“K2.6 es nuestro modelo de código más potente hasta la fecha.” Escribió Kimi en su cuenta de WeChat.
El 20 de abril por la noche, Kimi lanzó oficialmente el modelo de código abierto K2.6, que muestra un mejor rendimiento tanto en programación como en capacidades de agente, aproximadamente un trimestre después del lanzamiento de la versión anterior, K2.5.
Aquí hay un pequeño incidente: se rumorea que DeepSeek V4 también se lanzará esta semana. Si todo avanza según lo previsto por los observadores externos, esta sería la enésima vez que Kimi y DeepSeek coinciden. Pero en un nivel más fundamental de infraestructura, hay una línea oculta: Kimi y DeepSeek, estas dos startups de modelos de gran tamaño, finalmente terminarán en el mismo río: avanzar juntas con las startups de chips chinos.
Retrocedamos en el tiempo hasta marzo de 2026, cuando Yang Zhilin, en el escenario de la conferencia GTC de NVIDIA, habló sobre la hoja de ruta tecnológica de Kimi. Dijo: “Muchos de los estándares técnicos de uso común en la actualidad son esencialmente productos de hace ocho o nueve años, y gradualmente se están convirtiendo en un cuello de botella para el Scaling.”
Para resolver problemas similares, Kimi ha contribuido a la comunidad de código abierto con el optimizador de segundo orden MuonClip, aplicado por primera vez a gran escala, la arquitectura Kimi Linear que hace que los modelos de gran tamaño procesen contextos largos de manera más eficiente, y Attention Residuals, que optimiza las conexiones entre capas de redes neuronales profundas.
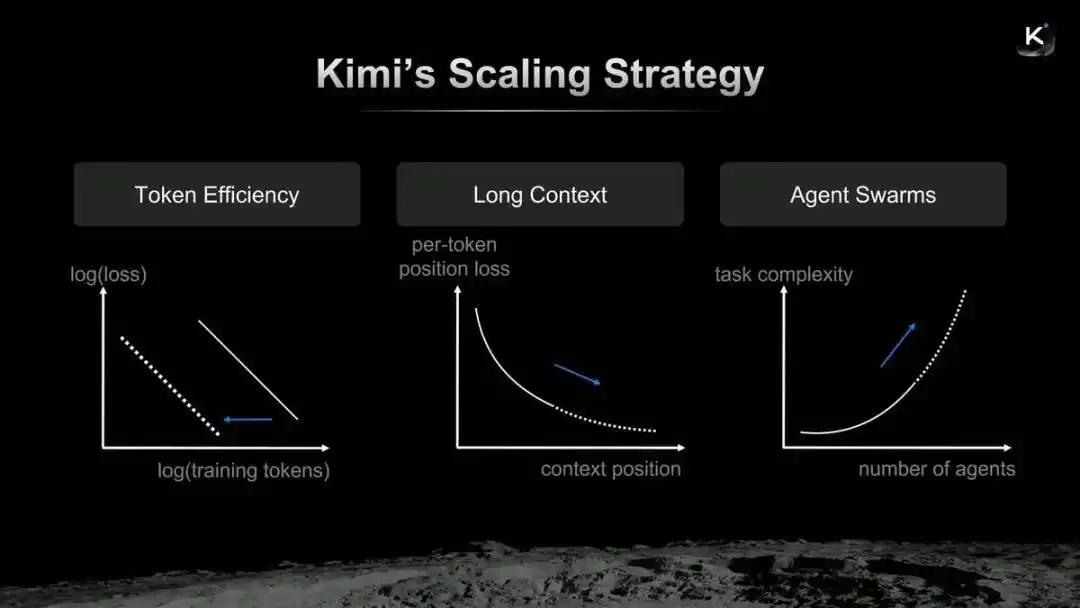
Estrategia de Scaling de Kimi
Yang Zhilin cree que la lógica de evolución de Kimi se resume en la eficiencia de Token, el contexto largo y la “combinación” de clusters de agentes. El recién lanzado Kimi K2.6 puede entenderse como una nueva tarea entregada por Yang Zhilin en esta ruta de Scaling.
El sitio web oficial de Kimi ya ha integrado K2.6
¿Código, Agente, y qué más?
Como una de las capacidades más fáciles de estandarizar, el código es un campo de batalla inevitable para los modelos de vanguardia.
Desde K2, pasando por K2.5, hasta K2.6, Kimi ha mantenido un ritmo de iteración de aproximadamente un trimestre en varios modelos de código abierto, pero dado que este es un número de versión menor, sugiere que Yang Zhilin podría tener más cartas bajo la manga.
“La capacidad de codificación de largo alcance de K2.6 ha mejorado significativamente, pudiendo codificar ininterrumpidamente durante 13 horas en pruebas, escribiendo o modificando más de 4000 líneas de código,” escribió Kimi en un material de comunicación. “En Kimi Code Bench, el estricto benchmark interno de evaluación de código de Kimi que cubre una variedad de tareas complejas de extremo a extremo, el rendimiento de K2.6 mejoró aproximadamente un 20% respecto a K2.5.”
Hay que tener en cuenta que K2.5 ya era un modelo muy “capaz”, que encabezó la lista en OpenRouter en febrero. Una fuente cercana a Kimi publicó una captura de pantalla de un momento en que el cofundador Zhang Yutao publicó en su círculo de amigos: “Parece estar muy satisfecho con esta versión.”

Rendimiento de K2.6 en pruebas de referencia de Agente general, programación y Agente visual
Para frameworks de Agente como OpenClaw y Hermes, las mejoras de K2.6 se centran en la precisión de las llamadas a API y la estabilidad de la ejecución prolongada: una para mejorar el costo de ejecución de tareas y la otra para optimizar la eficiencia de ejecución de tareas.
En K2.5, lanzado en enero, Kimi introdujo el concepto de “cluster de agentes”, dividiendo una tarea en múltiples subproyectos y asignándolos automáticamente a diferentes agentes especializados para su procesamiento, reduciendo así el tiempo de procesamiento de la tarea y evitando la posibilidad de que todo el proyecto colapse bajo un flujo de tareas en serie.
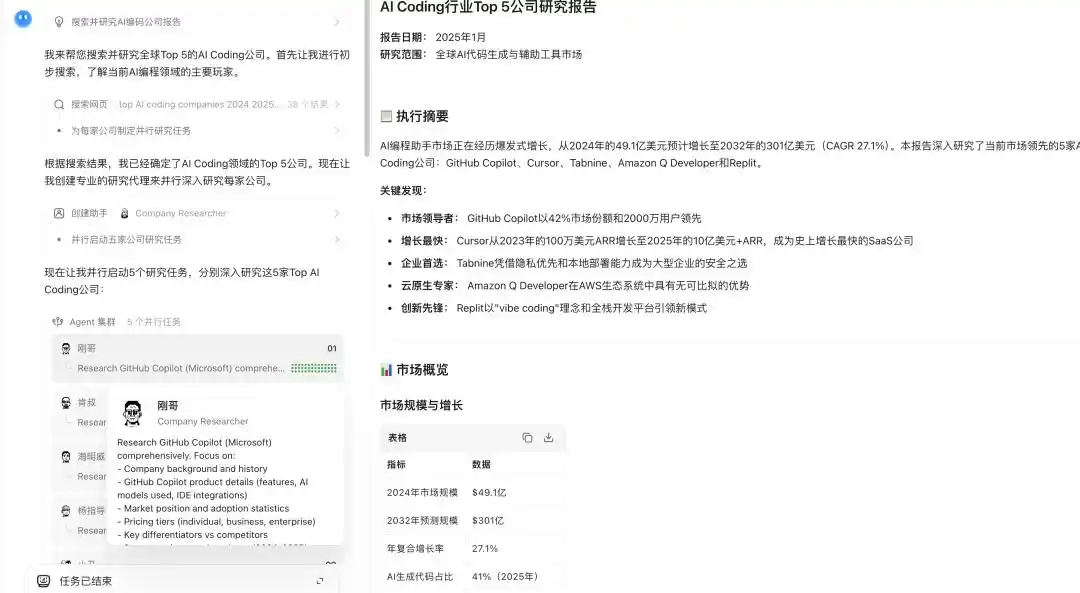
Demostración de la capacidad de cluster de agentes de Kimi K2.6
En la nueva versión K2.6, esta capacidad se amplía aún más, integrando y procesando en paralelo la búsqueda en amplitud con la investigación en profundidad, el análisis de documentos a gran escala con la redacción de textos largos y la generación de contenido en múltiples formatos, admitiendo hasta 300 subagentes que completan 4000 pasos de colaboración en paralelo.
Si tuviera que resumir los aspectos destacados de Kimi K2.6 en una frase, incluirían aproximadamente: evolución de las capacidades de código y tareas de largo alcance, evolución de la capacidad de clusters de agentes y optimización de la adaptación con frameworks de agentes principales.
Si tuviera que elegir una preferencia personal entre estas características funcionales, creo que el cluster de agentes es la capacidad más valiosa, ya que personifica directamente la capacidad explosiva de la computación paralela. Tanto el código como la estabilidad de las tareas de largo alcance son cosas que el modelo debe hacer en su iteración. Lo más importante es que, basándose en estas mejoras de capacidad, se impulse la innovación en la forma de trabajar, la eficiencia e incluso la forma de interactuar de los agentes.
Después de todo, como usuario, no quiero que me diga lo que puede hacer, sino que impulse a los agentes para resolver mis problemas reales y generar productividad efectiva.
Cuando se lanzó K2.5, un investigador académico comenzó a utilizar este modelo para proyectos de investigación. En ese momento, su evaluación fue que no tenía puntos débiles y podía servir como asistente de investigación.
“Los multiagentes proporcionados por el fabricante son realmente efectivos; el año pasado, muchos agentes nacionales todavía eran juguetes (toy).”
Si K2.5 de Kimi recibió buenas evaluaciones tanto internas como externas, ¿cómo será el efecto de K2.6, que va un paso más allá?
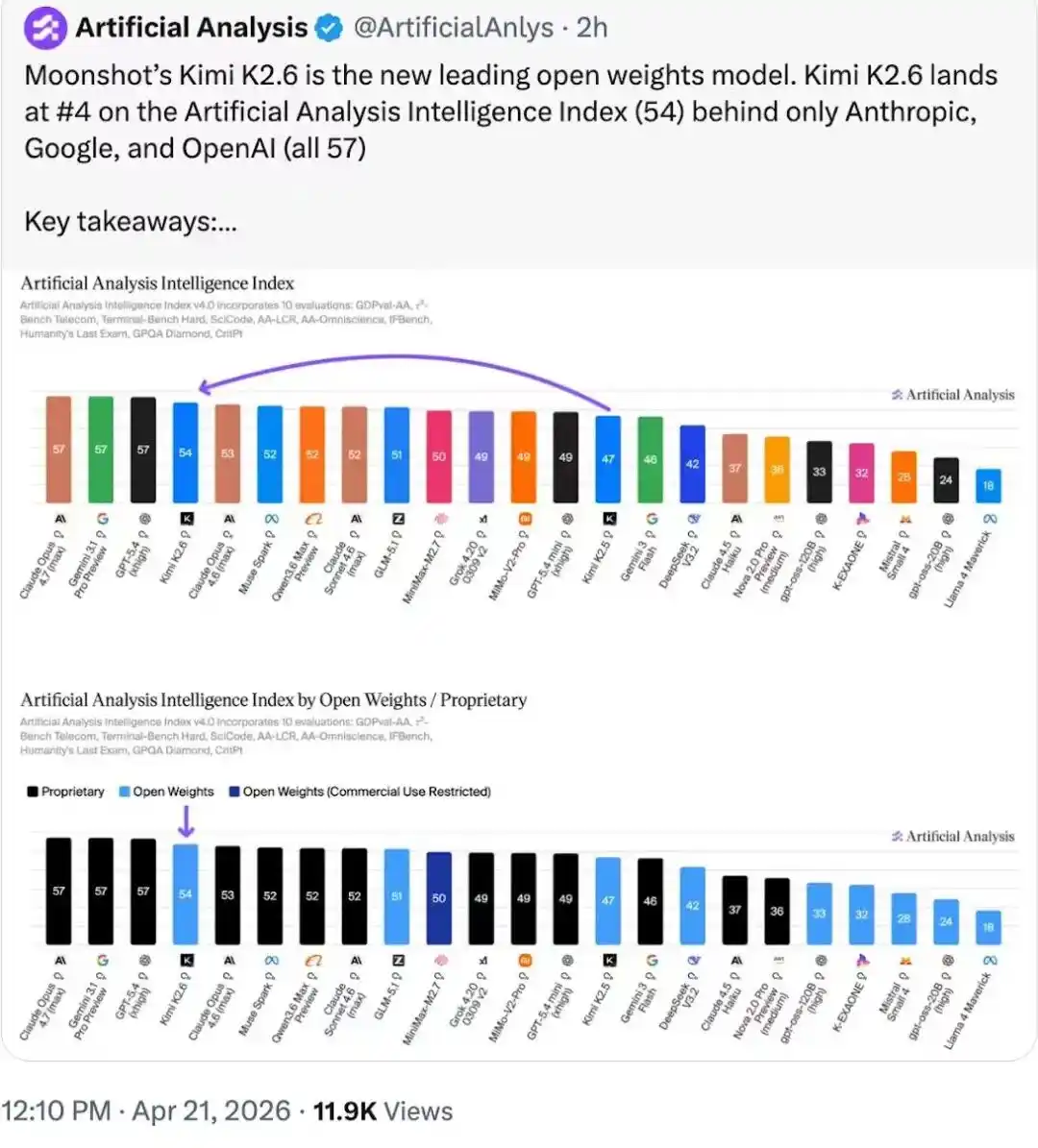
Lista de inteligente Artifacial Analysis, Kimi K2.6 solo es superado por tres modelos cerrados y lidera la lista de pesos de modelos de código abierto
La “nueva historia” en la hoja de ruta
Kimi siempre está dando ideas nuevas a la industria de vez en cuando, incluyendo MuonClip, Kimi Linear y Attention Residuals mencionados en la hoja de ruta del discurso de Yang Zhilin. Algunas exploraciones también han recibido comentarios positivos de los principales actores de la industria.
A mediados de marzo, Kimi publicó el artículo de investigación Attention Residuals, proponiendo el uso de mecanismos de atención para transformar las conexiones residuales. Musk tuiteó directamente que este era un “avance impresionante de Kimi.”

El fin de semana pasado, Kimi publicó un nuevo artículo de investigación titulado “Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter” (PrfaaS, Prelleno previo como servicio), que menciona nuevas exploraciones de Kimi en la arquitectura, discutiendo centralmente aún la separación PD (Prefill y Decode).
La separación PD no es un tema nuevo: la fase Prefill de la inferencia del modelo es una tarea intensiva en computación, mientras que la fase Decode depende del ancho de banda de la memoria. La memoria debe leer y escribir KVCache repetidamente. Esta arquitectura busca desacoplar las tareas intensivas en computación de las intensivas en ancho de banda, mejorar la utilización y el rendimiento del poder de cómputo y, por lo tanto, reducir costos y aumentar la eficiencia.
Aunque la separación PD es buena, también tiene un punto de bloqueo: debe basarse en una red RDMA de alta velocidad dentro del mismo centro de datos.
El punto central del artículo de PrfaaS de Kimi es: reducir drásticamente el volumen de caché KV basándose en un modelo híbrido (Kimi Linear), y luego desacoplar completamente Prefill y Decode en diferentes clusters heterogéneos.
El ejemplo experimental mencionado en el artículo muestra que el cluster especializado de prellenado PrfaaS utiliza 32 H200, que se enfocan en alta potencia de cálculo; el cluster local de decodificación PD utiliza 64 GPU H20 interconectadas a través de una red interna RDMA; los dos clusters están conectados a través de una línea dedicada VPC, con un ancho de banda total entre clusters de aproximadamente 100 Gbps. El modelo probado fue un modelo de atención híbrida Kimi Linear con 1T de parámetros.
Los resultados de las pruebas mostraron que el esquema PrfaaS-PD entre centros de datos, en comparación con el esquema de cluster PD homogéneo con 96 tarjetas H20, mejoró el rendimiento en un 54%, el P90 TTFT (el 90% de los usuarios, el tiempo de espera desde que se envía la solicitud hasta que se devuelve la primera palabra) se redujo de 9.73s a 3.51s, una reducción del 64%, y la transmisión de caché KV entre centros de datos solo ocupó el 13% del ancho de banda total de 100 Gbps.
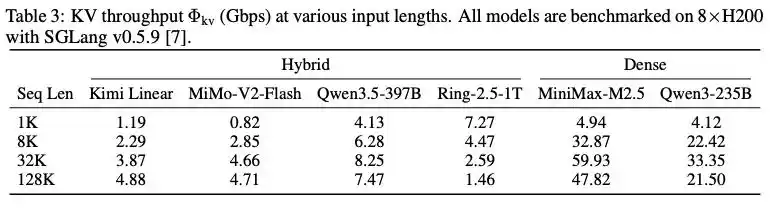
Comparación del rendimiento de KV entre el modelo de arquitectura híbrida y el modelo denso bajo diferentes longitudes de contexto
Para demostrar la ventaja de la arquitectura de modelo híbrido, el artículo menciona un conjunto de experimentos: bajo el framework de inferencia SGLang v0.5.9 y 8 tarjetas H200, se realizaron pruebas de referencia en varios modelos principales. Con una longitud de contexto de 32K, el rendimiento KV del modelo MiMo-V2-Flash que utiliza atención híbrida fue de solo 4.66 Gbps, mientras que el modelo de atención densa de escala similar MiniMax-M2.5 alcanzó 59.93 Gbps, demostrando directamente que la arquitectura de atención híbrida puede reducir los requisitos de transmisión de caché KV a un rango que puede ser soportado por Ethernet común.
“Centros de datos cruzados + hardware heterogéneo, desbloquean el potencial de reducir significativamente el costo por token.” Dijo Kimi en su cuenta oficial.
Sobre la reducción de costos por token, ya lo mencioné en el artículo “El pueblo extraña a DeepSeek”, hay espacio para optimizar tanto a nivel de modelo como de hardware. El profesor Hu Yanping de la Universidad de Finanzas y Economía de Shanghai publicó un mensaje en su círculo de amigos, enfatizando que la resolución de este problema no puede depender solo de un DeepSeek. “La solución del problema depende de la eficiencia de costos del suministro de potencia de cálculo, la mejora intergeneracional de la calidad del modelo, el avance continuo del paradigma de inteligencia, los efectos de amplificación del flujo de trabajo y la conexión de escenarios, etc.”
Desde esta perspectiva, Kimi le ha contado una nueva historia de reducción de costos por token a la industria.
Modelos chinos convocan a chips chinos
En el artículo sobre Prefill-as-a-Service, más personas solo notaron la narrativa de centros de datos cruzados, pero pasaron por alto el punto del hardware heterogéneo.
Es importante señalar que H200 y H20 todavía están basados en la arquitectura Hopper en cuanto a la arquitectura del chip. La heterogeneidad mencionada en el artículo se refiere a la heterogeneidad en ancho de banda y potencia de cálculo. Su revelación es: podemos usar una parte de las tarjetas nacionales con mayor potencia de cálculo para hacer Prefill, o tarjetas nacionales con mayor ancho de banda para hacer Decode, por supuesto, también se pueden mezclar con tarjetas extranjeras para lograr reducción de costos y aumento de eficiencia.
Puede decirse que esta es una puerta que Kimi abre para los chips chinos en la inferencia de modelos de gran tamaño.
En opinión de un profesional de la computación nacional, para aprovechar esta ola de beneficios de tráfico traída por soluciones como Prefill-as-a-Service, todavía hay que enfrentar el viejo problema del ecosistema.
En los últimos años, los modelos de gran tamaño chinos se han visto obstaculizados por el problema del ecosistema para utilizar la computación nacional, pero hay otro detalle que pasa desapercibido: productos como el H20 han estado fuera de suministro durante un año. En otras palabras, a corto plazo, las opciones para chips de inferencia son solo nacionales.
Con la explosión de la demanda de inferencia, en comparación con la oferta, el desafío del ecosistema se convertirá en un problema secundario: la dependencia de los modelos de gran tamaño chinos de la computación nacional ha pasado de ser opcional a ser obligatoria. Precisamente por esto, muchas predicciones discuten que DeepSeek V4 se está adaptando a la computación nacional.
En “La última carta apremiante para DeepSeek” que escribí con el profesor Hu Yanping, dije que adaptarse a la computación nacional es un camino muy difícil para los modelos nacionales, pero a la larga es inevitable hacerlo. Algo que es inevitable hacer, debe tener un punto de partida, quizás DeepSeek V4 sea ese punto de partida.
Ahora, DeepSeek V4 aún no ha llegado, y Kimi ya ha explorado un camino viable para la combinación de modelos chinos + chips chinos con su propia práctica.
Kimi, como representante de los modelos, extendió primero la rama de olivo, y ahora el problema se lo han pasado a las startups de chips chinos.
¿Recuerdan la reacción de Jensen Huang cuando se le preguntó sobre la prohibición de exportar chips a China en el último podcast de “the Dwarkesh Podcast”? Dijo que los chips no son enriquecimiento de uranio, que la prohibición de ventas no puede detener el progreso de los chips chinos, que aún pueden desarrollar modelos mediante la superposición violenta de chips nacionales.
¿Por qué dijo Jensen Huang esto? El próximo paso de DeepSeek y Kimi es la respuesta estándar.
Este artículo proviene del WeChat público “Tencent Technology”, autor: Su Yang, editor: Xu Qingyang





