Por | Alter
El 24 de abril por la mañana, el tan esperado DeepSeek V4 finalmente se dio a conocer.
Ese mismo día, DeepSeek-V4-Pro llegó a la cima de la lista de modelos de código abierto de Hugging Face, y se destacaron dos "innovaciones de nivel nuclear":
Primero, un contexto ultra-largo de un millón de tokens, pero con una caché KV de solo el 10% de la de V3.2, lo que fue elogiado por ingenieros de Amazon como una solución a la escasez de HBM;
Segundo, la adaptación a chips nacionales, con una estrecha colaboración con Huawei durante el desarrollo y una adaptación inmediata a chips nacionales como Ascend y Cambricon.
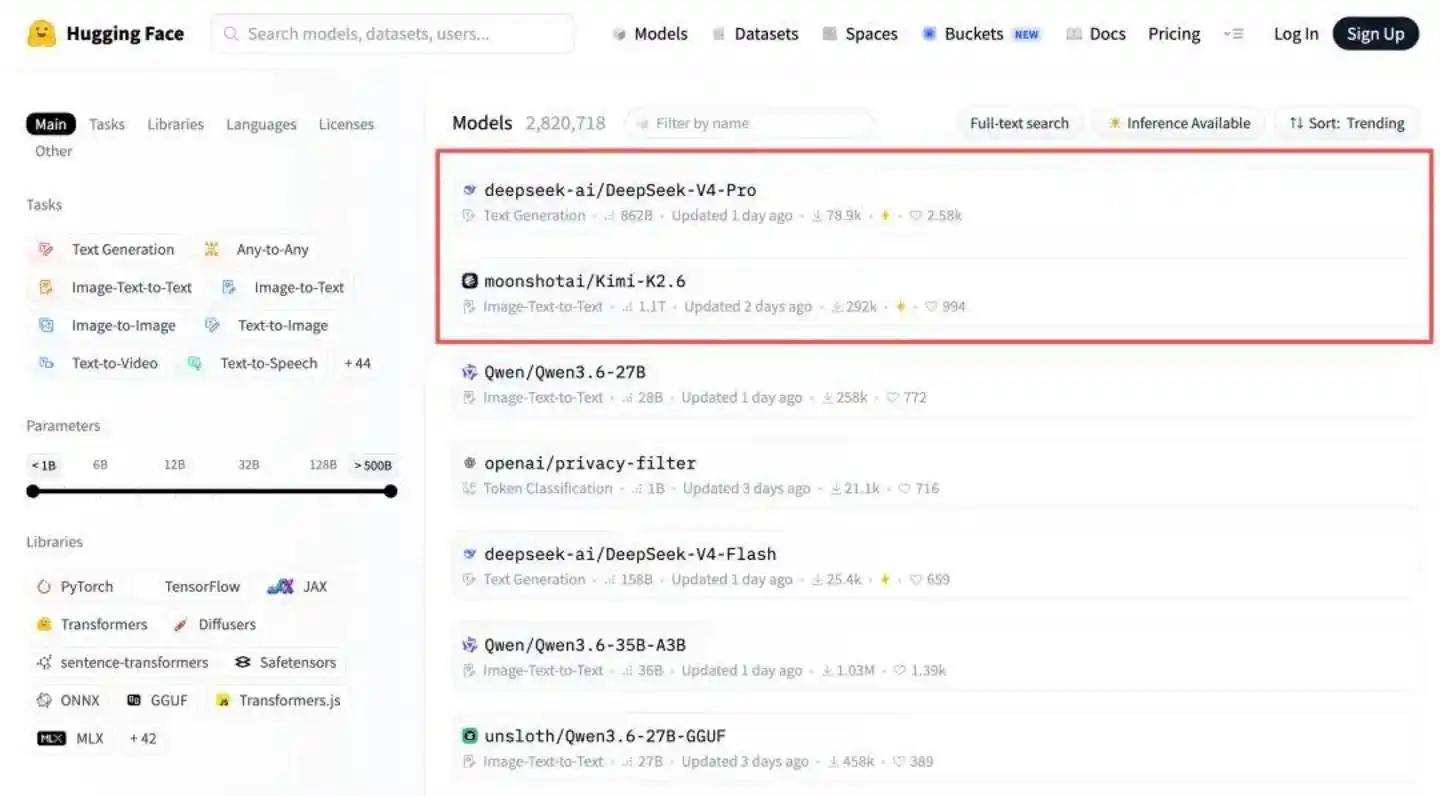
Coincidentemente, el segundo lugar en la lista de modelos de código abierto de Hugging Face lo ocupó Kimi K2.6, lanzado y de código abierto en la noche del 20 de abril.
Si esto hubiera sucedido al otro lado del Pacífico, el "choque" de dos modelos de billones de parámetros habría llevado a ataques mutuos por valoraciones y mapas comerciales, pero en China se desarrolló una escena completamente diferente: no hubo acusaciones, ni guerras de relaciones públicas con corrientes ocultas, e incluso hubo una "intercambio" en la base tecnológica.
Detrás de lo "inusual" se esconde una divergencia en el camino tecnológico de la IA entre China y EE.UU.: Silicon Valley está enloquecido "levantando muros altos", tratando de proteger los intereses establecidos con el código cerrado; los fabricantes de modelos grandes de China eligen "derribar muros", evolucionando de manera colaborativa en el suelo del código abierto.
01 Silicon Valley atrapado en el "Juego de Tronos"
A diferencia de la ruta de código abierto de los modelos grandes chinos, que florecen en diversidad, los líderes de IA de Silicon Valley, como OpenAI, Anthropic y Google Gemini, son todos defensores del código cerrado.
Cuando la innovación tecnológica de vanguardia queda encerrada en sus respectivos centros de datos, frente a la presión de los costos de computación y las expectativas del mercado de capitales, el "espíritu de Silicon Valley", conocido por su apertura y colaboración, se desvanece gradualmente, y los jugadores caen inevitablemente en un "juego de poder" de suma cero.
En los últimos dos años, la "guerra fría" tecnológica se ha convertido en desacuerdos públicos, y el medio más típico es competir por la atención: en momentos clave del lanzamiento de productos de la competencia, lanzar rápidamente actualizaciones importantes propias para contrarrestar su visibilidad se ha convertido en una operación habitual en Silicon Valley.
Ya en mayo de 2024, OpenAI y Google lanzaron simultáneamente nuevos productos de IA, uno diciendo que GPT-4o era líder mundial, el otro que la familia Gemini podía cubrir todo el ecosistema y todos los caminos. Finalmente, los CEOs de ambas empresas no pudieron contenerse y se burlaron públicamente del otro en las redes sociales.
No solo la "lucha" con Google, la competencia entre OpenAI y Anthropic también se ha intensificado: el 16 de abril, Anthropic acaba de lanzar el nuevo modelo Claude Opus 4.7, y OpenAI anunció dos horas después una actualización importante de Codex, proclamando "Codex for (almost) everything". Está claro que la coincidencia de timing no fue casualidad, sino una "intervención" cuidadosamente planificada por OpenAI contra Anthropic.
Además de las "luchas culturales" en el campo de la opinión pública, las "luchas físicas" de desacreditación mutua también se han convertido en la norma en Silicon Valley.
Anthropic anunció con gran fanfarria el 7 de abril que sus ingresos anualizados habían alcanzado los 300 mil millones de dólares, superando con éxito los 250 mil millones de OpenAI.
Una semana después, el director de ingresos de OpenAI dijo sin rodeos en una carta interna a todos los empleados: los 300 mil millones de ingresos anualizados anunciados por Anthropic tenían serias fallas, porque utilizaban el "método bruto", incluyendo en sus ingresos totales las comisiones completas destinadas a proveedores de servicios en la nube como Amazon y Google, lo que resultó en una sobreestimación de unos 80 mil millones de dólares en los ingresos anualizados.
La práctica de desacreditar a un oponente en una carta interna no es común en la industria tecnológica, y el objetivo无非 era decirles a los inversores que el mito del crecimiento de Anthropic estaba inflado.
Y una vez que surge la hostilidad, afecta cada decisión.
Cuando Anthropic se "enfrentó" al Pentágono por negarse a eliminar ciertas cláusulas de seguridad de un contrato, OpenAI anunció pocas horas después que había llegado a un acuerdo con el Departamento de Defensa de EE.UU.
En el "Super Bowl" de 2026, Anthropic invirtió mucho en un anuncio que decía: "La publicidad está entrando en el campo de la IA, pero no entrará en Claude." Se podría decir que fue un "golpe directo" a OpenAI, que acababa de comenzar a probar funciones publicitarias.......
¿Por qué los antiguos "hermanos de armas" han llegado a un punto de confrontación?
La raíz está en la lógica inherente del modelo comercial de código cerrado: la base de supervivencia del código cerrado es construir un foso, y la premisa para construir un foso es bloquear la difusión tecnológica, monopolizando la fuerza productiva más avanzada. Además, la incompatibilidad de las rutas tecnológicas y la oposición de narrativas de productos forman naturalmente un equilibrio de Nash: quien "cese el fuego" primero, verá colapsar su narrativa de marca, hundiéndose cada vez más en el pantano del consumo interno.
02 "Evolución colaborativa" del campo de código abierto
Volviendo la mirada a China, el guión es completamente diferente.
Hace más de un año, la aparición de DeepSeek-R1 frenó la carrera emprendedora de modelos grandes, y los "seis pequeños tigres" de modelos grandes en la ronda final fueron los primeros en verse afectados. La mayor diferencia con Silicon Valley es que DeepSeek no actuó como un "tiburón" que se come todos los peces en el estanque, sino como un pez globo que activó todo el ecosistema de modelos grandes de China, haciendo que todos abrazaran el código abierto.
Un ejemplo directo es Moon Dark Side (月之暗面), cuya trayectoria de crecimiento coincide高度 con la de DeepSeek: ambos son equipos初创 que comenzaron en 2023, ambos mantienen una estructura de equipo con muy pocas personas pero una alta densidad de talento, y ambos son firmes creyentes de la Ley de Escalado (Scaling Law).
En julio de 2025, Moon Dark Side lanzó el primer modelo de código abierto de un billón de parámetros del mundo, Kimi K2, y en el informe técnico no ocultó que había adoptado la arquitectura MLA de código abierto de DeepSeek. Para los modelos grandes, la peor pesadilla al procesar textos largos es el muro de memoria, y lo disruptivo de la arquitectura MLA es que comprime ingeniosamente la caché KV en más del 93%.
Con el "estándar industrial" contribuido por DeepSeek, los equipos de modelos grandes, incluido Moon Dark Side, no necesitan reinventar la rueda, reduciendo rápidamente los costos de inferencia.
La historia no se detuvo ahí.
Al revisar la documentación técnica de DeepSeek V4, se describe en detalle la arquitectura del modelo, y una actualización importante fue cambiar el optimizador de la mayoría de los módulos de AdamW a Muon, logrando una velocidad de convergencia más rápida y una mayor estabilidad en el entrenamiento.
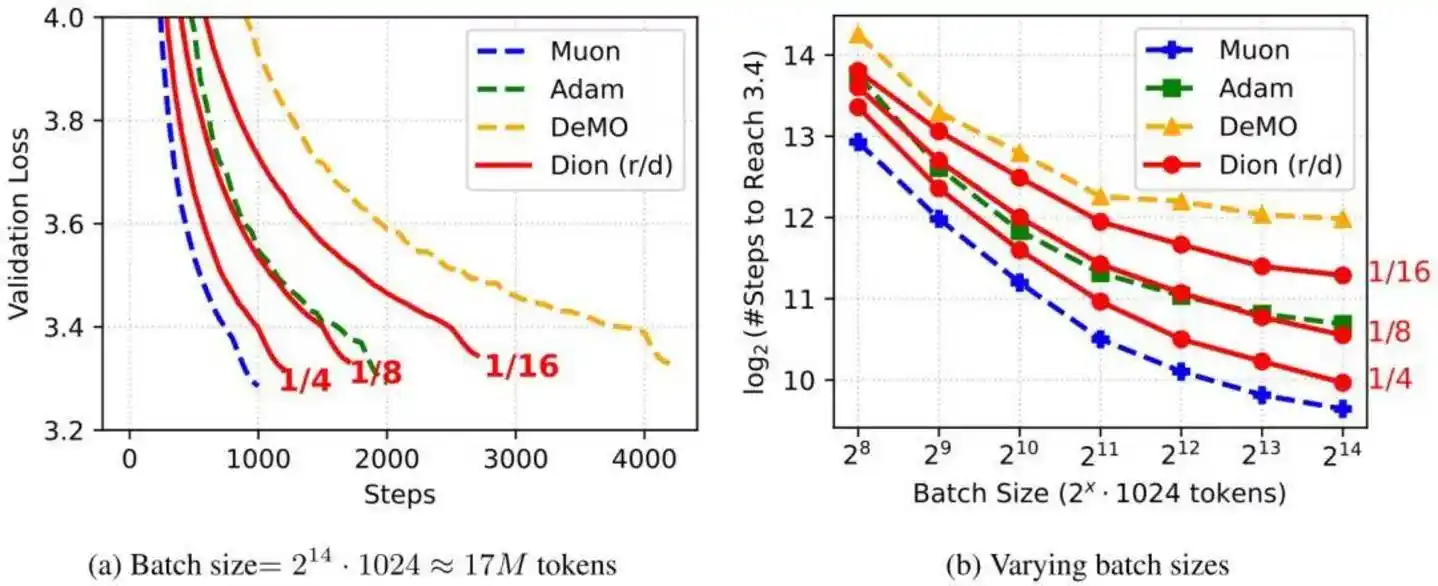
En la documentación técnica de Kimi K2.6, también se menciona el optimizador Muon, que logró una mejora de eficiencia de 2 veces con la misma cantidad de entrenamiento.
El optimizador Muon, mencionado en ambos modelos, fue propuesto por primera vez por el investigador independiente Keller Jordan en un blog a fines de 2024. El equipo de Moon Dark Side, también afectado por AdamW, realizó mejoras clave de ingeniería en Muon a principios de 2025, añadiendo capacidades como Weight Decay y control RMS, y lo renombró como MuonClip.
Moon Dark Side validó primero la estabilidad del optimizador Muon en Kimi K2, logrando "zero Loss Spike" durante todo el pre-entrenamiento. DeepSeek, al entrenar el modelo grande V4, también adoptó el optimizador Muon ya validado.
Cabe señalar que la "evolución colaborativa" de los modelos grandes de código abierto no ha caído en la homogeneización, sino que avanza por un camino de "armonía en la diferencia".
Por ejemplo, DeepSeek-V4 se centra en攻坚 las capacidades centrales del modelo base, consolidando further el techo de rendimiento de los modelos grandes de código abierto globales, proporcionando a toda la industria una base fundamental con un rendimiento comparable al de los flagships de código cerrado; Kimi K2.6 se dedica a la implementación de ingeniería de Agent, resolviendo el punto doloroso de la ejecución autónoma de larga distancia de los modelos grandes, abriendo el camino clave para que los modelos grandes entren en escenarios de producción reales.
En todo el proceso, no hubo negociaciones comerciales prolongadas, ni batallas de patentes tensas. En el campo de código abierto, la innovación tecnológica fluye libremente como el agua, y quien lo hace bien, todos lo usan.
Absorbiendo nutrientes del ecosistema de código abierto, complementándose en las rutas tecnológicas. Los fabricantes de modelos grandes de China están demostrando al mundo otra posibilidad beyond Silicon Valley con sus acciones.
03 EE.UU. "construye muros", China "construye caminos"
Mientras se elogia la evolución colaborativa del código abierto,必须 enfrentar una realidad comercial.
Actualmente, los ingresos anualizados de OpenAI y Anthropic superan los cien mil millones de dólares, mientras que los ingresos de los principales fabricantes de modelos grandes de China acaban de cruzar la puerta de los mil millones de dólares anualizados.
La valoración de OpenAI en el mercado secundario es de aproximadamente 880 mil millones de dólares, la valoración de Anthropic ya se ha disparado a alrededor de 1 billón de dólares, mientras que las valoraciones de la nueva ronda de financiación de Kimi y DeepSeek son de 180 mil millones y 200 mil millones de dólares, respectivamente.
Algunos gritan que la capitalización de mercado de los fabricantes de modelos grandes de China está subestimada, mientras que otros creen: "Poder convertir la reputación tecnológica en dinero real es una prueba de vida o muerte para los fabricantes chinos." Por un tiempo, las discusiones sobre la "relación costo-beneficio" del código abierto han sido clamorosas.
Para ver el resultado final, se puede partir de la etapa competitiva de los modelos grandes:

La primera etapa fue "competir por parámetros, competir por Benchmark". Para fines de abril de 2026, esta etapa基本 termino, y las puntuaciones de cada uno en la lista ya no mostraron diferencias sustanciales.
La segunda etapa es "competir por eficiencia de entrenamiento, competir por costos de inferencia, competir por innovación arquitectónica". Esta es exactamente la etapa actual, y también es el resultado inevitable de la presión de los costos de computación.
La tercera etapa será "competir por sistemas Agent, competir por ecosistema, competir por desarrolladores". Cuando los tokens pasen de ser tráfico gratuito a "combustible" para ejecutar tareas, la prosperidad del ecosistema决定ará la vida o la muerte.
¿En qué nicho ecológico se encuentran los modelos grandes de código abierto de China? Encontramos dos conjuntos de datos comparativos直观.
Uno es el costo de entrenamiento.
GPT-5, lanzado en agosto de 2025, costó más de 500 millones de dólares entrenarlo; Kimi K2 Thinking, en el mismo período, costó aproximadamente 4.6 millones de dólares; DeepSeek no公布ó el costo de entrenamiento de los modelos de la serie V4, pero el modelo V3 costó solo 5.576 millones de dólares...... Los fabricantes de modelos grandes de China usaron recursos que no llegaban a las migajas de OpenAI para entrenar modelos del mismo nivel.
El otro es el volumen de llamadas.
Después de entrar en 2026, los datos de la plataforma de agregación de múltiples modelos OpenRouter mostraron: impulsado por productos Agent como OpenClaw, el consumo global de tokens mostró un crecimiento exponencial, y el "equipo de ensueño" de código abierto de China, con su reputación de "bueno y barato", ha superado a EE.UU. en volumen de llamadas durante varias semanas consecutivas.
La razón no es difícil de explicar.
El campo de código abierto de China ya ha validado la "rueda de retroalimentación positiva": la empresa A abre el código de la tecnología subyacente, la empresa B la adopta y realiza optimizaciones de ingeniería, y luego devuelve los resultados y experiencias de optimización a todo el ecosistema. Si la evolución de los modelos de código cerrado se basa en un crecimiento lineal apilando cantidades masivas de computación, lo que espera a la ruta de código abierto será la difusión exponencial traída por la colisión mutua de innovaciones tecnológicas.
Según el informe de investigación de JPMorgan, la tasa de crecimiento anual compuesto del consumo de tokens de inferencia de IA en China entre 2025 y 2030 será de aproximadamente 330%, pasando de 10 billones de tokens en 2025 a 3900 billones de tokens en 2030, un aumento de 370 veces.
Es decir, 2026仍处于 el estallido inicial de la IA, y en los próximos 5 años aún habrá cientos de veces más oportunidades de crecimiento,远未到 el momento de sacar conclusiones definitivas.
Precisamente por la confianza en las oportunidades a largo plazo, mientras los gigantes de Silicon Valley construyen muros desesperadamente, los fabricantes de modelos grandes de China eligen complementarse colaborativamente, consolidando constantemente el camino hacia AGI.
04 Para terminar
¿Quién tendrá la última palabra en esta ola de IA轰轰烈烈? La respuesta no solo concierne a los modelos, sino también a la autonomía y control de la computación. Si comparamos los modelos con "bombas atómicas", la computación nacional que se libera del bloqueo tecnológico externo es el "cohete" que envía la bomba atómica al cielo.
Es alentador que la integración entre los modelos nacionales y la computación nacional sea cada vez más estrecha: en la documentación técnica de DeepSeek V4, el NPU Ascend y la GPU de NVIDIA se enumeraron juntos en la lista de verificación de hardware; Moon Dark Side, en su artículo más reciente, ejecutó el prellenado y decodificación de la inferencia de modelos grandes en diferentes chips, abriendo la puerta a la participación a gran escala de chips nacionales en la inferencia de modelos.
A principios de 2025, DeepSeek R1 le dio a los modelos grandes nacionales la oportunidad de sentarse a la mesa; para 2026, el campo de modelos grandes de código abierto de China, en colaboración sinérgica, está creando constantemente más capital duro para definir las reglas del juego.







