La investigación automatizada ha salido esta vez de la "caja de arena" del código para entrar en el mundo físico real.
Recientemente, Jim Fan, director del laboratorio NVIDIA GEAR, presentó un nuevo proyecto llamado ENPIRE. Es la primera vez que han logrado una investigación automatizada en hardware robótico.
Colocaron 8 agentes Codex en una flota de robots, asignaron potencia de cálculo GPU y un amplio presupuesto de tokens, y solo les dieron un objetivo simple: resolver las tareas lo más rápido posible, mantener los robots ocupados pero seguros, y no desperdiciar potencia de cálculo.
A partir de ahí, la intervención humana fue mínima. Los agentes impulsaron de forma autónoma todo el ciclo cerrado, incluyendo el reinicio automático de escenarios, la búsqueda de literatura, la implementación de ideas y la construcción de infraestructura, el entrenamiento y despliegue de estrategias, la autoverificación, el análisis de registros y la mejora del código, iterando continuamente hasta completar de forma confiable en hardware real tareas delicadas de alta precisión, como atar bridas, organizar alfileres en una caja o instalar GPUs.
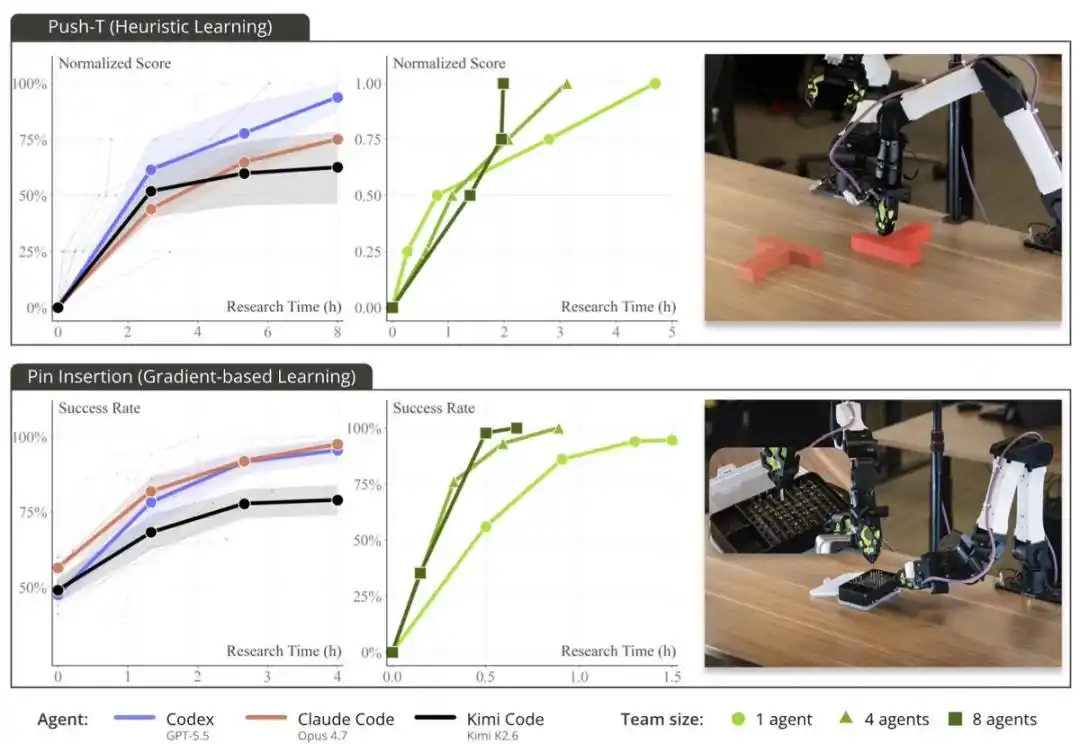
También observaron una "ley de escala física": aumentar el número de robots en paralelo (por ejemplo, de unos pocos a 8) aceleraba significativamente la velocidad de resolución de tareas.
Actualmente, algunos sistemas de este laboratorio ya pueden realizar iteraciones autónomas durante toda la noche sin intervención humana, y los investigadores solo necesitan revisar los informes por la mañana.
Jim Fan afirmó que el objetivo futuro es que los miembros del equipo puedan tomarse vacaciones tranquilamente, e incluso que el CEO de NVIDIA, Jensen Huang, no se dé cuenta de que el laboratorio sigue funcionando de forma autónoma.
El proyecto ENPIRE tiene planes de ser totalmente de código abierto, lo que permitiría que desarrolladores comunes también pudieran construir sistemas similares de investigación robótica autónoma en casa.

Dirección del proyecto: https://research.nvidia.com/labs/gear/enpire/
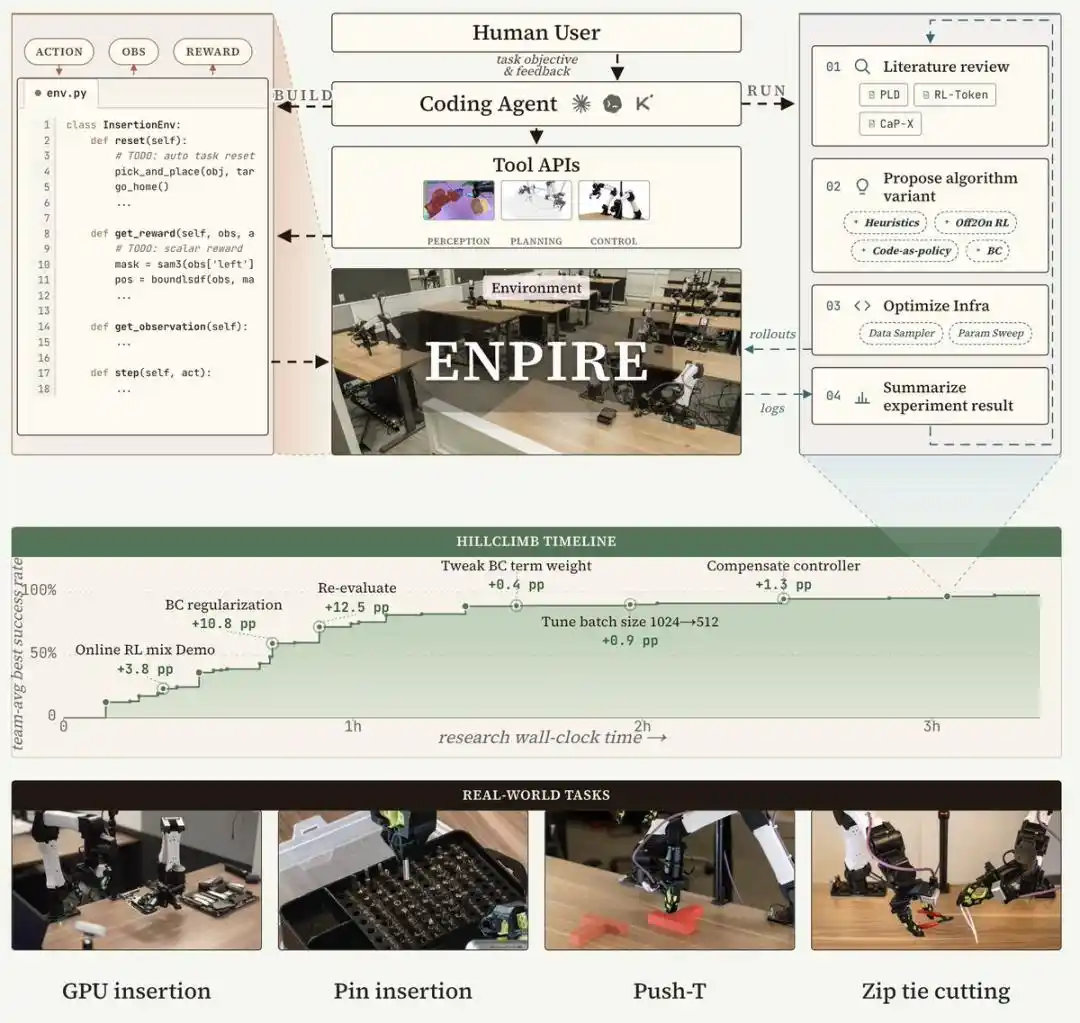
Arquitectura del sistema ENPIRE: Cuatro módulos forman un ciclo cerrado
ENPIRE es un sistema de framework diseñado para agentes de programación, que construye un ciclo de retroalimentación física reproducible mediante cuatro módulos principales: el módulo de entorno (EN) se encarga del reinicio y verificación automática, el módulo de mejora de estrategias (PI) inicia la optimización de políticas, el módulo Rollout (R) permite la evaluación de políticas en paralelo con uno o varios robots, y el módulo evolutivo (E) permite a los agentes de programación analizar registros, consultar literatura, y mejorar la infraestructura de entrenamiento y el código de algoritmos para resolver modos de fallo.
Este sistema de ciclo cerrado convierte el aprendizaje robótico en el mundo real en un proceso de optimización controlado y gestionado por agentes, minimizando así la intervención manual y permitiendo realizar experimentos de abalación justos entre diferentes recetas de entrenamiento y variantes de agentes.
Con el apoyo de ENPIRE, los agentes de programación de vanguardia pueden desarrollar estrategias de forma autónoma y lograr una tasa de éxito del 99% en tareas desafiantes de manipulación diestra en el mundo real, como PushT, organizar alfileres en una caja, o cortar bridas con un cortador.
Descubrimiento clave: Restablecer el entorno es a menudo más fácil que completar la tarea
Una observación clave fue: Para muchas tareas robóticas, restablecer el entorno suele ser más fácil que completar la tarea en sí.
Por lo tanto, el enfoque de ENPIRE es hacer que el agente construya primero un entorno de reinicio automático mediante Code-as-Policy. En muchos casos, el reinicio es esencialmente una tarea de "pick-and-place" que puede resolver Cap-X.
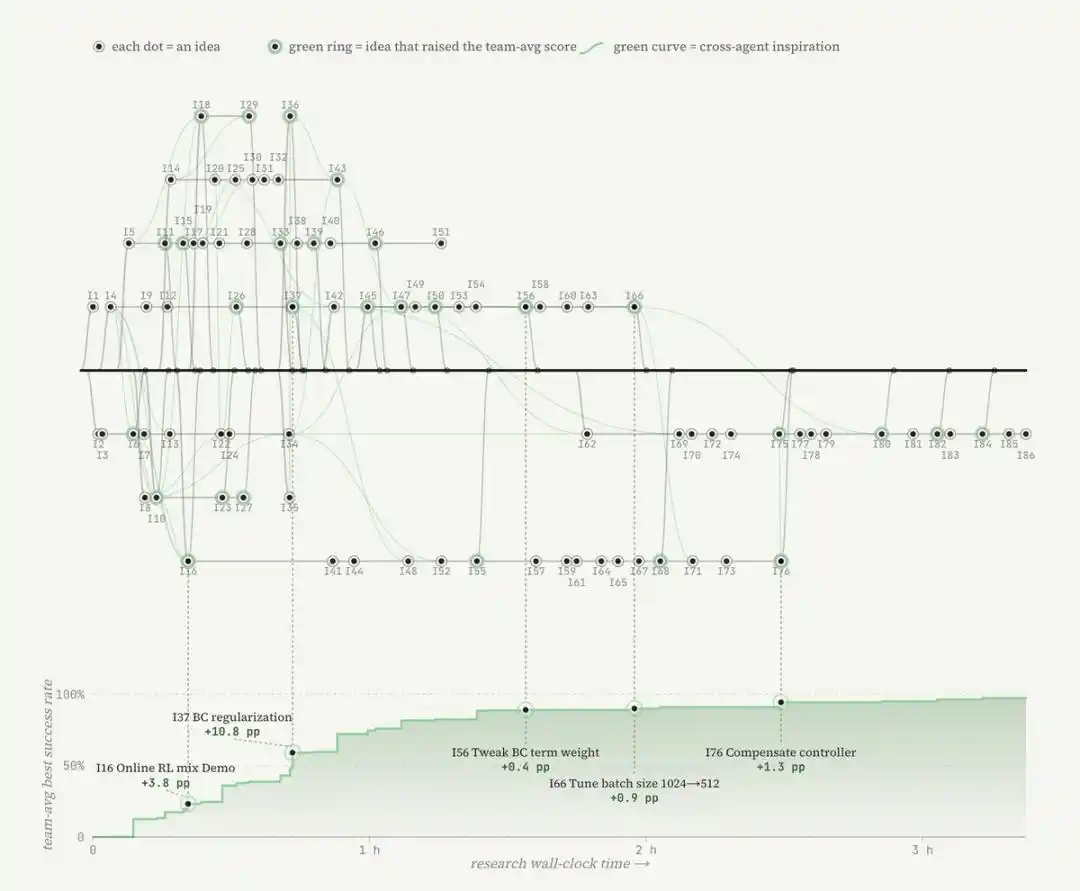
Posteriormente, el agente escribe una función de recompensa basada en reglas heurísticas. El equipo de investigación coloca entonces ese entorno en un sandbox e inicia una investigación automatizada guiada por los puntos obtenidos.
Esto también refleja la definición de investigación automatizada de Karpathy: la automatización aquí no es simplemente ajustar un hiperparámetro o cambiar un pequeño fragmento de código. El agente explora diferentes paradigmas desde Internet y reescribe cualquier parte que pueda impulsar el rendimiento, incluyendo algoritmos, objetivos de entrenamiento, e incluso el cargador de datos.
En la tarea de los alfileres, un agente incluso escribió por sí solo un controlador de seguridad de fuerza de contacto, cuyo efecto superó al de simplemente ajustar algunos parámetros de aprendizaje por refuerzo.
Nuevas métricas: MRU y MTU
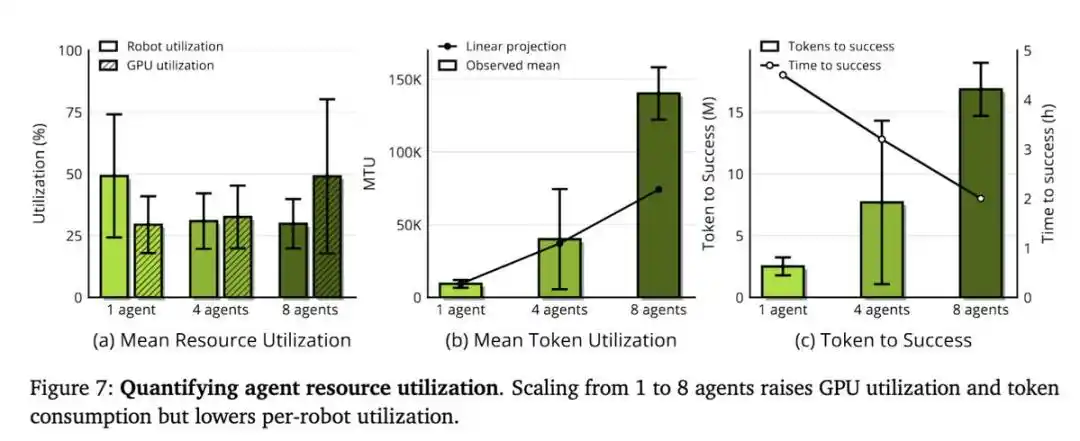
La capacidad de escalado de ENPIRE depende del tamaño del equipo de agentes y los recursos computacionales, aunque aquí el recurso realmente escaso no es la GPU, sino el tiempo de los robots.
Cuando el equipo de investigación proporcionó 8 robots a los agentes, en lugar de 1, el tiempo necesario para que la tarea de los alfileres alcanzara un rendimiento casi perfecto se redujo de más de 1,5 horas a unos 40 minutos. Estos agentes se coordinaban mediante Git: compartiendo código, descartando ideas no ideales y seleccionando de forma autónoma los mejores resultados de ejecución entre ellos.
Esto apunta a un cambio mayor: la investigación robótica se está convirtiendo en un trabajo de diseño de entornos, es decir, construir entornos en los que los agentes de programación puedan realizar investigación automatizada; el trabajo algorítmico se desplaza a un nivel superior, hacia la construcción de un ciclo de retroalimentación que los agentes puedan cerrar por sí mismos.
Y este ciclo se acumula de forma compuesta: una habilidad que un agente domina hoy, mañana se convierte en un módulo base para construir y restablecer entornos de tareas más difíciles. La capacidad genera nueva capacidad.
En este paradigma, la verdadera limitación dura es el presupuesto de interacción con el mundo real.
Por lo tanto, el equipo de investigación propuso dos métricas:
- Utilización Media del Robot (Mean Robot Utilization, MRU): la proporción de tiempo que los robots ejecutan realmente experimentos respecto al tiempo total real transcurrido.
- Utilización Media de Tokens (Mean Token Utilization, MTU): mide la eficiencia con la que los agentes convierten tokens en progreso de investigación.
En sus experimentos, la MRU estuvo constantemente por debajo del 50%. Es decir, los robots permanecían inactivos la mitad del tiempo, esperando a que los agentes pensaran. Por lo tanto, un mejor "harness" y modelos más rápidos se traducirían directamente en beneficios reales.
PushT es un punto de referencia de operación robótica de larga data. Normalmente, para completar esta tarea, se necesita una gran cantidad de datos de demostración humana, además de horas de entrenamiento por clonación de comportamiento.
Pero ellos vieron que Codex, Claude Code y Kimi Code "resolvieron" esta tarea en menos de 2 horas usando un método heurístico basado en reglas: sin usar redes neuronales, sin entrenamiento y sin depender de ningún dato humano.
Para permitir que más personas prueben la investigación automatizada en el mundo físico desde casa, han desarrollado un sistema completo de pila completa basado en el kit SO-101 de @LeRobotHF + NVIDIA Jetson Thor. Este sistema puede completar la tarea PushT.
Enlaces de referencia:
https://x.com/_wenlixiao/status/2066913334994358342
https://x.com/DrJimFan/status/2066921736369766762
Este artículo procede del WeChat oficial "机器之心" (ID: almosthuman2014), autor: Yang Wen.





