Rompiendo el paradigma tradicional de preentrenamiento de grandes modelos, el equipo del exalumno post-00 de Tsinghua, Wang Guan, presenta otra innovación:
Utilizaron un modelo recurrente jerárquico (HRM) para reemplazar el Transformer estándar y propusieron el preentrenamiento eficiente HRM-Text que va más allá del Escalamiento.

Enlace al artículo: https://arxiv.org/abs/2605.20613
Utilizando aproximadamente entre 100 y 900 veces menos tokens de entrenamiento y entre 96 y 432 veces menos potencia computacional estimada que los modelos baseline estándar, HRM-Text logró un rendimiento comparable al de modelos de código abierto con parámetros de 2B a 7B.
Además, utilizando 1B de parámetros, 40B de tokens no repetidos y un coste de entrenamiento de aproximadamente 1500 dólares, HRM-Text logró los siguientes resultados en evaluaciones de referencia principales: MMLU 60.7%, ARC-C 81.9%, DROP 82.2%, GSM8K 84.5%, MATH 56.2%.
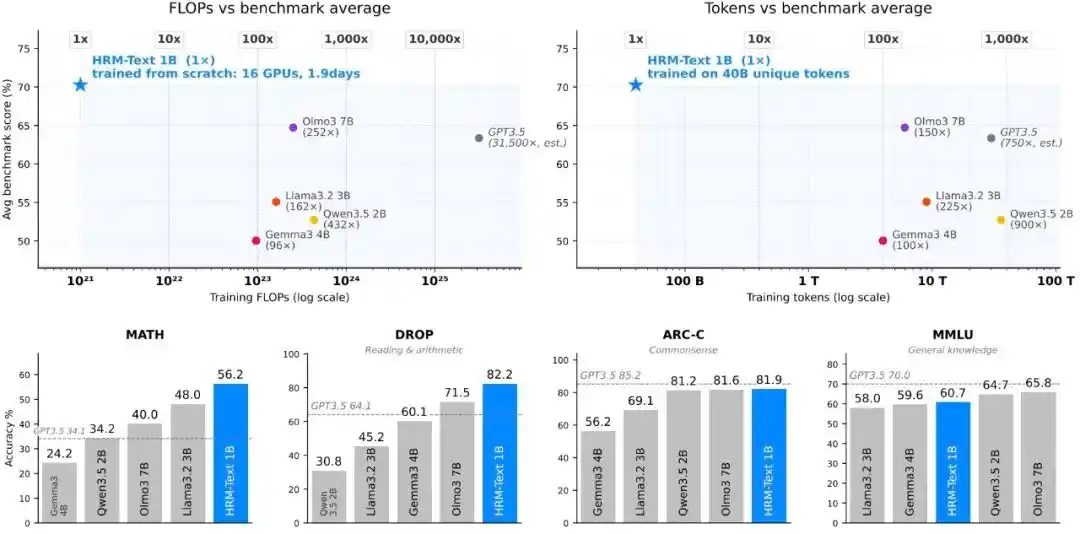
Figura| Eficiencia del preentrenamiento.
Sobre esta base, propusieron explícitamente: Los sesgos estructurales y los objetivos de entrenamiento específicos pueden reducir significativamente el umbral del preentrenamiento. Este esquema de entrenamiento puede hacer viable entrenar un modelo base desde cero.
¿Cómo está diseñado HRM-Text?
El preentrenamiento de modelos de lenguaje grandes (LLM) depende cada vez más de un puñado de instituciones con recursos suficientes de cómputo y datos. Entrenar un modelo base competitivo a menudo requiere billones de tokens, miles de GPUs, e incluso inversiones computacionales de millones de dólares.
Sin embargo, el modo de entrenamiento actual no es eficiente. Muchos de los cálculos se consumen en tokens irrelevantes como prompts, relleno de formato y ruido de páginas web, lo que hace que gran parte de la potencia de entrenamiento no sirva directamente para la inferencia.
En este trabajo, el equipo de investigación rediseñó la arquitectura y los objetivos de entrenamiento, haciendo que el preentrenamiento de HRM-Text sea relativamente más eficiente.
Arquitectura: Se adoptó un modelo recurrente jerárquico con dos escalas temporales, dividiendo el cálculo en un módulo lento H y un módulo rápido L. El Transformer estándar realiza una sola pasada hacia adelante por token, mientras que HRM realiza múltiples actualizaciones recursivas sobre el mismo token. Los módulos H y L ocupan cada uno aproximadamente la mitad de los parámetros centrales recurrentes, y el cálculo total equivale aproximadamente a desplegar recursivamente el mismo conjunto de parámetros 4 veces, aumentando la profundidad computacional sin incrementar el número de parámetros.
Objetivo de entrenamiento: Ya no se utiliza el preentrenamiento autorregresivo estándar de texto completo, sino que se entrena directamente en pares de instrucción-respuesta, calculando la pérdida solo en la parte de respuesta, y combinándolo con el enmascaramiento PrefixLM, que permite atención bidireccional en la parte de instrucción y generación con enmascaramiento causal en la parte de respuesta.
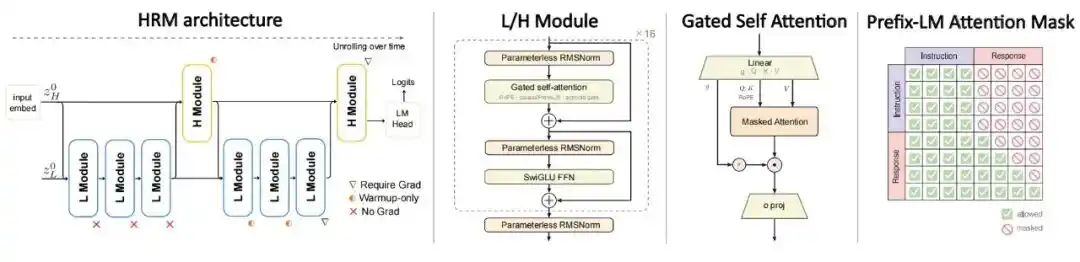
Figura| Arquitectura de HRM-Text.
Para mejorar la estabilidad del entrenamiento recurrente, el equipo introdujo MagicNorm y Warmup Deep Credit Assignment.
MagicNorm es una estrategia de normalización híbrida que aprovecha la asimetría entre las profundidades de cálculo hacia adelante y hacia atrás bajo retropropagación truncada (Truncated BPTT), utilizando PreNorm dentro de los módulos y añadiendo una normalización adicional en la salida del módulo, mejorando así la estabilidad del entrenamiento recurrente profundo.
Warmup Deep Credit Assignment propaga el gradiente solo en los últimos 2 pasos recursivos al inicio del entrenamiento, y luego lo extiende linealmente hasta los últimos 5 pasos. Este mecanismo permite que el modelo converja de manera estable con caminos de crédito más cortos, introduciendo gradualmente dependencias más largas.
¿Qué tal es su rendimiento?
Los resultados experimentales muestran que HRM-Text tiene ventajas claras en eficiencia arquitectónica, objetivos de entrenamiento y rendimiento general.
1. Con potencia computacional de entrenamiento fija, ¿es la arquitectura recurrente más efectiva?
Los resultados muestran que, bajo condiciones de FLOPs alineados, HRM 1B supera a Transformer 1B, Transformer 3B, Looped Transformer 1B y RINS 1B en la mayoría de los benchmarks; la comparación con TRM también indica que el entrenamiento de HRM es más estable.
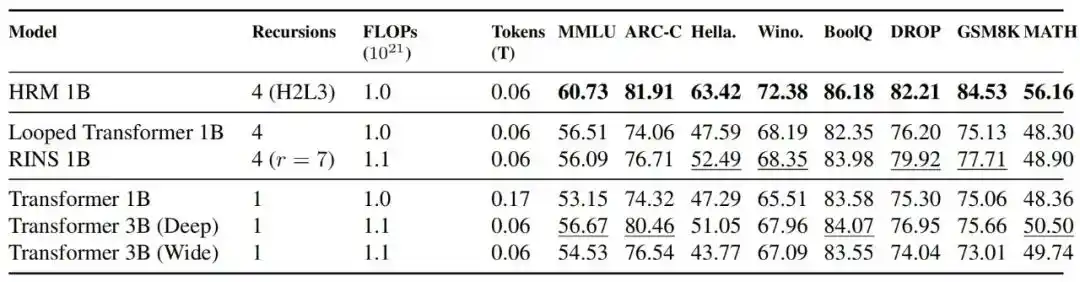
Figura| Comparación de rendimiento y estabilidad con modelos Transformer. HRM mantuvo dinámicas de entrenamiento estables en todas las escalas, mientras que los modelos Transformer mostraron inestabilidad severa a la escala de 1B de parámetros. Además, a escala de 0.6B, HRM necesitó solo 2 veces menos cálculo que los modelos Transformer para lograr un rendimiento competitivo en la mayoría de benchmarks.
2. ¿Ayudan el objetivo de completar tareas y PrefixLM?
Los experimentos de ablación muestran que, bajo condiciones de FLOPs alineados, el MMLU de Transformer 1B pasó de 40.55 en el autorregresivo estándar, a 47.72 tras introducir el objetivo de completar tareas, a 53.15 tras añadir PrefixLM, y a 60.73 tras cambiar a la arquitectura HRM.
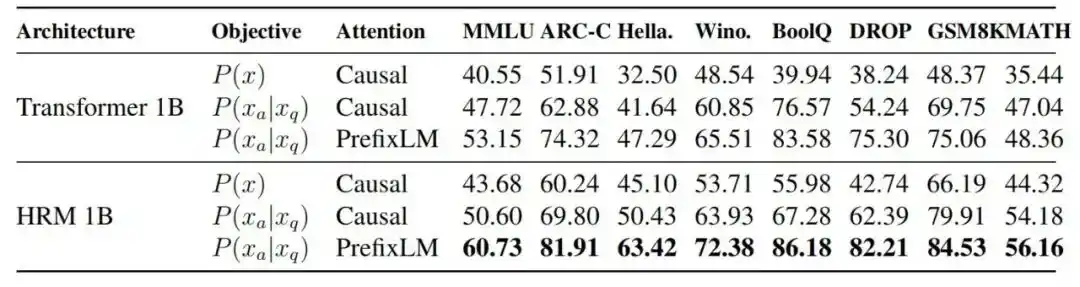
Figura| Comparación de rendimiento entre diferentes arquitecturas de modelo y objetivos de entrenamiento.
3. ¿Cómo se compara la eficiencia de HRM-Text con los modelos abiertos contemporáneos?
HRM-Text 1B alcanzó 60.7, 81.9, 82.2, 84.5 y 56.2 en MMLU, ARC-C, DROP, GSM8K y MATH respectivamente. Comparado con modelos abiertos que generalmente tienen presupuestos de entrenamiento mayores, utilizando solo 40B de tokens únicos y 1B de parámetros, entró en el rango de rendimiento de modelos de código abierto de 2B a 7B; los tokens necesarios para el entrenamiento fueron hasta 900 veces menos, y el coste computacional fue hasta 432 veces menor.
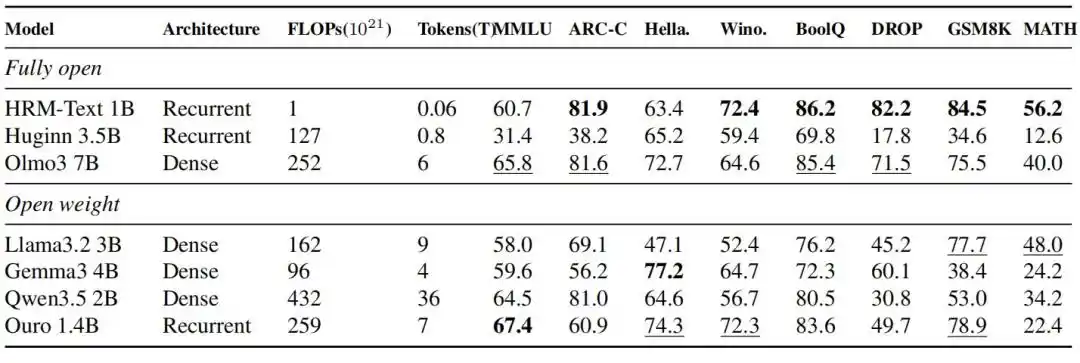
Figura| Resultados de evaluación de HRM-Text 1B comparado con modelos completamente abiertos contemporáneos y de pesos abiertos.
4. ¿Proporciona la estructura recurrente una mayor profundidad efectiva?
Los resultados muestran que el Transformer estándar y el Looped Transformer se estabilizan en capas relativamente superficiales, mientras que HRM mantiene cambios de representación más notables entre bloques, menor similitud de coseno y mayores valores KL de logit lens incluso en capas más profundas.
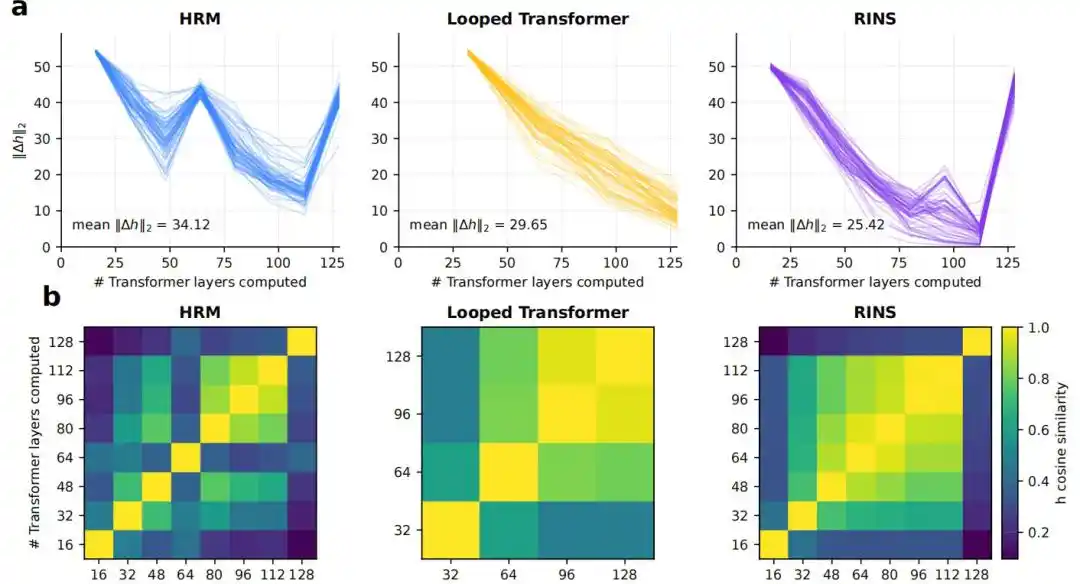
Figura| Análisis de profundidad efectiva.
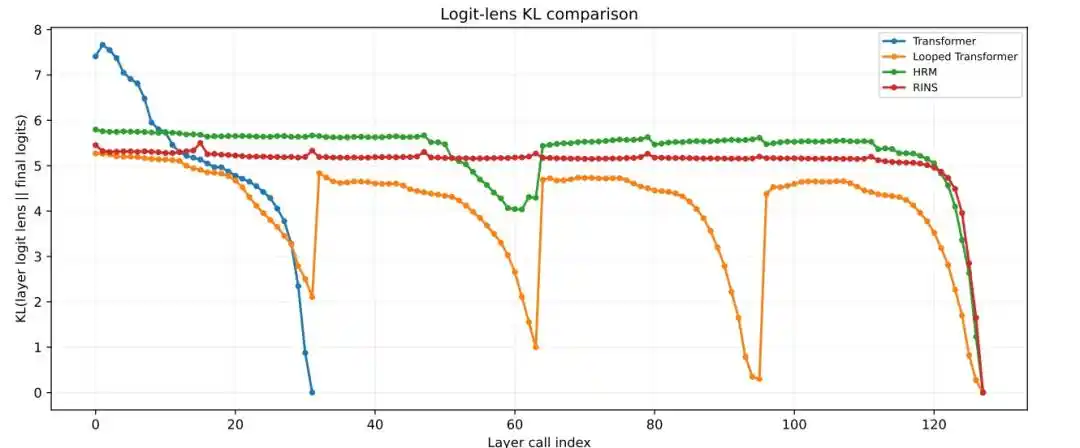
Figura| Análisis KL de Logit Lens por capas.
Limitaciones y direcciones futuras
Aunque HRM-Text mostró un rendimiento sólido en tareas intensivas de razonamiento, este método aún tiene limitaciones y propone direcciones de investigación futuras.
1. Avanzando hacia la desacoplamiento de "conocimiento" y "razonamiento"
Actualmente, una cobertura más amplia de conocimiento fáctico aún depende más de la escala del modelo y la amplitud de datos. HRM-Text solo se entrenó en 40B de tokens únicos, y las fuentes de conocimiento explícito solo constituyen una parte de la mezcla de datos formateados para tareas. En el futuro, los investigadores necesitarán diseñar por separado un núcleo de razonamiento compacto y un almacenamiento externo de hechos, entregando la amplitud de conocimiento a corpus seleccionados, módulos aumentados con recuperación o memoria aprendible.
2. Tiempo de cómputo adaptativo
La planificación recurrente de HRM-Text aporta una mayor profundidad serial efectiva, pero esto también significa que el modelo debe ejecutar un número fijo de pasos recursivos durante la inferencia. En el futuro, una dirección valiosa a explorar es introducir un mecanismo de tiempo de cómputo adaptativo, permitiendo que muestras simples detengan el cálculo antes y reserven el presupuesto recursivo completo para muestras difíciles, reduciendo el coste de inferencia.
3. El rango actual de validación de escalabilidad sigue siendo limitado
Los experimentos actuales de escalado solo cubren hasta el grupo de control Transformer de 3B de parámetros y HRM-Text de 1B. El equipo de investigación afirma que queda por ver en trabajos posteriores si aún se pueden mantener ventajas de eficiencia similares a escalas de modelo más grandes.
4. PrefixLM y el marco de inferencia
Actualmente, PrefixLM aún enfrenta ciertas limitaciones de implementación de ingeniería en despliegues prácticos. Aunque puede ejecutarse en marcos de inferencia de generación de texto estándar como vLLM, esto requiere que el marco admita máscaras de atención personalizadas durante la fase de prellenado. Extenderlo a escenarios de conversación de múltiples turnos requerirá además diseñar un mecanismo de KV-cache que garantice la visibilidad bidireccional dentro de los fragmentos del usuario, y también asegure que el proceso de generación del asistente siga sujeto a restricciones causales.
Para más detalles técnicos, consulta el artículo original.
Este artículo proviene del WeChat público "Titulares Académicos" (ID: SciTouTiao), autor: Xia Qiansi.







