Biên soạn: KarenZ, Foresight News
Tiêu đề gốc: Giải Mã Thuật Toán Đề Xuất Mới Của X Bằng Ngôn Ngữ Dễ Hiểu: Từ 'Vớt Dữ Liệu' Đến 'Chấm Điểm'
Elon Musk đã thay đổi hệ thống đề xuất của Twitter từ 'xây dựng thủ công các quy tắc và phần lớn thuật toán heuristic' thành 'hoàn toàn dựa vào AI mô hình lớn để đoán sở thích của bạn'?
Vào ngày 20 tháng 1, Twitter (X) chính thức tiết lộ thuật toán đề xuất mới, tức là logic đằng sau dòng thời gian "Dành Cho Bạn" (For You) trên trang chủ.
Nói một cách đơn giản, thuật toán hiện tại là: trộn lẫn "nội dung từ những người bạn theo dõi" và "nội dung trên toàn mạng có thể hợp khẩu vị của bạn" lại với nhau, sắp xếp chúng theo thứ tự dựa trên một loạt hành động bạn đã thực hiện trước đó trên X như thích, bình luận, v.v., trải qua hai lần lọc, và cuối cùng biến thành luồng thông tin đề xuất mà bạn lướt xem.
Dưới đây là logic cốt lõi được dịch bằng ngôn ngữ dễ hiểu:
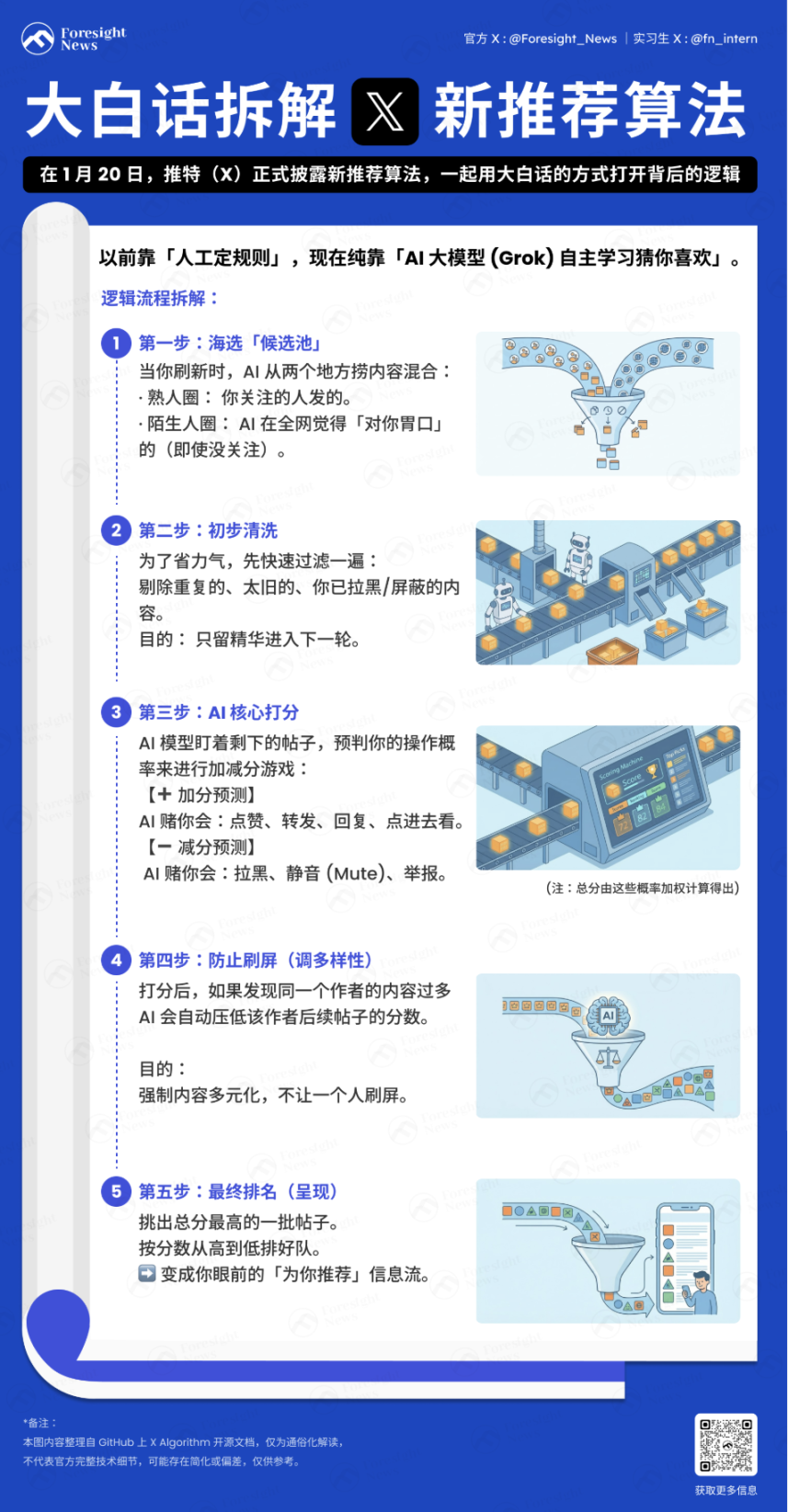
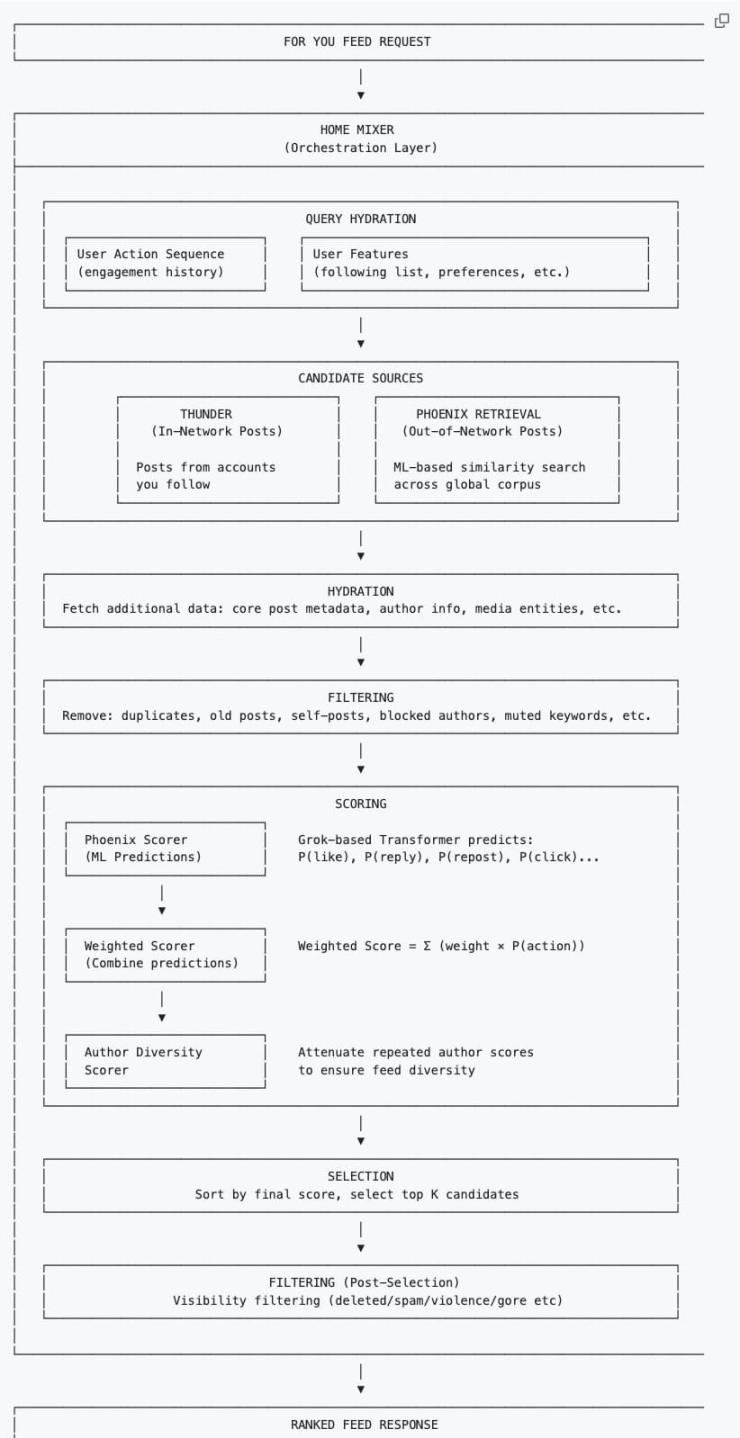
Xây Dựng Hồ Sơ Người Dùng
Hệ thống đầu tiên thu thập thông tin ngữ cảnh của người dùng để xây dựng "hồ sơ" cho việc đề xuất sau này:
-
Chuỗi hành vi người dùng: Lịch sử tương tác (thích, chia sẻ lại, thời gian dừng lại, v.v.).
-
Đặc điểm người dùng: Danh sách theo dõi, cài đặt sở thích cá nhân, v.v.
Nội Dung Đến Từ Đâu?
Mỗi khi bạn làm mới dòng thời gian "Dành Cho Bạn", thuật toán sẽ tìm nội dung từ hai nơi sau:
-
Vòng kết nối quen thuộc (Thunder): Các bài đăng từ những người bạn theo dõi.
-
Vòng kết nối người lạ (Phoenix): Những người bạn không theo dõi, nhưng AI sẽ dựa vào khẩu vị của bạn để tìm ra những bài đăng bạn có thể quan tâm (ngay cả khi bạn không theo dõi tác giả) từ biển người mênh mông.
Hai nhóm nội dung này sẽ được trộn lẫn với nhau, tạo thành các bài đăng ứng viên.
Bổ Sung Dữ Liệu và Lọc Sơ Bộ
Sau khi vớt lên hàng nghìn bài đăng, hệ thống sẽ kéo siêu dữ liệu đầy đủ của bài đăng (thông tin tác giả, tệp media, văn bản chính), quy trình này gọi là Hydration. Sau đó, một vòng làm sạch nhanh sẽ được thực hiện để loại bỏ nội dung trùng lặp, bài đăng cũ, bài đăng do chính người dùng đăng, nội dung từ tác giả đã chặn hoặc nội dung có từ khóa bị chặn.
Bước này nhằm tiết kiệm tài nguyên tính toán, tránh để nội dung không hiệu quả đi vào giai đoạn chấm điểm cốt lõi.
Chấm Điểm Như Thế Nào?
Đây là phần quan trọng nhất. Mô hình Transformer dựa trên Phoenix Grok sẽ theo dõi từng bài đăng ứng viên còn lại sau khi lọc và tính toán xác suất bạn thực hiện các hành động khác nhau với nó. Đây là một trò chơi cộng điểm và trừ điểm:
Điểm cộng (Phản hồi tích cực): AI nghĩ rằng bạn có thể sẽ thích, chia sẻ lại, trả lời, nhấp vào hình ảnh hoặc nhấp vào để xem trang cá nhân.
Điểm trừ (Phản hồi tiêu cực): AI nghĩ rằng bạn có thể sẽ chặn tác giả, tắt tiếng (Mute), báo cáo.

Điểm cuối cùng = (Xác suất thích × Trọng số) + (Xác suất trả lời × Trọng số) – (Xác suất chặn × Trọng số)...
Đáng chú ý là, trong thuật toán đề xuất mới, Author Diversity Scorer (Bộ chấm điểm đa dạng tác giả) thường sẽ can thiệp sau khi AI tính toán xong điểm cuối cùng. Khi phát hiện trong một loạt bài đăng ứng viên có nhiều nội dung từ cùng một tác giả, công cụ này sẽ tự động "hạ thấp" điểm số của các bài đăng tiếp theo của tác giả đó, giúp các tác giả bạn thấy được đa dạng hơn.
Cuối cùng, dựa trên điểm số để sắp xếp và chọn ra một loạt bài đăng có điểm cao nhất.
Lọc Lần Hai
Hệ thống kiểm tra lại một lần nữa số bài đăng có điểm cao nhất (ví dụ: top 1500) để lọc bỏ những bài vi phạm (như thư rác, nội dung bạo lực), loại bỏ trùng lặp cho nhiều phần của cùng một thread (chuỗi bài), và cuối cùng sắp xếp theo điểm số từ cao xuống thấp, trở thành luồng thông tin bạn nhìn thấy.
Tóm Tắt
X đã loại bỏ tất cả các tính năng được thiết kế thủ công và phần lớn thuật toán heuristic khỏi hệ thống đề xuất. Tiến bộ cốt lõi của thuật toán mới nằm ở việc "để AI tự học sở thích người dùng", đạt được bước nhảy vọt từ "bảo máy tính làm thế nào" sang "để máy tính tự học cách làm".
Đầu tiên là đề xuất chính xác hơn, "dự đoán đa chiều" phù hợp hơn với nhu cầu thực tế. Thuật toán mới dựa vào mô hình lớn Grok để dự đoán nhiều hành vi người dùng — không chỉ tính "liệu có thích / chia sẻ lại hay không", mà còn tính "liệu có nhấp vào liên kết để xem hay không", "thời gian dừng lại thế nào", "liệu có theo dõi tác giả hay không", thậm chí dự đoán "liệu có báo cáo / chặn hay không". Sự đánh giá tinh vi như vậy giúp nội dung được đề xuất phù hợp với nhu cầu tiềm thức của người dùng ở một mức độ chưa từng có.
Thứ hai, cơ chế thuật toán tương đối công bằng hơn, ở một mức độ nào đó có thể phá vỡ lời nguyền "độc quyền tài khoản lớn", mang lại nhiều cơ hội hơn cho tài khoản mới, tài khoản nhỏ: Thuật toán heuristic trong quá khứ có một vấn đề chết người: các tài khoản lớn dựa vào lịch sử tương tác cao, đăng nội dung gì cũng có thể nhận được曝光 (phơi sáng) cao, trong khi tài khoản mới dù có nội dung chất lượng cao, cũng bị chôn vùi vì "không có tích lũy dữ liệu". Cơ chế cách ly ứng viên (Candidate isolation mechanism) khiến mỗi bài đăng được chấm điểm độc lập, không liên quan đến "việc các nội dung khác trong cùng lô có phải là爆款 (bom tấn) hay không". Đồng thời, Author Diversity Scorer cũng sẽ giảm hành vi刷屏 (làm ngập màn hình) của các bài đăng tiếp theo cùng tác giả trong cùng một lô.
Đối với công ty X: Đây là một biện pháp cắt giảm chi phí và tăng hiệu quả, dùng sức mạnh tính toán để đổi lấy nhân lực, dùng AI để đổi lấy tỷ lệ giữ chân. Đối với người dùng, chúng ta đang đối mặt với một "siêu bộ não" luôn luôn suy đoán lòng người. Nó càng hiểu chúng ta, chúng ta càng không thể rời xa nó, nhưng cũng chính vì nó quá hiểu chúng ta, chúng ta sẽ càng lún sâu vào "buồng kén thông tin" (information cocoon) do thuật toán dệt nên, và dễ trở thành đối tượng bị bắt giữ chính xác bởi các nội dung mang tính cảm xúc.
Twitter:https://twitter.com/BitpushNewsCN
Nhóm trao đổi Telegram của Bitpush:https://t.me/BitPushCommunity
Kênh Telegram của Bitpush: https://t.me/bitpush





