Nota del editor: Este informe, basado en aproximadamente 400.000 sesiones de Claude Code, analiza cómo las herramientas de programación de IA están cambiando la relación entre las personas y el código.
El descubrimiento más importante es el siguiente: en la programación asistida por agentes de IA, los humanos deciden principalmente "qué hacer" y Claude se encarga sobre todo de "cómo hacerlo". El usuario asume la mayor parte de las decisiones de planificación, mientras que Claude asume la mayor parte del trabajo de ejecución. En otras palabras, la IA se está haciendo cargo de la escritura de código, la modificación de archivos, la ejecución de comandos, la depuración y otros aspectos de implementación, pero la definición de objetivos y la evaluación de resultados siguen dependiendo del ser humano.
Lo que es más importante, la efectividad del uso de Claude Code no depende únicamente de que el usuario sea programador. El informe muestra que, en tareas que generan código, el índice de éxito de usuarios con profesiones no técnicas (como derecho, finanzas, gestión o investigación científica) ya se acerca al de los ingenieros de software. Lo que realmente influye en el resultado es si el usuario comprende el problema que quiere resolver.
Esto significa que la programación de IA reduce la barrera de implementación, no la barrera de juicio. En el futuro, las personas que comprendan el negocio, el contexto, puedan plantear claramente los requisitos y evaluar los resultados podrán utilizar mejor la IA que aquellas que solo sepan escribir código. La IA no reemplazará automáticamente el conocimiento del dominio, sino que amplificará su valor.
A continuación, el texto original:
Hallazgos clave
Basándonos en investigaciones previas, hemos desarrollado un marco para estudiar la programación interactiva con agentes de IA. Este marco, basado en un análisis con protección de la privacidad de aproximadamente 400.000 sesiones de Claude Code entre octubre de 2025 y abril de 2026, evalúa la composición de las tareas, la forma de colaboración entre humanos e IA y la tasa de éxito de las tareas.
En una sesión típica, el humano es responsable de la mayoría de las decisiones de planificación (decidir "qué hacer"), mientras que Claude se encarga de la mayoría de las decisiones de ejecución (decidir "cómo completarlo"). Cuanto mayor sea la experiencia del usuario en un dominio determinado, mayor será el volumen de trabajo que Claude completará por cada instrucción. En tareas de codificación, la tasa media de éxito de los principales grupos profesionales -es decir, si completaron lo que el usuario pretendía, con pruebas verificables como pruebas aprobadas, envío de código, etc.- es casi igual a la de los ingenieros de software.
Cuanto mayor sea la competencia del usuario en el dominio, más probable será que la sesión termine con éxito. Sin embargo, la diferencia entre usuarios intermedios y expertos no es grande. Durante los siete meses que observamos, la proporción de sesiones dedicadas a depuración disminuyó casi a la mitad, y el uso se orientó hacia un enfoque más integral del agente: implementar y ejecutar código, analizar datos y redactar documentos no relacionados con código.
Durante estos siete meses, el valor típico de las tareas aumentó en casi todos los tipos de trabajo. Al comparar con información de ofertas de empleo autónomo para estimar el valor de las tareas, el aumento promedio fue de aproximadamente el 25%.
Introducción
La programación con agentes de IA está creciendo rápidamente. Desde finales de 2025, la proporción de proyectos en GitHub con actividad de agentes de codificación se ha más que duplicado, y los usuarios de Claude Code utilizan ahora esta herramienta un promedio de 20 horas a la semana. ¿Pueden las personas sin experiencia formal en programación dirigir con éxito a un agente para realizar trabajos técnicos complejos? ¿Cómo afectará la rápida adopción y mejora de estas herramientas al trabajo del conocimiento en un sentido más amplio? Aún no podemos dar una respuesta completa, pero podemos ver algunas señales tempranas en los datos de uso de Claude Code.
Este informe, basado en un análisis con protección de la privacidad de aproximadamente 400.000 sesiones interactivas de unos 235.000 usuarios entre octubre de 2025 y abril de 2026, proporciona evidencia del uso real de Claude Code. Continúa nuestras investigaciones previas sobre las métricas de autonomía en las sesiones de Claude Code y sobre cómo Claude Code ha cambiado el trabajo interno en Anthropic. Este artículo propone un marco para describir el uso de asistentes de programación de IA interactivos: qué trabajo se realiza, quién lo realiza y si tiene éxito. Nos centramos en el uso de Claude Code a través de la interfaz de línea de comandos (CLI), Claude.ai o la aplicación de escritorio de Claude Code. Al rastrear cómo cambia el uso de la programación con agentes a medida que mejora la capacidad de los modelos, podemos comprender mejor el impacto de estas herramientas en profesionales de la programación y en el mercado laboral de trabajadores del conocimiento.
Lo que sucede en Claude Code quizás presagia el futuro del trabajo del conocimiento: los agentes se integrarán gradualmente en trabajos que no implican codificación. Descubrimos que Claude está manejando tareas más complejas y valiosas. Al mismo tiempo, todavía existe una clara división del trabajo en la programación con agentes: los humanos deciden qué construir, el agente decide cómo construirlo.
También vemos evidencia de que lo que realmente amplifica la efectividad de la herramienta es la experiencia en el dominio, no la habilidad en programación. En particular, los expertos en un dominio tienen más probabilidades de éxito y se recuperan más fácilmente de errores y malentendidos. Sin embargo, la brecha entre expertos y usuarios intermedios no es grande. Esto sugiere que tener suficiente competencia en un dominio permite utilizar estas herramientas de manera casi tan efectiva como un experto profundo.
Estos hallazgos nos permiten observar preliminarmente posibles cambios en el mercado laboral. En nuestros datos, el éxito depende de si una persona comprende el problema que quiere resolver, no de si tiene formación en programación. Si estos patrones se mantienen en toda la economía, esto implicaría que, aunque las herramientas de programación con agentes puedan estar absorbiendo parte del trabajo orientado a la implementación, también están recompensando a quienes realmente comprenden los problemas que resuelven en su trabajo. Los agentes de codificación no están reemplazando la experiencia en el dominio. Por el contrario, cuanto más comprensión aporta un trabajador al agente, más trabajo de alta calidad puede completar este.
División del trabajo
¿Qué hacen las personas con Claude Code?
Para entender cómo las personas usan Claude Code, clasificamos cada sesión en uno de los nueve modos de trabajo, es decir, la actividad única que mejor describe el objetivo de esa sesión. Cuatro de estos modos se relacionan directamente con la escritura o mantenimiento de código: construir algo nuevo, arreglar algo roto, probar código, y orquestar otros agentes o flujos de automatización. Otra categoría es operar software, incluyendo implementar, configurar, ejecutar flujos de trabajo y monitorear sistemas. Dos categorías están más orientadas a averiguar "qué se debe hacer": entender cómo funciona un sistema existente y planificar cambios antes de realizar modificaciones. Las últimas dos categorías no están relacionadas con código, o el código es solo una parte auxiliar del producto final: analizar datos y comunicarse mediante presentaciones y otros documentos basados en texto.
Aproximadamente el 56% de las sesiones consisten en escribir código (25%), arreglar código (26%), o probar y orquestar código (5%). Operar software representa el 17%, planificar o explorar el 14%, y analizar o escribir texto el 13% (ver Figura 1).
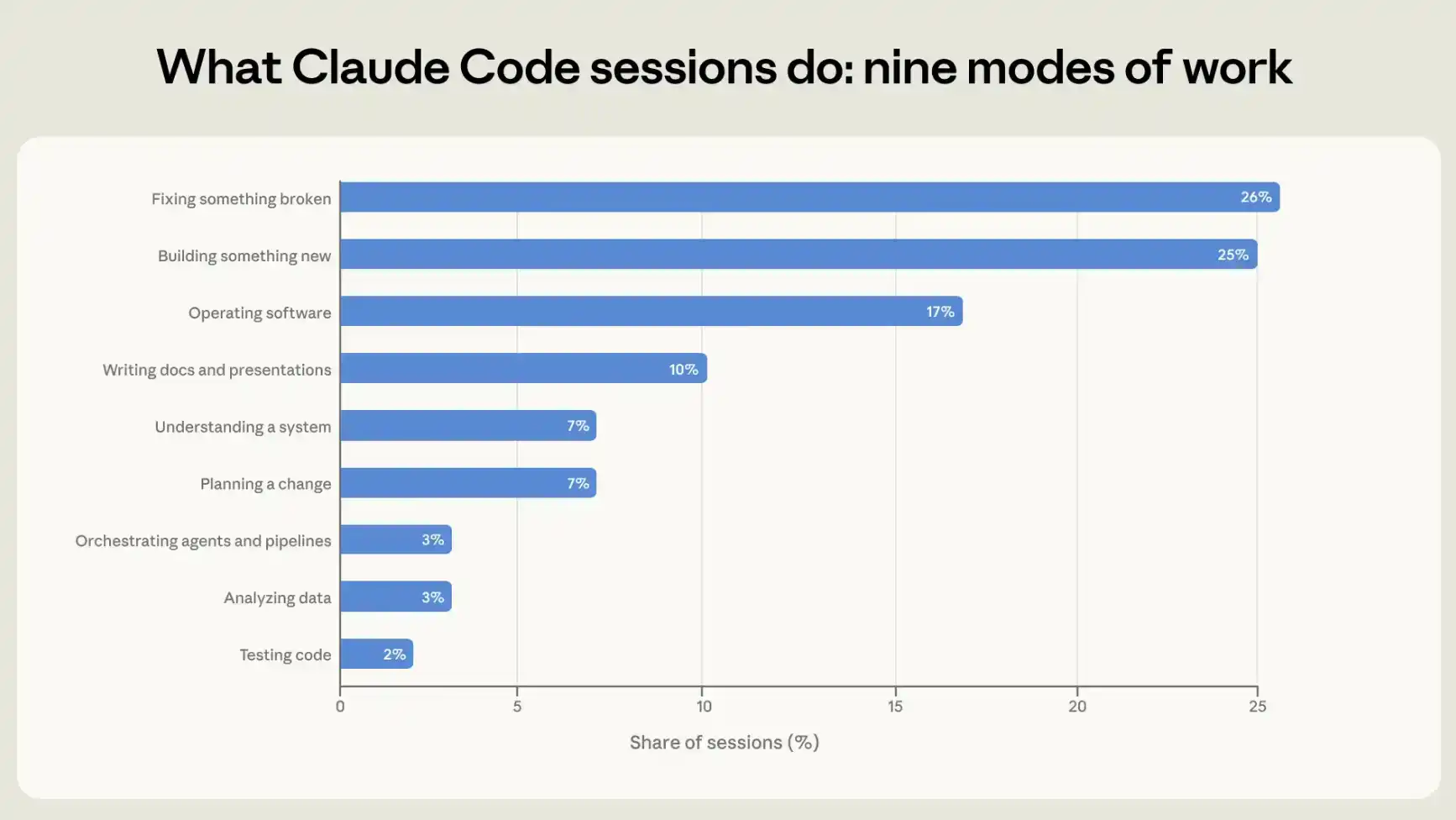
Primero hacemos que el modelo lea el registro de la sesión y clasifique cada sesión en consecuencia; luego usamos nuestra herramienta de análisis con protección de privacidad para cruzar los resultados de clasificación con los datos de telemetría registrados automáticamente para cada sesión, incluido si se agregaron o eliminaron líneas de código. Existe una alta consistencia entre las dos fuentes. Por ejemplo, en las sesiones marcadas por nuestro clasificador como de creación o modificación de código, más del 90% mostraron cambios de código en los datos de telemetría. Para más detalles, ver el apéndice.
¿Quién toma las decisiones?
¿Cuán autónomo es Claude Code? Las evaluaciones de capacidad muestran que su límite superior ya es alto y sigue aumentando. Por ejemplo, en pruebas de referencia como la evaluación de lapso de tiempo de METR, los modelos de vanguardia ahora pueden completar de manera autónoma tareas de software que antes requerían horas de trabajo humano, superando obstáculos por sí mismos. Pero en el uso real, ¿cómo es realmente la situación? Aquí nos centramos en cuánto trabajo de guía asumen los humanos y Claude en sesiones reales.
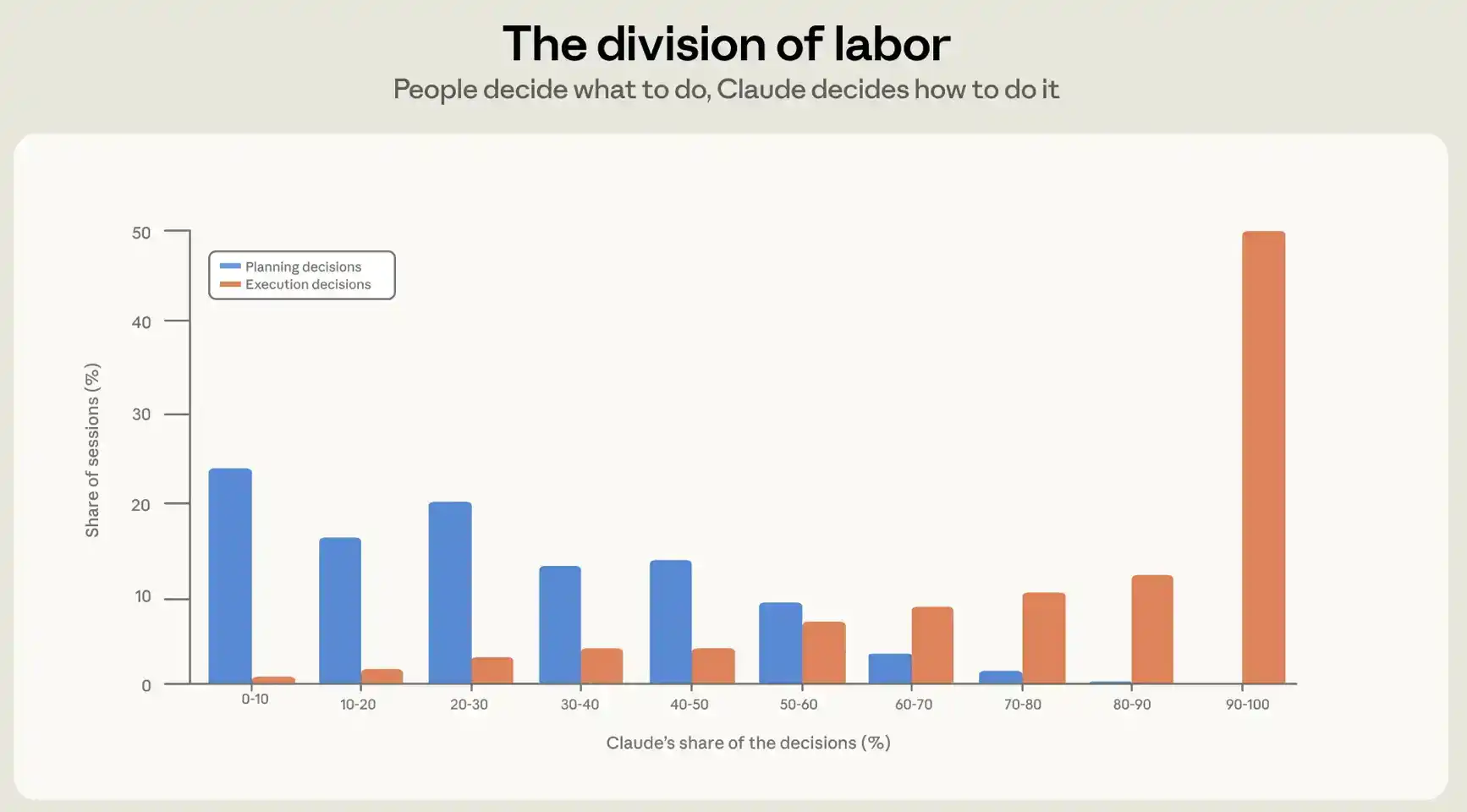
Estudiamos esta pregunta desde dos ángulos. Primero, observamos en qué medida las personas delegan decisiones a Claude; segundo, observamos cuántas acciones asignan a Claude. Para entender la división de decisiones en una sesión, construimos un clasificador de atribución de decisiones con protección de privacidad basado en el contenido de la sesión. Pedimos al clasificador que liste todas las decisiones significativas en la sesión y las divida en decisiones de planificación y decisiones de ejecución. Las decisiones de planificación incluyen qué hacer, qué enfoque adoptar, qué se considera terminado; las decisiones de ejecución incluyen qué archivos modificar, qué código escribir, en qué lenguaje y qué comandos ejecutar. Luego, el clasificador atribuye cada decisión a Claude o al usuario, y genera dos números para cada sesión: el porcentaje de decisiones de planificación asumidas por el usuario y el porcentaje de decisiones de ejecución asumidas por el usuario.
En promedio, los humanos toman alrededor del 70% de las decisiones de planificación, pero solo alrededor del 20% de las decisiones de ejecución (ver Figura 2). En la práctica, la programación con agentes forma una clara división del trabajo: los humanos deciden qué construir, los agentes deciden cómo construirlo.
Para entender el grado de delegación de acciones en una sesión, no miramos el contenido, sino la estructura de la sesión. Las sesiones de Claude Code consisten en interacciones de ida y vuelta entre Claude y el usuario: el usuario envía un indicador, Claude ejecuta acciones; luego el usuario envía el siguiente indicador, y así sucesivamente. En una sesión típica, hay alrededor de cuatro de estos turnos. En nuestros datos históricos de octubre a abril, cada indicador enviado por el usuario activaba, en promedio, que Claude ejecutara alrededor de 10 acciones, a veces incluso más de 100. En cada turno, Claude lee archivos, edita código, ejecuta comandos y produce, en promedio, 2400 palabras.
Cuánto trabajo completa Claude entre una verificación del usuario y la siguiente depende en gran medida de quién toma las decisiones. Cuando el usuario retiene el control sobre el proceso de ejecución, es decir, toma más del 80% de las decisiones de ejecución, Claude ejecuta menos acciones por turno, alrededor de 8. Y cuando Claude tiene el control de la planificación, es decir, toma más del 80% de las decisiones de planificación, asume la mayor cantidad de acciones, alrededor de 16.
Nivel de experiencia
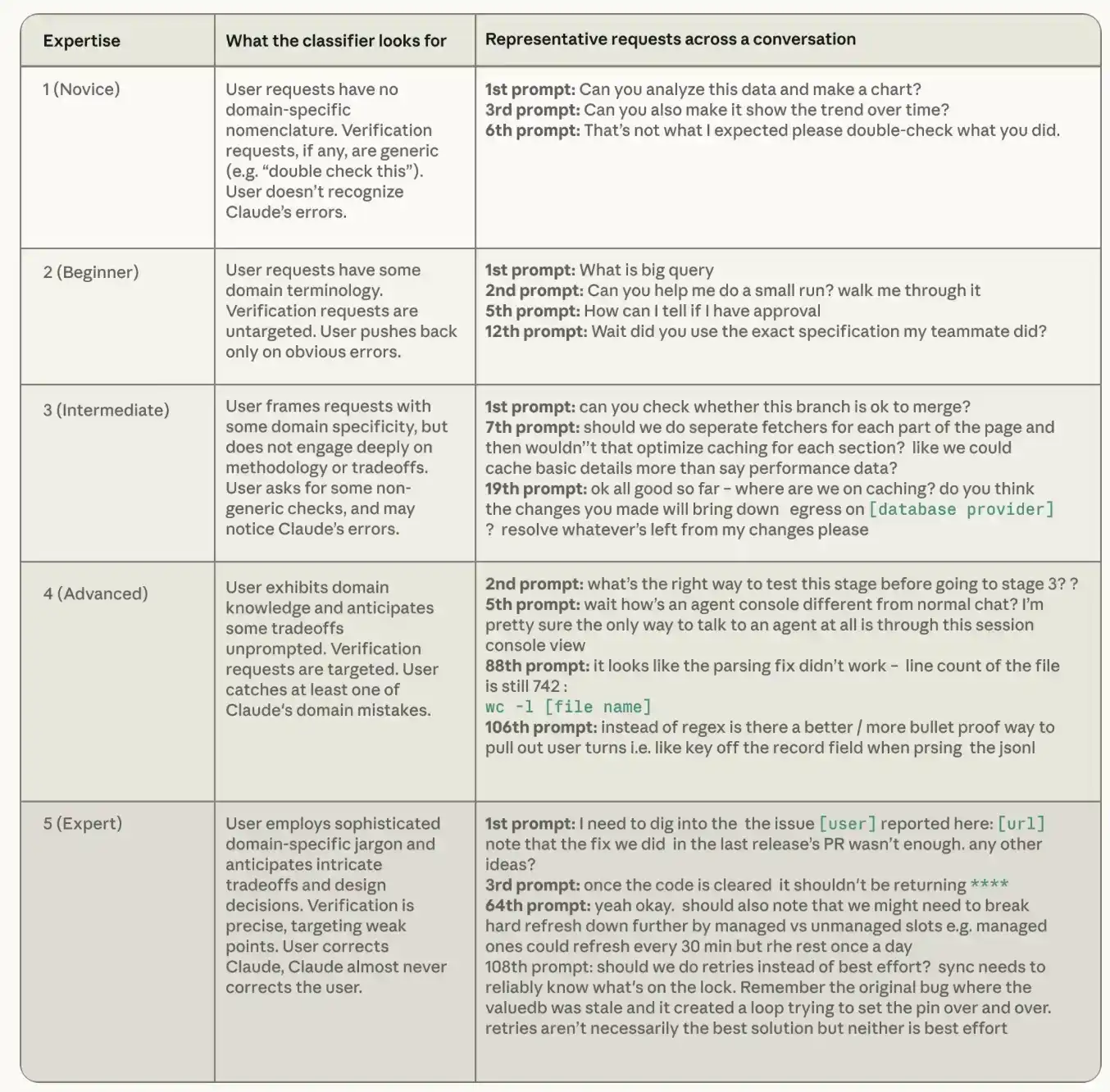
Basándose en el registro de cada sesión, Claude evalúa el nivel de experiencia aparente del usuario en esa tarea en una escala de cinco niveles, desde principiante hasta experto. El clasificador de nivel de experiencia se centra en tres señales: la precisión de las instrucciones dadas por el usuario, qué pide el usuario que Claude verifique, y si es más común que el usuario corrija a Claude o que Claude corrija al usuario. Es importante señalar que este nivel de experiencia es completamente diferente del puesto de trabajo o de la capacidad general, y lo clave es que es específico de la tarea. Un ingeniero senior que pregunte por primera vez sobre Rust puede seguir siendo un principiante en tareas de Rust. Un contador que nunca ha usado Python, si puede indicar con precisión a Claude qué reglas de conciliación debe ejecutar un script de Python y puede detectar casos límite que procesaría incorrectamente al cierre mensual, es un experto en esa tarea.
La siguiente tabla muestra cómo definimos cada nivel de experiencia en el clasificador y proporciona ejemplos de solicitudes del conjunto de datos público de sesiones de agentes de codificación SWE-chat. Las conversaciones clasificadas como "principiante" dan instrucciones generales que no reflejan conocimiento específico del dominio; las conversaciones clasificadas como "experto" transmiten una comprensión profunda del repositorio de código y del entorno técnico.
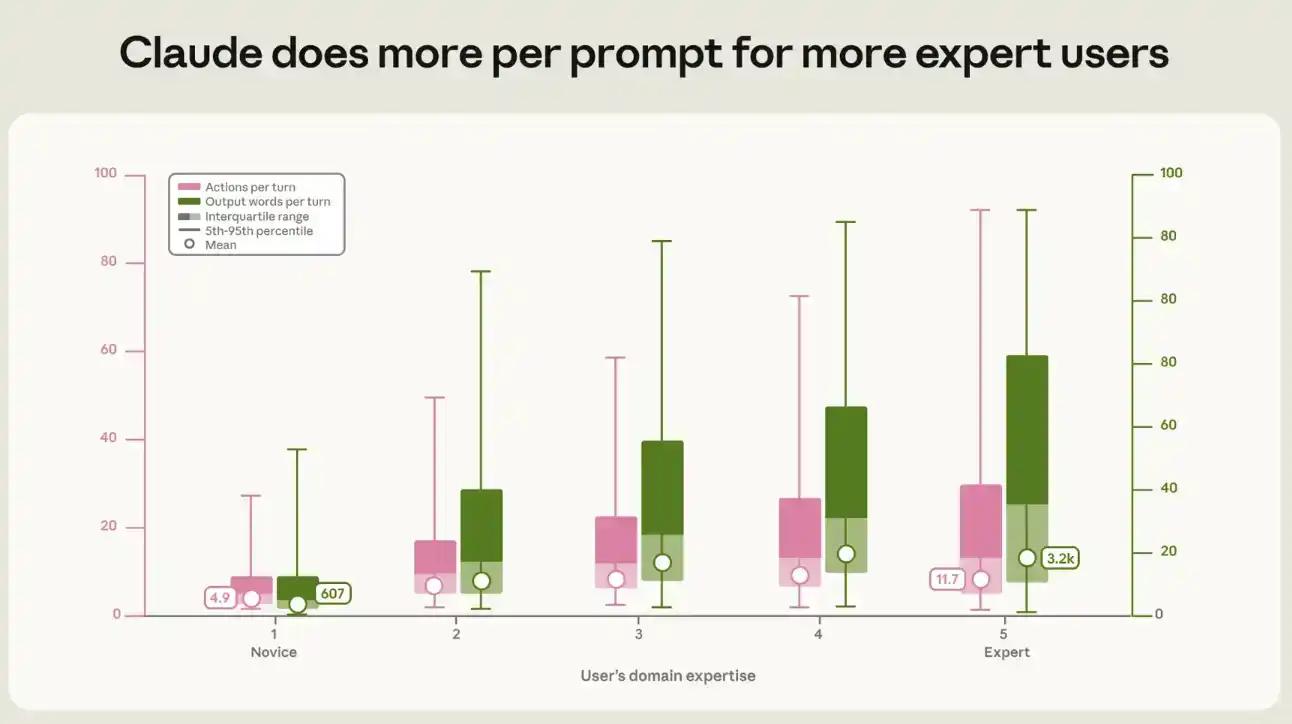
Cuantificamos la relación entre el nivel de experiencia y el volumen de salida y actividad generado por cada indicador de Claude. En una sesión típica de principiante, cada indicador activa que Claude ejecute alrededor de 5 acciones y produzca alrededor de 600 palabras; en una sesión de experto, la cadena de acciones es más del doble, alrededor de 12 acciones, y la producción es de alrededor de 3200 palabras, cinco veces más (ver Figura 3). Esta brecha entre principiantes y expertos aparece en todos los tipos de trabajo y en todos los rangos de valor de tarea.
Estas métricas complementan nuestra investigación anterior sobre la autonomía de Claude Code. La investigación anterior rastreaba el tiempo de ejecución del agente y con qué frecuencia los usuarios aprobaban automáticamente sus acciones. En contraste, nuestras métricas de atribución de decisiones capturan quién toma decisiones sustanciales a lo largo de toda la sesión, y el volumen de salida y número de acciones por indicador miden el grado de actividad autónoma que cada instrucción humana puede desencadenar en Claude.
Quién usa Claude Code y para qué lo usa
Usuarios
Para entender quién realiza este trabajo, inferimos la profesión de cada usuario a partir de los registros de sesión y la mapeamos a una de las 23 categorías principales del Sistema de Clasificación Ocupacional Estándar (SOC) de la Oficina de Estadísticas Laborales de EE. UU. Se pidió al clasificador que juzgara solo en base a las siguientes señales: el contexto del proyecto que el agente carga al inicio de la sesión, nombres y estructura de archivos, materiales o productos a los que el usuario hace referencia, como documentos legales, datos clínicos, informes financieros, material de cursos, etc., y el vocabulario que usa el usuario. Se instruyó explícitamente al clasificador para que no tomara "estar escribiendo código" como evidencia de que el usuario tiene una profesión de programación. Solo cuando había una señal clara de que el trabajo de software o datos era parte de la profesión del usuario, la sesión se asignaba a las categorías SOC relacionadas con codificación, es decir, "Profesiones informáticas y matemáticas". Si un abogado construye un script para verificar automáticamente si falta una cláusula en un conjunto de contratos, aunque la sesión consista principalmente en escribir software, se clasificaría como profesión legal. Si no había ninguna señal sobre la profesión del usuario, la sesión no se clasificaba.
Pudimos inferir la profesión en aproximadamente el 70% de las sesiones. Entre estas sesiones clasificables, "Profesiones informáticas y matemáticas" es el grupo más grande, lo cual no es sorprendente, ya que esta categoría abarca la mayoría de trabajos relacionados con software. Le siguen Operaciones comerciales y financieras, Arte, diseño y medios, Gestión, y Ciencias de la vida, físicas y sociales. En nuestra muestra, los grupos profesionales no relacionados con software de más rápido crecimiento son Gestión, Ventas y Profesiones legales.
Trabajo
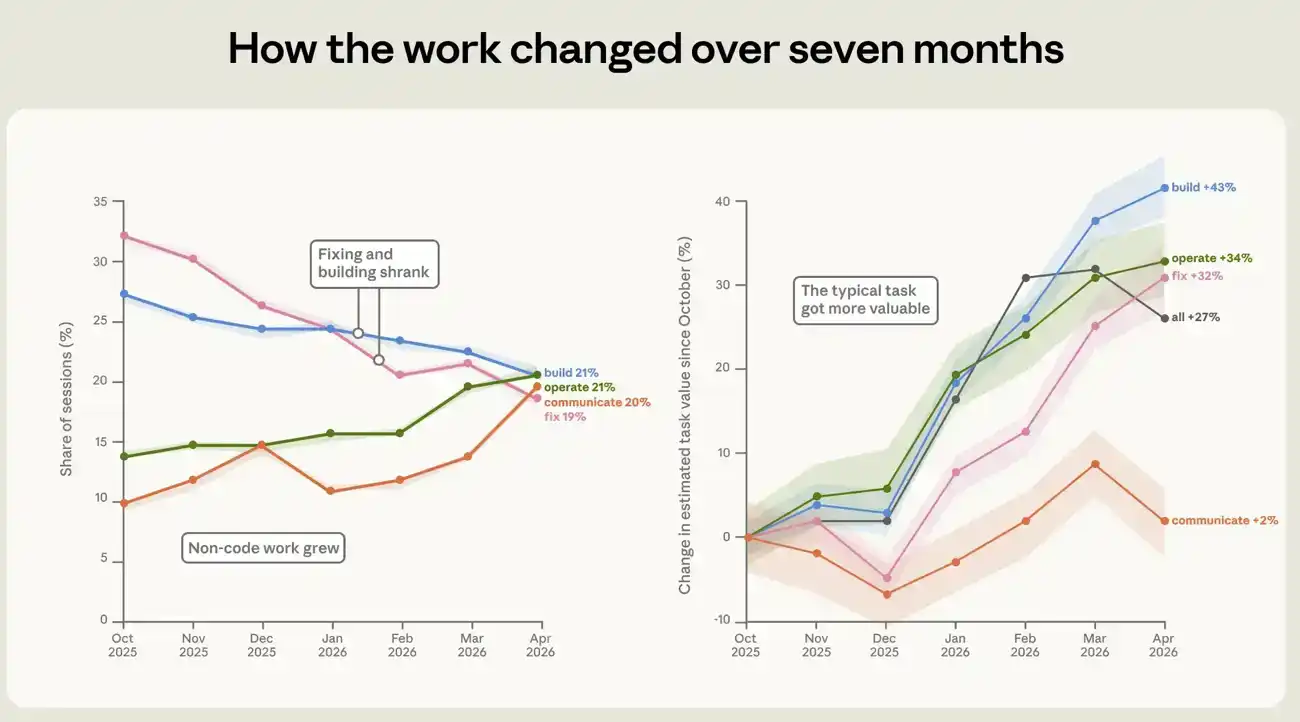
De octubre de 2025 a abril de 2026, la composición del trabajo realizado con Claude Code cambió significativamente. El cambio más notable fue que la proporción de sesiones dedicadas a arreglar código dañado disminuyó del 33% al 19% (ver Figura 4). En su lugar, hubo más trabajo centrado en el código. La proporción de operación de software aumentó del 14% al 21%. La escritura y el análisis de datos aproximadamente se duplicaron, pasando de alrededor del 10% a alrededor del 20%.
El valor de las tareas en sí también aumentó. Medimos aproximadamente el valor económico de cada sesión estimando el costo de un trabajo similar en el mercado de trabajo autónomo, calibrando con un conjunto de datos real de ofertas de empleo públicas. Según esta métrica, el valor estimado promedio de una sesión aumentó un 27% entre octubre y abril. Este aumento se produjo en múltiples tipos de trabajo. El valor de las tareas de construcción, operación y reparación aumentó aproximadamente un 43%, 34% y 32%, respectivamente. Estas estimaciones de precio son aproximadas, por lo que las usamos principalmente para comparar tendencias a lo largo del tiempo entre diferentes tareas, no como un valor en dólares directamente legible. Para más detalles sobre cómo se construyó el estimador de valor de tarea, ver el apéndice.
El éxito depende de lo que aporta el usuario
Estimar el valor de las tareas es una forma de entender cómo Claude Code ayuda a las personas a completar su trabajo. Otro ángulo es observar cuántas sesiones tienen éxito y qué características de la sesión se correlacionan con el éxito. En todas las métricas de éxito, vemos un patrón claro: cuanto mayor es el nivel de experiencia que el usuario muestra en la sesión, mayor es la probabilidad de que la sesión sea exitosa. La mayor parte de la mejora se concentra en el extremo inferior de experiencia; es decir, la brecha entre principiante y usuario intermedio es mayor que la brecha entre usuario intermedio y experto.
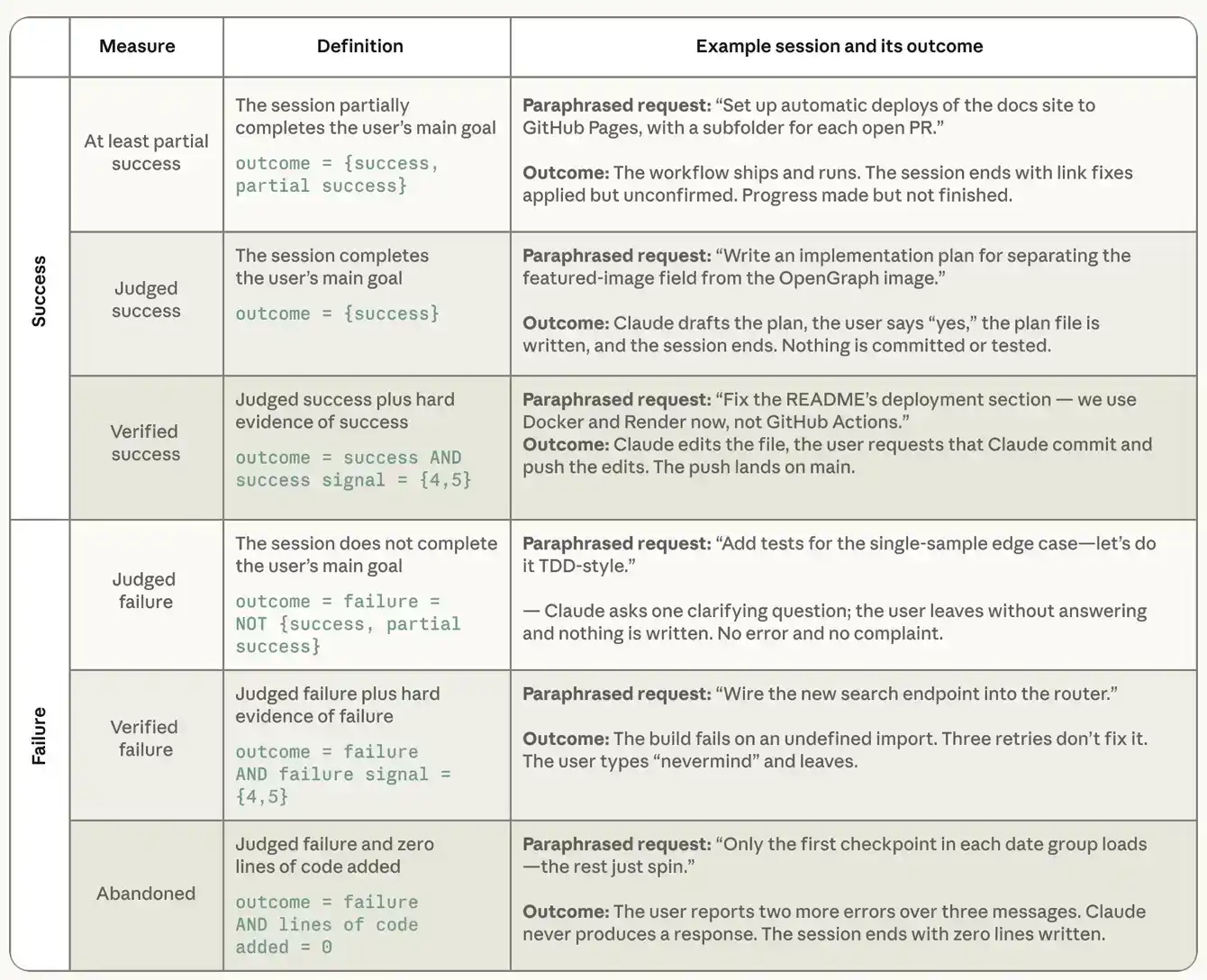
Antes de analizar las características de las sesiones exitosas, necesitamos especificar con precisión cómo medimos el éxito. No podemos observar los resultados del mundo real del usuario ni preguntarles directamente si completaron lo que pretendían con Claude. Por lo tanto, dependemos de dos métodos complementarios de medición basados en registros de sesión. El primero es "éxito juzgado", donde un clasificador lee el registro completo de la sesión y juzga si el usuario completó su objetivo original, con opciones que incluyen éxito, éxito parcial, fracaso, sin objetivo claro. Luego, dos clasificadores complementarios evalúan la fuerza de la evidencia de ese juicio para determinar un "éxito verificado". El clasificador de señales de éxito busca evidencia verificable de éxito, incluyendo especialmente actividad git acorde con el trabajo, como commits y pull requests, conjunto de pruebas aprobado, y confirmación explícita del usuario. Clasifica la sesión en una escala desde "sin señal" hasta "señal débil" (1 punto) y hasta "múltiples señales fuertes" (5 puntos). Otro clasificador paralelo de señales de fracaso puntúa la evidencia de que las cosas salieron mal, incluyendo errores, fallos en pruebas, intentos repetidos de lo mismo y objeciones del usuario a la salida. El éxito verificado requiere dos condiciones simultáneamente: que la sesión sea juzgada como exitosa y que exista al menos una señal fuerte verificable de éxito. El siguiente análisis se centra en el grado de éxito o fracaso en la sesión, por lo que excluimos las sesiones que el clasificador de resultados de éxito juzgó como "sin objetivo claro", que representan aproximadamente el 7.7% de la muestra completa.
Recompensa del nivel de experiencia
Entonces, ¿qué sesiones tienen más probabilidades de éxito? Los resultados muestran que la puntuación de experiencia de la sesión descrita anteriormente tiene una gran influencia en el éxito de la sesión.
Alguien podría preocuparse de que la experiencia no sea el verdadero factor impulsor. Tal vez los expertos simplemente eligen tareas diferentes, o difieren en otros aspectos. En esta sección, respondemos parcialmente a esta preocupación al comparar sesiones del mismo tipo de trabajo, mismo valor estimado, mismo mes, mismo tema y del mismo grupo profesional general, y examinar cómo el nivel de experiencia del usuario afecta los resultados.
En todas las métricas de éxito, cuanto mayor es el nivel de experiencia mostrado por el usuario en la sesión, más probable es que la sesión sea exitosa. Las sesiones calificadas como de principiante alcanzaron un éxito en nuestra métrica más estricta, "éxito verificado", en un 15%, y al menos un éxito parcial en un 77%. Las sesiones calificadas como intermedias o superiores tuvieron tasas de éxito verificado del 28% al 33%, y tasas de éxito parcial del 91% al 92% (ver Figura 5).
En cada métrica, la mayor parte de la ganancia proviene del paso de principiante a intermedio; la pendiente se ralentiza al pasar de intermedio a experto. Para detalles sobre el análisis de regresión detrás de la Figura 5, ver el apéndice.
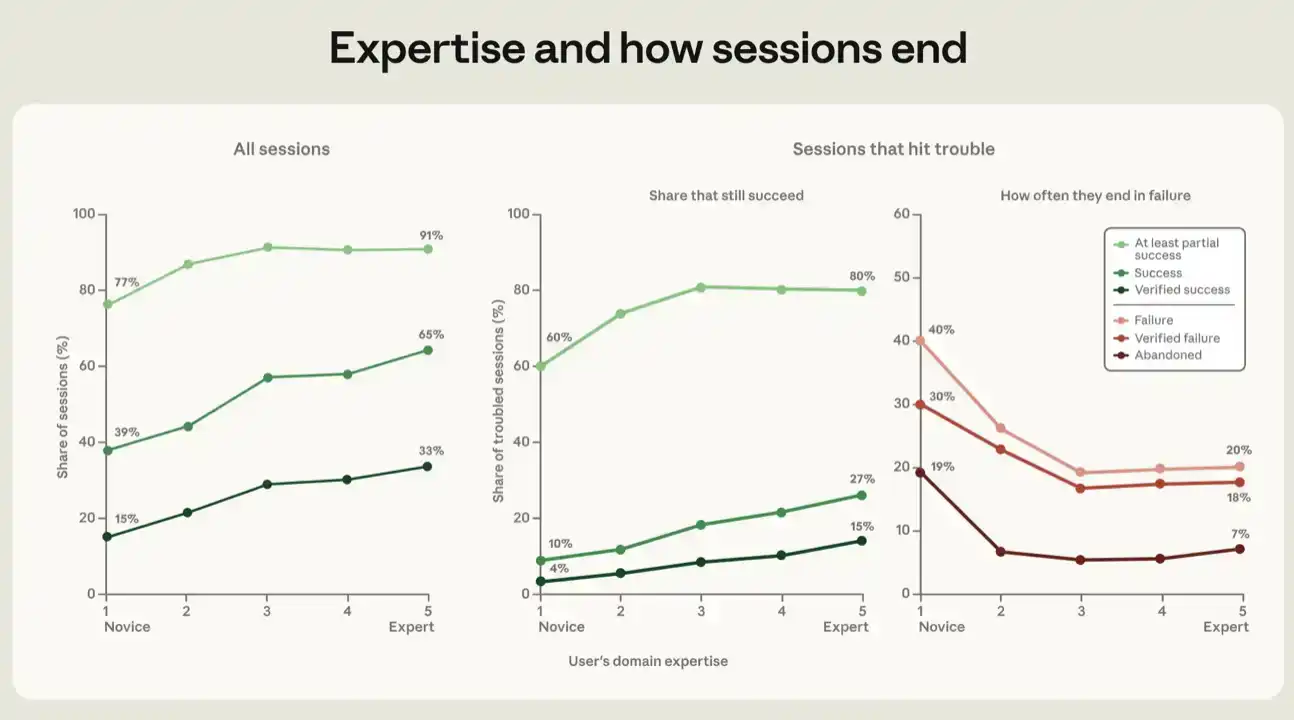
Se puede ver un gradiente similar en las sesiones que encontraron desafíos. Cuando el clasificador de señales de fracaso registra evidencia verificable de fracaso, consideramos que la sesión "tuvo problemas". Esto puede incluir errores, fallos en pruebas, múltiples intentos de completar lo mismo, o que el usuario exprese frustración e insatisfacción. En las sesiones con problemas, controlando todas las variables mencionadas anteriormente, la proporción de éxito verificado aumentó del 4% en sesiones de principiante al 15% en sesiones de experto (ver Figura 5). Si usamos métricas de éxito más laxas, encontramos que la proporción de al menos éxito parcial fue del 60% entre usuarios principiantes y del 80% al 81% entre usuarios intermedios y expertos.
También rastreamos la relación inversa, entre el nivel de experiencia y varios indicadores de fracaso. Es importante notar que, en este análisis, las sesiones juzgadas como fracasadas son aquellas que no lograron siquiera un éxito parcial. Si una sesión con problemas es juzgada como fracaso y no se escribió ninguna línea de código, la llamamos "abandonada". En las sesiones donde el usuario parecía principiante, el 19% terminó siendo abandonada; en otros grupos de usuarios, esta proporción fue del 5% al 7%. En otras palabras, los usuarios con menos experiencia, cuando se esfuerzan por alcanzar un objetivo y encuentran dificultades, son más propensos a abandonar. Parte del valor de la competencia parece radicar en la capacidad de redirigir al agente hacia el camino correcto.
La profesión puede ser menos importante que el nivel de experiencia
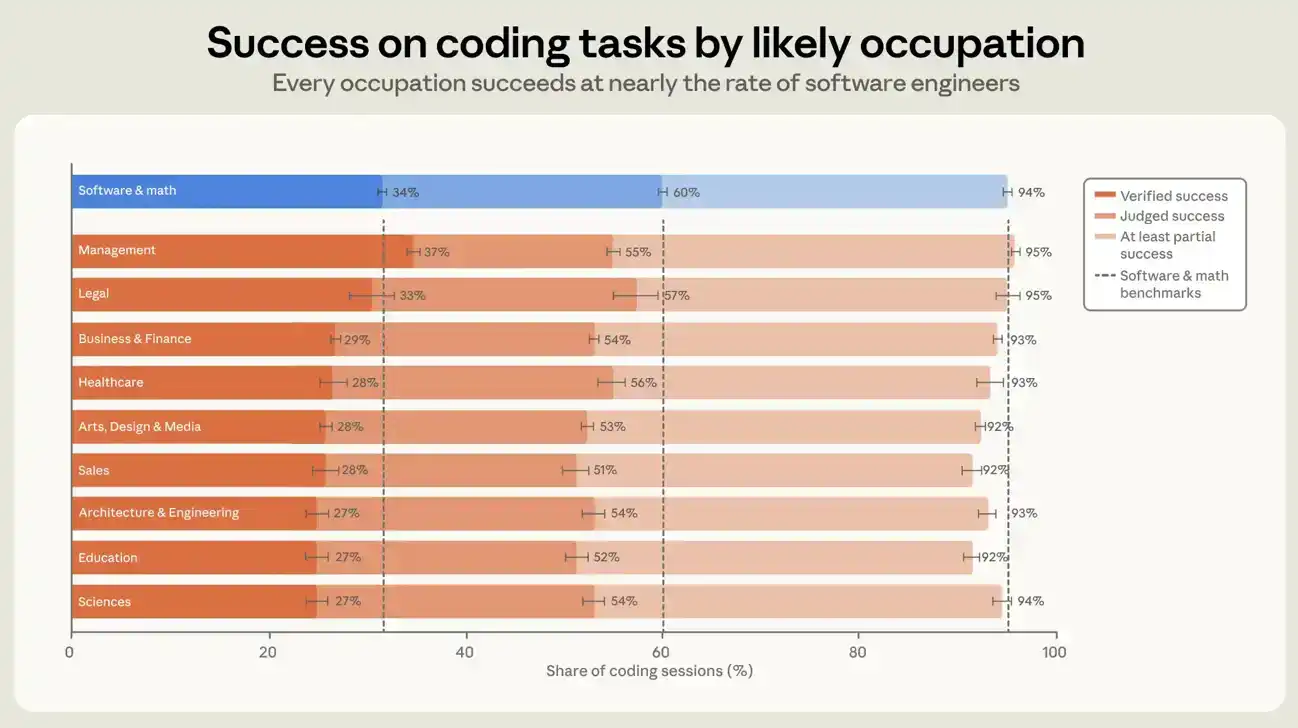
Los usuarios con profesiones relacionadas con software tuvieron una tasa de éxito verificado de aproximadamente el 30% en todas las sesiones, y los usuarios de otras profesiones de aproximadamente el 26%. En las sesiones que generaron código, es decir, sesiones que agregaron o modificaron al menos una línea de código, estas cifras fueron del 34% y 29%, respectivamente (ver Figura 6). Si usamos una definición de éxito más laxa, la brecha entre profesiones relacionadas con software y otras profesiones se reduce aún más. En las sesiones que generaron código, las proporciones de al menos éxito parcial fueron del 89% y 88%, respectivamente. Una diferencia de cinco puntos porcentuales no es grande, y durante los siete meses no se amplió ni se redujo, aunque las tasas de éxito de ambos grupos aumentaron. En las sesiones que generaron código, cada uno de los diez grupos profesionales más grandes en nuestro conjunto de datos tuvo una diferencia en la tasa de éxito con los ingenieros de software de dentro de siete puntos porcentuales. Las profesiones de gestión tuvieron la tasa de éxito verificado más alta, ligeramente superior a las profesiones de ingeniería de software. La mayor tasa de éxito verificado de los gestores puede reflejar que las habilidades de gestión son transferibles a la tarea de dirigir agentes. Pero también puede deberse en parte a nuestra forma de medición: la verificación depende en cierta medida de la confirmación explícita del usuario durante la sesión, y los gestores pueden estar más acostumbrados a expresarse cuando obtienen el resultado deseado.
Perspectiva
Los resultados de este informe esbozan un panorama emergente: la programación con agentes está amplificando ciertos conocimientos y habilidades, mientras reemplaza a otras. En las sesiones que generan código, las principales profesiones tienen tasas de éxito no muy diferentes a las de las profesiones relacionadas con software. Parece que los agentes de codificación están haciendo que tener experiencia en programación sea menos importante para completar con éxito tareas de programación.
Al mismo tiempo, las sesiones exitosas tienen más probabilidades de mostrar experiencia en el dominio. Las sesiones calificadas como expertas tienen una tasa de éxito verificado más del doble que las de principiantes. Cuando una sesión encuentra problemas, los principiantes abandonan a una tasa varias veces mayor que otros usuarios. La propia forma de colaboración hace que esta imagen sea más clara: los expertos en el dominio pueden guiar a Claude para que realice más trabajo por cada instrucción. Por lo tanto, la capacidad de guiar a Claude hacia el éxito proviene más del dominio de un campo que de la capacidad de escribir código. Cualquier persona con ese dominio en cualquier campo ahora puede realizar trabajos técnicos que antes no podía. Y aquellos que carecen de esa comprensión profesional, incluso usando las mismas herramientas, obtendrán mucho menos. Además, la mayor parte de la ganancia proviene de ser competente, no de ser un experto. Tener una comprensión operativa de un dominio ya proporciona la mayor parte de la recompensa; la especialización profunda solo aporta una pequeña ventaja adicional.
Estos hallazgos son aún preliminares. Como en la mayoría de nuestras investigaciones, no podemos medir resultados del mundo real, como si el código escrito en una sesión fue usado o descartado posteriormente, o si produjo resultados de valor económico. Además, este informe excluye el uso no interactivo, que representa una parte considerable de la actividad total. Desarrollar un marco para medir este tipo de uso es un enfoque importante para el trabajo futuro. Y, todas nuestras clasificaciones de sesiones dependen de que el modelo lea los registros de la sesión. En el apéndice, mostramos que los clasificadores son consistentes con los datos de telemetría independientes en la dirección esperada, y en la mayoría de las sesiones son consistentes con el juicio de un modelo de referencia fuerte. Pero validar clasificadores a gran escala sigue siendo difícil; las propias sesiones de Claude Code añaden dificultad, ya que pueden ser demasiado largas y complejas para usar anotación humana como un punto de referencia real.
A medida que los modelos, los usuarios y la división del trabajo entre ellos continúan cambiando, el panorama de este informe también se actualizará. Esperamos que estas métricas nos ayuden a rastrear las grandes transiciones que están ocurriendo. Por ejemplo, si la recompensa por el nivel de experiencia comienza a disminuir en el futuro, eso indicaría que los modelos están comenzando a proporcionar el juicio clave que actualmente aportan los usuarios, y el beneficio de estas herramientas se extendería desde los expertos en el dominio a una población más amplia. Si la proporción de usuarios fuera de las profesiones de software que completan con éxito sesiones de codificación continúa aumentando, podría significar que la producción de software se está convirtiendo en parte del trabajo ordinario en todos los campos, y no solo en el producto de una única profesión. Estos cambios alterarán quién se beneficia de la programación con agentes y cuánto, y afectarán las habilidades más valoradas en el mercado laboral.





