Original Title: A shallow dive into formal verification
Original Author: Vitalik
Original Compilation: Peggy, BlockBeats
Editor's Note: As AI programming capabilities rapidly advance, software security is facing a new paradox: AI can generate code more efficiently, but it can also find vulnerabilities more efficiently. For the cryptocurrency industry, this issue is especially critical. Defects in smart contracts, ZK proofs, consensus algorithms, and on-chain asset systems often do not result in simple software errors but in irreversible financial losses and a collapse of trust.
In this article, Vitalik discusses another path to code security in the AI era: formal verification. Simply put, instead of relying on human auditors to check code line by line, it involves writing the properties a program should satisfy as mathematical propositions and then using machine-checkable proofs to verify whether these properties hold. In the past, formal verification remained a relatively niche research and engineering field due to its high barrier to entry and cumbersome process. However, as AI can assist in writing both code and proofs, this approach is gaining renewed practical significance.
The core argument of the article is not that "formal verification can solve all security problems." On the contrary, Vitalik repeatedly reminds us that "provable security" does not equal absolute security: proofs may omit critical assumptions, specifications themselves may be written incorrectly, unverified code, hardware boundaries, and side-channel attacks can all become new sources of risk. Yet, it still offers a more reliable security paradigm: expressing developer intent in multiple ways and then having the system automatically check whether these expressions are compatible with each other.
This is particularly important for Ethereum. Future Ethereum will increasingly rely on complex underlying components, including STARKs, ZK-EVMs, quantum-resistant signatures, consensus algorithms, and high-performance EVM implementations. The implementations of these systems are extremely complex, but their core security goals can often be formalized relatively clearly. It is precisely in such scenarios that AI-assisted formal verification can potentially deliver the greatest value: letting AI handle writing efficient code and proofs, while humans check whether the finally proven propositions truly correspond to the intended security goals.
From a broader perspective, this article is also Vitalik's response to network security in the AI era. Faced with more powerful AI attackers, the answer is not to abandon open source, give up smart contracts, or revert to relying on a few centralized institutions. Instead, it is to compress critical systems into smaller, more verifiable, and more trustworthy "secure cores." AI may lead to a proliferation of sloppy code, but it may also make truly important code more secure than ever before.
Below is the original text:
Special thanks to Yoichi Hirai, Justin Drake, Nadim Kobeissi, and Alex Hicks for providing feedback and review on this article.
Over the past few months, a new programming paradigm has been rapidly emerging in Ethereum's cutting-edge research circles and many other corners of the computing field: developers are writing code directly in very low-level languages, such as EVM bytecode, assembly language, or using Lean, and verifying its correctness by writing machine-checkable mathematical proofs in Lean.
When applied properly, this approach has the potential to generate extremely efficient code and be significantly more secure than traditional software development methods. Yoichi Hirai has called it the "ultimate form of software development." This article will attempt to explain the underlying logic of this methodology: what formal verification of software can actually do, and where its limitations and boundaries lie—both within the Ethereum context and in the broader field of software development.
What is Formal Verification?
Formal verification refers to writing proofs of mathematical theorems in a way that can be automatically checked by a machine.
To give a relatively simple yet interesting example, consider a basic theorem about the Fibonacci sequence: every third number is even, and the other two are odd.

A simple way to prove this is by mathematical induction, advancing three steps at a time.
First, consider the base case. Let F1 = F2 = 1, F3 = 2. By direct observation, we can see that the proposition—"when i is a multiple of 3, Fi is even; otherwise, Fi is odd"—holds for all numbers up to and including x = 3.
Next is the inductive step. Assume the proposition holds up to 3k+3. That is, we know the parity of F3k+1, F3k+2, and F3k+3 is odd, odd, and even, respectively. Then, we can calculate the parity of the next group of three numbers:
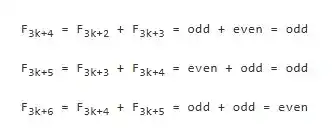
Thus, we have completed the derivation from "knowing the proposition holds up to 3k+3" to "confirming the proposition also holds up to 3k+6." By repeating this reasoning, we can be confident that this rule holds for all integers.
This argument is convincing to humans. But what if the thing you want to prove is a hundred times more complex, and you really, really want to make sure you haven't made a mistake? That's when you can construct a proof that can convince a computer as well.
It would look something like this:

This is the same reasoning, but expressed in Lean. Lean is a programming language often used for writing and verifying mathematical proofs.
It looks quite different from my "human-readable" proof above, and for good reason: what's intuitive for a computer is very different from what's intuitive for a human. By computer, we mean the old-fashioned sense of the word—a "deterministic" program built from if/then statements, not a large language model.
In the proof above, you aren't emphasizing the fact that fib(3k+4) = fib(3k+3) + fib(3k+2); you're emphasizing that fib(3k+3) + fib(3k+2) is odd, and the rather grandiosely named `omega` tactic in Lean automatically combines this with its understanding of the definition of fib(3k+4).
In more complex proofs, sometimes you have to explicitly state at each step exactly which mathematical law allows you to take that step, and these laws sometimes have obscure names like `Prod.mk.inj`. On the other hand, you can also expand huge polynomial expressions in a single step, needing only to write a line like `omega` or `ring` to complete the argument.
This lack of intuitiveness and cumbersome nature is a big reason why machine-verifiable proofs, while having existed for nearly 60 years, have remained a niche field. But at the same time, many things that were almost impossible in the past are rapidly becoming feasible due to the rapid progress of AI.
Verifying Computer Programs
At this point, you might think: Okay, so we can make computers verify proofs of mathematical theorems, and we can finally be sure which of those crazy new discoveries about prime numbers are actually true and which are just errors hidden in hundreds of pages of PDFs. Maybe we can even figure out if Shinichi Mochizuki's proof of the ABC conjecture is correct! But aside from satisfying curiosity, what's the practical significance of this?
There are many answers. For me, a very important answer is: verifying the correctness of computer programs, especially those involving cryptography or security. After all, a computer program is itself a mathematical object. Therefore, proving that a computer program will behave in a certain way is essentially proving a mathematical theorem.
For example, suppose you want to prove whether an encrypted communication software like Signal is truly secure. You could start by writing down mathematically what "security" even means in this context. Roughly, you want to prove that, under certain cryptographic assumptions holding true, only the person with the private key can learn any information about the message content. In reality, of course, there are many kinds of security properties that truly matter.
And it turns out there is indeed a team trying to figure this out. One of the security theorems they propose looks roughly like this:

Here is Leanstral's summary of what this theorem means:
The `passive_secrecy_le_ddh` theorem is a tight reduction showing that, under the Random Oracle Model, the passive message confidentiality of X3DH is at least as hard to break as the DDH assumption.
In other words, if an attacker can break the passive message confidentiality of X3DH, then they can also break DDH. Since DDH is generally assumed to be a hard problem, X3DH can therefore be considered secure against passive attacks.
The theorem proves that if an attacker can only passively observe Signal's key exchange messages, they cannot distinguish the final generated session key from a random key with more than a negligible probability advantage.
If you then combine this with a proof that AES encryption is correctly implemented, you can get a proof that Signal's protocol encryption mechanism can resist passive attackers.
Similar verification projects already exist for proving the secure implementation of TLS and other cryptographic components within browsers.
If you can achieve end-to-end formal verification, you are proving not just that a protocol description is theoretically secure, but that the specific piece of code users actually run is also secure in practice. From a user's perspective, this significantly increases the degree of "trustlessness": to fully trust this code, you don't need to inspect the entire codebase line by line; you only need to check the statements that have been proven to hold.
Of course, there are some very important asterisks to retain here, especially regarding what the word "secure" actually means. It's easy to forget to prove the really important claims; it's easy to end up in a situation where the claim that needs to be proven doesn't have a more concise description than the code itself; it's also easy to sneak in assumptions into the proof that ultimately don't hold. It's also easy to decide that only one part of the system truly needs formal proof, but then get hit by a critical vulnerability in another part, or even at the hardware level. Even Lean's own implementation could have bugs. But before delving into these headache-inducing details, let's take a further look: if formal verification could be done ideally and correctly, what kind of nearly utopian prospects might it bring?
Formal Verification for Security
Bugs in computer code are inherently worrying.
When you put cryptocurrency into immutable on-chain smart contracts, code bugs become even more terrifying. Because if the code is wrong, North Korean hackers could automatically transfer all your money away, with almost no recourse for you.
When all this is wrapped in zero-knowledge proofs, code bugs become even more terrifying. Because if someone successfully breaks a zero-knowledge proof system, they could withdraw all the funds, and we might have no idea what went wrong—or worse, we might not even know a problem has occurred.
When we have powerful AI models, code bugs become even more terrifying. Models like Claude Mythos, after two more years of improvement, could likely automate the discovery of such vulnerabilities.

Faced with this reality, some have begun to advocate abandoning the very idea of smart contracts, and even the notion that cyberspace can ever be a domain where defenders have an asymmetric advantage over attackers.
Here are some quotes:
"To fortify a system, you need to spend more tokens discovering vulnerabilities than an attacker spends exploiting them."
And:
"Our industry is built around deterministic code. Write, test, deploy, and know it will run—but in my experience, this contract is breaking down. Among top operators of truly AI-native companies, codebases have begun to become something 'you believe will run,' and the probability corresponding to this belief can no longer be precisely stated."
Worse, some believe the only solution is to abandon open source.
This would be a bleak future for cybersecurity. It would be an exceptionally bleak future for those who care about decentralization and freedom on the internet. The entire cypherpunk spirit is fundamentally built on the idea that on the internet, defenders have the advantage. Building a digital "castle"—whether it manifests as encryption, signatures, or proofs—is easier than destroying it. If we lose this, then internet security can only come from economies of scale, from hunting down potential attackers worldwide, and more broadly, from a choice: either dominate everything, or face ruin.
I disagree with this assessment. I have a much more optimistic vision for the future of cybersecurity.
I believe the challenge posed by powerful AI vulnerability discovery is indeed severe, but it is a transitional challenge. After the dust settles and we enter a new equilibrium, we will arrive at a state that is more favorable to defenders than before.
Mozilla agrees. To quote them:
"You might need to re-prioritize everything else and dedicate yourself to this task in a sustained, focused way. But there is light at the end of the tunnel. We are incredibly proud to see how the team has stepped up to meet this challenge, and others will too. Our work is not yet done, but we've passed the inflection point and are beginning to see a better future that is more than just 'keeping up.' Defenders finally have a chance for a decisive win."
......
"There is a limited number of defects, and we are entering a world where we can finally find them all."
Now, if you Ctrl+F for "formal" and "verification" in Mozilla's article, you'll find neither word appears. The positive future of cybersecurity does not strictly depend on formal verification, nor on any other single technology.
What does it depend on? Basically, on this chart:
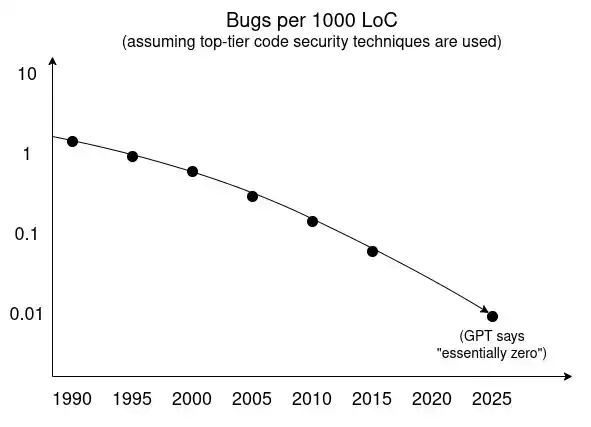
Over the past few decades, many technologies have contributed to the trend of "declining vulnerability counts":
Type systems;
Memory-safe languages;
Software architecture improvements, including sandboxing, capability systems, and more generally, clearly distinguishing the "trusted computing base" from "other code";
Better testing methodologies;
Accumulated knowledge about safe and unsafe coding patterns;
Increasingly available pre-written and audited software libraries.
AI-assisted formal verification should not be seen as a brand new paradigm, but as a powerful accelerator: it is accelerating a trend and paradigm that was already moving forward.
Formal verification is not a panacea. But in certain scenarios, it is especially applicable: namely, when the goal is far simpler than the implementation. This is particularly evident in some of the trickiest technologies that need to be deployed for Ethereum's next major iteration, such as quantum-resistant signatures, STARKs, consensus algorithms, and ZK-EVMs.
STARKs are very complex software. But the core security property they implement is easy to understand and formalize: if you see a proof that points to a hash H of program P, input x, and output y, then either the hash algorithm used by the STARK has been broken, or P(x) = y. Hence, we have projects like Arklib, which aims to create a fully formally verified STARK implementation. Another related project is VCV-io, which provides foundational oracle computation infrastructure that can be used for formal verification of various cryptographic protocols, many of which are themselves dependencies of STARKs.
More ambitious is evm-asm: a project attempting to build a complete EVM implementation and formally verify it. Here, the security property is less clear-cut. Simply put, its goal is to prove that this implementation is equivalent to another EVM implementation written in Lean, which is optimized for intuitiveness and readability without regard to runtime efficiency.
Of course, theoretically, a situation could still arise where we have ten EVM implementations, all proven equivalent to each other, yet all share the same fatal flaw that somehow allows an attacker to transfer all ETH from an address they don't control. But the probability of this happening is much lower than the probability of a single EVM implementation having such a flaw today. Another security property whose importance we truly learned through painful experience—resistance to DoS attacks—is also relatively easy to specify.
Two other important directions are:
Byzantine Fault Tolerant consensus. Formally defining all desired security properties is not easy here either. But given that related bugs have been very common, attempting formal verification is still worthwhile. Therefore, there is ongoing work on Lean consensus implementations and their proofs.
Smart contract programming languages. Examples include formal verification work in Vyper and Verity.
In all these cases, a huge incremental value of formal verification is that the proofs are truly end-to-end. Many of the trickiest bugs are interactive bugs that appear at the boundaries between two separately considered subsystems. End-to-end reasoning about the entire system is too difficult for humans, but an automated rule-checking system can do it.
Formal Verification for Efficiency
Let's look at evm-asm again. It's an EVM implementation.
But it's an EVM implementation written directly in RISC-V assembly language.
Literally assembly.
Here is the ADD opcode:
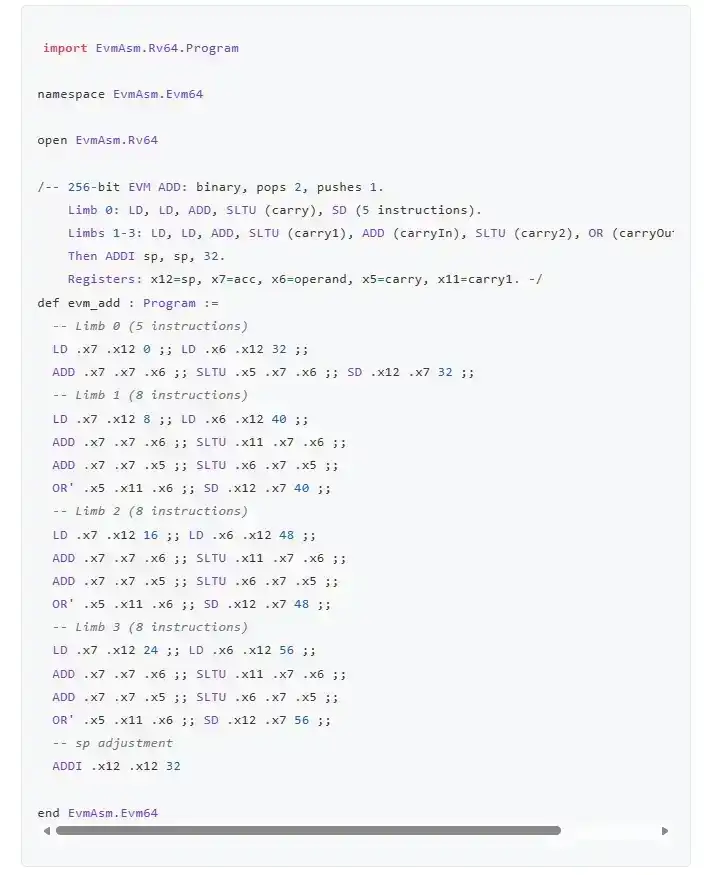
RISC-V is chosen because the ZK-EVM provers currently being built typically work by proving RISC-V and compiling Ethereum clients down to RISC-V. Therefore, if you write an EVM implementation directly in RISC-V, theoretically it should be the fastest implementation you can get. RISC-V can also be emulated very efficiently on ordinary computers, and RISC-V laptops already exist. Of course, for true end-to-end, you also need to formally verify the RISC-V implementation itself, or the prover's arithmetic representation. But don't worry—such work already exists too.
Writing code directly in assembly is something we used to do fifty years ago. Since then, we've largely moved to writing code in higher-level languages. Higher-level languages sacrifice some efficiency, but in exchange, they make coding much faster and, more importantly, make understanding other people's code much faster—which is necessary for security.
With the combination of formal verification and AI, we have a chance to "go back to the future." Specifically, we can let AI write the assembly code, and then write formal proofs verifying that this assembly code has the properties we want. At a minimum, this target property can be that it is completely equivalent to an implementation written in a human-friendly high-level language optimized for readability.
This way, there is no longer a need for a single code object to balance readability and efficiency. We would have two separate objects: one, the assembly implementation, optimized purely for efficiency and tailored to the specific execution environment; and two, the security claims, or the high-level language implementation, optimized purely for readability. Then, we use a mathematical proof to prove equivalence between the two. Users can automatically verify this proof once; after that, they only need to run the fast version.
This is very powerful. It's not without reason that Yoichi Hirai calls it the "ultimate form of software development."
Formal Verification is Not a Panacea
In cryptography and computer science, there is a tradition almost as old as formal methods themselves: criticizing formal methods, or more broadly, criticizing reliance on "proofs." The literature is full of practical case studies. Let's start with the simpler, early hand-written proofs in cryptography. Menezes and Koblitz criticized them in 2004:
"In 1979, Rabin proposed an encryption function that is 'provably' secure in the sense that it has a reducibility security property.
The reducibility security claim is: anyone who can find the message m from ciphertext y must also be able to factor n.
Soon after Rabin proposed his encryption scheme, Rivest pointed out that ironically, the very feature that gave it extra security would also cause the system to collapse completely against another type of attacker, the so-called 'chosen ciphertext' attacker. Specifically, suppose the attacker can somehow induce Alice to decrypt a ciphertext of the attacker's own choosing. Then the attacker could factor n using the same procedure Sam used in the previous paragraph."
Menezes and Koblitz then gave several more examples. Together they reveal a pattern: designing cryptographic protocols around being "easier to prove" often makes the protocols less "natural" and more likely to break in scenarios the designers never considered.
Now, let's return to machine-verifiable proofs and code. Here is an example from a 2011 paper that found bugs in a formally verified C compiler:
"The second CompCert issue we discovered manifests in two bugs that generate code like this: `stwu r1, -44432(r1)`
Here a large PowerPC stack frame is being allocated. The problem is that the 16-bit displacement field overflows. CompCert's PPC semantics don't specify a constraint on the width of this immediate value, because it assumes the assembler will catch out-of-range values."
Consider a 2022 paper:
"In CompCert-KVX, commit e2618b31 fixed a bug: the 'nand' instruction would be printed as 'and'; 'nand' was only selected in the rare ~(a & b) pattern. This bug was found by compiling randomly generated programs."
Fast forward to today, 2026, Nadim Kobeissi, describing vulnerabilities in formally verified software from Cryspen, writes:
"In November 2025, Filippo Valsorda independently reported that libcrux-ml-dsa v0.0.3 generates different public keys and signatures on different platforms given the same deterministic inputs. This bug was in the `_vxarq_u64` builtin wrapper, which implements the XAR operation used in SHA-3's Keccak-f permutation. The fallback path passed the wrong parameter to the shift operation, causing SHA-3 digests to be corrupted on ARM64 platforms lacking hardware SHA-3 support. This is a Type I failure: the builtin was marked as verified, while the entire NEON backend had no runtime safety or correctness proof."
And:
"The libcrux-psq crate implements a post-quantum pre-shared key protocol. In the `decrypt_out` method, the AES-GCM 128 decryption path calls `.unwrap()` on the decryption result instead of propagating the error. A malformed ciphertext can crash the process."
These four issues above can be categorized into two types:
Type 1: Only part of the code was verified because verifying the rest was too hard; and it turned out the unverified code was more prone to bugs than the authors thought, and these bugs were often more critical.
Type 2: The authors forgot to explicitly specify a key property that needed to be proven.
Nadim's article categorizes the failure modes of formal verification; he lists other types as well. For example, another major type is: the formal specification itself is wrong, or the proof contains erroneous claims that are silently accepted by the build system.
Finally, we can also look at formal verification failures at the software-hardware boundary. A common issue here is verifying that a system is resistant to side-channel attacks. Even if you protect a message with theoretically perfectly secure encryption, if someone a few meters away can capture electrical fluctuations and extract your private key after a few hundred thousand encryptions, you are still not secure.
"Differential power analysis" is a now well-understood example of such a technique.
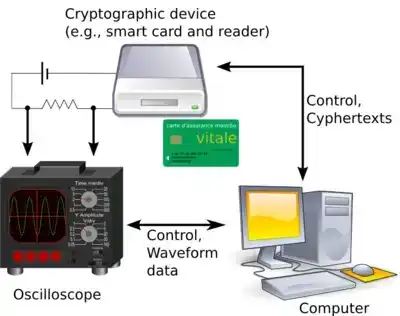
Differential power analysis is a common side-channel attack. Source: Wikipedia
There have been attempts to prove systems resistant to such attackers. However, any such proof requires some mathematical model of the attacker, within which you can then prove security. Sometimes, people use the "d-probing model": assuming a known upper bound on the number of locations in a circuit an attacker can probe. But the problem is that some forms of leakage are not captured by this model.
A common problem observed in this article is transitional leakage: if the signal you observe does not depend on the specific value at a location, but on the change of that value, then often you can recover the needed information from two values—the old and the new—rather than relying on just one. The article also categorizes other forms of leakage.
For decades, these critiques of formal verification have, in turn, helped formal verification get better. Compared to the past, we are now more skilled at being wary of such issues. But even today, it is still not perfect.
If we zoom out, there is a common thread here: formal verification is powerful. But despite marketing claims that it provides "provable correctness," "provable correctness" fundamentally does not prove that software, or hardware, is "correct" in the true sense.
For most people, "correct" roughly means: this thing behaves in accordance with the user's understanding of the developer's intent.
And "secure" roughly means: this thing's behavior does not deviate from user expectations in a way that harms the user's interests.
In both cases, correctness and security ultimately boil down to a comparison: on one side is a mathematical object, and on the other is human intent or expectation. Strictly speaking, human intent and expectation are also mathematical objects—after all, the human brain is part of the universe, which follows physical laws; with enough computing power, you could theoretically simulate them. But they are incredibly complex mathematical objects that neither computers nor we ourselves can truly understand or even read. For practical purposes, we can treat them as black boxes. The only reason we have any understanding of our own intentions and expectations is that each of us has years of experience observing our own thoughts and inferring the thoughts of others.
And precisely because we cannot stuff raw human intent directly into a computer, formal verification cannot prove a comparison between a system and human intent. Therefore, "provable correctness" and "provable security" do not actually prove "correctness" and "security" as humans understand them—there is no way to truly achieve this until we can simulate human brains.
So What Is Formal Verification Actually Useful For?
I tend to view test suites, type systems, and formal verification as different implementations of the same underlying approach to programming language safety—and this might be the only sensible way to view them. What they have in common is: redundantly stating our intent in different ways and then automatically checking whether these different statements are compatible with each other.
For example, look at this Python code:

Here, you've expressed your intent in three different ways:
First, direct expression: implementing the Fibonacci formula through code.
Second, indirect expression: using the type system to state that inputs, outputs, and intermediate steps in recursion are integers.
Third, using a "bundle of examples" approach: that is, test cases.
When running this file, the system uses these examples to check if the formula holds. The type checker can verify if the types are compatible: adding two integers is a valid operation and yields another integer. Type systems are often very useful in physics calculations too: if you are calculating acceleration but get a result in m/s instead of m/s², you know you messed up somewhere. And "bundle of examples" definitions, of which test cases are one kind, often align more with how humans process concepts than direct, explicit definitions do.
The more different ways you can express your intent, the better; ideally, these ways should be sufficiently different from each other, forcing you to think about the same problem in different ways. If all these expressions end up being compatible with each other, the probability that you have actually expressed what you intended to express is higher.
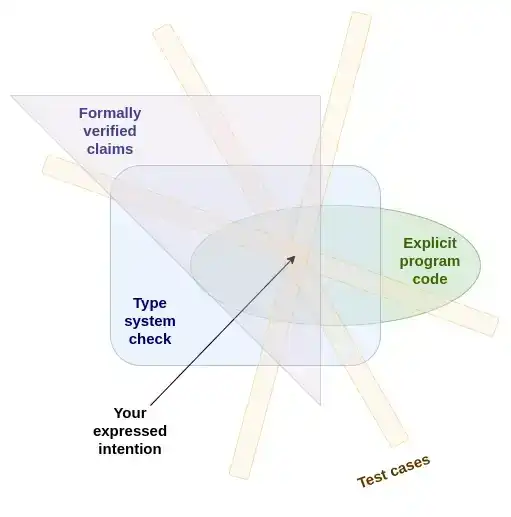
The core of secure programming is expressing your intent in many different ways and then automatically verifying that these expressions are compatible with each other.
Formal verification can push this approach even further. With formal verification, you can describe your intent in almost arbitrarily many redundant ways; the program only passes verification if these descriptions are compatible with each other.
You can simultaneously write an optimized implementation and a very inefficient but human-readable implementation and verify they are consistent. You can ask ten friends to each list mathematical properties they think the program should satisfy and check if the program satisfies them all; if it fails, you figure out whether the program is wrong or if that mathematical property itself is problematic. And AI can make all of the above extremely efficient.
So How Do I Get Started?
Realistically speaking, you probably won't be writing proofs yourself. The fundamental reason formal methods have never really taken off is that most people have a hard time understanding how to write these darn proofs.
Can you tell me what this code means?
(In case you're wondering, it's one of many sub-lemmas in a proof for a specific security claim about a variant of the SPHINCS signature scheme: namely, that unless a hash collision occurs, signing a given message requires using a value at least as high on one of the hash chains compared to signing any other message. Therefore, the information it needs cannot be computed from another signature.)
Instead of handwriting code and proofs, you can have AI write programs for you—either directly in Lean, or in assembly if you want speed—and prove the various properties you want along the way.
One advantage of this task is that it is essentially self-verifying, so you don't need to watch it continuously. You can absolutely let the AI run for hours on its own. The worst that can happen is that it spins its wheels, making no progress; or, as my Leanstral once did, to make its job easier, it directly replaced the statement it was asked to prove.
What you ultimately need to check is whether the proposition it proves is indeed the thing you wanted to prove.
For this SPHINCS signature variant, the final statement is as follows:

This actually borders on being somewhat "readable":
If the number generated from one hash digest (dig1) is not equal to the number generated from another hash digest (dig2), then the following statements cannot both be true:
For all numbers, each digit of dig1 is less than or equal to the corresponding digit of dig2;
For all numbers, each digit of dig2 is less than or equal to the corresponding digit of dig1.
The comparison here is between the "extended digits" (`wotsFullDigits`) generated after adding a checksum. That is, inevitably, in some positions, the extended digits of dig1 will be higher; and in other positions, the extended digits of dig2 will be higher.
Regarding writing proofs with large language models, I've found Claude to be quite good already, and DeepSeek 4 Pro is also competent enough. Leanstral is a promising alternative: it's a smaller, open-weight model specifically fine-tuned for writing in Lean. It has 119 billion parameters, but only activates 6 billion parameters per token, so it can run locally, albeit slowly—about 15 tokens per second on my laptop.
According to benchmarks, Leanstral outperforms many much larger general-purpose models:
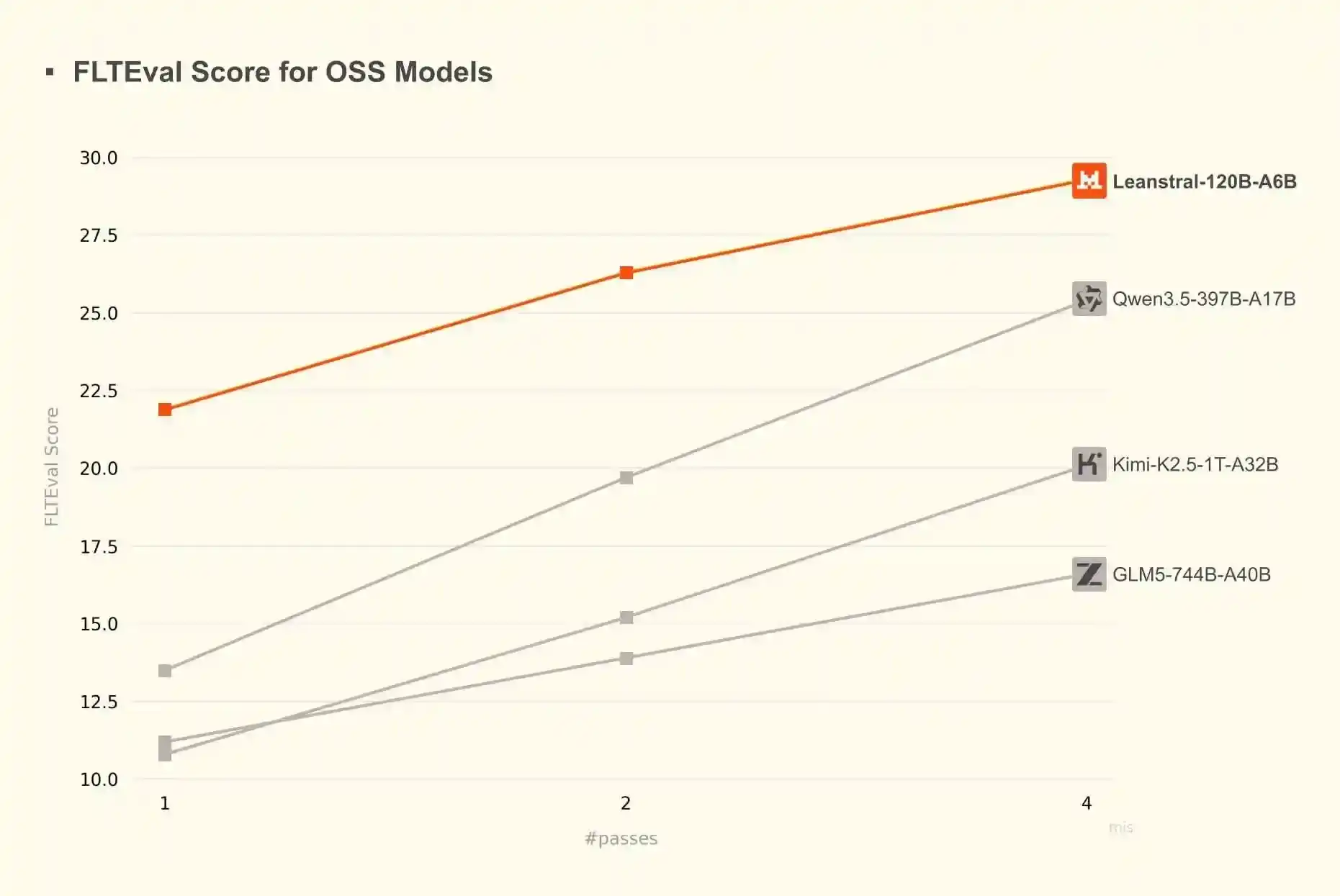
Based on my personal experience so far, it's slightly weaker than DeepSeek 4 Pro but still effective.
Formal verification won't solve all our problems. But if we want to establish a model of internet security where we don't have to trust a handful of powerful organizations, we need to be able to trust code instead—including when facing powerful AI adversaries. AI-assisted formal verification can take us a significant step in that direction.
Like blockchain and ZK-SNARKs, AI and formal verification are highly complementary technologies.
Blockchain brings open verifiability and censorship resistance at the cost of privacy and scalability; ZK-SNARKs bring back privacy and scalability—in fact, even stronger than before.
AI lets you write code at scale, at the cost of reduced accuracy; formal verification brings back accuracy—in fact, even stronger than before.
By default, AI will lead to a proliferation of very rough code, and bug counts will increase. Indeed, in some contexts, allowing more bugs is the correct trade-off: defective software is still better than no such software if the impact of the bugs is light. But here, there is still an optimistic future for cybersecurity: software will continue to bifurcate into "insecure edge components" surrounding a "secure core."
These insecure edge components will run in sandboxes and be granted only the minimum permissions needed to accomplish their tasks. The secure core will manage everything. If the secure core crashes, everything crashes—your personal data, your money, and more are at risk. But if an insecure edge component fails, the secure core can still protect you.
When it comes to the secure core, we won't let buggy code proliferate unchecked. We will actively control the size of the secure core, keeping it small enough, or even shrinking it further. Instead, we will channel all the additional capabilities brought by AI into enhancing the security of the secure core itself, enabling it to bear the immense burden of trust required in a highly digitized society.
Your operating system kernel, or at least part of it, will be one such secure core. Ethereum will be another. Ideally, at least for all non-high-performance-intensive computing, the hardware you use will become a third secure core. Some systems related to the Internet of Things will be a fourth.
At least within these secure cores, the old adage—"bugs are inevitable, you can only try to find them before the attackers do"—will no longer hold true. It will be replaced by a more hopeful world where we can achieve genuine security.
Of course, if you prefer to hand over your assets and data to software written poorly enough that it might accidentally send them all into a black hole, you will still have that freedom.
Original Link






