Authors: Li Hailun, Su Yang
On January 6th, Beijing time, NVIDIA CEO Jensen Huang, clad in his signature leather jacket, once again took the main stage at CES 2026.
At CES 2025, NVIDIA showcased the mass-produced Blackwell chip and a full-stack physical AI technology suite. During the event, Huang emphasized that an "era of Physical AI" was dawning. He painted a future full of imagination: autonomous vehicles with reasoning capabilities, robots that can understand and think, and AI Agents capable of handling long-context tasks involving millions of tokens.
A year has passed in a flash, and the AI industry has undergone significant evolution and change. Reviewing these changes at the launch event, Huang specifically highlighted open-source models.
He stated that open-source reasoning models like DeepSeek R1 have made the entire industry realize: when true openness and global collaboration kick in, the diffusion speed of AI becomes extremely rapid. Although open-source models still lag behind the most advanced models by about six months in overall capability, they close the gap every six months, and their downloads and usage have already seen explosive growth.

Compared to 2025's focus more on vision and possibilities, this time NVIDIA began systematically addressing the question of "how to achieve it":围绕推理型 AI (focusing on reasoning AI), it is bolstering the compute, networking, and storage infrastructure required for long-term operation, significantly reducing inference costs, and embedding these capabilities directly into real-world scenarios like autonomous driving and robotics.
Huang's CES keynote this year unfolded along three main lines:
● At the system and infrastructure level, NVIDIA redesigned the compute, networking, and storage architecture around long-term inference needs. With the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the Inference Context Memory Storage platform at the core, these updates directly target bottlenecks like high inference costs, difficulty in sustaining context, and scalability limitations, solving the problems of letting AI 'think a bit longer', 'afford to compute', and 'run persistently'.
● At the model level, NVIDIA placed Reasoning / Agentic AI at the core. Through models and tools like Alpamayo, Nemotron, and Cosmos Reason, it is pushing AI from "generating content" towards "continuous thinking", and from "one-time response models" to "agents that can work long-term".
● At the application and deployment level, these capabilities are being directly integrated into Physical AI scenarios like autonomous driving and robotics. Whether it's the Alpamayo-powered autonomous driving system or the GR00T and Jetson robotics ecosystem, they are driving scaled deployment through partnerships with cloud providers and enterprise platforms.

01 From Roadmap to Mass Production: Rubin's Full Performance Data Revealed for the First Time
At this CES, NVIDIA fully disclosed the technical details of the Rubin architecture for the first time.
In his speech, Huang started with the concept of Test-time Scaling. This concept can be understood as: making AI smarter isn't just about making it "study harder" during training anymore, but rather letting it "think a bit longer when encountering a problem".
In the past, improvements in AI capability relied mainly on throwing more compute power at the training stage, making models larger and larger; now, the new change is that even if the model stops growing, simply giving it a bit more time and compute power to think during each use can significantly improve the results.
How to make "AI thinking a bit longer" economically feasible? The Rubin architecture's next-generation AI computing platform is here to solve this problem.
Huang introduced it as a complete next-generation AI computing system, achieving a revolutionary drop in inference costs through the co-design of the Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, and Spectrum-6.

The NVIDIA Rubin GPU is the core chip responsible for AI compute in the Rubin architecture, aiming to significantly reduce the unit cost of inference and training.
Simply put, the Rubin GPU's core mission is to "make AI cheaper and smarter to use".
The core capability of the Rubin GPU lies in: the same GPU can handle more work. It can process more inference tasks at once, remember longer context, and communicate faster with other GPUs. This means many scenarios that previously required "stacking multiple cards" can now be accomplished with fewer GPUs.
The result is that inference is not only faster, but also significantly cheaper.
Huang recapped the hardware specs of the Rubin architecture's NVL72 for the audience: it contains 220 trillion transistors, with a bandwidth of 260 TB/s, and is the industry's first platform supporting rack-scale confidential computing.

Overall, compared to Blackwell, the Rubin GPU achieves a generational leap in key metrics: NVFP4 inference performance increases to 50 PFLOPS (5x), training performance to 35 PFLOPS (3.5x), HBM4 memory bandwidth to 22 TB/s (2.8x), and single GPU NVLink interconnect bandwidth doubles to 3.6 TB/s.
These improvements work together to enable a single GPU to handle more inference tasks and longer context, fundamentally reducing the reliance on the number of GPUs.

The Vera CPU is a core component designed specifically for data movement and Agentic processing, featuring 88 NVIDIA-designed Olympus cores, equipped with 1.5 TB of system memory (3x that of the previous Grace CPU), and achieving coherent memory access between CPU and GPU through 1.8 TB/s NVLink-C2C technology.
Unlike traditional general-purpose CPUs, Vera focuses on data scheduling and multi-step reasoning logic processing in AI inference scenarios, essentially acting as the system coordinator that enables "AI thinking a bit longer" to run efficiently.
NVLink 6, with its 3.6 TB/s bandwidth and in-network computing capability, allows the 72 GPUs in the Rubin architecture to work together like a single super GPU, which is key infrastructure for reducing inference costs.
This way, the data and intermediate results needed by AI during inference can quickly circulate between GPUs, without repeatedly waiting, copying, or recalculating.


In the Rubin architecture, NVLink-6 handles internal collaborative computing between GPUs, BlueField-4 handles context and data scheduling, and ConnectX-9 undertakes the system's high-speed external network connectivity. It ensures the Rubin system can communicate efficiently with other racks, data centers, and cloud platforms, a prerequisite for the smooth operation of large-scale training and inference tasks.
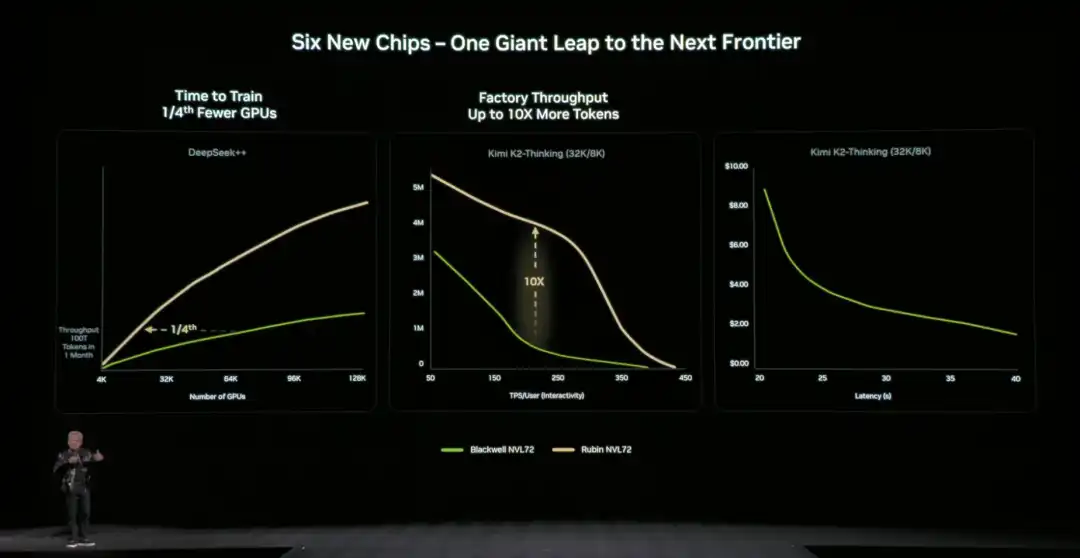
Compared to the previous generation architecture, NVIDIA also provided specific,直观的数据 (intuitive data): compared to the NVIDIA Blackwell platform, it can reduce token costs in the inference phase by up to 10 times, and reduce the number of GPUs required for training Mixture of Experts (MoE) models to 1/4 of the original.
NVIDIA officially stated that Microsoft has already committed to deploying hundreds of thousands of Vera Rubin chips in its next-generation Fairwater AI super factory, and cloud service providers like CoreWeave will offer Rubin instances in the second half of 2026. This infrastructure for "letting AI think a bit longer" is moving from technical demonstration to scaled commercial use.

02 How is the "Storage Bottleneck" Solved?
Letting AI "think a bit longer" also faces a key technical challenge: where should the context data be stored?
When AI handles complex tasks requiring multi-turn dialogue or multi-step reasoning, it generates a large amount of context data (KV Cache). Traditional architectures either cram it into expensive and capacity-limited GPU memory or put it in ordinary storage (which is too slow to access). If this "storage bottleneck" isn't solved, even the most powerful GPU will be hampered.
To address this issue, NVIDIA fully disclosed the BlueField-4 powered Inference Context Memory Storage Platform for the first time at this CES. The core goal is to create a "third layer" between GPU memory and traditional storage. It's fast enough, has ample capacity, and can support AI's long-term operation.
From a technical implementation perspective, this platform isn't the result of a single component working alone, but rather a set of co-designed elements:
- BlueField-4 is responsible for accelerating the management and access of context data at the hardware level, reducing data movement and system overhead;
- Spectrum-X Ethernet provides high-performance networking, supporting high-speed data sharing based on RDMA;
- Software components like DOCA, NIXL, and Dynamo are responsible for optimizing scheduling, reducing latency, and improving overall throughput at the system level.
We can understand this platform's approach as extending the context data, which originally could only reside in GPU memory, to an independent, high-speed, shareable "memory layer". This一方面 (on one hand) relieves pressure on the GPU, and另一方面 (on the other hand) allows for rapid sharing of this context information between multiple nodes and multiple AI agents.
In terms of actual效果 (effects), the data provided by NVIDIA官方 (officially) is: in specific scenarios, this method can increase the number of tokens processed per second by up to 5 times, and achieve同等水平的 (equivalent levels of) energy efficiency optimization.
Huang emphasized多次 (repeatedly) during the presentation that AI is evolving from "one-time dialogue chatbots" to true intelligent collaborators: they need to understand the real world, reason continuously, call tools to complete tasks, and retain both short-term and long-term memory. This is the core characteristic of Agentic AI. The Inference Context Memory Storage Platform is designed precisely for this long-running,反复思考的 (repeatedly thinking) form of AI. By expanding context capacity and speeding up cross-node sharing, it makes multi-turn conversations and multi-agent collaboration more stable, no longer "slowing down the longer it runs".

03 The New Generation DGX SuperPOD: Enabling 576 GPUs to Work Together
NVIDIA announced the new generation DGX SuperPOD (Super Pod) based on the Rubin architecture at this CES, expanding Rubin from a single rack to a complete data center solution.
What is a DGX SuperPOD?
If the Rubin NVL72 is a "super rack" containing 72 GPUs, then the DGX SuperPOD connects multiple such racks together to form a larger-scale AI computing cluster. This released version consists of 8 Vera Rubin NVL72 racks, equivalent to 576 GPUs working together.
When AI task scales continue to expand, the 576 GPUs of a single SuperPOD might not be enough. For example, training ultra-large-scale models, simultaneously serving thousands of Agentic AI agents, or processing complex tasks requiring millions of tokens of context. This requires multiple SuperPODs working together, and the DGX SuperPOD is the standardized solution for this scenario.
For enterprises and cloud service providers, the DGX SuperPOD provides an "out-of-the-box" large-scale AI infrastructure solution. There's no need to figure out how to connect hundreds of GPUs, configure networks, manage storage, etc., themselves.
The five core components of the new generation DGX SuperPOD:
○ 8 Vera Rubin NVL72 Racks - The core providing computing power, 72 GPUs per rack, 576 GPUs total;
○ NVLink 6 Expansion Network - Allows the 576 GPUs across these 8 racks to work together like one超大 (super large) GPU;
○ Spectrum-X Ethernet Expansion Network - Connects different SuperPODs, and to storage and external networks;
○ Inference Context Memory Storage Platform - Provides shared context data storage for long-running inference tasks;
○ NVIDIA Mission Control Software - Manages scheduling, monitoring, and optimization of the entire system.
With this upgrade, the foundation of the SuperPOD is the DGX Vera Rubin NVL72 rack-scale system at its core. Each NVL72 is itself a complete AI supercomputer, internally connecting 72 Rubin GPUs via NVLink 6, capable of handling large-scale inference and training tasks within a single rack. The new DGX SuperPOD consists of multiple NVL72 units, forming a system-level cluster capable of long-term operation.
When the compute scale expands from "single rack" to "multi-rack", new bottlenecks emerge: how to stably and efficiently传输海量数据 (transfer massive amounts of data) between racks.围绕这一问题 (Around this issue), NVIDIA simultaneously announced the new generation Ethernet switch based on the Spectrum-6 chip at this CES, and introduced "Co-Packaged Optics" (CPO) technology for the first time.
Simply put, this involves packaging the originally pluggable optical modules directly next to the switch chip, reducing the signal transmission distance from meters to millimeters, thereby significantly reducing power consumption and latency, and also improving the overall stability of the system.
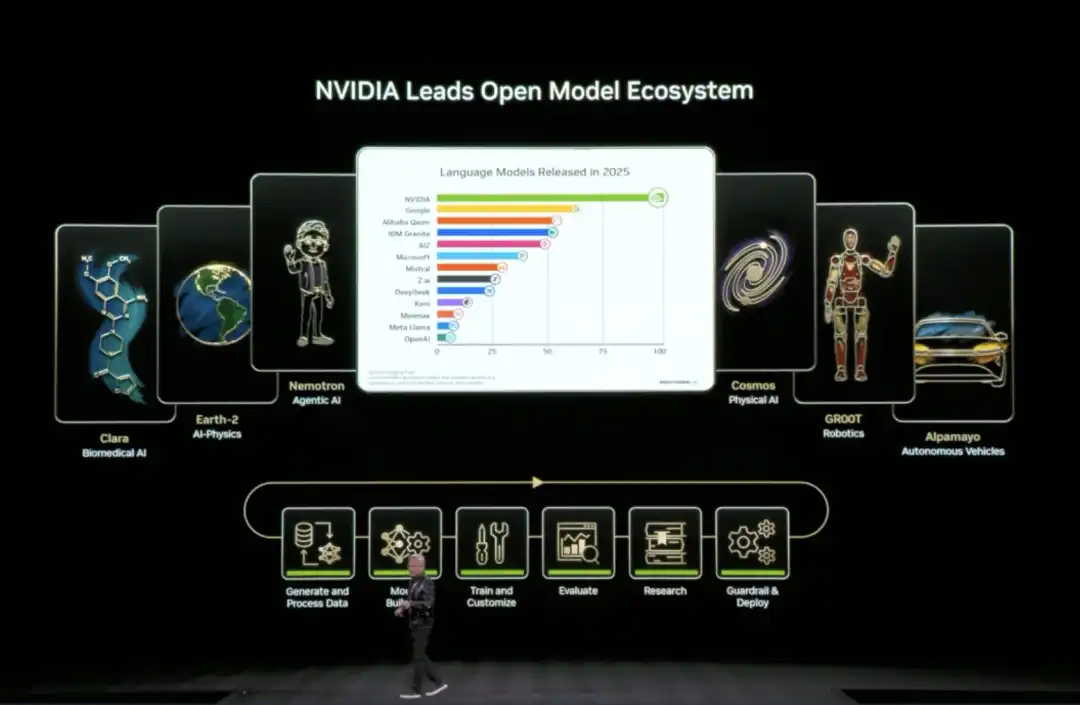
04 NVIDIA's Open Source AI "Full Stack": Everything from Data to Code
At this CES, Huang announced the expansion of its open-source model ecosystem (Open Model Universe), adding and updating a series of models, datasets, code libraries, and tools. This ecosystem covers six areas: Biomedical AI (Clara), AI Physics Simulation (Earth-2), Agentic AI (Nemotron), Physical AI (Cosmos), Robotics (GR00T), and Autonomous Driving (Alpamayo).
Training an AI model requires not just compute power, but also high-quality datasets, pre-trained models, training code, evaluation tools, and a whole set of infrastructure. For most companies and research institutions, building these from scratch is too time-consuming.
Specifically, NVIDIA has open-sourced six layers of content: compute platforms (DGX, HGX, etc.), training datasets for various domains, pre-trained foundation models, inference and training code libraries, complete training process scripts, and end-to-end solution templates.
The Nemotron series was a key focus of this update, covering four application directions.
In the reasoning direction, it includes small-scale reasoning models like Nemotron 3 Nano, Nemotron 2 Nano VL, as well as reinforcement learning training tools like NeMo RL and NeMo Gym. In the RAG (Retrieval-Augmented Generation) direction, it provides Nemotron Embed VL (vector embedding model), Nemotron Rerank VL (re-ranking model), relevant datasets, and the NeMo Retriever Library. In the safety direction, there is the Nemotron Content Safety model and its配套数据集 (matching dataset), and the NeMo Guardrails library.
In the speech direction, it includes Nemotron ASR for automatic speech recognition, the Granary Dataset for speech, and the NeMo Library for speech processing. This means if a company wants to build an AI customer service system with RAG, it doesn't need to train its own embedding and re-ranking models; it can directly use the code NVIDIA has already trained and open-sourced.
05 Physical AI Domain Moves Towards Commercial Deployment
The Physical AI domain also saw model updates—Cosmos for understanding and generating videos of the physical world, the general-purpose robotics foundation model Isaac GR00T, and the vision-language-action model for autonomous driving, Alpamayo.

Huang claimed at CES that the "ChatGPT moment" for Physical AI is approaching, but there are many challenges: the physical world is too complex and variable, collecting real data is slow and expensive, and there's never enough.
What's the solution? Synthetic data is one path. Hence, NVIDIA introduced Cosmos.
This is an open-source foundational model for the physical AI world, already pre-trained on massive amounts of video, real driving and robotics data, and 3D simulation. It can understand how the world works and connect language, images, 3D, and actions.
Huang stated that Cosmos can achieve several physical AI skills, such as generating content, performing reasoning, and predicting trajectories (even if only given a single image). It can generate realistic videos based on 3D scenes, generate physically plausible motion based on driving data, and even generate panoramic videos from simulators, multi-camera footage, or text descriptions. It can even还原 (recreate) rare scenarios.
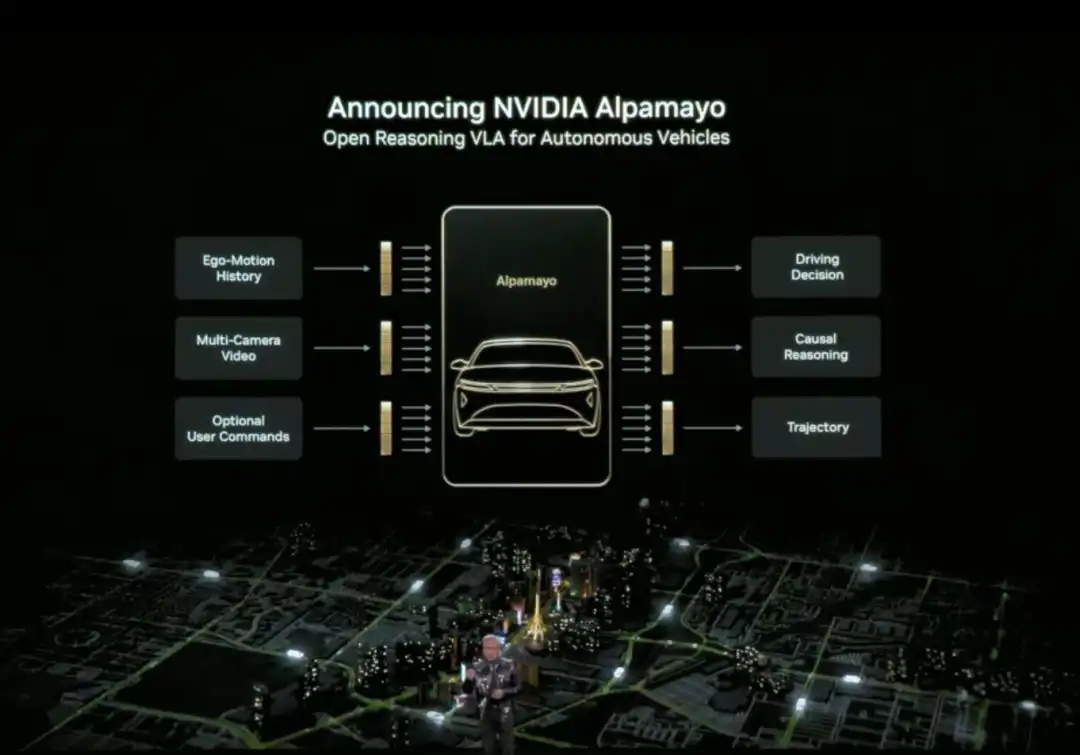
Huang also officially released Alpamayo. Alpamayo is an open-source toolchain for the autonomous driving domain, and the first open-source vision-language-action (VLA) reasoning model. Unlike previous open-sourcing of only code, NVIDIA this time open-sourced the complete development resources from data to deployment.
Alpamayo's biggest breakthrough is that it is a "reasoning" autonomous driving model. Traditional autonomous driving systems follow a "perception-planning-control" pipeline architecture—see a red light and brake, see a pedestrian and slow down, following preset rules. Alpamayo introduces "reasoning" capability, understanding causal relationships in complex scenes, predicting the intentions of other vehicles and pedestrians, and even handling decisions requiring multi-step thinking.
For example, at an intersection, it doesn't just recognize "there's a car ahead", but can reason "that car might be turning left, so I should wait for it to go first". This capability upgrades autonomous driving from "driving by rules" to "thinking like a human".
Huang announced that the NVIDIA DRIVE system has officially entered the mass production phase, with the first application being the new Mercedes-Benz CLA, planned to hit US roads in 2026. This vehicle will be equipped with an L2++ level autonomous driving system, adopting a hybrid architecture of "end-to-end AI model + traditional pipeline".
The robotics field also saw substantial progress.
Huang stated that leading global robotics companies, including Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics, and XRlabs, are developing products based on the NVIDIA Isaac platform and the GR00T foundation model, covering various fields from industrial robots and surgical robots to humanoid robots and consumer robots.

During the launch event, Huang stood in front of a stage filled with robots of different forms and用途 (purposes), displayed on a tiered platform: from humanoid robots, bipedal and wheeled service robots, to industrial robotic arms, engineering machinery, drones, and surgical assist devices, presenting a "robotics ecosystem landscape".
From Physical AI applications to the Rubin AI computing platform, to the Inference Context Memory Storage platform and the open-source AI "full stack".
These actions showcased by NVIDIA at CES constitute NVIDIA's narrative for推理时代 AI 基础设施 (AI infrastructure for the reasoning era). As Huang repeatedly emphasized, when Physical AI needs to think continuously, run persistently, and truly enter the real world, the problem is no longer just about whether there's enough compute power, but about who can actually build the entire system.
At CES 2026, NVIDIA has provided an answer.
Trending Cryptos
Related Questions
QWhat are the three main topics of Jensen Huang's CES 2026 keynote?![]()
AThe three main topics are: 1) Reconstructing computing, networking, and storage architecture around long-term inference needs with the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the inference context memory storage platform. 2) Placing reasoning/agentic AI at the core through models and tools like Alpamayo, Nemotron, and Cosmos Reason. 3) Directly applying these capabilities to physical AI scenarios like autonomous driving and robotics.
QWhat is the key innovation of the Rubin GPU architecture and its primary goal?![]()
AThe key innovation of the Rubin GPU architecture is its ability to handle more inference tasks and longer context within a single GPU, facilitated by a significant performance leap over Blackwell. Its primary goal is to 'make AI cheaper and smarter to use' by dramatically reducing the cost of inference and the number of GPUs required for many tasks.
QWhat problem does the Inference Context Memory Storage Platform solve, and what are its core components?![]()
AIt solves the 'storage bottleneck' problem, where context data (KV Cache) from multi-step AI reasoning tasks traditionally had to be stored in expensive, limited GPU memory or slow conventional storage. Its core components are the BlueField-4 DPU (for hardware-accelerated data management), Spectrum-X Ethernet (for high-performance networking), and software components like DOCA, NIXL, and Dynamo for system optimization.
QWhat major advancement did NVIDIA announce for the autonomous driving sector?![]()
ANVIDIA announced the official entry of its DRIVE system into mass production, with the first application being the new Mercedes-Benz CLA, planned for US roads in 2026. They also open-sourced Alpamayo, the first visual-language-action (VLA) reasoning model for autonomous driving, which introduces causal reasoning and multi-step decision-making capabilities.
QWhat is the significance of the new DGX SuperPOD based on the Rubin architecture?![]()
AThe new DGX SuperPOD scales the Rubin architecture from a single rack (NVL72 with 72 GPUs) to a data-center-scale solution. Composed of 8 NVL72 racks for a total of 576 GPUs, it provides an 'out-of-the-box' massive AI computing cluster for training ultra-large models or serving thousands of Agentic AI agents, managed by the NVIDIA Mission Control software.
Related Reads





Trading
Hot Articles
What is SONIC
Sonic: Pioneering the Future of Gaming in Web3 Introduction to Sonic In the ever-evolving landscape of Web3, the gaming industry stands out as one of the most dynamic and promising sectors. At the forefront of this revolution is Sonic, a project designed to amplify the gaming ecosystem on the Solana blockchain. Leveraging cutting-edge technology, Sonic aims to deliver an unparalleled gaming experience by efficiently processing millions of requests per second, ensuring that players enjoy seamless gameplay while maintaining low transaction costs. This article delves into the intricate details of Sonic, exploring its creators, funding sources, operational mechanics, and the timeline of significant events that have shaped its journey. What is Sonic? Sonic is an innovative layer-2 network that operates atop the Solana blockchain, specifically tailored to enhance the existing Solana gaming ecosystem. It accomplishes this through a customised, VM-agnostic game engine paired with a HyperGrid interpreter, facilitating sovereign game economies that roll up back to the Solana platform. The primary goals of Sonic include: Enhanced Gaming Experiences: Sonic is committed to offering lightning-fast on-chain gameplay, allowing players and developers to engage with games at previously unattainable speeds. Atomic Interoperability: This feature enables transactions to be executed within Sonic without the need to redeploy Solana programmes and accounts. This makes the process more efficient and directly benefits from Solana Layer1 services and liquidity. Seamless Deployment: Sonic allows developers to write for Ethereum Virtual Machine (EVM) based systems and execute them on Solana’s SVM infrastructure. This interoperability is crucial for attracting a broader range of dApps and decentralised applications to the platform. Support for Developers: By offering native composable gaming primitives and extensible data types - dining within the Entity-Component-System (ECS) framework - game creators can craft intricate business logic with ease. Overall, Sonic's unique approach not only caters to players but also provides an accessible and low-cost environment for developers to innovate and thrive. Creator of Sonic The information regarding the creator of Sonic is somewhat ambiguous. However, it is known that Sonic's SVM is owned by the company Mirror World. The absence of detailed information about the individuals behind Sonic reflects a common trend in several Web3 projects, where collective efforts and partnerships often overshadow individual contributions. Investors of Sonic Sonic has garnered considerable attention and support from various investors within the crypto and gaming sectors. Notably, the project raised an impressive $12 million during its Series A funding round. The round was led by BITKRAFT Ventures, with other notable investors including Galaxy, Okx Ventures, Interactive, Big Brain Holdings, and Mirana. This financial backing signifies the confidence that investment foundations have in Sonic’s potential to revolutionise the Web3 gaming landscape, further validating its innovative approaches and technologies. How Does Sonic Work? Sonic utilises the HyperGrid framework, a sophisticated parallel processing mechanism that enhances its scalability and customisability. Here are the core features that set Sonic apart: Lightning Speed at Low Costs: Sonic offers one of the fastest on-chain gaming experiences compared to other Layer-1 solutions, powered by the scalability of Solana’s virtual machine (SVM). Atomic Interoperability: Sonic enables transaction execution without redeployment of Solana programmes and accounts, effectively streamlining the interaction between users and the blockchain. EVM Compatibility: Developers can effortlessly migrate decentralised applications from EVM chains to the Solana environment using Sonic’s HyperGrid interpreter, increasing the accessibility and integration of various dApps. Ecosystem Support for Developers: By exposing native composable gaming primitives, Sonic facilitates a sandbox-like environment where developers can experiment and implement business logic, greatly enhancing the overall development experience. Monetisation Infrastructure: Sonic natively supports growth and monetisation efforts, providing frameworks for traffic generation, payments, and settlements, thereby ensuring that gaming projects are not only viable but also sustainable financially. Timeline of Sonic The evolution of Sonic has been marked by several key milestones. Below is a brief timeline highlighting critical events in the project's history: 2022: The Sonic cryptocurrency was officially launched, marking the beginning of its journey in the Web3 gaming arena. 2024: June: Sonic SVM successfully raised $12 million in a Series A funding round. This investment allowed Sonic to further develop its platform and expand its offerings. August: The launch of the Sonic Odyssey testnet provided users with the first opportunity to engage with the platform, offering interactive activities such as collecting rings—a nod to gaming nostalgia. October: SonicX, an innovative crypto game integrated with Solana, made its debut on TikTok, capturing the attention of over 120,000 users within a short span. This integration illustrated Sonic’s commitment to reaching a broader, global audience and showcased the potential of blockchain gaming. Key Points Sonic SVM is a revolutionary layer-2 network on Solana explicitly designed to enhance the GameFi landscape, demonstrating great potential for future development. HyperGrid Framework empowers Sonic by introducing horizontal scaling capabilities, ensuring that the network can handle the demands of Web3 gaming. Integration with Social Platforms: The successful launch of SonicX on TikTok displays Sonic’s strategy to leverage social media platforms to engage users, exponentially increasing the exposure and reach of its projects. Investment Confidence: The substantial funding from BITKRAFT Ventures, among others, emphasizes the robust backing Sonic has, paving the way for its ambitious future. In conclusion, Sonic encapsulates the essence of Web3 gaming innovation, striking a balance between cutting-edge technology, developer-centric tools, and community engagement. As the project continues to evolve, it is poised to redefine the gaming landscape, making it a notable entity for gamers and developers alike. As Sonic moves forward, it will undoubtedly attract greater interest and participation, solidifying its place within the broader narrative of blockchain gaming.
2.2k Total ViewsPublished 2024.04.04Updated 2024.12.03

What is $S$
Understanding SPERO: A Comprehensive Overview Introduction to SPERO As the landscape of innovation continues to evolve, the emergence of web3 technologies and cryptocurrency projects plays a pivotal role in shaping the digital future. One project that has garnered attention in this dynamic field is SPERO, denoted as SPERO,$$s$. This article aims to gather and present detailed information about SPERO, to help enthusiasts and investors understand its foundations, objectives, and innovations within the web3 and crypto domains. What is SPERO,$$s$? SPERO,$$s$ is a unique project within the crypto space that seeks to leverage the principles of decentralisation and blockchain technology to create an ecosystem that promotes engagement, utility, and financial inclusion. The project is tailored to facilitate peer-to-peer interactions in new ways, providing users with innovative financial solutions and services. At its core, SPERO,$$s$ aims to empower individuals by providing tools and platforms that enhance user experience in the cryptocurrency space. This includes enabling more flexible transaction methods, fostering community-driven initiatives, and creating pathways for financial opportunities through decentralised applications (dApps). The underlying vision of SPERO,$$s$ revolves around inclusiveness, aiming to bridge gaps within traditional finance while harnessing the benefits of blockchain technology. Who is the Creator of SPERO,$$s$? The identity of the creator of SPERO,$$s$ remains somewhat obscure, as there are limited publicly available resources providing detailed background information on its founder(s). This lack of transparency can stem from the project's commitment to decentralisation—an ethos that many web3 projects share, prioritising collective contributions over individual recognition. By centring discussions around the community and its collective goals, SPERO,$$s$ embodies the essence of empowerment without singling out specific individuals. As such, understanding the ethos and mission of SPERO remains more important than identifying a singular creator. Who are the Investors of SPERO,$$s$? SPERO,$$s$ is supported by a diverse array of investors ranging from venture capitalists to angel investors dedicated to fostering innovation in the crypto sector. The focus of these investors generally aligns with SPERO's mission—prioritising projects that promise societal technological advancement, financial inclusivity, and decentralised governance. These investor foundations are typically interested in projects that not only offer innovative products but also contribute positively to the blockchain community and its ecosystems. The backing from these investors reinforces SPERO,$$s$ as a noteworthy contender in the rapidly evolving domain of crypto projects. How Does SPERO,$$s$ Work? SPERO,$$s$ employs a multi-faceted framework that distinguishes it from conventional cryptocurrency projects. Here are some of the key features that underline its uniqueness and innovation: Decentralised Governance: SPERO,$$s$ integrates decentralised governance models, empowering users to participate actively in decision-making processes regarding the project’s future. This approach fosters a sense of ownership and accountability among community members. Token Utility: SPERO,$$s$ utilises its own cryptocurrency token, designed to serve various functions within the ecosystem. These tokens enable transactions, rewards, and the facilitation of services offered on the platform, enhancing overall engagement and utility. Layered Architecture: The technical architecture of SPERO,$$s$ supports modularity and scalability, allowing for seamless integration of additional features and applications as the project evolves. This adaptability is paramount for sustaining relevance in the ever-changing crypto landscape. Community Engagement: The project emphasises community-driven initiatives, employing mechanisms that incentivise collaboration and feedback. By nurturing a strong community, SPERO,$$s$ can better address user needs and adapt to market trends. Focus on Inclusion: By offering low transaction fees and user-friendly interfaces, SPERO,$$s$ aims to attract a diverse user base, including individuals who may not previously have engaged in the crypto space. This commitment to inclusion aligns with its overarching mission of empowerment through accessibility. Timeline of SPERO,$$s$ Understanding a project's history provides crucial insights into its development trajectory and milestones. Below is a suggested timeline mapping significant events in the evolution of SPERO,$$s$: Conceptualisation and Ideation Phase: The initial ideas forming the basis of SPERO,$$s$ were conceived, aligning closely with the principles of decentralisation and community focus within the blockchain industry. Launch of Project Whitepaper: Following the conceptual phase, a comprehensive whitepaper detailing the vision, goals, and technological infrastructure of SPERO,$$s$ was released to garner community interest and feedback. Community Building and Early Engagements: Active outreach efforts were made to build a community of early adopters and potential investors, facilitating discussions around the project’s goals and garnering support. Token Generation Event: SPERO,$$s$ conducted a token generation event (TGE) to distribute its native tokens to early supporters and establish initial liquidity within the ecosystem. Launch of Initial dApp: The first decentralised application (dApp) associated with SPERO,$$s$ went live, allowing users to engage with the platform's core functionalities. Ongoing Development and Partnerships: Continuous updates and enhancements to the project's offerings, including strategic partnerships with other players in the blockchain space, have shaped SPERO,$$s$ into a competitive and evolving player in the crypto market. Conclusion SPERO,$$s$ stands as a testament to the potential of web3 and cryptocurrency to revolutionise financial systems and empower individuals. With a commitment to decentralised governance, community engagement, and innovatively designed functionalities, it paves the way toward a more inclusive financial landscape. As with any investment in the rapidly evolving crypto space, potential investors and users are encouraged to research thoroughly and engage thoughtfully with the ongoing developments within SPERO,$$s$. The project showcases the innovative spirit of the crypto industry, inviting further exploration into its myriad possibilities. While the journey of SPERO,$$s$ is still unfolding, its foundational principles may indeed influence the future of how we interact with technology, finance, and each other in interconnected digital ecosystems.
232 Total ViewsPublished 2024.12.17Updated 2024.12.17
What is AGENT S
Agent S: The Future of Autonomous Interaction in Web3 Introduction In the ever-evolving landscape of Web3 and cryptocurrency, innovations are constantly redefining how individuals interact with digital platforms. One such pioneering project, Agent S, promises to revolutionise human-computer interaction through its open agentic framework. By paving the way for autonomous interactions, Agent S aims to simplify complex tasks, offering transformative applications in artificial intelligence (AI). This detailed exploration will delve into the project's intricacies, its unique features, and the implications for the cryptocurrency domain. What is Agent S? Agent S stands as a groundbreaking open agentic framework, specifically designed to tackle three fundamental challenges in the automation of computer tasks: Acquiring Domain-Specific Knowledge: The framework intelligently learns from various external knowledge sources and internal experiences. This dual approach empowers it to build a rich repository of domain-specific knowledge, enhancing its performance in task execution. Planning Over Long Task Horizons: Agent S employs experience-augmented hierarchical planning, a strategic approach that facilitates efficient breakdown and execution of intricate tasks. This feature significantly enhances its ability to manage multiple subtasks efficiently and effectively. Handling Dynamic, Non-Uniform Interfaces: The project introduces the Agent-Computer Interface (ACI), an innovative solution that enhances the interaction between agents and users. Utilizing Multimodal Large Language Models (MLLMs), Agent S can navigate and manipulate diverse graphical user interfaces seamlessly. Through these pioneering features, Agent S provides a robust framework that addresses the complexities involved in automating human interaction with machines, setting the stage for myriad applications in AI and beyond. Who is the Creator of Agent S? While the concept of Agent S is fundamentally innovative, specific information about its creator remains elusive. The creator is currently unknown, which highlights either the nascent stage of the project or the strategic choice to keep founding members under wraps. Regardless of anonymity, the focus remains on the framework's capabilities and potential. Who are the Investors of Agent S? As Agent S is relatively new in the cryptographic ecosystem, detailed information regarding its investors and financial backers is not explicitly documented. The lack of publicly available insights into the investment foundations or organisations supporting the project raises questions about its funding structure and development roadmap. Understanding the backing is crucial for gauging the project's sustainability and potential market impact. How Does Agent S Work? At the core of Agent S lies cutting-edge technology that enables it to function effectively in diverse settings. Its operational model is built around several key features: Human-like Computer Interaction: The framework offers advanced AI planning, striving to make interactions with computers more intuitive. By mimicking human behaviour in tasks execution, it promises to elevate user experiences. Narrative Memory: Employed to leverage high-level experiences, Agent S utilises narrative memory to keep track of task histories, thereby enhancing its decision-making processes. Episodic Memory: This feature provides users with step-by-step guidance, allowing the framework to offer contextual support as tasks unfold. Support for OpenACI: With the ability to run locally, Agent S allows users to maintain control over their interactions and workflows, aligning with the decentralised ethos of Web3. Easy Integration with External APIs: Its versatility and compatibility with various AI platforms ensure that Agent S can fit seamlessly into existing technological ecosystems, making it an appealing choice for developers and organisations. These functionalities collectively contribute to Agent S's unique position within the crypto space, as it automates complex, multi-step tasks with minimal human intervention. As the project evolves, its potential applications in Web3 could redefine how digital interactions unfold. Timeline of Agent S The development and milestones of Agent S can be encapsulated in a timeline that highlights its significant events: September 27, 2024: The concept of Agent S was launched in a comprehensive research paper titled “An Open Agentic Framework that Uses Computers Like a Human,” showcasing the groundwork for the project. October 10, 2024: The research paper was made publicly available on arXiv, offering an in-depth exploration of the framework and its performance evaluation based on the OSWorld benchmark. October 12, 2024: A video presentation was released, providing a visual insight into the capabilities and features of Agent S, further engaging potential users and investors. These markers in the timeline not only illustrate the progress of Agent S but also indicate its commitment to transparency and community engagement. Key Points About Agent S As the Agent S framework continues to evolve, several key attributes stand out, underscoring its innovative nature and potential: Innovative Framework: Designed to provide an intuitive use of computers akin to human interaction, Agent S brings a novel approach to task automation. Autonomous Interaction: The ability to interact autonomously with computers through GUI signifies a leap towards more intelligent and efficient computing solutions. Complex Task Automation: With its robust methodology, it can automate complex, multi-step tasks, making processes faster and less error-prone. Continuous Improvement: The learning mechanisms enable Agent S to improve from past experiences, continually enhancing its performance and efficacy. Versatility: Its adaptability across different operating environments like OSWorld and WindowsAgentArena ensures that it can serve a broad range of applications. As Agent S positions itself in the Web3 and crypto landscape, its potential to enhance interaction capabilities and automate processes signifies a significant advancement in AI technologies. Through its innovative framework, Agent S exemplifies the future of digital interactions, promising a more seamless and efficient experience for users across various industries. Conclusion Agent S represents a bold leap forward in the marriage of AI and Web3, with the capacity to redefine how we interact with technology. While still in its early stages, the possibilities for its application are vast and compelling. Through its comprehensive framework addressing critical challenges, Agent S aims to bring autonomous interactions to the forefront of the digital experience. As we move deeper into the realms of cryptocurrency and decentralisation, projects like Agent S will undoubtedly play a crucial role in shaping the future of technology and human-computer collaboration.
901 Total ViewsPublished 2025.01.14Updated 2025.01.14
