Tác giả: Yanhua
Tổng hợp từ: Podwise
Gần đây OpenClaw đang bùng nổ, mọi nơi đều thảo luận. Nhưng thành thật mà nói, phần lớn nội dung đều nói về lý thuyết, kiến trúc và tầm nhìn. Dùng thứ này thực sự để làm gì? Làm thế nào để triển khai trong công việc hàng ngày? Không nhiều người nói rõ.
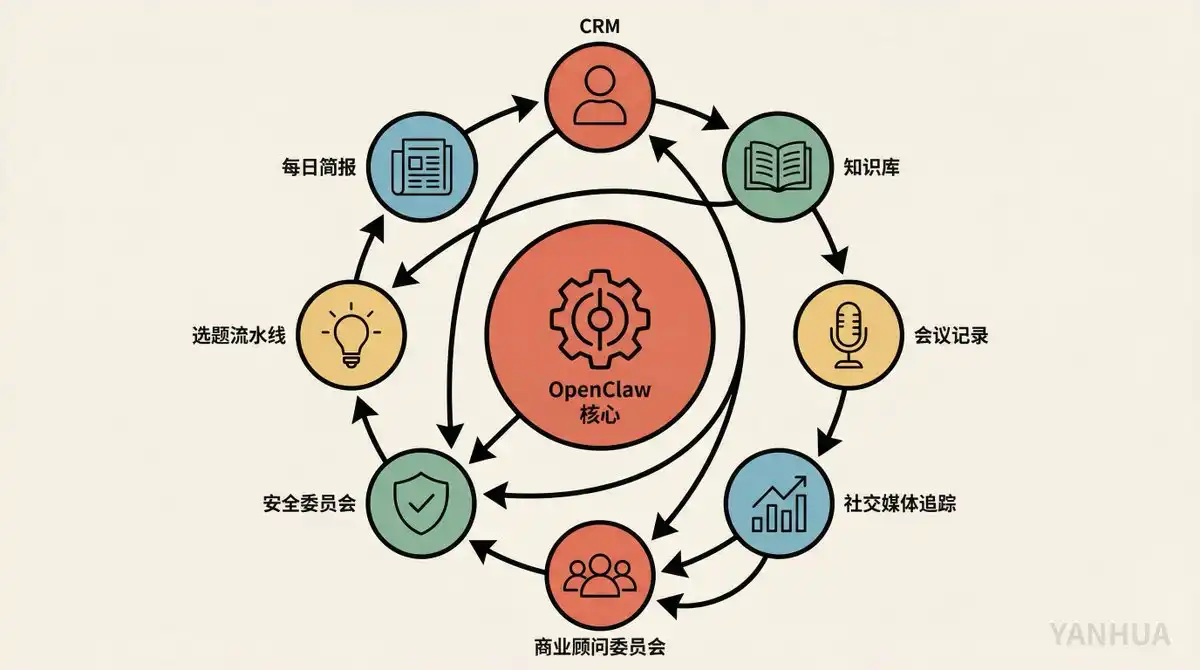
Matthew Berman gần đây đã ra một video, trải ra tất cả các trường hợp sử dụng mà anh ấy dùng OpenClaw để xây dựng. Không nói khái niệm, toàn là thực hành. CRM, kho kiến thức, hội đồng cố vấn kinh doanh, rà soát an ninh, theo dõi mạng xã hội, dây chuyền chọn đề tài video, báo cáo hàng ngày, nhật ký thực phẩm... Một người, một máy MacBook, làm công việc của một đội hậu cần của một công ty nhỏ.
Tôi sẽ phân tích những trường hợp sử dụng cốt lõi nhất của anh ấy. Không tâng bốc, không chê bai, từng cái một: mỗi trường hợp là gì, chạy như thế nào, điểm tốt ở đâu.
Trường hợp sử dụng 1: CRM ngôn ngữ tự nhiên, từ 0 đến dùng được trong 30 phút
Đây là trường hợp sử dụng đầu tiên Berman trình diễn, và cũng là trực quan nhất.
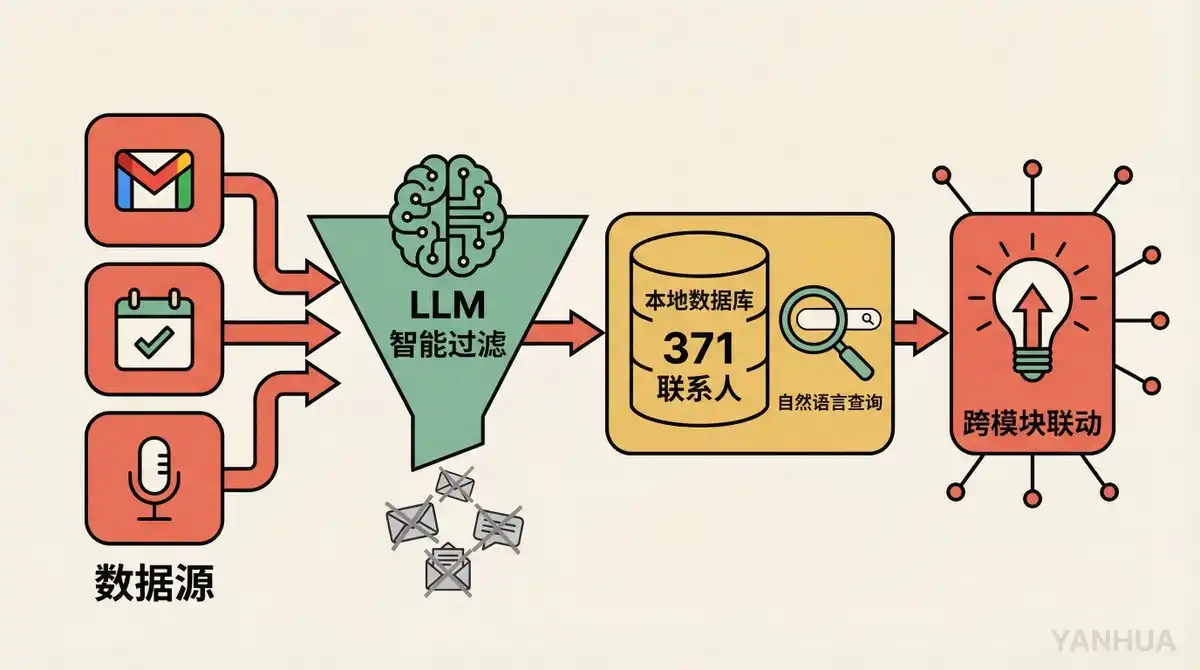
Quá trình xây dựng: Anh ấy dùng ngôn ngữ tự nhiên nói với OpenClaw, "Hãy giúp tôi xây dựng một CRM, trích xuất dữ liệu từ Gmail, Google Calendar và Fathom, lọc bỏ email marketing và email chào hàng lạnh, chỉ giữ lại những cuộc trò chuyện và danh bạ có giá trị." Không viết một dòng code. Chạy được sau 30 phút.
Thu thập dữ liệu: Hệ thống quét email mỗi 30 phút, kiểm tra Fathom (công cụ ghi chép cuộc họp AI) mỗi 5 phút trong giờ làm việc. Tất cả dữ liệu trước khi lưu vào, đều được một LLM đánh giá: email này có đáng lưu không? Danh bạ này có quan trọng không?
Khả năng cốt lõi:
-
371 danh bạ, tất cả đều có thể truy vấn bằng ngôn ngữ tự nhiên. "Lần trước tôi nói chuyện với John về cái gì?" "Ai là người cuối cùng liên hệ với tôi từ công ty X?"
-
Điểm đánh giá sức khỏe mối quan hệ, tự động đánh dấu những người lâu không liên lạc
-
Phát hiện danh bạ trùng lặp và đề xuất hợp nhất
-
Tìm kiếm nhúng vector, hỗ trợ khớp mờ ở cấp độ ngữ nghĩa
Chi tiết ấn tượng nhất: Khi Berman ở trong các ngữ cảnh khác (như muốn chọn đề tài video), CRM sẽ chủ động xen vào: "Bạn đã từng nói chuyện với một nhà tài trợ về chủ đề tương tự, có lẽ họ sẵn sàng tài trợ cho tập này." Hệ thống liên kết xuyên module, không chỉ thụ động lưu dữ liệu, mà còn chủ động tạo kết nối.
Nguyên văn của Berman: "Nếu tôi có thể xây một CRM tùy chỉnh hoàn toàn trong 30 phút, rồi dành một hai giờ để tối ưu hóa, thì tại sao tôi lại phải trả phí cho công ty CRM?"
Trường hợp sử dụng 2: Tự động theo dõi các mục hành động trong cuộc họp
Trường hợp này phối hợp chặt chẽ với CRM, nhưng đáng để nói riêng.
Quy trình làm việc: Cuộc họp kết thúc → Fathom ghi chép toàn văn → OpenClaw khớp danh bạ CRM → Trích xuất mục hành động → Gửi Telegram cho Berman phê duyệt → Những mục được phê duyệt tự động vào Todoist
Một số thiết kế then chốt:
-
Phân biệt mục hành động "của tôi" và "của đối phương". Những thứ đối phương hứa sẽ gửi cho bạn, hệ thống đánh dấu là "waiting on", tự động theo dõi xem đối phương có thực hiện không.
-
Tự học lọc. Nếu Berman từ chối một mục hành động ("Cái này không phải nhiệm vụ của tôi"), hệ thống sẽ học lý do và cập nhật quy tắc trích xuất. Lần sau tình huống tương tự sẽ không bắt nữa.
-
Tự động kiểm tra tình trạng hoàn thành 3 lần mỗi ngày. Ví dụ bạn nói trong cuộc họp "Hôm nay tôi sẽ gửi email đi", hệ thống sẽ kiểm tra xem bạn có thực sự gửi không, nếu gửi rồi thì tự động đánh dấu.
-
Tự động lưu trữ sau 14 ngày. Những mục quá hạn chưa hoàn thành tự động dọn dẹp, giữ danh sách sạch sẽ.
Giá trị của thứ này không nằm ở một chức năng đơn lẻ nào, mà ở chỗ nó tự động hóa hoàn toàn khâu "theo sau cuộc họp" - khâu dễ bị bỏ dở nhất.
Trường hợp sử dụng 3: Kho kiến thức cá nhân, chỉ cần ném một liên kết vào
Berman lâu nay có một điểm đau: thấy nội dung hay, lưu lại, rồi không bao giờ tìm thấy nữa.
Giải pháp của anh ấy cực kỳ đơn giản: Tất cả liên kết ném vào Telegram, phần còn lại để OpenClaw lo.
Hệ thống sẽ tự xử lý các loại nội dung này:
-
Bài viết: Trực tiếp thu thập toàn văn, đối với trang web có paywall thì dùng automation trình duyệt đăng nhập rồi trích xuất
-
Video YouTube: Thu thập phụ đề/văn bản ghi chép
-
Bài đăng X: Không chỉ thu thập một bài, sẽ tự động theo dõi cả chuỗi bài, các bài viết liên kết ngoài cũng được thu thập
-
PDF: Trực tiếp phân tích văn bản
Tất cả nội dung được nhúng vector hóa, lưu vào SQLite cục bộ. Sau đó có thể tìm kiếm bằng ngôn ngữ tự nhiên: "Cho tôi xem tất cả bài viết về OpenAI", một phát truy xuất.
Cộng thêm hợp tác nhóm: Mỗi nội dung nhập kho tự động đồng bộ sang Slack dưới dạng "Matt muốn các bạn xem cái này". Đội ngũ biết đây là thứ sếp tự đọc, không phải AI tuỳ tiện đẩy.
Điểm then chốt của trường hợp này không phải là công nghệ phức tạp, mà là ngưỡng sử dụng cực thấp. Không cần gắn thẻ, không cần phân loại, không cần sắp xếp. Ném vào là xong, AI làm phần còn lại cho bạn.
Trường hợp sử dụng 4: Hội đồng cố vấn kinh doanh, 8 chuyên gia mỗi tối giúp bạn họp
Cá nhân tôi nghĩ đây là trường hợp sử dụng điên rồ nhất toàn bộ video.
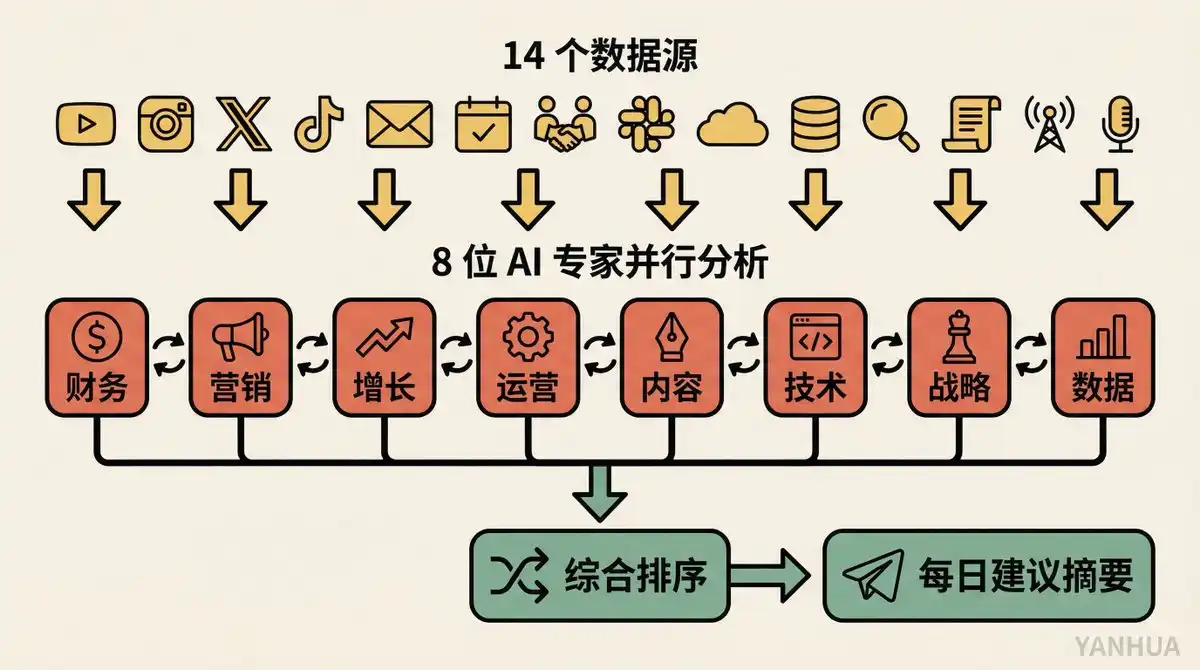
Dữ liệu đầu vào: 14 nguồn dữ liệu kinh doanh. Phân tích YouTube, tương tác mỗi bài Instagram, phân tích X, dữ liệu TikTok, chiến dịch email, ghi chép cuộc họp, tình trạng sức khỏe task Cron, tin nhắn Slack... Về cơ bản bao quát mọi khía cạnh nghiệp vụ của anh ấy.
Quy trình phân tích: 8 vai trò chuyên gia AI (tài chính, marketing, tăng trưởng, vận hành, v.v.), mỗi vai trò phân tích độc lập toàn bộ dữ liệu, chạy song song. Sau khi phân tích xong, chúng thảo luận phát hiện với nhau, tổng hợp bất đồng, rồi hợp thành một danh sách đề xuất được sắp xếp theo mức độ ưu tiên.
Cách thức giao nhận: Tự động chạy mỗi sáng sớm, kết quả gửi đến Telegram dưới dạng tóm tắt đánh số. Berman thức dậy liếc qua, có thể hỏi sâu bất kỳ điều nào: "Nói rõ hơn về điều số 3."
Tính gợi mở của trường hợp này nằm ở chế độ hợp tác đa Agent. Không phải một AI đưa ra đề xuất cho bạn, mà là một nhóm AI tranh luận với nhau rồi mới đưa ra đề xuất. Giống như một hội đồng quản trị thực sự, tài chính nói tiết kiệm tiền, marketing nói tiêu tiền, cuối cùng thỏa hiệp ra một phương án thực tế.
Trường hợp sử dụng 5: Ủy ban an ninh, AI mỗi tối rà soát AI
Kiến trúc tương tự Cố vấn kinh doanh, nhưng hướng hoàn toàn khác.
Thời gian chạy: 3:30 sáng mỗi tối (tránh khung giờ task khác, tránh xung đột hạn ngạch API Anthropic).
Đội ngũ rà soát: Chuyên gia an ninh bốn góc độ. Góc nhìn tấn công, góc nhìn phòng thủ, góc nhìn quyền riêng tư dữ liệu, góc nhìn tính xác thực thao tác.
Phạm vi rà soát: Toàn bộ codebase, lịch sử commit Git, log chạy, log lỗi, dữ liệu lưu trữ. Không phải quét quy tắc tĩnh, mà là để AI thực sự đọc code và hiểu logic.
Đầu ra: Opus 4.6 tổng hợp tất cả phát hiện, đánh số rồi gửi đến Telegram. Vấn đề then chốt cảnh báo ngay lập tức. Berman có thể trực tiếp trả lời "fix it", hệ thống tự sửa.
Tự tiến hóa: Kinh nghiệm sau mỗi lần sửa được ghi nhớ, quy tắc rà soát liên tục lặp. Một số đêm không có đề xuất mới, vì hệ thống xác nhận trạng thái hiện tại là an toàn.
Điểm tuyệt nhất của trường hợp này là dùng AI để rà soát chính bản thân AI. Berman rất thẳng thắn: Phòng chống prompt injection không bao giờ có thể hoàn hảo. Nhưng thay vì giả vờ rủi ro không tồn tại, hãy để hệ thống tự kiểm tra sức khỏe mỗi ngày một lần.
Trường hợp sử dụng 6: Theo dõi mạng xã hội + Báo cáo hàng ngày
Phạm vi theo dõi: Bốn nền tảng YouTube, Instagram, X, TikTok. Mỗi ngày tự động lấy snapshot, lưu vào cơ sở dữ liệu SQLite.
Chiều dữ liệu: YouTube theo dõi theo video: lượt xem, thời gian xem, tỷ lệ tương tác; các nền tảng khác theo dõi dữ liệu hiệu suất cấp bài đăng.
Hai mục đích:
-
Báo cáo hàng ngày. Mỗi sáng gửi đến Telegram, báo cho anh ấy biết hôm qua nội dung nào tốt, nội dung nào không
-
Cho Hội đồng cố vấn kinh doanh. Dữ liệu mạng xã hội là một trong 14 nguồn dữ liệu, trực tiếp tham gia phân tích nghiệp vụ mỗi tối
Ở đây thể hiện hiệu ứng bánh xe quay của toàn hệ thống: Module theo dõi mạng xã hội không chạy đơn lẻ, dữ liệu nó tạo ra đồng thời phục vụ hai trường hợp sử dụng downstream là báo cáo và hội đồng cố vấn.
Trường hợp sử dụng 7: Dây chuyền chọn đề tài video, từ một câu nói đến thẻ Asana
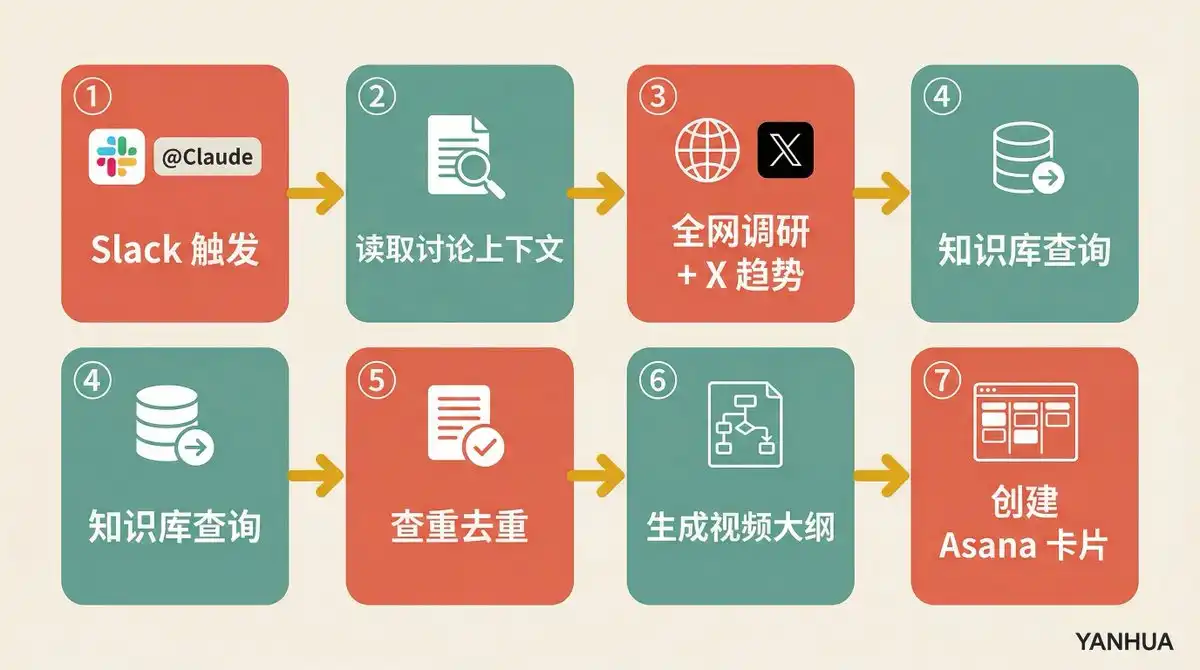
Cách kích hoạt: Trong thảo luận Slack, bất kỳ ai trả lời bài đăng "@Claude, đây là một ý tưởng video".
Quy trình tự động:
-
Đọc toàn bộ ngữ cảnh chuỗi thảo luận Slack
-
Tìm kiếm toàn mạng + Nghiên cứu xu hướng X
-
Truy vấn kho kiến thức, xem có tư liệu đã lưu liên quan không
-
Kiểm tra trùng lặp, xem có trùng với đề tài đã có không
-
Tạo dàn ý video hoàn chỉnh: đề xuất tiêu đề, đề xuất ảnh thu nhỏ, hook mở đầu, khung quy trình video
-
Đánh giá "Đề tài này có đáng làm không"
-
Tạo thẻ dự án trong Asana, đính kèm tất cả tài liệu nghiên cứu và liên kết
Berman trong video đã trình diễn một case thực tế: Tin về bản phát hành Quen 3.5 được chia sẻ lên Slack, có người đánh dấu là ý tưởng video, hệ thống tự động tạo gói đề tài hoàn chỉnh, bao gồm thảo luận của các KOL khác nhau trên Twitter, phản ứng của cộng đồng mã nguồn mở, và góc độ video đề xuất.
Giá trị của trường hợp này: Nén khoảng cách từ "bắt lấy cảm hứng" đến "phương án khả thi" xuống gần bằng không.
Trường hợp sử dụng 8: Hệ thống trí nhớ, để AI càng dùng càng hiểu bạn
Trải nghiệm dùng ChatGPT của đa số mọi người là: Mỗi cuộc trò chuyện đều như lần đầu gặp mặt. OpenClaw của Berman thì không.
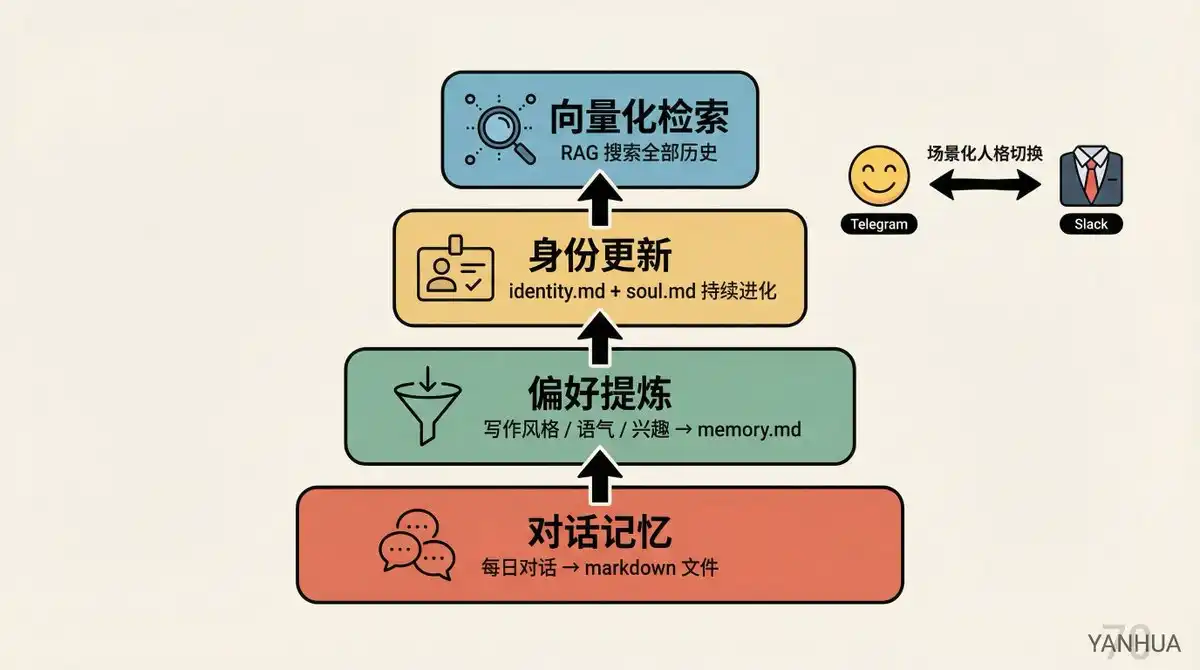
Cấp độ trí nhớ:
-
Trí nhớ hội thoại: Cuộc trò chuyện hàng ngày tự động lưu thành file markdown
-
Tinh luyện sở thích: Từ hội thoại trích xuất sở thích viết lách, phong cách ngữ khí, mối quan tâm, theo dõi cổ phiếu, quy tắc phân loại email, v.v., lưu vào memory.md
-
Cập nhật danh tính: Mỗi lần bắt đầu hội thoại mới, hệ thống đọc file trí nhớ, cập nhật identity.md và soul.md
-
Truy xuất vector hóa: Tất cả file trí nhớ được vector hóa, hỗ trợ tìm kiếm RAG
Chuyển đổi nhân cách theo ngữ cảnh: Berman cấu hình hai tính cách cho AI. Khi chat riêng Telegram thì như bạn bè, hài hước thoải mái; trong kênh nhóm Slack tự động trở thành phong cách đồng nghiệp chuyên nghiệp. Tất cả đều được định nghĩa trong soul.md.
Trường hợp này biến AI từ "công cụ" thành "bạn đồng hành". Nó không chỉ thực hiện chỉ thị, mà thực sự hiểu bạn là ai, bạn muốn gì.
Trường hợp sử dụng 9: Nhật ký thực phẩm, AI giúp bạn phát hiện nguồn dị ứng
Đây là trường hợp sử dụng bất ngờ nhất.
Cách dùng: Chụp ảnh thức ăn gửi cho OpenClaw, nó tự nhận diện và ghi lại. Mỗi ngày nhận 3 lần nhắc, báo cáo cảm giác dạ dày. Tất cả dữ liệu lưu vào nhật ký thực phẩm.
Khả năng phân tích: Mỗi tuần kích hoạt phân tích một lần, đối chiếu chéo bản ghi thực phẩm và báo cáo triệu chứng, nhận diện mẫu hình.
Thành quả thực tế: Hệ thống thông qua phân tích thành phần thực phẩm trong ảnh và phản hồi triệu chứng của Berman, phát hiện dạ dày anh ấy nhạy cảm với hành tây. Đây là điều chính anh ấy hoàn toàn không biết.
Một chatbot, giúp người ta kiểm tra nguồn dị ứng thực phẩm. Trước đây cần phải đến bệnh viện làm xét nghiệm chuyên biệt.
Trường hợp sử dụng 10: Task định thời + Sao lưu tự động + Cập nhật tự động
Phần này không hào nhoáng lắm, nhưng có lẽ là cơ sở hạ tầng quan trọng nhất.
Danh sách task Cron:
| Tần suất | Task |
|------|------|
| Mỗi 5 phút | Kiểm tra ghi chép cuộc họp Fathom |
| Mỗi 30 phút | Quét email |
| Mỗi ngày 3 lần | Kiểm tra hoàn thành mục hành động |
| Mỗi tối | Đồng bộ tài liệu, quét CRM, rà soát an ninh, thu thập log, làm mới dữ liệu video, tạo báo cáo buổi sáng |
| Mỗi tuần | Tổng hợp trí nhớ, xem trước thu nhập |
| Mỗi giờ | Commit Git + Sao lưu cơ sở dữ liệu |
Chiến lược sao lưu: Tất cả cơ sở dữ liệu SQLite tự động phát hiện, mã hóa, đóng gói tải lên Google Drive, giữ lại 7 ngày gần nhất. Code mỗi giờ Git push GitHub. Bất kỳ sao lưu nào thất bại, Telegram cảnh báo ngay lập tức.
Cập nhật tự động: 9h tối mỗi ngày kiểm tra phiên bản mới của OpenClaw, hiển thị changelog, nói một câu "update" là tự động nâng cấp khởi động lại.
Theo dõi API: Ghi lại mỗi lần gọi LLM dùng model nào, tiêu hao bao nhiêu token. Thậm chí tải về hướng dẫn prompting chính thức của các model, để hệ thống tối ưu cách viết prompt dựa trên model thực tế sử dụng.
Triết lý thiết kế của cơ sở hạ tầng này chỉ một điều: Bạn ngủ的时候, hệ thống đang làm việc; hệ thống có vấn đề的时候, bạn biết ngay lập tức.
Tạo hình ảnh và video: Sáng tạo nội dung trực quan theo nhu cầu
Berman đã kết nối Veo (tạo video) và NanoBanana Pro (tạo ảnh Gemini) vào OpenClaw.
Cách dùng rất đơn giản: Trong Telegram nói "video biệt thự Tuscany Ý", hệ thống gọi Veo tạo, tự động tải xuống gửi đến Telegram, rồi xóa file cục bộ tiết kiệm dung lượng. Tạo ảnh tương tự, bảo nó muốn gì, NanoBanana Pro tạo xong đẩy trực tiếp.
Bản thân trường hợp này không quá ấn tượng, nhưng giá trị của nó nằm ở chỗ có thể được nhúng vào các quy trình làm việc khác. Ví dụ khi dây chuyền chọn đề tài video tạo đề xuất ảnh thu nhỏ, có thể trực tiếp gọi tạo ảnh để xuất ảnh.
Quay lại toàn cục: Mối quan hệ giữa các trường hợp này mới là trọng điểm
Nếu bạn chỉ xem từng trường hợp đơn lẻ, sẽ thấy "khá hay, nhưng hình như cũng không đặc biệt lắm". ChatGPT cũng có thể giúp bạn tra danh bạ, Notion AI cũng có thể giúp bạn sắp xếp kho kiến thức.
Nhưng sức mạnh thực sự của hệ thống Berman nằm ở dòng chảy dữ liệu giữa các trường hợp sử dụng:
-
Dữ liệu CRM → Cho Hội đồng cố vấn kinh doanh
-
Nội dung kho kiến thức → Cho dây chuyền chọn đề tài video
-
Dữ liệu mạng xã hội → Cho báo cáo hàng ngày + Hội đồng cố vấn
-
Ghi chép cuộc họp → Cho CRM + Hệ thống mục hành động
-
Log chạy của tất cả module → Cho Ủy ban an ninh
Mỗi module không phải là ốc đảo. Chúng tạo thành một bánh xe dữ liệu củng cố lẫn nhau. Đây mới là lý do tại sao một người + một máy MacBook có thể cho ra hiệu quả của một đội ngũ nhỏ.
Berman có một câu nói mà tôi thấy đặc biệt đúng: "Bạn sẽ bắt đầu thấy tất cả các phần khác nhau tôi xây dựng tương tác với nhau như thế nào, khiến nhau trở nên mạnh mẽ hơn."
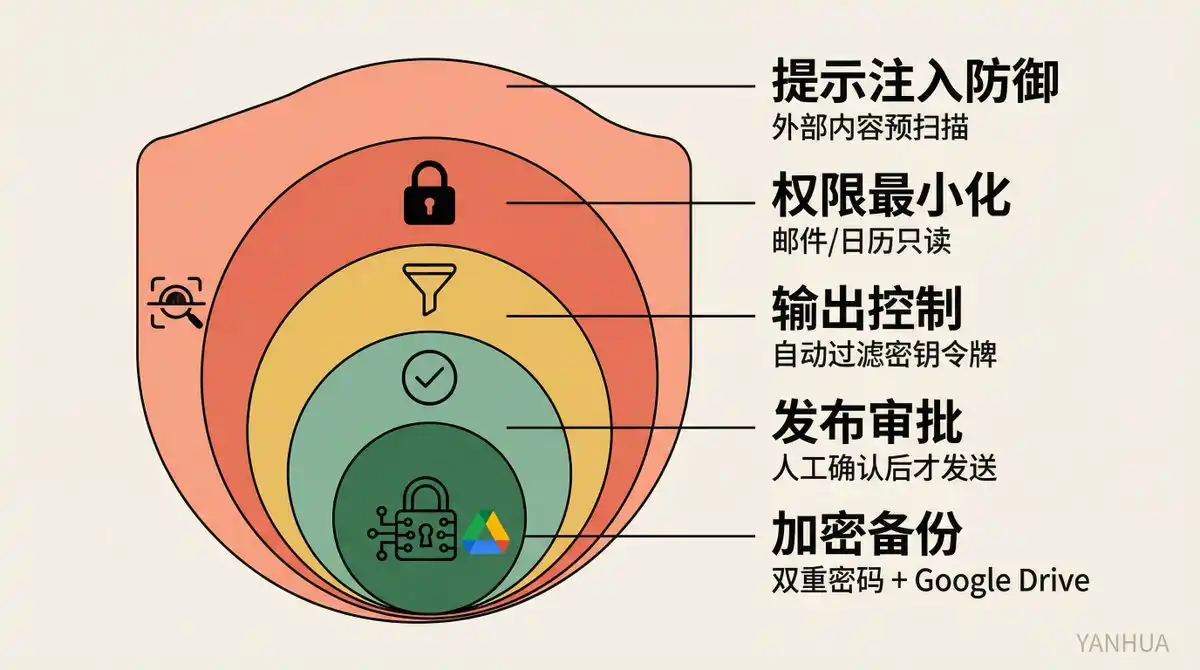
Nhắc nhở an ninh: Thắt dây an toàn trước khi chạy
Công sức Berman bỏ ra về an ninh đáng được nhấn mạnh riêng:
-
Phòng chống prompt injection: Tất cả nội dung bên ngoài được coi là tiềm ẩn độc hại, quét code xác định trước khi nhập kho
-
Quyền hạn tối thiểu: Email, lịch chỉ đọc, không cho quyền ghi
-
Kiểm soát đầu ra: Tóm tắt không nhắc lại từng chữ, tự động lọc khóa và token
-
Phê duyệt phát hành: Phải xác nhận thủ công trước khi gửi email, đăng tweet
-
Sao lưu mã hóa: Bảo vệ bằng mật khẩu kép, file .env không bao giờ đưa vào kho
Anh ấy nói rất rõ: "Không có giải pháp an ninh hoàn hảo. Mô hình ngôn ngữ lớn là hệ thống không xác định, hoàn toàn ngăn chặn prompt injection là không thể. Nhưng điều này không có nghĩa là bạn không làm gì cả."
Xem xong những trường hợp sử dụng này, cảm nhận lớn nhất của tôi là: "Full-stack" thời đại AI không còn là chỉ biết viết front-end và back-end, mà là chỉ có thể xây dựng và quản lý một整套 AI workflow. Berman không viết code, nhưng anh ấy có nhận thức cực kỳ rõ ràng về nhu cầu của bản thân, và biết cách dùng ngôn ngữ tự nhiên dịch những nhu cầu này thành hệ thống có thể chạy.
Đây có lẽ là kỹ năng đáng học nhất năm 2026.
Dựa trên video "21 INSANE Use Cases For OpenClaw" của Matthew Berman, podcast Podwise tổng hợp, video gốc bao gồm prompt đầy đủ cho mỗi trường hợp sử dụng, khuyến nghị xem để lấy. Nếu bạn cũng đang dùng OpenClaw hoặc framework tương tự để xây dựng hệ thống AI của riêng mình, hãy trao đổi ở bình luận xem bạn xây trường hợp nào trước.





