Por | Tecnología No Debe Ser Fría
El 24 de abril, en el campo de los modelos grandes, cayó una bota. La versión preliminar de DeepSeek-V4 se lanzó oficialmente y simultáneamente se hizo de código abierto, llevando directamente el contexto ultra largo de 1M (un millón de palabras) a la configuración de fábrica del servicio oficial.
Si hubiera sido hace un año, esta capacidad de procesamiento de texto largo de primer nivel era un derecho exclusivo de las grandes empresas extranjeras, encerrado detrás de muros de pago empresariales. Ahora, se presenta directamente en la mesa de la comunidad de código abierto, convirtiéndose en una infraestructura que los desarrolladores pueden tomar y usar a su antojo. Para los desarrolladores que han estado trabajando hasta tarde con bases de código extensas o contratos legales complejos, esto es sin duda una buena noticia.
Pero detrás de esta liberación tecnológica, el comunicado oficial incluye una revelación muy contenida: "Limitado por la capacidad computacional de alta gama, el rendimiento del servicio DeepSeek-V4-Pro es actualmente muy limitado".
Para aquellos acostumbrados a ver a los fabricantes hablar sobre sus reservas de capacidad computacional en las conferencias de lanzamiento, esta franqueza transmite una rara seriedad.
En la segunda mitad de la batalla de los modelos grandes, la industria sabe bien quién tiene cuántas fichas de hardware de alta gama. En lugar de mantener una prosperidad a nivel de parámetros, es mejor aclarar la situación actual de la industria. El movimiento de DeepSeek esta vez en realidad abandona la obsesión de competir puramente en puntuaciones, y encuentra un esquema de compromiso que equilibra el avance tecnológico con la realidad del hardware, entre avances en algoritmos centrales, el ecosistema de computación heterogénea aún por perfeccionar en China, y el entorno comercial real de las empresas.
La industria de IA china se está despojando de la vestimenta de quemar dinero a ciegas de sus inicios, y está entrando en una era extremadamente realista de "libro de cuentas de capacidad computacional".
¿Cómo se equilibran las cuentas de capacidad del Pro?
Analicemos específicamente ese V4-Pro cuyo rendimiento está explícitamente limitado. Como buque insignia del sistema, el V4-Pro tiene un total de parámetros de hasta 1.6T, pero durante la inferencia solo necesita activar 49B parámetros. Este diseño de esparcidad extremo no es un modelo de escaparate solo para exhibición; bajo la estricta prueba de las líneas de producción reales, su base tecnológica tiene una defensa muy sólida.
La capacidad de manejar código complejo y razonamiento lógico es la piedra de toque para probar si un modelo grande puede realmente ingresar a los eslabones centrales de producción. En el entorno de evaluación Agentic Coding (código de agente), el desempeño práctico del V4-Pro se mantiene firmemente en el primer nivel de los modelos de código abierto actuales.
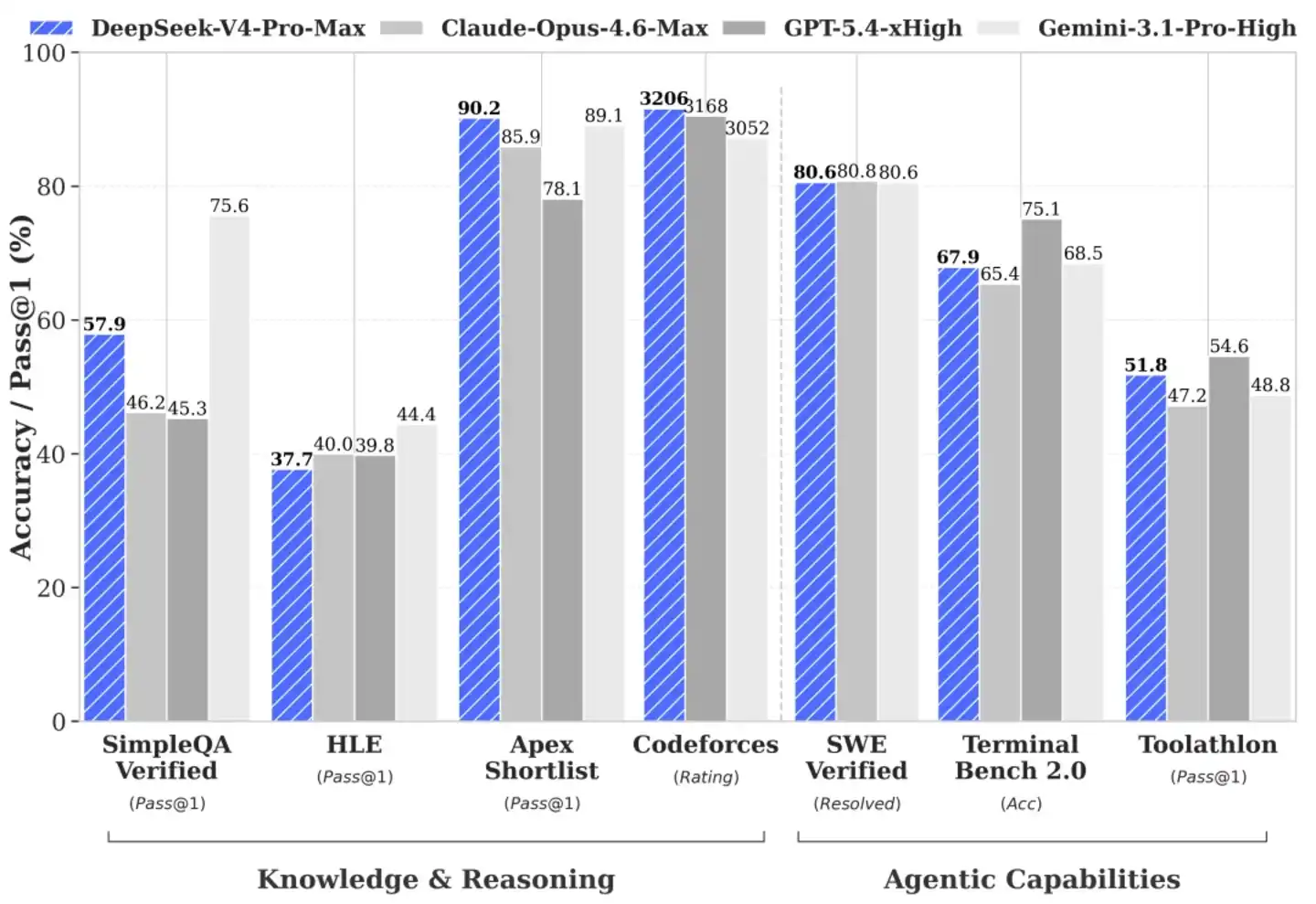
DeepSeek ya lo ha integrado en su propia línea de producción de código, convirtiéndolo en una herramienta de productividad de la que dependen en gran medida los ingenieros de primera línea. La retroalimentación del personal de I+D muestra que su experiencia en generación y corrección de código es mejor que Sonnet 4.5, y en escenarios que no requieren pensamiento profundo se acerca a Opus 4.6, aunque aún hay una brecha con el modo de pensamiento de Opus 4.6.
Detrás de este desempeño en combate real está la excavación extrema de la profundidad algorítmica por parte del equipo de investigación. En evaluaciones de conocimiento mundial que ponen a prueba la calidad de la limpieza de datos de preentrenamiento y la densidad de conocimiento, el V4-Pro supera a la mayoría de los modelos de código abierto existentes, y actualmente solo es ligeramente inferior al modelo cerrado de primer nivel Gemini-Pro-3.1. En cuanto a evaluaciones de matemáticas, STEM (ciencia, tecnología, ingeniería, matemáticas) y código tipo competencia, obtuvo la calificación para competir en igualdad de condiciones con los grandes fabricantes cerrados de clase mundial.
Obtener este poder de combate obviamente no depende simplemente de apilar tarjetas de capacidad computacional. Los equipos nacionales saben bien que competir en reservas de GPU de alta gama no es realista. Que el V4-Pro pueda procesar contextos ultra grandes de 1M con memoria de video limitada tiene como soporte subyacente la profunda reestructuración del mecanismo de atención por parte del equipo de desarrollo. Lograron un nuevo esquema de compresión de atención, realizando compresión de alta intensidad en la dimensión token, combinado con su característica tecnología de atención dispersa DSA (DeepSeek Sparse Attention).
Esta ruta tecnológica original, junto con la introducción por primera vez de una ventana deslizante y algoritmos de compresión para KV Cache, controla efectivamente los costos computacionales y el uso de memoria asociados con el procesamiento de secuencias largas. Para permitir que los desarrolladores realmente puedan invocar su capacidad en sus negocios, el equipo de desarrollo adaptó subyacentes herramientas Agent principales como Claude Code y OpenClaw.
La documentación técnica incluso indica claramente que los desarrolladores pueden activar directamente el modo de pensamiento al manejar tareas complejas, estableciendo el parámetro reasoning_effort en max. Esta optimización de ingeniería a nivel de sistema realizada con recursos computacionales limitados demuestra precisamente a la industria que, incluso con capacidad computacional de alta gama limitada, los equipos locales aún pueden ampliar los límites de rendimiento del modelo mediante un diseño de arquitectura nativa.
¿A quién afecta el volumen de activación de 13B?
Aquellos que se centran en el cuello de botella de rendimiento de la versión Pro a menudo pasan por alto el punto de apoyo comercial oculto detrás de DeepSeek: la versión Flash. Hay voces en la industria que creen que esto no es más que un producto de compromiso ante la escasez de capacidad computacional, una opinión que claramente subestima la consideración a largo plazo del equipo directivo. Se trata de un posicionamiento estratégico práctico hacia el ecosistema de下沉 (hundimiento/penetración), realizado después de un cálculo de costos严密 (estricto/meticuloso).

Según la información revelada en el código de adaptación publicado, el número total de parámetros de la versión Flash se mantiene en el nivel masivo de 284B, pero su número de parámetros activados se fija precisamente en 13B.
13B, en un contexto donde los competidores intentan impulsar los parámetros hacia billones (escala de trillones USA), no parece llamativo. Pero esto refleja precisamente la lógica económica de la arquitectura Mixture of Experts (MoE - Mezcla de Expertos) en la implementación comercial: el total de parámetros determina la amplitud del conocimiento del modelo, mientras que los parámetros activados determinan directamente el costo de electricidad y el ancho de banda de memoria que el servidor necesita gastar cada vez que se llama a la interfaz.
Mantener el volumen de activación en 13B extrae directamente el modelo grande de los costosos centros de supercomputación inteligente de primer nivel. Su demanda de memoria de video por tarjeta y picos de capacidad computacional es muy moderada. Los resultados de las pruebas prácticas muestran que la versión Flash mantiene un nivel estable de velocidad de respuesta y precisión al enfrentar grandes volúmenes de tareas diarias simples y de alta frecuencia, y la capacidad de razonamiento genérico subyacente no mostró una caída significativa. Para los desarrolladores pequeños y medianos y las empresas de larga cola que necesitan procesar miles de llamadas API diarias, esta es verdaderamente una herramienta de productividad asequible y ejecutable.
La lógica industrial más profunda radica en que los chips de computación heterogénea主流的 (principales/mainstream) nacionales actuales aún están en período de catch-up (ponerse al día) en cuanto al rendimiento absoluto por tarjeta. Los sistemas de cálculo que llevan la activación completa很容易 (fácilmente) tocan la pared de memoria (memory wall), lo que lleva a una baja eficiencia operativa; pero frente a la versión Flash con un volumen de activación de solo 13B, estos chips pueden funcionar sin problemas con un consumo de energía medio-bajo.
Este paso de DeepSeek revitaliza una gran cantidad de recursos de capacidad computacional nacionales de gama media-baja subutilizados, proporcionando un campo de pruebas muy adecuado para los chips nacionales que urgentemente necesitan escenarios de implementación. Esta lógica de construcción de infraestructura con向下包容 (包容: tolerancia/inclusividad hacia abajo) se ajusta mucho más a la realidad comercial actual que simplemente subir posiciones en varias listas de pruebas.
¿Pueden los chips nacionales soportarlo?
Lo que generó un amplio debate en la industria con este lanzamiento fue su etiqueta de implementación全栈国产 (pila completa nacional). Durante mucho tiempo, ha existido un cierto desajuste entre las empresas de algoritmos y los fabricantes de chips nacionales: las empresas de modelos temían que un ecosistema de hardware inmaduro retrasara el progreso de I+D, mientras que los fabricantes de chips carecían de los modelos grandes más avanzados para realizar ajustes finos en profundidad. Esta vez, el punto muerto se rompió sustancialmente.
Huawei Computing se pronunció rápidamente, confirmando que toda la serie de productos del超节点 (supernodo) Ascend admite completamente el nuevo modelo. Desde los detalles técnicos, los chips subyacentes de Ascend,依靠 (apoyándose en) la tecnología de kernel fusionado y paralelismo de múltiples flujos, redujeron efectivamente los costos computacionales del sistema, estabilizando así el rendimiento de inferencia en escenarios de texto largo. Cambricon también completó rápidamente la adaptación Day 0 y liberó el código subyacente como open source, mientras que Haiguang DCU anunció simultáneamente haber cerrado el ciclo.
Pero necesitamos separar la表象繁荣 (prosperidad superficial) del ecosistema y examinar la resistencia real que enfrenta la costura软硬 (software-hardware) en la sala de máquinas. Tomando como ejemplo la serie de chips Ascend 950, según消息业内 (mensajes de la industria), este chip cuenta con 112GB de HBM propio, un ancho de banda de 1.4TB/seg y un consumo de energía por tarjeta de 600 vatios. En precisiones de inferencia específicas (como FP4), su capacidad computacional por tarjeta ya ha mostrado un rendimiento de datos extremadamente fuerte, alcanzando 2.87 veces la del H20 de Nvidia. Pero en los rangos de precisión de entrenamiento general FP16 o FP32 más exigentes, aún existe una brecha de rendimiento entre el hardware nacional y el de Nvidia.
Además, la所谓的 (llamada) "adaptación Day 0" dista del funcionamiento sin pérdidas de los negocios empresariales, y aún debe superar los costos ocultos derivados de una cadena de suministro no transparente. Los estándares de conexión de alta velocidad del hardware del supernodo son extremadamente cerrados, y el flujo de componentes centrales es como una caja negra de información. Esta barrera en el extremo de la compra sin duda hace que el despliegue y mantenimiento a escala de los sistemas de capacidad computacional sean más complejos.
Al mismo tiempo, actualmente este sistema depende高度 (altamente) de las grandes órdenes de compra agregada de un número muy pequeño de grandes instituciones nacionales. La escasez de pedidos del mercado exterior significa que esta batalla de突破算力 (avance/ruptura de capacidad computacional) solo puede librarse en la circulación interna. Este ciclo comercial único hace que la eficiencia operativa de todo el sistema de colaboración软硬协同 (software-hardware) necesite urgentemente el temple de entornos comerciales más diversos.
La tensa escalada de capacidad de producción de capacidad computacional de alta gama llevó directamente a DeepSeek a admitir con franqueza en su comunicado que, para que la versión Pro logre una reducción de precio significativa,仍需等待 (aún necesita esperar) la上市批量 (venta al por mayor/liberación批量 (batch) en el mercado) del supernodo en la segunda mitad del año. El modelo grande y los chips nacionales确实 (ciertamente) completaron el acoplamiento físico inicial, pero bajo la brecha tecnológica y las restricciones de la cadena de suministro, esta postura de correr heridos es precisamente el corte de supervivencia más real del ecosistema de capacidad computacional nacional.
¿Puede la tecnología seguir funcionando si la gente se va?
Volviendo la vista a la competencia comercial real, el surgimiento de DeepSeek-V4 es una defensa estratégica extremadamente precisa. Durante el último año más o menos, esta empresa ha estado constantemente en una situación de alta presión. El赛道 (carril) del lado C se convirtió en un mar rojo, y los fabricantes líderes utilizaron fondos masivos para realizar lanzamientos intensivos. Los datos de QuestMobile presentan una tendencia competitiva clara: hasta marzo de 2026, Doubao (豆包) alcanzó 345 millones de MAU, Qianwen (千问) 166 millones, y DeepSeek se mantuvo firme en su base fundamental con 127 millones.
La competencia de tráfico externo es feroz, y la base técnica interna también enfrenta pruebas de fluidez. La competencia por la caza de talentos dentro de la industria es feroz, y el personal clave de múltiples líneas de negocio ha salido接连 (sucesivamente). Según履历公开 (currículos públicos) e información de la industria, el autor principal de la primera generación de modelos de lenguaje grande confirmó su incorporación a Tencent, el contribuyente principal de V3 se fue a Xiaomi, el investigador principal de R1 ingresó a ByteDance, y también se confirmaron nuevos destinos para las fuerzas centrales en la dirección multimodal. Según rumores业内 (de la industria), el autor central de la dirección OCR, Wei Haoran, también renunció.
Los cambios en los miembros centrales de I+D必然 (necesariamente) provocarán un escrutinio estricto externo sobre su impulso de desarrollo posterior: ¿se verá afectada la capacidad innovadora de la arquitectura subyacente de esta empresa que se basa en la tecnología?
En este momento, el lanzamiento de la versión preliminar de V4 se convirtió en la respuesta más directa. Demuestra al mercado que la empresa ha establecido una línea de desarrollo sistemático con capacidad de resistencia al riesgo. Incluso frente a ajustes en la estructura del personal, la lógica de su evolución tecnológica aún puede mantenerse en funcionamiento preciso. Esta resiliencia organizacional basada en un sistema de ingeniería obtuvo迅速 (rápidamente) retroalimentación positiva en el mercado de capitales.
Recientemente, se reveló que DeepSeek busca financiación con una valoración no inferior a 10.000 millones de dólares, planeando recaudar fondos para补充储备 (complementar reservas). Según medios de la industria citando消息接近 (mensajes de personas cercanas) a la transacción, los rumores del mercado indican que se espera que un importante gigante de internet inyecte capital, lo que posiblemente impulse esta valoración. Si esta transacción se concretara finalmente, reescribiría el récord de valoración en el campo de los modelos grandes nacionales, superando el desempeño anterior de Moonshot AI (月之暗面). En el período clave de negociación de financiación, presentar resultados sustanciales de contexto de un millón de palabras y adaptación de pila completa nacional fue una jugada racional de la gerencia para estabilizar el tablero estratégico y responder a las dudas externas.
Para terminar
En el contexto comercial tecnológico donde los conceptos se actualizan con frecuencia, los equipos dispuestos a专注于 (concentrarse en) la construcción de infraestructura subyacente siempre son escasos. El lanzamiento de DeepSeek-V4 establece un tono务实而冷峻 (práctico y sobrio/sereno) para la competencia en la segunda mitad de los modelos grandes.
Frente al cuello de botella de la capacidad computacional, no optaron por disimarlo, sino que arrojaron la real situación de oferta y demanda del hardware nacional de alta gama al mercado; frente a la demanda de implementación下沉 (de penetración/hundimiento), utilizaron la versión Flash con activación de 13B para proporcionar espacio de supervivencia a los chips de capacidad computacional nacional que están en período de puesta al día; frente al cerco externo de tráfico y la competencia por talento, respondieron con una capacidad concreta de procesamiento de texto largo a nivel de industria.
La cita original de "Xunzi" que la oficinal引用 (citó) el día del lanzamiento es极富深意 (extremadamente significativa): "No ser seducido por la fama, no temer la calumnia, actuar según el Dao (camino), y corregirse端正然 (correcta y firmemente)".
El modelo puede ser de código abierto, pero la capacidad computacional no es gratuita. Lo que DeepSeek entregó esta vez no es un modelo más fuerte, sino una solución sobre cómo se redistribuye la capacidad después de que la capacidad computacional se convierte en una restricción. En la realidad donde la capacidad computacional aún es imperfecta, esta quizás sea la dirección de evolución más cercana a la esencia de la industria.





