La palabra "recursividad" ha cobrado repentinamente gran popularidad en los círculos de IA.
Dos empresas emergentes han adoptado directamente este término como nombre de sus compañías, y muchos laboratorios han comenzado a incluir en sus hojas de ruta un acrónimo de tres letras llamado RSI, que corresponde al nombre en inglés de Recursive Self-Improvement (Mejora Recursiva de Sí Misma). Al igual que la AGI, el RSI se está convirtiendo en una señal secreta de la industria que provoca tanto emoción como inquietud, incluso cuando su definición aún no está completamente alineada entre todos.
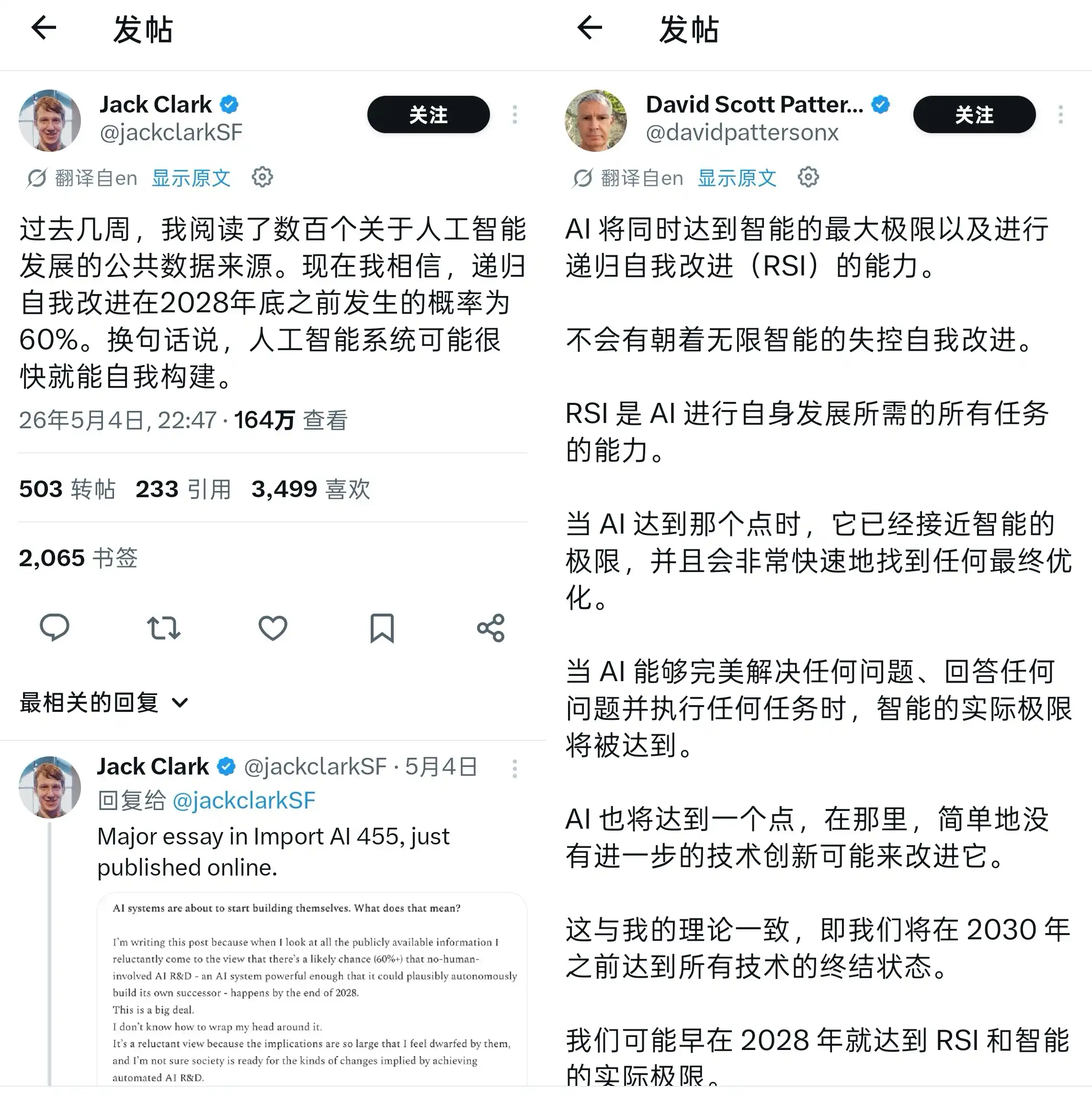
(Fuente de la imagen: X)
¿Qué es el RSI? En términos simples, consiste en que la IA se entrene a sí misma. En el ámbito técnico, el RSI siempre ha sido considerado uno de los principales indicadores del progreso de la inteligencia artificial, al nivel de la memoria, el razonamiento y la multimodalidad. La única limitación es el poder de cómputo, y el ser humano deja de ser una condición necesaria, ni siquiera un ayudante.
Suena a ciencia ficción, o quizás, ¿suena peligroso? Pero si lo pensamos con calma, esta no es la primera vez que el sector de la IA se apasiona. Desde AlphaGo en 2016 hasta ChatGPT en 2023, y la actual carrera armamentística de parámetros en los modelos grandes, la naturaleza de la industria de la IA es perseguir lo siguiente que "lo cambie todo". Desde la perspectiva de Leike Technology AGI (ID: leikejiagi), el RSI podría ser la próxima celebración.
El RSI está de moda: cuando la IA puede autoconstruirse mediante "recursividad"
En mayo de este año, el conocido investigador de IA Richard Socher fundó con gran repercusión una empresa llamada Recursive Superintelligence, cuyo nombre es directamente RSI.
Él declaró: "Nuestro objetivo central es construir una superinteligencia de mejora recursiva de sí misma en el verdadero sentido. Todo el proceso de concepción, implementación y verificación de la investigación se completará automáticamente."
Otro caso que suscita más conversación en los círculos internos es el proyecto Auto-Research impulsado por Andrej Karpathy: utilizar un grupo de agentes para entrenar modelos de lenguaje, haciendo que el modelo realice tareas de investigación simples por sí mismo y se mejore a sí mismo.
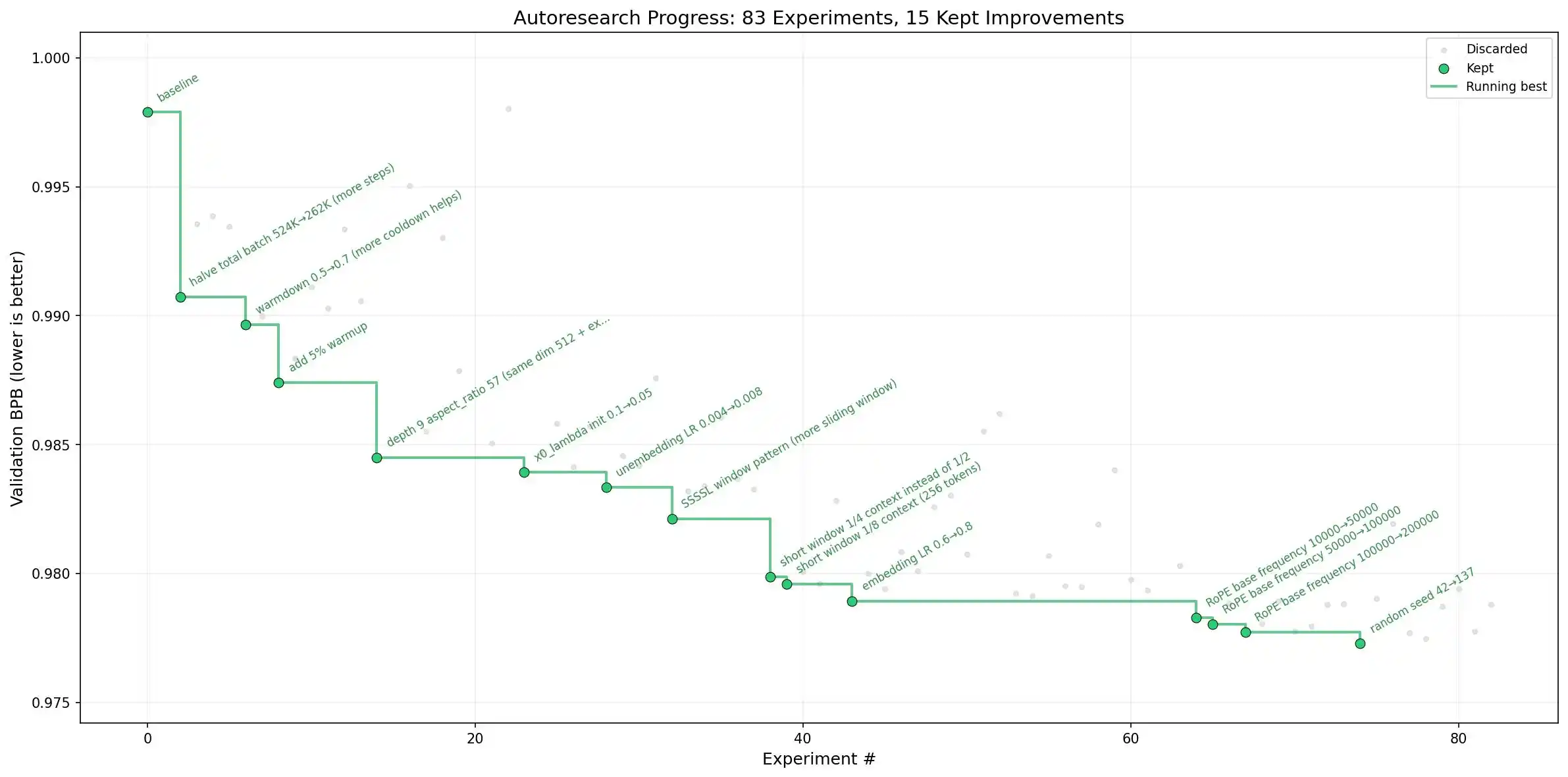
Fuente de la imagen: github
Andrej Karpathy es también una figura legendaria; dejó su huella en la conducción autónoma en Tesla y en el desarrollo de GPT en OpenAI. Ahora, él ha apostado por el RSI como su próxima etapa, avanzando de manera abierta y transparente, lo que también indica que realmente cree que esto es posible.
Curiosamente, él es sorprendentemente sincero sobre este proyecto, actualizando regularmente su progreso en Twitter, y también ha publicado el código en un repositorio público de GitHub. Por supuesto, Andrej Karpathy también dijo que su trabajo actual todavía implica iteraciones en modelos pequeños del nivel de GPT-2, "aún no es una investigación innovadora (por ahora)", pero esto ya es suficiente para impulsar a un gran número de investigadores a seguir su ejemplo.
Lo más importante es que Andrej Karpathy se unió recientemente al equipo de preentrenamiento de Anthropic. Anthropic tiene a Claude, y Karpathy tiene la metodología de auto-research. Si ambas partes se combinan, modelo grande + ciclo de autoevaluación, una vez que funcione, ya no será un juego a pequeña escala del nivel de GPT-2.

Fuente de la imagen: haimagazine
Otra empresa llamada Adaption lanzó una herramienta llamada AutoScientist, cuyo objetivo es automatizar el proceso de entrenamiento de modelos de vanguardia. La lógica es la misma que la de los auto-researchers de Andrej Karpathy: entrenar agentes para realizar mejoras graduales. La diferencia es que Adaption tiene mayores ambiciones, buscando abordar directamente un ciclo cerrado de entrenamiento para un modelo de vanguardia a gran escala completo.
En realidad, estas dos empresas representan dos enfoques diferentes: Andrej Karpathy valida gradualmente desde la base, construyendo impulso en la comunidad mientras publica código abierto; Adaption apunta directamente a escenarios comerciales de entrenamiento de modelos grandes, con una intención más fuerte de implementación. Quién logre hacerlo funcionar primero tendrá un impacto completamente diferente en toda la industria.
El CEO de Google lanza agua fría: aún no hemos llegado a ese punto
En cuanto al RSI, los expertos en IA también tienen opiniones diversas.
El CEO de Google, Sundar Pichai, fue bastante cauteloso en sus palabras al reconocer la realidad en un podcast el mes pasado: "(El RSI) es un continuo, ciertamente todos estamos progresando. Pero si lo describimos como lo hace la gente, eso representa una aceleración del siguiente nivel, con muchas implicaciones, pero aún no hemos llegado a ese punto."
Aunque esto es así, la descripción de "continuo" ya contiene bastantes cosas que dan qué pensar.
En enero de este año, un programador que lideró el desarrollo de Claude Code en Anthropic admitió que cerca del 100% del código del equipo fue escrito por Claude Code. Esto es, literalmente, la IA escribiéndose a sí misma. No es la IA asistiendo a los ingenieros a escribir código, sino que la herramienta de IA ya está reemplazando en cierta medida a los ingenieros para escribir su propio código.
Fuente de la imagen: Anthropic
Anthropic realizó una encuesta interna sobre la versión preliminar de Mythos: de 18 ingenieros, 5 consideraron que, si se mejoraran los sistemas complementarios, esta versión de Mythos podría reemplazar a un ingeniero de nivel L4, es decir, un programador intermedio capaz de asumir proyectos complejos de forma independiente sin supervisión en tiempo real.
Sin embargo, las deficiencias están claramente escritas: "Las principales debilidades reportadas por Claude incluyen: tareas ambiguas más allá del ciclo de gestión, comprender las prioridades organizacionales, el gusto, la verificación, el seguimiento de instrucciones y la epistemología". Lo que quiere decir es que sus debilidades son precisamente aquellas cosas que requieren autodirección, y la autodirección es la base del RSI.
Resulta interesante que el Centro de Estudios de Seguridad y Tecnología Emergente (CSET) de Georgetown reunió el año pasado a un grupo de expertos para estudiar específicamente el RSI. Estos expertos mostraron una clara división en sus evaluaciones: una parte anticipa una próxima "explosión de superinteligencia", mientras que otra parte espera un progreso más lento que eventualmente alcanzará una meseta.
Pero tenían un consenso: la recursividad hace que el futuro sea especialmente difícil de predecir.
En relación a esto, un artículo de la investigadora de METR, Ajeya Cotra, desglosa el proceso del RSI en varios hitos. Creo que este es el marco de análisis más útil actualmente.
El primer nivel se llama "suficiencia" (adequacy): después de eliminar completamente a los humanos, el sistema aún puede realizar investigación, incluso si no es tan buena como la humana, pero puede funcionar.
El segundo nivel se llama "paridad" (parity): la investigación realizada de forma independiente por la IA es de calidad comparable a la realizada de forma independiente por humanos.
El tercero se llama "supremacía" (supremacy): el rendimiento del sistema independiente de IA supera al de los sistemas de colaboración entre humanos e IA.
Es un poco como los niveles L2, L3, L4, L5 en la conducción autónoma. El juicio de Ajeya Cotra es: estamos muy cerca del primer nivel. Pero no dio un calendario para cuándo llegará el segundo nivel. Sin embargo, proporcionó un razonamiento muy claro: una vez que llegue el segundo nivel, la aceleración posterior superará con creces la del pasado, "posiblemente se alcanzará el tercer nivel en un año".
¿Por qué tan rápido? Porque en el momento en que se alcanza el segundo nivel, la IA se convierte en un equipo de investigación que no necesita dormir, no necesita reuniones, no necesita alinear OKRs. Puede probar, modificar y volver a probar las 24 horas del día sin interrupción. En cambio, la investigación humana, incluso con la persona más eficiente, tiene solo unas pocas horas de trabajo profundo efectivo al día, interrumpidas por innumerables distracciones y costos de comunicación. Una vez que este cuello de botella ya no existe, la aceleración es abruptamente ascendente.
En China nadie habla de RSI, pero DeepSeek y compañía ya rozan el borde
Después de hablar sobre el progreso en el extranjero, quizás te preguntes: ¿y en China?
Para ser francos, los fabricantes chinos rara vez mencionan públicamente el RSI. Que las empresas de IA extranjeras puedan escribir "superinteligencia recursiva" en su misión es algo casi impensable en China. Pero si hablamos de dejar que la IA se mejore a sí misma, los fabricantes chinos ya han rozado el borde en diferentes caminos de manera discreta.
El ejemplo más típico es DeepSeek. Gastan un orden de magnitud menos dinero que OpenAI, pero en muchas tareas de razonamiento ya pueden competir directamente. Esto se debe a una optimización extrema de la eficiencia algorítmica: arquitectura MoE, compresión extrema de parámetros de activación y pulido de estrategias de entrenamiento.
Aunque esto tiene poco que ver con el RSI, es un camino que utiliza métodos más inteligentes para reemplazar la fuerza bruta del poder de cómputo. Y este camino coincide precisamente con una de las lógicas centrales del RSI: permitir que el modelo encuentre el camino más inteligente durante la iteración.
En cuanto a Baidu Wenxin, el aprendizaje por refuerzo que impulsa la autooptimización del modelo ya es una práctica de ingeniería habitual. Aunque no utilizan el nombre RSI, están haciendo lo mismo: permitir que el modelo mejore continuamente a través de ciclos de autorretroalimentación en tareas específicas. Desde esta perspectiva, los fabricantes chinos no están dejando de hacer RSI; simplemente han convertido ciertos aspectos del RSI en prácticas de ingeniería diarias, solo que no le ponen ese nombre.

(Fuente de la imagen: generado por gemini)
Por supuesto, también existen brechas objetivas. La densidad de talento de OpenAI y Anthropic aún no es comparable con la de ninguna empresa china, lo que significa que, en la exploración del RSI, actualmente el estado es de seguimiento.
Pero la experiencia histórica nos dice que la velocidad de alcance de los fabricantes chinos después de que "el camino de la canalización esté claro" a menudo es sorprendente. El marco del RSI está siendo desglosado cada vez más claramente por los expertos extranjeros, y el código de Karpathy también está públicamente disponible en GitHub. Una vez que se consolida un camino reproducible, las capacidades de control de costos de los actores chinos y la densidad de escenarios de implementación serán una variable subestimada por el mercado.
Pero al mismo tiempo, también debemos ser un poco cautelosos. De hecho, los datos generados por la IA utilizados para entrenar la siguiente versión de la IA tienden a degradarse en calidad. La lógica del RSI es que la IA genera datos buenos, luego utiliza esos datos para entrenar a la siguiente generación de IA, haciendo que la siguiente generación sea más fuerte.
La realidad podría ser la contraria: los datos generados por la IA a menudo contienen sus propias alucinaciones, sesgos y degradación de calidad. Estos datos de segunda mano se alimentan a la siguiente versión, que a su vez produce resultados de tercera generación aún peores. Después de varias iteraciones, todo el sistema colapsa, como una fotocopiadora que copia constantemente copias de copias, donde la décima copia está borrosa.
La academia denomina a esto colapso del modelo, y ya existen artículos que verifican que este fenómeno existe realmente.
Además, el entorno ideal que requiere el RSI simplemente no existe en el mundo real. Para que este sistema funcione, dos premisas son indispensables: poder de cómputo ilimitado y un ecosistema de investigación colaborativa y abierta a nivel global.
La realidad es que el costo de entrenar un modelo de vanguardia ha alcanzado el nivel de miles de millones, la capacidad de producción de chips es limitada, la energía es limitada, los datos de calidad también están disminuyendo, los controles de exportación y la desvinculación tecnológica están dividiendo la investigación de IA en varios círculos que no se comunican entre sí. Ni las personas ni los bienes fluyen libremente. Si ni siquiera se pueden reunir estas condiciones básicas, ni hablar del RSI.
El RSI ya no es solo un problema técnico; también requiere un mundo lo suficientemente abierto, y si esta premisa se puede establecer, realmente no depende del círculo tecnológico.
Para terminar
Finalmente, comparto una observación que me parece interesante: en los últimos cinco años, toda la industria primero llevó a las personas a la "adoración de los parámetros" con el preentrenamiento a gran escala; luego, el RLHF (aprendizaje por refuerzo basado en la retroalimentación humana) hizo creer que "los valores se pueden ajustar"; y ahora, el RSI cuenta la historia de "la máquina ejecutando toda la cadena de desarrollo por sí misma". Cada paso hace que los humanos retrocedan un paso, no para abandonar la industria, sino para salir de la cadena de decisión.
Aunque este retroceso no necesariamente sea malo, es irreversible. Una vez que un eslabón es automatizado, la intuición, experiencia y capacidad de juicio humanos en ese eslabón se deterioran gradualmente, como descubrir que la capacidad de orientación efectivamente empeora después de dejar de usar el GPS.
Para entonces, puede que ni siquiera entendamos realmente cómo se fabrican las herramientas.






