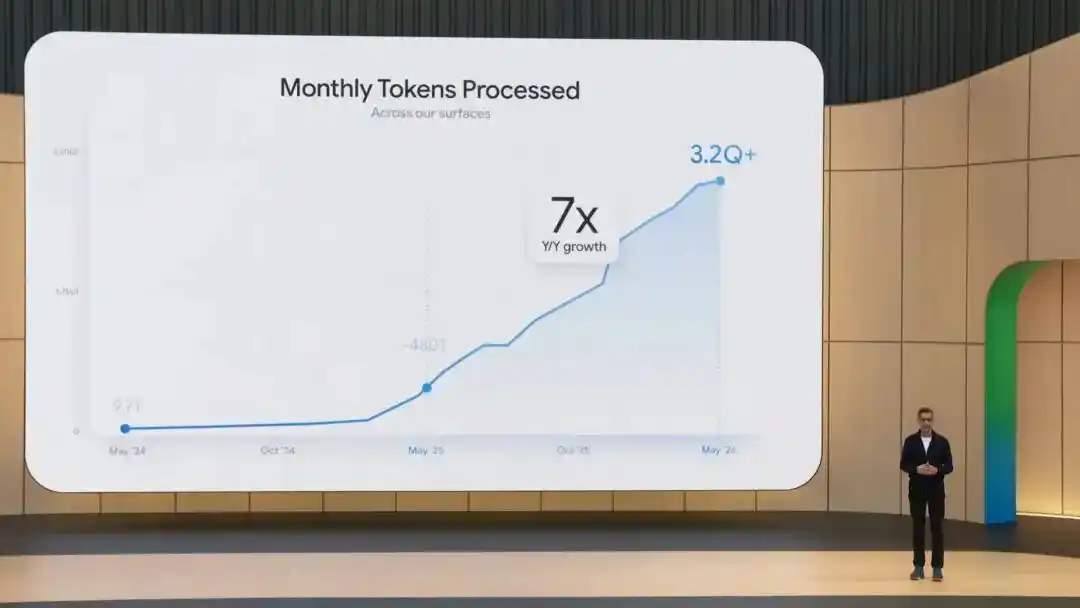
Gemini App đạt hơn 900 triệu MAU,xử lý 3,200 nghìn tỷ Token mỗi tháng, Nano Banana tạo ra hơn 50 tỷ hình ảnh......
Tại sự kiện Google I/O vừa kết thúc vào rạng sáng nay, CEO Google Sundar Pichai ngay lập tức đưa ra những con số này.
Một năm qua, AI trở thành chủ đề chính của mọi ngành công nghiệp, vị thế của Gemini trong Google cũng bắt đầu chuyển từ một ứng dụng độc lập thành nền tảng AI nền tảng quan trọng nhất trong mọi sản phẩm của Google.
Buổi ra mắt này cũng bắt đầu từ mô hình, sau đó dẫn đến các sản phẩm Coding và Agent.
Gemini Omni đẩy khả năng tạo video của Google theo hướng "mô hình thế giới", Gemini 3.5 Flash thì cùng với công cụ lập trình AI hướng đến nền tảng phát triển Agent.
Hai khả năng này sau đó sẽ đi vào hệ sinh thái hoàn chỉnh của Google: tìm kiếm, ứng dụng Gemini, Flow, Spark, Chrome, kính XR và các kịch bản thương mại điện tử.
Gemini Omni xuất hiện, thời khắc "Nano Banana" của làng video đã đến
Điểm đầu tiên được triển khai chi tiết trong buổi ra mắt là Gemini Omni. Chúng tôi đã làm một video so sánh với Seedance 2.0 để xem sự khác biệt giữa hai bên.
Google mô tả Gemini Omni là một mô hình mới có thể "tạo ra bất kỳ nội dung nào từ bất kỳ đầu vào nào".
Nó kết hợp khả năng suy luận của Gemini với các mô hình phương tiện sinh sẵn có của Google, nhằm mục tiêu nâng cao khả năng hiểu biết về thế giới, khả năng tạo đa phương thức và khả năng chỉnh sửa của mô hình.

Google nhấn mạnh, các mô hình như Veo, Nano Banana, Genie đã có thể tạo video, hình ảnh và mô phỏng tương tác, nhưng Gemini Omni tiến xa hơn, bắt đầu xử lý các vấn đề gần với thế giới vật lý hơn như động lực học, trọng lực.
Ví dụ được trình diễn tại hiện trường bao gồm video giải thích sự gấp nếp protein. Người dùng chỉ cần nhập gợi ý như "tạo một video giải thích bằng hoạt hình đất sét về sự gấp nếp protein", Omni có thể biến khái niệm khoa học trừu tượng thành nội dung video.

Nó cũng hỗ trợ chỉnh sửa video tự nhiên hơn. Người dùng có thể tải lên video của mình, sau đó sửa đổi phong cách, thêm phần tử, điều chỉnh chi tiết bằng cách đối thoại, thậm chí biến một hình tròn thông thường thành hố đen, biến cảnh đi dạo ban đêm thành một bức tranh giàu kịch tính hơn.

Google cho biết, Gemini Omni bắt đầu từ video, sau đó sẽ dần dần tiến đến "bất kỳ đầu vào đến bất kỳ đầu ra nào". Đây cũng là lý do Google luôn thiết kế Gemini thành một mô hình đa phương thức.
Mô hình đầu tiên của dòng Omni, Gemini Omni Flash, đã được tích hợp vào các sản phẩm của Google, thông tin về Omni Pro sẽ được công bố sau. Tính năng Omni trong ứng dụng Gemini cũng đã mở cửa cho người dùng đăng ký Google AI Plus, Pro và Ultra.
Điều này có nghĩa, Gemini Omni không chỉ là một mô hình tạo video. Google muốn đặt nó vào câu chuyện kể về "mô hình thế giới": mô hình không chỉ tạo ra hình ảnh, mà còn phải hiểu mối quan hệ vật lý, quan hệ chuyển động và logic cảnh vật trong hình ảnh.
Sau khi đi vào các ứng dụng như Gemini App, Google Flow và YouTube Shorts, Omni cũng sẽ mở rộng công cụ sáng tạo sinh của Google từ chỉnh sửa ảnh sang chỉnh sửa video.
Gemini 3.5 Flash ra mắt, AI viết mã bước vào chế độ cực nhanh
Nếu Gemini Omni tương ứng với việc tạo và chỉnh sửa, thì Gemini 3.5 Flash tương ứng với tốc độ, chi phí và khả năng thực thi.

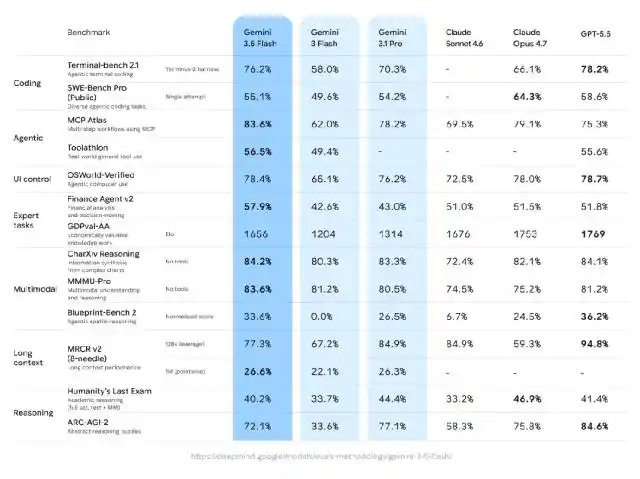
Google đã ra mắt Gemini 3.5 Flash tại buổi ra mắt, gọi nó là một trong những mô hình đầu tiên của dòng Gemini 3.5, tập trung vào agentic coding, nhiệm vụ dài hạn và quy trình làm việc thực tế.
So với 3.1 Pro, 3.5 Flash cải thiện rõ rệt trong hầu hết các bài kiểm tra chuẩn, đặc biệt là khả năng về mã, cũng như các đánh giá như GDPVal gần với nhiệm vụ kinh tế thực tế hơn.
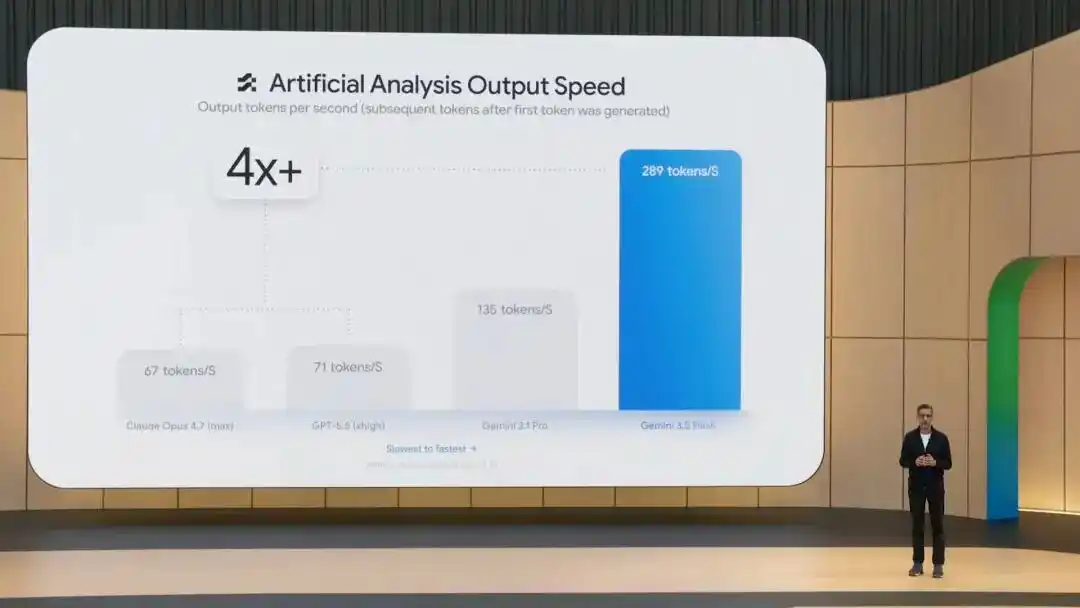
Bên cạnh hiệu suất kiểm tra chuẩn tốt, 3.5 Flash có tốc độ xuất tokens nhanh hơn 4 lần so với các mô hình tiên tiến khác, và sau khi được tối ưu hóa đặc biệt trong Antigravity, tốc độ có thể đạt tới 12 lần.
Đáng chú ý, vào tháng 3 năm nay, các nhiệm vụ phát triển liên quan nội bộ của Google xử lý khoảng 500 tỷ tokens mỗi ngày, sau đó cứ vài tuần lại tăng gấp đôi, hiện đã vượt quá 3 nghìn tỷ tokens mỗi ngày. Google gọi đây là một vòng lặp phản hồi, sử dụng quy mô sử dụng thực tế lớn để tiếp tục cải thiện 3.5 Flash.
Cùng với mô hình ra mắt là Antigravity 2.0.
Nó đã nâng cấp từ IDE chạy bằng agent trước đây thành một ứng dụng máy tính để bàn độc lập, chuyển trọng tâm sang agent first. Người dùng không còn chỉ để AI hỗ trợ viết mã trong trình soạn thảo, mà thông qua đối thoại Agent, sản phẩm Agent và sự phối hợp đa Agent để hoàn thành nhiệm vụ phát triển.
Antigravity 2.0 được thêm vào CLI đầy đủ, Antigravity SDK, hỗ trợ giọng nói gốc của mô hình âm thanh Gemini, và tích hợp các dịch vụ như Android, Firebase, Google AI Studio. Antigravity 2.0, với tư cách là ứng dụng máy tính để bàn độc lập, cũng đã mở cửa cho người dùng toàn cầu.
Google đã sử dụng một màn trình diễn cường độ cao tại hiện trường để giải thích hướng đi của Antigravity 2.0: để Agent xây dựng một hệ điều hành có thể chạy từ con số không. Nhiệm vụ này được thực hiện song song bởi 93 Agent con, kéo dài 12 giờ, phát ra hơn 15.000 yêu cầu mô hình, xử lý 2,6 tỷ tokens, từ dự án trống tạo ra các mô-đun lõi như bộ lập lịch, quản lý bộ nhớ, hệ thống tệp.
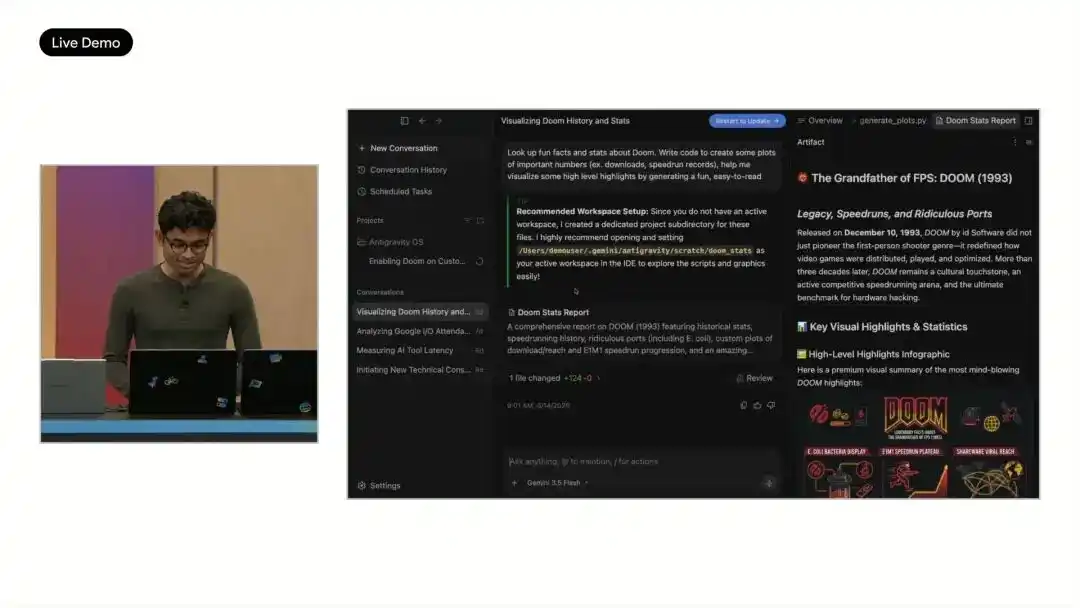
Google tuyên bố, việc này không thể hoàn thành trên Gemini 3.1 Pro, còn sử dụng Gemini 3.5 Flash chỉ tiêu tốn dưới 1000 USD API credits.
Hiện trường còn trình diễn hệ thống này chạy chương trình tàu hỏa SL và Doom. Do hệ thống ban đầu thiếu trình điều khiển video và bàn phím, Antigravity tiếp tục tạo mã liên quan và sửa chữa, để Doom có thể chạy. Google còn cho biết, các dự án như bộ công cụ chỉnh sửa ảnh, ứng dụng nhắn tin thời gian thực, nền tảng cộng tác đa người dùng đã được thử nghiệm theo cách tương tự, công việc kỹ thuật vốn cần nhiều ngày được nén xuống còn vài giờ hoặc ngắn hơn.
Gemini 3.5 Flash đã mở cửa cho tất cả người dùng, bao phủ các sản phẩm và API của Google.Gemini 3.5 Pro vẫn đang được sử dụng nội bộ và cải thiện, dự kiến mở cửa vào tháng sau.
Từ hộp tìm kiếm đến Agent thông tin, Google làm lại tìm kiếm AI
Sau mô hình và công cụ phát triển, Google chuyển trọng tâm sang tìm kiếm. Google Search chính là AI Search.

Google cho biết, AI Mode đã đạt hơn 1 tỷ MAU, lượng truy vấn tăng gấp đôi mỗi quý kể từ khi ra mắt.
Từ hôm nay, AI Mode được nâng cấp lên Gemini 3.5. Hộp tìm kiếm thông minh mới cũng bắt đầu được đẩy ra từ hôm nay. Nó hỗ trợ nhập liệu văn bản, hình ảnh, tệp và video, và đưa ra đề xuất AI khi người dùng nhập câu hỏi.

AI Overviews và AI Mode cũng được hợp nhất thành trải nghiệm tìm kiếm AI liên tục hơn. Người dùng có thể xem câu trả lời AI trên trang kết quả tìm kiếm chính trước, sau đó vào AI Mode để tiếp tục hỏi thêm, ngữ cảnh sẽ được giữ lại. Trải nghiệm tìm kiếm mới này đã được triển khai toàn cầu cho phiên bản máy tính để bàn và di động vào ngày ra mắt.
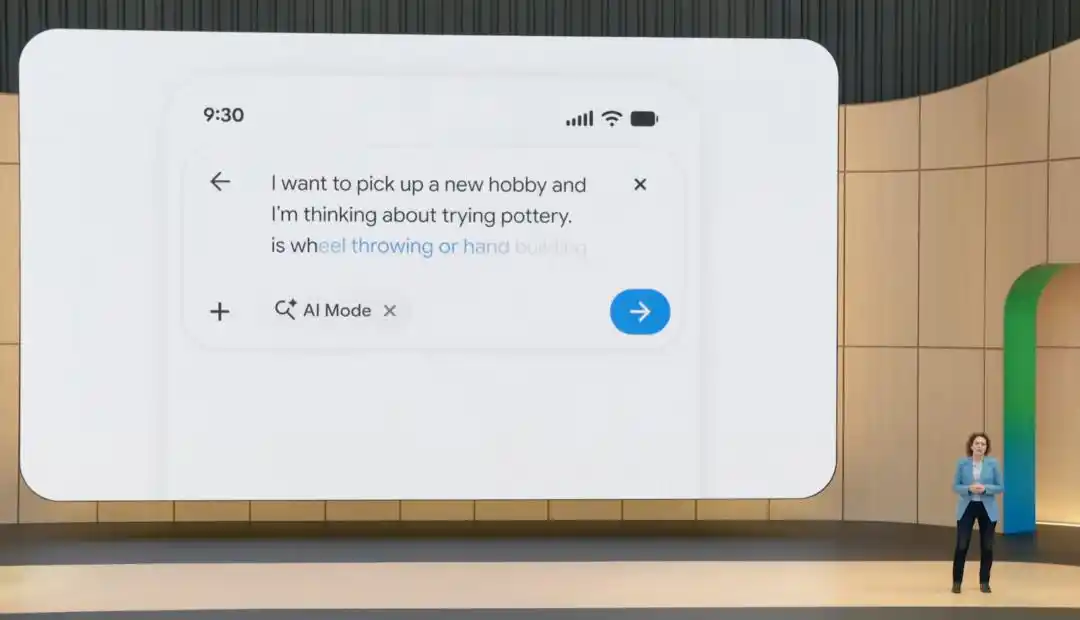
Thay đổi lớn hơn là Agent tìm kiếm. Người dùng sẽ có thể tạo Agent thông tin trong Search vào mùa hè năm nay, để nó theo dõi liên tục một loại thông tin nào đó.
Ví dụ, người dùng có thể để nó theo dõi cổ phiếu công nghệ sinh học lớn có tỷ lệ P/E dưới 15, dòng tiền dương, nợ thấp; cũng có thể để nó theo dõi dài hạn thông tin cho thuê nhà, giày thể thao hợp tác và sản phẩm mới ra mắt. Khi điều kiện thay đổi, Agent sẽ gửi cho người dùng bản cập nhật tổng hợp.

Google còn đưa khả năng agentic coding của Antigravity vào tìm kiếm.
Sau này, tìm kiếm không chỉ trả về trang web, tóm tắt hoặc thẻ, mà còn có thể tạo ra giao diện tương tác cho các câu hỏi cụ thể. Ví dụ người dùng hỏi "hố đen ảnh hưởng đến không-thời gian như thế nào", Search có thể tạo ra một thành phần trực quan tương tác; tiếp tục hỏi "lỗ đen kép tạo ra sóng hấp dẫn như thế nào", Search sẽ tạo lại một giao diện động có thể điều chỉnh tham số. Generative UI with Antigravity sẽ được cung cấp miễn phí cho tất cả người dùng vào mùa hè năm nay.

Các trải nghiệm tùy chỉnh phức tạp hơn cũng đang trên đường.
Google đã trình diễn tại hiện trường một công cụ lập kế hoạch cuối tuần, Search sẽ kết hợp thông tin thời tiết, bản đồ, sở thích người dùng, Gmail, Calendar để tạo ra một công cụ nhỏ có thể tiếp tục chỉnh sửa, chia sẻ và đồng bộ với lịch. Loại trải nghiệm tùy chỉnh này sẽ mở cửa trước cho người dùng đăng ký trong vài tháng tới.
Tắt máy vẫn chạy, Gemini Spark đưa khả năng Agent vào cuộc sống cá nhân
Sản phẩm mới quan trọng nhất ở phía người tiêu dùng là Gemini Spark.

Gemini Spark là một Agent AI cá nhân, chạy trên máy ảo chuyên dụng của Google Cloud, có thể thực thi nhiệm vụ suốt ngày đêm. Nó được cung cấp bởi Gemini 3.5 và Antigravity harness, hỗ trợ nhiệm vụ chạy nền dài hạn.
Sau khi người dùng tắt máy tính, Spark vẫn có thể tiếp tục làm việc. Ban đầu nó kết nối với các công cụ của Google, vài tuần tới sẽ kết nối với công cụ bên thứ ba thông qua MCP.

Buổi ra mắt đã trình diễn một số kịch bản điển hình của Spark.
Người dùng có thể để nó tổng hợp các bản phát hành và tiến triển của Gemini Live trong tuần qua, trích xuất thông tin từ Docs, Gmail và lịch sử trò chuyện, sau đó tạo email nhóm bằng phong cách viết cá nhân.
Cũng có thể để nó quản lý tiệc khu phố, duy trì bảng RSVP Google Sheets, theo dõi ai mang cái gì, tạo bản nháp email nhắc nhở cho hàng xóm chưa đăng ký, và tự động tạo trang quảng cáo Google Slides.
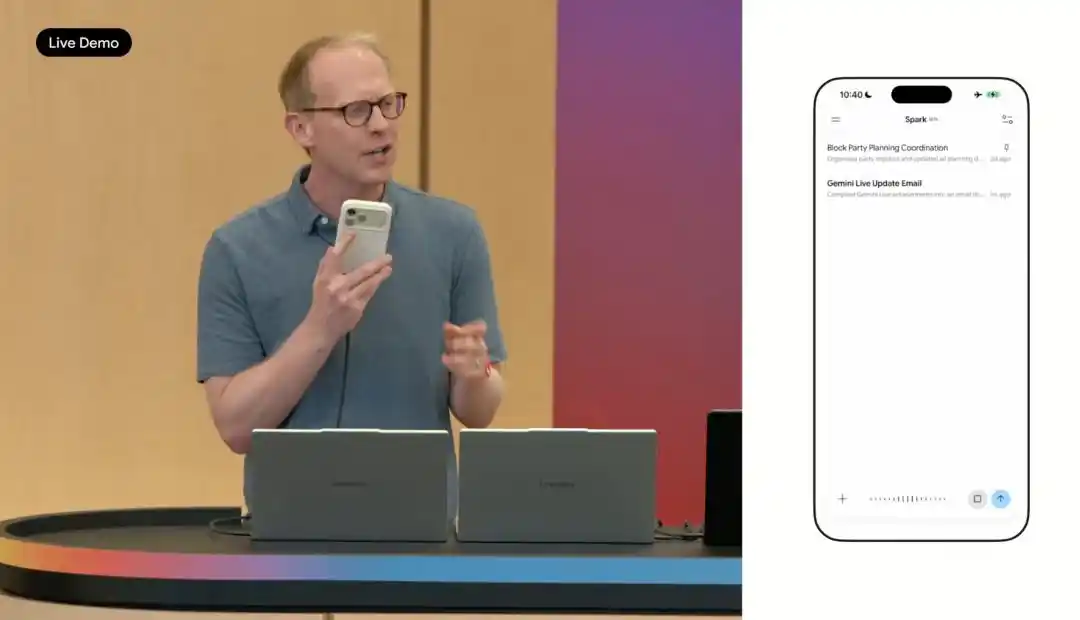
Spark còn hỗ trợ nhập giọng nói trên điện thoại di động.
Người dùng có thể nói ra nhiều nhiệm vụ cùng lúc, ví dụ như đánh dấu tất cả các cuộc họp với Sundar thành màu hồng sáng, viết thư mời cho hàng xóm mới, tạo tài liệu việc cần làm trước khi kết thúc năm học của con cái. Spark sẽ chia những nội dung này thành nhiều nhiệm vụ độc lập và thực thi ở chế độ nền, kết quả có thể đồng bộ giữa điện thoại và máy tính.
Gemini Spark sẽ mở cửa cho một số người thử nghiệm vào tuần này, và ra mắt dưới dạng beta cho người dùng đăng ký Google AI Ultra tại Mỹ vào tuần sau.

Google đồng thời ra mắt gói Ultra mới với giá 100 USD mỗi tháng, và giảm gói Ultra cao cấp nhất từ 250 USD xuống còn 200 USD mỗi tháng.
Vào cuối mùa hè năm nay, Spark sẽ đi vào Chrome, trở thành trình duyệt thông minh có thể thực thi nhiệm vụ trong trang web.

Ứng dụng Gemini đại cải tổ, cùng với "Bản tin sáng AI" phiên bản Google
Bản thân ứng dụng Gemini cũng đón nhận một đợt đại cải tổ thay da đổi thịt.
Google đã giới thiệu ngôn ngữ thiết kế mới Neural Expressive, thêm vào hoạt ảnh chất lỏng, màu sắc rực rỡ, phông chữ mới và phản hồi xúc giác.
Ứng dụng Gemini phiên bản mới không còn hiển thị câu trả lời dưới dạng đoạn văn dài, mà sẽ tạo bố cục phù hợp hơn cho việc đọc và thao tác theo thời gian thực dựa trên nội dung, bao gồm hình ảnh tương tác, dòng thời gian, video nhúng. Neural Expressive hiện đã được đẩy toàn cầu trên Android, iOS và phiên bản web.
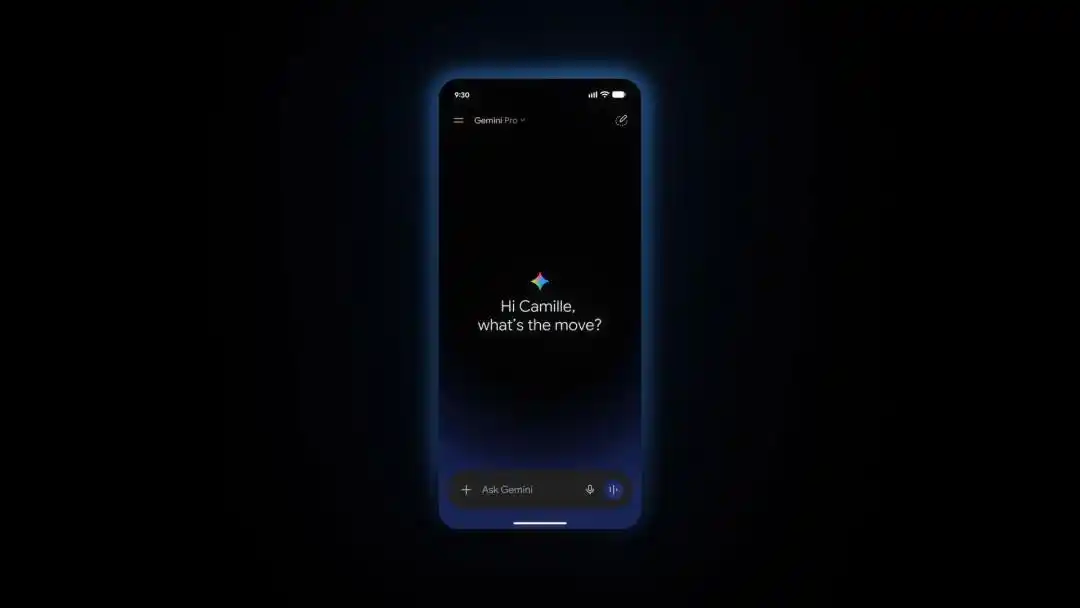
Gemini Live cũng được làm lại, mở ra có thể trực tiếp vào cuộc đối thoại thời gian thực. Lựa chọn giọng địa phương sẽ được đưa ra trong vài tuần tới.
Ứng dụng Gemini còn thêm Daily Brief. Đây là một Agent tóm tắt cá nhân hóa dành cho buổi sáng, sẽ tổng hợp thông tin từ Gmail, Calendar, Tasks, sắp xếp những việc người dùng cần quan tâm trong ngày, và cung cấp lối vào hành động tiếp theo.
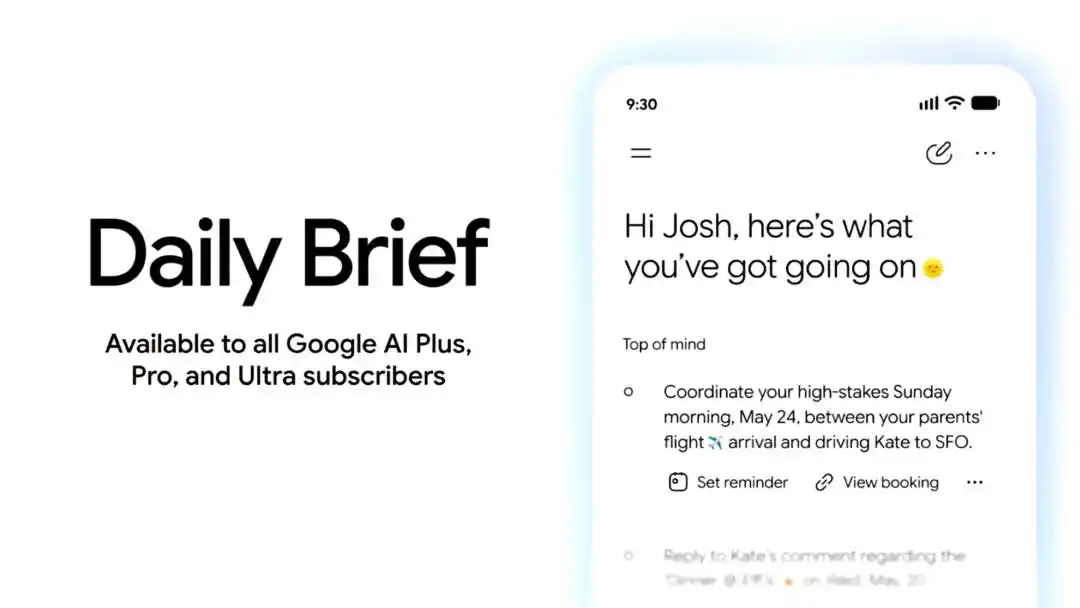
Daily Brief bắt đầu ra mắt từ hôm nay cho người dùng đăng ký Google AI Plus, Pro và Ultra tại Mỹ.
Ngoài câu chuyện lớn hơn về Gemini, Google cũng cập nhật một vài sản phẩm hàng ngày.
Google Maps gần đây đã hoàn thành bản nâng cấp lớn nhất trong mười năm, và thêm vào Ask Maps. Nó cho phép người dùng đặt câu hỏi dài hơn, phức tạp hơn. Ví dụ, buổi ra mắt đưa ra một kịch bản: con rơi xuống ao vịt, đám cưới bắt đầu sau 30 phút, người dùng muốn biết đi bộ đến đâu có thể mua váy mới.

Docs cũng có được khả năng tạo bằng giọng nói mới. Người dùng không cần nhập gợi ý chính xác, có thể trực tiếp nói ra ý tưởng bằng giọng nói, để Gemini lấy CV từ Drive, tìm thông tin sự kiện từ Gmail, sau đó tạo bản nháp Google Docs. Khả năng này sẽ ra mắt cho người dùng đăng ký Pro và Ultra vào mùa hè năm nay, khả năng giọng nói tương tự cũng sẽ đi vào Gmail.
Sau khi nâng cấp khả năng tạo, việc nhận diện nguồn gốc nội dung cũng trở nên quan trọng hơn bao giờ hết.
Google cho biết, SynthID ra mắt ba năm qua, đã thêm dấu ấn nước vô hình cho hơn 100 tỷ hình ảnh và video, cũng như lượng âm thanh tương đương 60.000 năm phát. Tiếp theo, SynthID và xác minh chứng chỉ nội dung sẽ mở rộng sang Search và Chrome.

Người dùng có thể tìm kiếm bằng cách khoanh vùng, hoặc trong Chrome nhấp chuột phải hỏi nội dung có phải do AI tạo hay không, hệ thống sẽ hiển thị nội dung đến từ AI, máy ảnh, hay đã từng được công cụ AI sinh chỉnh sửa.
Google còn thông báo, OpenAI, Kakao và ElevenLabs sẽ áp dụng SynthID 2. Trước đó NVIDIA đã tham gia hệ thống SynthID. Với Google, SynthID không chỉ là tính năng an toàn, mà còn là một phần trong việc tranh thủ tiêu chuẩn minh bạch nội dung AI.

Bộ công cụ sáng tạo của Google, bắt đầu vây công hình ảnh, thiết kế và video
Trong lĩnh vực công cụ sáng tạo, Google đã phát hành dày đặc nhiều sản phẩm nặng ký.
Google Pics là sản phẩm tạo và chỉnh sửa hình ảnh mới trong Google Workspace, hướng đến các kịch bản như poster tiệc, infographic, hình quảng cáo. Người dùng có thể bắt đầu từ một hình cơ bản, xóa phần tử, điều chỉnh kích thước đối tượng, chỉnh sửa văn bản và dịch văn bản. Nội dung do Pics tạo ra sẽ có dấu ấn nước SynthID. Google Pics sẽ ra mắt vào mùa hè năm nay.

Sản phẩm thiết kế Stitch cũng đón nhận cập nhật. Người dùng có thể thông qua một câu prompt tạo giao diện trang web hoặc ứng dụng, sau đó tiếp tục chỉnh sửa bằng văn bản hoặc giọng nói, ví dụ như phóng to tiêu đề, điều chỉnh menu, làm nổi bật thêm tùy chọn pizza. Stitch hỗ trợ xuất thiết kế dưới dạng mã, hoặc trực tiếp xuất bản trang web, các cập nhật liên quan hiện đã phát hành.

Cập nhật của Google Flow đặc biệt được chú ý. Sau khi Gemini Omni đi vào Flow, người dùng có thể dựa trên video gốc để thay đổi môi trường, thêm hiệu ứng hình ảnh, đưa vào nhân vật mới, đồng thời cố gắng giữ lại màn trình diễn ban đầu.
Flow còn thêm Agent mới, hỗ trợ thực thi nhiều hành động cùng lúc. Ví dụ như từ một hình ảnh đơn tạo 16 video với góc máy khác nhau, hoặc biến một nhóm cảnh sáng sớm thành cảnh đêm khuya hàng loạt.

Flow Tools cho phép người dùng tạo công cụ sáng tạo của riêng mình trong Flow, ví dụ như hiệu ứng video, hoạt hình vẽ tay và công cụ phân lớp văn bản, đồng thời hỗ trợ chia sẻ và remix.
Google Flow Music có thể mở rộng một đoạn riff piano thành bản demo âm nhạc có hướng phong cách. Các tính năng mới của Google Flow và Google Flow Music này đã ra mắt.
Đặt cược vào kính thông minh, Google lại thử sức với lối vào thế hệ tiếp theo
Phần cứng, Google cũng mở rộng nền tảng cấp hệ điều hành Android XR này từ headset, thiết bị XR, sang hình dáng kính thông minh.
Android XR là nền tảng Google hợp tác với Samsung, và được tối ưu hóa cho Qualcomm Snapdragon.

Google cho biết, kính AI sẽ chia thành hai loại: một loại là kính hiển thị có tròng nhỏ, loại còn lại là kính âm thanh. Kính hiển thị đã được trình diễn tại I/O năm ngoái, năm nay các nhà phát triển đầu tiên đã bắt đầu tạo trải nghiệm hiển thị, kế hoạch thử nghiệm người dùng đáng tin cậy sẽ mở rộng vào cuối năm nay.
Ra mắt sớm hơn là kính âm thanh.
Kính âm thanh đầu tiên sẽ ra mắt vào mùa thu năm nay, do Samsung tham gia xây dựng phần cứng và trải nghiệm, Warby Parker và Gentle Monster chịu trách nhiệm thiết kế kính. Những chiếc kính này kết nối với điện thoại, hỗ trợ Android và iOS. Câu trả lời của Gemini được phát riêng tư qua tai nghe, thay vì hiển thị trên tròng kính.

Tại buổi ra mắt, người trình diễn có thể thông qua kính để Gemini dẫn đường đến nơi gặp bạn bè tuần trước, giữa đường ghé quán cà phê; cũng có thể để Gemini mở DoorDash tự động đặt cà phê, chờ người dùng xác nhận;
cũng có thể để nó tóm tắt tin nhắn im lặng, và ghi bữa tối gia đình vào lịch. Kính còn có thể kết hợp với đồng hồ đeo tay, để người dùng chụp ảnh hiện trường, và dùng Nano Banana tạo hình ảnh hoạt hình, sau đó xem trước trên đồng hồ.
Cuối buổi ra mắt, kịch bản sử dụng Gemini cũng được mở rộng sang lĩnh vực an ninh mạng.
Google đã giới thiệu CodeMender. Đây là một Agent an toàn mã, có thể tự động tìm kiếm và sửa chữa lỗ hổng phần mềm quan trọng. Google sẽ mời một số chuyên gia thử nghiệm API CodeMender, sau đó sẽ ra mắt rộng rãi hơn.

Xem toàn bộ buổi ra mắt, lượng thông tin lớn đến mức khiến người ta hơi ngộp thở. Chỉ là khi những tính năng AI này thực sự mở cửa cho hàng chục triệu, hàng trăm triệu người dùng, một vấn đề tính toán thực tế nhất đã đặt ngay trước mặt: Khoản chi phí tính toán khổng lồ này, Google sẽ kiếm lại bằng cách nào?
Hơn hai mươi năm qua, Google đại diện cho một mô hình internet miễn phí điển hình. Người dùng dùng sự chú ý và dữ liệu đổi lấy dịch vụ, Google dùng quảng cáo và phân phối để kiếm tiền. Mô hình này đã biến Google thành công ty cơ sở hạ tầng mạnh nhất thời đại internet.
Nhưng chi phí suy luận của mô hình lớn, hoàn toàn không cùng cấp độ với việc truy vấn một lần tìm kiếm.
Bộ nhớ ngữ cảnh dài, tạo đa phương thức, Agent xuyên ứng dụng, tự động hóa cấp doanh nghiệp, đằng sau những khả năng này đều là tiêu thụ sức tính toán chạy liên tục. AI càng đi sâu, Google càng khó tiếp tục dùng cách "nâng cấp tính năng miễn phí" để tiêu hóa chi phí.
Đây là lý do tại sao xem toàn bộ buổi ra mắt, Google I/O nhìn bề ngoài nói về nâng cấp trải nghiệm, nhưng đằng sau lại hướng đến đăng ký, hợp đồng doanh nghiệp, hóa đơn tính toán và phí dịch vụ dài hạn.

Lối vào miễn phí đương nhiên sẽ không biến mất, vì đó vẫn là nền tảng để Google thu thập người dùng, dữ liệu và vị thế hệ sinh thái. Nhưng trên những lối vào này, Google đang xếp chồng thêm một tầng dịch vụ thông minh mới: mô hình mạnh hơn, bộ nhớ dài hơn, quyền hệ thống sâu hơn, thực thi nhiệm vụ phức tạp hơn, và dịch vụ cấp doanh nghiệp ổn định hơn.
Nói cách khác, Google đang từ công ty dịch vụ internet miễn phí, tiến thêm một bước trở thành công ty cơ sở hạ tầng đăng ký AI.
Chỉ là, vấn đề cũng theo đó mà đến, người dùng có sẵn lòng trả phí để tìm kiếm không? Thông thường, không.
Nhưng, nếu đây là một "trợ lý siêu toàn năng" có thể thay bạn xử lý email suốt ngày đêm, tổng hợp nhiệm vụ, phân tích báo cáo, tiếp quản nhà thông minh, thậm chí còn giúp bạn viết mã phát triển ứng dụng? Bạn có sẵn lòng bỏ ra vài chục đến trăm đô la mỗi tháng cho nó không?
Đây chính là mệnh đề thương mại cốt lõi mà Google I/O năm nay khao khát muốn xác minh. Và nhìn quanh thị trường cuồng nhiệt hiện nay, câu trả lời dường như đã rõ ràng từ lâu.
Bài viết này đến từ tài khoản công chúng WeChat "APPSO", tác giả: Phát hiện sản phẩm ngày mai






