Authors: Li Hailun, Su Yang
On January 6th, Beijing time, NVIDIA CEO Jensen Huang, clad in his signature leather jacket, once again took the main stage at CES 2026.
At CES 2025, NVIDIA showcased the mass-produced Blackwell chip and a full-stack physical AI technology suite. During the event, Huang emphasized that an "era of Physical AI" was dawning. He painted a future full of imagination: autonomous vehicles with reasoning capabilities, robots that can understand and think, and AI Agents capable of handling long-context tasks involving millions of tokens.
A year has passed in a flash, and the AI industry has undergone significant evolution and change. Reviewing these changes at the launch event, Huang specifically highlighted open-source models.
He stated that open-source reasoning models like DeepSeek R1 have made the entire industry realize: when true openness and global collaboration kick in, the diffusion speed of AI becomes extremely rapid. Although open-source models still lag behind the most advanced models by about six months in overall capability, they close the gap every six months, and their downloads and usage have already seen explosive growth.

Compared to 2025's focus more on vision and possibilities, this time NVIDIA began systematically addressing the question of "how to achieve it":围绕推理型 AI (focusing on reasoning AI), it is bolstering the compute, networking, and storage infrastructure required for long-term operation, significantly reducing inference costs, and embedding these capabilities directly into real-world scenarios like autonomous driving and robotics.
Huang's CES keynote this year unfolded along three main lines:
● At the system and infrastructure level, NVIDIA redesigned the compute, networking, and storage architecture around long-term inference needs. With the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the Inference Context Memory Storage platform at the core, these updates directly target bottlenecks like high inference costs, difficulty in sustaining context, and scalability limitations, solving the problems of letting AI 'think a bit longer', 'afford to compute', and 'run persistently'.
● At the model level, NVIDIA placed Reasoning / Agentic AI at the core. Through models and tools like Alpamayo, Nemotron, and Cosmos Reason, it is pushing AI from "generating content" towards "continuous thinking", and from "one-time response models" to "agents that can work long-term".
● At the application and deployment level, these capabilities are being directly integrated into Physical AI scenarios like autonomous driving and robotics. Whether it's the Alpamayo-powered autonomous driving system or the GR00T and Jetson robotics ecosystem, they are driving scaled deployment through partnerships with cloud providers and enterprise platforms.

01 From Roadmap to Mass Production: Rubin's Full Performance Data Revealed for the First Time
At this CES, NVIDIA fully disclosed the technical details of the Rubin architecture for the first time.
In his speech, Huang started with the concept of Test-time Scaling. This concept can be understood as: making AI smarter isn't just about making it "study harder" during training anymore, but rather letting it "think a bit longer when encountering a problem".
In the past, improvements in AI capability relied mainly on throwing more compute power at the training stage, making models larger and larger; now, the new change is that even if the model stops growing, simply giving it a bit more time and compute power to think during each use can significantly improve the results.
How to make "AI thinking a bit longer" economically feasible? The Rubin architecture's next-generation AI computing platform is here to solve this problem.
Huang introduced it as a complete next-generation AI computing system, achieving a revolutionary drop in inference costs through the co-design of the Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, and Spectrum-6.

The NVIDIA Rubin GPU is the core chip responsible for AI compute in the Rubin architecture, aiming to significantly reduce the unit cost of inference and training.
Simply put, the Rubin GPU's core mission is to "make AI cheaper and smarter to use".
The core capability of the Rubin GPU lies in: the same GPU can handle more work. It can process more inference tasks at once, remember longer context, and communicate faster with other GPUs. This means many scenarios that previously required "stacking multiple cards" can now be accomplished with fewer GPUs.
The result is that inference is not only faster, but also significantly cheaper.
Huang recapped the hardware specs of the Rubin architecture's NVL72 for the audience: it contains 220 trillion transistors, with a bandwidth of 260 TB/s, and is the industry's first platform supporting rack-scale confidential computing.

Overall, compared to Blackwell, the Rubin GPU achieves a generational leap in key metrics: NVFP4 inference performance increases to 50 PFLOPS (5x), training performance to 35 PFLOPS (3.5x), HBM4 memory bandwidth to 22 TB/s (2.8x), and single GPU NVLink interconnect bandwidth doubles to 3.6 TB/s.
These improvements work together to enable a single GPU to handle more inference tasks and longer context, fundamentally reducing the reliance on the number of GPUs.

The Vera CPU is a core component designed specifically for data movement and Agentic processing, featuring 88 NVIDIA-designed Olympus cores, equipped with 1.5 TB of system memory (3x that of the previous Grace CPU), and achieving coherent memory access between CPU and GPU through 1.8 TB/s NVLink-C2C technology.
Unlike traditional general-purpose CPUs, Vera focuses on data scheduling and multi-step reasoning logic processing in AI inference scenarios, essentially acting as the system coordinator that enables "AI thinking a bit longer" to run efficiently.
NVLink 6, with its 3.6 TB/s bandwidth and in-network computing capability, allows the 72 GPUs in the Rubin architecture to work together like a single super GPU, which is key infrastructure for reducing inference costs.
This way, the data and intermediate results needed by AI during inference can quickly circulate between GPUs, without repeatedly waiting, copying, or recalculating.


In the Rubin architecture, NVLink-6 handles internal collaborative computing between GPUs, BlueField-4 handles context and data scheduling, and ConnectX-9 undertakes the system's high-speed external network connectivity. It ensures the Rubin system can communicate efficiently with other racks, data centers, and cloud platforms, a prerequisite for the smooth operation of large-scale training and inference tasks.
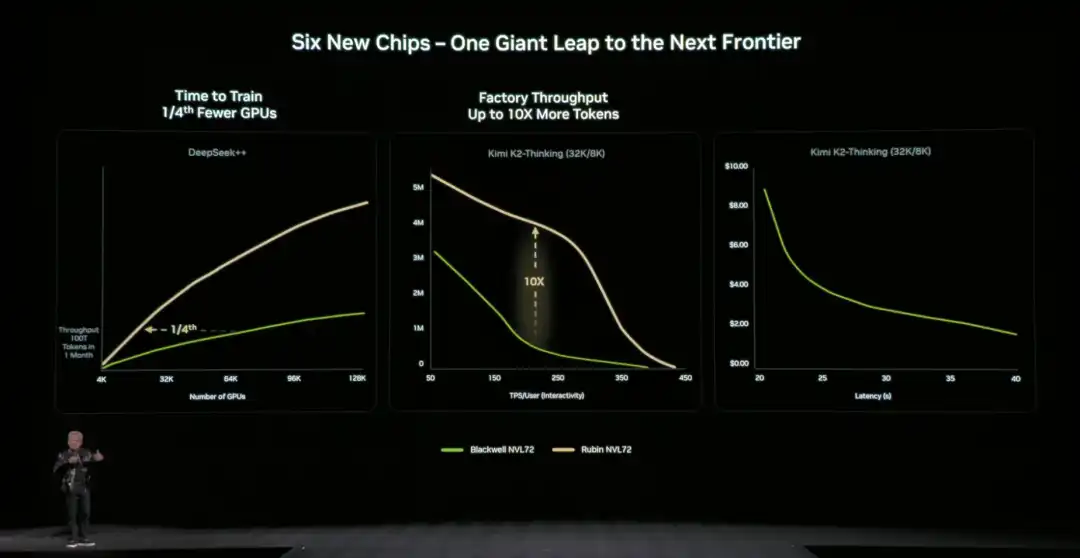
Compared to the previous generation architecture, NVIDIA also provided specific,直观的数据 (intuitive data): compared to the NVIDIA Blackwell platform, it can reduce token costs in the inference phase by up to 10 times, and reduce the number of GPUs required for training Mixture of Experts (MoE) models to 1/4 of the original.
NVIDIA officially stated that Microsoft has already committed to deploying hundreds of thousands of Vera Rubin chips in its next-generation Fairwater AI super factory, and cloud service providers like CoreWeave will offer Rubin instances in the second half of 2026. This infrastructure for "letting AI think a bit longer" is moving from technical demonstration to scaled commercial use.

02 How is the "Storage Bottleneck" Solved?
Letting AI "think a bit longer" also faces a key technical challenge: where should the context data be stored?
When AI handles complex tasks requiring multi-turn dialogue or multi-step reasoning, it generates a large amount of context data (KV Cache). Traditional architectures either cram it into expensive and capacity-limited GPU memory or put it in ordinary storage (which is too slow to access). If this "storage bottleneck" isn't solved, even the most powerful GPU will be hampered.
To address this issue, NVIDIA fully disclosed the BlueField-4 powered Inference Context Memory Storage Platform for the first time at this CES. The core goal is to create a "third layer" between GPU memory and traditional storage. It's fast enough, has ample capacity, and can support AI's long-term operation.
From a technical implementation perspective, this platform isn't the result of a single component working alone, but rather a set of co-designed elements:
- BlueField-4 is responsible for accelerating the management and access of context data at the hardware level, reducing data movement and system overhead;
- Spectrum-X Ethernet provides high-performance networking, supporting high-speed data sharing based on RDMA;
- Software components like DOCA, NIXL, and Dynamo are responsible for optimizing scheduling, reducing latency, and improving overall throughput at the system level.
We can understand this platform's approach as extending the context data, which originally could only reside in GPU memory, to an independent, high-speed, shareable "memory layer". This一方面 (on one hand) relieves pressure on the GPU, and另一方面 (on the other hand) allows for rapid sharing of this context information between multiple nodes and multiple AI agents.
In terms of actual效果 (effects), the data provided by NVIDIA官方 (officially) is: in specific scenarios, this method can increase the number of tokens processed per second by up to 5 times, and achieve同等水平的 (equivalent levels of) energy efficiency optimization.
Huang emphasized多次 (repeatedly) during the presentation that AI is evolving from "one-time dialogue chatbots" to true intelligent collaborators: they need to understand the real world, reason continuously, call tools to complete tasks, and retain both short-term and long-term memory. This is the core characteristic of Agentic AI. The Inference Context Memory Storage Platform is designed precisely for this long-running,反复思考的 (repeatedly thinking) form of AI. By expanding context capacity and speeding up cross-node sharing, it makes multi-turn conversations and multi-agent collaboration more stable, no longer "slowing down the longer it runs".

03 The New Generation DGX SuperPOD: Enabling 576 GPUs to Work Together
NVIDIA announced the new generation DGX SuperPOD (Super Pod) based on the Rubin architecture at this CES, expanding Rubin from a single rack to a complete data center solution.
What is a DGX SuperPOD?
If the Rubin NVL72 is a "super rack" containing 72 GPUs, then the DGX SuperPOD connects multiple such racks together to form a larger-scale AI computing cluster. This released version consists of 8 Vera Rubin NVL72 racks, equivalent to 576 GPUs working together.
When AI task scales continue to expand, the 576 GPUs of a single SuperPOD might not be enough. For example, training ultra-large-scale models, simultaneously serving thousands of Agentic AI agents, or processing complex tasks requiring millions of tokens of context. This requires multiple SuperPODs working together, and the DGX SuperPOD is the standardized solution for this scenario.
For enterprises and cloud service providers, the DGX SuperPOD provides an "out-of-the-box" large-scale AI infrastructure solution. There's no need to figure out how to connect hundreds of GPUs, configure networks, manage storage, etc., themselves.
The five core components of the new generation DGX SuperPOD:
○ 8 Vera Rubin NVL72 Racks - The core providing computing power, 72 GPUs per rack, 576 GPUs total;
○ NVLink 6 Expansion Network - Allows the 576 GPUs across these 8 racks to work together like one超大 (super large) GPU;
○ Spectrum-X Ethernet Expansion Network - Connects different SuperPODs, and to storage and external networks;
○ Inference Context Memory Storage Platform - Provides shared context data storage for long-running inference tasks;
○ NVIDIA Mission Control Software - Manages scheduling, monitoring, and optimization of the entire system.
With this upgrade, the foundation of the SuperPOD is the DGX Vera Rubin NVL72 rack-scale system at its core. Each NVL72 is itself a complete AI supercomputer, internally connecting 72 Rubin GPUs via NVLink 6, capable of handling large-scale inference and training tasks within a single rack. The new DGX SuperPOD consists of multiple NVL72 units, forming a system-level cluster capable of long-term operation.
When the compute scale expands from "single rack" to "multi-rack", new bottlenecks emerge: how to stably and efficiently传输海量数据 (transfer massive amounts of data) between racks.围绕这一问题 (Around this issue), NVIDIA simultaneously announced the new generation Ethernet switch based on the Spectrum-6 chip at this CES, and introduced "Co-Packaged Optics" (CPO) technology for the first time.
Simply put, this involves packaging the originally pluggable optical modules directly next to the switch chip, reducing the signal transmission distance from meters to millimeters, thereby significantly reducing power consumption and latency, and also improving the overall stability of the system.
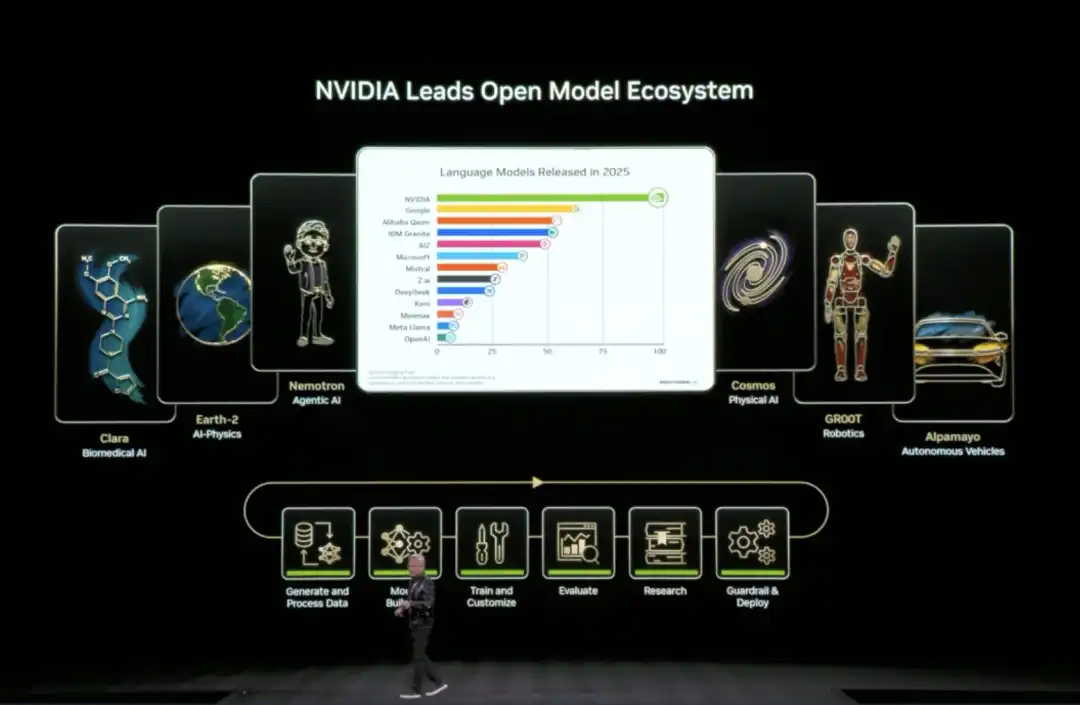
04 NVIDIA's Open Source AI "Full Stack": Everything from Data to Code
At this CES, Huang announced the expansion of its open-source model ecosystem (Open Model Universe), adding and updating a series of models, datasets, code libraries, and tools. This ecosystem covers six areas: Biomedical AI (Clara), AI Physics Simulation (Earth-2), Agentic AI (Nemotron), Physical AI (Cosmos), Robotics (GR00T), and Autonomous Driving (Alpamayo).
Training an AI model requires not just compute power, but also high-quality datasets, pre-trained models, training code, evaluation tools, and a whole set of infrastructure. For most companies and research institutions, building these from scratch is too time-consuming.
Specifically, NVIDIA has open-sourced six layers of content: compute platforms (DGX, HGX, etc.), training datasets for various domains, pre-trained foundation models, inference and training code libraries, complete training process scripts, and end-to-end solution templates.
The Nemotron series was a key focus of this update, covering four application directions.
In the reasoning direction, it includes small-scale reasoning models like Nemotron 3 Nano, Nemotron 2 Nano VL, as well as reinforcement learning training tools like NeMo RL and NeMo Gym. In the RAG (Retrieval-Augmented Generation) direction, it provides Nemotron Embed VL (vector embedding model), Nemotron Rerank VL (re-ranking model), relevant datasets, and the NeMo Retriever Library. In the safety direction, there is the Nemotron Content Safety model and its配套数据集 (matching dataset), and the NeMo Guardrails library.
In the speech direction, it includes Nemotron ASR for automatic speech recognition, the Granary Dataset for speech, and the NeMo Library for speech processing. This means if a company wants to build an AI customer service system with RAG, it doesn't need to train its own embedding and re-ranking models; it can directly use the code NVIDIA has already trained and open-sourced.
05 Physical AI Domain Moves Towards Commercial Deployment
The Physical AI domain also saw model updates—Cosmos for understanding and generating videos of the physical world, the general-purpose robotics foundation model Isaac GR00T, and the vision-language-action model for autonomous driving, Alpamayo.

Huang claimed at CES that the "ChatGPT moment" for Physical AI is approaching, but there are many challenges: the physical world is too complex and variable, collecting real data is slow and expensive, and there's never enough.
What's the solution? Synthetic data is one path. Hence, NVIDIA introduced Cosmos.
This is an open-source foundational model for the physical AI world, already pre-trained on massive amounts of video, real driving and robotics data, and 3D simulation. It can understand how the world works and connect language, images, 3D, and actions.
Huang stated that Cosmos can achieve several physical AI skills, such as generating content, performing reasoning, and predicting trajectories (even if only given a single image). It can generate realistic videos based on 3D scenes, generate physically plausible motion based on driving data, and even generate panoramic videos from simulators, multi-camera footage, or text descriptions. It can even还原 (recreate) rare scenarios.
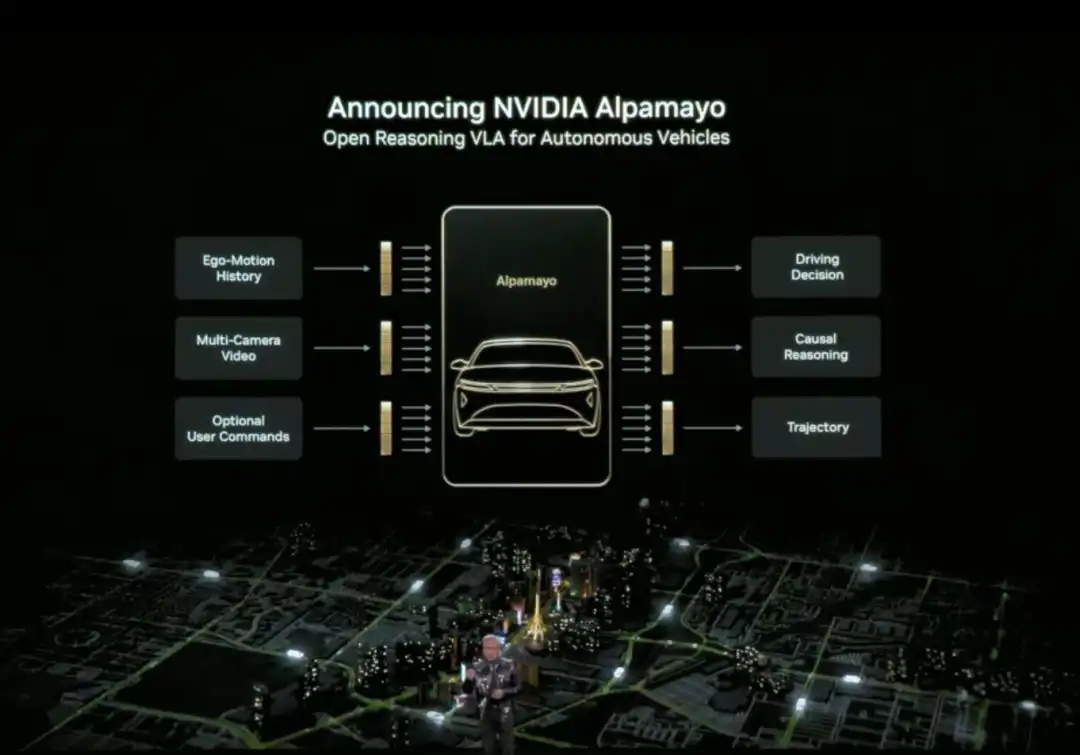
Huang also officially released Alpamayo. Alpamayo is an open-source toolchain for the autonomous driving domain, and the first open-source vision-language-action (VLA) reasoning model. Unlike previous open-sourcing of only code, NVIDIA this time open-sourced the complete development resources from data to deployment.
Alpamayo's biggest breakthrough is that it is a "reasoning" autonomous driving model. Traditional autonomous driving systems follow a "perception-planning-control" pipeline architecture—see a red light and brake, see a pedestrian and slow down, following preset rules. Alpamayo introduces "reasoning" capability, understanding causal relationships in complex scenes, predicting the intentions of other vehicles and pedestrians, and even handling decisions requiring multi-step thinking.
For example, at an intersection, it doesn't just recognize "there's a car ahead", but can reason "that car might be turning left, so I should wait for it to go first". This capability upgrades autonomous driving from "driving by rules" to "thinking like a human".
Huang announced that the NVIDIA DRIVE system has officially entered the mass production phase, with the first application being the new Mercedes-Benz CLA, planned to hit US roads in 2026. This vehicle will be equipped with an L2++ level autonomous driving system, adopting a hybrid architecture of "end-to-end AI model + traditional pipeline".
The robotics field also saw substantial progress.
Huang stated that leading global robotics companies, including Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics, and XRlabs, are developing products based on the NVIDIA Isaac platform and the GR00T foundation model, covering various fields from industrial robots and surgical robots to humanoid robots and consumer robots.

During the launch event, Huang stood in front of a stage filled with robots of different forms and用途 (purposes), displayed on a tiered platform: from humanoid robots, bipedal and wheeled service robots, to industrial robotic arms, engineering machinery, drones, and surgical assist devices, presenting a "robotics ecosystem landscape".
From Physical AI applications to the Rubin AI computing platform, to the Inference Context Memory Storage platform and the open-source AI "full stack".
These actions showcased by NVIDIA at CES constitute NVIDIA's narrative for推理时代 AI 基础设施 (AI infrastructure for the reasoning era). As Huang repeatedly emphasized, when Physical AI needs to think continuously, run persistently, and truly enter the real world, the problem is no longer just about whether there's enough compute power, but about who can actually build the entire system.
At CES 2026, NVIDIA has provided an answer.
熱門幣種推薦
相關問答
QWhat are the three main topics of Jensen Huang's CES 2026 keynote?![]()
AThe three main topics are: 1) Reconstructing computing, networking, and storage architecture around long-term inference needs with the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the inference context memory storage platform. 2) Placing reasoning/agentic AI at the core through models and tools like Alpamayo, Nemotron, and Cosmos Reason. 3) Directly applying these capabilities to physical AI scenarios like autonomous driving and robotics.
QWhat is the key innovation of the Rubin GPU architecture and its primary goal?![]()
AThe key innovation of the Rubin GPU architecture is its ability to handle more inference tasks and longer context within a single GPU, facilitated by a significant performance leap over Blackwell. Its primary goal is to 'make AI cheaper and smarter to use' by dramatically reducing the cost of inference and the number of GPUs required for many tasks.
QWhat problem does the Inference Context Memory Storage Platform solve, and what are its core components?![]()
AIt solves the 'storage bottleneck' problem, where context data (KV Cache) from multi-step AI reasoning tasks traditionally had to be stored in expensive, limited GPU memory or slow conventional storage. Its core components are the BlueField-4 DPU (for hardware-accelerated data management), Spectrum-X Ethernet (for high-performance networking), and software components like DOCA, NIXL, and Dynamo for system optimization.
QWhat major advancement did NVIDIA announce for the autonomous driving sector?![]()
ANVIDIA announced the official entry of its DRIVE system into mass production, with the first application being the new Mercedes-Benz CLA, planned for US roads in 2026. They also open-sourced Alpamayo, the first visual-language-action (VLA) reasoning model for autonomous driving, which introduces causal reasoning and multi-step decision-making capabilities.
QWhat is the significance of the new DGX SuperPOD based on the Rubin architecture?![]()
AThe new DGX SuperPOD scales the Rubin architecture from a single rack (NVL72 with 72 GPUs) to a data-center-scale solution. Composed of 8 NVL72 racks for a total of 576 GPUs, it provides an 'out-of-the-box' massive AI computing cluster for training ultra-large models or serving thousands of Agentic AI agents, managed by the NVIDIA Mission Control software.
你可能也喜歡




交易
熱門文章
什麼是 $S$
理解 SPERO:全面概述 SPERO 簡介 隨著創新領域的不斷演變,web3 技術和加密貨幣項目的出現在塑造數字未來中扮演著關鍵角色。在這個動態領域中,SPERO(標記為 SPERO,$$s$)是一個引起關注的項目。本文旨在收集並呈現有關 SPERO 的詳細信息,以幫助愛好者和投資者理解其基礎、目標和在 web3 和加密領域內的創新。 SPERO,$$s$ 是什麼? SPERO,$$s$ 是加密空間中的一個獨特項目,旨在利用去中心化和區塊鏈技術的原則,創建一個促進參與、實用性和金融包容性的生態系統。該項目旨在以新的方式促進點對點互動,為用戶提供創新的金融解決方案和服務。 SPERO,$$s$ 的核心目標是通過提供增強用戶體驗的工具和平台來賦能個人。這包括使交易方式更加靈活、促進社區驅動的倡議,以及通過去中心化應用程序(dApps)創造金融機會的途徑。SPERO,$$s$ 的基本願景圍繞包容性展開,旨在彌合傳統金融中的差距,同時利用區塊鏈技術的優勢。 誰是 SPERO,$$s$ 的創建者? SPERO,$$s$ 的創建者身份仍然有些模糊,因為公開可用的資源對其創始人提供的詳細背景信息有限。這種缺乏透明度可能源於該項目對去中心化的承諾——這是一種許多 web3 項目所共享的精神,優先考慮集體貢獻而非個人認可。 通過將討論重心放在社區及其共同目標上,SPERO,$$s$ 體現了賦能的本質,而不特別突出某些個體。因此,理解 SPERO 的精神和使命比識別單一創建者更為重要。 誰是 SPERO,$$s$ 的投資者? SPERO,$$s$ 得到了來自風險投資家到天使投資者的多樣化投資者的支持,他們致力於促進加密領域的創新。這些投資者的關注點通常與 SPERO 的使命一致——優先考慮那些承諾社會技術進步、金融包容性和去中心化治理的項目。 這些投資者通常對不僅提供創新產品,還對區塊鏈社區及其生態系統做出積極貢獻的項目感興趣。這些投資者的支持強化了 SPERO,$$s$ 作為快速發展的加密項目領域中的一個重要競爭者。 SPERO,$$s$ 如何運作? SPERO,$$s$ 採用多面向的框架,使其與傳統的加密貨幣項目區別開來。以下是一些突顯其獨特性和創新的關鍵特徵: 去中心化治理:SPERO,$$s$ 整合了去中心化治理模型,賦予用戶積極參與決策過程的權力,關於項目的未來。這種方法促進了社區成員之間的擁有感和責任感。 代幣實用性:SPERO,$$s$ 使用其自己的加密貨幣代幣,旨在在生態系統內部提供多種功能。這些代幣使交易、獎勵和平台上提供的服務得以促進,增強了整體參與度和實用性。 分層架構:SPERO,$$s$ 的技術架構支持模塊化和可擴展性,允許在項目發展過程中無縫整合額外的功能和應用。這種適應性對於在不斷變化的加密環境中保持相關性至關重要。 社區參與:該項目強調社區驅動的倡議,採用激勵合作和反饋的機制。通過培養強大的社區,SPERO,$$s$ 能夠更好地滿足用戶需求並適應市場趨勢。 專注於包容性:通過提供低交易費用和用戶友好的界面,SPERO,$$s$ 旨在吸引多樣化的用戶群體,包括那些以前可能未曾參與加密領域的個體。這種對包容性的承諾與其通過可及性賦能的總體使命相一致。 SPERO,$$s$ 的時間線 理解一個項目的歷史提供了對其發展軌跡和里程碑的關鍵見解。以下是建議的時間線,映射 SPERO,$$s$ 演變中的重要事件: 概念化和構思階段:形成 SPERO,$$s$ 基礎的初步想法被提出,與區塊鏈行業內的去中心化和社區聚焦原則密切相關。 項目白皮書的發布:在概念階段之後,發布了一份全面的白皮書,詳細說明了 SPERO,$$s$ 的願景、目標和技術基礎設施,以吸引社區的興趣和反饋。 社區建設和早期參與:積極進行外展工作,建立早期採用者和潛在投資者的社區,促進圍繞項目目標的討論並獲得支持。 代幣生成事件:SPERO,$$s$ 進行了一次代幣生成事件(TGE),向早期支持者分發其原生代幣,並在生態系統內建立初步流動性。 首次 dApp 上線:與 SPERO,$$s$ 相關的第一個去中心化應用程序(dApp)上線,允許用戶參與平台的核心功能。 持續發展和夥伴關係:對項目產品的持續更新和增強,包括與區塊鏈領域其他參與者的戰略夥伴關係,使 SPERO,$$s$ 成為加密市場中一個具有競爭力和不斷演變的參與者。 結論 SPERO,$$s$ 是 web3 和加密貨幣潛力的見證,能夠徹底改變金融系統並賦能個人。憑藉對去中心化治理、社區參與和創新設計功能的承諾,它為更具包容性的金融環境鋪平了道路。 與任何在快速發展的加密領域中的投資一樣,潛在的投資者和用戶都被鼓勵進行徹底研究,並對 SPERO,$$s$ 的持續發展進行深思熟慮的參與。該項目展示了加密行業的創新精神,邀請人們進一步探索其無數可能性。儘管 SPERO,$$s$ 的旅程仍在展開,但其基礎原則確實可能影響我們在互聯網數字生態系統中如何與技術、金融和彼此互動的未來。
421 人學過發佈於 2024.12.17更新於 2024.12.17

什麼是 AGENT S
Agent S:Web3中自主互動的未來 介紹 在不斷演變的Web3和加密貨幣領域,創新不斷重新定義個人如何與數字平台互動。Agent S是一個開創性的項目,承諾通過其開放的代理框架徹底改變人機互動。Agent S旨在簡化複雜任務,為人工智能(AI)提供變革性的應用,鋪平自主互動的道路。本詳細探索將深入研究該項目的複雜性、其獨特特徵以及對加密貨幣領域的影響。 什麼是Agent S? Agent S是一個突破性的開放代理框架,專門設計用來解決計算機任務自動化中的三個基本挑戰: 獲取特定領域知識:該框架智能地從各種外部知識來源和內部經驗中學習。這種雙重方法使其能夠建立豐富的特定領域知識庫,提升其在任務執行中的表現。 長期任務規劃:Agent S採用經驗增強的分層規劃,這是一種戰略方法,可以有效地分解和執行複雜任務。此特徵顯著提升了其高效和有效地管理多個子任務的能力。 處理動態、不均勻的界面:該項目引入了代理-計算機界面(ACI),這是一種創新的解決方案,增強了代理和用戶之間的互動。利用多模態大型語言模型(MLLMs),Agent S能夠無縫導航和操作各種圖形用戶界面。 通過這些開創性特徵,Agent S提供了一個強大的框架,解決了自動化人機互動中涉及的複雜性,為AI及其他領域的無數應用奠定了基礎。 誰是Agent S的創建者? 儘管Agent S的概念根本上是創新的,但有關其創建者的具體信息仍然難以捉摸。創建者目前尚不清楚,這突顯了該項目的初期階段或戰略選擇將創始成員保密。無論是否匿名,重點仍然在於框架的能力和潛力。 誰是Agent S的投資者? 由於Agent S在加密生態系統中相對較新,關於其投資者和財務支持者的詳細信息並未明確記錄。缺乏對支持該項目的投資基礎或組織的公開見解,引發了對其資金結構和發展路線圖的質疑。了解其支持背景對於評估該項目的可持續性和潛在市場影響至關重要。 Agent S如何運作? Agent S的核心是尖端技術,使其能夠在多種環境中有效運作。其運營模型圍繞幾個關鍵特徵構建: 類人計算機互動:該框架提供先進的AI規劃,力求使與計算機的互動更加直觀。通過模仿人類在任務執行中的行為,承諾提升用戶體驗。 敘事記憶:用於利用高級經驗,Agent S利用敘事記憶來跟蹤任務歷史,從而增強其決策過程。 情節記憶:此特徵為用戶提供逐步指導,使框架能夠在任務展開時提供上下文支持。 支持OpenACI:Agent S能夠在本地運行,使用戶能夠控制其互動和工作流程,與Web3的去中心化理念相一致。 與外部API的輕鬆集成:其多功能性和與各種AI平台的兼容性確保了Agent S能夠無縫融入現有技術生態系統,成為開發者和組織的理想選擇。 這些功能共同促成了Agent S在加密領域的獨特地位,因為它以最小的人類干預自動化複雜的多步任務。隨著項目的發展,其在Web3中的潛在應用可能重新定義數字互動的展開方式。 Agent S的時間線 Agent S的發展和里程碑可以用一個時間線來概括,突顯其重要事件: 2024年9月27日:Agent S的概念在一篇名為《一個像人類一樣使用計算機的開放代理框架》的綜合研究論文中推出,展示了該項目的基礎工作。 2024年10月10日:該研究論文在arXiv上公開,提供了對框架及其基於OSWorld基準的性能評估的深入探索。 2024年10月12日:發布了一個視頻演示,提供了對Agent S能力和特徵的視覺洞察,進一步吸引潛在用戶和投資者。 這些時間線上的標記不僅展示了Agent S的進展,還表明了其對透明度和社區參與的承諾。 有關Agent S的要點 隨著Agent S框架的持續演變,幾個關鍵特徵脫穎而出,強調其創新性和潛力: 創新框架:旨在提供類似人類互動的直觀計算機使用,Agent S為任務自動化帶來了新穎的方法。 自主互動:通過GUI自主與計算機互動的能力標誌著向更智能和高效的計算解決方案邁進了一步。 複雜任務自動化:憑藉其強大的方法論,能夠自動化複雜的多步任務,使過程更快且更少出錯。 持續改進:學習機制使Agent S能夠從過去的經驗中改進,不斷提升其性能和效率。 多功能性:其在OSWorld和WindowsAgentArena等不同操作環境中的適應性確保了它能夠服務於廣泛的應用。 隨著Agent S在Web3和加密領域中的定位,其增強互動能力和自動化過程的潛力標誌著AI技術的一次重大進步。通過其創新框架,Agent S展現了數字互動的未來,為各行各業的用戶承諾提供更無縫和高效的體驗。 結論 Agent S代表了AI與Web3結合的一次大膽飛躍,具有重新定義我們與技術互動方式的能力。儘管仍處於早期階段,但其應用的可能性廣泛且引人入勝。通過其全面的框架解決關鍵挑戰,Agent S旨在將自主互動帶到數字體驗的最前沿。隨著我們深入加密貨幣和去中心化的領域,像Agent S這樣的項目無疑將在塑造技術和人機協作的未來中發揮關鍵作用。
1.2k 人學過發佈於 2025.01.14更新於 2025.01.14
如何購買S
歡迎來到HTX.com!在這裡,購買Sonic (S)變得簡單而便捷。跟隨我們的逐步指南,放心開始您的加密貨幣之旅。第一步:創建您的HTX帳戶使用您的 Email、手機號碼在HTX註冊一個免費帳戶。體驗無憂的註冊過程並解鎖所有平台功能。立即註冊第二步:前往買幣頁面,選擇您的支付方式信用卡/金融卡購買:使用您的Visa或Mastercard即時購買Sonic (S)。餘額購買:使用您HTX帳戶餘額中的資金進行無縫交易。第三方購買:探索諸如Google Pay或Apple Pay等流行支付方式以增加便利性。C2C購買:在HTX平台上直接與其他用戶交易。HTX 場外交易 (OTC) 購買:為大量交易者提供個性化服務和競爭性匯率。第三步:存儲您的Sonic (S)購買Sonic (S)後,將其存儲在您的HTX帳戶中。您也可以透過區塊鏈轉帳將其發送到其他地址或者用於交易其他加密貨幣。第四步:交易Sonic (S)在HTX的現貨市場輕鬆交易Sonic (S)。前往您的帳戶,選擇交易對,執行交易,並即時監控。HTX為初學者和經驗豐富的交易者提供了友好的用戶體驗。
2.6k 人學過發佈於 2025.01.15更新於 2026.06.02

