El Prompt ha muerto, que viva el loop.
Esto es lo que ha estado circulando y debatiéndose en Internet últimamente, y el nuevo énfasis que Lao Huang (Huang Renxun) ha puesto en la nueva tendencia de la IA:
Ya nadie escribe prompts. El nuevo trabajo es escribir y manejar loops. (Nobody writes prompts anymore. The new job is to write and handle loops.)
¿Qué es un loop? Traducido literalmente es "ciclo", y en términos de la comunidad de IA sería:
Ya no das instrucciones a la IA con tus propias manos, sino que diseñas un sistema que da las instrucciones por ti, verifica los resultados y, si no son satisfactorios, vuelve a intentarlo por sí mismo, hasta que el trabajo esté terminado.
¿Eh? ¿No es esto lo mismo que hacen los Agentes hoy en día? ¿Por qué inventar un nuevo concepto?
Dejemos esta duda de lado por ahora. Después de mirar a mi alrededor, descubrí que este "loop" realmente está de moda.
Además de Lao Huang, una serie de grandes figuras como Peter (el "padre de la langosta"), Boris Cherny (el "padre de Claude Code"), Andrew Ng y otros están hablando y promoviendo activamente el loop.
(Peter) Deja de escribir prompts para los Agentes de programación, diseña loops que den prompts al Agente por ti.
(Boris) Ya no le escribo prompts a Claude. Tengo un montón de loops ejecutándose, son ellos los que le dan instrucciones a Claude y deciden qué hacer a continuación. Mi trabajo es escribir loops.
Y cuando "escribir loops" reemplaza a "escribir prompts" como la nueva rutina diaria de los grandes expertos, está claro que el loop ya ha superado la etapa de "ser solo otro concepto nuevo".
Las únicas preguntas que quedan son:
¿A qué se refiere exactamente "loop"? ¿Cómo se puso tan de moda de repente?
¿Qué es realmente un loop?
Para entender este nuevo concepto de "loop", tenemos que recordar el viejo paradigma anterior.
El estándar de la programación con IA en los últimos dos años era así:
Tú escribías un prompt, la IA escupía un código, si no estabas satisfecho, escribías otro prompt, la IA lo modificaba, tú lo revisabas de nuevo... y así sucesivamente.
Básicamente, era un tira y afloja constante, con la persona supervisando todo el proceso.
Karpathy incluso criticó indirectamente que "el ser humano es el cuello de botella" y aconsejó:
No puedes sentarte ahí esperando para escribir un prompt para cada paso, tienes que desvincularte del flujo.
Desvincular a la persona del flujo es precisamente lo que el loop pretende resolver.
Su lógica central se resume en una frase:
Tú defines un objetivo, la IA lo ejecuta por sí misma, se verifica a sí misma al terminar, si no pasa la verificación vuelve a intentarlo con el error reportado, y así hasta que lo logre o alcance el límite de presupuesto establecido.
En este punto, el rol del ser humano cambia de "mensajero" a "diseñador de reglas".
Volviendo entonces a la duda inicial: ¿En qué se diferencia esto de un Agente?
Obviamente, el Agente es quien hace el trabajo, mientras que el loop es el mecanismo de gestión que permite que esa entidad siga trabajando sin que tú la supervises.
Un Agente sin loop: tú dices una cosa, él actúa una vez, es esencialmente una herramienta obediente.
Un Agente equipado con un loop se convierte en un sistema verdaderamente autónomo.

El principio suena sencillo, pero quizás aún sea un poco abstracto.
No te preocupes, revisé la implementación actual del loop y descubrí que ya está integrado en sistemas que conocemos.
En cuanto a la implementación de productos, se ha formado una "dualidad" en torno al loop.
Uno es Claude Code, que todos usamos a diario, y que ha construido un trío de funciones alrededor del loop:
/loop se encarga de ciclos programados, /goal se basa en objetivos (ejecuta hasta que se cumplan las condiciones de aceptación), y /schedule maneja tareas programadas en la nube (puede ejecutarse incluso con el portátil cerrado).
El diseño más ingenioso es el de /goal, que esconde un principio clave del loop: no puedes corregir tu propio examen.
Claude Code ha integrado este principio directamente en su arquitectura:
El modelo grande escribe el código, y otro modelo pequeño e independiente, Haiku, lo verifica. Cada modelo tiene su función.
De esta manera, el Agente no se da a sí mismo una calificación alta, y la verificación tiene un poder restrictivo real.

El otro es OpenAI Codex.
El enfoque de Codex se acerca más a una combinación de "línea de producción automatizada + orientación a objetivos + múltiples sub-Agentes". En la experiencia práctica de algunos desarrolladores, se pueden ver hasta 8 Agentes ejecutándose simultáneamente en sus respectivos sandbox en la nube, cada uno haciendo su trabajo, para finalmente consolidar los resultados.
Curiosamente, aunque los caminos de implementación de ambas empresas son diferentes, la forma final resultante es muy similar:
Ambas descomponen tareas complejas, las distribuyen entre múltiples Agentes para ejecución paralela y luego consolidan los resultados.
En evaluaciones públicas y reputación en la comunidad, su rendimiento ya es muy similar.
Esto también indica un problema: el modelo en sí mismo ya no puede marcar una gran diferencia, la verdadera brecha está en la orquestación del loop en las capas superiores.
Hablando de esto, veamos directamente cómo trabaja a diario Boris Cherny, el "padre de Claude Code".
Él mismo relata que en noviembre del año pasado desinstaló su IDE, no lo abrió en un mes y finalmente lo eliminó.
Ahora tiene cientos de pequeños Agentes ejecutándose simultáneamente bajo su supervisión: algunos escanean issues de GitHub, otros leen comentarios de usuarios en Slack, otros monitorean fallos en CI. Cada Agente trabaja en su propia rama de código aislada, uno escribe el código y otro ejecuta las pruebas para verificarlo.
Solo los casos que no se pueden resolver llegan a su bandeja de entrada, esperando su juicio.
Según revela, desde Opus 4.5, todo su código ha sido escrito por Claude Code, y ahora la mayor parte del código se completa directamente en su teléfono móvil.
Lo siguiente son ciclos, donde los Agentes se dan prompts entre sí, sin necesidad de revisión humana intermedia.
¿Ves? La forma final del loop ya es bastante clara:
La persona no escribe código, ni escribe prompts, solo escribe reglas y criterios de juicio, y deja el resto a cargo del loop.
Cómo ponerlo en loop
Entonces, ¿cómo podemos ponerlo en loop?
Un blogger llamado Codez en X ya lo ha resumido por todos, publicó una hoja de ruta práctica de 14 pasos. Aquí selecciono algunas ideas clave.

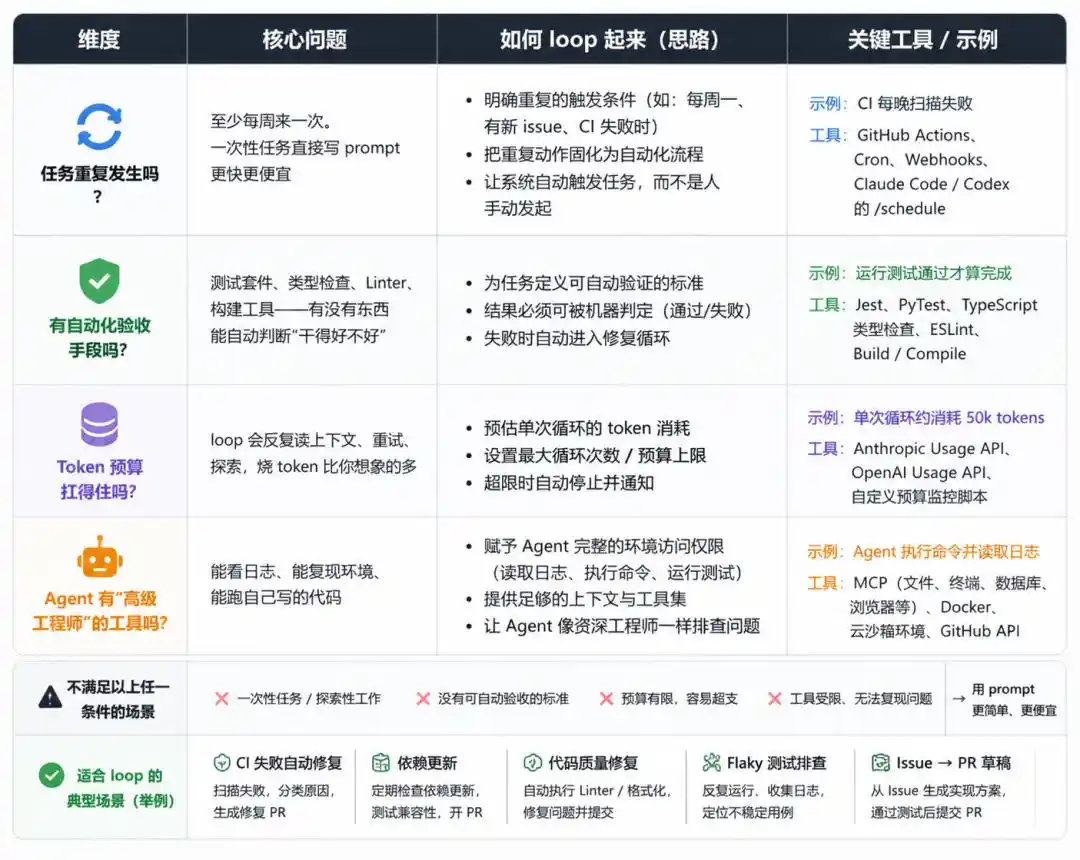
Paso 1: No te apresures a construir, primero haz la "prueba de 4 condiciones"
No puedes meter cualquier tarea en un loop, construirlo a ciegas solo generará pérdidas.
Antes de actuar, responde cuatro preguntas:
¿La tarea se repite con frecuencia?
¿Existen medios automatizados para verificar los resultados?
¿El presupuesto de tokens puede soportarlo?
¿El Agente tiene las herramientas de un "ingeniero senior"?
△
Solo si pasas las cuatro, vale la pena construir un loop.
Paso 2: Comienza con el loop mínimo viable
La primera vez, no te compliques, construye solo un conjunto de cuatro elementos:
Un activador (Automation): Puede ejecutarse programado o activado por eventos. En Claude Code usa /loop, en Codex usa el panel Automations.
Una habilidad (Skill): Escribe el contexto del proyecto en STATE.md, para que no necesite reinterpretarse en cada ejecución.
Un archivo de estado (State File): Usa Markdown para registrar "en qué punto está, qué salió bien, qué falló", para continuar la próxima vez.
Una barrera (Gate): Pruebas, verificación de tipos, construcción – algo que pueda detener automáticamente resultados malos.
Y el orden es clave: primero ejecútalo manualmente una vez → escríbelo como Skill → intégralo en un loop → finalmente programa la ejecución.
Saltarse pasos es la principal causa de muerte de los loops en entornos de producción.
Paso 3: Sé quien "divide el examen", no quien "lo califica"
El principio más importante en todo el diseño de loops ya se mencionó anteriormente: quien escribe el código y quien lo verifica deben estar separados.
Llevado a la operación concreta, esto significa:
Usar un modelo (o sub-Agente) para escribir, y usar otro modelo independiente (u otro sub-Agente) para verificar. El que verifica no debe poder ver el proceso de razonamiento del que escribe el código.
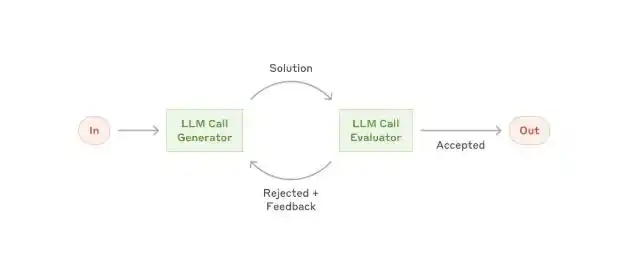
¿Por qué es tan importante? Porque cuando un modelo califica su propio código, tiende a ser "demasiado permisivo".
Todo código que "parece correcto" probablemente tenga una serie de problemas cuando se enfrenta a un verificador independiente.
Paso 4: No vuelvas a caer en los errores que otros ya cometieron
Anexo algunas guías para evitar problemas.
1. Sin condiciones de parada duras. Un loop se ejecutará hasta que descubras la factura o seas limitado, por lo que necesitas establecer límites de tokens, límites de iteraciones y límites de tiempo.
2. El estado no se persiste. La memoria del Agente es de corta duración, lo que aprende hoy lo olvida mañana, por lo que necesita escribirse en un archivo de estado (STATE.md) y leerse cada vez que se ejecuta.
3. Hacer que el loop toque trabajos que "requieren juicio". Reescribir arquitecturas, código de autorización, lógica de pagos, decisiones de dirección de producto: no dejes que el loop toque estos. El loop es adecuado para trabajos "claros en lo correcto/incorrecto, verificables por máquina y que no dependan del juicio humano", como correcciones automáticas de Lint, actualizaciones de dependencias en PRs, clasificación de fallos en CI, reproducción de pruebas intermitentes (Flaky).
4. No leer los Diff. El loop integra código cada vez más rápido, y tu comprensión del código base se vuelve cada vez más superficial. Esto se llama "deuda de comprensión": el verdadero costo no es la factura de tokens, sino el día en que tengas que depurar un sistema que nadie en el equipo ha leído. Por lo tanto, se recomienda leer los Diff, aunque sea un vistazo rápido.
Paso 5: Solo hay una métrica de medición
No te preocupes por cuántos tokens se gastan, cuántos PRs se abren, cuántas tareas se ejecutan.
La única métrica útil es: ¿Cuál es el costo promedio por modificación aceptada?.
Si tu "tasa de aceptación" es inferior al 50%, significa que estás haciendo el trabajo de revisión que el loop debería ahorrarte, es decir, el loop está generando pérdidas.
Del Prompt al Loop: Cuatro Cambios de Paradigma
Ya entendemos los principios y métodos, así que la última pregunta es solo una:
¿Por qué el loop está tan de moda ahora?
Aunque, estrictamente hablando, el concepto de Loop Engineering tiene menos de tres semanas de historia.
Pero no surgió de la nada; si retrocedemos en la línea de tiempo, podemos ver un camino evolutivo muy claro.
Los grandes expertos ya han resumido este camino por todos, así que tomemos prestado su trabajo:
De Prompt → Context → Harness → Loop, cuatro cambios en total.
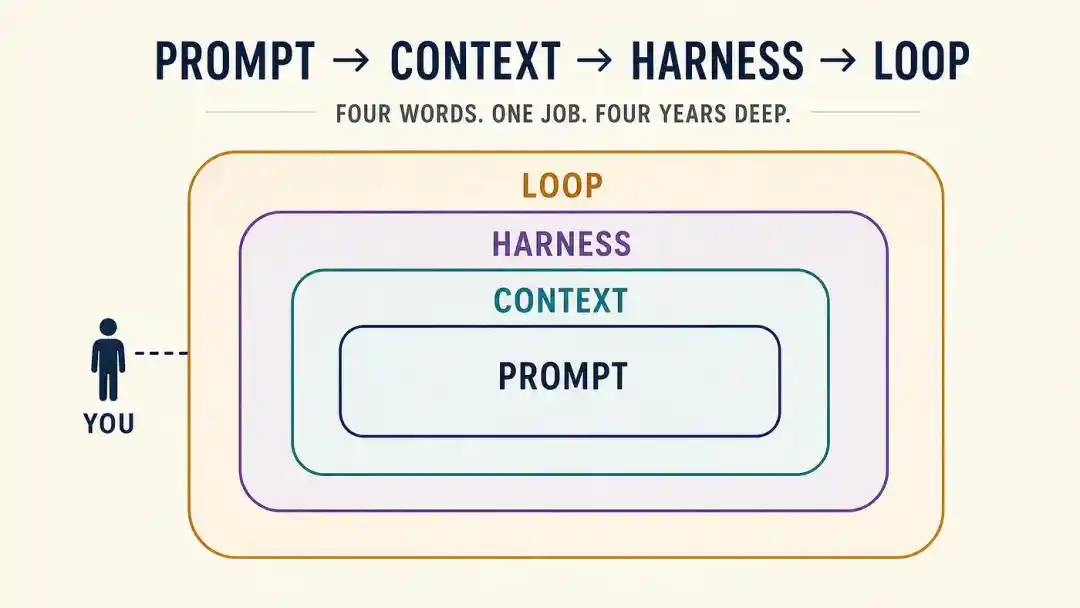
En resumen, de 2023 a 2024, fue el reinado de la Prompt Engineering.
En ese momento, todos reflexionaban sobre una cosa: cómo escribir prompts para que la IA trabajara bien.
Escribir bien o mal producía resultados muy diferentes, por lo que en ese entonces "saber escribir prompts" equivalía básicamente a "saber usar IA".
En esta etapa, la relación entre humanos e IA todavía estaba en el nivel más superficial: tú decías algo, ella respondía algo, hasta cada instrucción tenía que ser escrita personalmente por la persona.
Pero a medida que las capacidades de los modelos se fortalecieron, las ventanas de contexto se alargaron y la integración de RAG y repositorios de código se popularizó, el problema comenzó a migrar por primera vez.
Aproximadamente entre 2024 y principios de 2025, la industria comenzó a enfatizar la importancia de la "Context Engineering", cambiando el enfoque de "cómo preguntar" a "qué mostrarle a la IA".
Es decir, la IA ya no dependía solo de un prompt, sino del contexto completo que se le proporcionaba.
En esta etapa, la capacidad de organizar información comenzó a ser más importante que escribir prompts, y el grado de control pasó de "una frase" a "un montón de información".
Para 2025-2026, a medida que los sistemas de Agentes se integraban gradualmente en flujos de desarrollo reales, el problema continuó expandiéndose.
Entonces, la gente descubrió que solo dar información y contexto ya no era suficiente; la IA necesitaba poder utilizar herramientas, ejecutar código, llamar a APIs, pasar por aprobaciones de permisos.
Por lo tanto, necesitabas construirle un entorno de ejecución donde pudiera trabajar, tener restricciones y acceder a recursos del mundo real.
El "Harness Engineering" nació precisamente para esto.
Y sobre la base de Harness, el "Loop Engineering" se convirtió en la dirección evolutiva más reciente.
Si Harness resolvía el problema de "si la IA puede trabajar en un entorno real", entonces Loop resuelve el problema de "si la IA puede trabajar continuamente en este entorno, avanzar en las tareas por sí misma, sin necesidad de que una persona la supervise paso a paso".
Su núcleo ya no es la capacidad de ejecución única, sino la capacidad operativa de un sistema en bucle cerrado.
Así que, de Prompt a Context, a Harness, a Loop, parece un cambio de conceptos, pero en esencia es un camino de migración continuo:
El grado de control humano sobre la IA se eleva constantemente, desde "escribir una frase", a "proporcionar información", luego a "construir un sistema", y finalmente a "diseñar un ciclo".
Un proceso que gradualmente libera las manos humanas.

De hecho, aunque el concepto de Loop acaba de ponerse de moda en la industria, el mundo académico ya tenía ideas similares desde antes.
Y muchos trabajos importantes están relacionados con una persona que conocemos hoy: Yao Shunyu (de Tencent).
Uno de sus trabajos más representativos en la dirección de Agentes de modelos grandes es el marco ReAct (Reason+Act) de 2022.
Este trabajo obtuvo el nivel Oral en ICLR 2023 y posteriormente recibió decenas de miles de citas.
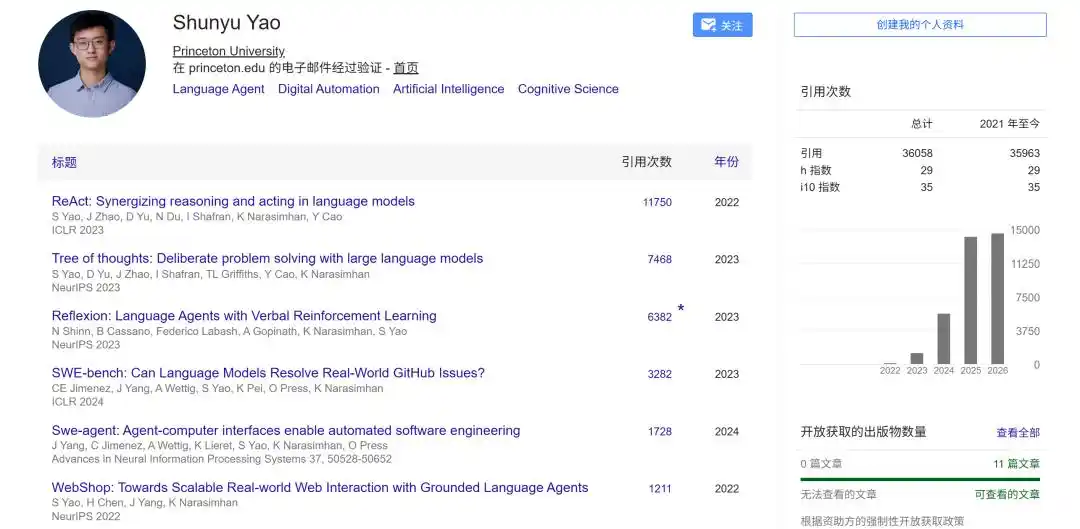
ReAct hizo algo crucial: vincular "razonamiento" y "acción" en un proceso cíclico.
El modelo grande ya no generaba una respuesta de una vez, sino que primero realizaba un pensamiento explicable, luego utilizaba herramientas para ejecutar acciones, después de la ejecución observaba la retroalimentación del entorno, y luego entraba en la siguiente ronda de razonamiento. En abstracto es:
Pensar → Actuar → Observar → Pensar de nuevo → Actuar de nuevo...
Esta estructura es esencialmente el primer esbozo sistematizado de un "ciclo de agente (agent loop)".
Después de ReAct, esta línea se expandió continuamente, por ejemplo, Reflexion introdujo un mecanismo de retroalimentación de "aprender de los errores", Tree of Thoughts se expandió a un razonamiento de búsqueda multipath, y una serie posterior de trabajos sobre agentes que usan herramientas perfeccionaron gradualmente la cadena completa de "planificación + ejecución + retroalimentación".
Estos logros académicos avanzaron poco a poco, convergiendo finalmente en la ingeniería en lo que hoy llamamos "sistemas de loop".
Así que, desde una perspectiva académica, Loop no es la invención de una sola persona, es un camino tecnológico que converge gradualmente.
Simplemente, en este camino, casualmente hay un investigador chino que conocemos en un punto clave.
Finalmente, no puedo evitar reflexionar, del Prompt al Loop, el desarrollo de la IA sigue siendo demasiado rápido.
La consecuencia de ser demasiado rápido es que algunos están emocionados, mientras que otros no pueden ocultar su preocupación.
Y Addy Osmani, director de ingeniería de Google y quien acuñó el nombre de Loop Engineering, es uno de estos últimos.
Lo deja muy claro en su extenso artículo "Loop Engineering":
Todavía es muy temprano. Mantengo reservas. Debes tener mucho cuidado con el costo de los tokens.

Las palabras de Karpathy dan aún más en qué pensar. En la conferencia Sequoia Capital AI Ascent 2026 citó una frase que él mismo ha recordado repetidamente:
Puedes externalizar tu pensamiento, pero no puedes externalizar tu comprensión.
Traduciendo: La IA puede pensar por ti, pero tú mismo debes entender realmente el problema.
Esta es probablemente la voz más lúcida en todo este fervor por los loops.
Enlaces de referencia:
[1]https://x.com/i/trending/2068190968809980300
[2]https://x.com/addyosmani/status/2064127981161959567
Este artículo proviene del WeChat Official Account "QbitAI", autor: Yishui (Una gota de agua)





