Người máy sinh học có mơ không? Nếu chúng mơ, chúng có mơ thấy cừu điện tử không?

Ảnh chụp màn hình phim "Blade Runner"
Vào năm 1968, khi tác giả Philip K. Dick của cuốn tiểu thuyết gốc cho bộ phim khoa học viễn tưởng "Blade Runner" gõ câu hỏi trừu tượng và đi trước thời đại này trên máy đánh chữ, có lẽ ông không ngờ rằng hơn nửa thế kỷ sau, các ông lớn công nghệ ở Thung lũng Silicon sẽ nghiêm túc đưa ra câu trả lời.
Có, chúng không chỉ có thể mơ thấy cừu điện tử, mà còn có thể hình ảnh hóa giấc mơ.
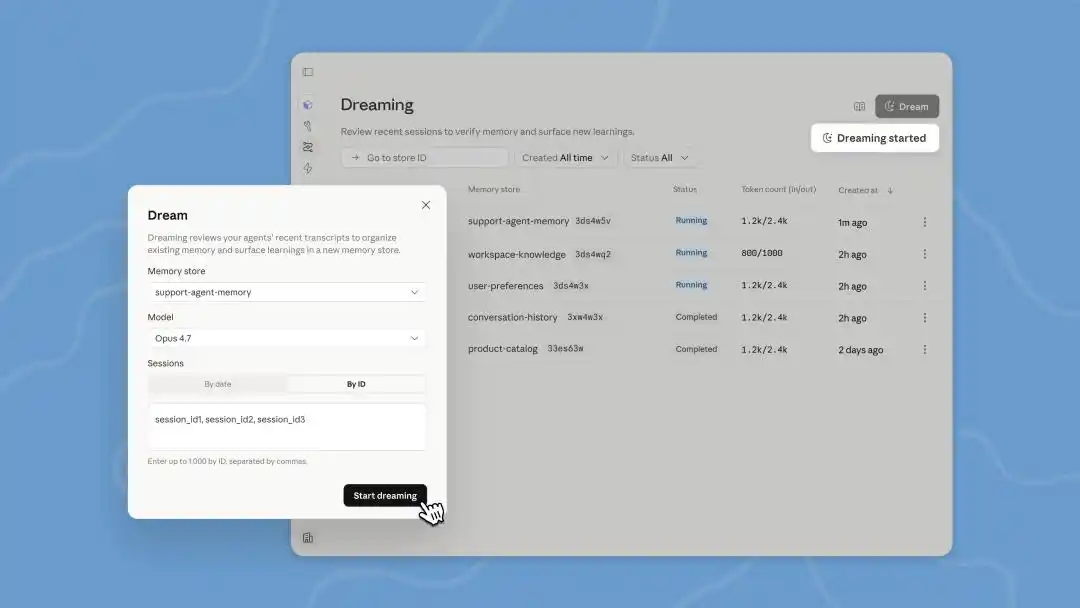
Hôm qua, tại hội nghị dành cho nhà phát triển ở San Francisco, Anthropic đã công bố một loạt tính năng mới cho nền tảng xây dựng trí tuệ nhân tạo Managed Agents: mở rộng bộ nhớ, xuất kết quả, hợp tác đa tác tử, và "mơ - Dreaming".
Theo cách nói của chính Anthropic, "bộ nhớ (memory) và giấc mơ (dreaming) cùng nhau tạo thành một hệ thống bộ nhớ agent vững chắc, có khả năng tự cải thiện".

Vừa là mơ, vừa là ký ức, những bạn không quá quan tâm đến lĩnh vực AI có lẽ sẽ đầy thắc mắc, những từ ngữ thuộc về con người này, từ khi nào có thể được áp dụng một cách trơn tru lên AI như vậy.
Ngay từ khi OpenAI ra mắt dòng o1 vào năm 2024, "một loạt mô hình AI được thiết kế để dành nhiều thời gian hơn để suy nghĩ trước khi phản hồi", từ "suy nghĩ" được dùng một cách cực kỳ tự nhiên, tự nhiên đến mức không ai dừng lại hỏi một câu: một chương trình dự đoán thống kê token tiếp theo, dựa vào đâu mà gọi là suy nghĩ?
Tiếp theo là reasoning (lập luận), memory (ký ức), reflection (phản tư), Imagining (tưởng tượng), lần lượt đưa những việc chỉ con người mới làm, lên sân khấu ra mắt sản phẩm.

Ảnh chụp màn hình phim "Paprika" bàn về giấc mơ
"Suy nghĩ" còn có thể giải thích là ẩn dụ, "ký ức" cũng tạm coi là mở rộng của thuật ngữ kỹ thuật, nhưng "mơ" thì thật sự hơi quá. Hàng nghìn năm văn sử triết chưa nghiên cứu rõ, công ty AI lại có thể thẳng thừng nói: Chúng tôi không chỉ làm ra cỗ máy biết suy nghĩ, mà còn làm ra cỗ máy biết mơ.
Mơ là gì, ngoài từ "mơ", không thể tìm thấy bất kỳ một thuật ngữ kỹ thuật nào khác để mô tả chính xác việc này sao?
AI mơ cũng phải trả tiền
Ngay từ sự kiện rò rỉ mã nguồn Claude Code, đã có cư dân mạng phát hiện Anthropic đang chuẩn bị một tính năng tên là Auto Dreaming. Lúc đó, mọi người đều nghĩ, lẽ nào AI cũng giống con người chúng ta, cần ngủ, cần nghỉ ngơi đủ, mới có thể tập trung hơn, thông minh hơn sao?
Nhưng chỉ cần hiểu nguyên lý hoạt động của AI Agent hiện tại, sẽ phát hiện cái gọi là "mơ" về bản chất chỉ là một lần xử lý hàng loạt nhật ký (log) ngoại tuyến tự động.
AI Agent hiện nay giỏi hoàn thành một số nhiệm vụ phức tạp có chuỗi dài. Ví dụ "giúp tôi nghiên cứu báo cáo tài chính mới nhất của năm đối thủ cạnh tranh này, và tổng hợp thành bảng". Trong quá trình này, Agent cần nhảy giữa các trang web khác nhau, đọc nhiều tài liệu, gọi các công cụ khác nhau, thậm chí có thể vấp phải cơ chế chống thu thập dữ liệu và thử lại.
Khi chuỗi nhiệm vụ trực tuyến phức tạp dài dằng dặc này kết thúc, hậu trường của Agent sẽ để lại một lượng lớn nhật ký chạy.
Hình ảnh được tạo bởi AI
Tính năng "mơ" của Anthropic, chính là để Agent trong thời gian nhàn rỗi, sắp xếp lại những bản ghi lịch sử này. Nó sẽ tìm kiếm mô hình từ đó, ví dụ phát hiện "mỗi lần gặp cửa sổ bật lên kiểu này, nhấp vào góc trên bên phải là có thể đóng", từ đó tối ưu hóa đường dẫn thao tác cho lần sau.
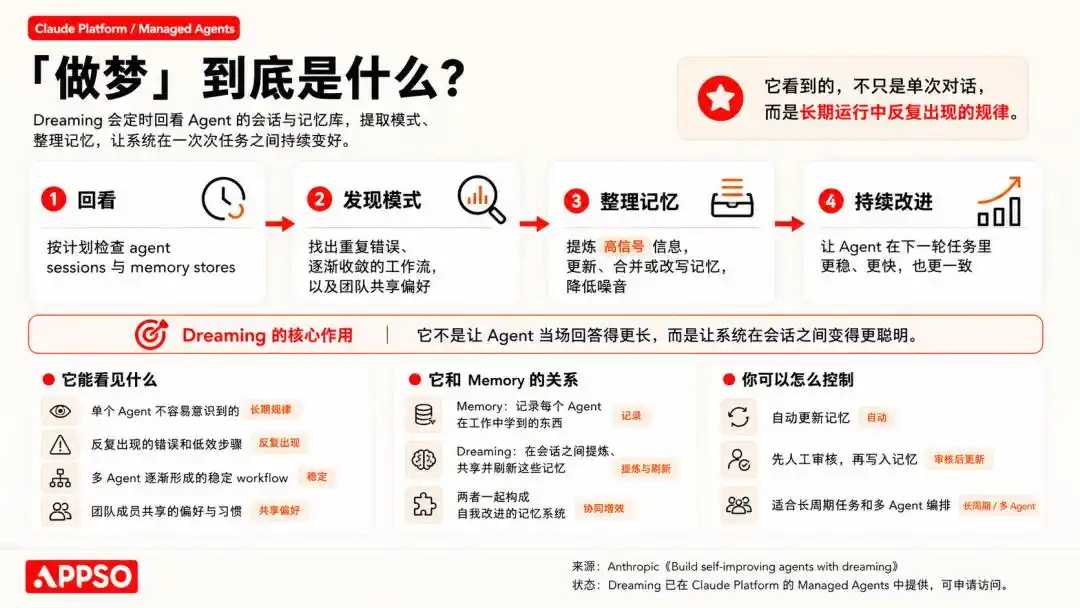
"Ký ức" chịu trách nhiệm thu nhận những thứ đã học trong khi làm việc, còn "giấc mơ" thì tinh luyện những ký ức này giữa các phiên hội thoại, và chia sẻ chúng giữa các Agent khác nhau.
Nói thẳng ra, đây là một cơ chế học tăng cường và tự sửa lỗi dựa trên dữ liệu lịch sử.

Giới thiệu về Dream: https://platform.claude.com/docs/en/managed-agents/dreams
Dreams trong Managed Agents được cập nhật tại hội nghị nhà phát triển lần này, là một tác vụ xử lý hậu trường, chúng ta cần kích hoạt thủ công. Claude một lần có thể đọc tối đa lịch sử hội thoại của 100 phiên, sau đó tạo ra một bộ memory hoàn toàn mới, để chúng ta xem xét rồi quyết định có nên dùng hay không.
Còn AutoDream đã được âm thầm đưa lên trước đó trong Claude Code, là mỗi lần nói chuyện xong một vòng với Agent, Claude Code sẽ kiểm tra hậu trường "có nên mơ không", mặc định là 24 giờ chạy một lần.
Tính năng tương tự như mơ, Hermes Agent cũng có. Hermes Agent chủ đạo là có thể tự học và tiến hóa, nó không chỉ hỗ trợ tự động tổng kết kinh nghiệm từ những nhiệm vụ trong quá khứ, đặt vào tệp ký ức.

Một tính năng tên là Curator, còn có thể tự động sắp xếp những hướng dẫn thao tác được tinh luyện này thành Skill.
Những Skill này sẽ được chấm điểm, trùng lặp thì hợp nhất, lâu không dùng tự động lưu trữ, thậm chí còn có vòng đời như active, stale, archived. Chúng ta còn có thể ghim (Pin) những Skill quan trọng, không để hệ thống tự động xóa.
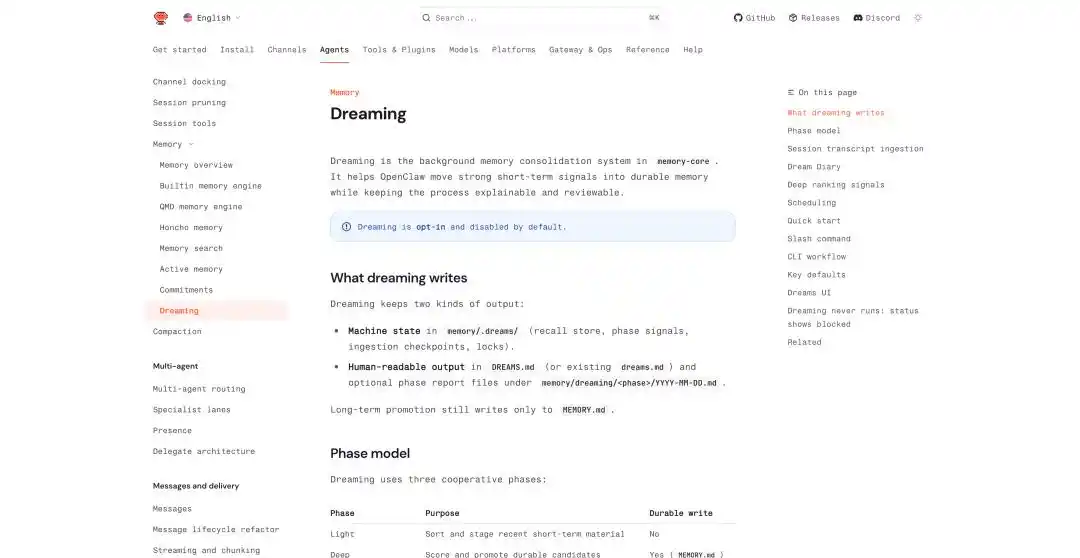
OpenClaw trong vài lần cập nhật gần đây, cũng đã thêm các cơ chế liên quan, như bộ nhớ bền vững xuyên phiên hội thoại, lập lịch tác vụ định kỳ, thực thi cách ly sub-agent, và tính năng mơ trực tiếp gọi là Dreaming.
Dreaming của OpenClaw: https://docs.openclaw.ai/concepts/dreaming
Trong cơ chế mơ của OpenClaw, nó tóm tắt hành trình của giấc mơ thành ba giai đoạn, light, REM, deep. Hai giai đoạn đầu chịu trách nhiệm sắp xếp, phản tư và quy nạp chủ đề, deep mới thực sự ghi nội dung vào bộ nhớ dài hạn MEMORY.md.
Việc củng cố ở giai đoạn ngủ sâu, sẽ do 6 tín hiệu có trọng số quyết định, có cần ghi vào bộ nhớ dài hạn hay không. Sáu tín hiệu này bao gồm tần suất, mức độ liên quan, tính đa dạng của truy vấn, tính kịp thời, mức độ lặp lại xuyên ngày, độ phong phú khái niệm.

Hình ảnh được tạo bởi AI
Ghi vào bộ nhớ dài hạn, sẽ tạo ra hai tệp, một tệp trạng thái hướng đến máy, đặt trong memory/.dreams/; tệp còn lại là bản ghi có thể đọc được cho người dùng, ghi vào DREAMS.md và báo cáo được tạo theo từng giai đoạn.
Ngoài ra, Dreaming có thể tự động chạy định kỳ, mặc định mỗi ngày chạy một quy trình đầy đủ vào 3 giờ sáng, thứ tự là light → REM → deep.
Ngoài đầu ra của việc mơ, OpenClaw còn duy trì một tài liệu gọi là Dream Diary, hệ thống sẽ tự động tạo ra một "nhật ký giấc mơ", ghi lại quá trình sắp xếp ký ức bằng cách thức tường thuật, nhấn mạnh tính có thể giải thích, có thể xem xét, thay vì ghi vào kho dữ liệu hộp đen.
Trong khoa học thần kinh có một hiểu biết rất kinh điển: thông tin con người thu nhận vào ban ngày, trước tiên đi vào hệ thống thiên về lưu trữ tạm thời hơn; còn trong quá trình ngủ, não bộ sẽ phát lại, củng cố và dọn dẹp những thông tin này, giữ lại cái quan trọng, vứt bỏ cái vô nghĩa.
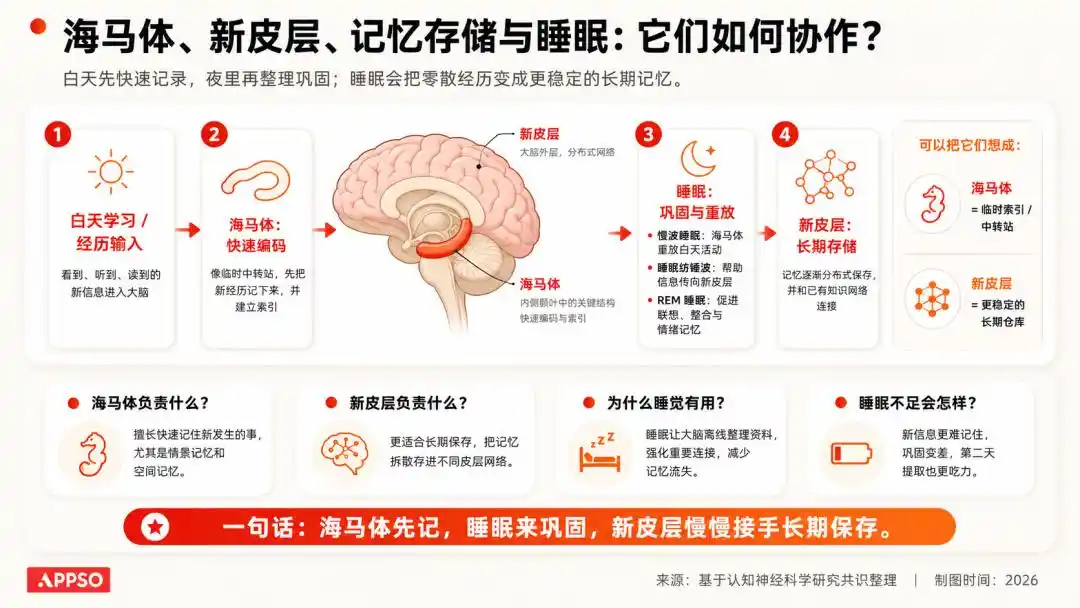
Hình ảnh được tạo bởi AI
Chúng ta sẽ không nhớ màu sắc của từng chiếc xe trên đường đi làm hôm qua, nhưng sẽ nhớ cách đến công ty.
Những giấc mơ này, nghe qua quả thật giống chúng ta mơ, nếu nhất định phải tìm điểm khác biệt, đại khái là khi Claude mơ, vẫn đang tiêu hao Token của chúng ta.
Nhưng Anthropic, OpenClaw đều không chọn gọi nó là "tối ưu hóa dựa trên phiên (session-based optimization)", hay là "điều chỉnh sau nhiệm vụ (post-task tuning)" v.v., những cái tên thiên về kỹ thuật.
Rốt cuộc, khi biến những cái tên phức tạp đó, trực tiếp thành "mơ", điều chúng ta cảm nhận được không còn là chức năng phần mềm, mà giống như một "sinh mệnh sống có hoạt động nội tâm".
Ký ức của AI, là ngữ cảnh vụn vặt
Đã đề cập đến "mơ", thì không thể không nhắc đến điều kiện tiên quyết của nó, ký ức (Memory).
Trong khoảng thời gian vừa qua, từ hot nhất trong giới AI từ kỹ thuật chỉ dẫn (prompt engineering), biến thành kỹ thuật ngữ cảnh (context engineering), kỹ thuật Skill, kỹ thuật Harness, nhưng dù thay đổi thế nào, hiện nay có giá trị nhất vẫn là kỹ thuật ngữ cảnh.
Chỉ dẫn hệ thống, đầu vào người dùng, hội thoại ngắn hạn, ký ức dài hạn, tài liệu được truy xuất trở về, đầu ra của việc gọi công cụ và Skill, trạng thái người dùng hiện tại, những tầng này chồng lên nhau, chính là "ngữ cảnh" mà agent thực sự đang dùng.
Để Agent có thể nhớ nhiều hơn, ghi lại nội dung hữu ích hơn, vẫn là bài toán khó trong suốt thời gian dài vừa qua.
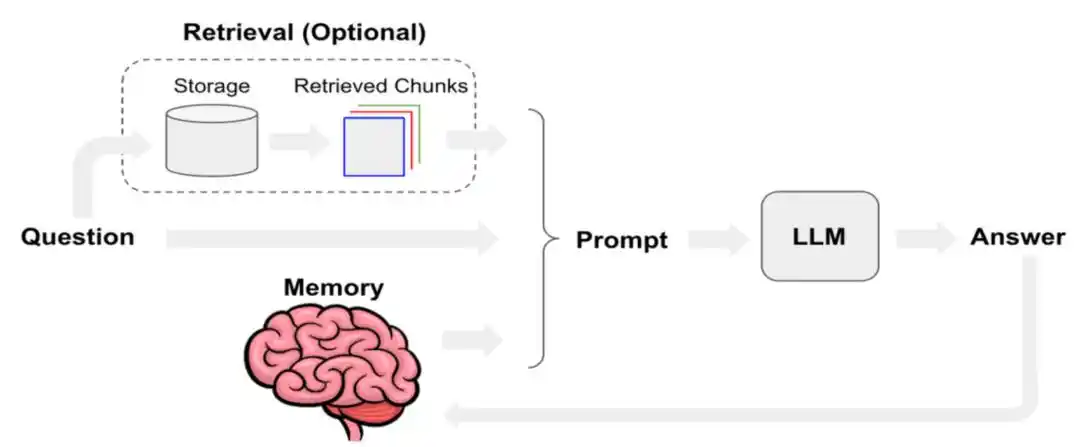
Manus năm ngoái đã đăng một bài blog kỹ thuật, chuyên nói về cách Manus tối ưu hóa kỹ thuật ngữ cảnh. Trong đó đề cập đến việc định nghĩa tỷ lệ trúng bộ đệm KV-Cache, là một trong những chỉ số đơn lẻ quan trọng nhất của AI Agent trong môi trường sản xuất. Đồng thời ở tầng gọi công cụ, ưu tiên làm "che phủ" thay vì "loại bỏ"; cũng như phương pháp lấy hệ thống tệp làm ngữ cảnh tối thượng.
Để hiểu cái gọi là KV Cache (bộ đệm khóa-giá trị), chúng ta có thể tưởng tượng mô hình ngôn ngữ lớn là một bệnh nhân cực kỳ ép buộc chỉ có thể đọc một chữ mỗi lần.
Khi nó xử lý một câu, nó sẽ tính toán cho mỗi Token được tạo ra một vectơ Key (khóa) và một vectơ Value (giá trị). Để không phải tính lại từ đầu mỗi lần, nó sẽ lưu trữ các cặp (K, V) khóa-giá trị này, đây chính là KV Cache.
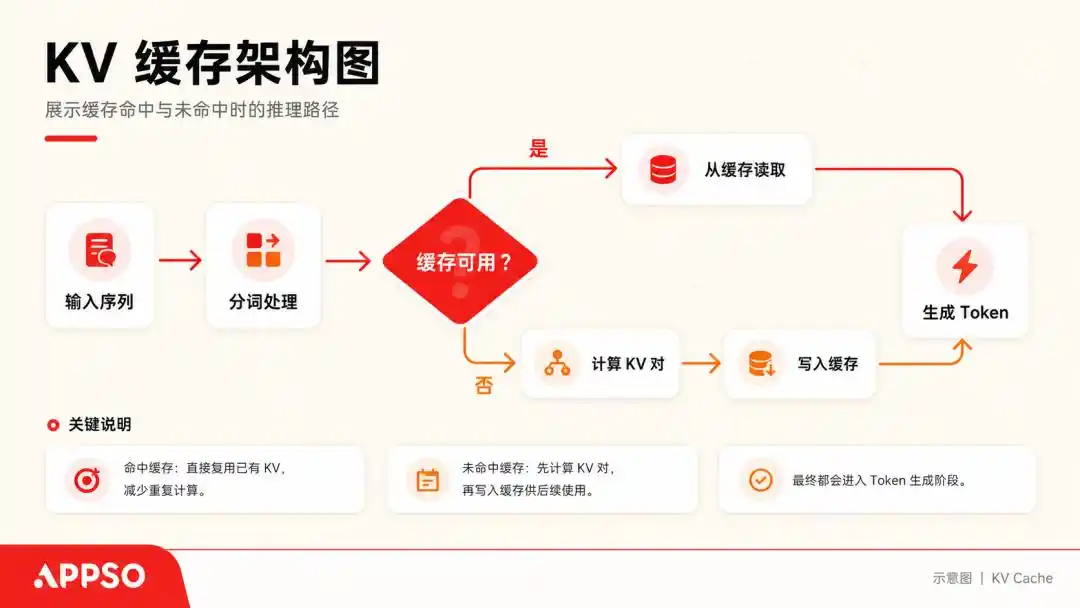
KV Cache (bộ đệm khóa-giá trị) là công nghệ tăng tốc cấp thấp dùng "đổi không gian lấy thời gian" khi mô hình ngôn ngữ lớn tạo văn bản. Bộ đệm khiến mô hình khi dự đoán từ tiếp theo, không cần tính toán lại tất cả các từ phía trước. Hình ảnh được tạo bởi AI.
Chỉ cần hội thoại tiếp tục, KV Cache sẽ không ngừng lưu lại. Thông thường, khi đối mặt với mô hình lớn có ngữ cảnh động dễ 128k, một mô hình tham số 70B chạy hết ngữ cảnh 128k, chỉ riêng KV Cache đã có thể nuốt chửng 64 GB bộ nhớ hiển thị.
Đây cũng là lý do tại sao cửa sổ ngữ cảnh của hầu hết các mô hình, hiện nhiều nhất đều là cấp triệu.
Hôm qua, một công ty mới nhận được 29 triệu USD vòng hạt giống Subquadratic, đã đăng trên X mô hình mới SubQ, chủ đạo là ngữ cảnh dài hơn.

SubQ tuyên bố có thể hỗ trợ cửa sổ ngữ cảnh tối đa 12 triệu token, đây là cửa sổ ngữ cảnh lớn nhất trong tất cả các mô hình lớn hiện nay.
Mặc dù chưa có bài báo kỹ thuật hoặc tài liệu mô tả mô hình, video giới thiệu có đề cập, lộ trình công nghệ cốt lõi của SubQ là chuyển từ "chú ý dày đặc" của Transformer truyền thống, sang kiến trúc "mở rộng thứ cấp/ tuyến tính" với chú ý thưa thớt. Kiến trúc mới hy vọng có thể giải quyết vấn đề ngữ cảnh càng dài, chi phí tính toán càng bùng nổ.

Kết quả thử nghiệm đưa ra cũng khá tích cực, ở 1 triệu token, tốc độ tăng hơn 50 lần, chi phí giảm hơn 50 lần; ở 12 triệu token, nhu cầu tính toán so với mô hình tiên phong có thể giảm gần 1000 lần.
Còn trên chuẩn dài RULER 128K, Subquadratic cho biết SubQ với độ chính xác 95%, chi phí 8 USD, so với Claude Opus độ chính xác 94%, chi phí khoảng 2600 USD, chi phí giảm khoảng 300 lần.
Hoặc là mở rộng cửa sổ ngữ cảnh, hoặc là để mô hình học cách mơ, tự vứt bỏ một số thứ.
Đây cũng là lý do tại sao các sản phẩm Agent như Anthropic, bây giờ buộc phải ra mắt Dreaming. Trong tình trạng cửa sổ ngữ cảnh bị hạn chế, AI thông minh hơn không thể chỉ dựa vào việc nhét thêm nội dung, mà cần có mục tiêu rõ ràng.
Thừa nhận máy móc chỉ là máy móc, khó hơn tưởng tượng
Hiểu được cơ chế mơ và ghi nhớ của AI, có lẽ chúng ta có thể biết được mối quan hệ giữa nó và hoạt động của con người.
Nhưng đặt tất cả những từ mà các công ty AI tạo ra dùng cho máy móc này lại với nhau, thinking suy nghĩ của OpenAI, memory ký ức và hallucination ảo giác phổ biến trong ngành, dreaming mơ lần này của Anthropic, cùng với đức hạnh và trí tuệ trong hiến pháp của Anthropic.
Chúng ta có thể thấy, công ty AI không chỉ đang bán sản phẩm, họ đang phân phối lại quyền sở hữu từ vựng trong khái niệm "con người". Mỗi lần chiếm dụng một từ, ranh giới giữa máy móc và con người lại mờ đi một tấc.

Ngôn ngữ sẽ định hình kỳ vọng, kỳ vọng định hình mức độ khoan dung, mức độ khoan dung quyết định chúng ta sẵn sàng giao bao nhiêu thứ cho nó. Đây là một chuỗi dài, nhưng điểm khởi đầu chính là những từ vô hại trên sân khấu ra mắt.
Một tầng ảnh hưởng tinh vi hơn là phân phối trách nhiệm. Khi công cụ được mô tả là một thực thể có "suy nghĩ", "ký ức", "giá trị quan", khi nó gặp sự cố, chúng ta sẽ tự nhiên coi nó như một "chủ thể hành vi" độc lập để truy cứu trách nhiệm, là AI này cần được "giáo dục", "gỡ lỗi", "hiệu chỉnh".
Nhưng thực sự nên bị chất vấn, là công ty đã triển khai chương trình này vào quy trình làm việc của chúng ta, và đội ngũ sản phẩm đã viết ra từ "dreaming". Đổi từ, người ngồi ở "ghế bị cáo" cũng thay đổi.
Và chúng ta nhìn thấy một cỗ máy biết "suy nghĩ", biết "ghi nhớ", giờ lại biết "mơ", cũng bắt đầu tin một cách vô thức rằng bên trong có cái gì đó. Bởi vì thừa nhận đây chỉ là một cỗ máy, cảm giác trải nghiệm "tôi đang nói chuyện với một tồn tại biết suy nghĩ" đó sẽ tan biến, quay trở lại là mối quan hệ công cụ lạnh lùng.

Giới thiệu tính năng mơ mộng ban ngày | Hình ảnh được tạo bởi AI
Tôi đã nghĩ đến, Dreaming mơ là xử lý nội dung trong quá khứ, tiếp theo công ty AI sẽ còn cho ra mắt Daydreaming, mơ mộng ban ngày, dùng để diễn tập trước tương lai.
Giới thiệu là, mơ mộng ban ngày hoặc mơ mộng, có thể để Agent ở trạng thái hoạt động, dùng một phần nhỏ sức tính toán nhàn rỗi, kết hợp với dự án đang tiến hành hiện tại, đồng thời thực hiện sinh thành thăm dò, chuẩn bị cho nhiệm vụ có thể xảy ra trong tương lai.
Bài viết này đến từ tài khoản công chúng WeChat "APPSO", tác giả: APPSO phát hiện sản phẩm ngày mai





