In May of this year, Meta drew a clear line for its own engineers.
People in the Applied AI Engineering department can no longer freely use Claude Code and Codex.

According to an internal guide obtained by The Information, a memo even directly called for a pause on certain tasks involving these two models. The wording was severe, stating this could trigger a "serious escalation with partners."
However, the strangeness lies precisely here.
Meta is one of Claude Code's largest global customers. Its total internal AI bill this year is heading towards tens of billions of dollars.
A tool used daily, purchased by the company at great cost, is now being restricted internally. And the reason for the restriction is probably something you wouldn't expect.
It's not that they aren't useful. On the contrary, it's because they are *too* useful.
This Red Line is Still in Effect
According to The Information report, these restrictions were set in May and are still in effect today.
To understand why Meta is so tense, we need to start with an internal AI coding assistant project.
This year, it formed an Applied AI Engineering team, focusing on its self-developed AI coding assistant MetaCode (formerly DevMate).
The goal is to stop Meta from spending huge sums continuing to use others' AI coding models and to train its own.
The official interface of Claude Code. Together with OpenAI's Codex, they have become the de facto standard for professional developers doing agentic programming.
But training a model that can write code is not simple.
You need to feed it massive amounts of high-quality data, and also generate enough, sufficiently tricky programming problems for it to practice on and be graded on. This set of problems and evaluations almost determines how powerful a coding model ultimately becomes.
But the problem lies precisely here.
The difficulty Meta encountered is how to prevent employees from becoming too reliant on these external tools while building the internal replacement.
What it worries about is the outputs from these external models seeping into the training data, causing the model it builds to secretly learn the competitor's capabilities.
To understand this concern, you need to know how a model "learns": You feed it what kind of data, it becomes that kind of model.
MetaCode wants to become stronger by relying on the training data and programming problem sets accumulated by engineers.
But once these problems, answers, and even grading criteria come from Claude or Codex, what MetaCode learns is no longer "skills trained by human engineers," but "Claude's skills."
It's copying answers from the competitor's test paper, becoming more and more like the competitor.
Even more hidden is the evaluation part.
Every time a model answers a question, something must tell it if it answered well so it knows where to improve.
If both problem creation and grading are handed to Codex, then MetaCode is evolving towards what "Codex thinks is correct," essentially copying the competitor's judgment standards bit by bit into its own mind.
This is why Meta's guide prohibits AI from being the problem creator or grader, and even governs whether "AI-generated materials can enter the environment accessible to the model under test."
As long as the competitor's output seeps into the training or evaluation chain in any way, the line of "who taught whom" becomes blurred.
Ultimately, Meta's pause on certain tasks is about isolating the training data.
It fears that the AI writes so well that it becomes unclear which skills were trained internally and which were learned from Claude and Codex.
And the latter set of capabilities is rented, not its own.
Surprisingly Detailed Restrictions
It must be clarified first that Meta's internal documents show no actual records of employees violating rules.
A Meta spokesperson also responded that the company has "clear policies" governing the use of AI tools. So this document is more like an internal early warning.
What tasks can't AI handle? Mainly the following three categories:
First, you cannot use Claude or Codex outputs to create test questions for your own model. The guide's exact words are, this "clearly falls into the category where engineers are not in the driver's seat," "We do not want tasks derived from models."
Second, AI cannot find bugs in source code, nor can it help you think about "what to test" based on code analysis.
Third, anything generated by AI cannot be placed anywhere accessible by the model under test.
Simply put, as long as AI participates in the judgment of "what to test" or "whether the answer is correct," the competitor's skills might mix in. The three rules block this opening.
What tasks can AI still do?
Setting up workflows, organizing code and files, building test frameworks for internal tools—these daily chores are allowed. The guide calls this type of work "test scaffolding" and "solution calibration," essentially assisting and building frameworks.
Even for these tasks, there is one ironclad rule: Every line of AI output must be reviewed by a human first.
In Meta's view, once you let a competitor's model create the test and grade it, it becomes unclear whose test this is.
What it truly wants to protect is that line of "who taught whom."
The Unavoidable "Distillation Trap"
What Meta worries about has a specific name in the industry: distillation.
The meaning is easy to understand: Use a stronger model to continuously answer questions, then use these answers to train a weaker model.
It's a bit like having the top student redo the entire exam paper, and the struggling student copies it, catching up to years of effort in months.
The massive investment others put into data, computing power, and research, you almost get for free.
Training a cutting-edge model from scratch costs astronomical sums of money and time. Distillation, however, might only require a batch of outputs from the other model, reducing costs and timelines to a fraction.
Distillation itself is standard industry practice; big companies also often distill their own large models to create smaller, cheaper versions for users.
The trouble only arises: Once you are copying someone else's model, the capabilities you train—are they your own, or borrowed? It's unclear.
Some call this the "distillation trap": The more you rely on the strongest model to build your own foundation, the harder it is to prove where your intelligence actually came from.
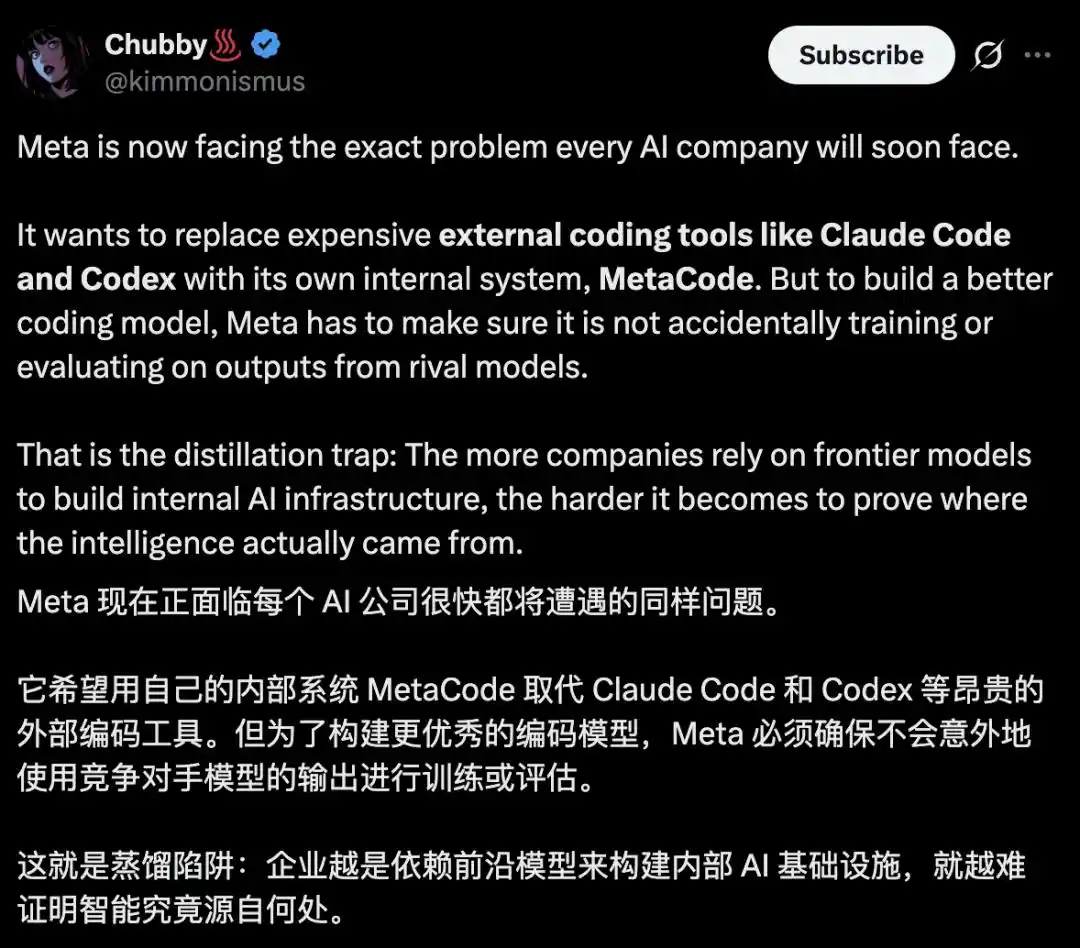
In the United States, the law does not explicitly prohibit distillation, and AI-generated content is not protected by copyright. Using the other's output to train your own model basically passes the legal hurdle.
The only barrier is the contract.
Both OpenAI's and Anthropic's terms of service contain similar restrictions: You cannot use the model's outputs to create something that competes with them.
Moreover, the enforcement power for this barrier lies entirely with the competitor.
Last year, Anthropic directly cut off OpenAI's API access to Claude, even though OpenAI claimed it was only for evaluating capabilities and safety, a "standard industry" practice.
Even Musk was forced to admit in a court hearing this past April that his xAI "partially" distilled OpenAI's models.

April 30, 2026, in the witness stand at a California federal court, Musk was asked if xAI used distillation techniques on OpenAI models to train Grok. He first said this was common practice for AI companies.
When pressed if this amounted to a "yes," he replied "partially."
The rules are fuzzy, and "enforcement power" is held by competitors. Who dares to bet their billions in investment that a competitor won't turn hostile?
From this perspective, Meta's tension is not at all excessive.
Here, there's also the consideration of saving money.
According to internal memos, Meta will burn tens of billions of dollars this year just on internal AI use. It has even started setting token usage limits for employees. Even a cash-rich giant like Meta is starting to find AI too expensive and is calculating carefully.
If development work can be shifted from expensive external tools to its own MetaCode, it saves money while avoiding the minefield of distillation—killing two birds with one stone.
A Tightrope-Walking Map
Regarding Meta's internal documents, tech law scholar and legal advisor Mark Leiser has a vivid phrase: This is "almost like a map for walking a tightrope."
On one side, you need to gain the benefits of external models; on the other, you must prevent their capabilities from slipping into your own system.
Of course, Meta isn't the only company walking this tightrope; it touches a vital point for the entire industry.
When you use a sufficiently smart AI to build another equally smart AI, in the end, you might find it hard to say clearly: Is this intelligence something you trained yourself, or did you secretly learn it from someone else's AI?
And this issue isn't that far from ordinary people either.
The code you write with AI, the plans you modify, the materials you compile—feeding them back becomes nourishment for the next generation of models.
In this cycle, who is standing on whose shoulders? That line has become increasingly blurred.
When AI starts helping us build AI, can we still tell whose capabilities are whose?
References:
https://x.com/kimmonismus/status/2071591755351224344
https://www.theinformation.com/articles/internal-docs-show-meta-putting-limits-claude-codex-fearing-distillation
This article is from the WeChat public account "New Zhiyuan", author: ASI Apocalypse