Autor: Wang Bo, Jiaziguangnian
"Jiaziguangnian" se enteró por fuentes cercanas a DeepSeek que, internamente, DeepSeek está organizando un nuevo equipo llamado Harness, con el enfoque en productos de agente de código, y competirá internamente con Claude Code de Anthropic.
Chen Deli, investigador senior de DeepSeek, también confirmó esto recientemente en las redes sociales, diciendo: "DeepSeek está organizando un nuevo equipo Harness para trabajar en productos e investigación en la dirección de Harness", y afirmó claramente: "En términos simples, es competir con Claude Code, hacer DeepSeek Code Harness".
Esto no es una contratación ordinaria.
La información de contratación muestra que DeepSeek ha abierto dos puestos clave esta vez: Gerente de Producto de Harness e Ingeniero de Desarrollo de Harness, y la ubicación del trabajo está actualmente limitada a Pekín. La oficina de DeepSeek en Pekín se encuentra en el Centro de Información Rongke, en el distrito de Haidian, muy cerca de la Universidad de Pekín y la Universidad de Tsinghua. En la versión oficial, se encuentra en la "Franja de Innovación AI del Centenario de Jingzhang", y en la versión popular, también se encuentra en el área de "Wang Huiwen", que está muy de moda recientemente.


Definición central: Modelo + Harness = Agente
En la descripción del puesto, una fórmula central se coloca en la posición más destacada:
Esta frase casi puede considerarse como la definición interna de DeepSeek para la ruta de producto de la próxima etapa: el modelo en sí es solo la base del Agente; la gestión del contexto, la invocación de herramientas, la planificación de tareas, la lectura y escritura de archivos, la modificación de código, la ejecución de terminal, la recolección de retroalimentación y el ciclo de evaluación fuera del modelo son las partes clave que permiten que el Agente realmente se integre en el flujo de trabajo.
La información de contratación añade: "Estamos transformando las capacidades de modelo de vanguardia de DeepSeek en productos líderes de Agente. Todos los trabajos, aparte del modelo en sí, pertenecen al ámbito de Harness." Además, este puesto participará en todo el proceso del "producto Agente de escritorio de DeepSeek" y "definirá la comprensión de DeepSeek sobre Harness".
"Jiaziguangnian" analiza que DeepSeek no solo quiere hacer un simple complemento de asistente de código, sino que está completando la capa intermedia que conecta el modelo con el flujo de trabajo real.
El año pasado, la industria ha demostrado: tener una fuerte capacidad de codificación no significa que los desarrolladores realmente la usen; que un modelo pueda escribir código no significa que pueda completar continuamente una tarea de ingeniería.
Lo que realmente cambia la forma de trabajar de los desarrolladores no es solo el modelo Claude, sino Claude Code; no es solo el modelo GPT, sino Codex; no es una respuesta de código en un cuadro de chat, sino un agente de ingeniería que puede entrar en la terminal, entender el proyecto, leer y escribir archivos, ejecutar comandos, corregir errores, gestionar Git e invocar herramientas.
Lo más fuerte de DeepSeek en el pasado era el modelo. Ahora, está comenzando a complementar las "manos" sobre ese modelo.
I. ¿Por qué DeepSeek enfatiza Harness?
En el contexto tradicional de productos de IA, "asistente de código" generalmente se refiere a dos tipos de productos: uno son complementos de autocompletado en el IDE, y el otro son preguntas y respuestas de código en un cuadro de chat.
Pero la palabra que aparece repetidamente en esta contratación de DeepSeek no es "Asistente de Código", sino Harness.
Harness originalmente en el contexto de ingeniería se refiere a "arnés de prueba" o "marco de ejecución". En el contexto de Agentes, se acerca más a un sistema externo que permite que el modelo realmente actúe. El modelo es responsable de la comprensión, el razonamiento y la generación; Harness es responsable de integrar estas capacidades en el entorno real.
La descripción del puesto menciona que este rol necesita planificar la hoja de ruta del producto DeepSeek Harness, conectar investigadores, ingenieros, la comunidad de código abierto y los usuarios finales, y comunicarse en profundidad con los investigadores del equipo de entrenamiento de modelos para lograr la evolución conjunta del modelo y el Harness.
Esta frase es clave.
Indica que lo que DeepSeek quiere hacer no es solo envolver el modelo existente en una capa, sino convertir el producto Agente en parte de la evolución del modelo. En el pasado, la lógica común de producto en las empresas de grandes modelos era: primero el equipo de investigación entrena un modelo, luego el equipo de producto desarrolla aplicaciones basadas en las capacidades del modelo. Pero en la era de los Agentes, este orden está cambiando. El producto ya no es solo la salida de las capacidades del modelo, sino el campo de entrenamiento de las capacidades del modelo.
Que un Agente de código falle en un proyecto real puede deberse no a un problema de interacción del producto, sino a que la forma en que el modelo comprime el contexto largo es incorrecta; puede no ser un problema de la cadena de invocación de herramientas, sino a que la estrategia del modelo para descomponer tareas es inestable; o puede que no sea una falta de capacidad de código, sino que le falta una comprensión continua de las restricciones de ingeniería, la retroalimentación de las pruebas y la intención del usuario.
Por lo tanto, el valor del equipo Harness no es solo "hacer un producto", sino convertir las tareas reales de desarrollo en una fuente de retroalimentación para la evolución continua del modelo.
II. ¿Por qué DeepSeek debe complementar Code Harness?
DeepSeek apostó por la capacidad de código desde muy temprano. Desde DeepSeek-Coder hasta DeepSeek-Coder-V2, la inversión de DeepSeek en modelos de código ha aumentado continuamente, mejorando el soporte de lenguajes, la longitud del contexto y la capacidad para tareas complejas. Su problema no es la falta de capacidad de código, sino que en el pasado esta capacidad se quedó más en la capa del modelo y aún no se ha convertido en un producto de alta frecuencia en el flujo de trabajo diario de los desarrolladores.
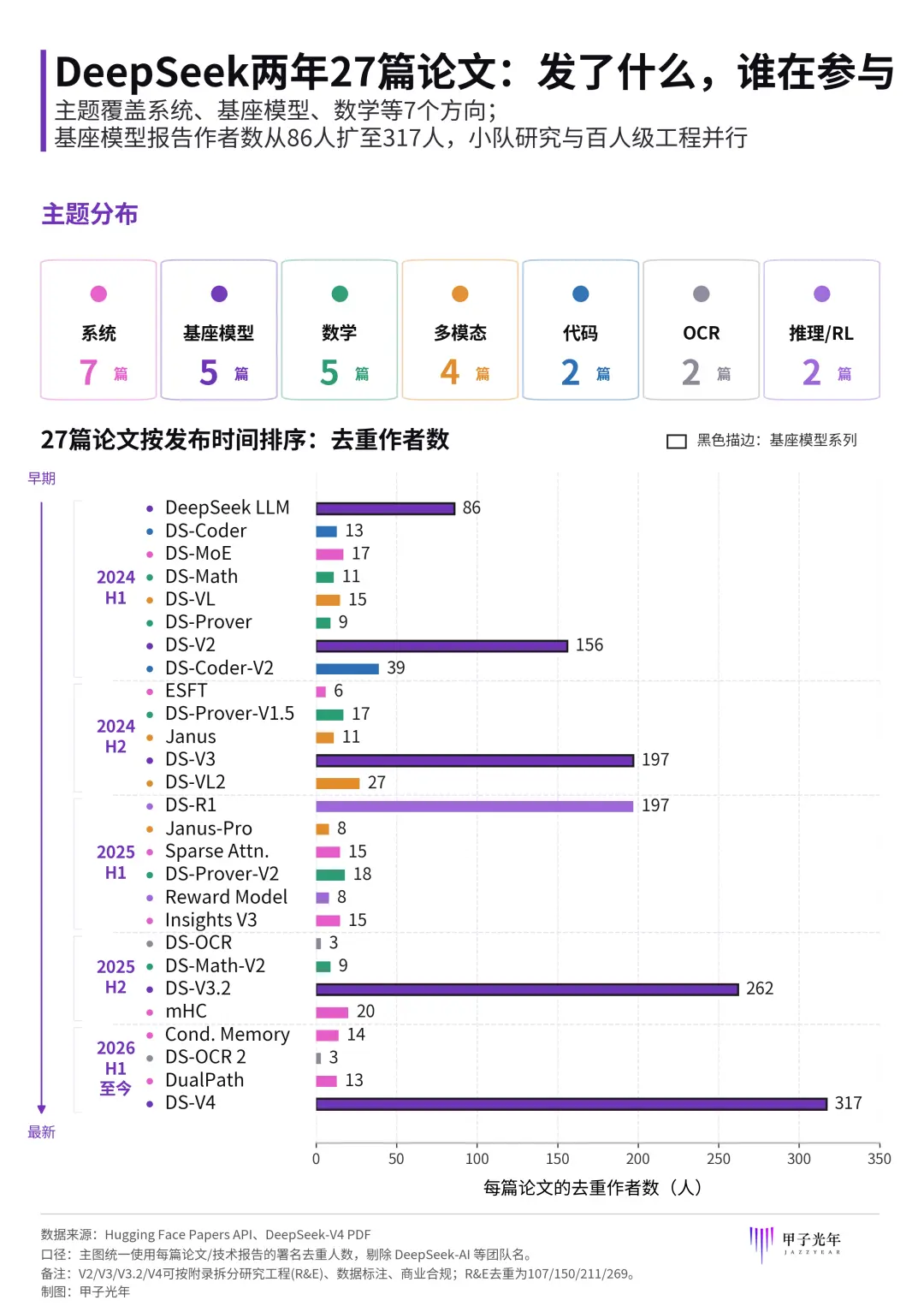
La popularidad de Claude Code demuestra una cosa: La competencia en IA de codificación está pasando de una competencia de capacidad de modelo a una competencia por la entrada al flujo de trabajo del desarrollador.
Esta es también una lección que DeepSeek debe complementar ahora. Más sutilmente, antes de que DeepSeek oficialmente tomara medidas, la comunidad de desarrolladores ya había creado una versión de "Claude Code basado en DeepSeek".
Un proyecto de código abierto llamado DeepSeek-TUI se hizo popular anteriormente en la comunidad de desarrolladores. Es un agente de codificación que se ejecuta en la terminal, puede leer y escribir archivos, ejecutar comandos Shell, buscar en la web, gestionar Git y coordinar sub-agentes a través de una interfaz TUI.
La popularidad de DeepSeek-TUI ilustra dos problemas:
-
Madurez de la mentalidad base: El modelo DeepSeek ya tiene la base para ser un Agente de código en la mentalidad de los desarrolladores. De lo contrario, la comunidad no generaría naturalmente un producto estilo Claude Code alrededor de él.
-
Falta a nivel oficial: A DeepSeek no le falta atención al modelo, le falta Harness oficial.
Para los desarrolladores, el atractivo de DeepSeek-TUI es directo: bajo costo, disponible en China, contexto largo y umbral de despliegue relativamente bajo. Muchos desarrolladores en China no es que no quieran usar Claude Code, sino que están limitados por el precio, la estabilidad del acceso, el sistema de cuentas y el cumplimiento empresarial.
Pero los proyectos comunitarios también tienen límites naturales:
-
Por muy activo que sea un proyecto de código abierto de terceros, es difícil que realmente controle el ritmo de evolución de las capacidades internas del modelo;
-
Puede adaptarse alrededor de la API, pero no puede decidir inversamente cómo se entrena el modelo;
-
Puede optimizar prompts, cadenas de herramientas e interacciones, pero es difícil inyectar sistemáticamente la retroalimentación de una gran cantidad de tareas reales en la mejora del modelo.
Aquí es precisamente donde reside el significado del Harness oficial.
DeepSeek desarrollando su propio Code Harness tiene varias ventajas que los proyectos comunitarios no poseen: colaboración con el equipo de modelos, derecho de diseño de interfaces, ciclo cerrado de datos de entrenamiento, escenarios de tareas reales internas y capacidad de operación a largo plazo del ecosistema de desarrolladores.
La comunidad de código abierto ya ha allanado el camino primero: los desarrolladores realmente necesitan una versión de DeepSeek de Claude Code. Ahora, DeepSeek quiere recuperar ese camino y convertirlo en su propio producto principal.
Y el hecho de que DeepSeek oficialmente comience a contratar personal significa que finalmente está preparado para tomar medidas directas.
Chen Deli mencionó en noviembre pasado en la Cumbre Mundial de Internet de Wuzhen 2025: "Una de las ventajas centrales de nuestra empresa es el largo plazo, insistir en esta línea principal de avances de inteligencia de vanguardia. Y en este proceso, también hemos renunciado a muchas cosas en líneas secundarias, no hacemos esas cosas rápidas y superficiales en las líneas secundarias."
Después de la guerra de modelos, comienza la verdadera guerra de Agentes. Esta vez, lo que DeepSeek quiere complementar es la capa más crítica entre el modelo y la acción: Harness.
DeepSeek está poniéndole un par de manos a su modelo.





