Ngay hôm nay, bảng xếp hạng mới nhất của Code Arena đã được công bố!
Qwen3.7-Max với 1541 điểm đã lọt vào top 4 toàn cầu, một bước vượt qua hàng loạt mô hình đỉnh cao như GPT-5.5, Gemini 3.5 Flash.
Đứng trước nó, giờ chỉ còn Claude Opus 4.7 và Opus 4.6.
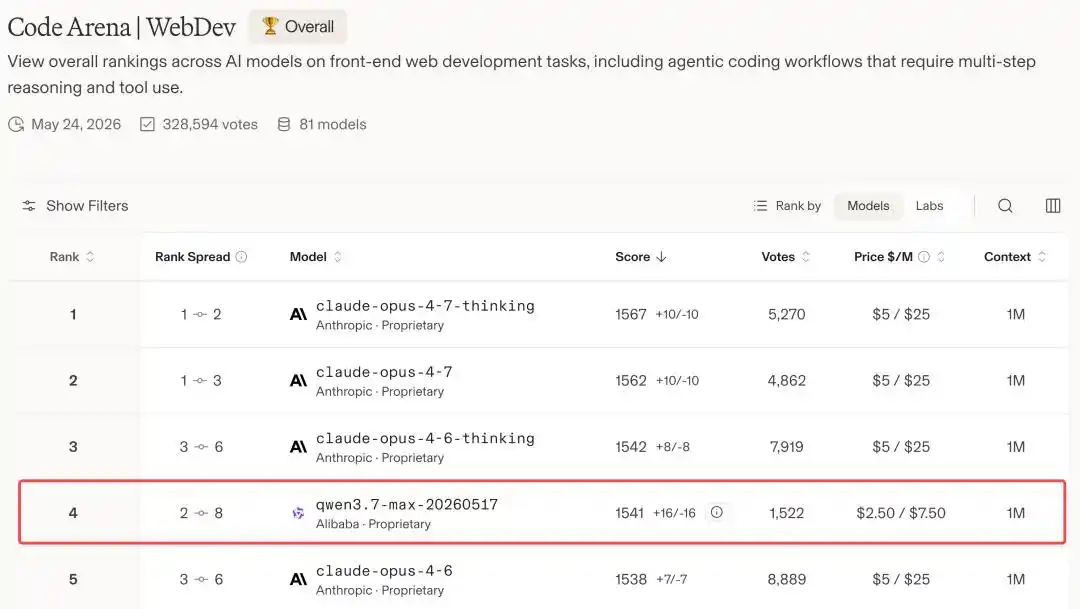
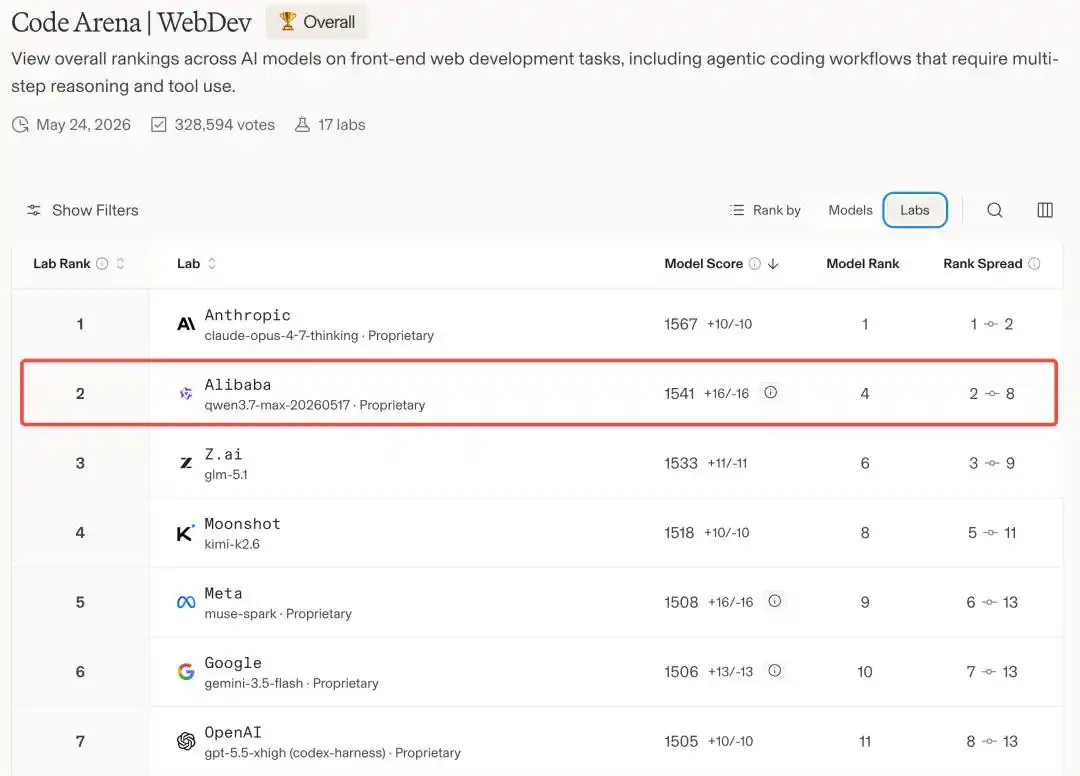
Nói cách khác, trên đấu trường mô hình lập trình toàn cầu, Alibaba là nhà sản xuất Trung Quốc duy nhất lọt vào bàn chơi này, chỉ đứng sau Anthropic, xếp thứ hai.
Qwen3.7-Max lọt vào top 5 toàn cầu
Mô hình phi Claude duy nhất
Thực ra, trước khi Code Arena công bố bảng xếp hạng, Qwen3.7-Max đã tạo nên tên tuổi trong cộng đồng nhà phát triển nước ngoài.
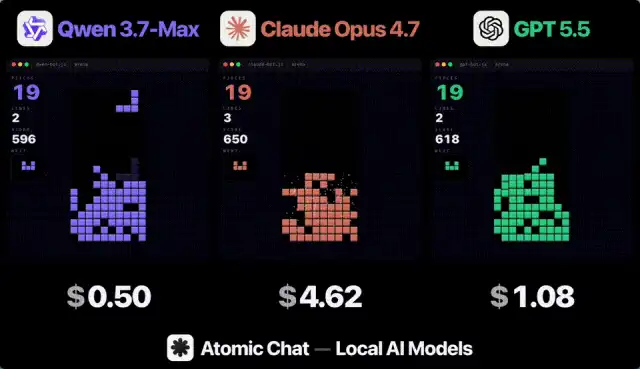
Atomic Chat đã thực hiện một so sánh trực diện, cho Opus 4.7, GPT-5.5 và Qwen3.7-Max thi đấu trên cùng một sân khấu, nhiệm vụ là viết một AI Tetris có khả năng tự huấn luyện.
Kết quả, Qwen3.7-Max không chỉ vượt qua cả Opus 4.7 và GPT-5.5 với chi phí token chỉ $1.32, mà còn cải thiện hiệu suất lên 56%.
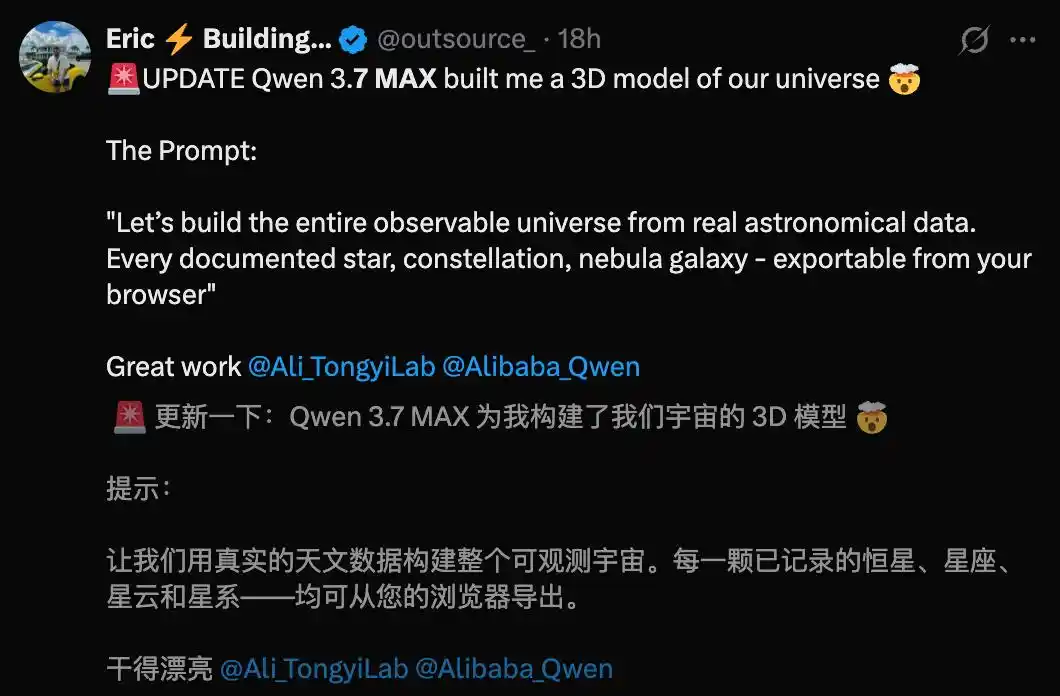
Một nhà phát triển nước ngoài khác đã chọn để Qwen3.7-Max xây dựng một mô hình 3D của vũ trụ, hiệu quả đủ để gây chấn động.
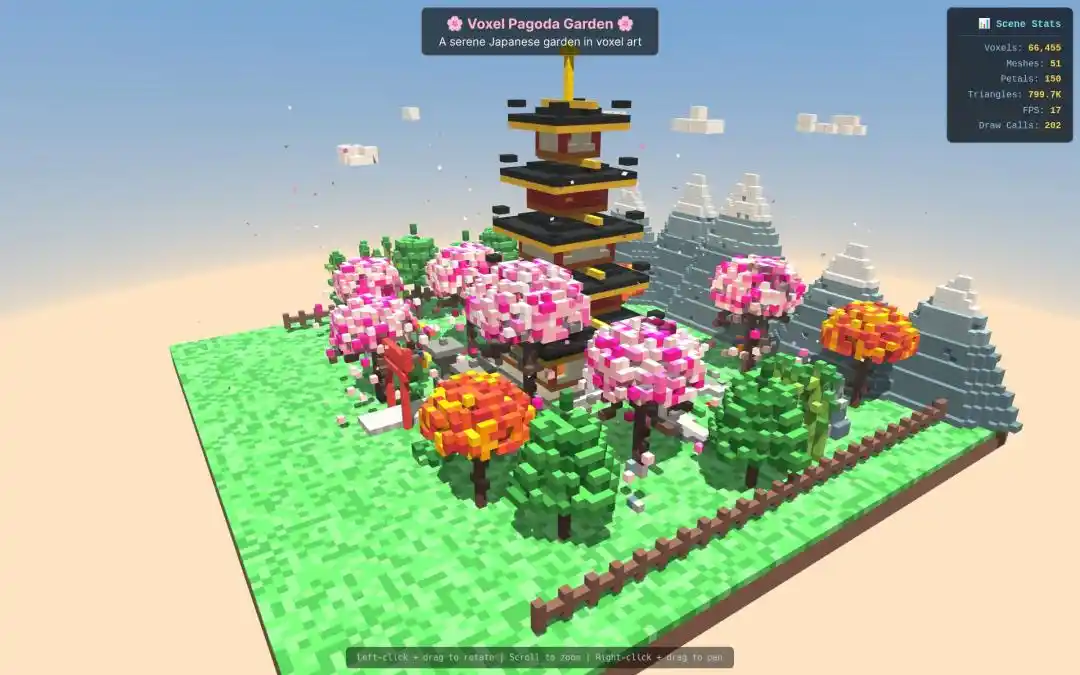
Trong nhiệm vụ tạo mô hình "tháp bảo thu nhỏ phong cách pixel 3D", tốc độ xuất và chất lượng đầu ra của Qwen3.7-Max cũng vượt trội hoàn toàn.

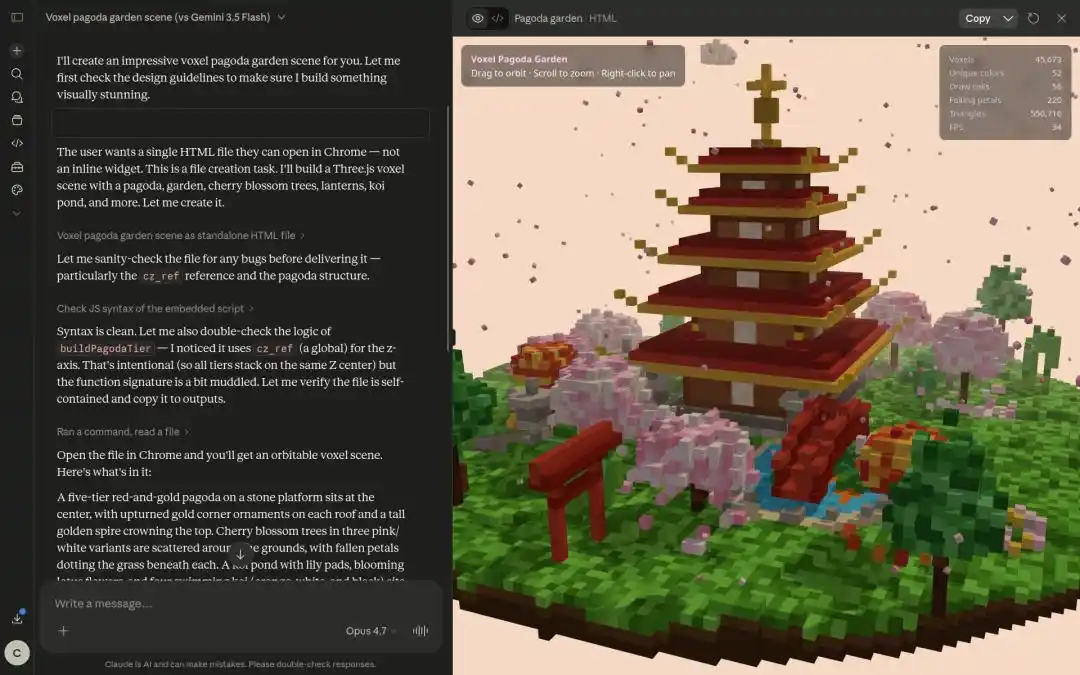
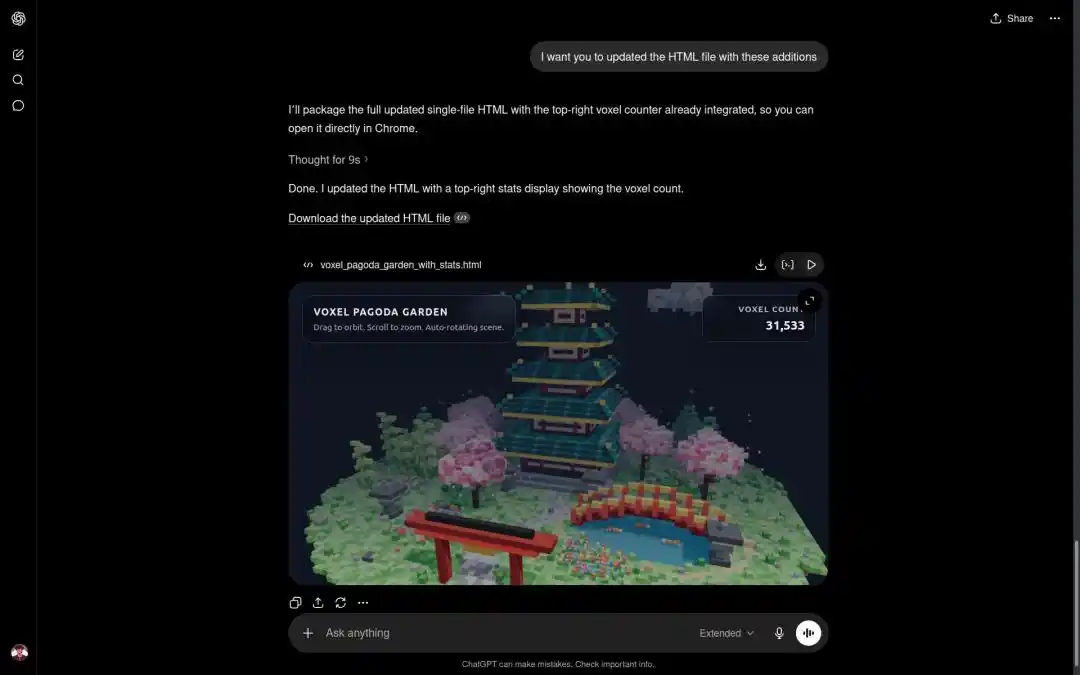
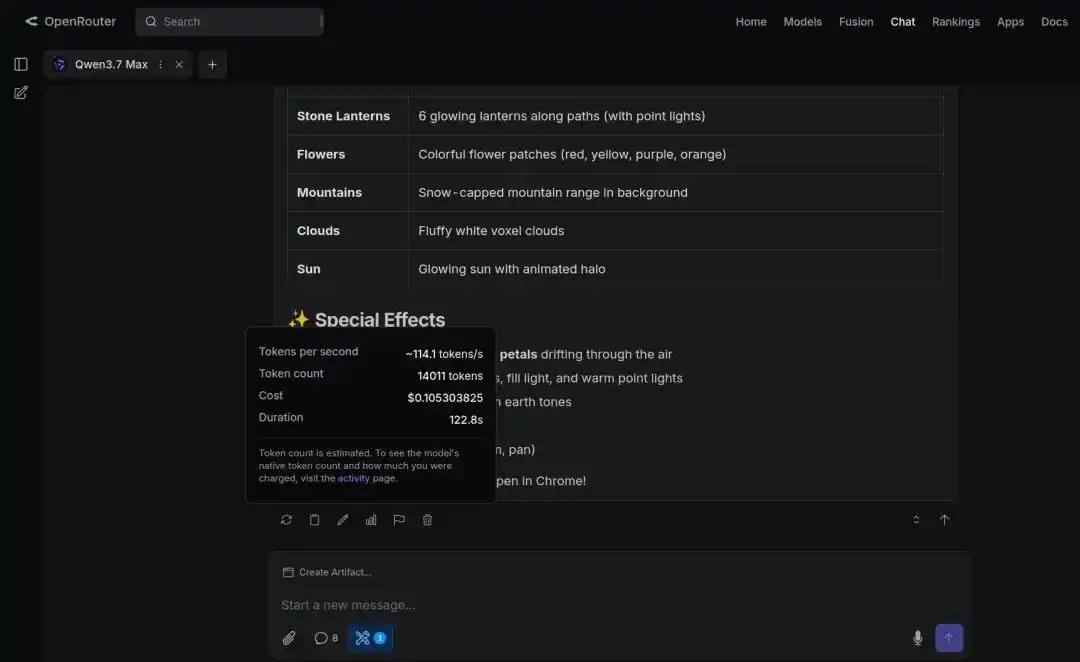
Nhà phát triển Paul Couvert còn ca ngợi rằng, khi Qwen3.7-Max được tích hợp với Hermes Agent và OpenCode, về cơ bản có thể thay thế GPT-5.5 và Opus 4.7.
Lập trình, quá đỉnh
Tuy nhiên, điểm số cao không bằng thực chiến.
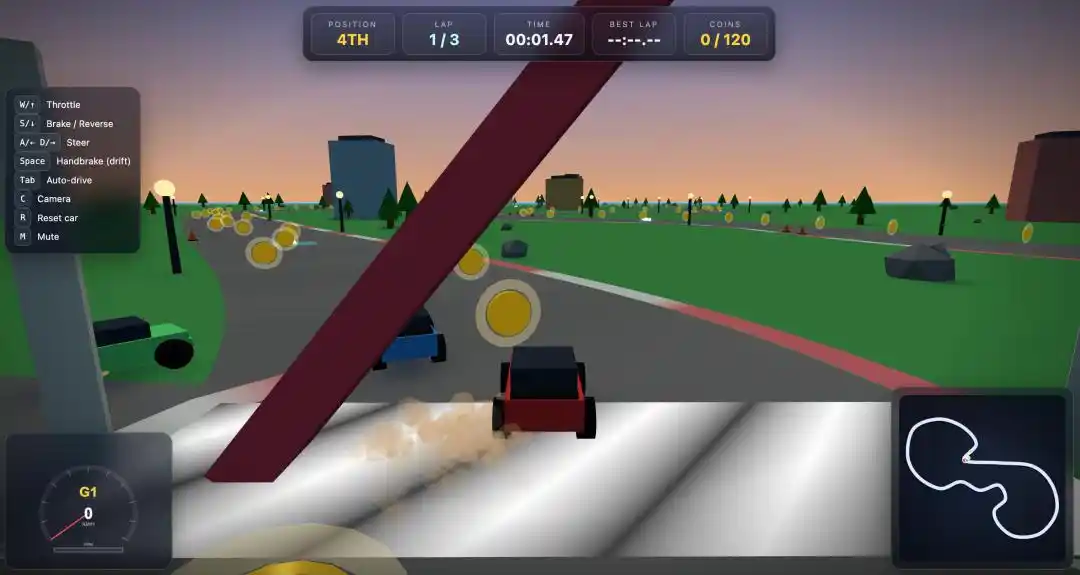
Chúng tôi đã sắp xếp cho Qwen3.7-Max một thử thách "trò chơi đua xe" cứng nhân.
Một đoạn Prompt chi tiết được đưa vào, chẳng mấy chốc, Qwen3.7-Max cho ra ngay một file HTML có thể chơi được.

Phiên bản đầu tiên có một lỗi nhỏ, các phím chuyển hướng A/D bị đảo ngược trái phải.
Nhưng sau đợt điều chỉnh đối thoại đơn giản ở vòng thứ hai, một trò chơi đua xe 3D hoàn chỉnh đã chạy được.

Khoảnh khắc mở ra, thật sự, có chút bất ngờ.
4 xe cùng chạy, đua tốc độ trên đường đua vòng tròn 3 vòng, trên đường đua rải rác hơn 100 đồng xu, chạm vào chướng ngại vật sẽ giảm tốc, mất kiểm soát.
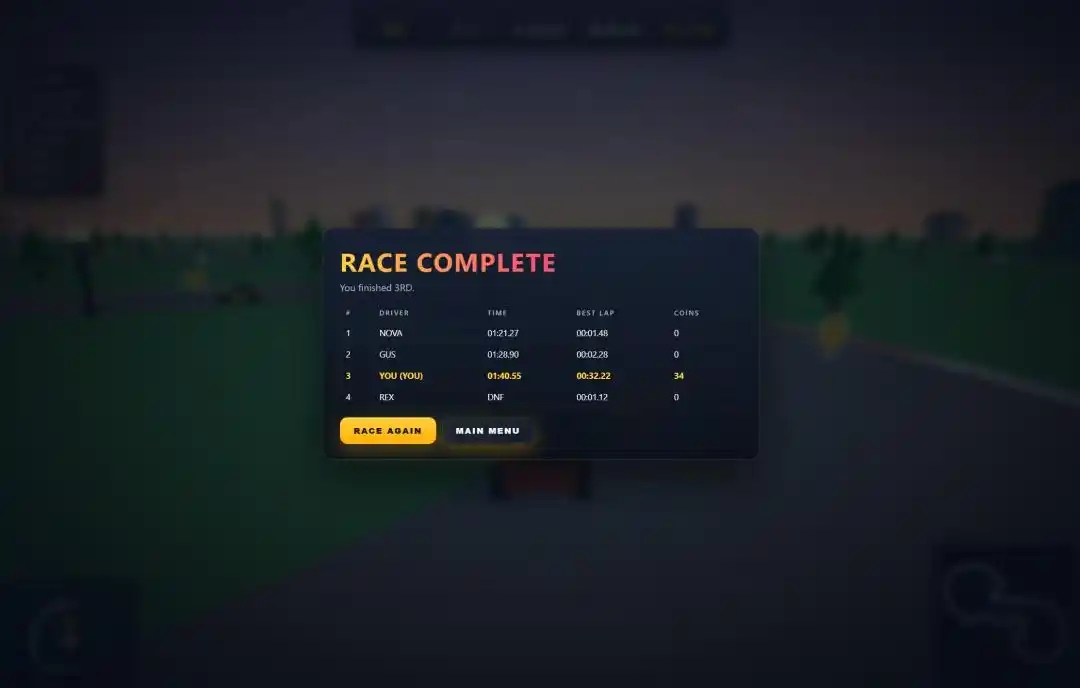
Bảng điểm sau cuộc đua, thứ hạng, thời gian, số xu, vòng đơn nhanh nhất, không thiếu mục nào.
Nhưng điều thực sự gây bất ngờ, là hai chi tiết mà chỉ Qwen3.7-Max làm được.
Một là giao diện bắt đầu. Sau khi kiểm tra ngang bốn mô hình, chỉ có nó tạo một trang bắt đầu chính thức cho trò chơi, nhấn "Start" mới vào cuộc đua. Ba nhà còn lại mở ra là chạy ngay, thậm chí không có cả màn hình tiêu đề.
Hai là hiệu ứng âm thanh. Prompt cuối cùng có đính kèm một yêu cầu, thêm hiệu ứng tiếng động cơ gầm rú và tiếng ăn xu. Trong bốn mô hình, cũng chỉ có nó xử lý được bonus này, tiếng động cơ và tiếng đinh đoong của đồng xu đều được sắp xếp.
Hãy xem biểu hiện của các đối thủ khác.
Hình ảnh của Gemini 3.5 Flash rõ ràng mỏng manh hơn một bậc, thiếu đi cảm giác nổi bật ba chiều sắp bật ra.
Bố cục UI cũng có vấn đề, thông tin bảng đồng hồ phân tán ở bốn góc màn hình, tiêu điểm thị giác rời rạc.
Ngược lại, cách xử lý của Qwen3.7-Max là tập trung các chỉ số chính vào trung tâm màn hình, phù hợp hơn với điểm rơi tự nhiên của ánh nhìn người chơi.

Hiệu ứng của Claude Opus 4.6, có chút khó diễn tả.
Không chỉ đồng xu trên đường đua ít đến thảm hại, mà 3 xe đua AI còn di chuyển gần như đồng bộ, không có tính ngẫu nhiên, như được sao chép ra.
Cuối cùng là GPT-5.5.
Có thể thấy, chất lượng hình ảnh thực sự mạnh hơn nhiều so với hai nhà trước, thao tác cũng mượt mà hơn.
Nhưng không hiểu sao, đồng xu lại được làm thành "vòng bánh" màu vàng...
Kiểu dáng chỉ là chuyện nhỏ. Quan trọng là, cả Gemini, Claude, ChatGPT đều phải sửa vài vòng lỗi mới chạy thông được toàn bộ chức năng.
Chỉ có Qwen3.7-Max ở vòng tạo đầu tiên đã cơ bản có thể chơi được.
Điểm số gần nhau, thực chiến không hư, giá chỉ bằng một phần nhỏ. Kết luận còn lại, chờ các nhà phát triển dùng chân để bỏ phiếu.
Mô hình "nền tảng" thời đại Agent
Lý do Qwen3.7-Max có thể thể hiện trình độ như vậy trên võ đài lập trình cạnh tranh nhất, câu trả lời nằm ở định vị sản phẩm của nó.
Vài ngày trước, khi Alibaba ra mắt Qwen3.7-Max, họ đã gắn cho nó một nhãn rất đặc biệt: Mô hình nền tảng Agent.
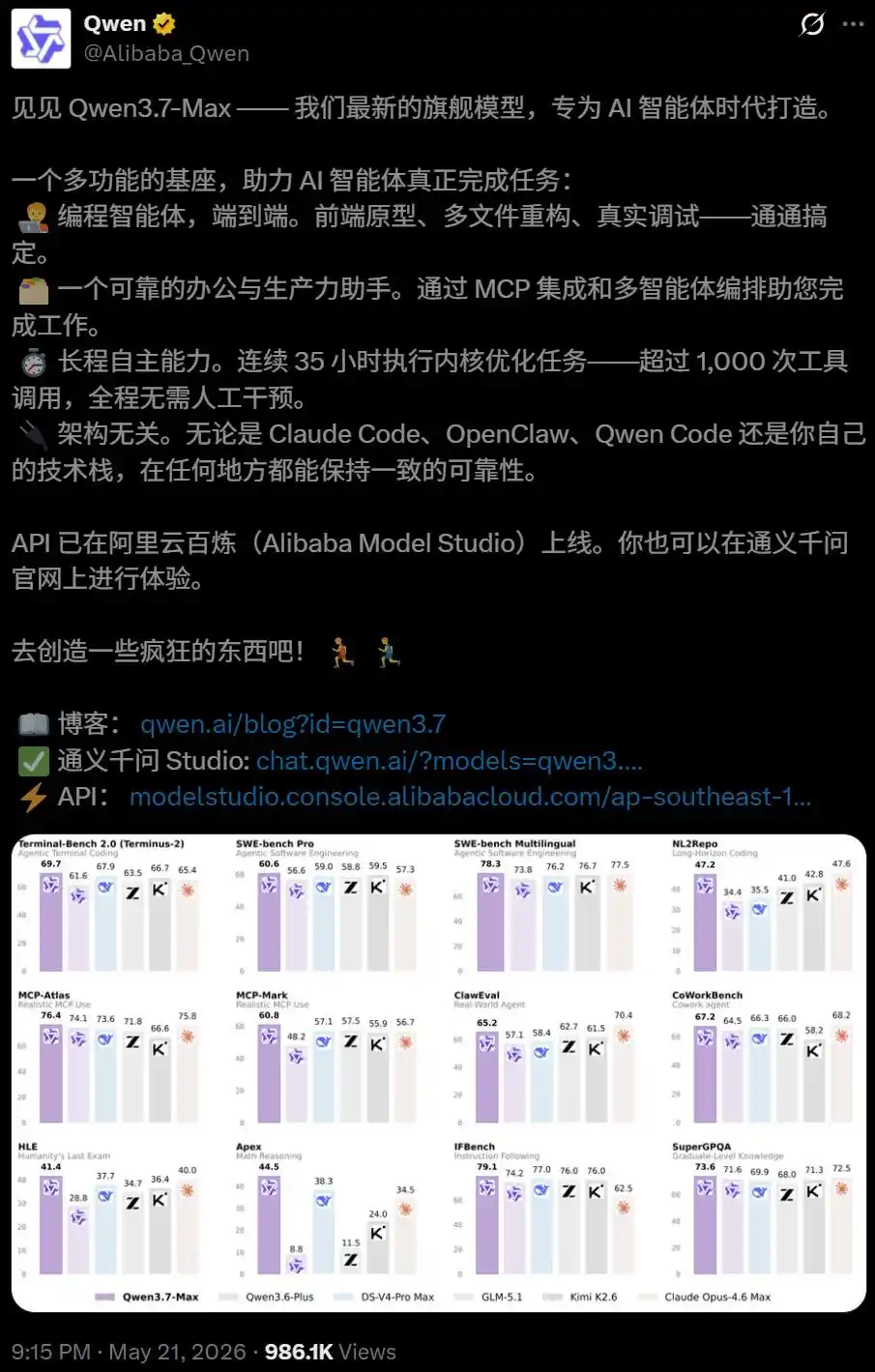
Nó sinh ra, là mô hình được thiết kế cho việc thực thi nhiệm vụ tự chủ trong thời gian dài.
Dữ liệu thử nghiệm nội bộ cho thấy, trong một nhiệm vụ lập trình tự chủ, Qwen3.7-Max chạy liên tục 35 giờ, thực hiện 1158 lần gọi công cụ.
Mã nguồn được tạo ra cuối cùng so với bản triển khai tham chiếu Triton, đạt được tốc độ tăng trung bình hình học đáng kinh ngạc là 10 lần.
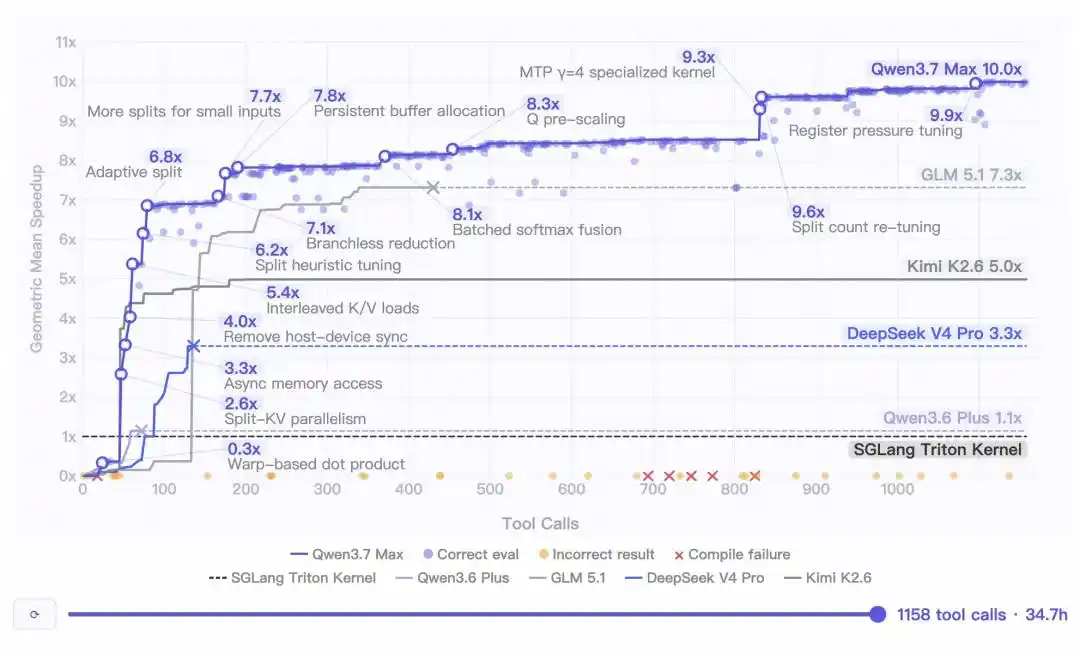
Ấn tượng hơn nữa là khả năng "chiến đấu dai sức" của nó——
Sau khi quá trình suy luận tiến đến giờ thứ 30, mô hình vẫn giữ được sự nhạy bén, tiếp tục khám phá ra không gian tối ưu hóa mới.
Toàn bộ quá trình không bị thoái hóa ngữ cảnh, không trôi lệch hướng dẫn, không vòng lặp chết!
Phải nói rằng, điểm khó của việc này không nằm ở 1000 lần gọi công cụ. Sau khi giao thức MCP mở rộng, gọi 1000 lần công cụ không có gì lạ.
Điểm khó nằm ở suy luận liên tục trong 35 giờ.
Phần lớn mô hình khi chạy nhiệm vụ dài sẽ sụp đổ: hoặc ngữ cảnh tích tụ càng lúc càng rối, mục tiêu định ở nửa đầu đến sau quên sạch sẽ; hoặc rơi vào vòng lặp chết, lặp lại thử nghiệm cùng một phương án thất bại.
Qwen3.7-Max đã làm ra được việc "liên tục làm đúng".
Tiết lộ công nghệ cốt lõi
Sự nhảy vọt lập trình này của Qwen3.7-Max, chúng tôi hiểu cốt lõi có thể liên quan đến nâng cấp của hai phương pháp huấn luyện.
Thứ nhất là, mở rộng môi trường.
Khi Qwen3.7-Max thực hiện huấn luyện lập trình, mỗi nhiệm vụ được chia thành ba chiều độc lập: bản thân nhiệm vụ, khung thực thi, phương thức xác thực, ba thứ kết hợp tự do.
Cùng một đề bài, đôi khi làm trong khung Claude Code, đôi khi làm trong OpenClaw, đôi khi đổi một phương thức xác thực.
Hiệu quả giống như một thực tập sinh được luân chuyển đến tất cả các nhóm dự án. Thứ nó buộc phải học là chiến lược tổng quát giải quyết vấn đề, không phải "trong một khung cụ thể thì làm sao để lách".
Điều này giải thích một hiện tượng phản trực giác: Qwen3.7-Max biểu hiện đều ổn trong các khung Claude Code, OpenClaw, Qwen Code, không xuất hiện tình trạng "trong khung của mình thì mạnh, đổi cái khác thì tụt dốc".

Nâng cấp thứ hai là, thực thi tự chủ tầm xa.
Trong huấn luyện, nhóm đã đưa vào khung "trò chơi sinh tồn tích lũy động".
Tức là, để mô hình đưa ra quyết định liên tục hơn một nghìn bước trong môi trường mô phỏng thay đổi liên tục, tự xây dựng giả thuyết, điều chỉnh chiến lược dựa trên phản hồi, và không được "thoái hóa ngữ cảnh" vì chạy quá lâu.
Ở đây có một dữ liệu trực quan, YC-Bench mô phỏng công ty khởi nghiệp vận hành cả năm, Qwen3.7-Max đạt doanh thu 2,08 triệu USD, gấp đôi thế hệ trước (1,05 triệu).
Quan trọng hơn, nó thể hiện sự tiến hóa chiến lược, khi gặp khủng hoảng ở giai đoạn giữa có thể tự chủ điều chỉnh hướng đi, nhận diện và chặn khách hàng độc hại, cuối cùng hội tụ vào vòng lặp thực thi ổn định.
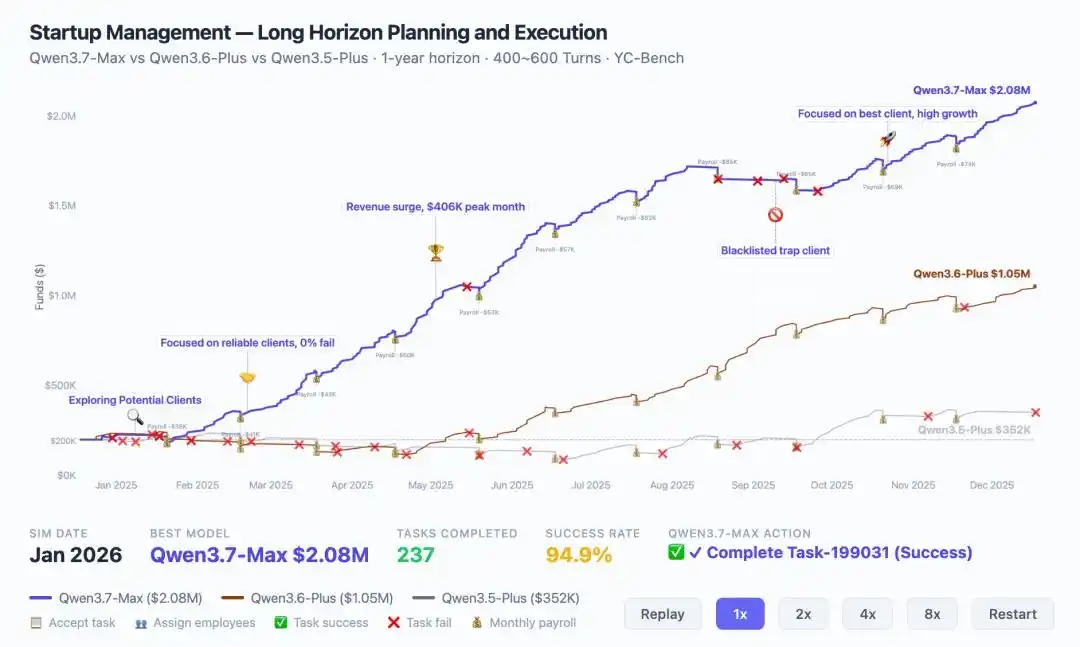
Đây chính là nền tảng hỗ trợ cho trường hợp tối ưu hóa kernel 35 giờ, cũng là lý do tại sao trên Kernel Bench L3, Qwen3.7-Max có thể khiến 96% tình huống chạy ra hiệu quả tăng tốc.
Mà lập trình mới chỉ là mặt trận đầu tiên. Nền tảng suy luận tầm xa cộng với gọi công cụ này, hướng tới một tham vọng lớn hơn——Nền tảng Agent tổng quát.
Chung kết lập trình, thêm một kẻ gây rối
Từ khi Code Arena ra mắt đến nay, những gì nó kiểm tra luôn là kỹ năng cứng, suy luận đa bước, sắp xếp công cụ, bàn giao dự án hoàn chỉnh, toàn là cạnh tranh thực chiến cấp độ Agent.
Hôm nay, Qwen3.7-Max với thành tích 1541 điểm đã chèn vào vị trí thứ tư, kẹp giữa Opus 4.6 Thinking và Opus 4.6.
Trên đường đua mà Claude thống trị phần lớn nửa năm này, nó đã đưa ra câu trả lời của mình, mô hình Trung Quốc không chỉ là kẻ đuổi theo, mà còn có thể là người định nghĩa.
Cuộc đua mô hình lập trình toàn cầu, không còn là độc diễn của thung lũng Silicon nữa.
Tài liệu tham khảo:
https://arena.ai/leaderboard/code/webdev
Bài viết này đến từ tài khoản WeChat công chúng "Tân Trí Nguyên", tác giả: ASI Khải Thị Lục