Tác giả | Vương Bác, Giáp Tử Quang Niên
"Giáp Tử Quang Niên" nhận được thông tin từ nguồn tin gần gũi với DeepSeek, rằng DeepSeek đang tổ chức nội bộ một nhóm Harness mới, hướng đến sản phẩm trí tuệ nhân tạo về mã nguồn, đối đầu nội bộ với Claude Code của Anthropic.
Nhà nghiên cứu kỳ cựu của DeepSeek, Trần Đức Lý, gần đây cũng đăng thông tin trên mạng xã hội xác nhận sự việc này, anh ấy nói "DeepSeek đang tổ chức một nhóm Harness mới để làm sản phẩm và nghiên cứu về hướng Harness", và thẳng thắn nói "Nói đơn giản là đối đầu với Claude Code, làm DeepSeek Code Harness".
Đây không phải là một đợt tuyển dụng thông thường.
Thông tin tuyển dụng cho thấy, DeepSeek lần này mở ra hai vị trí then chốt: Quản lý sản phẩm Harness và Kỹ sư phát triển Harness, địa điểm làm việc hiện tại chỉ giới hạn ở Bắc Kinh. Văn phòng của DeepSeek ở Bắc Kinh nằm tại Trung tâm Thông tin Rongke, quận Hải Điện, rất gần với Đại học Bắc Kinh và Đại học Thanh Hoa. Trong cách nói chính thức, nơi đây nằm ở "Vành đai đổi mới AI Bắc Kinh - Trương Gia Khẩu trăm năm", còn trong cách nói dân gian, nơi đây cũng nằm trong khu vực "Vương Huệ Văn" đang rất nổi gần đây.


Định nghĩa cốt lõi: Model + Harness = Agent
Trong mô tả vị trí, một công thức cốt lõi được đặt ở vị trí nổi bật nhất:
Câu nói này gần như có thể coi là định nghĩa nội bộ của DeepSeek về con đường sản phẩm hóa giai đoạn tiếp theo: bản thân mô hình chỉ là nền tảng của Agent, phần ngoài mô hình như quản lý ngữ cảnh, gọi công cụ, lập kế hoạch nhiệm vụ, đọc ghi tệp, sửa đổi mã, thực thi terminal, thu hồi phản hồi, vòng lặp đánh giá, mới là phần then chốt để Agent thực sự có thể đi vào quy trình công việc.
Thông tin tuyển dụng viết thêm: "Chúng tôi đang chuyển hóa khả năng mô hình tiên phong của DeepSeek thành sản phẩm Agent hàng đầu. Tất cả công việc ngoài bản thân mô hình đều thuộc phạm vi của Harness." Ngoài ra, vị trí này sẽ tham gia toàn bộ quá trình của "sản phẩm Agent phiên bản desktop của DeepSeek" và "định nghĩa sự hiểu biết của DeepSeek về Harness".
"Giáp Tử Quang Niên" phân tích, DeepSeek không đơn giản muốn làm một plugin trợ lý viết mã, mà là đang bổ sung lớp trung gian để mô hình thông suốt đến quy trình công việc thực tế.
Một năm qua, ngành công nghiệp đã chứng minh: khả năng về mã mạnh, không có nghĩa là nhà phát triển sẽ thực sự sử dụng; mô hình có thể viết mã, cũng không có nghĩa là nó có thể liên tục hoàn thành một nhiệm vụ kỹ thuật.
Thứ thực sự thay đổi cách làm việc của nhà phát triển, không phải là mô hình Claude riêng lẻ, mà là Claude Code; không phải là mô hình GPT riêng lẻ, mà là Codex; không phải là một câu trả lời mã trong khung chat, mà là một trí tuệ nhân tạo kỹ thuật có thể đi vào terminal, hiểu dự án, đọc ghi tệp, chạy lệnh, sửa lỗi, quản lý Git, gọi công cụ.
Trước đây, DeepSeek mạnh nhất là về mô hình. Bây giờ, nó bắt đầu bổ sung lớp "tay" trên mô hình đó.
Một. Tại sao DeepSeek nhấn mạnh Harness?
Trong ngữ cảnh sản phẩm AI truyền thống, "trợ lý viết mã" thường có nghĩa là hai loại sản phẩm: một là plugin tự động hoàn thành trong IDE, hai là hỏi đáp mã trong khung chat.
Nhưng từ lặp đi lặp lại trong đợt tuyển dụng này của DeepSeek không phải là Code Assistant, mà là Harness.
Harness vốn trong ngữ cảnh kỹ thuật chỉ "khung kiểm tra" hoặc "khung chạy", đặt trong ngữ cảnh Agent, nó gần giống hơn với một hệ thống bên ngoài giúp mô hình thực sự hành động. Mô hình chịu trách nhiệm hiểu, suy luận và tạo ra, Harness chịu trách nhiệm kết nối những khả năng này vào môi trường thực tế.
Mô tả vị trí đề cập, vai trò này cần lập kế hoạch lộ trình sản phẩm Harness của DeepSeek, kết nối nhà nghiên cứu, kỹ sư, cộng đồng mã nguồn mở với người dùng cuối, và giao tiếp sâu với nhà nghiên cứu của nhóm huấn luyện mô hình, thực hiện sự tiến hóa chung của mô hình và Harness.
Câu nói này rất quan trọng.
Nó cho thấy những gì DeepSeek muốn làm không chỉ là bọc một lớp vỏ cho mô hình hiện có, mà là biến bản thân sản phẩm Agent thành một phần của quá trình tiến hóa mô hình. Trước đây, logic sản phẩm phổ biến của các công ty mô hình lớn là: nhóm nghiên cứu trước tiên huấn luyện một mô hình, nhóm sản phẩm sau đó dựa trên khả năng mô hình để làm ứng dụng. Nhưng trong thời đại Agent, trình tự này đang bị phá vỡ. Sản phẩm không còn chỉ là đầu ra của khả năng mô hình, mà là nơi huấn luyện khả năng mô hình.
Một Agent mã trong dự án thực tế thất bại, có thể không phải là vấn đề tương tác sản phẩm, mà là cách thức nén ngữ cảnh dài của mô hình không đúng; có thể không phải là vấn đề chuỗi gọi công cụ, mà là chiến lược phân giải nhiệm vụ của mô hình không ổn định; cũng có thể không phải là khả năng mã không đủ, mà là nó thiếu sự hiểu biết liên tục về ràng buộc kỹ thuật, phản hồi kiểm tra và ý định người dùng.
Vì vậy, giá trị của nhóm Harness không chỉ là "làm sản phẩm", mà là biến nhiệm vụ phát triển thực tế thành nguồn phản hồi cho sự tiến hóa liên tục của mô hình.
Hai. Tại sao DeepSeek phải bổ sung Code Harness?
DeepSeek đã sớm đặt cược vào khả năng về mã. Từ DeepSeek-Coder đến DeepSeek-Coder-V2, sự đầu tư của DeepSeek vào mô hình mã liên tục được tăng cường, hỗ trợ ngôn ngữ, độ dài ngữ cảnh và khả năng nhiệm vụ phức tạp không ngừng được nâng cao. Vấn đề của nó không phải là không có khả năng về mã, mà là trước đây phần khả năng này chủ yếu dừng lại ở lớp mô hình, chưa biến thành sản phẩm tần suất cao trong quy trình công việc hàng ngày của nhà phát triển.
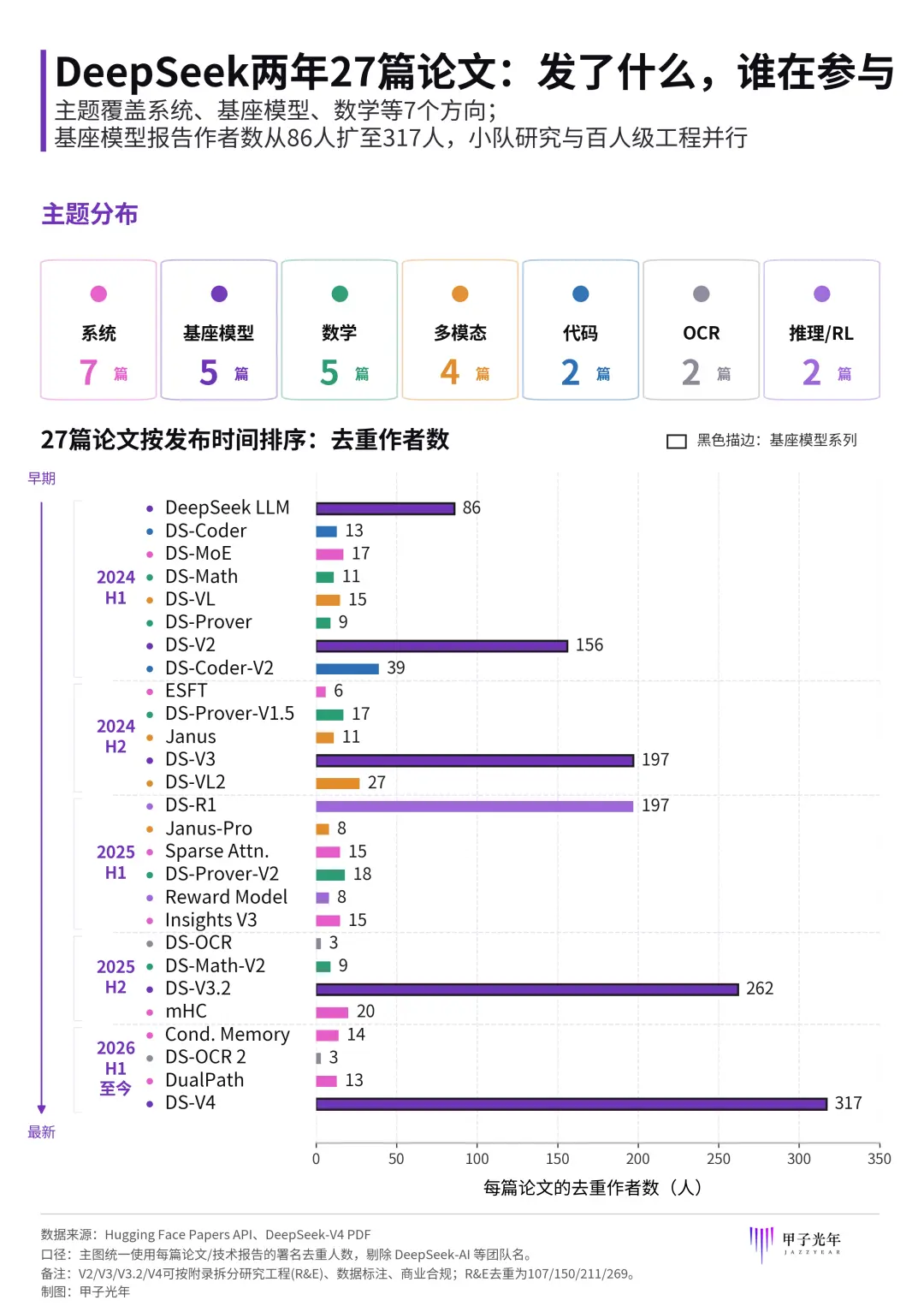
Sự nổi tiếng của Claude Code đã chứng minh một điều: Cạnh tranh AI Coding đang chuyển từ cạnh tranh khả năng mô hình, sang cạnh tranh cửa ngõ vào quy trình công việc của nhà phát triển.
Đây cũng là bài học mà DeepSeek hiện tại phải bổ sung. Tinh tế hơn, trước khi DeepSeek chính thức ra tay, cộng đồng nhà phát triển đã thay nó làm một phiên bản "Claude Code phiên bản DeepSeek".
Một dự án mã nguồn mở tên là DeepSeek-TUI trước đó đã nổi tiếng trong cộng đồng nhà phát triển. Nó là một coding agent chạy trong terminal, có thể đọc ghi tệp, thực thi lệnh Shell, tìm kiếm web, quản lý Git, và thông qua giao diện TUI để phối hợp các sub-agent.
Sự nổi tiếng của DeepSeek-TUI nói lên hai vấn đề:
-
Tâm trí cơ bản đã trưởng thành: Mô hình DeepSeek trong tâm trí nhà phát triển đã có nền tảng để làm Agent mã. Nếu không cộng đồng sẽ không tự nhiên mọc ra sản phẩm kiểu Claude Code xung quanh nó.
-
Sự thiếu hụt ở cấp độ chính thức: DeepSeek thiếu không phải là sự chú ý về mô hình, mà là Harness chính thức.
Trong mắt nhà phát triển, sức hấp dẫn của DeepSeek-TUI rất trực tiếp: chi phí thấp, có thể sử dụng trong nước, ngữ cảnh dài, ngưỡng triển khai tương đối thấp. Nhiều nhà phát triển trong nước không phải không muốn dùng Claude Code, mà là bị hạn chế bởi giá cả, ổn định truy cập, hệ thống tài khoản và tuân thủ doanh nghiệp.
Nhưng dự án cộng đồng cũng có ranh giới tự nhiên:
-
Một dự án mã nguồn mở của bên thứ ba dù có tích cực đến đâu, cũng rất khó thực sự nắm bắt nhịp độ tiến hóa nội bộ của mô hình;
-
Nó có thể làm thích ứng xung quanh API, nhưng không thể quyết định ngược lại mô hình sẽ được huấn luyện như thế nào;
-
Nó có thể làm prompt, chuỗi công cụ và tối ưu hóa tương tác, nhưng rất khó đưa phản hồi nhiệm vụ thực tế với số lượng lớn vào cải tiến mô hình một cách có hệ thống.
Ý nghĩa của Harness chính thức nằm chính xác ở đây.
DeepSeek tự làm Code Harness, nó có một số lợi thế mà dự án cộng đồng không có: hợp tác nhóm mô hình, quyền thiết kế giao diện, vòng lặp dữ liệu huấn luyện, cảnh nhiệm vụ thực tế nội bộ, và khả năng vận hành lâu dài hệ sinh thái nhà phát triển.
Cộng đồng mã nguồn mở đã dọn đường trước: nhà phát triển thực sự cần một phiên bản Claude Code của DeepSeek. Bây giờ, DeepSeek muốn thu hồi con đường này, biến nó thành sản phẩm chính thức của mình.
Và việc DeepSeek chính thức bắt đầu tuyển người, có nghĩa là cuối cùng nó đã chuẩn bị tự mình xuống sân.
Trần Đức Lý vào tháng 11 năm ngoái tại Hội nghị Thế giới Internet Ô Trấn 2025 đã đề cập: "Một lợi thế cốt lõi của công ty chúng tôi là chủ nghĩa dài hạn, kiên trì làm chủ tuyến đột phá trí tuệ tiên phong. Trong quá trình này, chúng tôi cũng từ bỏ nhiều việc trên các tuyến phụ, không làm những việc ngắn hạn, nhanh chóng trên tuyến phụ."
Sau chiến tranh mô hình, cuộc chiến Agent thực sự đã bắt đầu. Lần này DeepSeek cần bổ sung là lớp then chốt nhất từ mô hình đến hành động - Harness.
DeepSeek đang lắp đôi tay cho mô hình của mình.





