Văn | Silicon Star
Trò đùa nổi tiếng của Sam Altman lần này đã ứng nghiệm lên tất cả mọi người.
Năm ngoái khi quảng bá GPT-5, CEO của OpenAI đã nói một câu sau đó bị cộng đồng mạng chế giễu: "Cảm giác đó, giống như chứng kiến vụ nổ bom nguyên tử, khiến người ta chóng mặt ngồi bệt xuống." Kể từ đó, mỗi khi giới AI ra mắt sản phẩm mới kèm theo những lời lẽ cường điệu, trò đùa này lại bị mang ra mổ xẻ.

Nhưng tối hôm trước, người chóng mặt ngồi bệt xuống không phải là Altman. Lần này là tất cả người dùng đang dán mắt vào màn hình chờ đợi OpenAI ra bài.
Altman theo thói quen lại làm ra vẻ bí ẩn, đăng một dòng tweet: "Chúng tôi đã chuẩn bị vài thứ thú vị."
Đến 3 giờ sáng, GPT-Image 2 chính thức ra mắt. Giới AI toàn cầu lập tức dậy sóng.
"Images are a language, not decoration." (Hình ảnh là một ngôn ngữ, không phải đồ trang trí)
Đây là câu đầu tiên OpenAI viết trên trang ra mắt. Dịch sang tiếng khác thì chỉ có một ý: Kể từ hôm nay, hình ảnh không còn là đồ trang trí, bản thân nó đã là ngôn ngữ. Đây là tuyên ngôn về bước nhảy vọt thế hệ gửi đến toàn ngành thị giác máy tính.
Suốt một năm qua, vẽ tranh AI vẫn còn mắc kẹt trong vũng lầy thẩm mỹ "vẽ có giống không". GPT-Image 2 xuất hiện, trực tiếp nhấn nút chuyển đổi — sinh ảnh AI chính thức bước vào "phòng thi trí tuệ" với tiêu chí logic có đúng không.
Độ chính xác của mô hình này, dùng từ "kinh khủng" để miêu tả cũng không quá lời.
Trên bảng xếp hạng tạo ảnh từ văn bản và chỉnh sửa ảnh của Artificial Analysis, nó đều đứng đầu, và biểu hiện thực chiến còn có tính áp đảo hơn nữa.
Cảm giác đó, giống như khi Seedance 2.0 trong lĩnh vực tạo video xuất hiện vậy, nó sớm không còn là công cụ hỗ trợ của con người nữa, nó đang định nghĩa tiêu chuẩn ngành mới.
Chú thích: Tất cả hình ảnh trong bài viết này đều được tạo bởi GPT-Image 2, nội dung hình ảnh hoàn toàn là hư cấu.
01 Sự thức tỉnh của cỗ máy tư duy
Trước đây, tiêu chuẩn đầu tiên để đánh giá một mô hình hình ảnh tốt hay không là xem nó có giống người thật, có giống vật mẫu không.
Trước con quái vật GPT-Image 2 này, bộ tiêu chuẩn đó đã lỗi thời. Hoàn toàn lỗi thời.
Điểm đột phá cốt lõi nhất của mô hình mới nằm ở đây: Nó là một mô hình hình ảnh hỗ trợ chế độ tư duy.
Nghĩa là sao? Sau khi người dùng nhập prompt, mô hình không còn đơn giản là khử nhiễu, ghép các điểm ảnh. Nó đầu tiên hoàn thành một lần mô phỏng tư duy ở backend, rồi mới bắt đầu vẽ.
Một bức ảnh test thực tế bị rò rỉ từ cộng đồng Linux.do minh họa rõ vấn đề nhất. Mô hình mô phỏng cảnh Lei Jun chạy bộ livestream:
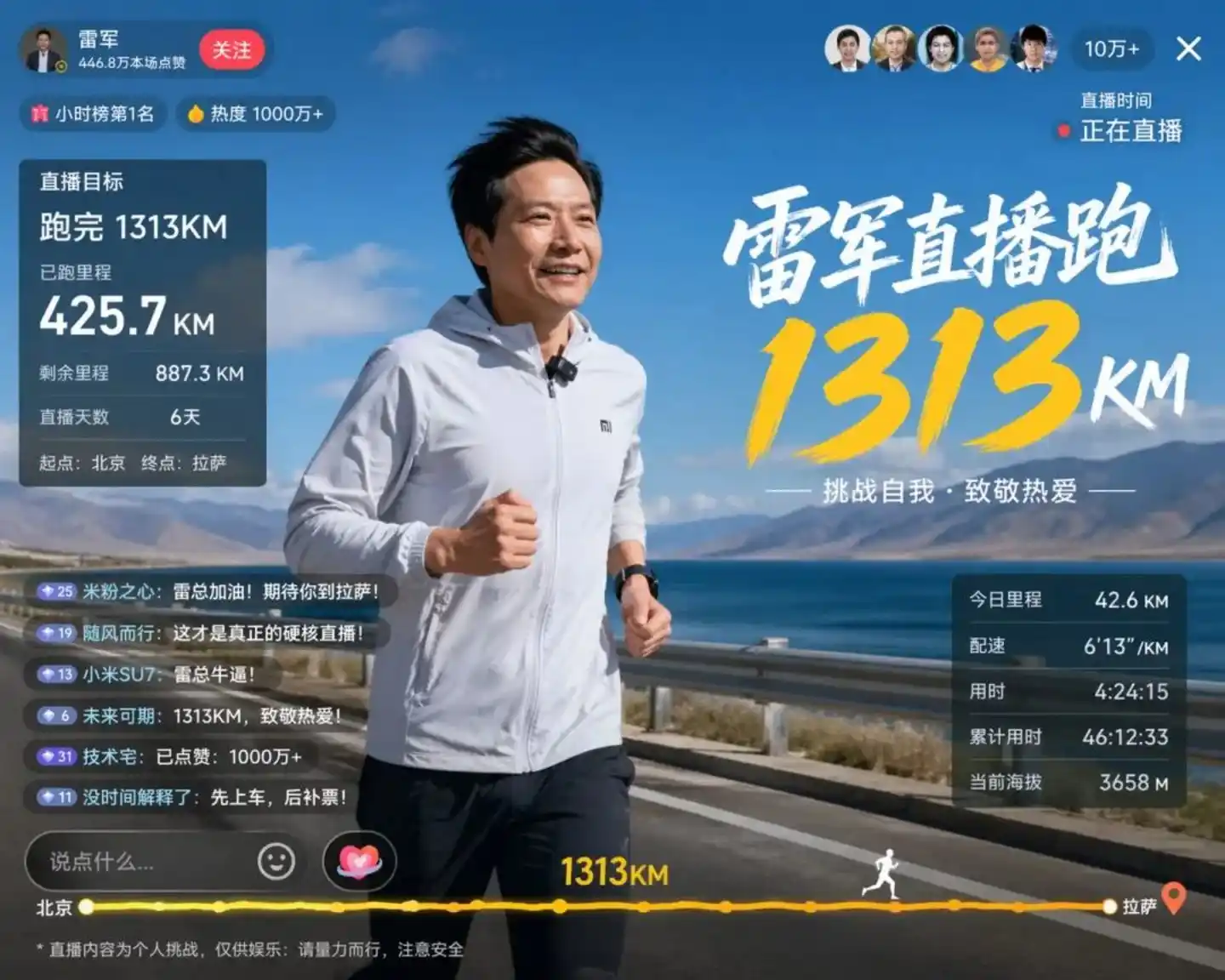
Nguồn ảnh: https://cdn3.linux.do/original/4X/0/f/3/0f37c8bc968e3d563cc6100d8e7f80ee305661ff.jpeg
Bức ảnh này khiến không ít nhà phát triển hít một hơi dài. Đặc điểm khuôn mặt của ông Lôi được khôi phục chính xác — giống như ảnh chụp — trong ảnh còn hiển thị rõ ràng: Mục tiêu livestream 1313km, số km đã chạy 425.7km, số km còn lại 887.3km. Tuyệt hơn nữa, độ cao hiện tại ghi là 3658m.
3658m là khái niệm gì? Từ Bắc Kinh đến Lhasa, độ cao điển hình khi vào khu vực Tây Tạng, chính xác là con số này.
Trong mắt con người, đây chỉ là phép cộng trừ toán học đơn giản và kiến thức địa lý thông thường. Nhưng hãy nghĩ thử: Đối với một mô hình hình ảnh, việc thống nhất ba yếu tố logic toán học + kiến thức địa lý + quy chuẩn UI có ý nghĩa gì?
Kết luận rất trực tiếp: Trước khi tạo ra điểm ảnh đầu tiên, GPT-Image 2 đã hoàn thành một vòng suy luận. Nó đã hiểu ý nghĩa của "số km", hiểu mối quan hệ logic của phép cộng trừ, và cũng hiểu đặc điểm trực quan của vùng cao nguyên.
Đây còn là vẽ tranh nữa sao. Đây là tư duy.
02 Từ đồ chơi đến công cụ sản xuất
Trước năng lực như vậy, thái độ của tất cả mọi người đối với mô hình hình ảnh, nên thay đổi.
Nó sớm không còn là món đồ chơi để bạn vẽ avatar, làm hình nền nữa. Một bước vượt qua ngưỡng "có thể dùng", lao thẳng vào khu vực "dùng tốt" — một công cụ có thể ném vào kịch bản thương mại để làm việc trực tiếp.
Lấy việc thiết kế poster mà nói. Thẩm mỹ bố cục, xử lý ánh sáng, sự nắm bắt tone màu thương hiệu của GPT-Image 2, không nghi ngờ gì đã đạt đến trình độ mà đại đa số nhà thiết kế con người bình thường khó lòng với tới.

Nguồn ảnh: https://cdn3.linux.do/original/4X/7/a/1/7a12ccd6b745be5ad8828eb0ac225d218fb43cbc.jpeg
Trong xã hội loài người, việc thuê một designer cao cấp thiết kế một poster cấp thương mại, chi phí giao tiếp, chi phí thời gian và thù lao thiết kế hàng nghìn tệ thường là gánh nặng đối với các doanh nghiệp vừa và nhỏ.
Tuy nhiên, với GPT-Image 2, ngay cả khi không hài lòng và điều chỉnh hàng chục lần, chi phí cũng chỉ ở mức vài đô la.
Trong các lĩnh vực như thiết kế poster, tài liệu marketing, minh họa tranh kèm, người dùng quan tâm căn bản không phải là "có thật không", mà quan tâm là "có đẹp không, có chuẩn không". Chính vì thế, hiệu suất thay thế của AI là mang tính hủy diệt.
Trong tài liệu dành cho nhà phát triển được cập nhật đồng bộ, còn ẩn giấu một chi tiết thú vị: Trong mã ví dụ xuất hiện thường xuyên model: "gpt-5.4".
Chế độ tư duy cộng với mô hình flagship, tổ hợp này ám chỉ một điều: GPT-Image 2 tuyệt đối không phải là sản phẩm đơn lẻ. Nó là thiết bị đầu cuối thị giác được sinh ra dành cho thế hệ mô hình ngôn ngữ lớn tiếp theo.
Thông qua Responses API mới, quá trình sinh ảnh sẽ tương tác tự nhiên như trò chuyện với mô hình ngôn ngữ lớn. Mô hình bổ sung chức năng cho phép sửa đổi qua đối thoại nhiều vòng, sau khi sinh ảnh lần đầu kết thúc, người dùng có thể đưa ra các chỉ thị sửa đổi khiến bên B đau đầu.
Thông qua Responses API mới, quá trình sinh ảnh sẽ tương tác tự nhiên như trò chuyện với mô hình ngôn ngữ lớn. Mô hình bổ sung chức năng sửa đổi đối thoại nhiều vòng, sau khi bản đầu tiên được tạo, người dùng có thể đưa ra các chỉ thị khiến nhà thiết kế bên B tăng huyết áp: "Nền tối thêm một chút." "Logo dịch sang bên vài pixel."
Những nhu cầu sửa đổi theo thời gian thực tương tác này,恰恰 là phần phiền phức và hao tổn kiên nhẫn nhất trong công việc hàng ngày của nhà thiết kế. Giờ đây, được giải quyết dễ dàng.
03 Đỉnh cao của kết xuất tiếng Trung
GPT-Image 2 tuy là mô hình của nước ngoài, nhưng người dùng trong nước lại nhất loạt khen ngợi.
Nguyên nhân chỉ có một: Hỗ trợ chữ Hán của nó, có thể nói là hoàn hảo.
Trong các ảnh test thực tế từ cộng đồng, bạn có thể thấy cảnh tranh luận nổi tiếng giữa Luo Yonghao và Wang Ziru:
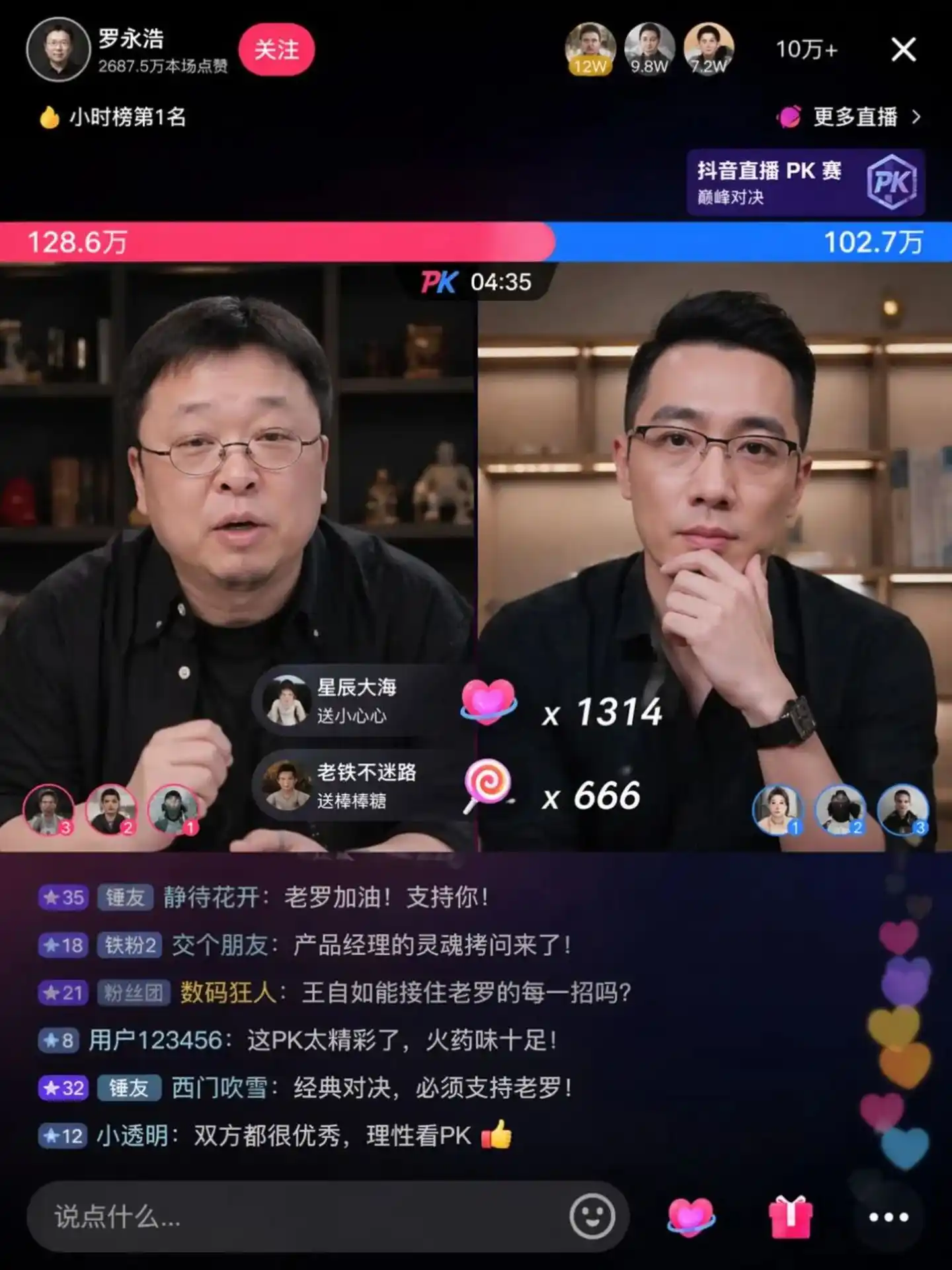
Nguồn ảnh: https://cdn3.linux.do/original/4X/0/9/7/097ed46991d2464442aebc6b1076a292cc839fec.jpeg
Có thể thấy Musk livestream bán hàng cho Lao Gan Ma:

Nguồn ảnh: https://cdn3.linux.do/original/4X/2/f/a/2fa77cf040e6337643829df4ec5ca6467d2866b2.jpeg
Thậm chí có thể thấy đơn thuốc bác sĩ viết:

Nguồn ảnh: https://cdn3.linux.do/original/4X/9/f/f/9ffeab83675648b43116cd0763f6c8b560611ae6.jpeg
Những văn bản trong các hình ảnh này, không còn là những "chữ Hán giả" xiêu vẹo, lộn xộn nữa, mà là những bản thiết kế hoàn chỉnh mang đậm vẻ đẹp thư pháp, cảm giác tầng lớp font chữ và nghệ thuật sắp xếp bố cục.
Rõ ràng, OpenAI đã đổ vào tập dữ liệu huấn luyện một lượng lớn ảnh ngữ liệu tiếng Trung, thực hiện huấn luyện tăng cường có mục tiêu.
So với mô hình thế hệ trước, sự mạnh mẽ của GPT-Image 2 được thể hiện rõ nét hơn.
Trong bài test so sánh, mô hình thế hệ trước phiên bản 1.5 tuy có thể vẽ ra thứ giống sách nấu ăn, nhưng nhìn kỹ, văn bản hầu như toàn là mã lộn.

Nguồn ảnh: https://cdn3.linux.do/optimized/4X/2/b/3/2b38f3c1a134515d564f07f81661c0bd9578c6b9_2_750x750.jpeg
Nhưng cùng một công thức nấu ăn do GPT-Image 2 tạo ra, lại khiến người ta thấy độ rõ nét của văn bản và thẩm mỹ đã có bước đột phá mang tính cột mốc.
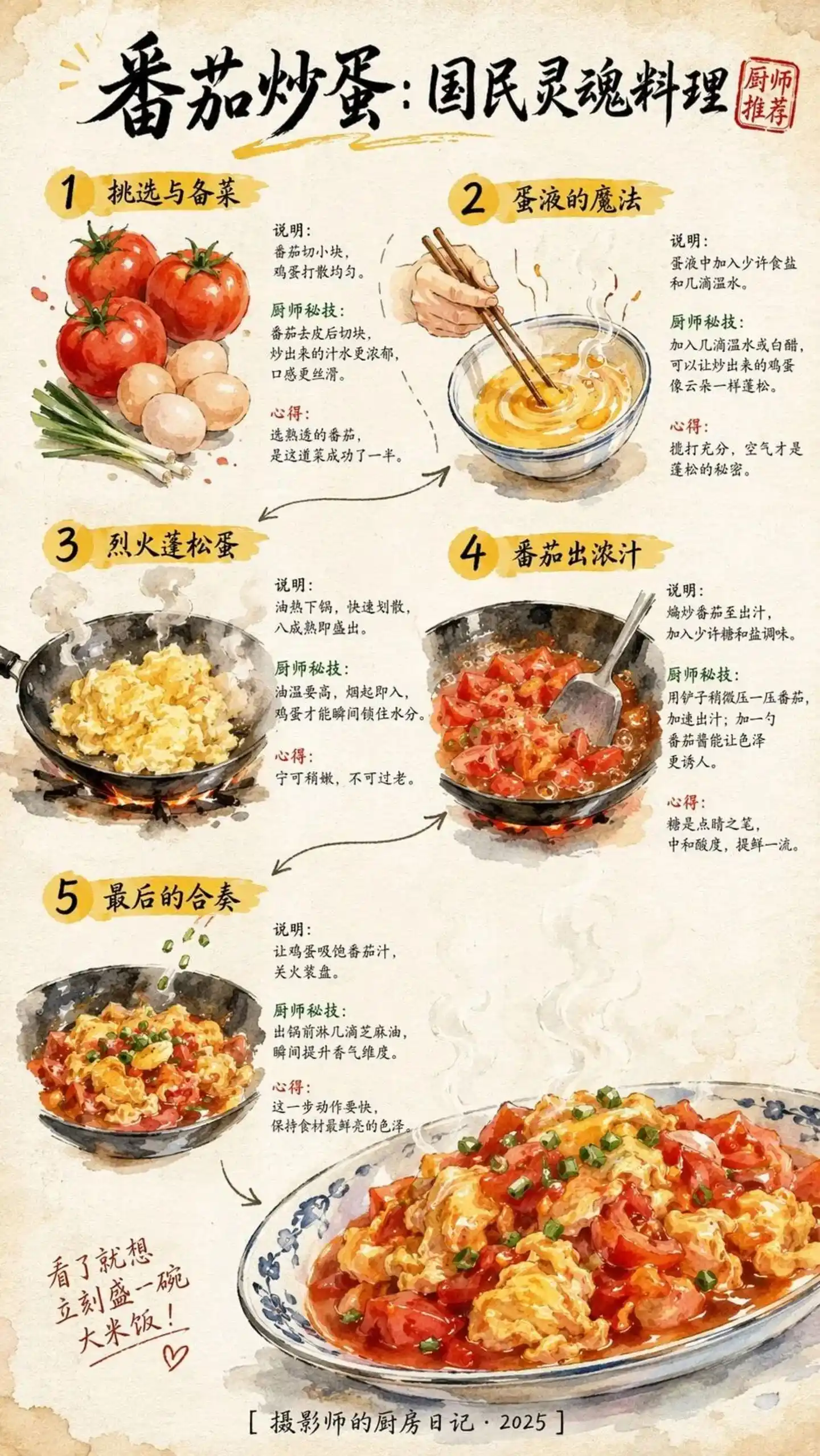
Nguồn ảnh: https://cdn3.linux.do/original/4X/0/2/5/02513b10135d824ccb1c22bd0c7eb441f1e34455.jpeg
Đối với prompt từ hơn trăm ký tự tiếng Trung, năm bước vẫn có thể nhìn thấy rõ ràng, tính nhất quán giữa hình và văn bản đáng hài lòng. Đây không chỉ là một bức ảnh, mà còn là một phương án thực chiến có thể tái hiện.
Tuy nhiên, ở đây cũng nảy sinh một vấn đề kỹ thuật thú vị: Mô hình hình ảnh có thực sự giải quyết triệt để vấn đề mã lộn không?
Phán đoán của tôi là: E là không.
Mô hình ngôn ngữ lớn tạo token, dựa vào logic ngữ nghĩa. Giai đoạn học tăng cường dựa vào xác suất, ngữ liệu chất lượng càng cao, logic càng hợp lý. Nhưng bản chất của mô hình hình ảnh, rốt cuộc là tạo điểm ảnh. Mối quan hệ logic giữa các điểm ảnh, hoàn toàn không giống với mối quan hệ logic giữa các văn bản.
Nói cách khác, mạnh mẽ như GPT-Image 2, cũng không thực sự "hiểu" quy luật của văn bản. Nó chỉ học vẹt diện mạo của văn bản ở tầng điểm ảnh.
Một bức ảnh thương lượng làm ăn với Ultraman đã lộ ra điểm này: Trên bao bì hai thùng đồ uống, chữ "Mengniu" và "Wanglaoji" to tướng được viết cực kỳ hoàn hảo, nhưng chữ nhỏ phía dưới vẫn là những khối màu mờ.

Nguồn ảnh: https://cdn3.linux.do/original/4X/d/7/c/d7c4fb063202bcbf56b9ca0623aa0ce6fc26e542.jpeg
Trong mô hình kỹ thuật hiện có, logic tạo vẫn là "sắp xếp theo điểm ảnh", cách một bước bản chất so với "kết xuất theo ký tự". Mã lộn ở những chỗ cực kỳ nhỏ, có thể vĩnh viễn không thể loại bỏ triệt để.
Nhưng nói lại, đối với hơn 90% kịch bản ứng dụng thương mại, như vậy đã đủ rồi.
04 Khiếm khuyết và ranh giới chưa đạt đến mức thần thánh
Dù đã ngồi lên ngôi vị số một thế giới, GPT-Image 2 cũng có mặt vụng về của nó.
Trong test thực tế phát hiện, do chế độ tư duy sẽ gọi tìm kiếm trực tuyến và tiến hành suy diễn logic, khi xử lý nhiệm vụ hư cấu cực kỳ phức tạp, mô hình đôi khi rơi vào vòng luẩn quẩn logic — suy nghĩ gần 40 phút, vẫn không thể trả lời.
Đồng thời, API tuyên bố hỗ trợ độ phân giải 2K thậm chí 4K, đồng nghĩa với mức tiêu thụ token cực cao và độ trễ.
Đối với người dùng thông thường, làm thế nào để cân bằng giữa chất lượng hình ảnh tuyệt đỉnh và tốc độ phản hồi, là bài học bắt buộc trong quá trình sử dụng tương lai.
Trong lĩnh vực kỹ thuật, năng lực mạnh mẽ mãi mãi là một thanh kiếm hai lưỡi.
Dù là mô hình hình ảnh hay mô hình video, đều không tránh khỏi việc phải đối mặt với thách thức đạo đức về giả mạo sâu (deep fake).
Trong hầu hết các trường hợp test thực tế hiện tại, AI tạo ra đều là nhân vật nổi tiếng, nhưng nếu thay họ bằng những người bình thường từng đăng ảnh trên các mạng xã hội, trong trường hợp không quen biết bản thân họ đã cực kỳ khó phân biệt thật giả.
Ngoại trừ mã lộn thỉnh thoảng xuất hiện trong nền có thể khiến AI lộ tẩy, bản thân con người đã không có bất kỳ sơ hở nào.
Vì vậy, những lĩnh vực từng phải do người thật hoàn thành, đang phải đối mặt với cuộc khủng hoảng niềm tin chưa từng có.
Việc ra mắt GPT-Image 2, đã đưa mô hình sinh ảnh từ đồ chơi trở thành công cụ sản xuất.
Trước đây người ta dùng AI để cung cấp cảm hứng, mà ngày nay AI bắt đầu thử nghiệm tiếp quản toàn bộ quy trình từ ý tưởng, tính toán, bố cục đến thành phẩm.
Đối với người làm trong ngành thiết kế, đây là một thời đại tràn ngập FOMO (Nỗi sợ bị bỏ lỡ).
Nhưng đối với những người giỏi sử dụng công cụ, có thẩm mỹ sản phẩm và tư duy logic, đây lại là một thời đại tốt nhất.
Hình ảnh bắt đầu học cách tư duy, văn bản không còn là tạp âm của điểm ảnh.
Mọi người cách điểm kỳ dị thị giác (visual singularity) nghĩ gì được đó đó, có lẽ thực sự chỉ còn một bước chân.