算力掣肘
去年底以来,摩尔线程、沐曦股份、壁仞科技、天数智芯等国产GPU掀起资本热浪。然而,二级市场财富盛宴之下,一条不容忽视的暗线正变得越来越明晰,其引发的问题也愈发迫切。
过去几年,国产AI芯片主要集中在相对安全且较为边缘的“推理侧”,如近期豆包计划豪购天数智芯5万块芯片用于推理运算任务,以满足这家中国最大AI APP终端的高频调用。
而在AI训练这一算力金字塔顶端序列中,国产芯片目前只能参与边缘“打杂”任务。
AI训练芯片主要用于人工智能模型的训练,期间会进行大量的矩阵运算和参数调整,因此需要具备强大的计算能力和高能效比,性能更强大且价格也十分高昂,如英伟达A100、H100、H200以及AMD的MI300系列等;
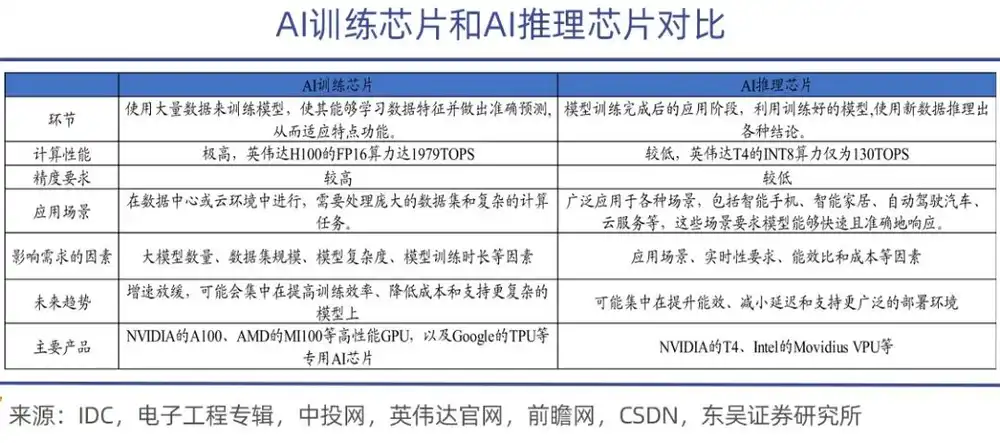
相较而言,推理芯片的任务要轻松许多。用于模型训练完成后的部署阶段,主要负责执行模型的推理任务,其对实时性要求较高,推理芯片需要在保证准确率的同时,具备快速响应和低功耗的特点。
一个恰当的比喻就是,训练是让AI模型“学会知识”,推理是让大模型“运用知识”。在学习阶段,训练芯片要调用巨量数据来“喂养”十亿、万亿乃至十万亿级参数的动态更新,不仅要具备强悍的算力,还需配置高效的带宽和通信能力,还要保障万卡级集群下的稳定性。
中美模型差距根源就在这些“看不见的地方”,尤其是高端训练芯片的缺席。
在大模型Scaling Law规律下,模型参数越大,算力需求相应线性增长,而指数级膨胀的算力及硬件成本开支,让训练大模型成为极少数科技巨头的“专属游戏”。
美国科技巨头中,仅Meta一家就计划2026年底部署超120万张高端GPU,年投入超1450亿美元;另据测算,谷歌拥有的AI总算力相当于500万块英伟达H100,一家企业占到了全球总量的1/4。
Amazon、Microsoft、Alphabet、Meta四家公司今年的资本开支高达7250亿美元,同比猛增77%,这一规模,相当于美国全年私人国内总投资的13%。大摩更是预测,到2027年,美国科技企业资本开支有望达到1.1万亿美元的历史纪录。
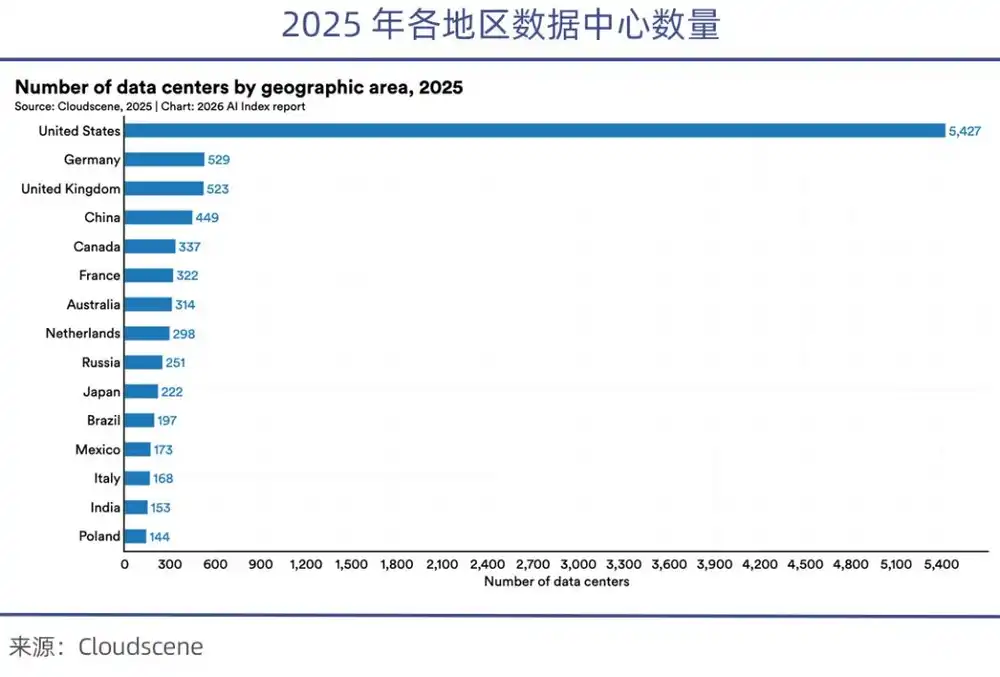
目前美国掌控全球七成以上高端GPU,芯片禁令后国内可用的高端芯片只有美国的1/8。斯坦福AI Index Report 2026报告中指出,美国数据中心数量(5427个)是中国10倍有余。
依据中国信息通信研究院(CAICT)的测算,截至2025年初,美国算力规模为2400 EFLOPS,中国1053 EFLOPS,美国是中国的2倍有余。
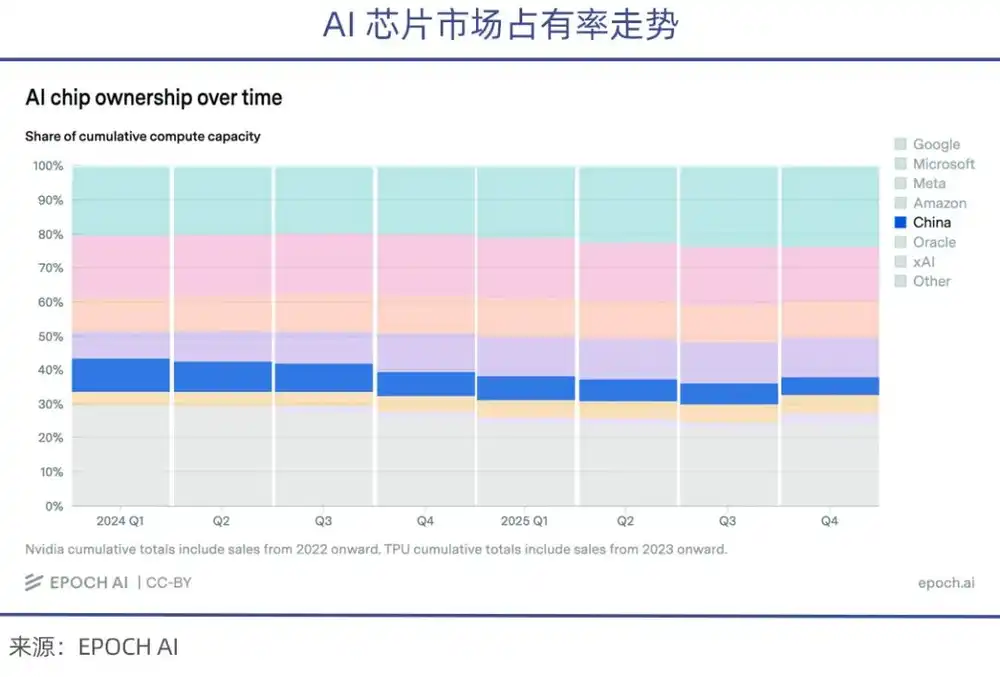
上述四家科技巨头在手的算力规模,每一家单拎出来,都已经超过中国所有AI企业之和。
这种碾压式的算力优势,使美国企业可以一年内完成十几轮大模型迭代实验。
马斯克甚至更加奢侈,旗下的xAI拥有号称全球“首个GW级AI集群”的Colossus 2。因此他有底气宣称,正在同时训练7个模型——两个1万亿、两个1.5万亿、一个6万亿和一个10万亿参数模型,这种“暴力美学”,只有在算力极度充裕的情况下才能做到。

与此同时,由于美国钳制芯片出口,在近年来出货的高端AI芯片中,中国企业获得的份额持续下滑(根据epoch.AI统计)。
可以毫不夸张地说,算力基座的巨大差距,将导致中国AI长期处于追赶阶段,也将让国产大模型追上美国同行的过程变得更加困难。
代际之差
“中国创新的步伐不可阻挡”,“谁要是觉得中国做不出来(芯片),那就真的看走眼了。中美之间的差距只是纳秒级别”。
英伟达创始人黄仁勋不止一次在公开场合称赞中国半导体的进步。

马斯克也经常会在X上表达相似的观点——“中国一定会解决芯片卡脖子问题,人工智能算力领域,必将远超全球其他国家”,“中国会赢下地球上的AI竞赛”。
科技界如雷贯耳的大佬对中国AI发展极尽溢美之词,很容易让人信以为真。这些言论显然有捧杀的嫌疑。部分美国媒体不断宣扬中美模型差距极小的舆论,试图混淆事实,掩盖一些客观真相。
对此,国内AI相关领域都应该保持清醒冷静。
如果说如今中国先进大模型在解决标准化问题时与美国竞品差别不大,那么在复杂工业和企业环境下,差距就会显得更加明显。
和美国Anthropic等公司的前沿模型相比,中国仍属于追赶者。美国CAISI评估认为,国内最强的DeepSeek V4 Pro落后美国前沿约8个月。
李开复近期在接受《华尔街日报》采访时指出,以Anthropic推出的Claude Fable 5等美国顶尖模型为标杆,美国目前领先中国约15个月。

大模型遵循Scaling Law规律,模型参数量越大、训练数据越多、投入的算力越大,模型的性能就越好。如今,美国最前沿大模型已进入十万亿参数时代,且迭代速度还在加快。
Anthropic最强大的Mythos已达10万亿参数,训练它就要耗费100亿美元;xAI的Colossus 2正同时训练7个模型,含6万亿和10万亿参数模型;OpenAI迭代一轮4万亿参数模型的周期仅为一个月。
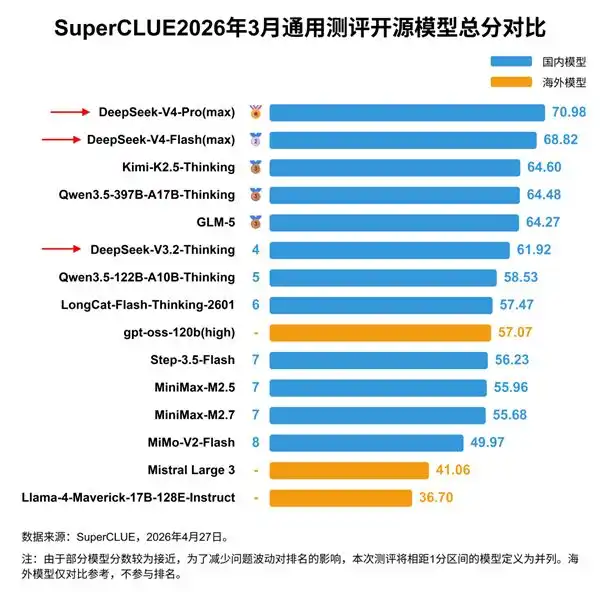
中国最强模型DeepSeek V4 Pro总参数量为1.6万亿,和美国十万亿级前沿相差约6倍。
Anthrpoic旗下的Claude系列,已经被公认为近两年最强的AI编程大模型,Mythos则又再一次刷新了公众的认知,其性能相比此前的旗舰Oups 4.6还要更加强大。
OpenBSD在业界有着最安全的系统的美名,结果Mythos找到了一个27年间都没发现的漏洞,它还在FFmpeg、Linux内核中寻觅到了几年甚至十几年都没发现的漏洞,而且全程自主发现,没有依靠人类。
要知道,大模型“预训练”决定了模型能力的上限,无法通过“后训练”将万亿级别参数模型调到达到10万亿参数模型的能力水平。而预训练的决定因子就是高端算力芯片,它决定了参数规模和训练迭代速度。
科大讯飞董事长刘庆峰就坦言,目前各家顶尖大模型厂商,特别是美国的巨头,都在建超大规模算力平台。而国产算力目前确实面临阵痛期,导致在训练超长文本上下文中遇到了限制。
可见,算力差距就是中美模型之差的根源。
国产崛起
一家企业垄断全球高端AI训练芯片90%的市场份额——这助力英伟达保持着全球第一大市值公司的王座。其总市值一度超过全球第三大经济体德国2025年的GDP。
集邦咨询数据显示,2026年Q1全球GPU服务器市场,英伟达一家吃掉68%,AMD占据5%-6%,而国产GPU厂商整体不足4%。
凭借先发优势,超强的技术壁垒、高速互联、软件生态以及绑定台积电先进制程,英伟达独霸天下。在高端训练场景,英伟达GB300性能强于AMD MI325,也好于寒武纪思元690、摩尔线程MTT40,尤其在万亿参数大模型训练中,性能强于竞品30%以上。
出口禁令之下,黄仁勋此前已表示,英伟达在华市场份额(新增)已基本归零,仅剩存量市场。国产替代政策支持下,包括华为昇腾910、海光DCU深算2号、寒武纪思元370/590,以及摩尔、沐曦等企业相继涌现。
其中昇腾910是华为最强算力芯片,昇腾910B算力达到640TOPS(INT8),可媲美到英伟达A100芯片。
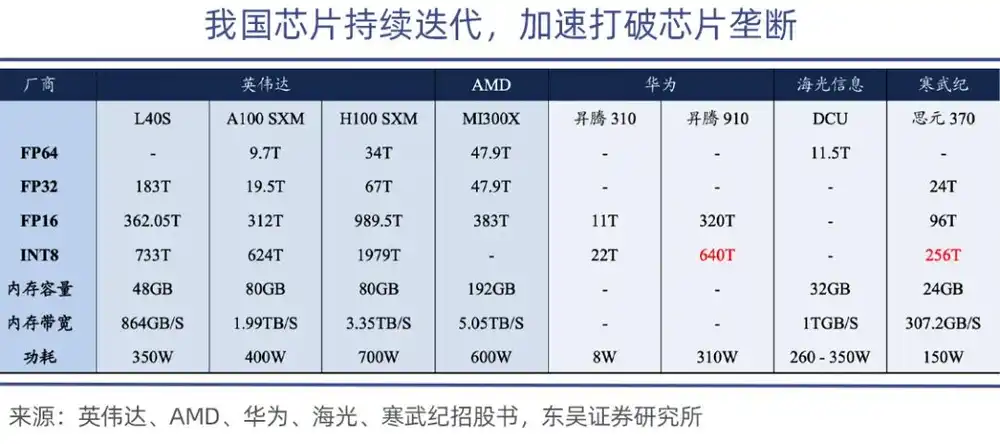
绝对性能层面,国产GPU虽仍有差距,但可先从推理与边缘场景入手,目前国产GPU基本满足国内政企通用推理需求,与英伟达中端产品差距缩小至15%-20%,具备替代可行性。
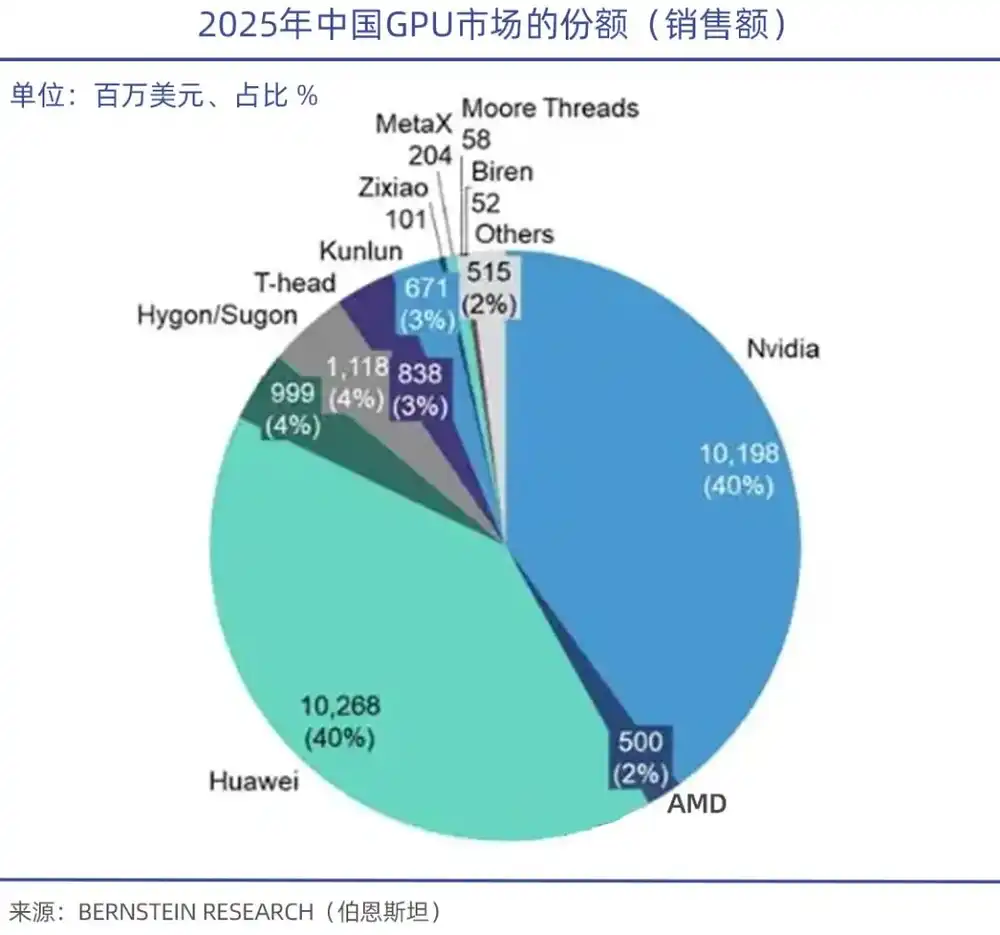
需要特别指出的是,算力性能固然重要,而其背后的技术软件生态才是国产GPU的软肋。正如CUDA才是铸造英伟达GPU帝国的根基,中国工程院院士郑纬民就指出,国产AI芯片核心问题是生态不够好,如果生态好,性能做到60%也有人用。
可以说,软件生态是GPU赛道最硬核的壁垒,在这方面英伟达的能力同样难以替代。
CUDA生态经过了十余年深耕,已经拥有超400万开发者、数十万开源模型、全品类第三方工具链,覆盖AI训练、推理、图形渲染、科学计算,生态壁垒强悍无二。
IDC数据显示,目前全球95%以上的AI模型基于CUDA生态开发。而国产GPU在依托政策支持下,需要和产业链进行长期协同,需要媒体舆论、资本市场给予足够的耐心。
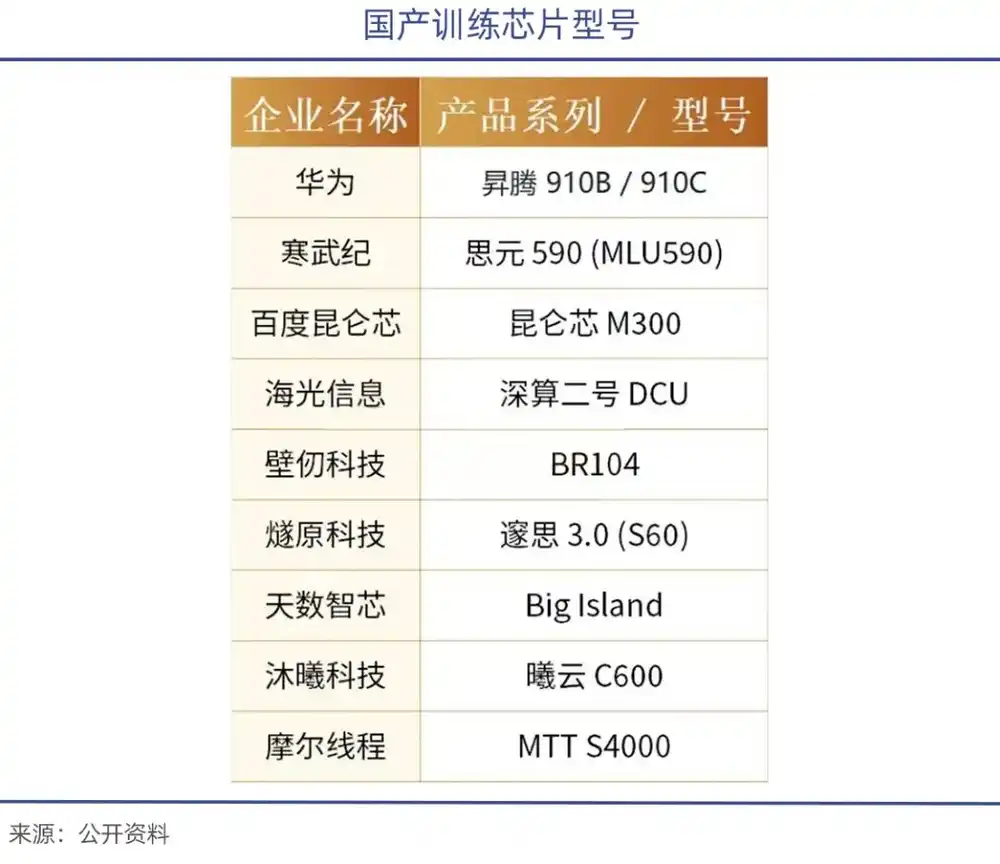
今年1月,智谱就联合华为开源新一代图像生成模型GLM-Image,该模型基于华为昇腾Atlas 800T A2设备与昇思MindSpore AI框架,完成从数据处理到模型训练的全流程闭环,是首个依托国产芯片实现全程训练的SOTA多模态模型;
摩尔线程还与北京智源人工智能研究院一起,基于MTT S5000智算集群与FlagOS-Robo框架,完成智源自研具身大脑模型RoboBrain 2.5的全流程训练。这一成果首次验证了,国产算力集群在具身智能大模型训练中的可用性。
可以看出,国产GPU在适配性和生态构建方面已经有所突破,并正从推理侧的“单点突破”,迈向训练侧的“逐步适配”,这已是一种长足进步。
总结
整体上看,在海外先进芯片进口受阻的背景下,不妨“中西结合”用两条腿来走路,同时重点扶持国内算力芯片,以满足迫切的市场需求。
需求的真实性毋庸置疑,“泡沫论”仍然存在,但声音并没有越来越大。全球市场对于AI建设的热情,已经超越了此前以往任何一个产业早期的发展历程。
今年以来,全球资本市场再度掀起超级AI周期,三星、sk海力士、博通、台积电股价屡创新高,国内市场上,以寒武纪等代表的硬科技也是涨势凶猛,光模块巨头中际旭创市值更是一度超过茅台。
回顾韩国半导体发展史,韩国以举国之力支持存储芯片产业,熬过至暗时刻,并最终击败日本,成为世界存储产业绝对王者。
无论存储芯片、手机芯片、乃至当下的AI芯片,中国都还处于追赶阶段,这绝非一朝一夕之功。但凭借巨大的市场、不断涌现的AI人才、庞大的资本实力,国产GPU已经开始展露出一定的适配性,能够解决很多AI企业的真实需要。
在这场关于国运的AI对弈中,中美两国既是对手,同时也有对方所需的技术、市场和资源。
本文来自微信公众号: 巨潮WAVE ,编辑:杨旭然,作者:谢泽锋,原文标题:《中美AI对弈之下的算力难题 | 巨潮》





