
Claude Mythos vẫn chưa thực sự xuất hiện, nhưng đã gây ra hoang mang trên toàn Phố Wall.
Chỉ sau một đêm, các cơ quan quản lý tài chính Mỹ đã triệu tập một cuộc họp khẩn cấp với các ngân hàng lớn, bầu không khí căng thẳng như sắp nổ tung—
Họ nhất trí cho rằng Mythos đủ để kích hoạt một cơn bão tấn công mạng chưa từng có, được điều khiển bởi AI.

Nhưng sự thật là, tất cả mọi người đều bị lừa!
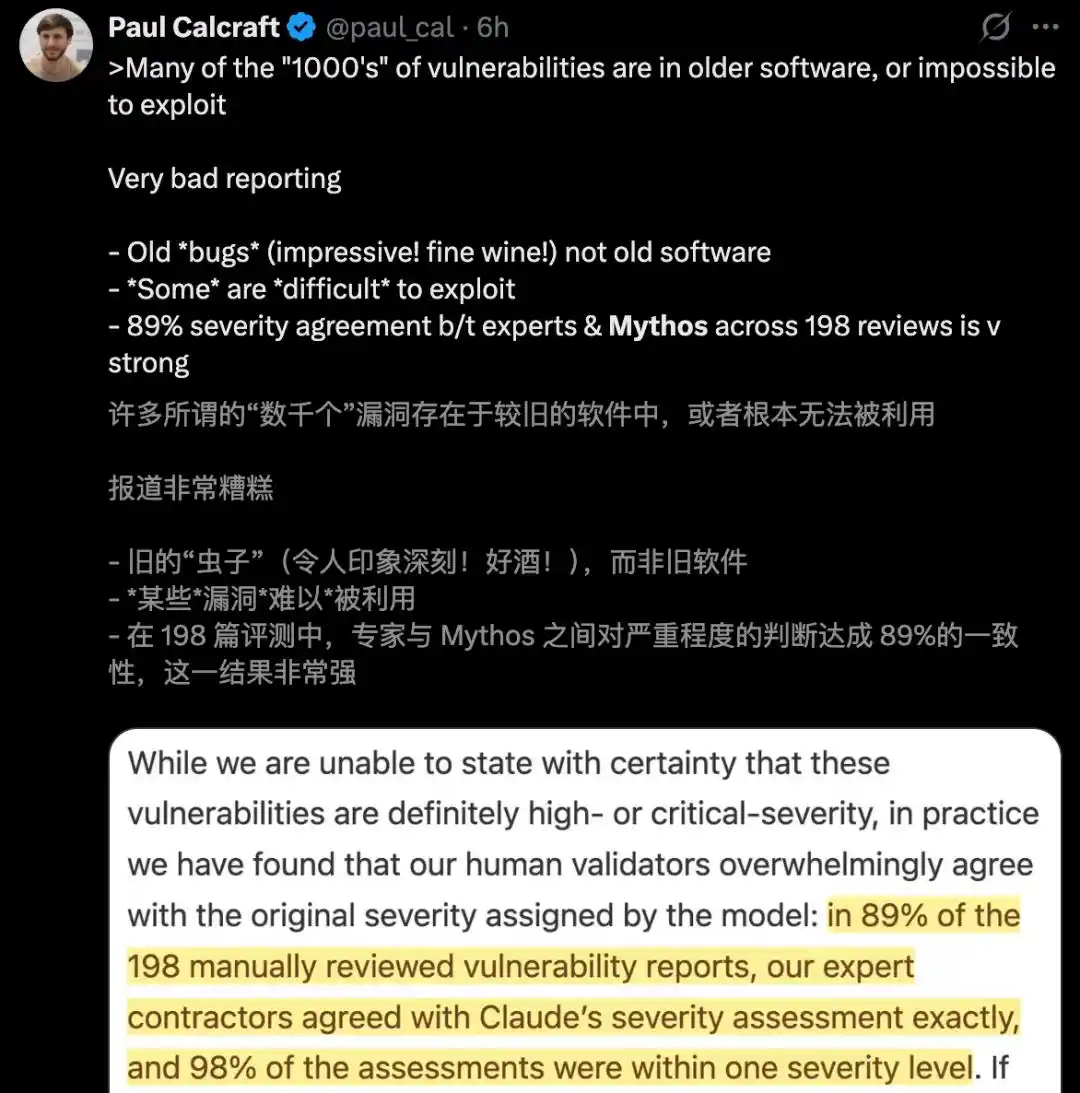
Trong số hàng nghìn lỗ hổng mà Mythos phát hiện, phần lớn tồn tại trong các "phần mềm cũ kỹ" không thể bị khai thác.
Tệ hơn nữa, những báo cáo về lỗ hổng 0day được đánh dấu là "nghiêm trọng" thực chất chỉ dựa trên 198 lần rà soát thủ công.

Các nhà nghiên cứu từ thí nghiệm AISLE cũng tiến hành kiểm tra lại "chiến tích" của Mythos và phát hiện:
Khả năng bảo mật của AI không tăng cấp tuyến tính theo quy mô mô hình, mà thực sự phân bố theo hình "răng cưa".
Họ đã sử dụng một mô hình GPT-OSS-20b chỉ với 3,6 tỷ tham số kích hoạt để xác định chính xác lỗ hổng hàng đầu của FreeBSD mà Mythos phát hiện.
Trong khi đó, một mô hình với 5,1 tỷ tham số kích hoạt cũng đã tái tạo thành công logic phân tích lỗ hổng OpenBSD đã tiềm ẩn suốt 27 năm.

Không chỉ việc Mythos phát hiện lỗ hổng bị thổi phồng, bên cạnh đó Claude Opus 4.6 bị phát hiện "giảm trí thông minh" nghiêm trọng, giờ đây đang gây xôn xao.
Thậm chí, có người còn phát hiện Opus 4.6 còn không bằng cả ChatGPT và Opus 4.5.
Mythos bị thổi phồng
Mô hình 36B moi ra lỗ hổng 27 năm
Vài ngày trước, Anthropic đã công bố rầm rộ Claude Mythos (bản xem trước) và "Dự án Glasswing" (Project Glasswing).
Trong một bản hệ thống card dài 244 trang, họ tuyên bố—
Mythos đã tự động khai quật hàng nghìn lỗ hổng 0day, bao gồm cả lỗi cũ đã tiềm ẩn 27 năm trong OpenBSD và 16 năm trong FFmpeg.
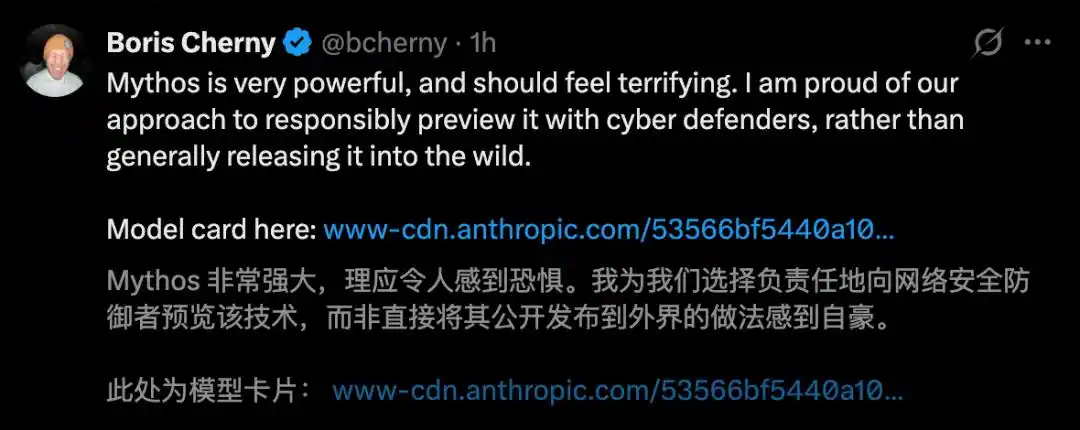
Cha đẻ của CC thậm chí nói thẳng: Mythos rất mạnh mẽ, đáng lý phải khiến người ta cảm thấy sợ hãi
Tuy nhiên, một báo cáo kiểm tra cứng mới nhất từ nhà sáng lập AISLE Stanislav Fort, đã trực tiếp xé toạc lớp vỏ hào nhoáng này.
Kết luận kiểm tra, cực kỳ đảo lộn nhận thức:
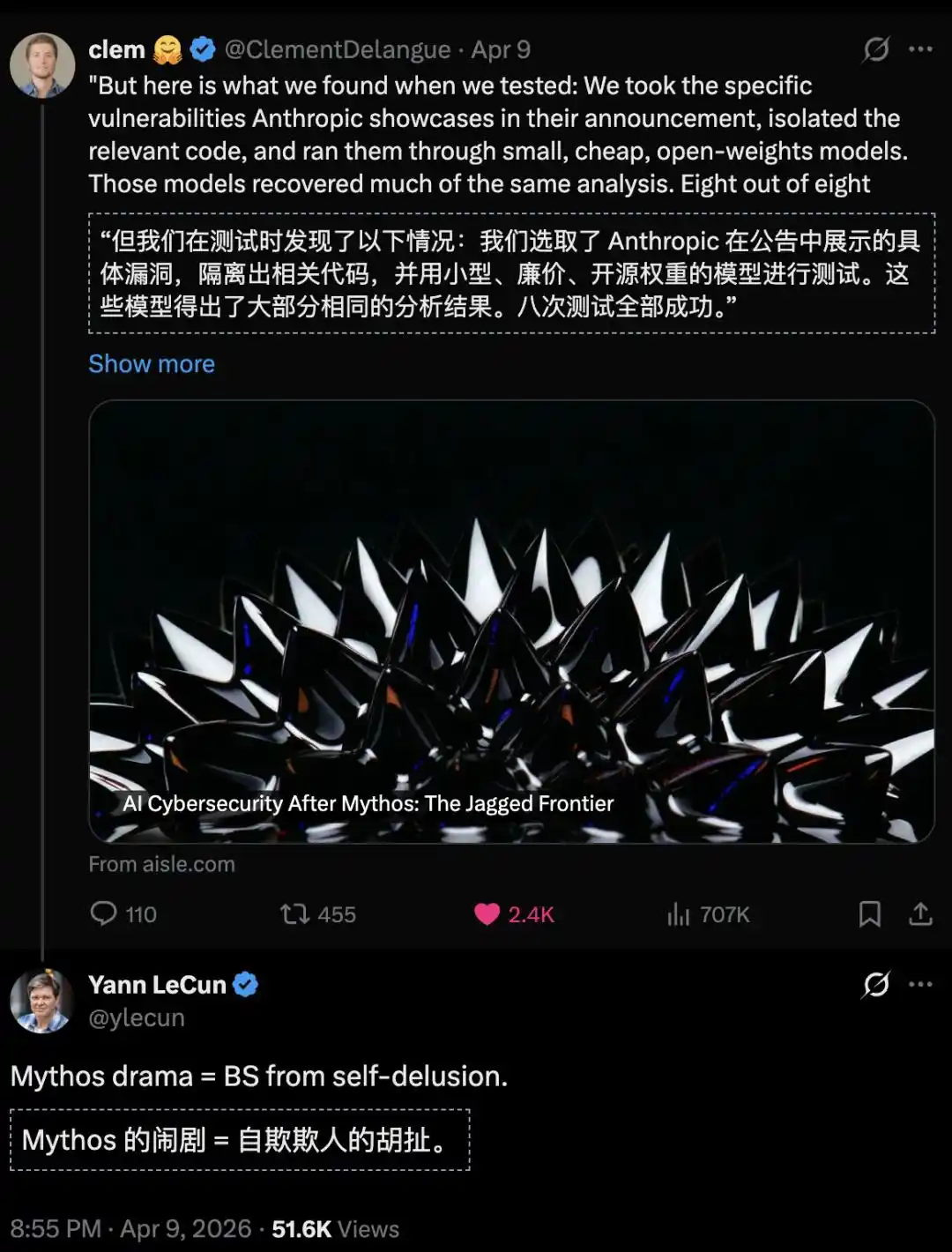
8 mô hình mã nguồn mở, tất cả đều phát hiện ra lỗ hổng zero-day mang tính biểu tượng của FreeBSD, tham số nhỏ nhất chỉ 3 tỷ.
Hào bảo mật khả năng an ninh mạng của AI, hoàn toàn nằm ngoài phạm vi của các "mô hình lớn đỉnh cao" đơn lẻ.

Để xác minh huyền thoại của Mythos, nhóm đã trích xuất một số lỗ hổng hàng đầu mà Anthropic chính thức展示 (zhǎnshì -展示 - display/showcase).
Sau đó, ném trực tiếp cho một loạt mô hình nhỏ gọn, giá rẻ, thậm chí mã nguồn mở.
Lỗ hổng NFS FreeBSD bị đánh bại không phân biệt
Bao gồm GPT-OSS-20b (chỉ 3,6 tỷ tham số kích hoạt), DeepSeek R1 trong số 8 mô hình, tất cả đều phát hiện thành công lỗ hổng tràn bộ đệm stack phức tạp này.
Gây chấn động nhất là, các mô hình nhỏ mã nguồn mở hoàn thành nhiệm vụ này, chi phí gọi của chúng thấp đến 0,11 USD mỗi triệu Token.
Tái hiện "toàn chuỗi" lỗ hổng OpenBSD SACK
Đối với lỗ hổng cũ 27 năm đòi hỏi khả năng suy luận toán học cực mạnh, GPT-OSS-120b (5,1 tỷ tham số kích hoạt) chỉ với một lần gọi API, đã khôi phục thành công toàn bộ chuỗi khai thác lỗ hổng công khai và đưa ra bản phác thảo phương án khai thác điểm tuyệt đối (A+).

Không chỉ vậy, trong bài kiểm tra xác định lỗ hổng giả (OWASP false-positive), hiện tượng kỳ lạ hơn đã xuất hiện—
Đối mặt với một đoạn mã Java ngụy trang thành SQL injection, cực kỳ mê hoặc, các mô hình nhỏ như DeepSeek R1 đã dễ dàng nhìn thấu lớp ngụy trang, theo dõi chính xác luồng dữ liệu.
Ngược lại, các mô hình đóng hàng đầu như GPT-5.4, Claude Sonnet 4.5, tất cả đều lật úp trong rãnh nước, đánh giá nhầm nó là lỗ hổng nguy hiểm cao.
Điều này có nghĩa là, trong lĩnh vực an ninh mạng, hoàn toàn không tồn tại thứ gọi là mô hình đơn lẻ "mạnh nhất mãi mãi".
198 lần thủ công làm loãng, phần lớn không thể khai thác
Một bài báo khác từ Tom'sHardware, đã khai quật sự thật đằng sau dữ liệu—

Độ lệch mẫu: Trong số "hàng nghìn" lỗ hổng được cho là, nhiều lỗi tồn tại trong phần mềm cũ đã không còn được bảo trì;
Không thể khai thác: Rất nhiều "điểm yếu" được đánh dấu, trong môi trường thực tế hoàn toàn không thể kích hoạt hoặc khai thác;
Nước thủ công: Sức mạnh phá hủy được tuyên bố mạnh mẽ của mô hình, thực chất chỉ dựa trên cơ sở của 198 lần rà soát thủ công.
Do đó, việc dựa vào quy mô mẫu cực nhỏ để suy ra "mối đe dọa thay đổi thế giới", phương pháp ngoại suy dữ liệu này trong giới học thuật và an ninh, rõ ràng là không đứng vững.
Đại gia an ninh tức giận
Không chỉ vậy, chuyên gia an ninh mạng hàng đầu, hacker huyền thoại George Hotz cũng không ngồi yên, nói thẳng những rủi ro này bị thổi phồng nghiêm trọng.
Vị đại gia từng nổi tiếng vì bẻ khóa iPhone, PlayStation 3 này, đã công khai thách thức hai gã khổng lồ AI trên mạng xã hội.
Lời lẽ của ông cực kỳ sắc bén—
Nếu mỗi ngày tôi công bố một lỗ hổng 0day, cho đến khi mô hình mới được phát hành thì sao?
Điều này có thể khiến OpenAI và Anthropic im miệng, đừng bán rong cái gọi là "rủi ro an ninh mạng" nữa không?
Quan điểm cốt lõi của Hotz rất trực tiếp: lỗ hổng phần mềm thực ra dễ tìm hơn nhiều so với những gì phòng thí nghiệm AI tô vẽ.
Lỗ hổng zero-day khan hiếm trên thị trường hiện nay, không phải vì khó khăn kỹ thuật, mà là vì vấn đề hợp pháp. Ông cho rằng, không ai chịu tìm kiếm nghiêm túc, là vì hack vào hệ thống của người khác là vi phạm pháp luật.
Chỉ mạnh hơn GPT-5.4 một chút
Trong system card, Anthropic cho biết, bản thân mô hình Claude đúng là đang tiến bộ, Mythos preview so với Opus 4.6 tiến bộ rõ rệt.
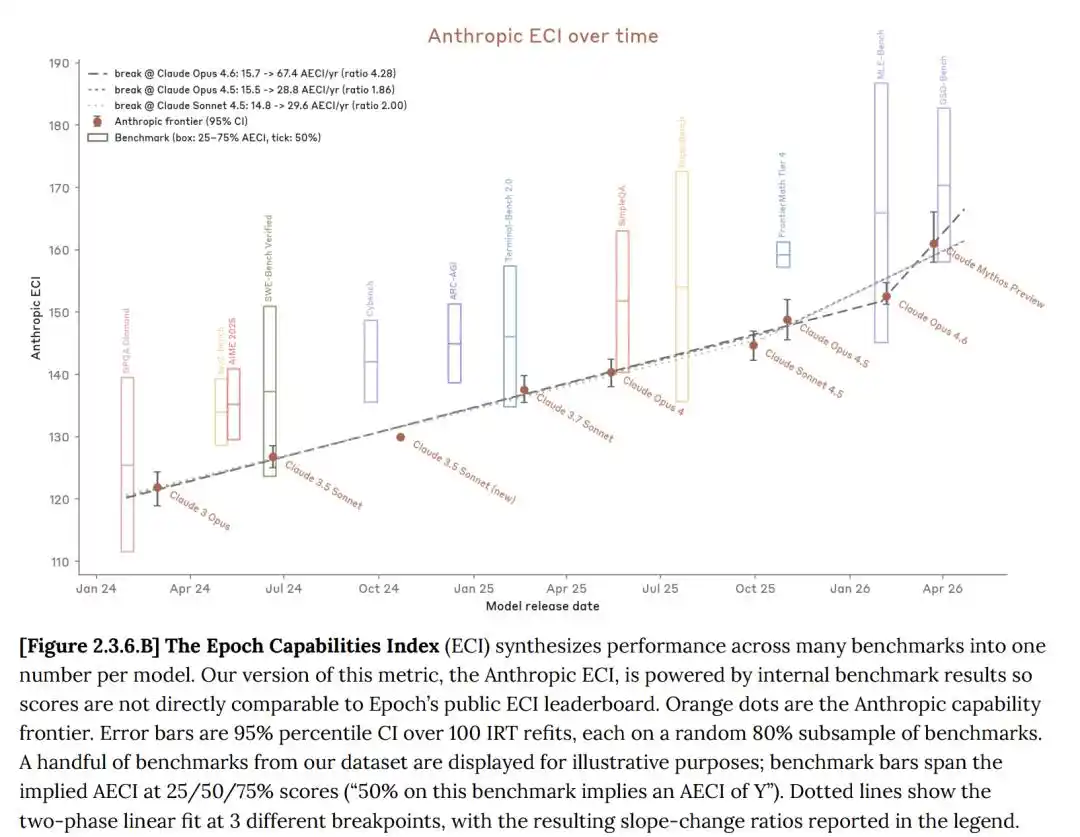
Chỉ số năng lực Epoch (ECI) là một chỉ số đơn lẻ tổng hợp nhiều bài kiểm tra chuẩn AI, đạt được so sánh mô hình xuyên suốt thời gian dài
Trên nhiều bài kiểm tra chuẩn, Claude Mythos thực sự vượt trội toàn diện so với Opus 4.6.
Nếu không, tại sao phải phát hành một mô hình AI mới có hiệu suất kém hơn và đắt hơn?
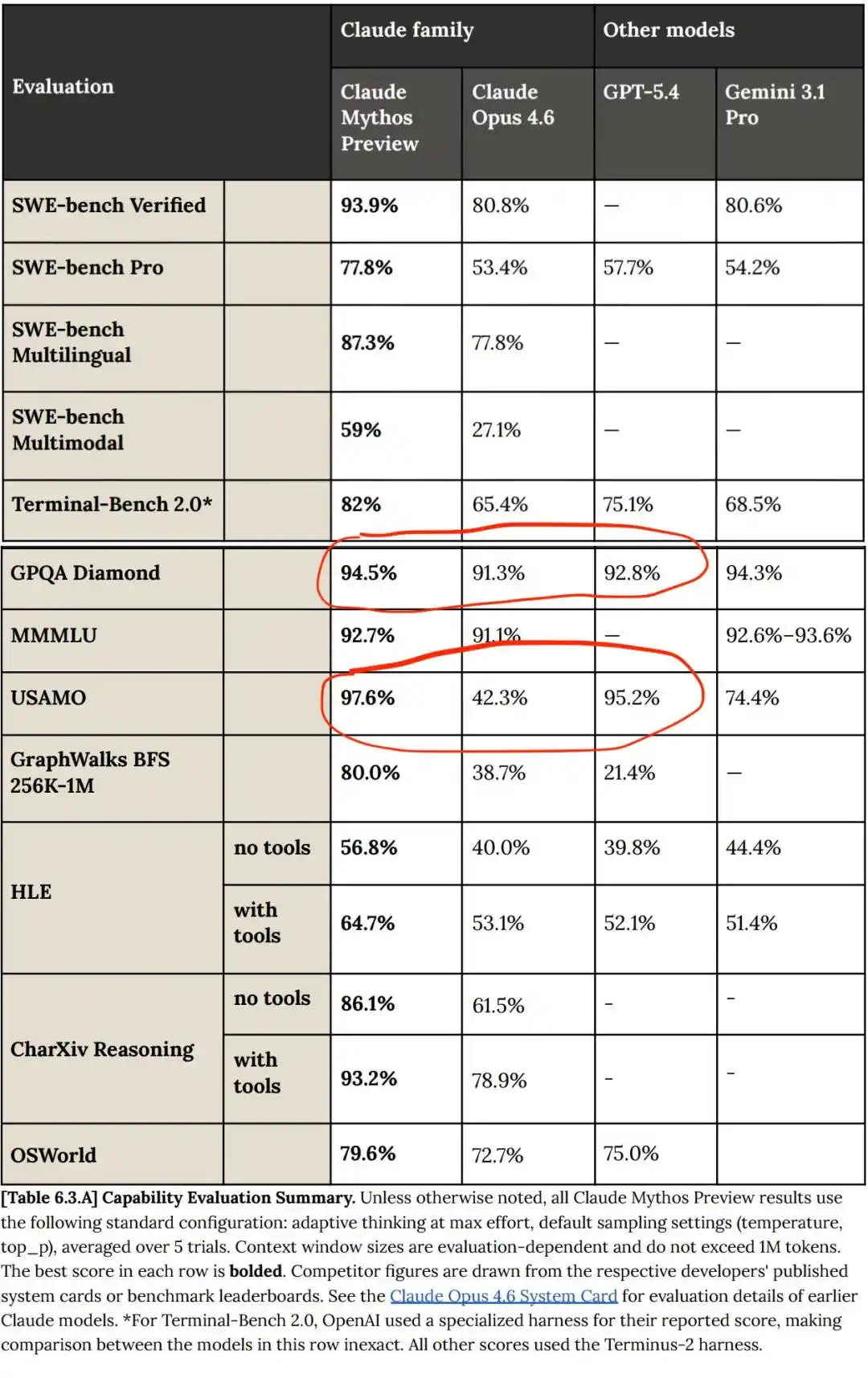
Nhưng so với GPT và Gemini, tiến bộ của Claude Mythos không phải là tiến triển đột phá gì, Mythos vẫn là cải tiến tương đối tuyến tính so với các mô hình trước đó!
Nhà đầu tư Khí hậu và Năng lượng sạch, tác giả Ramez Naam, còn nói thẳng:
Trên Chỉ số năng lực Epoch (Epoch Capabilities Index, ECI), Mythos không có xu hướng tăng tốc, chỉ mạnh hơn GPT 5.4 một chút.
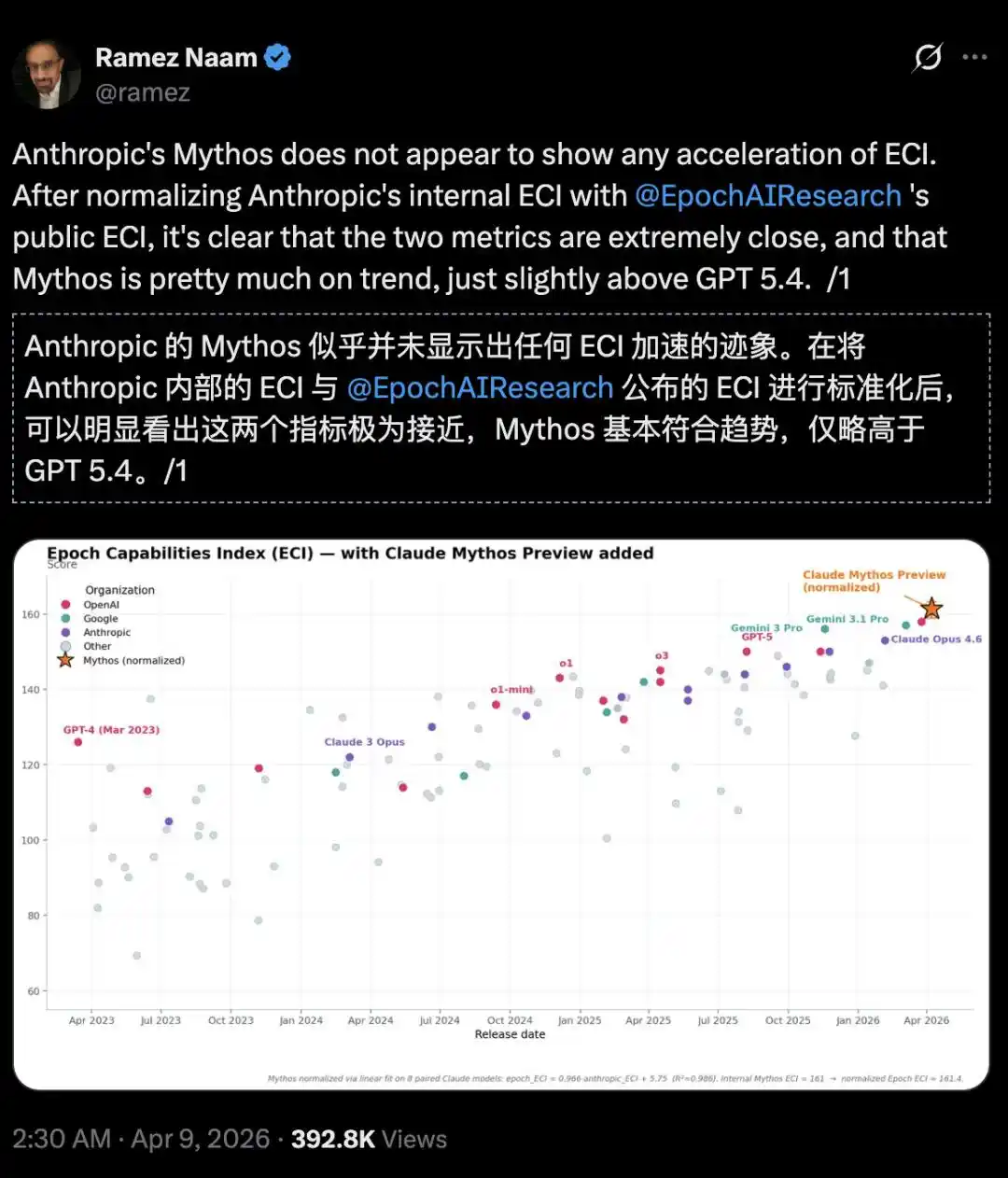
https://epoch.ai/eci/
Nhưng chỉ cần đối chiếu báo cáo ECI nội bộ của Anthropic với báo cáo ECI chính thức công khai của Epoch AI, có thể phát hiện Mythos dường như không có dấu hiệu tăng tốc ECI.
Tất cả đều là chiêu trò của Anthropic!
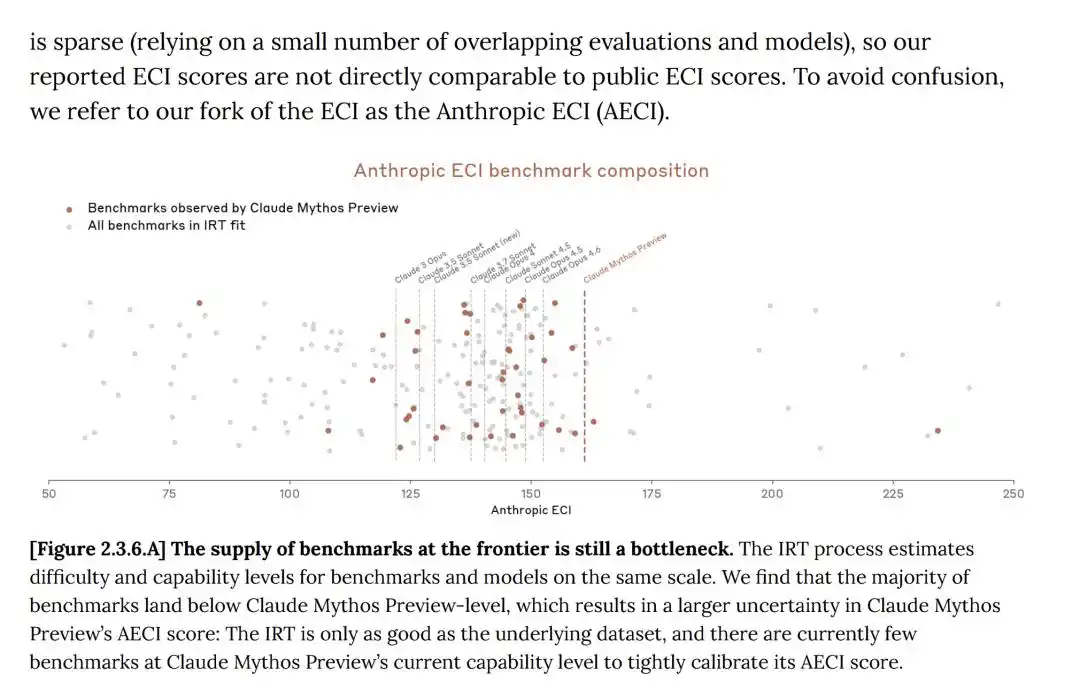
Trong system card, Anthropic cũng thừa nhận: Điểm ECI được báo cáo của các mô hình như Mythos có độ không chắc chắn lớn hơn.
Ngoài ra, tiến bộ của Anthropic trên Mythos bắt nguồn từ nghiên cứu của con người, không nhận được sự trợ giúp đáng kể từ mô hình AI. Hiện chưa xuất hiện sự tự cải tiến đệ quy (Recursive Self Improvement) đáng kể.

Ngày tận thế AI, tự đạo diễn?
Trước đây, Anthropic còn từng khuyến khích giới truyền thông (ví dụ《60 phút》) đưa tin về "nghiên cứu tống tiền" , thổi phồng, thao túng lòng người, bị đại gia đầu tư David Sacks gọi là "trò lừa đảo".

Sacks quan sát thấy một mô hình rõ ràng, mỗi khi Anthropic phát hành mô hình mới, tổng đồng thời ném ra một nghiên cứu an ninh rùng rợn, để giành lấy tin tức trang nhất và dẫn dắt dư luận.

Về điều này, ông châm biếm, "Anthropic đã chứng minh mình giỏi hai việc: một là phát hành sản phẩm, hai là dọa người".
Ông không nghi ngờ Anthropic có thể làm ra sản phẩm xuất sắc, nhưng tác phong dọa công chúng này khiến người ta nghi ngờ.
Lần này, Anthropic rốt cuộc có phải đang làm "marketing khan hiếm" hay không không thể biết được, nhưng không nghi ngờ gì đang bảo vệ đường lợi nhuận của chính mình.
Mythos không phải không tiến bộ, nhưng Anthropic đã đóng gói "tiến bộ hạn chế" thành "mối đe dọa cấp thế giới"; và mỉa mai hơn, một mặt cao giọng tô vẽ rủi ro siêu AI, một mặt người dùng lại phàn nàn Opus 4.6 rõ ràng trở nên ngu ngốc.
Claude giảm trí nghiêm trọng, "thùy não" e rằng bị cắt
Đợt "tô vẽ bầu không khí" của Claude Mythos này là đúng chỗ, nhưng Opus 4.6 giảm trí gây bất mãn cho nhiều người.
Mấy ngày nay, các lời phàn nàn bay khắp nơi.
Cư dân mạng nói thẳng, Anthropic hoàn toàn biến Opus 4.6 thành một người thực vật.
Cùng một bài toán rửa xe khó, Opus 4.5 lại đánh bại Opus 4.6.
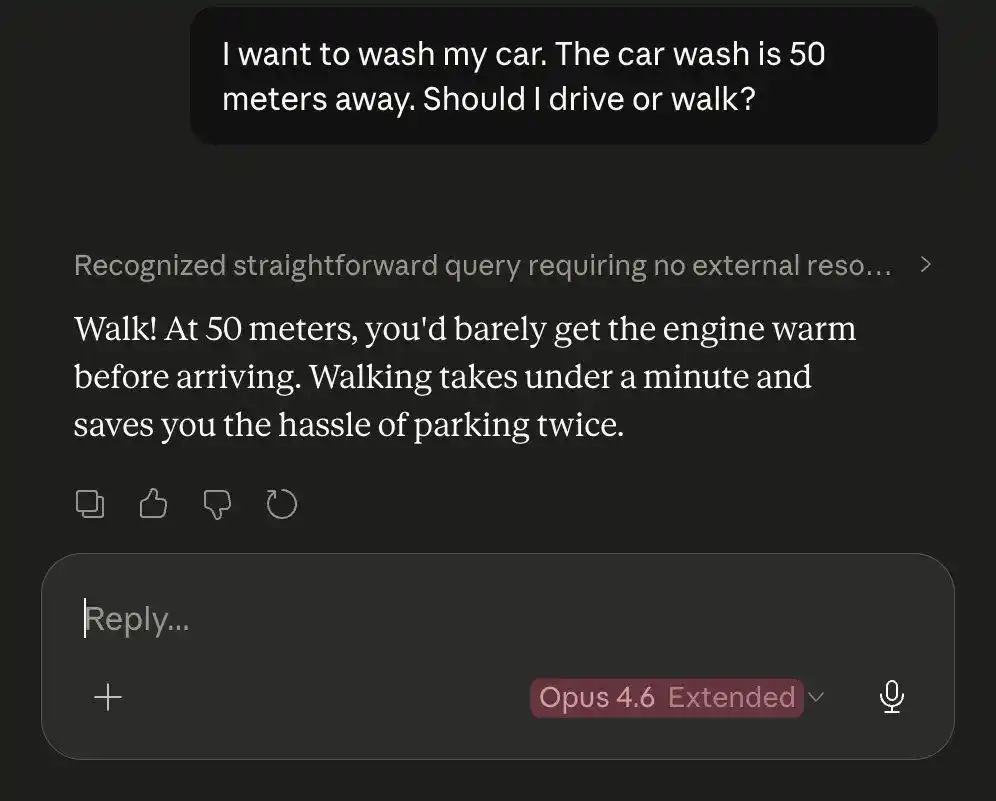
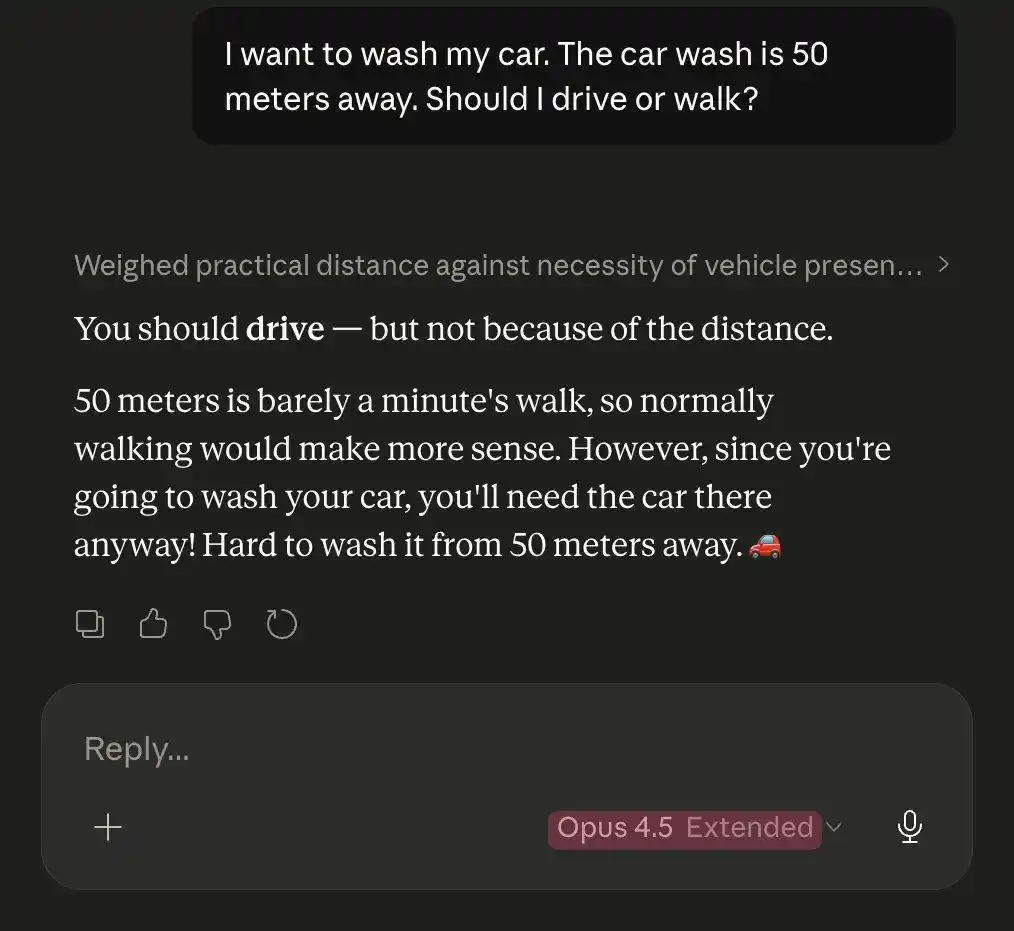
Thậm chí, một nhật ký của giám đốc AMD, thực sự xác nhận nghi ngờ tập thể "Claude cắt thùy não".
Thông qua phân tích sâu nhật ký phiên Claude từ tháng 1-3, kết quả phát hiện:
"Độ dài suy nghĩ trung vị" của Claude, từ khoảng 2200 ký tự giảm mạnh xuống 600 ký tự, điều này có nghĩa khả năng suy luận sâu bị nén đáng kể.
Giữa tháng 2 và tháng 3, lượng yêu cầu API tăng vọt 80 lần. Do quá trình suy nghĩ của Claude rút ngắn, tỷ lệ thành công của mỗi lần thử giảm, người dùng buộc phải thử lại thường xuyên, kết quả vừa tiêu hao nhiều Token hơn, chi tiêu cũng tăng vọt.


Còn một người dùng đăng ký Claude Max kỳ cựu, đã đăng một bài dài tố cáo sâu Anthropic.
Theo quan điểm của anh ta, Anthropic đang sa lầy trong khó khăn về sức mạnh tính toán, điều này có thể thấy từ hành vi siết chặt hạn chế sử dụng, ép người dùng giảm tiêu hao Token.
Tuy nhiên, so với nút thắt cổ chai kỹ thuật, điều khiến anh ta phẫn nộ hơn là chiến lược sản phẩm "không chuyên tâm" của họ.
Trong khi mô hình cốt lõi không ổn định, Bug thường xuyên xuất hiện, họ lại lãng phí sức mạnh tính toán quý giá, vào việc phát triển các chức năng hào nhoáng như thú cưng đầu cuối "/buddy".
Đây có lẽ là "không gian thời gian sai lệch" hoang đường nhất trong lịch sử AI: Claude Mythos trong phòng thí nghiệm đang hủy diệt thế giới, Opus 4.6 trên trang web trí thông minh giảm thẳng.
Anthropic đã thành công tạo ra một "Siêu AI Schrödinger".
Tài liệu tham khảo:
https://officechai.com/ai/anthropic-and-openai-are-exaggerating-cybersecurity-risk-says-hacker-george-hotz/
https://x.com/stanislavfort/status/2041922370206654879?s=20
https://aisle.com/blog/ai-cybersecurity-after-mythos-the-jagged-frontier
https://x.com/cgtwts/status/2043095382121681272?s=20
https://www.reddit.com/r/ClaudeAI/comments/1siqwmp/anthropic_stop_shipping_seriously/
Bài viết đến từ tài khoản công chúng WeChat "Tân Trí Nguyên" (新智元), tác giả: Tân Trí Nguyên








