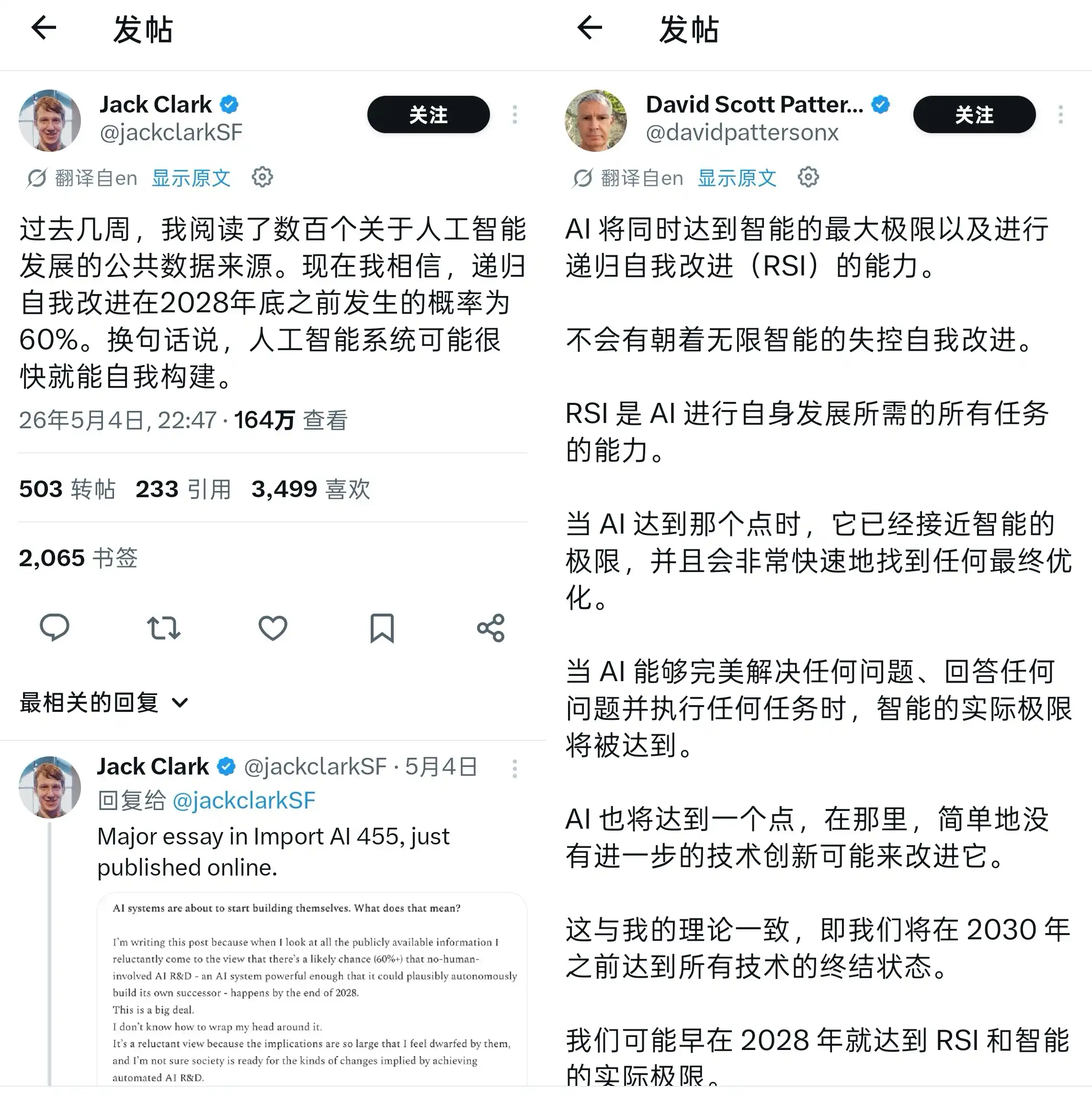
Từ "đệ quy" gần đây bỗng nhiên trở nên nóng hổi trong giới AI.
Hai công ty khởi nghiệp trực tiếp lấy từ này làm tên công ty, nhiều phòng thí nghiệm bắt đầu đưa vào lộ trình một từ viết tắt ba chữ RSI, chính là tên tiếng Anh của đệ quy – recursive self-improvement (tự cải tiến đệ quy). Giống như AGI, RSI đang trở thành một mật mã ngành khiến người ta vừa hào hứng vừa lo lắng, dù định nghĩa của mọi người về nó vẫn chưa hoàn toàn thống nhất.
(Nguồn: X)
RSI là gì? Nói một cách đơn giản, chính là để AI tự huấn luyện chính mình. Trong giới công nghệ, RSI luôn được coi là một trong những dấu mốc chính cho sự tiến bộ của trí tuệ nhân tạo, cùng với trí nhớ, suy luận và đa phương thức. Giới hạn duy nhất là sức mạnh tính toán, con người trong đó không còn là điều kiện cần thiết, thậm chí không được coi là trợ thủ.
Nghe có vẻ rất khoa học viễn tưởng, hay nói cách khác, nghe có vẻ rất nguy hiểm? Nhưng hãy bình tĩnh suy nghĩ, đây không phải lần cuồng nhiệt đầu tiên của ngành AI. Từ AlphaGo năm 2016 đến ChatGPT năm 2023, rồi đến cuộc chạy đua tham số mô hình lớn của các hãng hiện nay, bản chất của ngành AI là đuổi theo thứ tiếp theo "thay đổi mọi thứ". Theo góc nhìn của AGI tại Leikejiagi, RSI có lẽ chính là cơn sốt tiếp theo.
RSI đang nổi: Khi AI có thể dựa vào 'đệ quy' để tự xây dựng
Tháng 5 năm nay, nhà nghiên cứu nổi tiếng giới AI Richard Socher đã thành lập ồn ào một công ty mới tên Recursive Superintelligence, tên gọi trực tiếp chính là RSI.
Ông cho biết: "Mục tiêu cốt lõi của chúng tôi là xây dựng siêu trí tuệ tự cải tiến đệ quy thực sự. Toàn bộ quá trình hình thành ý tưởng nghiên cứu, thực hiện và xác minh đều được hoàn thành tự động."
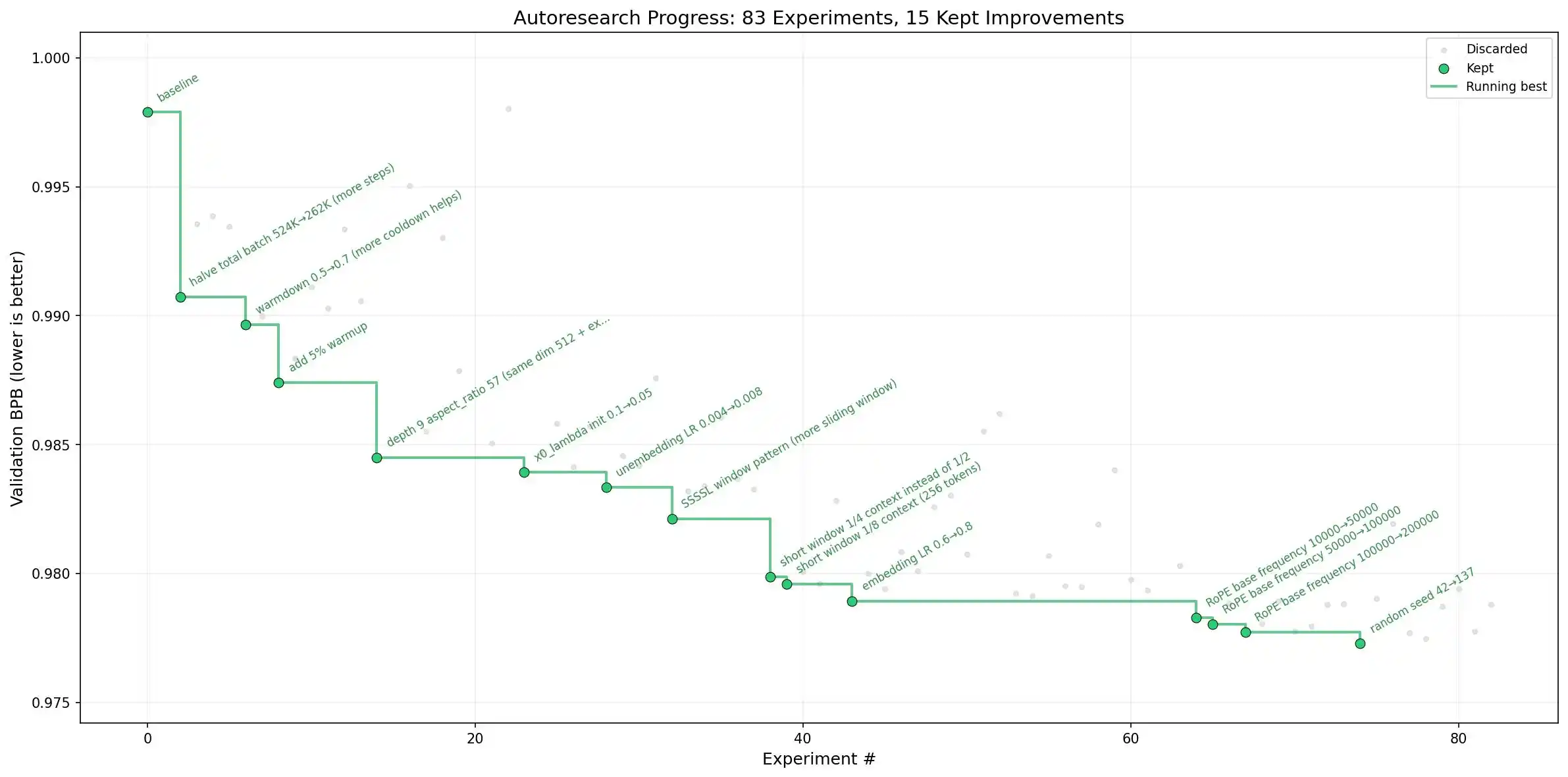
Một trường hợp khác khiến giới nội bộ bàn tán nhiều hơn là dự án Auto-Research do Andrej Karpathy thúc đẩy: Sử dụng cụm tác nhân thông minh để huấn luyện mô hình ngôn ngữ, để mô hình tự làm các nhiệm vụ nghiên cứu đơn giản, tự cải thiện chính mình.
Nguồn: github
Andrej Karpathy cũng là một nhân vật huyền thoại, ông đã để lại những dấu ấn mạnh mẽ khi làm xe tự lái tại Tesla và làm GPT tại OpenAI. Giờ đây ông xem RSI là chặng tiếp theo để all in, và đang thúc đẩy theo cách công khai minh bạch, điều này cũng cho thấy ông thực sự tin rằng việc này có thể làm được.
Thú vị là, ông vô cùng thẳng thắn với dự án này, thường xuyên cập nhật tiến độ trên Twitter, mã nguồn cũng được công khai trên kho lưu trữ GitHub. Tất nhiên, Andrej Karpathy cũng tự nói rằng, công việc hiện tại vẫn là lặp lại trên các mô hình nhỏ ở cấp độ GPT-2, "chưa phải là nghiên cứu đột phá (tạm thời)", nhưng điều này đã đủ để thu hút một lượng lớn nhà nghiên cứu theo đuổi.
Quan trọng hơn, Andrej Karpathy gần đây đã gia nhập đội tiền huấn luyện của Anthropic. Anthropic có Claude, Karpathy có phương pháp luận auto-research này, một khi hai bên kết hợp, mô hình lớn + vòng lặp tự huấn luyện, nếu chạy thông, sẽ không còn là những thử nghiệm nhỏ ở cấp độ GPT-2 nữa.

Nguồn: haimagazine
Một công ty khác tên Adaption đã ra mắt công cụ AutoScientist, với mục tiêu tự động hóa quá trình huấn luyện các mô hình tiên phong. Logic giống với auto-researchers của Andrej Karpathy, huấn luyện tác nhân để cải tiến dần dần. Chỉ có điều tham vọng của Adaption lớn hơn, muốn trực tiếp giải quyết toàn bộ vòng lặp khép kín huấn luyện một mô hình tiên phong kích thước đầy đủ.
Hai công ty này thực chất đại diện cho hai hướng đi: Andrej Karpathy xác minh từng phần từ nền tảng, vừa mã nguồn mở vừa tích lũy động lực trong cộng đồng; Adaption nhắm thẳng đến kịch bản huấn luyện mô hình lớn thương mại hóa, ý chí triển khai thực tế mạnh mẽ hơn. Hướng đi nào chạy thông trước sẽ có tác động hoàn toàn khác biệt đến toàn ngành.
CEO Google dội nước lạnh: Chúng ta chưa đến mức đó
Về RSI, các đại gia giới AI cũng có nhiều ý kiến khác nhau.
CEO Google Sundar Pichai tháng trước trong một podcast đã thận trọng thừa nhận thực tế: "(RSI) là một thể liên tục, chúng ta thực sự đều đang tiến bộ. Nhưng nếu theo cách mọi người mô tả RSI, thì đó đại diện cho một sự tăng tốc cấp độ tiếp theo, sẽ có nhiều tác động, nhưng chúng ta chưa đến bước đó."
Mặc dù vậy, nhưng mô tả "thể liên tục" ở đây đã chứa đựng không ít điều khiến người ta suy nghĩ sâu xa.
Tháng 1 năm nay, một lập trình viên chủ chốt phát triển Claude Code tại Anthropic thừa nhận, gần 100% mã trong nhóm là do Claude Code viết, đây là một nghĩa đen của việc AI đang viết mã cho chính mình. Không phải AI hỗ trợ kỹ sư viết mã, mà công cụ AI ở một mức độ nào đó đã thay thế kỹ sư viết mã cho chính nó.
Nguồn: Anthropic
Anthropic có một cuộc khảo sát nội bộ về bản xem trước Mythos: Trong 18 kỹ sư, có 5 người cho rằng, nếu hệ thống hỗ trợ được cải thiện thêm, phiên bản Mythos này có thể thay thế một kỹ sư L4, tức là một lập trình viên trung cấp có thể đảm nhận dự án phức tạp độc lập, không cần giám sát theo thời gian thực.
Nhưng khuyết điểm cũng được viết rõ ràng: "Các điểm yếu chính mà Claude báo cáo bao gồm: nhiệm vụ mơ hồ trên chu kỳ quản lý, hiểu ưu tiên của tổ chức, gu thẩm mỹ, xác minh, tuân thủ chỉ thị và nhận thức luận." Ý nói rằng, điểm yếu của nó lại chính là những việc mang tính tự chủ, mà tự chủ lại là nền tảng của RSI.
Thú vị là, Trung tâm Nghiên cứu An ninh và Công nghệ Mới nổi Georgetown (CSET) năm ngoái đã tổ chức một nhóm chuyên gia nghiên cứu chuyên sâu về RSI. Nhóm chuyên gia này khi đánh giá đã xuất hiện sự phân chia rõ rệt, một bộ phận dự đoán sắp đón "vụ nổ siêu trí tuệ", bộ phận khác dự đoán tiến triển sẽ chậm hơn, cuối cùng sẽ chạm đến một giai đoạn tắc nghẽn nào đó.
Nhưng họ có một sự đồng thuận: Đệ quy khiến tương lai trở nên đặc biệt khó dự đoán.
Vì vậy, một bài viết của nhà nghiên cứu METR Ajeya Cotra đã phân giải quá trình RSI thành vài cột mốc, tôi nghĩ đây là khung phân tích dễ sử dụng nhất hiện nay.
Cấp đầu tiên gọi là "đủ" (adequacy): Sau khi loại bỏ hoàn toàn con người, hệ thống vẫn có thể nghiên cứu – dù không bằng con người, nhưng có thể vận hành.
Cấp thứ hai gọi là "tương đương" (parity): Nghiên cứu do AI thực hiện độc lập, chất lượng tương đương với nghiên cứu do con người thực hiện độc lập.
Cấp thứ ba gọi là "vượt trội" (supremacy): Hiệu suất của hệ thống độc lập AI vượt qua hệ thống kết hợp giữa con người và AI.
Hơi giống L2, L3, L4, L5 trong xe tự lái. Đánh giá của Ajeya Cotra là: Chúng ta đã rất gần với cấp đầu tiên. Nhưng khi nào cấp thứ hai đến, bà không đưa ra lịch trình thời gian, nhưng bà đã đưa ra một suy luận rất rõ ràng, một khi cấp thứ hai đến, gia tốc tiếp theo sẽ vượt xa quá khứ, "có thể sẽ lao đến cấp thứ ba trong vòng một năm."
Tại sao nhanh như vậy? Bởi vì đến thời điểm cấp thứ hai, AI sẽ trở thành một nhóm nghiên cứu không cần ngủ, không cần họp, không cần căn chỉnh KPI. Nó có thể thử, sửa, thử lại liên tục 24 giờ. Còn con người làm nghiên cứu, dù hiệu suất cao đến đâu, thời gian làm việc sâu hiệu quả một ngày cũng chỉ vài giờ, giữa chừng còn xen kẽ vô số sự gián đoạn và chi phí giao tiếp, một khi nút thắt cổ chai này không tồn tại, gia tốc sẽ tăng vọt theo kiểu vách đá.
Trong nước không ai gọi RSI, nhưng DeepSeek đã chạm đến mép giới hạn
Trước đó đã bàn về một loạt tiến triển ở nước ngoài, bạn có thể hỏi: Trong nước thì sao?
Thẳng thắn mà nói, các hãng trong nước rất ít khi công khai gọi RSI, các công ty AI nước ngoài có thể viết "siêu trí tuệ đệ quy" vào sứ mệnh công ty, việc này ở trong nước hầu như không thể tưởng tượng được. Nhưng nếu nói đến việc để AI tự cải thiện chính mình, các hãng trong nước thực tế đã âm thầm chạm đến mép giới hạn trên các con đường khác nhau.
Ví dụ điển hình nhất là DeepSeek. Họ tiêu ít tiền hơn OpenAI một bậc, nhưng trên nhiều nhiệm vụ suy luận đã có thể đối đầu trực tiếp. Dựa vào việc tối ưu hóa cực đại hiệu suất thuật toán – kiến trúc MoE, nén cực đại tham số kích hoạt, mài giũa kỹ thuật hóa chiến lược huấn luyện.
Mặc dù điều này liên quan không nhiều đến RSI, nhưng đây là một con đường dùng phương pháp thông minh hơn để thay thế con đường dùng sức mạnh tính toán thuần túy. Mà con đường này lại trùng khớp với logic cốt lõi của RSI: Để mô hình tìm ra con đường thông minh hơn trong quá trình lặp.
Về phía Baidu Wenxin, học tăng cường thúc đẩy mô hình tự tối ưu hóa đã là thao tác thường quy. Dù không dùng tên RSI, nhưng làm cùng một việc: Để mô hình trên nhiệm vụ cụ thể thông qua vòng lặp tự phản hồi không ngừng cải thiện. Từ góc nhìn này, các hãng trong nước không phải không làm RSI, chỉ là họ đã biến một số khâu của RSI thành thực tiễn kỹ thuật hàng ngày, chỉ là không treo tên này.

(Nguồn: gemini tạo)
Tất nhiên, khoảng cách cũng tồn tại khách quan. Mật độ nhân tài của OpenAI và Anthropic, hiện tại bất kỳ hãng nào trong nước cũng chưa sánh bằng, điều này có nghĩa là trong việc khám phá RSI, hiện tại vẫn là trạng thái theo sau.
Nhưng kinh nghiệm lịch sử cho chúng ta biết, tốc độ đuổi kịp của các hãng trong nước sau khi "con đường đường ống rõ ràng" thường là đáng kinh ngạc. Khung RSI đang được các đại thần nước ngoài phân giải ngày càng rõ ràng, mã của Karpathy cũng công khai trên GitHub, một khi con đường có thể tái hiện được thông suốt, khả năng kiểm soát chi phí và mật độ kịch bản triển khai của người chơi trong nước, sẽ là một biến số bị thị trường đánh giá thấp nghiêm trọng.
Nhưng đồng thời, chúng ta cũng phải tạt một chút nước lạnh thích đáng. Thực tế, dữ liệu do AI tự sinh ra, dùng để huấn luyện phiên bản AI tiếp theo, chất lượng sẽ giảm xuống. Logic của RSI là AI sinh ra dữ liệu tốt, sau đó dùng những dữ liệu này huấn luyện thế hệ AI tiếp theo, khiến thế hệ AI tiếp theo mạnh hơn.
Mà tình hình thực tế có thể ngược lại, trong dữ liệu do AI sinh ra thường lẫn vào ảo tưởng, định kiến, suy giảm chất lượng của chính nó, những dữ liệu tay hai này được đút cho phiên bản tiếp theo, phiên bản tiếp theo lại sản xuất ra hàng tay ba tệ hơn, lặp vài vòng sau toàn bộ hệ thống sẽ sụp đổ, giống như một máy photocopy liên tục sao chép bản sao, in đến tờ thứ mười mặt đã mờ.
Giới học thuật gọi đây là sụp đổ mô hình, đã có luận văn xác minh hiện tượng này thực sự tồn tại.
Hơn nữa, môi trường lý tưởng mà RSI cần, trong thế giới thực không hề tồn tại. Hệ thống này để chạy được, hai tiền đề không thể thiếu: Sức mạnh tính toán vô hạn, hệ sinh thái nghiên cứu hợp tác mở toàn cầu.
Mà thực tế chi phí huấn luyện một mô hình tiên phong đã đến mức tỷ, năng lực sản xuất chip có hạn, năng lượng có hạn, dữ liệu chất lượng cao cũng đang giảm, kiểm soát xuất khẩu và tách rời công nghệ đang cắt nghiên cứu AI thành vài vòng tròn không lưu thông với nhau, người và hàng đều không lưu động được, ngay cả những điều kiện cơ bản này còn không đủ, thì đừng nói đến RSI.
RSI không chỉ là vấn đề kỹ thuật nữa, nó còn cần một thế giới đủ mở, mà tiền đề này có thành lập được không, giới kỹ thuật thực sự không thể nói được.
Viết ở cuối
Cuối cùng nói một quan sát tôi thấy thú vị: Toàn ngành trong năm năm qua, đầu tiên là tiền huấn luyện quy mô lớn kéo con người vào "sùng bái tham số", sau đó là RLHF (học tăng cường dựa trên phản hồi con người) khiến người ta tin "giá trị quan có thể tinh chỉnh", hiện tại là RSI đang kể câu chuyện "máy móc tự chạy toàn bộ chuỗi nghiên cứu phát triển". Mỗi bước đều đẩy con người lùi lại một bước, không phải rút khỏi ngành, mà là rút khỏi chuỗi quyết định.
Tuy cách rút lui này không hẳn là xấu, nhưng nó không thể đảo ngược. Một khi một khâu nào đó được tự động hóa tiếp quản, trực giác, kinh nghiệm, năng lực phán đoán của con người ở khâu đó sẽ dần thoái hóa, giống như sau khi không dùng GPS bạn sẽ phát hiện năng lực nhận đường thực sự đang kém đi.
Đến lúc đó, chúng ta thậm chí không chắc có thể thực sự hiểu công cụ được tạo ra như thế nào.






