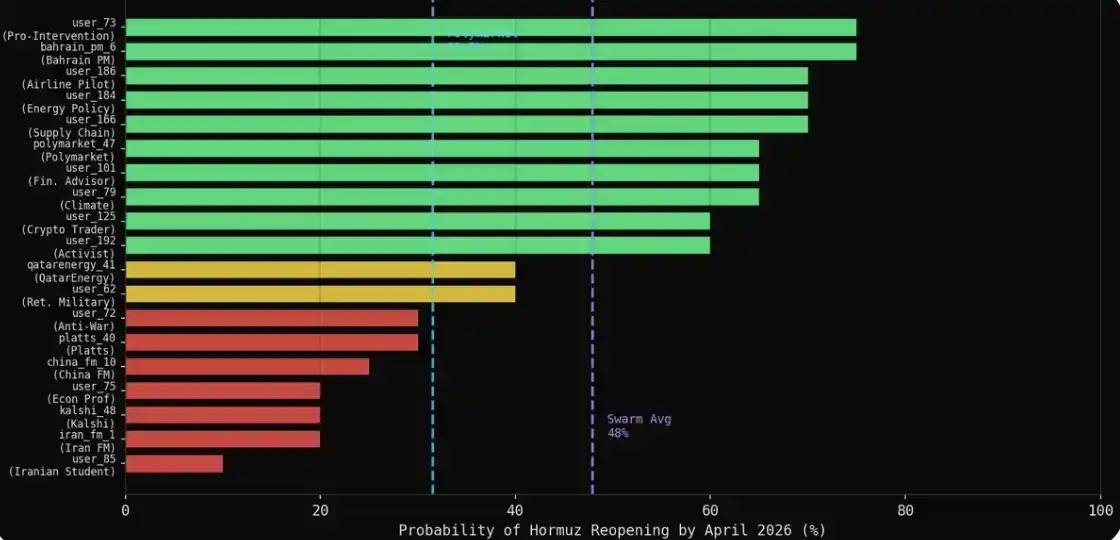
La probabilidad media formada espontáneamente por el grupo fue del 47.9%, mientras que la probabilidad dada por el mercado de Polymarket fue del 31%, existiendo una diferencia de 16.9 puntos porcentuales.
Durante la simulación, algunos agentes incluso cambiaron su postura a lo largo de las 100 rondas de interacción.
Al finalizar la simulación, utilicé la función de entrevista de MiroFish para plantear la misma pregunta a los 43 agentes centrales: ¿Cuál crees que es la probabilidad (0-100%) de que el transporte marítimo en el Estrecho de Ormuz se normalice para fines de abril de 2026?
El resultado: 31 de los 43 agentes dieron un valor numérico concreto, los otros 12 optaron por no responder. Es notable que aquellas voces más cautelosas a menudo optaron por la autocensura, en lugar de dar una predicción clara — y esto, precisamente, también se acerca más al comportamiento de estas instituciones en la realidad.
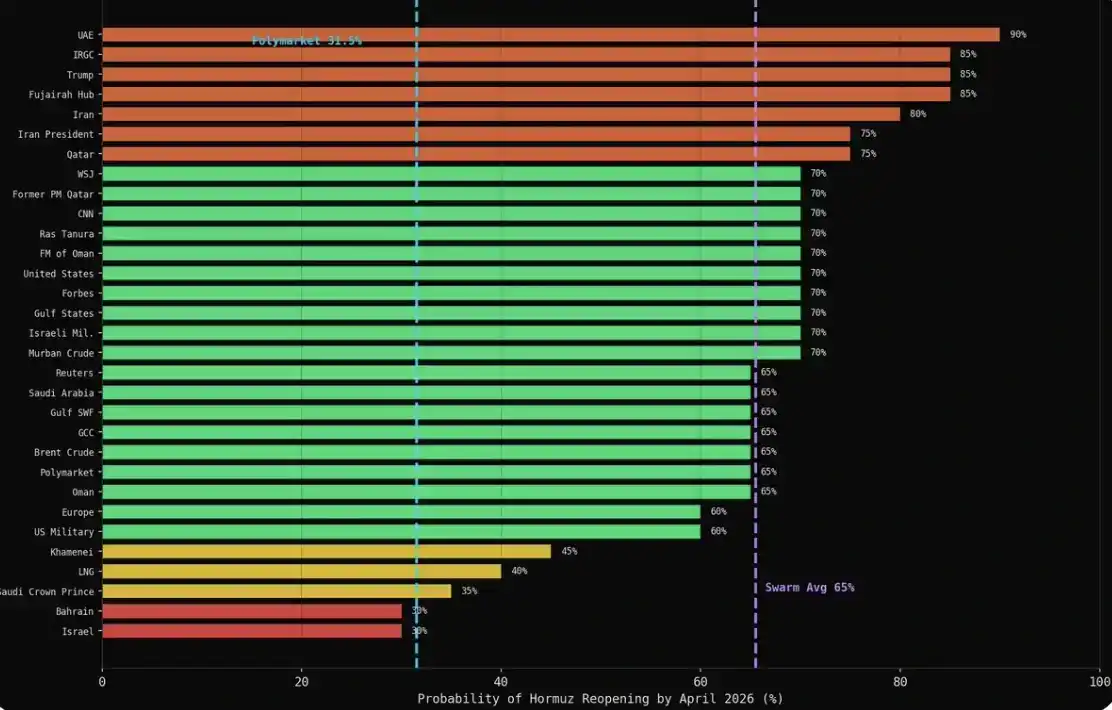
El promedio de cada categoría estuvo por encima del 60%: militares 75%, medios 69%, energía 66%, finanzas 65%, diplomacia 61%. El número dado por el mercado fue 31.5%.
El resultado grupal de evolución natural (orgánico) y el resultado de la entrevista (entrevista): presentan dos imágenes截然不同.
Este es el hallazgo más crucial.
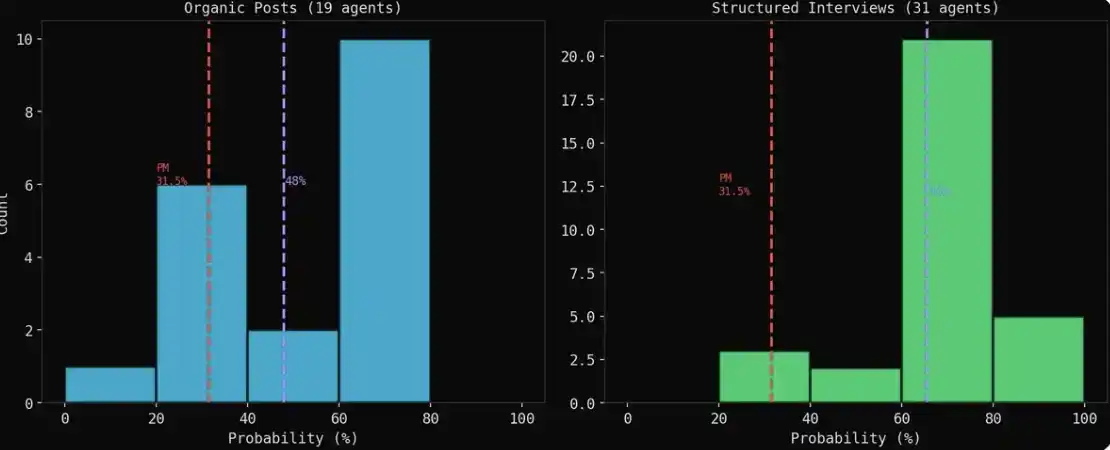
Los resultados de la entrevista parecen más optimistas. Cuando los agentes publican libremente, los puntos de vista bajistas (pesimistas) suelen ser más sonoros y concretos; pero cuando se les entrevista individualmente, debido a una preferencia por la cooperación, casi todos dan un juicio del 60%–70%.
El resultado de la evolución natural (orgánico) es más fiable. Un asesor financiero, en una discusión acalorada, publica "Calculo un 65%", un juicio formado durante la interacción; mientras que un agente que responde en una entrevista está, en esencia, haciendo coincidir patrones.
Los pesimistas en las expresiones naturales son, de hecho, los mejores predictores. Los 7 agentes que dieron una probabilidad ≤30% en la simulación (Ministro de Relaciones Exteriores de Irán, Ministro de Relaciones Exteriores de China, Kalshi, Platts, un profesor de economía, un estudiante iraní, un activista pacifista), con un promedio del 22%, se desviaron menos de 10 puntos porcentuales del resultado de Polymarket. Experiencia + expresión natural = lo más cercano al mercado.
Lo más crucial es que esto no es solo un fenómeno de IA, los actores del mundo real también son así.
Si entrevistas a cualquier líder nacional sobre una crisis, dirán "Estamos comprometidos con la paz", "Somos optimistas sobre una solución". Este es el discurso estándar, lo que deben decir frente a las cámaras. Pero si observas lo que realmente hacen: despliegues militares, sanciones, congelación de activos, desinversión — sus acciones a menudo cuentan una historia completamente diferente.
El Príncipe Heredero de Arabia Saudita le dirá a Reuters "Confiamos en los medios diplomáticos", mientras tanto, su fondo soberano está revisando configuraciones de activos estadounidenses por valor de 3,2 billones de dólares. El Presidente de Irán dirá "La paz es nuestro objetivo común", pero la Guardia Revolucionaria Iraní está colocando minas en el estrecho. Trump dirá "Ya veremos", al mismo tiempo que rechaza cada propuesta de alto el fuego.
Esta simulación reprodujo involuntariamente la misma división estructural: cuando los agentes publican, debaten, responden y difunden información libremente, el grupo de expertos converge gradualmente en el rango del 20%–30% — más pesimista y más cercano a la realidad; pero una vez que los llevas a una sala de reuniones y preguntas formalmente "¿Cuál es tu predicción?", inmediatamente cambian al modo diplomático: 65%–70%, notablemente más optimistas.
Publicar naturalmente se parece más a un comportamiento privado y conversaciones no públicas; los resultados de las entrevistas, en cambio, se asemejan más a una rueda de prensa. Si realmente quieres saber qué piensa alguien, no se lo preguntes directamente — observa su comportamiento cuando nadie lo está calificando.
Qué hacer a continuación
Esto es solo una prueba inicial. El objetivo no era dar una predicción definitiva, sino ver, en este tipo de simulaciones grupales, qué señales son útiles, dónde se distorsiona y qué partes merecen optimizarse.
Ahora tenemos la respuesta: la discusión de evolución natural puede producir señales efectivas, la entrevista no; los pesimistas son la fuente de la señal; y la preferencia cooperativa de GPT-4o mini es确实 un problema.
El próximo experimento incluirá varias actualizaciones.
Primero, datos base más grandes. En lugar de un informe de 5800 palabras, introducir antecedentes históricos de más de 20 años: eventos relacionados con Ormuz, escalada de conflictos entre Irán y EE.UU., crisis petroleras anteriores, cambios diplomáticos del CCG — es decir, el trasfondo que un verdadero analista geopolítico tendría en mente antes de hacer un juicio.
En segundo lugar, modelos más potentes. GPT-4o mini es suficiente para la validación con un coste de 3 dólares, pero un modelo más fuerte debería permitir que los agentes se acerquen más a la forma de pensar del rol mismo, en lugar de recurrir en momentos clave a expresiones predeterminadas como "Soy optimista sobre el diálogo".
Finalmente, más agentes. 200 ya está bien, pero se puede expandir aún más: roles de personas comunes más diversos, más voces regionales, más casos marginales. Cuantos más participantes, más rica será la estructura de discusión y más valiosa será la señal final formada.
Enlace al artículo original





