Autor: Friday, TechFlow de Shenchao
Anthropic acaba de presentar un informe impecable en papel.
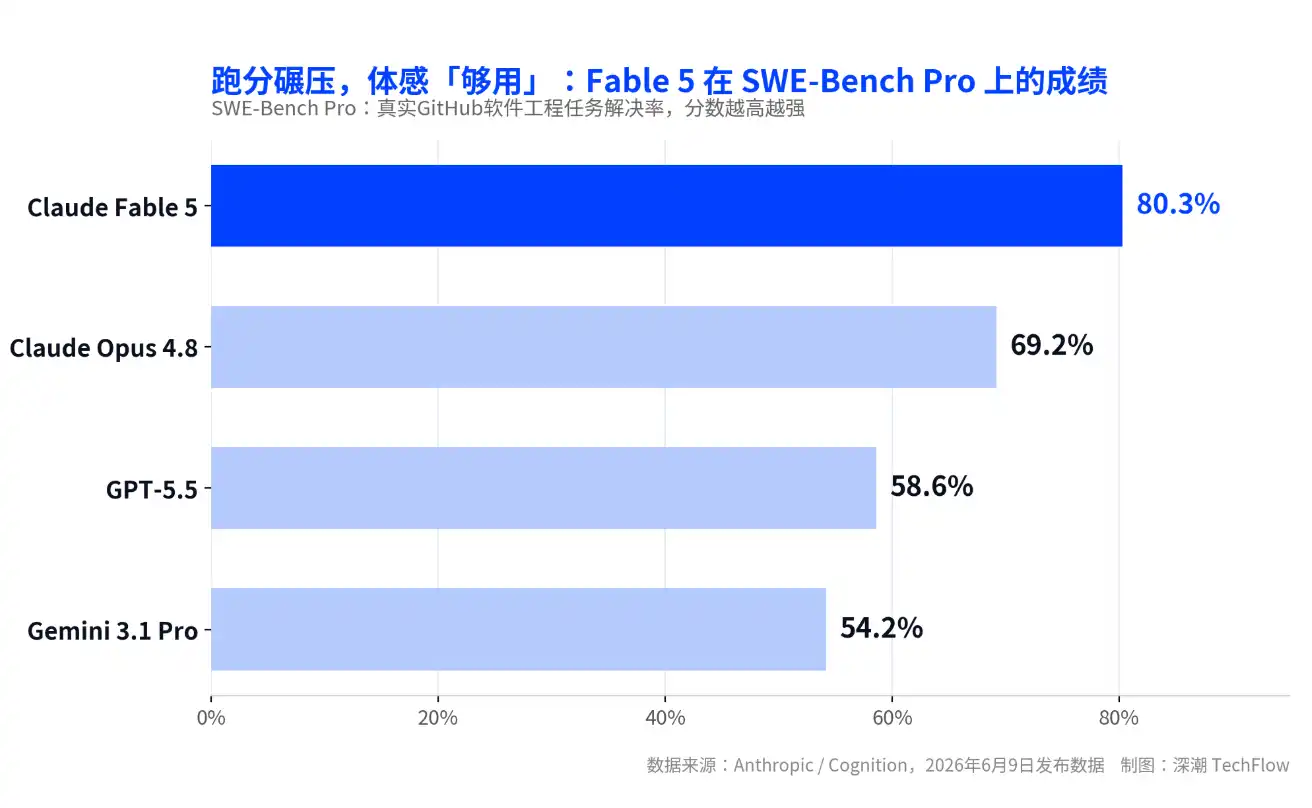
Claude Fable 5, lanzado el 9 de junio, es el primer modelo de nivel Mythos de la empresa abierto al público, logrando un 80.3% en el benchmark SWE-Bench Pro para tareas reales de ingeniería de software, superando a su propio modelo insignia anterior, Opus 4.8, en unos 11 puntos porcentuales y aventajando a GPT-5.5 en más de 20 puntos.
Pero la reacción de los usuarios fue un balde de agua fría.
Tres días después del lanzamiento, el título de un popular post en el subreddit r/artificial (con 305,000 visitas semanales) decía: "Claude Fable me hizo darme cuenta de que no necesito un modelo mejor." El usuario Axi0m-22 contó que usó Fable por un tiempo para investigación de seguridad y trabajo diario, y casi de inmediato volvió a Opus para escribir código y a Haiku para tareas menores. Puso un ejemplo: Es como tener un iPhone 14 y ver el lanzamiento del iPhone 17. "Sabes que el nuevo es mejor, pero piensas: bueno, el mío está bien."
La zona de más votos es tomada por los "suficientes": La fatiga de modelos se convierte en el sentimiento principal
El comentario con más votos, 42, dice: "Además de una ventana de contexto más grande, desde Opus 4.5 ya no sentí que necesitara modelos más potentes."
La declaración de otro usuario, hyprlab, obtuvo 13 votos: "Cambiar a un modelo que quema tokens más rápido no veo beneficio para mi flujo de trabajo, el modo intensivo de Opus 4.8 ya es suficientemente cómodo."
Detrás de este tipo de comentarios hay un cálculo de costos común.
El precio API de Fable 5 es de 10 dólares por millón de tokens de entrada, casi el doble que Opus 4.8. El usuario siromega37 lo dijo sin rodeos: "Mayor consumo de tokens, pero sin retorno de inversión. Creo que estamos viendo una meseta, la burbuja finalmente estallará."
El usuario hobopwnzor ofrece una interpretación más sistemática: "Ya hemos estado en la cima de la curva S por un tiempo. Los avances recientes provienen principalmente de herramientas periféricas y de ingeniería, no de la capacidad del modelo en sí."
Las restricciones de seguridad son la mayor queja: "El 90% de los usos son directamente rechazados"
Si "suficiente" es solo un sentimiento, las quejas sobre las restricciones de seguridad son un problema de producto concreto.
Según la explicación oficial de Anthropic, Fable 5 comparte el modelo base con Mythos 5, que solo está disponible para unas pocas instituciones, la diferencia es que Fable tiene un clasificador de seguridad incorporado: las solicitudes en áreas de alto riesgo como ciberseguridad son interceptadas y respondidas por Opus 4.8. La empresa afirma que este mecanismo está ajustado de manera conservadora, se activa en menos del 5% de las sesiones en promedio y puede bloquear solicitudes inocuas.
En este post de Reddit, la percepción de la tasa de activación parece mucho mayor al 5%. El usuario jradoff, con 17 votos, dijo que le pidió a Fable que revisara la seguridad de su código y el resultado fue que "básicamente rechazó procesar cualquier cosa relacionada con seguridad" y luego fue derivado a Opus. Otro comentario con 12 votos es más duro: "El 90% de lo que quieres que haga es rechazado, es inútil."
Los usuarios de pago están más molestos. El usuario kaitava, suscrito al plan de 200 dólares, escribió: "Estoy pagando el doble por el uso, quiero que haga una revisión de seguridad y es degradado a Opus. Ahora no me gusta nada de él, solo espero a que OpenAI lo alcance."
Para un producto insignia que promete un salto de capacidad, "el precio en usabilidad pagado por la seguridad" se está convirtiendo en una variable clave para que los usuarios decidan si pagar o no.
Voces en contra: La percepción de usuarios con tareas intensivas es "noche y día"
El post no carece de oponentes, y el perfil de los contrarios es bastante claro: cuanto más pesada la tarea, más alta la evaluación.
El comentario del usuario Phylaras obtuvo 15 votos: "Fable hizo una diferencia real para mí. En esas tareas complejas que requieren una ventana de contexto enorme, encontró errores que no se habían detectado antes." Un usuario que dice trabajar en simulaciones de física de altas energías comentó que un solo modelo de simulación tiene fácilmente de 8,000 a 10,000 líneas de código, con cientos de modelos interactuando: "Tener un modelo que pueda trabajar de forma continua e independiente, entendiendo los detalles del entorno, es algo que espero con ansias" .
La refutación más enérgica vino del usuario Navetz: "Honestamente, quienes han usado este modelo pensarán que este post es una locura. Para mí es claramente más inteligente, lo uso constantemente. Se lo explico a mis amigos no técnicos: esto es como pasar de un jugador universitario a un titular de la NBA directamente."
También hubo sugerencias de uso equilibrado. El usuario ready-eddy sugirió usar Fable como "planificador y reparador", no como "constructor" diario, a menos que no importe gastar dinero. Otro comentario lo resumió más como un manual de uso: usar Fable para cálculos de tablas es elegir el modelo equivocado, usar Haiku para ejecutar tareas complejas con 16 agentes también es elegir mal, "no hay modelos intrínsecamente malos, solo modelos usados en el escenario equivocado".
Después de que las puntuaciones y la percepción se desconectan, ¿la IA pública seguirá mejorando?
El comentario más interesante en este debate llevó el tema del producto hacia la estructura de la industria.
El usuario KedMcJenna propuso una "teoría de la congelación de la IA pública": los modelos a los que el público general tiene acceso podrían quedarse para siempre cerca del nivel actual, mientras que las élites empresariales y gubernamentales seguirán obteniendo modelos privados más fuertes. "Sabemos que al menos está Mythos, probablemente hay otros más fuertes de los que nunca oiremos hablar".
Este comentario apunta a un hecho: Mythos 5 no está abierto al público, actualmente solo está disponible a través del programa Project Glasswing para agencias de defensa de redes y empresas de infraestructura crítica.
Mirando las puntuaciones de referencia y la opinión pública juntas, las conclusiones no son contradictorias.
Los benchmarks miden el límite superior de capacidad, mientras que los comentarios más votados en Reddit reflejan el techo de las necesidades diarias. Cuando las tareas de la mayoría de los usuarios ya fueron satisfechas en la era de Opus 4.6, los modelos más fuertes solo pueden demostrar su valor en escenarios extremos como simulaciones físicas o contextos superlargos. Los fabricantes de modelos ya no enfrentan el problema de "si puede o no hacerlo", sino el de "quién lo necesita, cuánto está dispuesto a pagar y cuánta fricción de seguridad puede tolerar".
Tres días después del lanzamiento, Fable 5 obtuvo dos informes de calificaciones completamente diferentes: uno en la tabla de benchmarks y otro en el campo de la opinión pública. Cuál se acerca más a la verdad depende de la velocidad con la que Anthropic ajuste su clasificador de seguridad y de las carteras de los usuarios intensivos.






