Tác giả: Wang Jianshuo
Ngày 6 tháng 3 năm 2023, ChatGPT vừa mới ra mắt, GPT-4 chưa được công bố, tôi và Sarah đã có một cuộc phỏng vấn về ChatGPT – tập thứ ba trong loạt "Traders' Talk 'Bạch thoại'" (Podcast Bạch thoại nói về ChatGPT đã phát hành, chào mừng lắng nghe).
Lúc đó ChatGPT mới ra mắt chưa lâu, số người thực sự sử dụng còn rất ít, cuộc phỏng vấn dài ba giờ này sau đó luôn đứng đầu danh mục ChatGPT trên tiểu vũ trụ. Trong đó, tôi đã đưa ra hơn hai mươi nhận định và dự đoán liên tục, hoàn toàn dựa trên trực giác và thông tin hạn chế, không có nhiều dữ liệu. Toàn bộ bản ghi chữ của cuộc phỏng vấn đó vẫn còn trên tài khoản công chúng.
Bây giờ là cuối tháng 5 năm 2026, ba năm đã trôi qua, AI đã phát triển thành một hình dạng mà năm đó không thể tưởng tượng được.
Tôi muốn làm một việc: lấy ra từng ý trong hai mươi nhận định năm đó, sử dụng dữ liệu mới nhất có thể tra cứu được ngày hôm nay, để đối chiếu một cách khách quan. Xem rõ thế giới đã thực sự thay đổi như thế nào trong ba năm, và cũng xem rõ chính tôi ba năm trước, những điểm nào đã nhìn đúng, những điểm nào đã nhìn lệch.
Để cố gắng không thiên vị, lần đối chiếu này tôi quyết định giao cho AI làm: ném bản ghi chữ của cuộc phỏng vấn năm đó vào một workflow, để nó điều phối 41 agent Opus 4.8, đầu tiên tách hai mươi nhận định ra từng ý, sau đó tự mình tìm kiếm dữ liệu mới nhất trên mạng, kiểm chứng chéo từng ý, cuối cùng cho điểm Wang Jianshuo ba năm trước. Nhóm agent này mất khoảng 20 phút, đốt khoảng 1.4 triệu token (tương đương khoảng 35 đô la), chạy ra báo cáo dưới đây. Tất cả nhận định đều đến từ chúng, không phải tôi. Ngày cơ sở được xác định là tháng 5 năm 2026.
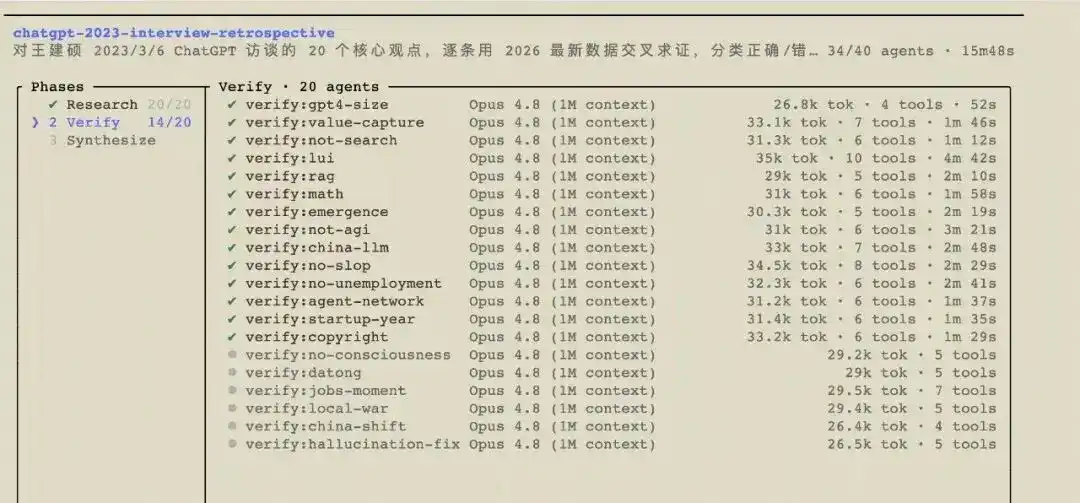
一、Bảng điểm
Ký hiệu phán quyết: ✅ Đúng · 🟢 Cơ bản đúng · 🟡 Một phần đúng · ❌ Sai
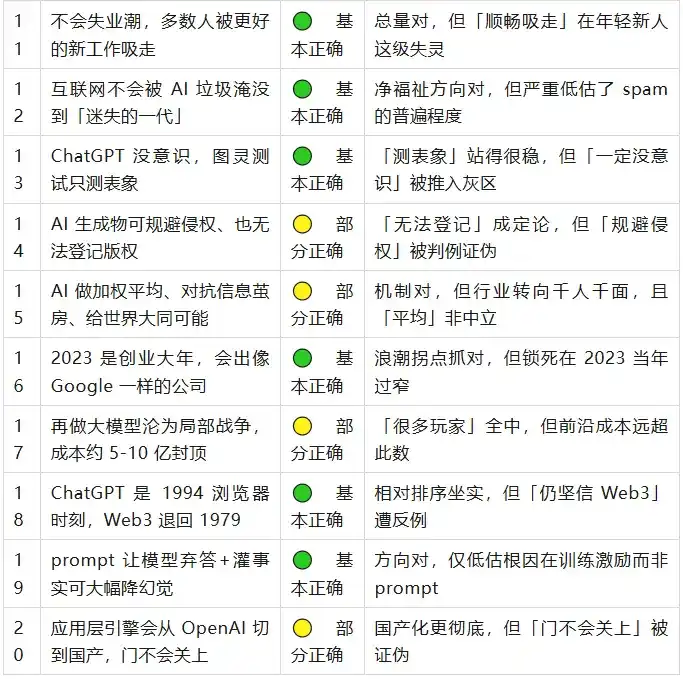
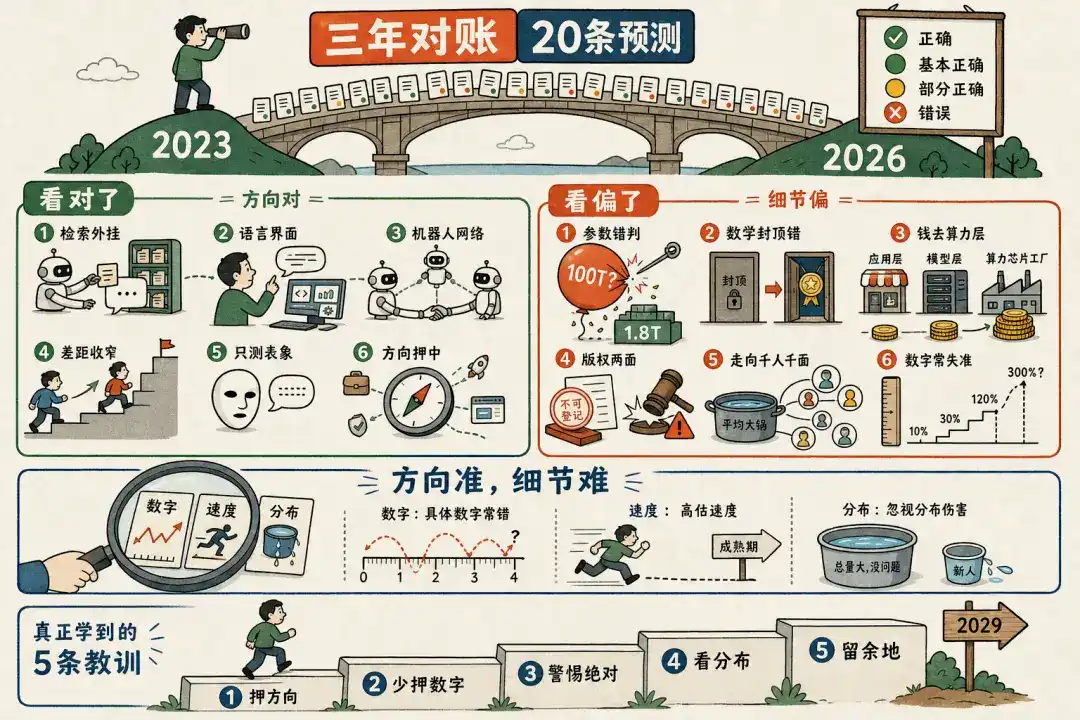
Nhìn tổng quan, hướng lớn của Wang Jianshuo năm đó hầu hết đều đứng vững, thực sự chỉ có một nhận định sai cứng – truyền rằng GPT-4 có 100T tham số. Nhưng ma quỷ ẩn giấu trong chi tiết: phía sau hầu hết mỗi nhận định "đúng", đều đè lên một cái đuôi không nói chính xác năm đó. Trong hai mươi nhận định không có nhận định nào hoàn toàn "vẫn chưa xác định", ba năm đủ dài, hầu hết mọi việc đều có xu hướng câu trả lời. Dưới đây sẽ nói chi tiết theo nhóm.
二、Nhìn đúng
Đặc điểm chung của nhóm này là: Hướng, cơ chế, thậm chí nhịp độ thời gian mà Wang Jianshuo đánh giá năm đó đều trúng, sai chỉ sai ở "mức độ" và "cách diễn đạt tuyệt đối hóa".
RAG và kiến trúc truy xuất (Quan điểm 2, 3)
> Năm 2023, Wang Jianshuo nói: Phương pháp chính để giải quyết kiến thức và ảo giác không phải là sửa mô hình, mà là dùng truy xuất vector để đổ kiến thức vào làm "phao cứu sinh"; kiến trúc đúng là công cụ tìm kiếm làm truy xuất, đưa kết quả cho LLM.
Đây chính là tiêu chuẩn thực tế của tất cả sản phẩm AI ngày nay. RAG đã trở thành kiến trúc mặc định cho doanh nghiệp AI, OpenAI, Google, Anthropic đều biến nó thành năng lực cấp nền tảng; ChatGPT Search về mặt chữ nghĩa chính là "dùng chỉ mục Bing để truy xuất trước, đưa kết quả cho GPT, rồi sinh ra câu trả lời có trích dẫn". Google AI Overviews dùng grounding để đạt khoảng 2 tỷ người dùng hoạt động hàng tháng, Perplexity một công ty thuần túy dựa vào kiến trúc này định giá vọt lên khoảng 200 tỷ đô la.
Vào thời điểm GPT-4 chưa được công bố, ngành công nghiệp mặc định là "dựa vào tinh chỉnh để đưa kiến thức vào", ông ấy đánh cược vào "không động tham số mô hình, gắn ngoài truy xuất", cơ chế và thời gian đều đúng.
Cần thành thật rằng: Ông ấy hình dung là "truy xuất một lần tĩnh", nhưng thực tế phức tạp hơn – ngữ cảnh dài, GraphRAG, agentic retrieval đều đến để bổ sung mạnh mẽ. Cuộc tranh luận "RAG đã chết" năm 2026, chính là chứng minh hướng lớn không chết, nó phủ định chỉ là "truy xuất đơn giản một lần", kết luận là nâng cấp thành truy xuất hỗn hợp, chứ không phải quay lại sửa tham số mô hình. Còn một điểm: Thuật ngữ RAG đã được đề xuất trong bài luận của Meta năm 2020, không phải ông ấy sáng tạo – ông ấy chỉ trong cửa sổ thời gian đã đánh cược trúng nó sẽ trở thành chủ lưu.
LUI là lục địa mới (Quan điểm 7)
> Năm 2023, Wang Jianshuo nói: Điểm vĩ đại nhất của ChatGPT không phải là AIGC, mà là mở ra LUI (giao diện người dùng ngôn ngữ tự nhiên), sẽ như GUI ngày xưa tái cấu trúc tương tác giữa người và máy, thúc đẩy một ngành công nghiệp mới lớn hơn nhiều so với "làm mô hình lớn" bản thân.
Phần "lục địa mới" này gần như hoàn toàn trúng. Ngôn ngữ tự nhiên đã trở thành lớp tương tác chủ đạo của đại chúng (ChatGPT 900 triệu người dùng hoạt động hàng tuần), và thúc đẩy một ngành công nghiệp mới độc lập – agent, coding agent, lớp giao thức tất cả đều thực hiện. Câu nói cụ thể nhất "lớn hơn nhiều so với làm mô hình bản thân" được xác nhận mạnh mẽ: giao thức MCP trở thành "tiêu chuẩn hệ điều hành" thời đại LUI, năm 2025 được OpenAI, Google, Microsoft toàn diện chấp nhận, cuối năm chuyển vào Linux Foundation; chỉ riêng sản phẩm Claude Code đã đạt doanh thu năm hóa khoảng 2.5 tỷ đô la.
Nhưng ông ấy đã dùng cách diễn đạt mạnh như "tái cấu trúc, thay thế GUI", ba năm sau nhìn lại là chồng lấp cùng tồn tại, chứ không phải thay thế. Ba ví dụ phản chứng rất cứng: Báo cáo MIT cho thấy 95% dự án thử nghiệm GenAI của doanh nghiệp không có ROI có thể đo lường được; computer-use agent thao tác trực tiếp giao diện trên tập kiểm tra mô hình đỉnh mới khoảng 78%, vừa chạm đến đường cơ sở con người; phần cứng ngôn ngữ thuần túy bỏ màn hình hầu như toàn bộ thất bại (Humane Pin năm 2025 ngừng phục vụ vĩnh viễn). Cách nói chính xác hơn là: LUI là lớp tương tác mới chồng lên trên GUI.
Mạng lưới robot và định vị mới (Quan điểm 9)
> Năm 2023, Wang Jianshuo nói: Khoảng mười năm tới sẽ xuất hiện "mạng lưới robot" – agent giữa chúng dùng ngôn ngữ tự nhiên tự động bắt tay, gọi lẫn nhau, không cần API truyền thống nữa; sẽ sinh ra một hệ thống định vị tên miền hoàn toàn mới. Bộ thứ này "hai ba năm là có thể làm xong".
Hướng đánh trúng đến kinh ngạc. MCP, A2A (đã quyên góp cho Linux Foundation, hơn 150 tổ chức hỗ trợ) giải quyết việc gọi lẫn nhau giữa agent; Agent Network Protocol trực tiếp dựa trên DID của W3C để làm "định vị agent không có trung tâm quyền lực", mục tiêu là "mạng lưới hợp tác hàng tỷ agent" – điều này đồng cấu trúc cao độ với "hệ thống tên miền hoàn toàn mới" mà ông ấy nói.
Hai chỗ cần sửa: Một là "không cần API" không thành lập, giao thức chủ lưu đáy là schema có cấu trúc, bản chất là chồng một lớp tiêu chuẩn lên trên API; hai là "hai ba năm làm xong" không thực hiện, dữ liệu Gartner cho thấy tính đến năm 2026 chỉ khoảng 17% tổ chức thực sự triển khai agent. Thú vị là, năm đó ông ấy thực sự chia lời nói thành tầng – hình thái ban đầu "hai ba năm", trưởng thành "khoảng mười năm". Nhịp độ hình thái ban đầu đánh trúng rất chuẩn, chu kỳ trưởng thành cũng thực sự là cấp mười năm. Tách hai tầng ra xem, chất lượng của điều này cao hơn so với nhìn bề ngoài.
Trung Quốc nhất định có thể làm ra mô hình lớn dùng được (Quan điểm 10, 20)
> Năm 2023, Wang Jianshuo nói: Trung Quốc nhất định có thể làm ra mô hình lớn dùng được, khoảng cách với đỉnh cao sẽ nhanh chóng thu hẹp trong khoảng ba năm (so sánh trình duyệt Hồng kỳ đuổi Netscape).
Đường thời gian của điều này trùng khớp đến bất ngờ. Stanford 2026 AI Index đo thực tế, khoảng cách chuẩn giữa mô hình Trung-Mỹ đỉnh cao từ tháng 5 năm 2023 là 17.5–31.6 điểm phần trăm, thu hẹp xuống 2.7%; trong khi đầu tư AI tư nhân của Mỹ gấp khoảng 23 lần Trung Quốc – dùng đầu vào nhỏ hơn nhiều để thực hiện sự thu hẹp. DeepSeek, Qwen, Kimi, GLM trở thành chủ lưu toàn cầu, hệ sinh thái mã nguồn mở thậm chí dẫn đầu.
Nhưng hai từ "nhanh chóng" lạc quan quá – trưởng thành thực sự xảy ra khoảng 14 tháng sau, chứ không phải "vài tháng". Và đây là đuổi kịp tính dùng được, không phải định nghĩa tiền tuyến: tính đến đầu năm 2026 vẫn không có mô hình Trung Quốc nào vượt qua OpenAI o3. Trong quan điểm 20, ông ấy sai rõ ràng: nhận định "cửa mở ra sẽ không đóng lại", bị OpenAI vào tháng 7 năm 2024 chủ động cắt API đối với Trung Quốc trực tiếp lật đổ, cửa bị phía cung cấp đóng lại; Wenxin Yiyan mà ông ấy nêu tên dẫn đầu ngược lại tụt hậu, thực sự tiếp sức là DeepSeek, Doubao, Qianwen năm đó còn không đáng kể.
Không có ý thức, bài kiểm tra Turing chỉ kiểm tra bề ngoài (Quan điểm 13)
> Năm 2023, Wang Jianshuo nói: ChatGPT không có ý thức, là "người nói vô ý, người nghe có lòng" tự mình đa tình; bài kiểm tra Turing vốn chỉ kiểm tra "có làm bạn nghĩ rằng nó có hay không", chứ không phải nó thực sự có.
Nhận định cốt lõi "kiểm tra bề ngoài" này đứng rất vững, còn được một thí nghiệm phản châm biếm xác thực: trong bài kiểm tra Turing UC San Diego năm 2025, GPT-4.5 dưới gợi ý "đóng vai nhân vật" bị phán là con người tỷ lệ cao đến 73%, cao hơn cả người thật, nhưng dựa hoàn toàn vào kỹ năng diễn xuất – đây chính là chú thích tốt nhất cho "chỉ kiểm tra có làm bạn nghĩ rằng nó có hay không".
Cần bổ sung là: "máy nhất định không có ý thức" cái luận đoán mạnh tuyệt đối hóa này, trong ba năm bị đẩy vào vùng xám. Anthropic đặt vị trí nghiên cứu "phúc lợi mô hình", đưa ra xác suất ý thức khoảng 15%–20%, còn cho Claude thêm chức năng "chủ động kết thúc hội thoại bị lạm dụng". Những điều này biến "tuyệt đối không có" thành "xác suất thấp nhưng không thể loại trừ". Tuy nhiên tất cả dựa trên "có thể, nên giả định" chứ không phải "đã chứng thực", hạt nhân không bị lật đổ, chỉ là giọng điệu năm đó xuống quá đầy.
Các nhận định đúng khác (Quan điểm 6, 11, 12, 16, 18, 19)
- Không phải AGI nhưng tiến một bước lớn
: Cả hai đầu đều đứng vững. Chính Altman trong thời đại GPT-5 vẫn nói "không phải AGI, thiếu học tập liên tục"; đồng thời IMO huy chương vàng, ARC-AGI từ gần 0 vọt lên 85%, "tiến một bước lớn" không tranh cãi. - Không có làn sóng thất nghiệp
: Tháng 4 năm 2026 tỷ lệ thất nghiệp Mỹ chỉ 4.3%. Điểm mù ở "phân bố" – nghiên cứu Stanford cho thấy, chính những người mới trẻ 22–25 tuổi ở cấp thang nghề nghiệp thứ nhất bị hút đi, cơ chế "hút trôi chảy" trên người họ thất bại. - Không bị chìm đắm trong rác AI
: Hướng phúc lợi ròng đúng, nhưng ông ấy đánh giá thấp nghiêm trọng quy mô – nội dung AI đã chiếm khoảng 52% trang web mới tăng, "AI slop" trở thành từ của năm. - Năm khởi nghiệp lớn
: Điểm rẽ của làn sóng nắm đúng, xAI (thành lập tháng 3 năm 2023) đã đạt định giá 2300 tỷ. Nhưng ông ấy khóa "công ty vĩ đại" vào năm 2023 quá hẹp – OpenAI, Anthropic thực sự có lượng tỷ đô đều thành lập sớm hơn. - Thời khắc trình duyệt 1994
: Sắp xếp tương đối xác thực, OpenAI năm 2025 thực sự ra mắt trình duyệt Atlas, biến phép ẩn dụ thành hiện thực chữ nghĩa. Chỉ là ChatGPT lan truyền mạnh hơn trình duyệt, phép ẩn dụ bảo thủ quá. - Prompt cộng đổ sự thật giảm ảo giác
: Hướng được xác nhận, GPT-5 ngắt mạng không truy xuất thời điểm tỷ lệ ảo giác vọt lên 47%, ngược lại xác thực "sự thật" là biến số then chốt. Chỉ đánh giá thấp nguyên nhân gốc ở khuyến khích huấn luyện, không phải prompt.
三、Nhìn sai, nhìn lệch
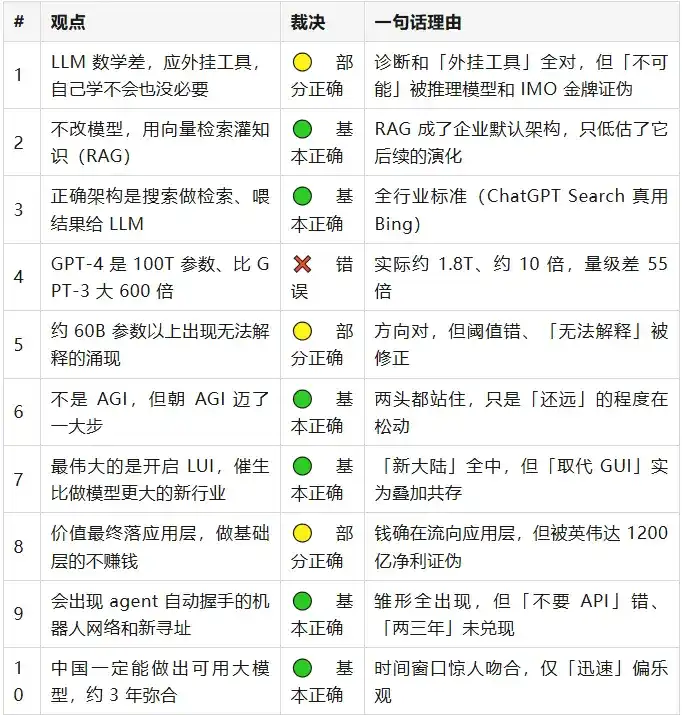
GPT-4 là 100T tham số (Quan điểm 4) – Sai hoàn toàn
> Năm 2023, Wang Jianshuo nói: (Tin đồn) GPT-4 là 100T tham số, so với GPT-3 175B khoảng 600 lần.
Hai con số đều sai. GPT-3 là 175B, tháng 7 năm 2023 ước tính tốt nhất bị rò rỉ là GPT-4 khoảng 1.8T, 16 chuyên gia MoE, chỉ khoảng 10 lần. 100T và thực tế chênh lệch khoảng 55 lần quy mô. Nguồn duy nhất của "100T", là CEO Cerebras năm 2021 một câu nói "khoảng" được chuyển thuật lại lần hai, Sam Altman ngay tháng 1 năm 2023 đã trực tiếp mắng bức ảnh so sánh đó là "complete bullshit".
Lời nói gốc của ông ấy đánh dấu "tin đồn", giữ lại sự không chắc chắn. Sâu hơn một tầng, khung "dùng bội số tham số để đo lường thế hệ" này bản thân đã lỗi thời: GPT-4.5, GPT-5 sau này của OpenAI thẳng thừng không công khai lượng tham số nữa. Đây là nhận định cứng duy nhất sai số, góc nhìn cũng lỗi thời.
Toán học LLM (Quan điểm 1) – Chẩn đoán đúng, kết luận khóa trần sai
> Năm 2023, Wang Jianshuo nói: Toán học LLM kém là bản chất, để nó tự học toán vừa không thể vừa không cần thiết, cách làm đúng là gắn ngoài công cụ.
"Chẩn đoán cộng lộ trình công cụ" toàn bộ đúng – nguyên nhân gốc chính là sinh token từng cái dẫn đến nhớ không đáng tin cậy (bài luận cơ chế năm 2025 xác thực chính xác trực giác "chữ số cuối thường đúng, chữ số giữa sai"); công cụ gắn ngoài nâng cao cũng khổng lồ (o4-mini cho phép dùng Python thời điểm, AIME 2025 đạt 99.5%).
Sai ở cách diễn đạt khóa trần như "không thể, không cần thiết". "Không thể" bị chứng minh sai – tháng 7 năm 2025 Gemini Deep Think và mô hình OpenAI trong IMO dùng thuần ngôn ngữ tự nhiên, không công cụ nhận huy chương vàng. Bước ngoặt then chốt là "mô hình suy luận" xuất hiện mới năm 2024–2025, điều này vào tháng 3 năm 2023 không thể dự kiến – vì vậy đối với dự đoán này nên khoan dung đánh giá hướng, chứ không nên trách móc thời điểm.
Nắm bắt giá trị (Quan điểm 8) – Đánh cược đúng một nửa, luận đoán cốt lõi ngược
> Năm 2023, Wang Jianshuo nói: Giá trị cuối cùng sẽ rơi vào lớp ứng dụng, công ty khai sáng lớp cơ sở (người làm mô hình) kết cục chưa chắc kiếm tiền.
Tiền thực sự bắt đầu chảy về lớp ứng dụng (Cursor ba năm đạt doanh thu năm hóa 2 tỷ) – nửa này đúng. Nhưng "làm lớp cơ sở không kiếm tiền" bị NVIDIA trực tiếp chứng minh sai: FY2026 lợi nhuận ròng khoảng 120 tỷ đô la, giá trị vốn hóa 5 nghìn tỷ+, là người duy nhất trên toàn thị trường rõ ràng có lợi nhuận lớn. Còn lớp mô hình ông ấy ngụ ý sẽ thắng (OpenAI năm 2026 dự lỗ khoảng 14 tỷ) ngược lại giống nhất cái ông ấy nói "lớp cơ sở đốt tiền không kiếm tiền".
Ông ấy không phân biệt "lớp cơ sở sức mạnh tính toán" và "lớp cơ sở mô hình", cũng không phân biệt "doanh thu" và "lợi nhuận". Giá trị năm 2026 so với năm 2023 càng cực đoan bị lớp sức mạnh tính toán nắm bắt, chứ không phải chuyển dịch về lớp ứng dụng. Cần bổ sung một câu: thua lỗ là nhà máy điện toán đám mây mua chip, không phải NVIDIA bán chip – đây chính là chỗ sai vị của ông ấy trong phép so sánh "xây dựng quá mức đường sắt".
Bản quyền (Quan điểm 14) – Đăng ký đúng, né tránh vi phạm sai
> Năm 2023, Wang Jianshuo nói: Nội dung sinh ra bởi AI có thể né tránh bản quyền (bảo vệ biểu đạt không bảo vệ tư tưởng); vật sinh ra có thể vừa không vi phạm, cũng không thể đăng ký.
"Không thể đăng ký" trở thành sự thật pháp lý đã định (năm 2025 Cục Bản quyền Mỹ rõ ràng "chỉ nhập từ gợi ý không đủ để chủ trương tác giả"). Nhưng "né tránh vi phạm" sai rõ ràng: tòa án nhiều lần xác định đầu ra AI nếu tương tự bản chất với tác phẩm gốc vẫn cấu thành vi phạm; Anthropic vì ngữ liệu ăn cắp dùng 1.5 tỷ đô la hòa giải, là bồi thường bản quyền lớn nhất lịch sử Mỹ. AI không những không "né tránh" bản quyền, ngược lại trả giá lớn nhất lịch sử.
Đại đồng thế giới (Quan điểm 15) – Cơ chế đúng, xu hướng đánh cược ngược
> Năm 2023, Wang Jianshuo nói: ChatGPT đưa quan điểm con người làm "bình quân gia quyền", có thể chống lại kén thông tin kiểu TikTok, cho "đại đồng thế giới" khả năng.
Tầng cơ chế đúng – năm 2025 nhiều nghiên cứu xác thực rõ ràng LLM đè quan điểm về số đông, đánh giá thấp có hệ thống thiểu số phái. Nhưng tầng phán đoán xã hội đánh cược ngược: chính ông ấy thêm "ít nhất hiện tại không phải nghìn người nghìn mặt", trong ba năm bị lật đổ – OpenAI từ tháng 4 năm 2025 đưa ký ức xuyên hội thoại và cá nhân hóa làm thành năng lực mặc định, AI đang đi với tốc độ cao đến nghìn người nghìn mặt. Quan trọng hơn, ông ấy tưởng tượng "bình quân gia quyền" là trung lập ước số chung thế giới, nhưng đo thực tế nó là dịch chuyển có hướng, còn chồng lấp xu nịnh, có thể dùng để chủ động thao túng lập trường – điều này hướng đến "chế tạo kén mới", chứ không phải "tiêu giải phân cực".
Chiến tranh cục bộ và chi phí (Quan điểm 17) – Tính chất toàn bộ trúng, định lượng chứng minh sai
> Năm 2023, Wang Jianshuo nói: Làm mô hình lớn nữa sẽ nhanh chóng trở thành "chiến tranh cục bộ", chi phí có thể biết (bỏ đường vòng khoảng 5-10 tỷ đô la khóa trần), sẽ có nhiều người chơi vào.
Hướng tính chất đúng đến kinh ngạc – nhiều người chơi vào, nhanh chóng hàng hóa hóa, mã nguồn mở đuổi kịp mã nguồn đóng, toàn bộ thực hiện. Nhưng "5-10 tỷ khóa trần" con số cứng này hai đầu đều sai: đầu tiền tuyến bị đánh giá thấp nghiêm trọng (cấp GPT-5 năm 2026 đạt 2-5 tỷ đô la huấn luyện, chồng lấp trung tâm dữ liệu nghìn tỷ và 5000 tỷ Stargate); đầu phục chế lại bị đánh giá cao (DeepSeek đè chi phí huấn luyện biên xuống cấp triệu đô la). Cùng một mô hình "chi phí" theo khẩu độ có thể chênh 200 lần, duy nhất không ở trong khoảng ông ấy cho.
Năng lực xuất hiện (Quan điểm 5) – Hướng đúng, số và khung định sai
> Năm 2023, Wang Jianshuo nói: Khoảng 60B tham số trở lên xuất hiện năng lực mới không có trong ngữ liệu gốc, nhà nghiên cứu cũng không thể giải thích.
Trực giác hướng tính thành lập, nhưng hai chỗ diễn đạt không đứng vững: một, không tồn tại "ngưỡng 60B" thống nhất – ngưỡng thực tế của chuỗi suy nghĩ khoảng 100B, năng lực khác nhau xuất hiện trên quy mô không bằng nhau từ 13B đến 540B; hai, "không thể giải thích" cuối năm 2023 bị một bài luận xuất sắc NeurIPS thách thức – nhiều "đột biến" là hiện tượng giả do lựa chọn chỉ số đánh giá tạo thành, đổi chỉ số liên tục sau đường cong trơn tru có thể dự đoán. Công bằng mà nói, năm đó ông ấy thuật lại là tự sự chủ lưu tuyệt đối, thực sự có thể sửa chính là lấy "60B" làm ngưỡng cứng, lấy "không thể giải thích" làm kết luận tính chất.
四、Nhìn lại ba năm, vài quy luật
Đối chiếu từng ý xong, lùi lại một bước nhìn, trong hai mươi nhận định của Wang Jianshuo này ẩn giấu vài quy luật đáng ghi nhớ hơn bất kỳ nhận định đơn lẻ nào.
一、Hướng xa đáng tin hơn số và mức độ. Trong hai mươi nhận định, phàm là phán đoán cơ chế và hướng (RAG, LUI, mạng lưới robot, bài kiểm tra Turing), gần như toàn bộ trúng; phàm là cho số cụ thể hoặc cách diễn đạt khóa trần (100T tham số, ngưỡng 60B, chi phí 5-10 tỷ, toán học "không thể"), gần như toàn bộ sai. Đối với lĩnh vực thay đổi nhanh, đánh cược hướng, đánh cược cơ chế, ít đánh cược số chính xác, càng cần cảnh giác loại từ nói đầy như "không thể, nhất định, khóa trần, tuyệt đối không có" – chúng là khu vực phát sinh cao bị thời gian tát vào mặt.
二、Về thời gian, ông ấy có xu hướng đánh giá cao tốc độ, đánh giá thấp mức độ. Phàm là nói "nhanh chóng, hai ba năm làm xong", thời kỳ trưởng thành phổ biến chậm hơn; nhưng đối với trần nhảy vọt năng lực lại đánh giá thấp – toán học có thể từ "không thể" đến huy chương vàng IMO, chi phí tiền tuyến có thể tăng đến quy mô năm đó không tưởng tượng được. Một câu: ngắn hạn quá lạc quan, dài hạn quá bảo thủ.
三、Sai ẩn giấu nhất, lặp lại xuất hiện ở "phân bố". Không phải hướng sai, mà là chỉ nhìn tổng lượng, bỏ qua phân bố. "Không có làn sóng thất nghiệp" đúng, nhưng tổn thương tập trung cao độ ở người mới trẻ; "giá trị rơi lớp ứng dụng" đúng một nửa, nhưng không phân biệt lớp sức mạnh tính toán và lớp mô hình. Tổng lượng đúng, che lấp thảm họa phân bố – đây là bài học đáng bổ sung nhất.
四、Chỗ để lời nói có dư địa, ba năm sau đều chịu được kiểm nghiệm. "Tin đồn" "ít nhất hiện tại" "giảm mạnh chứ không loại bỏ" "hình thái ban đầu hai ba năm, trưởng thành khoảng mười năm" – phàm là nhận định năm đó mang từ giới hạn, chia tầng lớp, hôm nay nhìn lại đều đứng vững hơn. Ngược lại câu tuyệt đối tuôn ra, dễ lật đổ nhất. Thành thật của dự đoán, một nửa ở dám nói, nửa kia ở dám đánh dấu sự không chắc chắn của mình.
五、Có một số vấn đề, ba năm căn bản không đủ. Giá trị cuối cùng quy về ai, xuất hiện có phải sự thật biến, máy cuối cùng có một chút ý thức không, ngữ cảnh dài có ăn mất RAG không – những tranh luận năm đó, đến năm 2026 vẫn là tranh luận. Có thể phân biệt "đã có câu trả lời" và "còn phải tiếp tục đợi", quan trọng hơn việc vội vàng đưa ra kết luận cho mỗi sự việc.
Wang Jianshuo ba năm trước, dựa vào trực giác trong sương mù GPT-4 chưa ra chỉ hai mươi hướng. Hôm nay đối chiếu xong, câu đáng ghi nhớ nhất có lẽ là: nhìn đúng hướng lớn thực ra không khó như vậy, khó là thừa nhận mình ở số, tốc độ và phân bố lần này đến lần khác suy nghĩ đương nhiên. Hai mươi nhận định này, thay vì nói là cho điểm quá khứ, không bằng nói là đặt vài quy tắc cho ba năm tới. Ba năm tiếp theo, năm 2029 lại đến đối một lần nữa.