小编注:以下讨论多为个人观点,不构成投资建议。信息整理自X。
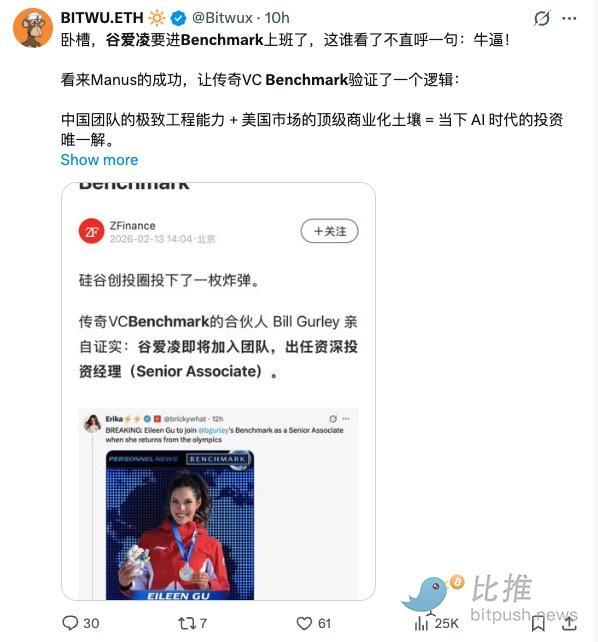
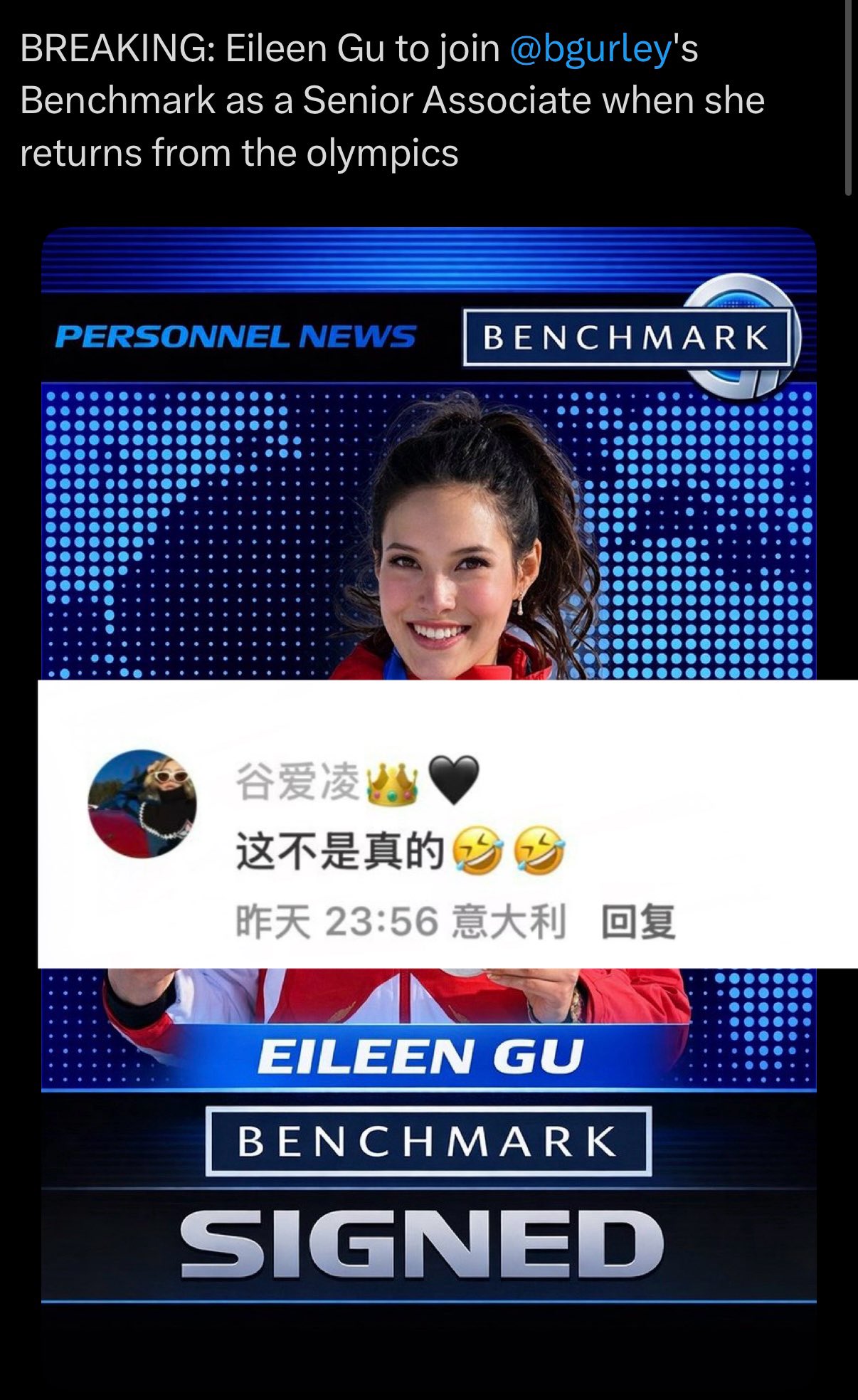
谷爱凌加入Benchmark?假的!
热门回复:
下一步HTX联席CEO,TRON全球大使 lol
她这几天被骂惨了,华语圈被骂,英文圈被怼,一会代表美国人,一会儿代表中国人!
冷知识:谷爱凌是美国身份,美国政府全球征税。所以谷爱凌在中国赚的每一分钱,40%都会给美国政府!
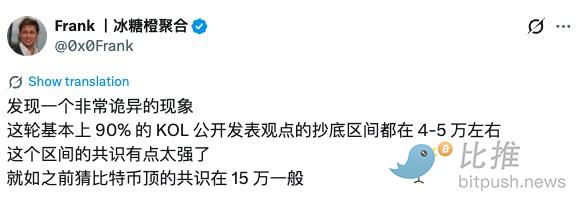
90%的KOL抄底区间在4-5万美金?
热门回复:
你观察的很对,其实真跌到四五万倒也合理,历史在哪摆着,大家都理解,就怕跌到两三万,甚至更低,那直接信仰崩塌了。
哈哈哈,前两个月他们喊的都是6万、真跌到4-5万他们就会喊3-4万的。
“八年了,还是1900”,E卫兵集体破防

香港跑会小作文大赏




行业悲观情绪弥漫,有人出逃,有人坚持
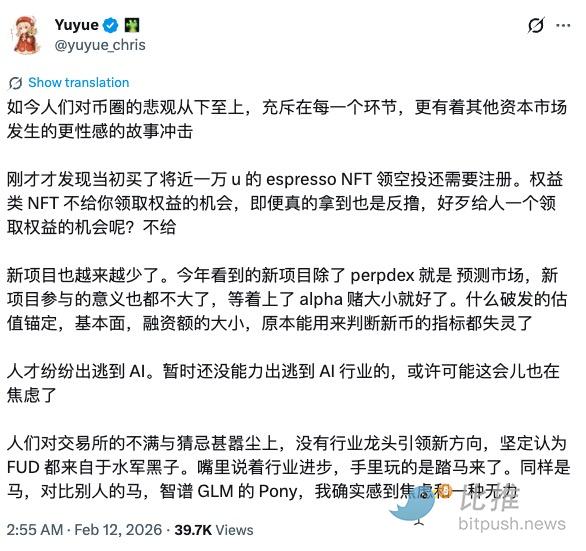
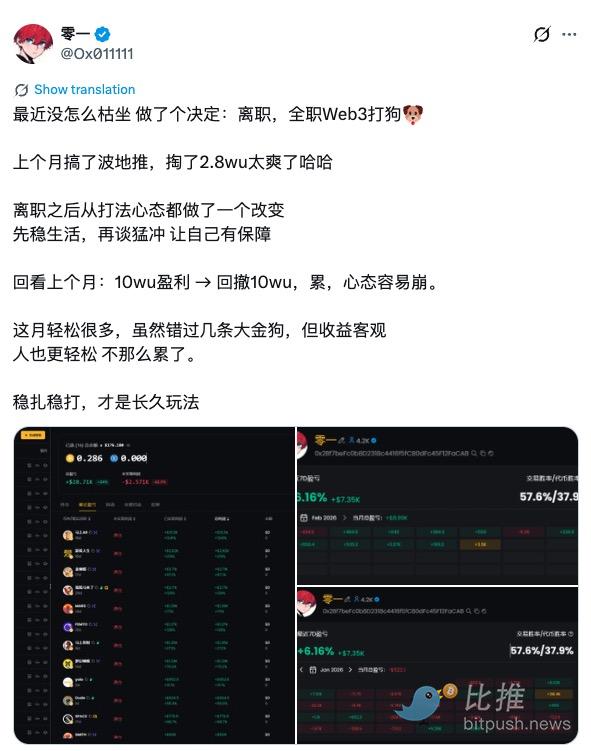

热门回复:
物极必反,等mean reversion。现在就是休息,谁越早休息好了,越有优势;
等就完事儿了;
Ai圈的虹吸效应 今年开始应该会表现的特别强烈了。
Twitter:https://twitter.com/BitpushNewsCN
比推 TG 交流群:https://t.me/BitPushCommunity
比推 TG 订阅: https://t.me/bitpush





