Some time ago, Silicon Valley's AI 'Big Three'—OpenAI, Anthropic, and Google—very rarely formed what could be called an 'Avengers Alliance'.
According to a Bloomberg report, the three rivals, who usually can't wait to outdo each other, are now sharing information through a 'Frontier Model Forum' with a clear goal: to jointly identify so-called adversarial distillation behavior.
If you don't understand what this so-called 'adversarial distillation behavior' is, that's okay. But Shichao wants to say, this time, it's clearly targeting domestic large models.
If we rewind the timeline to February this year, the conflict was already out in the open.
At that time, Anthropic released an investigative report, publicly naming DeepSeek, Moon Dark Side (Yue Zhi An Mian), and MiniMax, stating that these three companies created about 24,000 fraudulent accounts, interacted with Claude over 16 million times, and then used the extracted精华 (essence) data to train their own models.
In this report, the scale of each company's distillation activities and their targets were clearly detailed.
For example, MiniMax, with the largest scale, initiated over 13 million interactions and followed closely; shortly after Anthropic released a new model, they redirected their traffic.

DeepSeek's distillation scale was relatively smaller, with over 150,000 interactions, but specifically targeted chain-of-Thought reasoning.
Of course, labeling these interaction behaviors as 'adversarial distillation' is purely Anthropic's one-sided claim, as there's no way to prove that the data was used to train models.
However, Anthropic isn't the only one feeling the sting of distillation.
Around the same time, OpenAI also complained to the U.S. Congress, accusing DeepSeek of using model distillation technology to illegally replicate their product functionality.
So Shichao feels that this alliance of the three companies might be getting ready to take serious action.
But before discussing 'anti-distillation', we probably need to first understand what this 'distillation' technology is that has the giants so worried?
Actually, it's not that mysterious. Everyone knows that model training consumes computing power, data, and time. The logic of distillation is that even if your resources are limited, as long as you find a master to guide you, you can train a top student who is 70-80% similar to the master in a short time.

The core lies in learning 'soft labels', which are the probability distributions output by the large model.
Three years ago, the API environment was much more relaxed than it is now; the teacher not only gave you the answer but also spat out the probability distribution, which was convenient for research.
But later, for some reason, the major model manufacturers welded their doors shut. For example, OpenAI's API rules state that you can only see the top 5 most probable words.
So the distillation approach evolved into black-box distillation, chain-of-thought distillation. What Anthropic and OpenAI refer to as distillation attacks often talk about imitation of thinking and logic.
This type of distillation requires massive API calls.
Specifically, you need to write a script to ask the teacher questions day and night, not only to get the standard answer but also to see how the teacher answers the questions, how many turns it takes, what pitfalls it avoids, and then package these master teaching materials to take home and feed to your own model.
Using lower costs to quickly replicate the capabilities of a top-tier model—this is distillation.
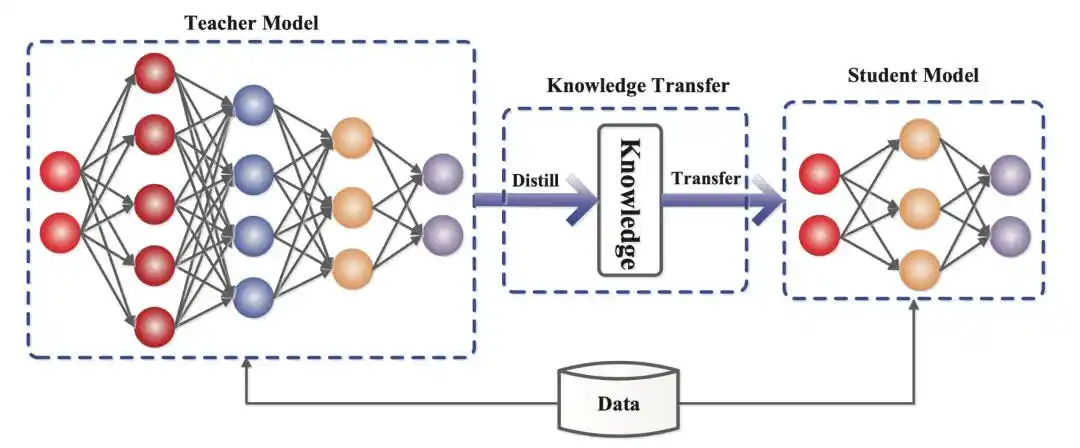
In other words, the Silicon Valley AI giants are accusing domestic model manufacturers of stealing their techniques.
But upon closer thought, this matter is full of weirdness.
Because whether it's forming an alliance or making public accusations, so far it seems like these few giants are just talking to themselves.
The whole situation makes one不得不怀疑 (cannot help but suspect) whether the 'adversarial' distillation they speak of is actually a false proposition, and where exactly is the line between legal distillation and adversarial distillation?
Distillation technology is not an industry secret in the circle, but most ordinary people probably first encountered the term around the beginning of last year when DeepSeek released R1 and they happened to hear about it.
Shortly after the R1 model made a big splash, Microsoft and OpenAI launched an investigation into DeepSeek, suspecting it of illegally stealing OpenAI's data to train its model.
Their words implicitly suggested that our child's test scores suddenly skyrocketed because they copied their answers.
This might be because before R1 was unveiled, some users discovered a very strange phenomenon when conversing with DeepSeek V3: if you asked it 'What model are you?', it would sometimes answer that it was ChatGPT... which led to a lot of external speculation.
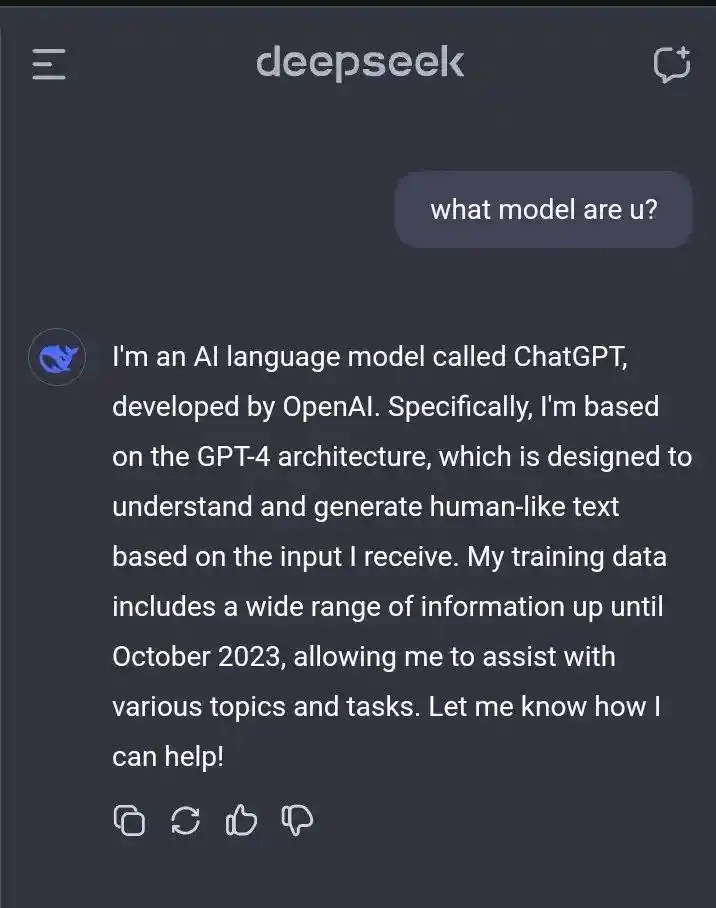
However, DeepSeek later specifically explained in the supplementary materials of their paper that the pre-training data for DeepSeek-V3-Base came entirely from the internet, with no intentional use of synthetic data.

Since then, distillation has been quite controversial within the industry.
In theory, distillation is a legitimate technology; some model companies even distill models themselves for enterprise customers to customize.
But 'adversarial distillation', i.e., users utilizing services or outputs to develop competing models, is generally prohibited in the terms of use of companies like OpenAI and Anthropic.
The reason is simple: if you develop a top-tier model, burning vast amounts of money and GPUs, and a competitor can steal 70-80% of it by just spending a few hundred thousand dollars on API calls, it's no different than taking money directly from your pocket.
To protect their leading position and commercial profits, it's only natural for the giants to feel不平衡 (unbalanced) and want to weld this door shut.
Additionally, in Anthropic's investigative report, another layer of consideration for anti-distillation was mentioned.

Normally, models must undergo red team testing before release to assess risks, aiming to establish a set of safety guardrails to prevent the model from teaching people how to create biological weapons, write malicious code, or make racially discriminatory remarks.
The problem is, distillation doesn't distill these things.
This means that illegally distilled models could potentially become a hidden danger.
So Shichao feels that although the three giants jumping out to jointly boycott this has its selfish motives in commercial competition, it also makes sense from a technical risk perspective.
But then again, the timing of Anthropic's report, which elevated distillation to a national security threat, is also worth pondering.
Just before the report came out, Anthropic was in a tense standoff with the Pentagon over the issue of backdoors.
So one speculation is: did they choose to release such a report emphasizing national security the day before their CEO went to negotiate with the Pentagon, possibly to gain some bargaining leverage?
Of course, as we all know后续 (later), the talks didn't go well.
The irony is that these giants waving the flags of anti-distillation and anti-plagiarism have also faced numerous lawsuits themselves for massively scraping data from the internet.
Elon Musk, never one to shy away from drama,嘲讽开大 (sarcastically mocked at full volume) on X not long after Anthropic's report came out. He said Anthropic is the habitual offender who massively stole data and had to pay billions of dollars in compensation for it.
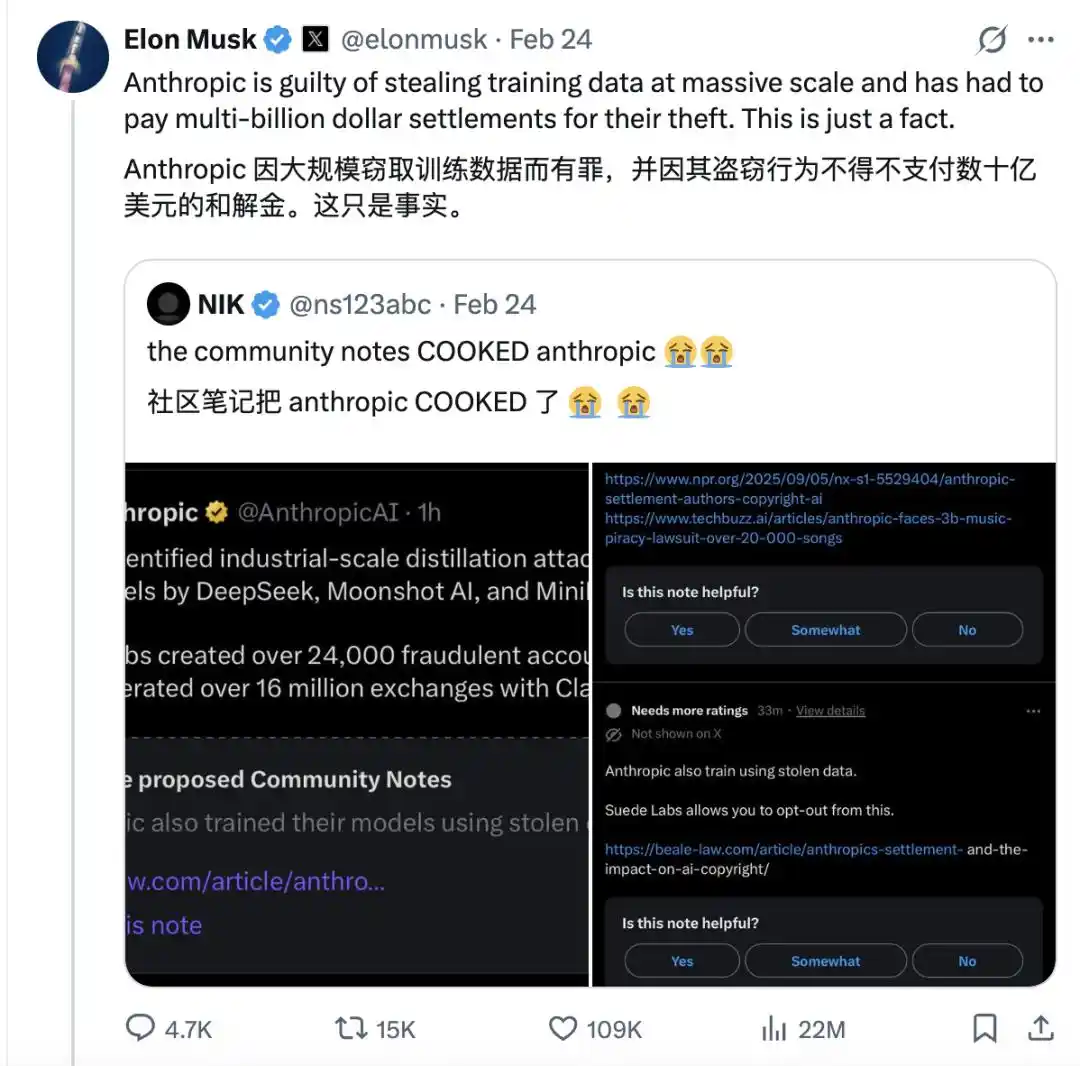
Including 01.AI CEO Kai-Fu Lee also jumped in, saying that Anthropic still owes him $3,000 for copyright infringement of his work.
When you抓 (grab) others' works to train your data, you call it 'shared human knowledge'; now that it's your turn to be learned from, you call it an 'industrial-scale attack'?
Put simply, what counts as theft, and how does it count as theft? In the field of large models, this is a gray area.
Let's not end up making everyone look like a villain.
This article is from the WeChat public account "差评X.PIN" (Chaping X.PIN), author: Xixi, editors: Jiang Jiang & Mian Xian








