Tác giả:Yanhua
Antonio Gullí là Giám đốc Kỹ thuật tại Google. Ông đã viết một cuốn sách 453 trang, phân tách việc phát triển AI Agent thành 21 mẫu thiết kế.
Nhưng đây không phải là một bài đánh giá sách. Động cơ tôi đọc cuốn sách này rất cụ thể: Tôi đã viết về Harness Engineering, viết về kinh nghiệm lỗi với Clawdbot, viết bài 'AI Agent không phải ma thuật' từ việc đốt Token đến bảy bước ngoặt thực sự hữu ích, mỗi lần viết xong đều có một câu hỏi chưa được nghĩ thấu đáo hoàn toàn:Có phải đằng sau những thứ này là một logic nền tảng có thể tái sử dụng không?
Cuốn sách này đã cho tôi câu trả lời, và sâu sắc hơn tôi nghĩ.
Thứ bạn viết có thể hoàn toàn không phải là Agent
Nhận định khốc liệt nhất của cuốn sách ẩn trong phần lời nói đầu.
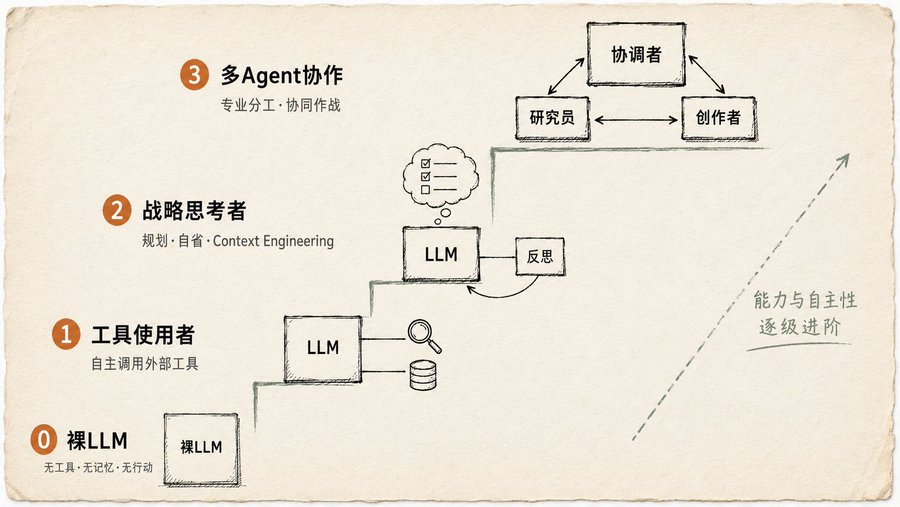
'AI' mà hầu hết mọi người đang sử dụng chỉ là Level 0: LLM trần, không có công cụ, không có bộ nhớ, không biết hành động. Bạn hỏi nó phim nào sẽ đoạt giải Oscar năm 2025, nó đoán mò. Sách viết rất thẳng thắn:Thứ Level 0, không phải là Agent.
Đi lên trên mới là Agent thực sự:
-
Level 1: Người sử dụng công cụ
Agent bắt đầu sử dụng công cụ: tìm kiếm, API, cơ sở dữ liệu. Nhưng nó không chỉ là 'có thể gọi API', mà còn phải tự đánh giá khi nào nên gọi, gọi cái gì, kết quả dùng thế nào. Sách đưa ra một ví dụ rất cụ thể: người dùng hỏi 'Gần đây có phim mới nào hay?', Agent tự nhận thức thông tin này không có trong dữ liệu huấn luyện, chủ động gọi công cụ tìm kiếm để tìm, rồi tổng hợp kết quả. Bước quan trọng nằm ở 'tự nhận thức'. Không phải con người bảo nó 'bạn tìm kiếm đi', mà là nó tự đánh giá cần phải tìm. Khả năng đánh giá này, là ngưỡng cửa của Level 1.
-
Level 2: Người suy nghĩ chiến lược
Thêm hai thứ: lập kế hoạch và Context Engineering. Sách định nghĩa Context Engineering: không phải chất đống thông tin, mà là lựa chọn, cắt gọt, đóng gói ngữ cảnh một cách tinh tế. Ví dụ rất hay: người dùng muốn tìm quán cà phê giữa hai địa điểm. Agent đầu tiên gọi công cụ bản đồ để lấy một đống dữ liệu, rồi tự đánh giá 'bước tiếp theo chỉ cần tên đường', cắt đầu ra bản đồ thành một danh sách ngắn, rồi đưa cho công cụ tìm kiếm địa phương. Mỗi bước đều đang thực hiện giảm nhiễu thông tin.
Sách có một câu tôi đã đọc đi đọc lại nhiều lần: 'Để AI đạt được độ chính xác cao nhất, phải cho nó ngữ cảnh ngắn gọn, tập trung, mạnh mẽ.' Context Engineering chính là làm việc này.
Đến cấp độ này, Agent còn có thể tự phản ánh. Sau khi hoàn thành công việc tự xem xét lại một lần, phát hiện vấn đề tự sửa. Tôi sẽ nói chi tiết hơn ở phần sau.
-
Level 3: Đa Agent cộng tác
Quan điểm của sách rất rõ ràng: đừng suốt ngày nghĩ đến việc tạo ra một super agent toàn năng. Cách làm thực sự đáng tin cậy là giống như xây dựng một đội, Agent quản lý dự án + Agent nghiên cứu + Agent thiết kế + Agent soạn thảo văn bản. Ví dụ trong sách là ra mắt sản phẩm mới: một 'Agent quản lý dự án' làm tổng điều phối, phân công nhiệm vụ cho 'Agent nghiên cứu thị trường', 'Agent thiết kế sản phẩm', 'Agent marketing'. Điểm quan trọng là giao tiếp: các Agent truyền dữ liệu như thế nào, đồng bộ trạng thái ra sao, xử lý xung đột thế nào. Chương này vẽ sáu cấu trúc liên kết giao tiếp, từ đơn Agent đơn giản nhất đến hỗn hợp tùy chỉnh linh hoạt nhất, mỗi loại phù hợp với tình huống nào đều có giải thích.
Xem hết bốn cấp độ này, tôi bỗng hiểu tại sao nhiều người nói 'Agent của tôi không tốt'. Mô hình không có vấn đề, vấn đề là bạn đang sử dụng nó như một chatbot, nó có thể còn chưa đến Level 1.
Context Engineering: Khái niệm bị đánh giá thấp nhất trong sách
Tôi đã viết một bài về Harness Engineering, nói rằng thiết kế đường đua quan trọng hơn sức ngựa động cơ. Sau khi đọc cuốn sách này tôi phát hiện, Context Engineering chính là ánh xạ của Harness Engineering ở cấp độ prompt.
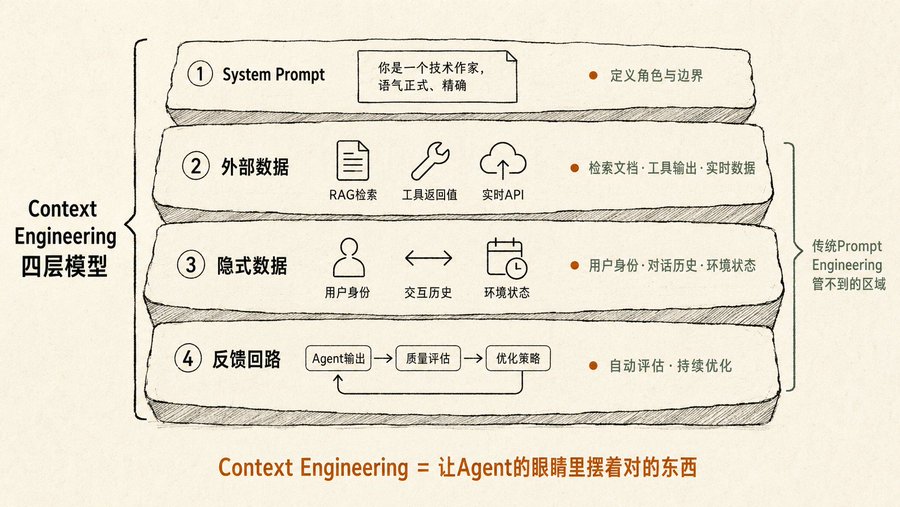
Prompt Engineering truyền thống chỉ quản lý 'bạn hỏi như thế nào'. Context Engineering trong sách quản lý 'trước khi hỏi, trước mắt Agent đang có gì'. Nó bao gồm bốn lớp thông tin:
-
Lớp thứ nhất, system prompt. Xác định Agent là ai, giọng điệu gì, ranh giới nào. Hầu hết mọi người chỉ viết lớp này.
-
Lớp thứ hai, dữ liệu bên ngoài. Tài liệu được truy xuất bởi RAG, giá trị trả về từ việc gọi công cụ, dữ liệu API thời gian thực. Đây là nơi hầu hết mọi người bị kẹt: biết phải cung cấp dữ liệu, nhưng không biết cách cung cấp sao cho không làm chìm đắm mô hình.
-
Lớp thứ ba, dữ liệu ngầm. Danh tính người dùng, lịch sử tương tác, trạng thái môi trường. Những thứ bạn không nói rõ nhưng Agent nên biết. Ví dụ, bạn nói với Agent 'Giúp tôi gửi email xác nhận cuộc họp ngày mai cho John', nó nên biết cuộc họp ngày mai trong lịch của bạn là gì, mối quan hệ giữa bạn và John thế nào.
-
Lớp thứ tư, vòng lặp phản hồi. Sau mỗi lần đầu ra, Agent tự động đánh giá chất lượng, điều chỉnh chiến lược ngữ cảnh cho lần sau. Sách gọi đây là 'tối ưu hóa context tự động', Vertex AI Prompt Optimizer của Google là triển khai kỹ thuật hóa theo hướng suy nghĩ này.
Khi tôi đọc đến đây đã nhớ lại bài viết trước đó 'AI Agent không phải ma thuật', trong đó có một kinh nghiệm là 'Agent của bạn cần quy tắc, và là rất nhiều quy tắc'. Nhìn lại bây giờ, về bản chất những quy tắc đó chính là phiên bản thủ công của Context Engineering, sách đã hệ thống hóa nó.
Reflection: Hai Agent thực sự tốt hơn một
Đây là một Pattern có giá trị thực chiến nhất với tôi trong cả cuốn sách.
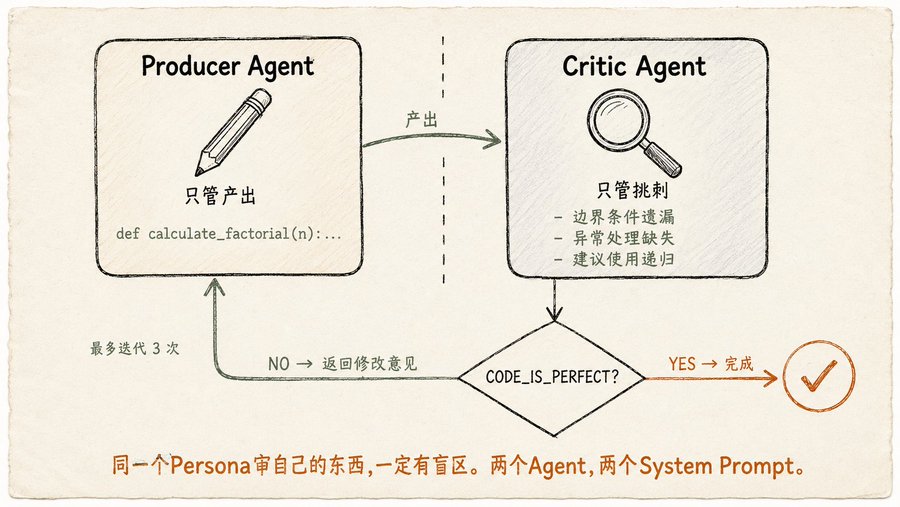
Core của Reflection rất đơn giản: Agent tự xem xét lại công việc sau khi hoàn thành, tự phát hiện vấn đề tự sửa. Nhưng cách thức thực hiện có điểm cần chú ý. Sách nói rất rõ:Producer và Critic phải sử dụng hai Agent khác nhau, với system prompt khác nhau. Cùng một persona xem xét lại thứ của chính mình, chắc chắn có điểm mù. Bạn để cùng một LLM viết code trước rồi tự xem xét lại code mình viết, nó rất có thể sẽ nói 'khá tốt'.
Sách đưa ra một ví dụ code hoàn chỉnh.
-
Prompt của Producer là 'Bạn là một lập trình viên Python, viết một hàm tính giai thừa, xử lý điều kiện biên và ngoại lệ'.
-
Prompt của Critic là 'Bạn là một kỹ sư cấp cao cực kỳ khắt khe, xem xét code từng dòng, kiểm tra Bug, phong cách, điều kiện biên bị bỏ sót, những điểm có thể cải thiện. Nếu hoàn hảo thì xuất ra
CODE_IS_PERFECT, ngược lại liệt kê tất cả vấn đề'. -
Sau đó là một vòng lặp for: Producer viết code → Critic xem xét → Producer sửa theo ý kiến → Critic xem xét lại → cho đến khi Critic nói
CODE_IS_PERFECThoặc đạt số lần lặp tối đa.
Đơn giản như vậy thôi. Nhưng sách nhắc nhở một vấn đề chi phí dễ bị bỏ qua: mỗi vòng lặp phản ánh là một lần gọi LLM mới, càng lặp nhiều càng đắt. Và khi lịch sử hội thoại phình ra, cửa sổ ngữ cảnh bị các phiên bản trước đó và ý kiến phê bình chiếm hết, không gian suy luận thực sự có thể dùng đang thu hẹp lại. Vì vậy best practice của Reflection là:Đặt một số lần lặp tối đa hợp lý (sách dùng 3), một khi Critic hài lòng thì dừng, đừng theo đuổi sự hoàn hảo.
Ứng dụng xa hơn việc viết code. Viết bài, lập kế hoạch, tóm tắt tài liệu, giải quyết bài toán logic, mô hình Producer-Critic đều có thể áp dụng. Sách liệt kê bảy loại tình huống ứng dụng, logic core giống nhau: đầu tiên tạo ra, sau đó xem xét, rồi chỉnh sửa.
Multi-Agent không phải càng phức tạp càng tốt
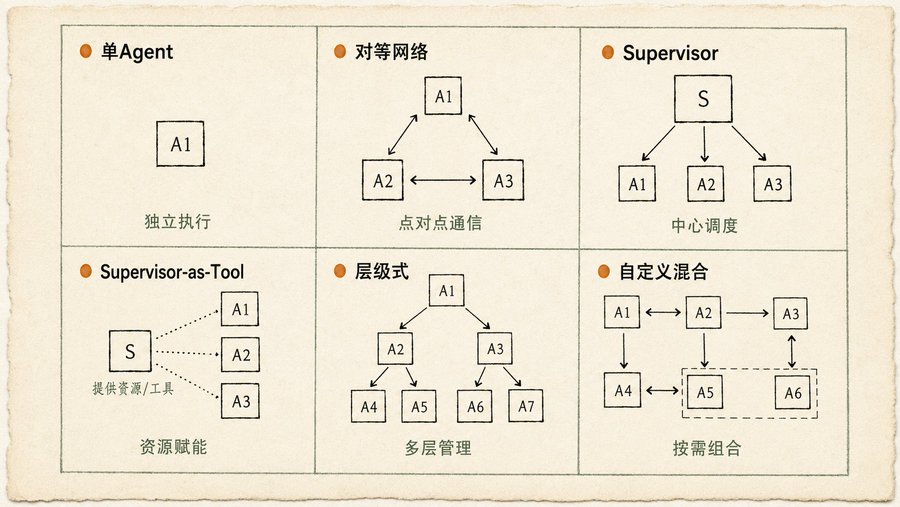
Trong chương Multi-Agent Collaboration, tôi thích nhất là sáu sơ đồ cấu trúc liên kết giao tiếp đó. Nhiều người ngay từ đầu đã làm phức tạp, nhưng thực tế hầu hết tình huống chỉ cần ba loại là đủ:
-
Single Agent (thực hiện độc lập): Nhiệm vụ có thể tách thành các vấn đề con không phụ thuộc lẫn nhau, mỗi Agent tự giải quyết của mình. Đơn giản, dễ bảo trì.
-
Mạng ngang hàng (Peer-to-Peer): Các Agent giao tiếp trực tiếp với nhau, không có nút điều khiển trung tâm. Phi tập trung, khả năng chịu lỗi cao, một Agent hỏng không ảnh hưởng toàn cục. Nhưng chi phí phối hợp cao, dễ lộn xộn.
-
Giám sát viên (Supervisor - trung tâm điều phối): Một Agent Supervisor quản lý một nhóm Agent Worker. Phân công nhiệm vụ, thu thập kết quả, giải quyết xung đột. Cấp bậc rõ ràng, dễ quản lý. Nhưng Supervisor là điểm hỏng duy nhất, cũng là nút cổ chai hiệu suất.
Ba loại còn lại (Supervisor-as-Tool, phân cấp, hỗn hợp tùy chỉnh) là biến thể và tổ hợp của ba loại trước. Sách nói rất thực tế:Cấu trúc liên kết bạn cần phụ thuộc vào độ phức tạp nhiệm vụ của bạn. Nhiệm vụ càng tách nhỏ, chi phí giao tiếp càng cao, đến một mức độ nhất định, mô hình Supervisor thực ra hiệu quả hơn mô hình phân cấp.
Cảm nhận của tôi là, nhiều người khi xây dựng Multi-Agent đã dành 80% thời gian trên giao thức giao tiếp, quên hỏi một câu hỏi cơ bản hơn: Nhiệm vụ này thực sự cần nhiều Agent không? Sách viết rất rõ, Single Agent Level 2 + Reflection thường đã đủ dùng. Level 3 là dành cho những tình huống mà Single Agent thực sự không thể giải quyết.
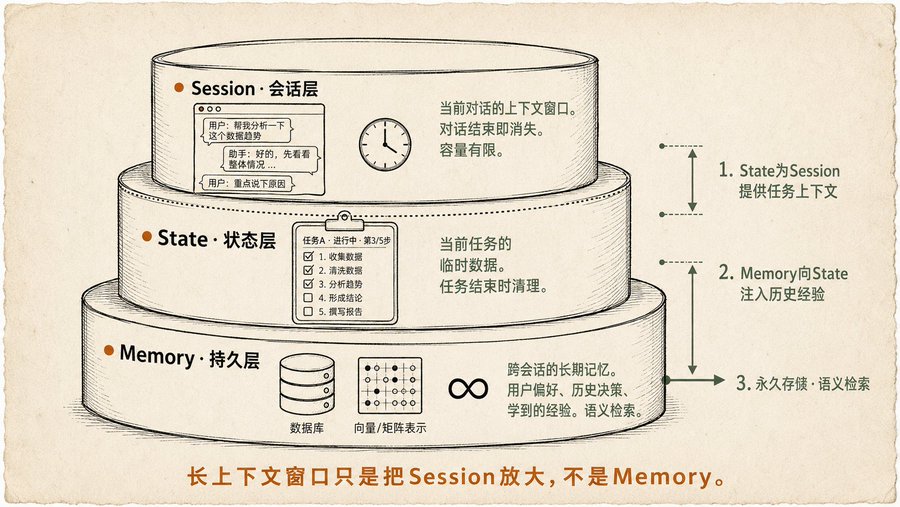
Mô hình Memory ba lớp, trước đây tôi đã cảm nhận mơ hồ nhưng chưa đặt tên
Chương Memory này tôi thấy đồng cảm nhất, vì khi viết hai bài về Obsidian + Claude, tôi đã luôn suy nghĩ một vấn đề: Bộ nhớ của Agent nên phân lớp như thế nào?
Sách đưa ra câu trả lời:
-
Session (lớp phiên làm việc): Cửa sổ ngữ cảnh của cuộc hội thoại hiện tại, đây là bộ nhớ ngắn nhất, hết phiên là mất. Mô hình ngữ cảnh dài chỉ phóng to cửa sổ này, nhưng về bản chất vẫn là tạm thời, và mỗi lần suy luận phải xử lý toàn bộ cửa sổ, vừa đắt vừa chậm.
-
State (lớp trạng thái): Dữ liệu tạm thời đang diễn ra trong nhiệm vụ hiện tại. Ví dụ 'nhiệm vụ đang làm là gì', 'đã hoàn thành đến bước nào', 'giữa chừng sinh ra dữ liệu gì'. Dài hơn Session, nhưng kết thúc nhiệm vụ là dọn dẹp, sách dùng cơ chế State của Google ADK để làm ví dụ hoàn chỉnh.
-
Memory (lớp bền vững): Bộ nhớ dài hạn xuyên phiên, xuyên nhiệm vụ. Sở thích người dùng, kinh nghiệm học được, quyết định lịch sử quan trọng, lưu trữ trong cơ sở dữ liệu hoặc vector database, truy xuất ngữ nghĩa. Sách nhấn mạnh một điểm rất quan trọng: Memory không chỉ là lưu lại, mà còn phải thiết kế cả một bộ chiến lược về 'lưu cái gì, khi nào lưu, truy xuất thế nào'. Lưu quá nhiều thì nhiễu lớn, lưu quá ít thì không đủ dùng.
Trước đây tôi viết bài về Clawdbot có đề cập đến 'file trạng thái' và 'tài liệu workspace', về bản chất chính là đang xây dựng thủ công lớp State và lớp Memory, sách đã đóng khung hóa việc này.
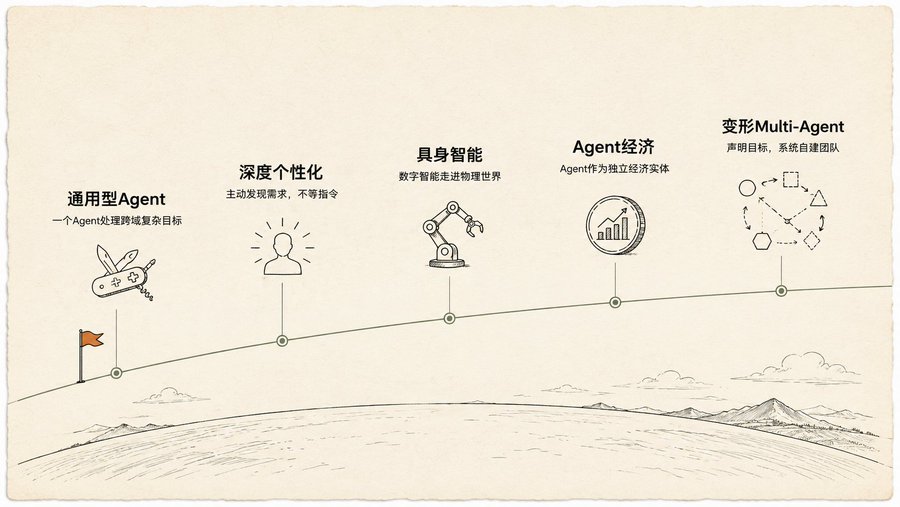
Năm giả định, cái thứ năm quái đản nhất
Cuối sách đề cập năm giả định về tương lai của Agent, bốn cái đầu vẫn nằm trong phạm vi suy diễn hợp lý: Agent đa năng từ viết code đến quản lý dự án, cá nhân hóa sâu chủ động phát hiện nhu cầu của bạn, trí tuệ thể chất bước ra khỏi màn hình vào thế giới vật lý, Agent trở thành thực thể kinh tế độc lập.
Cái thứ năm làm tôi chấn động:Multi-Agent có thể biến hình.
Bạn chỉ tuyên bố mục tiêu, ví dụ 'làm một doanh nghiệp thương mại điện tử bán cà phê đặc sản'. Hệ thống tự động quyết định: đầu tiên tạo ra 'Agent nghiên cứu thị trường' và 'Agent thương hiệu'. Chạy một vòng dữ liệu xong, tự đánh giá Agent thương hiệu không cần nữa, tách thành ba Agent mới: 'Agent thiết kế Logo', 'Agent xây dựng website', 'Agent chuỗi cung ứng'. Nếu Agent xây dựng website trở thành nút cổ chai, hệ thống sẽ tự động nhân bản ra ba Agent song song cùng làm các trang khác nhau. Trong suốt quá trình, hệ thống liên tục tự động tối ưu prompt của mỗi Agent, không ngừng tổ chức lại cấu trúc đội.
Sách gọi đây là 'hệ thống đa Agent tự biến hình, dẫn dắt bởi mục tiêu'. Nó không phải đang thực hiện kế hoạch bạn viết, mà là tự tạo kế hoạch, tự điều chỉnh kế hoạch, tự tổ chức lại đội ngũ thực hiện.
Điều này làm tôi nhớ đến AutoResearch của Karpathy: viết một program.md, định nghĩa mục tiêu, chỉ số, ranh giới, nhấn 'Khởi động'. Con người ở bên ngoài vòng lặp. Nhưng cuốn sách này đẩy xa hơn: ngay cả việc đội Agent được thành lập thế nào, tổ chức lại ra sao, đều giao cho hệ thống tự quyết định. Con người chỉ tuyên bố 'muốn gì'.
Ba việc có thể làm ngay
Sau khi đọc xong cuốn sách, tôi có ba hành động có thể triển khai ngay:
-
Thứ nhất, thêm một Critic cho Agent hiện tại của bạn. Bất kể bạn dùng Claude Code, CrewAI hay framework tự xây dựng, hãy thêm một bước ở cuối workflow hiện có: để một Agent khác (với system prompt khác) xem xét lại đầu ra của bước trước. Tạo code thì thêm xem xét code, viết bài thì thêm kiểm tra sự thật, lập kế hoạch thì thêm đánh giá tính khả thi. Tăng thêm một lần gọi LLM, nhưng chất lượng thường tăng gấp đôi. Mô hình Producer-Critic trong sách là plug-and-play.
-
Thứ hai, bắt đầu làm Context Engineering, không chỉ là Prompt Engineering. Xem lại file hướng dẫn bạn viết cho Agent. Nếu toàn là quy tắc 'bạn phải làm thế nào', thiếu ngữ cảnh 'bạn đang đối mặt với môi trường gì', hãy bổ sung. Nói cho Agent biết nó đang ở dự án nào, trước đây đã quyết định gì, sở thích người dùng là gì. Chương Context Engineering trong sách và file
AGENTS.mdcủa bạn là hai cách diễn đạt của cùng một việc. -
Thứ ba, đừng vội sử dụng Multi-Agent. Hãy làm cho Single Agent của bạn đạt Level 2: có công cụ, có Reflection, có Memory. Sách nhấn mạnh đi nhấn mạnh lại, Single Agent Level 2 cộng với Producer-Critic và Context Engineering, có thể bao phủ tuyệt đại đa số tình huống thực tế. Level 3 là dành cho những nhiệm vụ thực sự đa lĩnh vực, nhiều giai đoạn, cần phân công song song. Vấn đề của hầu hết mọi người không phải là không đủ Agent, mà là một Agent còn chưa được điều chỉnh tốt.
Cuốn sách này 453 trang, Springer xuất bản năm 2025. Ví dụ code bao phủ LangChain/LangGraph, Google ADK, CrewAI, OpenAI API. Lời nói đầu do Google Cloud AI VP viết, còn có một lời giới thiệu từ CIO của Goldman Sachs, ngoài dự đoán là hay.
Nhưng lý do tôi giới thiệu nó không phải là 'toàn diện'. Là bạn sẽ nhận ra một điều sau khi đọc xong: những cái hố bạn đã vấp trên Agent trong nửa năm qua, đều có người tổng hợp thành mẫu rồi. Bạn không cần phải phát minh lại Reflection, không cần phải đoán Memory nên phân lớp như thế nào, không cần phải thử xem Multi-Agent nên dùng cấu trúc liên kết giao tiếp nào.
Đã có người vẽ bản đồ thay bạn, phần còn lại là bước đi.
Bạn có đang dùng AI Agent để phát triển không? Agent hiện tại của bạn đang ở Level mấy?





