Cada vez que se lanza un modelo de vanguardia, el mundo de la IA fija su mirada en unas cuantas hojas de calificaciones familiares.
MMLU-Pro, MMMU, MMMU-Pro... Estos nombres pueden resultar extraños para los usuarios comunes, pero para las empresas de modelos y los investigadores, se han convertido casi en "asignaturas estándar". GPT, Claude, Gemini, Llama, Qwen, DeepSeek... todos entregan constantemente sus resultados en estos benchmarks.
"El talento se demuestra en la práctica". El desempeño de los modelos a menudo depende de estas puntuaciones para demostrarlo.
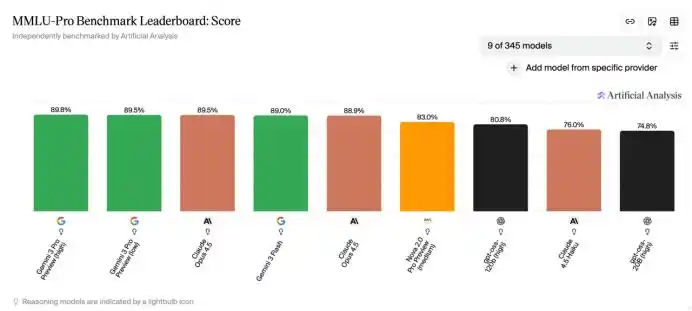
Muchas de las gráficas de comparación de rendimiento en las presentaciones de modelos no pueden prescindir de ellas; algunas clasificaciones en HuggingFace también se basan en estos sistemas de evaluación. Incluso podría decirse que hoy en día, cuando la industria de la IA discute sobre las capacidades de los modelos, ya utiliza un lenguaje común definido por estos benchmarks.
Pero lo interesante es que casi todos se centran en las puntuaciones, pero pocos saben quién crea los exámenes. Y detrás de MMLU-Pro, MMMU y MMMU-Pro, se puede ver el mismo nombre: Chen Wenhu.
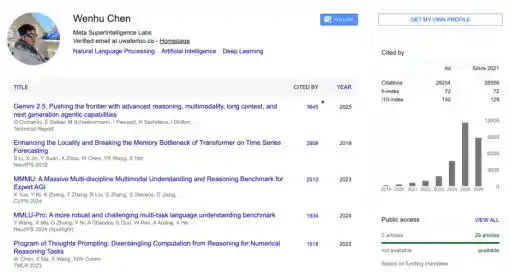
Es profesor asistente en el Departamento de Ciencias de la Computación de la Universidad de Waterloo en Canadá. En Google Scholar, sus artículos han sido citados más de 30,000 veces.
También es el fundador del "TIGERLab" (Laboratorio de Investigación en Generación de Texto e Imagen). Debido a que su nombre en inglés contiene "TIGER", Chen Wenhu le dio un nombre en chino muy distintivo: "Hutou Bang" (La Pandilla del Tigre).
01
Después del fallo del viejo examen
Chen Wenhu llamó la atención de más personas inicialmente debido a MMLU-Pro.
MMLU solía ser uno de los benchmarks de evaluación más utilizados para medir las capacidades de los modelos de lenguaje grandes. Es como un examen integral que cubre múltiples disciplinas, utilizado para medir el rendimiento de los modelos en tareas de comprensión del conocimiento y razonamiento.
En un principio, este examen era muy útil. Las diferencias entre modelos podían reflejarse en las puntuaciones, y la industria también podía observar a través de él si los modelos de lenguaje grandes realmente estaban progresando.
Pero pronto surgió el problema.
A medida que las capacidades de los modelos mejoraban continuamente, MMLU gradualmente se volvió "insuficiente". Las puntuaciones de los modelos de vanguardia eran cada vez más altas, y las diferencias entre ellos cada vez más pequeñas.
Este problema se volvió aún más evidente después de que OpenAI lanzara o3. La precisión de o3 en MMLU ya se acercaba al 100%, y otros modelos de vanguardia también obtuvieron puntuaciones cercanas a la perfección.
Esto puede sonar como una buena noticia, pero para la evaluación, significa problemas.
Si todos pueden obtener puntuaciones cercanas a la perfección en un examen, es difícil seguir determinando quién es mejor y en qué aspectos. Aún puede demostrar que los modelos poseen ciertas capacidades, pero ya no es adecuado para medir nuevos progresos.
La industria de la IA necesitaba un examen más difícil y menos susceptible de ser "aprobado con trucos".
En 2024, Chen Wenhu y su equipo lanzaron MMLU-Pro.
MMLU-Pro reformó este examen en lugar de simplemente ampliar el banco de preguntas.
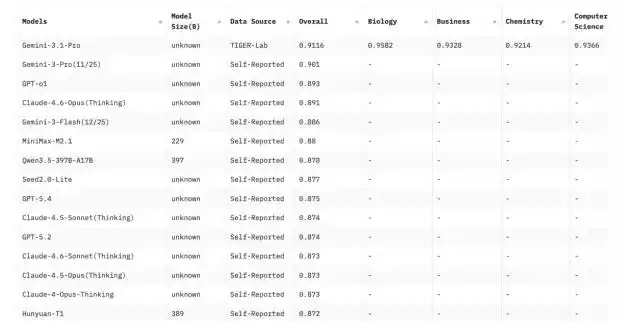
Contiene 12,032 preguntas que cubren 14 campos, incluyendo matemáticas, física, química, derecho, ingeniería, psicología, salud, etc. En comparación con la versión original de MMLU, amplió las opciones de respuesta de 4 a 10, reduciendo la probabilidad de que el modelo adivine correctamente; al mismo tiempo, incorporó más preguntas centradas en el razonamiento y eliminó aquellas relativamente simples, ambiguas o con poca capacidad discriminatoria del banco original.
El efecto fue directo.
Los resultados del artículo mostraron que la precisión de los modelos en MMLU-Pro disminuyó entre un 16% y un 33% en comparación con la MMLU original. Cuando se probó el mismo modelo con 24 estilos diferentes de prompts, la fluctuación en los resultados también disminuyó de aproximadamente un 4-5% en la MMLU original a alrededor de un 2%.
Es decir, este nuevo examen no solo es más difícil, sino también más estable.
Permitió que los modelos que parecían sobresalientes en el examen antiguo volvieran a mostrar diferencias significativas. También se hizo más fácil discernir si un modelo realmente sabe razonar o simplemente es mejor para enfrentarse a preguntas antiguas.
02
Benchmarks útiles
MMLU-Pro pronto fue adoptado por la industria.
Posteriormente, MMLU-Pro ingresó a la pista de conjuntos de datos y benchmarks de NeurIPS 2024 y también fue integrado en el framework de evaluación de modelos de lenguaje lm-evaluation-harness de EleutherAI. Para la comunidad de modelos de código abierto, esto significó que ya no era solo un conjunto de datos en un artículo, sino que se había integrado en la cadena de herramientas de evaluación comúnmente utilizada.
Muchos modelos comenzaron a reportar puntuaciones de MMLU-Pro en sus lanzamientos. Algunas clasificaciones en HuggingFace también lo incorporaron a sus sistemas de evaluación.
Si MMLU-Pro resolvía el problema del "fallo del viejo examen" en la evaluación de modelos de lenguaje, entonces MMMU situó a Chen Wenhu y TIGERLab en el centro de la evaluación multimodal.
El problema de los modelos multimodales es más complejo.
Los modelos de lenguaje responden preguntas principalmente procesando texto. Los modelos multimodales, en cambio, deben procesar simultáneamente información en diferentes formatos como imágenes, gráficos, diagramas, mapas, tablas, partituras, estructuras químicas, etc. No solo deben entender el enunciado, sino también comprender realmente el contenido de las imágenes y combinar la información visual, la información textual y el conocimiento disciplinario para razonar.
El benchmark MMMU incluye 11,500 preguntas multimodales, provenientes de exámenes universitarios, pruebas y libros de texto, cubriendo seis grandes áreas: arte y diseño, negocios, ciencias, salud y medicina, humanidades y ciencias sociales, tecnología e ingeniería, que se subdividen en 30 disciplinas y 183 subcampos.
Estas preguntas no se limitan a preguntar al modelo "qué hay en la imagen"; exigen que el modelo combine la información de la imagen con el conocimiento disciplinario, como lo haría un estudiante al resolver un problema profesional.
Cuando se lanzó MMMU, el equipo de investigación evaluó 14 modelos multimodales de código abierto, así como modelos propietarios representativos como GPT-4V y Gemini Ultra. Incluso los modelos propietarios más potentes en ese momento, GPT-4V y Gemini Ultra, solo alcanzaron precisiones del 56% y 59% respectivamente.
Estas cifras indican que, aunque los modelos multimodales parecen avanzar rápidamente, aún tienen un amplio margen de mejora en problemas que realmente requieren comprensión profesional y razonamiento.
Posteriormente, el equipo de Chen Wenhu lanzó MMMU-Pro, bloqueando aún más los caminos que permitían a los modelos eludir la información visual. Filtra preguntas que podrían responderse solo con modelos de texto, amplía las opciones de respuesta e introduce una configuración "vision-only", incrustando la pregunta en la imagen misma, exigiendo al modelo completar simultáneamente la lectura visual y la comprensión textual.
En pocas palabras, evita que el modelo "adivine la respuesta solo leyendo el texto".
Este tipo de trabajo puede sonar un tanto minucioso, pero es crucial. Porque los modelos multimodales en el futuro se integrarán en escenarios como la medicina, la educación, la investigación científica, el diseño, la ingeniería, etc., y solo ser capaces de describir imágenes no es suficiente. Deben poder juzgar, razonar, explicar y también encontrar la parte verdaderamente útil dentro de información visual compleja.
03
La persona detrás del "examen"
El trabajo posterior de Chen Wenhu en MMLU-Pro y MMMU proviene de su línea de investigación de siempre.

Sus intereses de investigación siempre han estado relacionados con la comprensión de información compleja, preguntas y respuestas basadas en conocimiento y razonamiento.
Se graduó de la licenciatura en la Universidad de Ciencia y Tecnología de Huazhong, luego obtuvo una maestría en la Universidad RWTH de Aquisgrán en Alemania y un doctorado en Ciencias de la Computación en la Universidad de California, Santa Bárbara. Durante su doctorado, ya comenzó a investigar en direcciones como preguntas y respuestas complejas, razonamiento sobre tablas y localización de evidencias en el conocimiento.
Este tipo de tareas tiene un punto en común: la respuesta a menudo no se encuentra en un solo texto.
Puede estar oculta en una tabla, puede requerir combinar un párrafo de texto con una imagen, o puede requerir que el modelo primero recupere información y luego la integre, calcule y razone. El modelo no puede limitarse a repetir conocimientos existentes.
Proyectos en los que Chen Wenhu ha participado, como HybridQA, TabFact, Program of Thoughts, MAmmoTH, están relacionados con esta línea.
Esto también explica por qué es sensible a las brechas en la evaluación de modelos.
Un buen benchmark no consiste simplemente en hacer las preguntas cada vez más difíciles, sino en prever dónde es más probable que el modelo "adivine correctamente" o "parezca que sabe".
El modelo puede haber memorizado el banco de preguntas, puede adivinar respuestas basándose en las opciones, o puede usar texto para eludir la información visual... Una buena evaluación debe cubrir estas brechas.
Después de su doctorado, Chen Wenhu ingresó a Google Research y posteriormente, de 2021 a 2025, participó en el desarrollo del modelo multimodal Gemini y en trabajos de evaluación en Google DeepMind. Esta experiencia también fue importante. El contacto prolongado con el desarrollo de modelos de vanguardia le permitió comprender mejor cómo crecen las capacidades de los modelos y detectar más fácilmente los posibles sesgos y puntos ciegos en la evaluación.
En el otoño de 2022, Chen Wenhu se unió a la Facultad de Ciencias de la Computación de la Universidad de Waterloo como profesor asistente. Ese mismo año, fue seleccionado como Canada CIFAR AI Chair. Posteriormente, fundó el "TIGERLab" (también conocido como Hutou Bang), continuando su investigación en torno a modelos fundamentales, capacidades multimodales y benchmarks.
Hutou Bang no se limita a crear benchmarks; también realiza investigación en modelos y sistemas.
En el ámbito del video, UniVideo intenta integrar la comprensión, generación y edición de video en un mismo framework, permitiendo que el modelo no solo genere una secuencia, sino que también comprenda el contenido, responda a instrucciones y complete modificaciones. Vamba se centra en la comprensión de videos largos, abordando problemas de memoria, cálculo y eficiencia en el entrenamiento de videos de hasta una hora. MoCha, desarrollado en colaboración con el equipo de IA generativa de Meta, se centra en la generación de personajes virtuales parlantes, creando videos de personajes de alta calidad a partir de descripciones de voz y texto.

Un creador de exámenes que nunca resuelve problemas no puede crear buenos exámenes. Desarrollar modelos ellos mismos, a su vez, los hace más adecuados para la evaluación.
Porque una evaluación verdaderamente buena a menudo surge de comprender los límites de las capacidades de los modelos. Solo sabiendo cómo se construyen los modelos, conociendo los problemas que encuentran en tareas reales, es más fácil diseñar preguntas que puedan medir diferencias y exponer problemas.
Hoy en día, Chen Wenhu se ha unido al Super Intelligent Lab de Meta, donde su trabajo continúa centrándose en datos de preentrenamiento multimodal y evaluación, sirviendo a los modelos fundamentales de Meta.
La industria de la IA no carece de personas visibles. En la industria de la IA, los focos suelen centrarse en emprendedores, investigadores destacados y los responsables de las grandes empresas de modelos. Los lanzamientos de nuevos productos, noticias sobre financiación, modelos de código abierto y reajustes de equipo suelen atraer más la atención del público y hacen que estos nombres sean más conocidos.
Pero hoy en día, la participación del talento chino en el campo de la IA va mucho más allá de estas posiciones más visibles.
Este artículo proviene de la cuenta pública de WeChat "字母AI", autor: Xiaojinya






