【Dẫn nhập】Thật điên rồ! Dữ liệu tiến hóa AI vừa được Meta và METR đo đạc trùng khớp hoàn hảo với "định luật mật độ" mà nhóm nghiên cứu Trung Quốc đề xuất hai năm trước. Thung lũng Silicon quay đầu nhìn lại, phát hiện các nhà nghiên cứu Trung Quốc đã dẫn trước hai năm trên con đường này!
Ba tổ chức nghiên cứu AI nghiêm túc nhất toàn cầu đã cùng đâm phải nhau trong tuần qua!
Ngày 3 tháng 4, tổ chức nghiên cứu Mỹ METR đã lặng lẽ cập nhật một báo cáo kỹ thuật, cô đọng kết luận cốt lõi thành một câu.
Năng lực AI tăng gấp đôi mỗi 88.6 ngày.
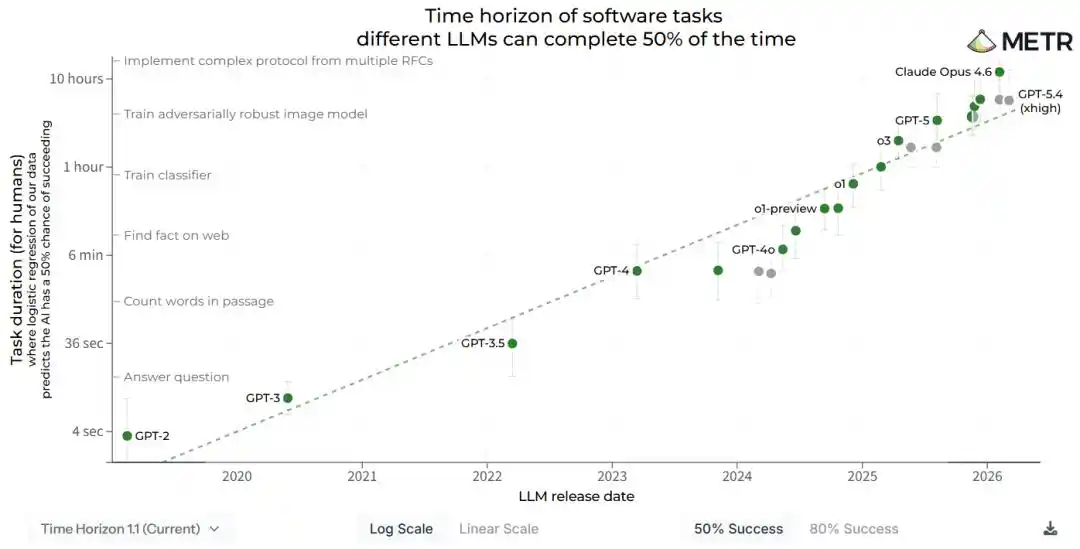
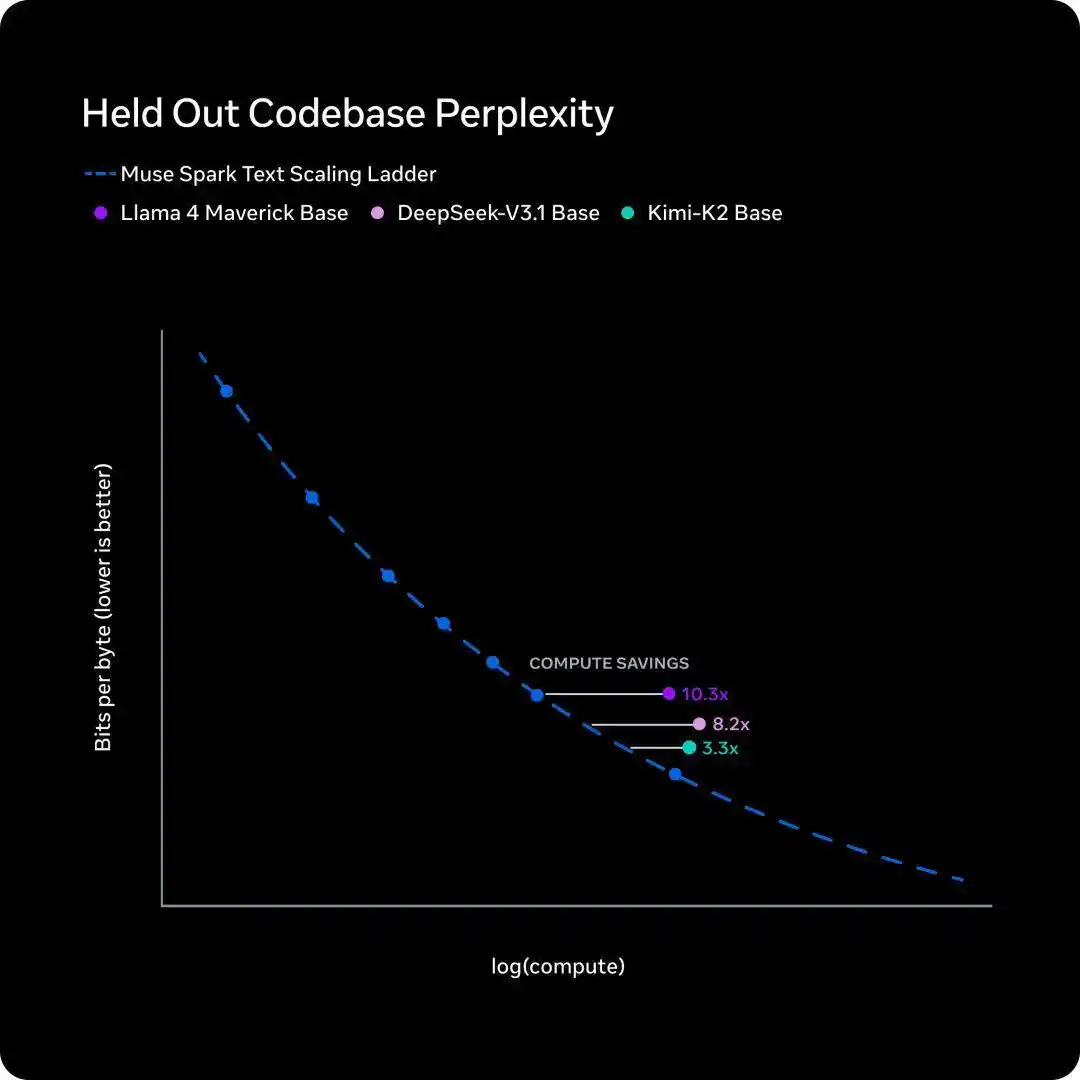
5 ngày sau, ngày 8 tháng 4, Phòng thí nghiệm siêu trí tuệ Meta (Meta超级智能实验室) đã phát hành mô hình mới Muse Spark, công bố một đường cong hiệu suất huấn luyện nội bộ gọi là scaling ladder, kết luận cũng là một câu.
Để đuổi kịp hiệu năng của Llama 4 Maverick một năm trước, mô hình mới chỉ cần chưa đến một phần mười lượng tính toán huấn luyện.
Một bên đo thời lượng nhiệm vụ, một bên đo lượng tính toán huấn luyện. Hai tổ chức không có liên hệ gì, phương pháp nghiên cứu hoàn toàn không trùng lặp.
Nhưng khi hai đường cong được quy đổi về cùng một hệ tọa độ, độ dốc gần như hoàn toàn trùng khớp.
Đến đây, sự việc đã đủ kỳ lạ.
Kỳ lạ hơn nữa là, đường cong này, đã được một nhóm nghiên cứu Trung Quốc vẽ ra đầy đủ từ hai năm trước, và còn được đăng trên tạp chí con của Nature.
Nó được gọi là định luật mật độ.

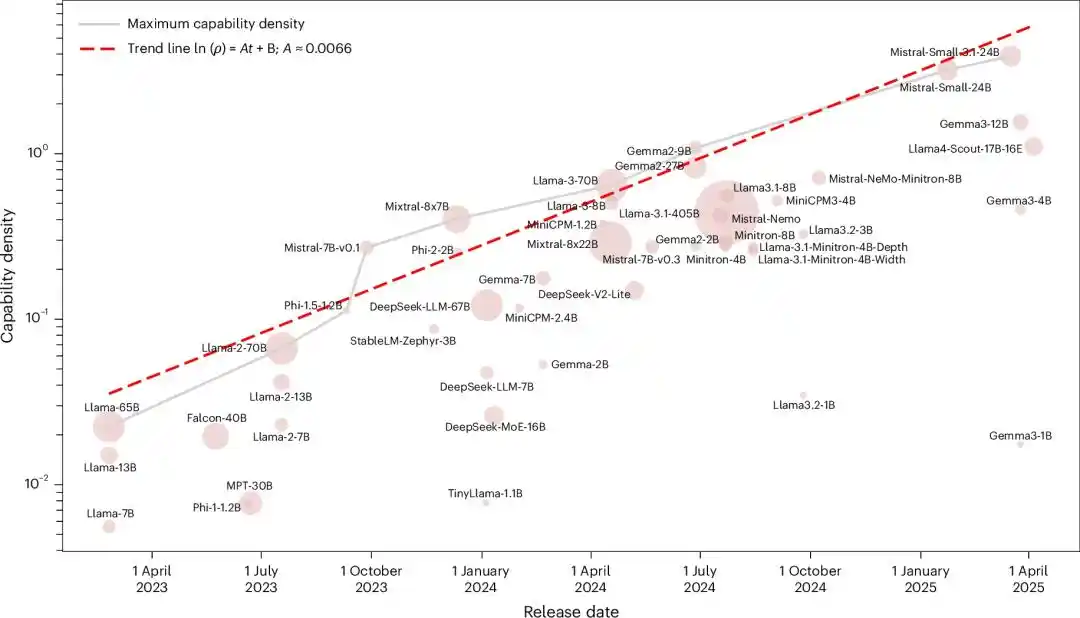
Hai năm trước, có người đã vẽ trước đường thẳng này
Khái niệm này lần đầu xuất hiện trong một bài báo có tên "Densing Law of LLMs".
Tác giả là nhóm liên kết giữa Mianbi Intelligence (面壁智能) và Đại học Thanh Hoa, do hai giáo sư Tôn Mậu Tùng (孙茂松) và Lưu Tri Viễn (刘知远) dẫn dắt, tác giả đầu tiên là nghiên cứu sinh tiến sĩ Tiêu Triều Quân (肖朝军).
Bài báo được đăng lên arXiv vào tháng 12 năm 2024, và được Nature Machine Intelligence chấp nhận vào tháng 11 năm 2025.

Địa chỉ bài báo: https://arxiv.org/abs/2412.04315

Địa chỉ bài báo: https://www.nature.com/articles/s42256-025-01137-0
Phán đoán cốt lõi của bài báo chỉ có một câu.
Mật độ thông minh của mô hình tăng cường theo cấp số mũ theo thời gian, lượng tham số cần thiết để đạt đến trình độ thông minh cụ thể, giảm một nửa mỗi 3.5 tháng.
Vào cuối năm 2024, câu nói này nghe có vẻ hơi quá khích.
Lúc đó toàn ngành đều tôn sùng scaling law. OpenAI đang đống mô hình, Anthropic đang đống mô hình, Meta cũng đang đống mô hình.
Mọi người đều nghĩ tham số càng lớn thì trí thông minh càng mạnh, đốt GPU đến cực hạn mới là chính đạo.
Nhưng nhóm nghiên cứu không nghĩ vậy.
Họ đặt tất cả các mô hình nền tảng mã nguồn mở có ảnh hưởng lúc đó, từ Llama-1 cho đến Gemma-2, MiniCPM-3, tổng cộng 51 mô hình vào cùng một thước đo.
Sau khi chạy năm điểm chuẩn, kết quả là mối quan hệ số mũ gần như hoàn hảo, R2 đạt 0.934.
Xem xét việc đánh giá mô hình lớn dễ bị nhiễu bẩn dữ liệu, họ lại đo lại một lần nữa bằng một tập dữ liệu lọc nhiễm mới xây dựng là MMLU-CF. R2=0.953.
Cả hai lần fitting đều đạt được R2 gần bằng 1. Về mặt thống kê, điều này gần như không thể là trùng hợp.
Nói cách khác là, mỗi mô hình mã nguồn mở chủ lực được phát hành trong hai năm qua, bất kể từ nhóm nào, dùng kiến trúc gì, đều rơi vào cùng một đường số mũ "tăng gấp đôi mỗi 3.5 tháng".
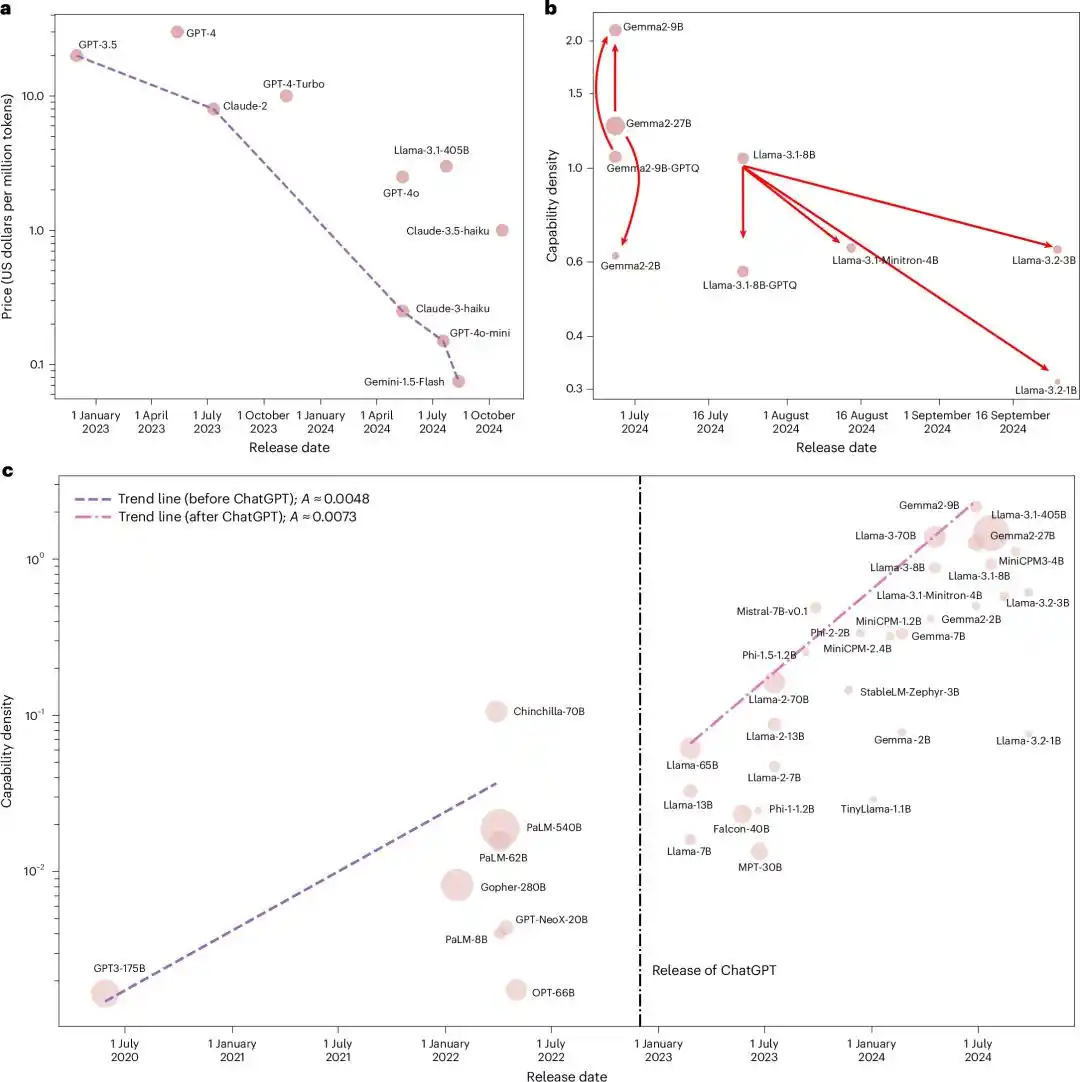
Đến đây, câu chuyện vẫn chỉ là "một nhóm nghiên cứu Trung Quốc đề xuất một quy luật kinh nghiệm trông có vẻ rất tích cực".
Điều thực sự biến việc này thành một "thời khắc", là những chuyện xảy ra trong nửa năm nhỏ tiếp theo.
Ba tổ chức, ba phương pháp, cùng một độ dốc
Trải rộng kết luận của ba bên Mianbi, Meta, METR ra xem.
- Định luật mật độ của Mianbi đo lường "cần bao nhiêu tham số cho cùng trình độ thông minh". Kết luận là nhu cầu tham số giảm một nửa mỗi 3.5 tháng.
- Scaling ladder của Meta đo lường "cần bao nhiêu tính toán huấn luyện cho cùng trình độ thông minh". Kết luận là Muse Spark tiết kiệm hơn một bậc độ lớn so với Llama 4 Maverick một năm trước.
- Báo cáo khoảng thời gian của METR đo lường "mô hình cùng loại có thể giải quyết nhiệm vụ dài bao nhiêu". Kết luận là thời lượng nhiệm vụ tăng gấp đôi mỗi 88.6 ngày.
Ba cây thước. Ba cơ quan học thuật. Ba con đường nghiên cứu không hề trùng lặp.
Nhưng khi tất cả các con số được quy đổi về cùng một hệ tọa độ để xem, độ dốc đường cong của chúng gần như hoàn toàn trùng khớp.
Điểm dễ bị bỏ qua nhất của việc này là, định luật mật độ là thứ được đề xuất sớm nhất trong ba cái. Sớm hơn scaling ladder của Meta gần hai năm, cũng sớm hơn việc mô hình hóa hoàn chỉnh của METR hơn một năm.
Và khi Meta vẽ ra đường scaling ladder đó trong blog phát hành đầu tháng tư, có lẽ chính họ cũng không nhận ra. Hình dạng của bức ảnh này, và đường cong trên một slide hội nghị học thuật ở Bắc Kinh năm 2024, gần như là cùng một đường.
Quan sát như thế nào, mới xứng đáng với hai chữ "định luật"
Trong giới khoa học, có một bộ tiêu chuẩn không thành văn, để phán đoán một quan sát kinh nghiệm có đủ tư cách được gọi là "định luật" hay không.
Không phải xem dữ liệu đẹp đến đâu, mà là xem nó có thể đồng thời thành lập trong nhiều hệ thống đo lường độc lập hay không.
Định luật Moore (Moore's Law) là định luật vì ngành bán dẫn đã từ ba chiều hoàn toàn khác nhau là độ chính xác quang khắc, mật độ transistor, chi phí tính toán trên đơn vị, kiểm chứng nó trong mấy chục năm.
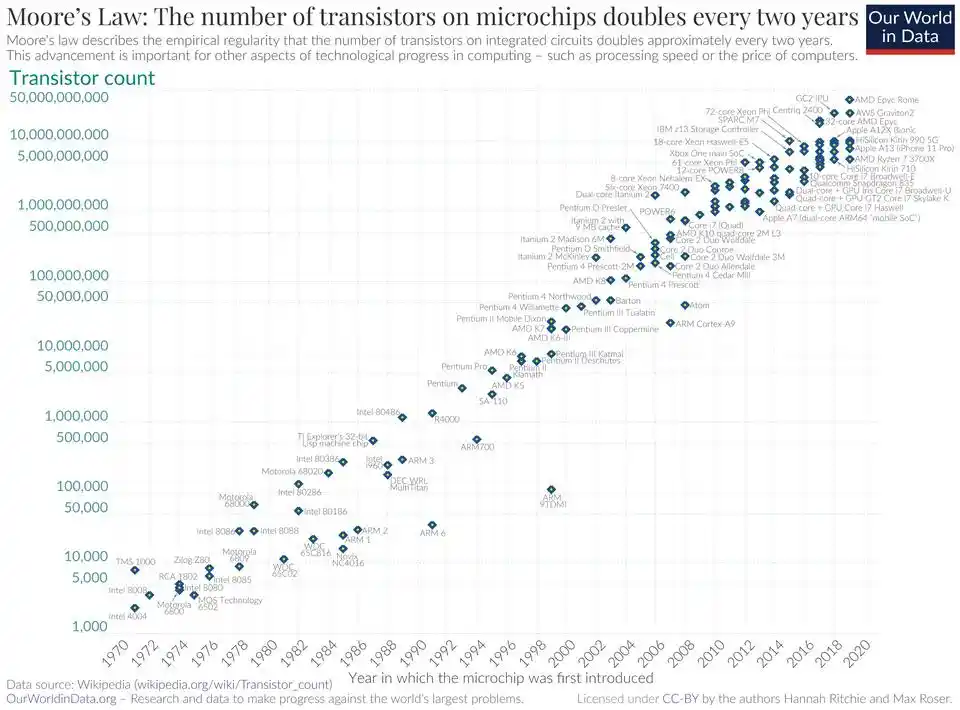
Định luật mật độ đi cùng một con đường.
Ban đầu nó chỉ là một đường cong fitting từ một nhóm duy nhất. Đến khi được tạp chí con của Nature chấp nhận, nó đã có thể tái hiện trên tập dữ liệu đã lọc nhiễm. Đến tháng này, nó lại được kiểm chứng độc lập hai lần trong dữ liệu huấn luyện của Meta và đánh giá nhiệm vụ của METR.
Đặt trong hệ tọa độ lớn hơn để xem, khoảnh khắc này giống hệt lúc điện lực mới vào New York những năm 1880.
Lúc đó cũng là vài nhà phát minh khác nhau, kỹ sư khác nhau, thành phố khác nhau, mỗi người làm mạng lưới điện của mình. Mãi đến khi có người vẽ tất cả đường cong phát triển của các dự án lên một tờ giấy, mọi người mới phản ứng lại. Đây không phải là mấy tiến bộ kỹ thuật rời rạc, mà là một thời đại mới đang lặng lẽ trải ra.
Chỉ có điều lần này, từ khi bài báo được công bố đến khi được đồng nghiệp toàn cầu kiểm chứng, chỉ mất chưa đầy một năm.
Ba suy luận, mỗi cái đang viết lại giả định ngành
Nếu định luật mật độ đứng vững, nó sẽ đồng thời viết lại rất nhiều thứ.
Thứ nhất, chi phí suy luận sẽ sụp đổ nhanh hơn tất cả dự kiến.
Một hệ quả của định luật mật độ là, đối với LLM đạt cùng hiệu năng, chi phí suy luận đại khái giảm một nửa mỗi 2.6 tháng.
Ngày nay, mức giảm này đã bị vượt qua bởi thực tế.
Dữ liệu theo dõi mới nhất của Epoch AI cho thấy, đối với LLM đạt trình độ hiệu năng Claude 3.5 Sonnet, giá token trong năm qua đã giảm 400 lần. Mức giảm nhanh nhất của cùng phân khúc hiệu năng chạm đến 900 lần/năm.
Mức giá 20 USD/triệu token của GPT-3.5 vào cuối năm 2022, ngày nay Mistral Nemo chỉ cần 0.02 USD, rẻ hơn 1000 lần, mô hình còn mạnh hơn.
Nhìn lại, dự đoán trong bài báo vẫn là bảo thủ.
Thứ hai, điểm bùng nổ trí tuệ đầu cuối, gần hơn tất cả tưởng tượng.
Nhân định luật mật độ và định luật Moore lên, sẽ được một con số kích thích hơn.
Theo ước tính hiện tại, quy mô mô hình hiệu quả lớn nhất có thể chạy trên chip cùng giá, đại khái tăng gấp đôi mỗi 88 ngày.
Con số này và 88.6 ngày mà METR tính toán gần như nhất trí. Hai con đường suy tính hoàn toàn khác nhau, đâm phải nhau sau dấu thập phân.
Ba đến năm năm tới, việc chạy mô hình cấp GPT đỉnh hiện tại trên một máy tính xách tay thông thường thậm chí một điện thoại di động, có thể không còn là khoa học viễn tưởng.
Thứ ba, chiến lược tối ưu của ngành mô hình lớn, đang lặng lẽ đảo ngược.
Ba năm qua, sự hiểu biết của ngành về scaling law luôn dừng lại ở "đống tham số đống dữ liệu"
Nhưng định luật mật độ đưa ra một phán đoán phản trực giác. Trong điều kiện tiên quyết mật độ tiếp tục tăng theo cấp số mũ, bất kỳ mô hình mạnh nhất nào ở trạng thái nào cũng chỉ có vài tháng cửa sổ tối ưu.
Đập toàn bộ tài nguyên để huấn luyện một mô hình lớn hơn, rồi đợi ba tháng bị một mô hình mới thể tích một nửa vượt qua, về mặt sổ sách kinh tế là không hợp lý.
Con đường thực sự bền vững, là đập tài nguyên vào việc nâng cao chính bản thân mật độ. Kiến trúc tốt hơn, dữ liệu chất lượng cao hơn, thuật toán huấn luyện thông minh hơn.
Mianbi, luôn đi theo cây thước do chính mình vẽ
Đáng nói một câu là, định luật mật độ không phải là một bài báo xong là kết thúc.
Mianbi Intelligence, người đề xuất lý thuyết này, hai năm qua luôn dùng loạt mô hình "MiniCPM" (Tiểu Cương Pháo) của chính mình để kiểm chứng nó.
Khi MiniCPM-1-2.4B được phát hành vào tháng 2 năm 2024, điểm chạy có thể ngang bằng hoặc vượt Mistral-7B của tháng 9 năm 2023. Nghĩa là, bốn tháng thời gian, 35% tham số, đạt được hiệu năng tương đương.
Con số này được viết thẳng vào bài báo trên tạp chí con của Nature, làm ví dụ thực chứng đầu tiên của định luật mật độ.
Từ đó về sau, loạt Tiểu Cương Pháo liên tục mã nguồn mở, bao phủ bốn hướng văn bản, đa phương thức, giọng nói, toàn phương thức dưới 10B tham số. Mức độ hoàn chỉnh mã nguồn mở này, trong nước ngoài Ali ra, chỉ có mỗi Mianbi một nhà làm được.
Cho đến nay, lượng tải xuống mã nguồn mở toàn cầu của loạt Tiểu Cương Pháo đã vượt 24 triệu lần.
Nó không phải là mô hình lớn nhất trong ngành. Nhưng nó là nhóm đầu tiên trong ngành lấy "ưu tiên mật độ" làm phương pháp luận công ty để thực thi.
Và khi Meta và METR trong tuần tháng 4 năm 2026 này dùng cách riêng của mình kiểm chứng định luật mật độ, công ty Trung Quốc này đã bắt đầu huấn luyện mô hình theo phương pháp luận này từ năm 2024, kỳ thực đã dẫn trước hai năm kinh nghiệm kỹ thuật.
Lần này, nhà nghiên cứu Trung Quốc đứng ở điểm xuất phát của đường cong
Một khuôn khổ lý thuyết do nhóm nghiên cứu Trung Quốc đề xuất hai năm trước, đang bị các cơ quan nghiêm túc nhất hải ngoại như Meta, METR, dùng cách riêng của họ, lần lượt phát hiện lại.
Sức nặng của việc này, có lẽ cần một chút thời gian mới có thể hoàn toàn hiểu.
Nó không phải là một câu chuyện "chúng ta cũng được". Nó là một câu chuyện "chúng ta thấy sớm hơn một chút".
Trong lịch sử khoa học, những khoảnh khắc như vậy không nhiều. Một phán đoán bị nghi ngờ vào năm 2024, đến năm 2026 đã trở thành cùng một đường cong được nhiều bằng chứng độc lập chỉ ra.
Loại "bất ước nhi đồng" xuyên địa lý, xuyên phương pháp, xuyên cơ quan này, trong vật lý học đã xảy ra vài lần, mỗi lần đều đánh dấu sự kết thúc của một mô hình cũ và sự bắt đầu của một mô hình mới.
Lần này nhà nghiên cứu AI Trung Quốc đứng ở điểm xuất phát đó.
Và đường cong đó, vẫn đang đi lên với tốc độ tăng gấp đôi mỗi 88 ngày.
Tài liệu tham khảo:
"Định luật mật độ" do Mianbi Intelligence sáng tạo, được cơ quan cấp cao hải ngoại như Meta công nhận
https://arxiv.org/abs/2412.04315
https://www.nature.com/articles/s42256-025-01137-0
https://metr.org/blog/2026-1-29-time-horizon-1-1/
https://ai.meta.com/blog/introducing-muse-spark-msl/
Bài viết từ WeChat public account "Tân Trí Nguyên" (新智元), biên tập: Hảo Khốn (好困) Đào Tử (桃子)








