Polygon has pulled ahead of Ethereum in daily transaction fees, and that doesn’t happen very often. If this pace continues, February could turn out to be a surprisingly strong month for Polygon!
Activity is picking up!
Polygon has pulled off a big win, overtaking Ethereum [ETH] in daily transaction fees! Recent data showed Polygon’s [POL] fees crossing $300K, a jump that proves rising network usage.
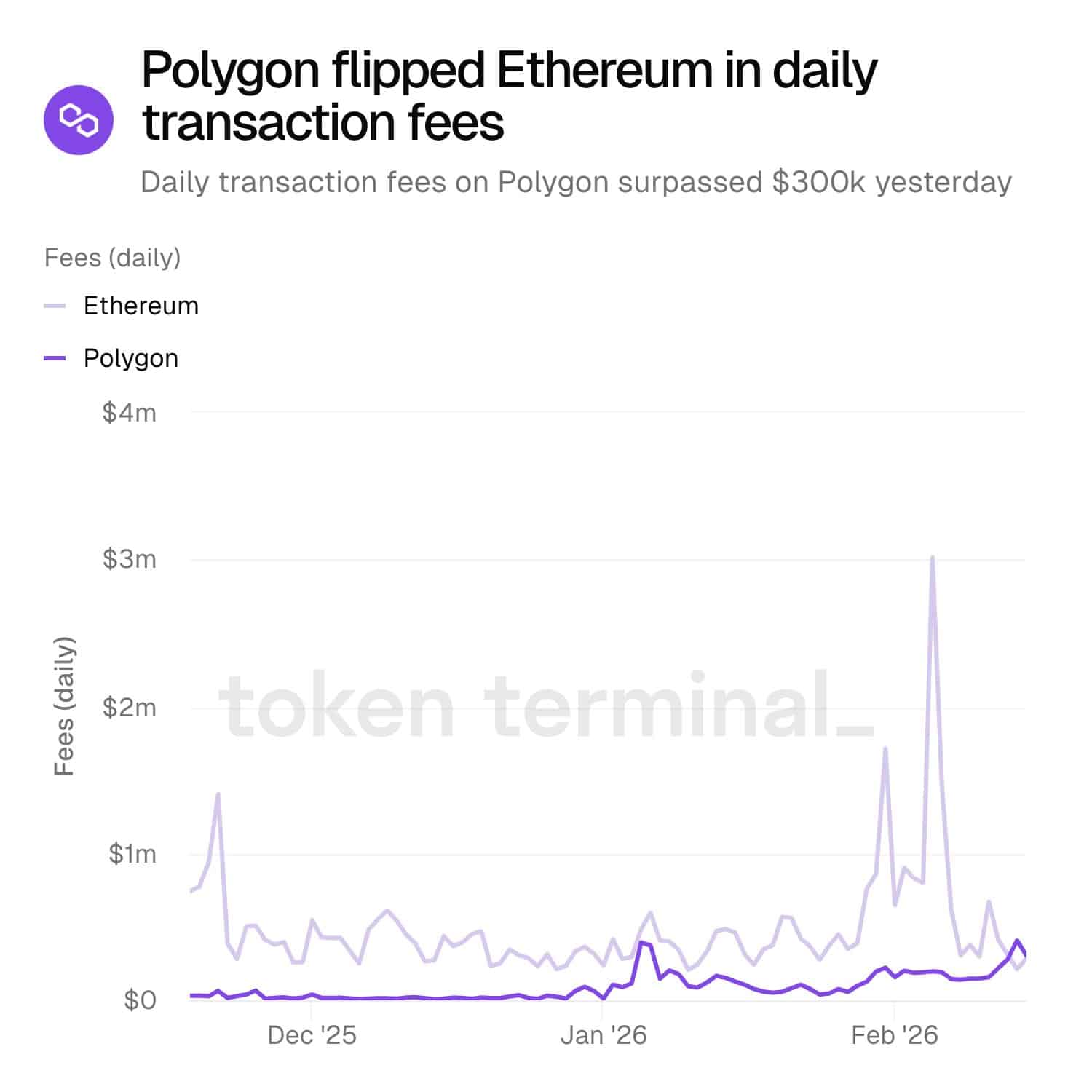
Source: X
This pace wasn’t limited to fees either.
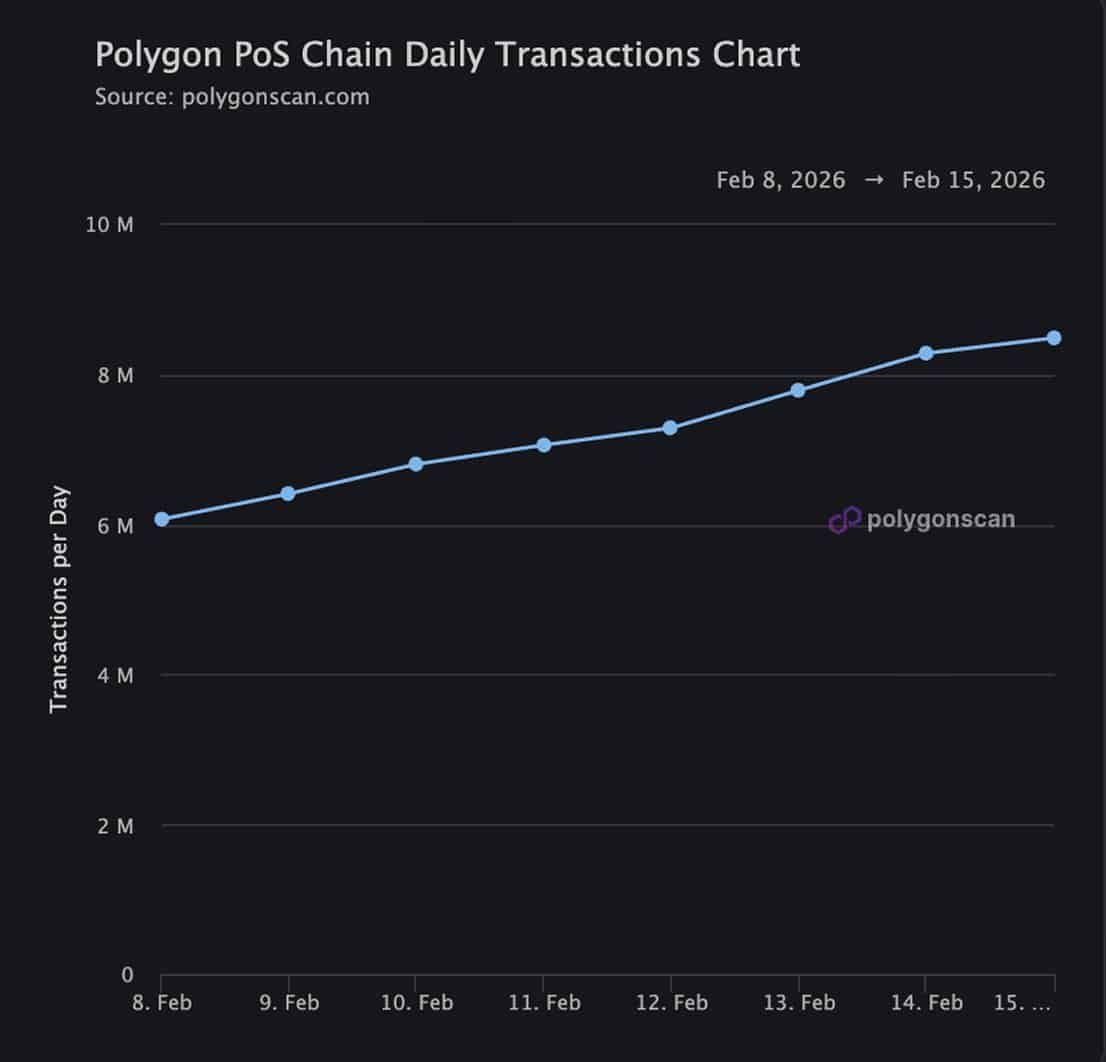
Source: X
Daily transactions on Polygon have climbed over the past week, rising about 50% in just seven days.
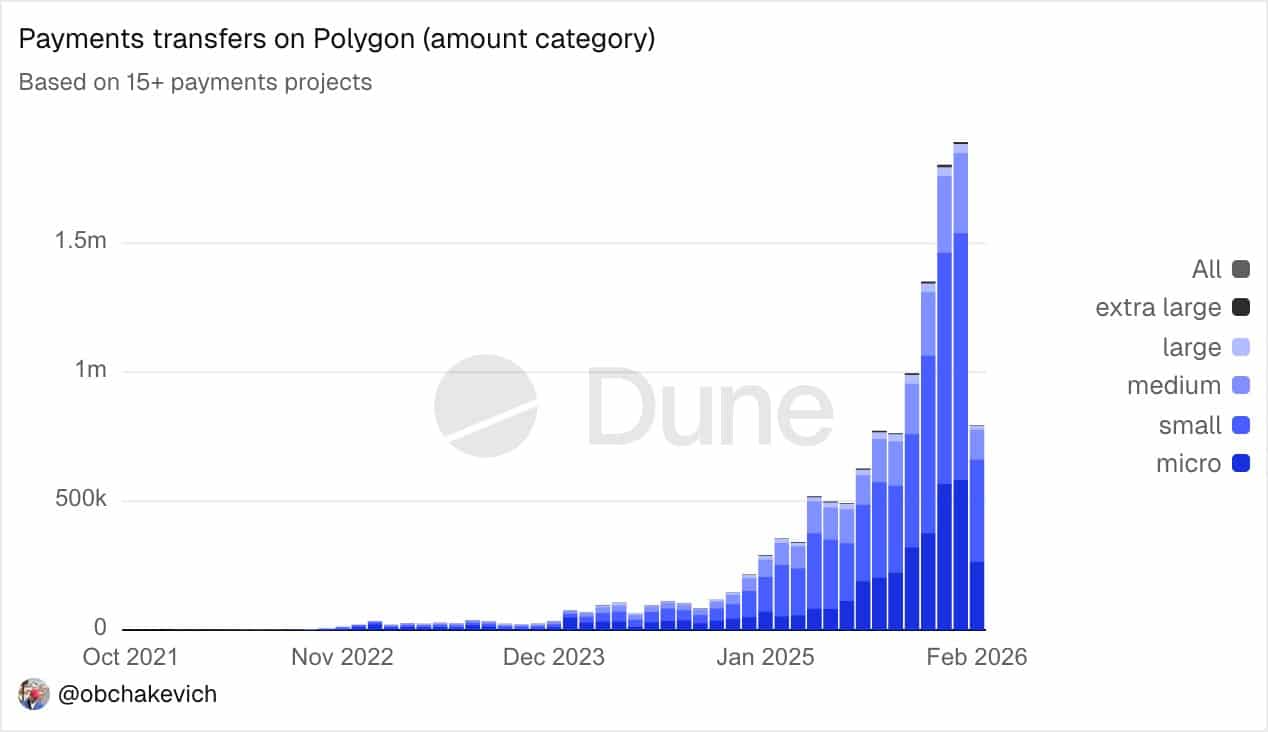
Payments play a big role
Share
- Share
- Tweet
-






