Por | AIDeepDive
Hoy, la acción de Zhipu (02513.HK), conocida como "la primera acción del mundo en modelos de gran tamaño", volvió a dispararse.
Durante la sesión, el incremento llegó a superar el 30%. Cerró en 1282 dólares de Hong Kong, con una ganancia diaria superior al 26%, alcanzando una capitalización bursátil de 571.570 millones de dólares de Hong Kong, estableciendo un nuevo máximo histórico.
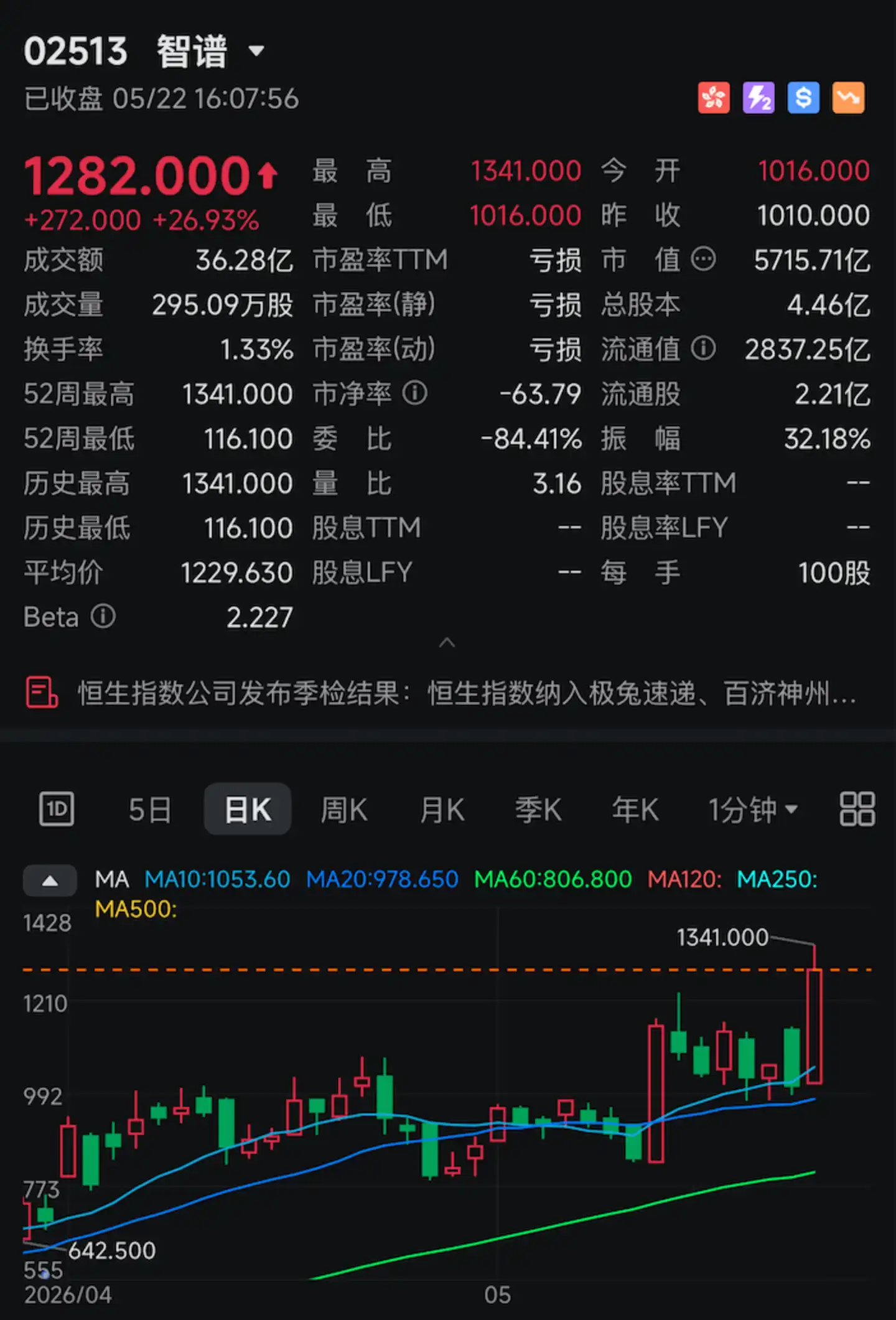
Lo que desencadenó este fuerte repunte fue un indicador técnico específico: 400 tokens/s.
El 22 de mayo, Zhipu abrió oficialmente su API de alta velocidad GLM-5.1 (GLM-5.1-highspeed) para clientes empresariales, con un parámetro clave: una velocidad de generación del modelo de 400 tokens por segundo, estableciendo un nuevo récord mundial para la velocidad de API de proveedores de modelos de gran tamaño.
Inicialmente pensé que era otro ejercicio de relaciones públicas de los modelos nacionales, pero tras examinar los detalles técnicos, finalmente comprendí la lógica detrás del movimiento del mercado de capitales.
¿Qué significa 400 tokens/s?
El modelo puede generar aproximadamente 200 caracteres chinos por segundo, equivalente a la producción intensa de un escritor profesional en un minuto, comprimida en solo un segundo.
La cantidad de texto que un creador tardaría días en escribir, la versión de alta velocidad de GLM-5.1 la puede completar en 1 minuto; una tarea de reestructuración de sistemas que a un ingeniero le tomaría 3 días, puede ejecutarse en el tiempo que se tarda en tomar un café.
01 La velocidad es más importante de lo que crees
La velocidad siempre ha sido la dimensión más fácil de pasar por alto en la competencia de modelos de IA.
En los últimos tres años, la carrera armamentística de modelos de gran tamaño se ha centrado en dos frentes: escala de parámetros (modelos más grandes e inteligentes) y guerra de precios (tokens más baratos y accesibles). "Rápido" nunca fue el protagonista.
Esto se debe a que, tradicionalmente, la "velocidad" se lograba reduciendo el tamaño del modelo. Para acelerar, se debía usar un modelo más pequeño y simplificado, a costa de una reducción de capacidades.
La importancia de la versión de alta velocidad de GLM-5.1 radica en que, manteniendo las capacidades completas de su modelo base insignia, lleva la velocidad a 400 tokens/s.
Tanto a nivel nacional como internacional, es la primera vez que se logran, sin compromisos, "capacidades insignia" y "latencia extremadamente baja".

¿Por qué es tan crucial la velocidad? Porque el campo de batalla principal de la IA está experimentando una migración fundamental.
Cuando la IA pasa de los ChatBots a la era de los Agentes (Agent), la conversación ya no es el escenario principal. Para que un Agente complete una tarea, a menudo necesita que el modelo se invoque a sí mismo decenas o incluso cientos de veces: escribir código, llamar a APIs, buscar información, usar herramientas...
En este modo de trabajo, la latencia entre cada invocación se acumula y amplifica inexorablemente. En una tarea que requiere 50 invocaciones, si se ahorra 1 segundo en cada una, toda la tarea es casi 1 minuto más rápida. Para asistentes de programación con IA, interacciones de voz o sistemas de decisión empresarial, esta diferencia puede ser decisiva.
En un nivel más profundo, con un presupuesto de tiempo fijo, un razonamiento más rápido significa que el modelo puede completar trayectorias de razonamiento más profundas y realizar más rondas de autoverificación. La velocidad está pasando de ser una métrica del sistema a convertirse en el límite mismo de la inteligencia.
02 ¿Qué tan difícil es lograr velocidad?
Entonces, ¿cuál es aproximadamente el nivel actual de la industria en cuanto a velocidad?
Entre los principales proveedores, GPT-4o de OpenAI ronda los 100–150 tokens/s, la serie Claude Sonnet de Anthropic está en 80–120 tokens/s, y la mayoría de las APIs de modelos insignia nacionales están en el rango de 50–100 tokens/s. 400 tokens/s es aproximadamente de 3 a 5 veces el promedio de la industria.
Lo más crítico es que esta brecha no se puede llenar simplemente asignando más capacidad de cómputo.
Un servidor con 8 tarjetas gráficas H200, en teoría, puede mover hasta 38 TB de datos por segundo. Para GLM-5.1, generar un solo token solo requiere leer unos 42 GB de parámetros activados. En teoría pura, debería acercarse a los 1000 tokens/s.
Pero los sistemas reales a menudo solo logran unas decenas de tokens/s.
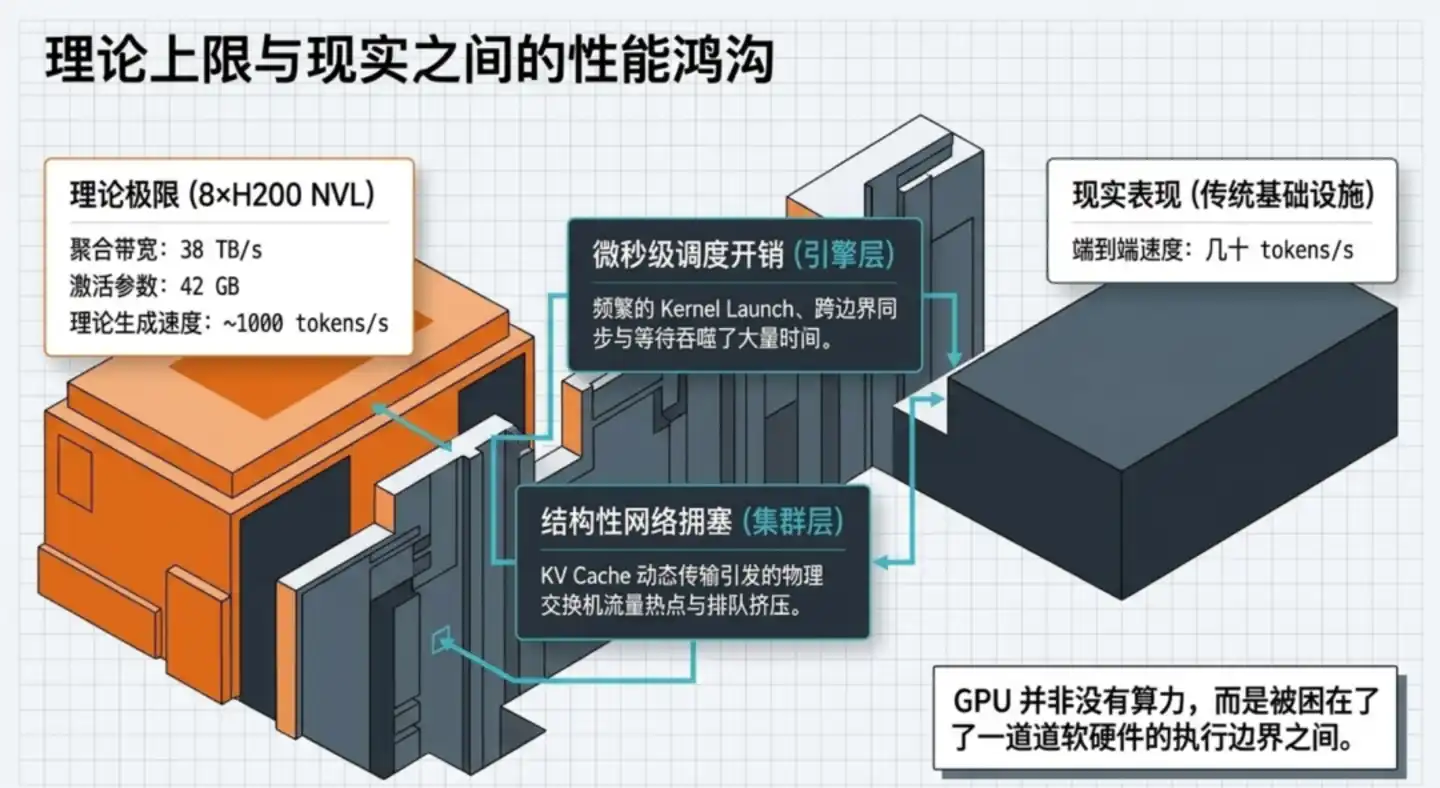
Es un abismo de un orden de magnitud. Las GPU no son lo suficientemente lentas, sino que gran parte del tiempo se pierde en esperas, tiempos de inactividad y programación ineficiente.
Zhipu logró este avance en velocidad gracias a innovaciones simultáneas en tres niveles: el motor de inferencia, las estrategias de paralelización y la arquitectura de red.
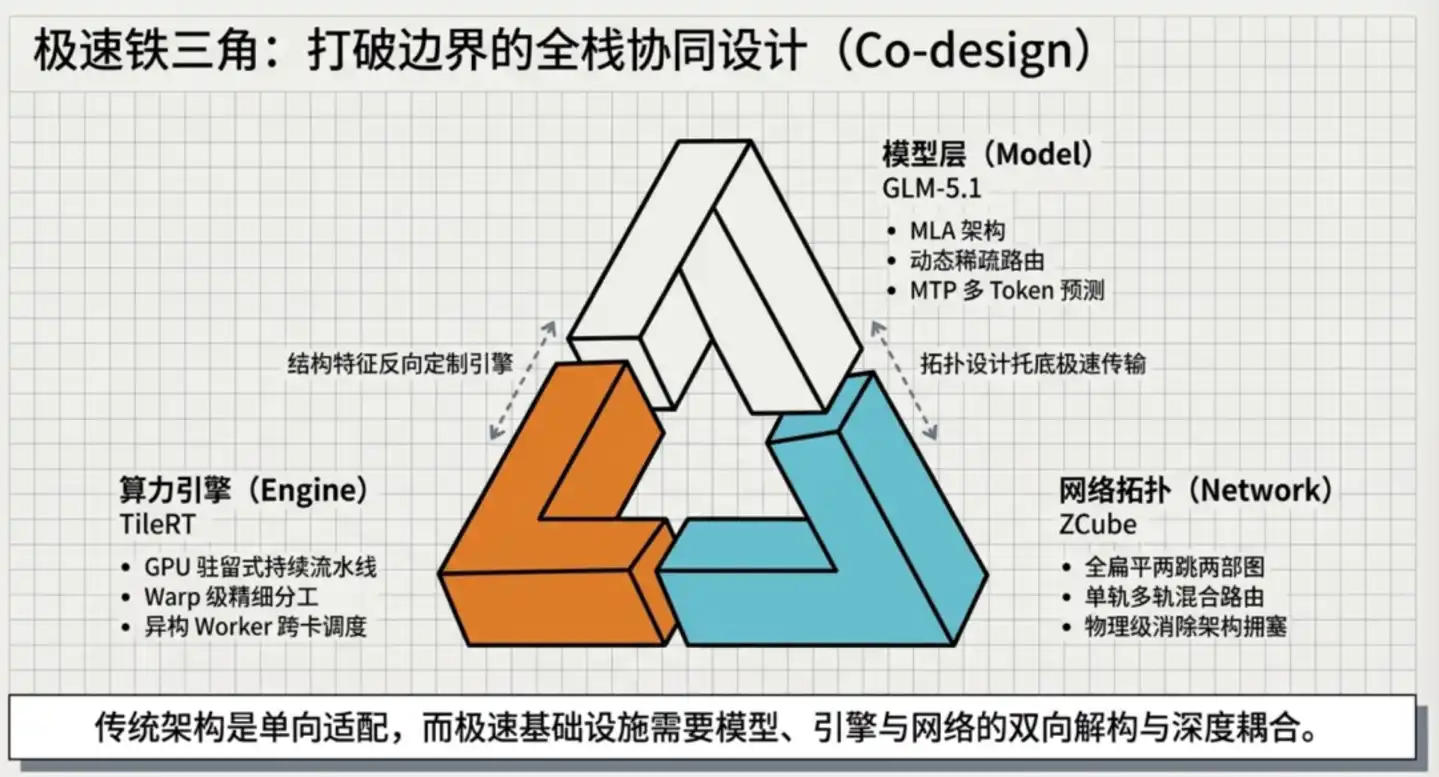
03 Tres capas tecnológicas superpuestas, acercándose al límite físico del hardware
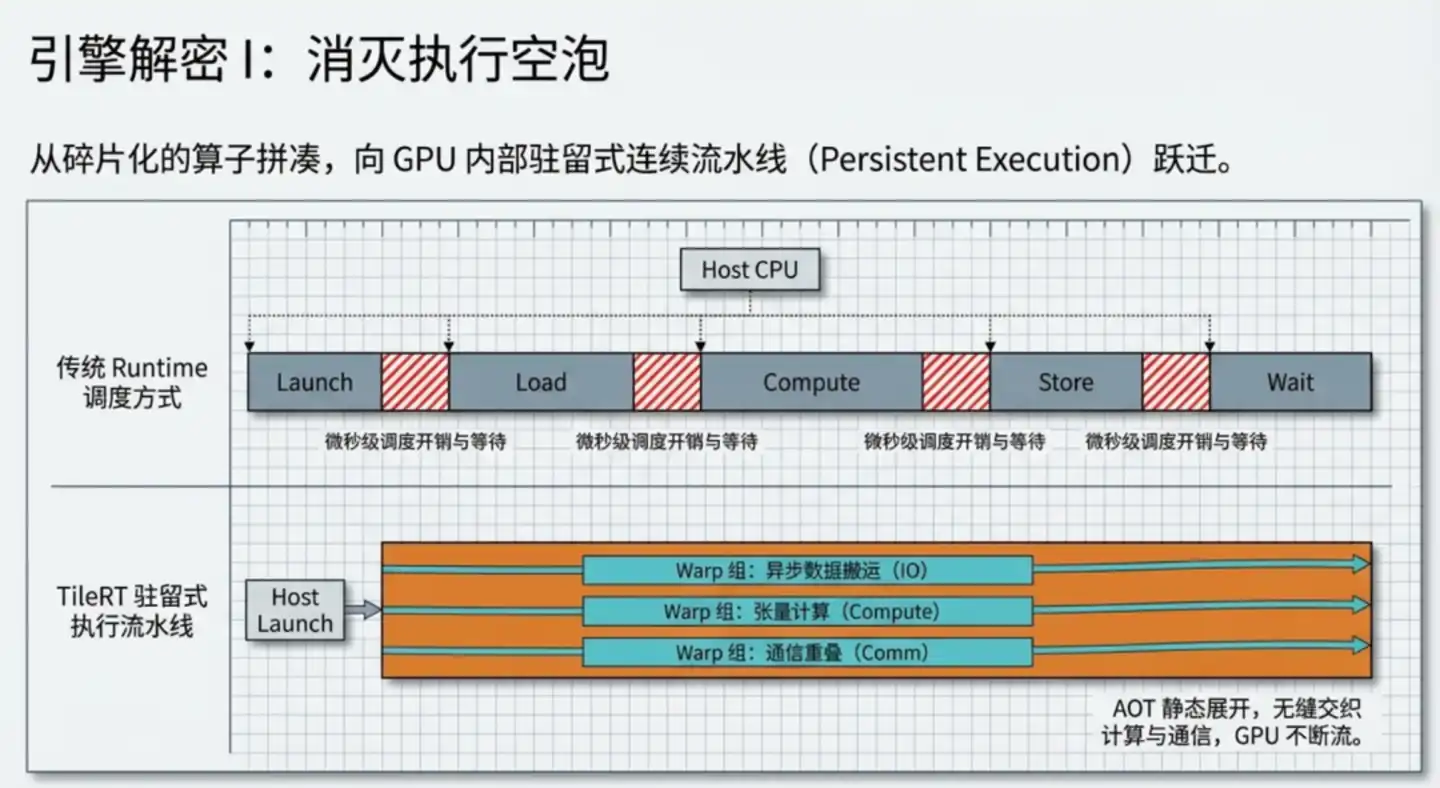
Originalmente, los modelos de gran tamaño funcionaban así: el modelo se descomponía en operadores independientes, cada uno iniciaba un núcleo de cálculo (kernel) por separado, se calculaba, se detenía, se sincronizaba y esperaba, y luego se iniciaba el siguiente.
En la fase de entrenamiento, donde cada cálculo tarda segundos o incluso minutos, estos costos de inicio y espera eran insignificantes. Pero durante la inferencia, al generar un solo token, un paso crítico puede requerir solo unas decenas de microsegundos, y los costos de inicio y espera se vuelven relativamente inaceptables.
La idea central de TileRT: compilar todo el modelo en un motor que se ejecute continuamente, iniciarlo una vez y que nunca se detenga.
TileRT despliega estáticamente toda la lógica de cálculo del modelo en una única línea de producción continua durante la fase de compilación del código. En tiempo de ejecución, la GPU mantiene un funcionamiento continuo a alta velocidad, el cálculo, el movimiento de datos y la comunicación avanzan en paralelo, y los resultados intermedios se mantienen en la memoria caché interna de alta velocidad de la GPU, sin necesidad de escribirlos repetidamente en la memoria de vídeo más lenta y volver a leerlos.
Aquí hay un detalle de diseño clave: Especialización de Warp.
Para entender Warp, primero hay que entender cómo funciona una GPU. La mayor diferencia entre una GPU y una CPU es que la GPU tiene miles de unidades de cálculo relativamente simples en su interior. Estas unidades se agrupan en conjuntos de 32, y este grupo se llama Warp.
Las 32 unidades dentro del mismo Warp siempre deben actuar de forma sincronizada y ejecutar la misma instrucción, como un pelotón en el ejército donde el sargento ordena a todos hacer el mismo movimiento simultáneamente.
En los marcos tradicionales, todos los Warps ejecutan la misma secuencia de instrucciones; TileRT asigna diferentes responsabilidades a diferentes grupos de Warps: algunos se encargan específicamente de mover los próximos lotes de datos de antemano, otros se encargan específicamente de los cálculos matemáticos, y otros se encargan específicamente de comunicarse con otras GPUs. Los tres grupos trabajan simultáneamente, coordinándose en una línea de producción sin esperarse unos a otros.
Es como pasar de "un trabajador que transporta ladrillos, levanta muros y realiza inspecciones en serie" a "grupos de transporte, grupos de construcción y grupos de inspección trabajando simultáneamente".
Una vez resuelta la eficiencia dentro de una sola tarjeta, surgen nuevos desafíos con la paralelización de múltiples tarjetas.
La práctica común de la industria es la paralelización de tensores (Tensor Parallel): Dividir la matriz de pesos del modelo en varias partes, cada GPU es responsable de una parte, calcula por separado y luego consolida los resultados a través de una interconexión de alta velocidad (NVLink).
Este esquema funciona muy bien para cálculos densos y estructurados como la multiplicación de matrices, y es la solución estándar de la industria para múltiples tarjetas en casi todos los marcos de inferencia de modelos grandes.
GLM-5.1 utiliza **MLA (Multi-head Latent Attention, Atención Latente de Múltiples Cabezas), un mecanismo de atención propuesto por DeepSeek.
Los mecanismos de atención tradicionales necesitan guardar una gran cantidad de datos intermedios (KV Cache) generados en cada paso para su uso posterior, lo que consume mucha memoria de vídeo; el enfoque de MLA es comprimir primero estos datos intermedios en un "vector latente" compacto para almacenarlos, y luego descomprimirlos cuando sea necesario, reduciendo significativamente los requisitos de memoria de vídeo y mejorando la eficiencia de la inferencia.
Pero en el flujo de cálculo de MLA hay un paso especial: necesita realizar indexación dispersa en una gran cantidad de información histórica: similar a buscar rápidamente los libros más relevantes en una enorme biblioteca y luego leer detenidamente esos libros.
El paso de "buscar libros" depende de información global y no es adecuado para distribuir entre múltiples tarjetas; "leer detenidamente" es el cálculo denso adecuado para la paralelización de múltiples tarjetas. Si se fuerza a las 8 GPUs a participar en la "búsqueda de libros", mucho tiempo se perderá en la comunicación de sincronización entre ellas.
La solución de TileRT es hacer que las GPU funcionen de manera heterogénea: la GPU 0 actúa específicamente como "bibliotecaria de referencia", responsable de la indexación dispersa y las decisiones de enrutamiento; las GPU 1–7 actúan como "analistas de lectura profunda", responsables del cálculo denso de atención y las operaciones matriciales. Ambos tipos de trabajadores colaboran para completar toda la capa de cálculo, utilizando las estrategias de paralelización más adecuadas para cada uno.
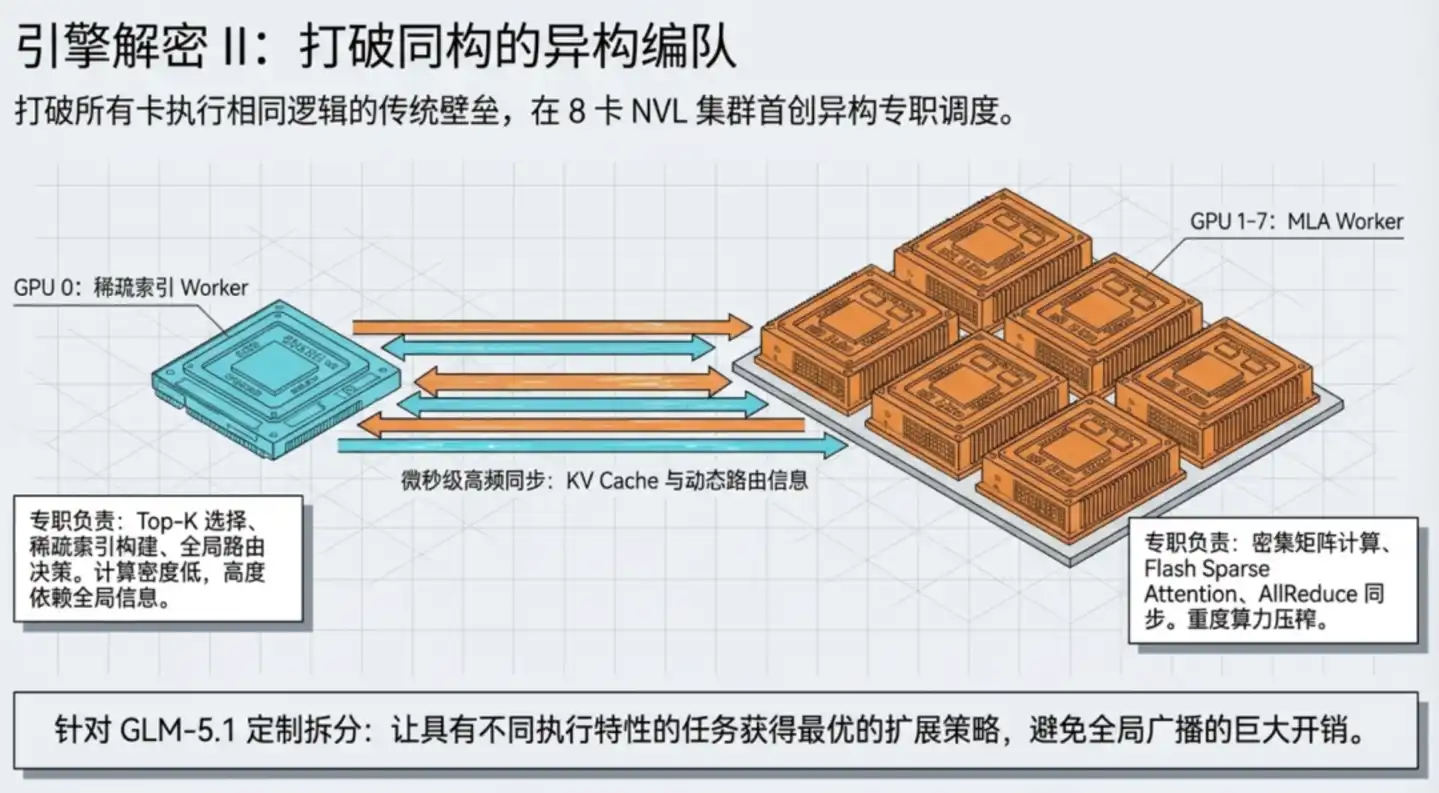
A continuación, TileRT integra directamente las operaciones de comunicación entre GPUs en la línea de ejecución, sin tratarlas como pasos independientes. Externamente, todo el sistema de 8 tarjetas completa una capa de cálculo de atención con solo una iniciación de kernel, y toda la comunicación y cálculo internos se completan sin problemas dentro de la línea de producción continua.
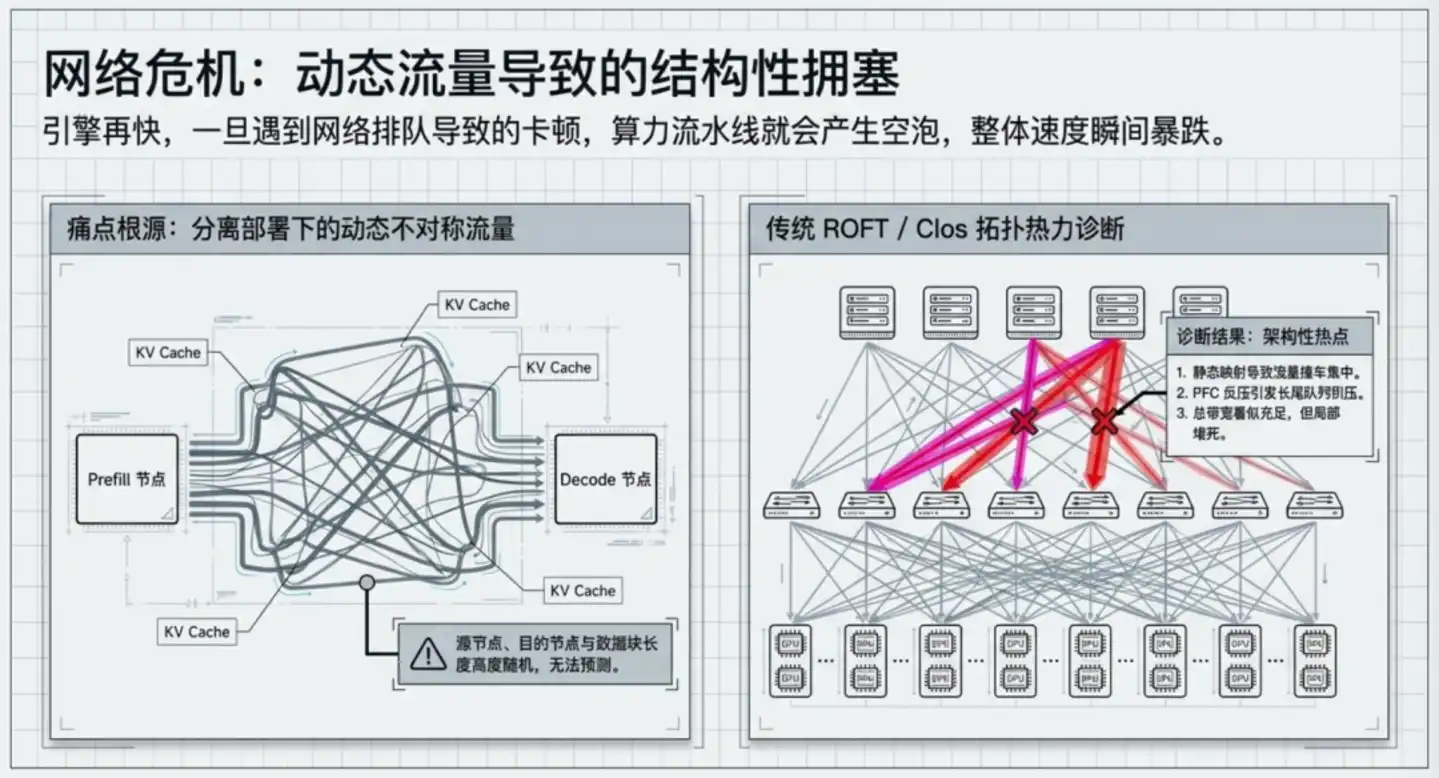
Las dos capas anteriores resuelven problemas dentro de una sola máquina. Cuando el clúster se amplía a cientos o incluso miles de GPUs, la transmisión de datos entre las GPUs se convierte en un nuevo cuello de botella.
La práctica común de la industria es ROFT (Rail-Optimized Fat-Tree), la solución oficial recomendada por NVIDIA y el estándar absoluto de la industria.
Su estructura es como un árbol: los servidores primero se conectan a los conmutadores de nivel inferior Leaf (capa de acceso, directamente frente a los servidores), los Leaf se conectan hacia arriba con los conmutadores Spine (capa troncal, responsable de la interconexión entre diferentes Leafs, como un nodo de autopista). Los datos que viajan entre dos GPUs deben "subir primero al Spine, luego bajar al Leaf de destino", pasando al menos por 3 saltos.
Para evitar que el tráfico se concentre en unas pocas rutas, esta arquitectura depende del algoritmo ECMP para distribuir los datos entre múltiples caminos, funcionando bien bajo la premisa de un tráfico de Internet "estadísticamente uniforme".
Pero el patrón de tráfico en escenarios de inferencia es completamente desigual. Las longitudes de contexto de diferentes solicitudes pueden variar decenas de veces, la dirección de transmisión del KV Cache entre GPUs es casi aleatoria, y algunos conmutadores Leaf se convierten periódicamente en puntos calientes, activando mecanismos de contrapresión que propagan la congestión desde lo local a toda la red. Esta congestión no se puede resolver ajustando parámetros de protocolo; es producto de la propia estructura de la topología.
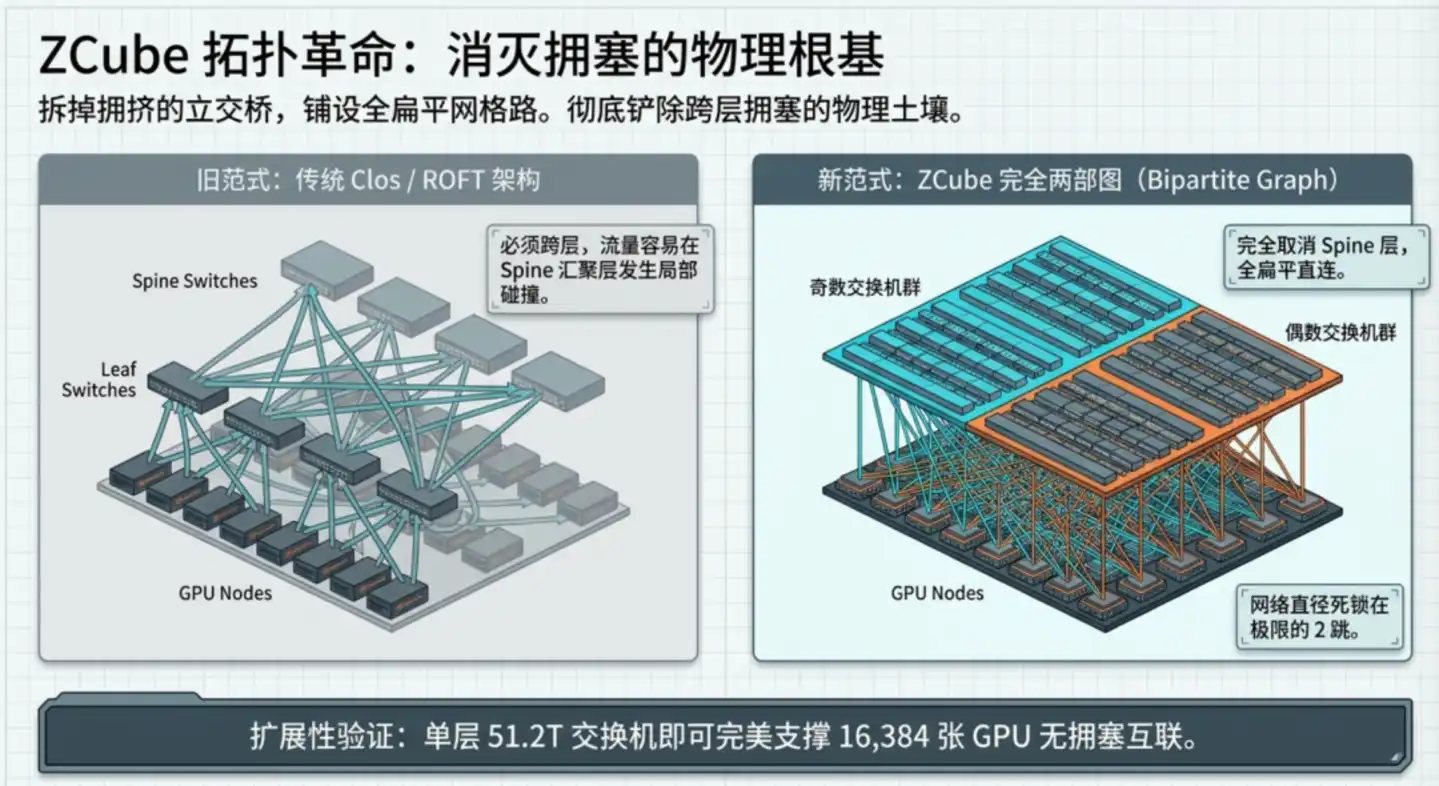
El avance fundamental de ZCube: hacer que este tipo de congestión sea físicamente imposible desde el nivel arquitectónico.
El diseño central se divide en dos pasos:
Primer paso, eliminar la capa troncal Spine y aplanar toda la red. Dividir todos los conmutadores Leaf en dos grupos según numeración par/impar, e interconectarlos completamente. Cualquier conmutador impar está conectado a todos los conmutadores pares, y viceversa. Cualquier par de GPUs puede comunicarse pasando como máximo por dos conmutadores, reduciendo los saltos de 3 a 2.
Segundo paso, y el más ingenioso: Cada tarjeta de red de GPU se conecta a los dos grupos de conmutadores de dos maneras radicalmente diferentes. Esta topología especial produce una propiedad matemática clave: Entre cualquier par de GPUs en toda la red, hay una y solo una ruta óptima.
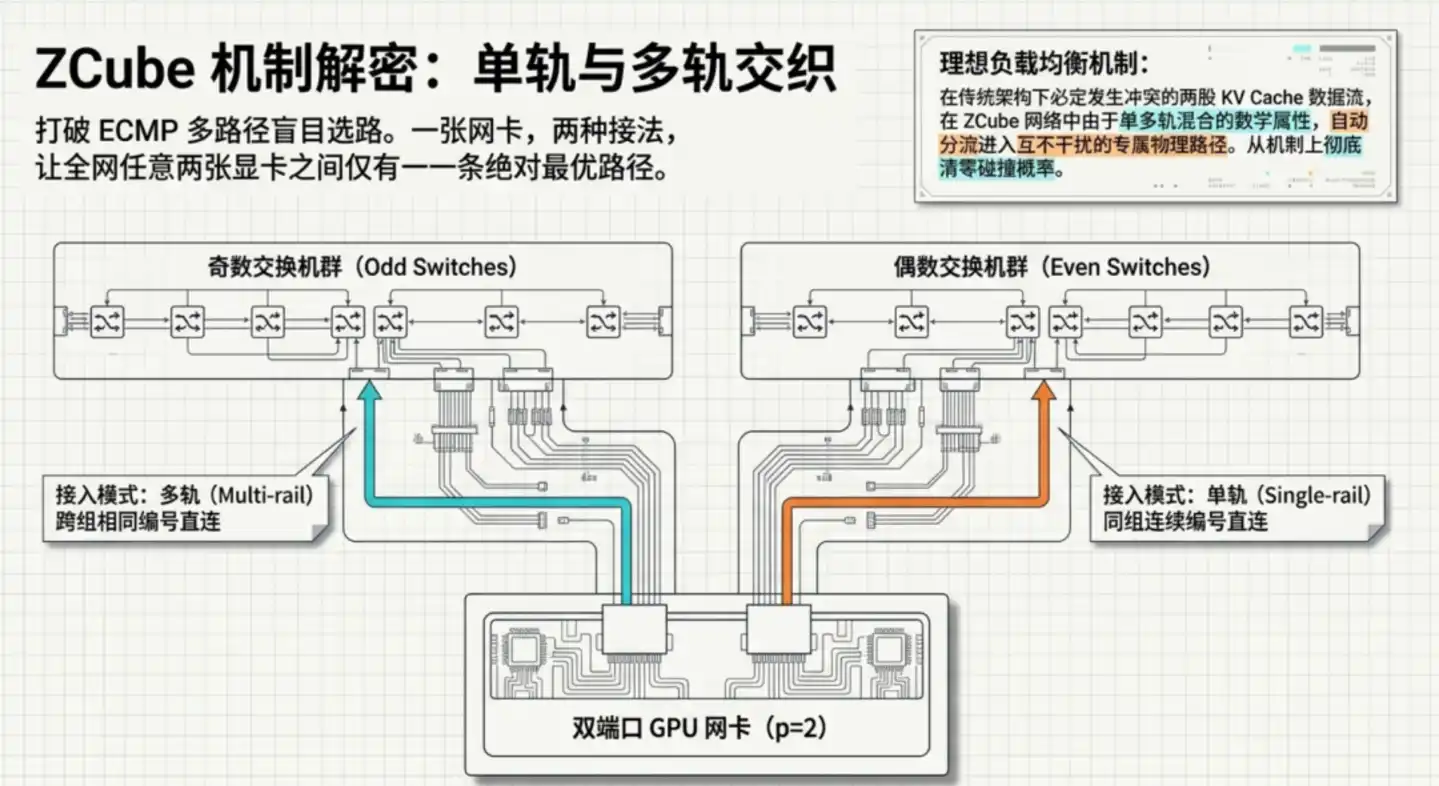
La "ruta única" elimina directamente la raíz de la congestión. Las arquitecturas tradicionales son propensas a puntos calientes precisamente porque hay múltiples rutas disponibles; si el algoritmo de equilibrio de carga elige mal, el tráfico se concentra. ZCube elimina la propia "elección" en el diseño: no necesita equilibrio porque literalmente no hay bifurcaciones.
04 Bajo las mismas condiciones de hardware, ¿cómo se traduce en números?
Después de actualizar el clúster de producción de GLM-5.1 de Zhipu del ROFT tradicional a ZCube, se obtuvieron tres cifras:
En resumen, Con la misma inversión en GPU, el clúster puede atender a más usuarios; con los mismos requisitos de experiencia de usuario, el clúster puede comprar un tercio menos de equipos de red. Mejora bidireccional en eficiencia y costos.
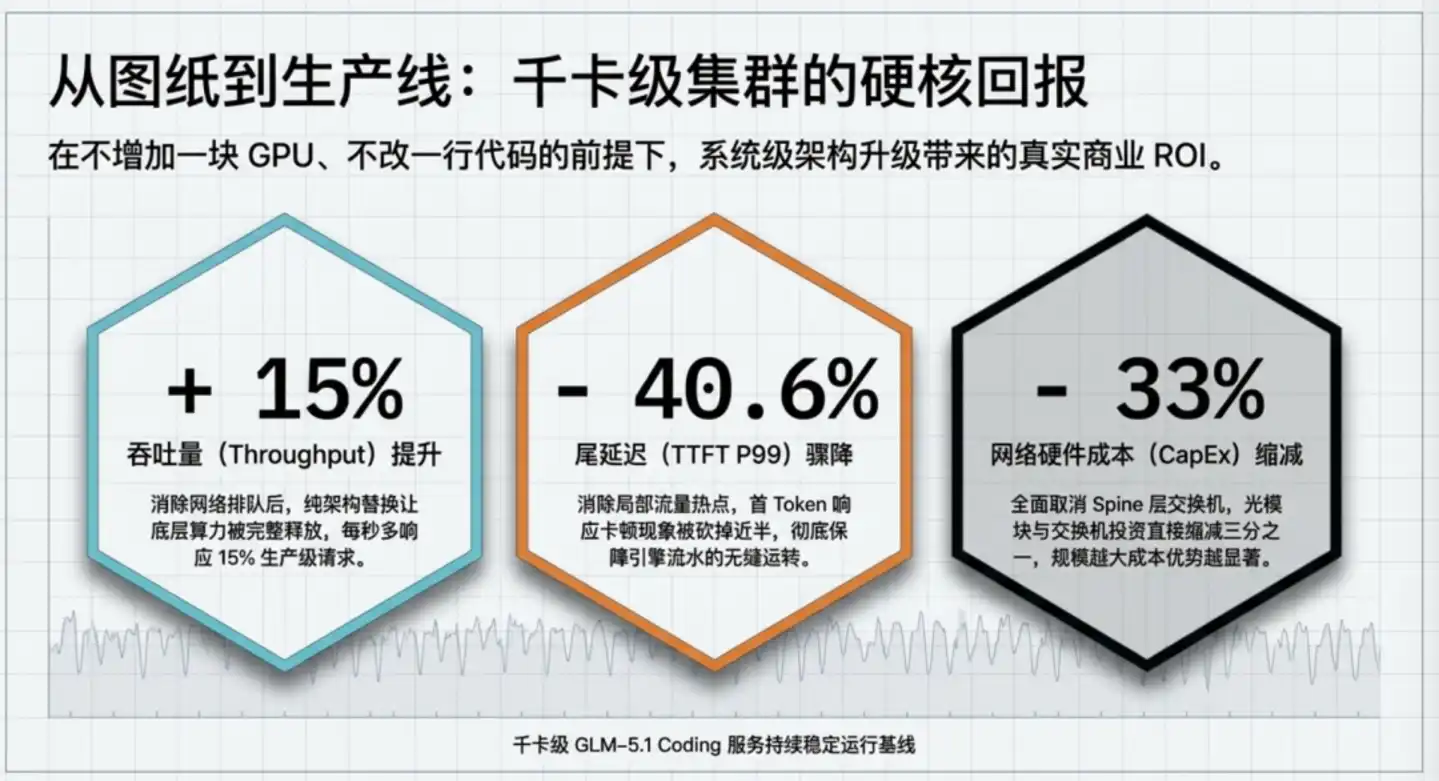
Específicamente, un aumento del 15% en el rendimiento, equivalente a obtener un 15% más de capacidad de cálculo gratis. Con el mismo número de GPUs, un 15% más de rendimiento equivale a una reducción de aproximadamente el 13% en el costo de hardware promedio por token, o la capacidad de atender a un 15% más de usuarios con el mismo costo.
Si un clúster tiene 1000 GPUs, esta actualización equivale a obtener gratuitamente la capacidad de 150 tarjetas adicionales. Según los precios actuales del mercado de tarjetas de inferencia de gama alta, esto representa un valor de capacidad de cálculo del orden de cientos de millones de yuanes.
Una reducción del 40.6% en la latencia de cola (tail latency), que resuelve la estabilidad, no la velocidad promedio. En una tarea de Agente que requiere 50 invocaciones, si la latencia de cola se reduce 1 segundo en cada una, el peor tiempo de finalización de toda la tarea se reduce casi 1 minuto.
Una reducción de un tercio en el costo es un ahorro directo a nivel de construcción. ZCube elimina la capa Spine, y para un clúster de la misma escala, la cantidad de conmutadores y módulos ópticos necesarios se reduce directamente en un tercio. Según cálculos de Zhipu, en un clúster de decenas de miles de tarjetas, solo este ítem puede ahorrar entre 210 y 640 millones de yuanes.
A largo plazo, a medida que la escala de los clústers aumenta exponencialmente, la complejidad de la comunicación entre GPUs se multiplica, y la probabilidad e impacto de la congestión también se amplifican. Esto significa que el valor de innovaciones arquitectónicas como ZCube se hará más evidente y acelerado con la expansión continua de los clústers de inferencia. Mañana, los beneficios para clústers de decenas de miles de tarjetas podrían superar el 15% de hoy.
05 Para finalizar
Después de leer el informe técnico de Zhipu, me pregunto si esto, como el surgimiento de DeepSeek, traerá una tormenta a la industria.
Pensándolo bien, el impacto de ambos parece estar en aspectos diferentes. Cuando apareció DeepSeek, demostró que la misma inteligencia se podía lograr con mucha menos capacidad de cálculo. El mercado temía que "se necesitarían menos GPUs", por lo que la capitalización bursátil de NVIDIA se redujo en casi 600.000 millones de dólares ese día.
Pero la tecnología de Zhipu hoy demuestra: con la misma capacidad de cálculo, se puede producir más. Está redefiniendo "cómo debería ser el resto de la infraestructura, además de las GPUs".
A corto plazo, NVIDIA no se verá afectada, pero a largo plazo, la ventaja competitiva de la combinación GPU + interconexión NVLink + red InfiniBand + ecosistema de software CUDA está siendo "socavada", especialmente la infraestructura InfiniBand que NVIDIA adquirió en 2019 con la compra de Mellanox por 6.900 millones de dólares. El margen premium de NVIDIA en el lado de red se erosionará significativamente.
Además, ZCube elimina la capa Spine, pero en cambio requiere una mayor densidad de puertos en los conmutadores Leaf. Se benefician los fabricantes capaces de producir conmutadores Leaf de alta densidad y gran número de puertos (como Ruijie, Arista, chips de conmutación de Broadcom), mientras que los perjudicados son aquellos que dependen principalmente de los conmutadores Spine de gama alta para obtener un margen premium.
En 2025, Celestica y NVIDIA en conjunto ocuparon aproximadamente el 50% de la cuota de mercado de conmutadores de red de backend para IA. Este panorama enfrentará una reestructuración si el paradigma ZCube se difunde.
Los módulos ópticos son la dirección más directamente beneficiada en esta cadena de suministro, con una lógica muy clara. Para los fabricantes nacionales de módulos ópticos (como InnoLight, TFC, etc.), esto es una ventaja estructural: no solo el volumen total aumenta, sino que la demanda de módulos ópticos de alta velocidad (800G, 1.6T) bajo el paradigma ZCube es más concentrada y urgente que en las arquitecturas tradicionales.
Tanto TileRT como la arquitectura ZCube son un motor de inferencia de software puro que se ejecuta en GPUs estándar, sin depender de características de hardware privativas de NVIDIA, y en teoría se pueden portar a chips nacionales como el Ascend de Huawei. Si esta dirección tiene éxito, reduciría significativamente la barrera de entrada del software para los chips nacionales de IA en escenarios de inferencia.
Este es quizás el significado más profundo detrás de esta innovación tecnológica.







