Autor: AI Product Aying
Leí un blog del equipo de Anthropic titulado "Lessons from building Claude Code: How we use skills". Este es probablemente el resumen práctico más profundo sobre Skills que he visto hasta ahora.
Las Skills no son algo complicado, pero realmente hacerlas bien tampoco me parece fácil.
Recuerdo que cuando las Skills se pusieron de moda, a todos les encantaba crear Skills de estilo literario o de escritura. Parecía que con solo meter su propio estilo de escritura, el modelo podía generar contenido de manera estable siguiendo ese estilo.
Pero luego probé un montón y descubrí que a menudo no funcionaba en absoluto.
Porque una Skill de estilo literario podría meter miles o incluso decenas de miles de palabras de contenido. Al cargar la Skill, el contexto ocupa una gran parte. Con un contexto tan pesado, la capacidad de razonamiento del modelo tiende a disminuir.
Al final, a menudo ocurría lo siguiente: aprendía el estilo, pero el contenido se volvía superficial y su capacidad analítica también se debilitaba.
Hay otra situación común.
Mucha gente, al escribir Skills, le gusta meter todo tipo de instrucciones de operación. Primero hacer qué, luego qué, tercero qué. Al ejecutarlas, descubren que el modelo no las ejecuta de manera estable.
Más tarde, poco a poco fui entendiendo que muchas de estas tareas repetitivas son más adecuadas para convertirse en Scripts, no para escribirlas como instrucciones largas.
Después de leer este artículo de Anthropic, mi mayor sensación es que mucha gente usa Skills, pero no necesariamente las entiende realmente.
En esencia, las Skills hacen Context Engineering. Cuándo debería meterse conocimiento en una Skill, cuándo debería dividirse en References, cuándo debería escribirse como Script, cuándo deberían usarse Gotchas para restringir al modelo; aquí hay mucha experiencia.
Después de entender el principio de funcionamiento de las Skills, al mirar hacia atrás esas Skills excelentes, descubres que lo que resuelven nunca es un problema de prompts, sino que resuelven problemas de contexto, de sedimentación de experiencia y de reutilización de capacidades.
Si quieren investigar las Skills en profundidad, especialmente recomiendo leer estos dos artículos:
https://claude.com/blog/lessons-from-building-claude-code-how-we-use-skills
https://research.perplexity.ai/articles/designing-refining-and-maintaining-agent-skills-at-perplexity
#01 No escribas tonterías
La Skill esencialmente está sedimentando el "conocimiento tácito" dentro de la organización. Por lo tanto, en la Skill no hay que repetir el sentido común que ya conoce. Lo que realmente tiene valor es esa información que el modelo directamente no conoce.
Anthropic enfatiza internamente con frecuencia que lo que realmente hay que escribir en una Skill son los Gotchas, es decir, los errores comunes.
Por ejemplo:
1. Esta tabla no se puede ordenar por created_at
2. Que staging devuelva 200 no significa éxito
3. request_id y trace_id son lo mismo
Porque esta información suele existir en la experiencia de los empleados. Así que hay que recordar siempre cuál es la esencia de una Skill.
Skill = Escribir la experiencia del maestro veterano.
A través de las Skills, sedimentar la experiencia que antes estaba dispersa en la cabeza de diferentes personas.
#02 Las Skills son en realidad Context Engineering
Esta es probablemente una de las perspectivas más profundas de Anthropic.
Una Skill no es un archivo markdown, sino una carpeta. Para quien ha usado Skills, esto suena a obviedad.
Pero estos dos días he estado reflexionando repetidamente y poco a poco me he dado cuenta: justamente quieren usar la forma de carpeta para expresar el concepto de Context Engineering.
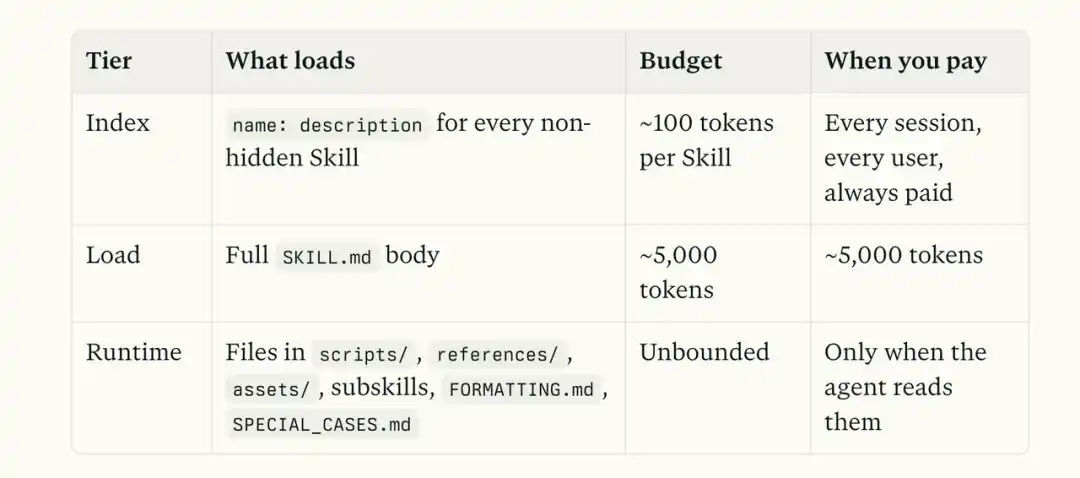
Vamos a mirar de nuevo la estructura típica de una Skill:
skill/ ├── SKILL.md ├── references/ (pone explicaciones detalladas, referencias API, condiciones límite) ├── scripts/ (pone scripts ejecutables) ├── examples/ (pone ejemplos) ├── assets/ (pone plantillas, imágenes, materiales fijos)
Cuando se invoca una Skill, el modelo primero lee SKILL.md. Si metemos toda la información en este archivo, rápidamente explotará el contexto.
Supongamos que es una Skill para resolver problemas de pago. Dentro tiene tanto explicaciones de códigos de error de Stripe, como casos históricos de fallos, además de scripts de diagnóstico y plantillas para el informe final.
Si todo este contenido se apila en SKILL.md, cada vez que se invoca la Skill, Claude tendría que leerlo todo de nuevo.
Incluso si el usuario solo quiere confirmar el significado de un código de error, incluso si solo quiere ver por qué no se actualiza cierto estado de pago. Una gran cantidad de información que directamente no se necesita, también será metida en el contexto.
Y el enfoque de Anthropic es completamente diferente.
SKILL.md se parece más a una página de navegación. Su responsabilidad es decirle al modelo que, al encontrar un error de Stripe, busque la explicación correspondiente en references.
Cuando necesita referenciar casos históricos, que busque problemas similares en examples; cuando realmente necesita ejecutar acciones de diagnóstico, que ejecute los scripts en scripts; y finalmente, al generar el informe de resolución de problemas, que use las plantillas en assets.
Todo el proceso es una exposición gradual.
La siguiente imagen, les recomiendo encarecidamente guardarla.
#03 Usa scripts siempre que sea posible
No dejes que el modelo desperdicie su limitado contexto y capacidad de razonamiento en trabajo repetitivo. Confía estas tareas a los scripts.
Por ejemplo. Mucha gente, al escribir Skills, lo escribe así:
1. Consultar datos de registro; 2. Consultar datos de pago; 3. Calcular tasa de conversión; 4. Analizar causa de la anomalía.
Esta forma de escribir no tiene problema. El modelo también puede completarlo. Pero cada vez que lo ejecuta, tiene que recorrer todo el flujo de análisis desde el principio.
Consultar datos, organizar datos, manejar varias situaciones límite, este trabajo es en realidad repetitivo.
Dado que estas capacidades ya han sido verificadas innumerables veces. ¿Por qué hacer que el modelo las reinvente una vez más? Mejor proporcionar directamente los scripts concretos.
Y mediante el uso de scripts, la ejecución de la Skill también será más precisa y ahorrará más Tokens.
Desde esta perspectiva, los Scripts dentro de una Skill están realmente sedimentando la capacidad organizativa. Detrás de cada script, a menudo está la mejor práctica resumida después de que el equipo ha tropezado con innumerables errores.
Después de solidificar estas capacidades. Claude puede trabajar cada vez sobre la base de esta experiencia, en lugar de comenzar de cero una y otra vez.
Por eso, cada vez siento más que, dentro de una Skill, las Instructions y los Scripts resuelven problemas en dos niveles diferentes.
Las Instructions proporcionan experiencia y juicio, los Scripts proporcionan capacidad y ejecución.
Por ejemplo, en una Skill de resolución de problemas de pago podría haber algo así:
Si Stripe devuelve 200, no asumas directamente que el pago fue exitoso, necesitas verificar más a fondo la tabla payment_events.
Esto pertenece a las Instructions. Porque es experiencia. Y check_payment_events() pertenece a Script, porque es capacidad de ejecución.
Si solo hay Script, el modelo sabe cómo consultar, pero no necesariamente sabe por qué consultar.
Si solo hay Instructions, el modelo sabe que debería consultar. Pero cada vez tiene que volver a implementar. Ambos son indispensables.
#04 La Description se parece más a una regla de enrutamiento
Mucha gente escribe la Description de la Skill de una manera que es naturalmente incorrecta.
Porque está acostumbrada a escribirla como una introducción de funciones. Por ejemplo: PR Management Skill ayuda a los usuarios a monitorear el estado de los PR, manejar problemas de CI, completar Merge automáticamente.
Pero el problema es que el modelo no busca Skills a través de funciones. Cuando se inicia Claude Code, primero escanea el nombre y la Description de todas las Skills.
Luego, según el problema actual del usuario, juzga qué Skill debería cargar.
Por lo tanto, la información más importante en la Description no es lo que puede hacer esta Skill, sino en qué situación debería cargarse.
La Description en realidad asume el trabajo de enrutamiento de toda la Skill.
En el mundo real, rara vez alguien dice 'ayúdame a invocar una herramienta de gestión de PR'. Es más probable que digan: ayúdame a vigilar este PR, CI se ha caído de nuevo, etc.
Así que una buena Description debería describir la intención del usuario, no enumerar funciones.
Incluso siento que se puede usar un método muy simple para comprobarlo.
Después de escribir la Description, borra toda la Skill, dejando solo esta línea de Description. Luego pregúntate: después de que el modelo vea el problema del usuario, ¿puede saber cuándo debería cargar esta Skill?
Si no puede, lo más probable es que todavía haya que seguir modificándola.
#05 Gestión y distribución de Skills
Otro punto es sobre la gestión de Skills.
Cuando una persona usa Skills, el asunto es realmente simple. Escribes unas cuantas Skills, las mantienes tú mismo, las actualizas tú mismo. Pero creo que la mayoría de los equipos después se encontrarán con el mismo problema.
Cuando las Skills pasan de ser unas pocas a docenas, incluso cientos, ¿cómo deberían gestionarse estas Skills? ¿Cómo actualizarlas? ¿Cómo distribuirlas a los miembros del equipo?
La experiencia de Anthropic en este aspecto, creo que es bastante digna de referencia.
Cuando el tamaño del equipo es relativamente pequeño, las Skills van directamente con el repositorio de código. Basta con ponerlas en el directorio .claude/skills dentro del proyecto. Todos comparten el mismo conjunto de Skills y también el mismo conjunto de métodos de trabajo.
Pero a medida que la cantidad de Skills aumenta, surge un nuevo problema.
Cuando se inicia Claude Code, escanea el nombre y la Description de todas las Skills, y luego juzga qué Skill debería invocar para la tarea actual. Cuantas más Skills, mayor es el costo de enrutamiento.
Por eso Anthropic luego comenzó a hacer Marketplace. Pero lo más interesante es la forma en que gestionan el Marketplace.
Muchas empresas, al enfrentar este problema, su primera reacción suele ser establecer un proceso de aprobación. Quien escribe una Skill, primero presenta una solicitud; después de aprobarla, entra en la biblioteca oficial de Skills. Internamente, nosotros también lo hicimos así, pero es muy pesado. Gestión por el mero hecho de gestionar.
Descubrí que la organización de Anthropic es muy ligera.
Dejan que las nuevas Skills primero se difundan en un pequeño círculo, que los compañeros las instalen y prueben por sí mismos.
Si cada vez más personas comienzan a usarla, significa que esta Skill realmente resuelve un problema real. En esta etapa, el autor la envía al Marketplace formal.
Así que ellos no discuten primero si la Skill tiene valor o no, sino que primero la dejan someter a la prueba de escenarios de uso real. Si mucha gente la usa, naturalmente entra en el sistema formal. Las Skills que quedan así son básicamente las que el equipo realmente necesita.