Phá vỡ mô hình tiền huấn luyện truyền thống cho mô hình lớn, đội ngũ cựu sinh viên TH Thanh Hoa Vương Quan 00 tuổi lại ra tác phẩm mới:
Họ sử dụng mô hình tuần hoàn phân tầng (HRM) thay thế Transformer tiêu chuẩn, đề xuất phương pháp tiền huấn luyện hiệu quả HRM-Text vượt xa Scaling.

Liên kết bài báo: https://arxiv.org/abs/2605.20613
Trong trường hợp chỉ sử dụng số lượng token huấn luyện ít hơn khoảng 100-900 lần so với mô hình baseline tiêu chuẩn, và khối lượng tính toán ước tính ít hơn 96-432 lần, HRM-Text vẫn đạt được hiệu suất có thể so sánh với các mô hình nguồn mở từ 2B đến 7B tham số.
Đồng thời, với 1B tham số, 40B token không lặp lại và chi phí huấn luyện khoảng 1500 USD, HRM-Text đã đạt được kết quả sau trong các bài kiểm tra chuẩn chủ đạo: MMLU 60.7%, ARC-C 81.9%, DROP 82.2%, GSM8K 84.5%, MATH 56.2%.
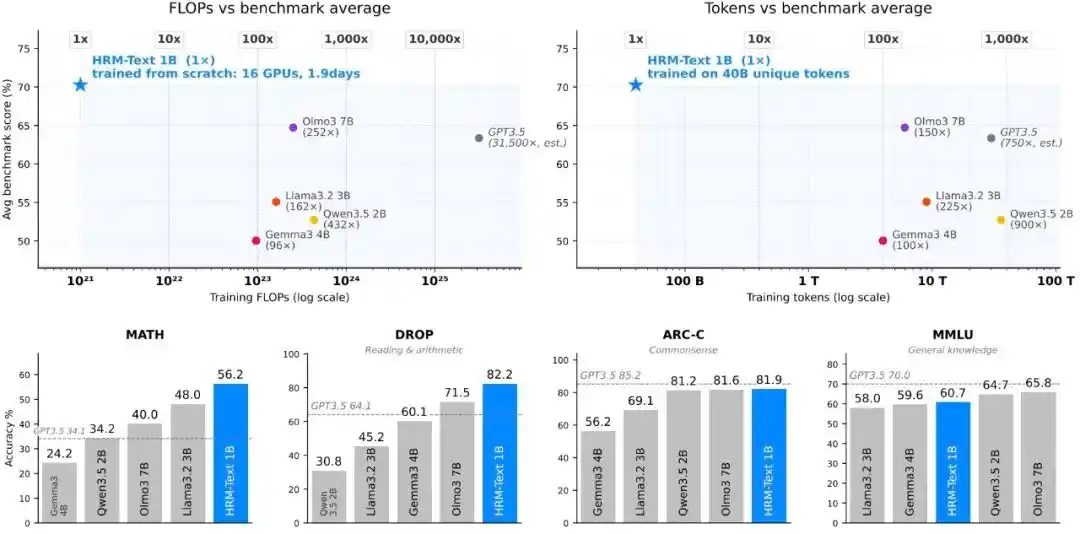
Hình | Hiệu quả tiền huấn luyện.
Trên cơ sở đó, họ nêu rõ: Tiên nghiệm cấu trúc và mục tiêu huấn luyện có mục tiêu, có thể giảm đáng kể ngưỡng tiền huấn luyện. Phương án huấn luyện này có thể làm cho việc huấn luyện mô hình cơ bản từ con số 0 trở nên khả thi.
HRM-Text được thiết kế như thế nào?
Tiền huấn luyện mô hình ngôn ngữ lớn (LLM), ngày càng phụ thuộc vào một số ít tổ chức sở hữu đầy đủ tài nguyên tính toán và dữ liệu. Huấn luyện một mô hình cơ bản có sức cạnh tranh, thường cần hàng nghìn tỷ token, hàng nghìn GPU, thậm chí đầu tư tính toán lên đến hàng triệu USD.
Tuy nhiên, mô hình huấn luyện hiện tại không hiệu quả, lượng lớn tính toán bị tiêu hao vào các token không liên quan như prompt, điền định dạng và nhiễu web, dẫn đến phần lớn sức tính toán huấn luyện không trực tiếp phục vụ suy luận.
Trong công trình này, nhóm nghiên cứu đã thiết kế lại kiến trúc và mục tiêu huấn luyện, giúp việc tiền huấn luyện HRM-Text trở nên hiệu quả hơn một cách tương đối.
Kiến trúc: Sử dụng mô hình tuần hoàn phân tầng với hai thang thời gian, chia tính toán thành mô-đun chậm H và mô-đun nhanh L. Transformer tiêu chuẩn chỉ thực hiện một lượt truyền thẳng cho mỗi token, HRM sẽ thực hiện cập nhật đệ quy nhiều vòng trên cùng một token. Mô-đun H và L mỗi cái chỉ chiếm một nửa số tham số của lõi đệ quy, tổng khối lượng tính toán tương đương với việc triển khai đệ quy 4 lần trên cùng một bộ tham số, từ đó nâng cao độ sâu tính toán mà không tăng số lượng tham số.
Mục tiêu huấn luyện: Không tiếp tục sử dụng tiền huấn luyện tự hồi quy toàn văn tiêu chuẩn, mà huấn luyện trực tiếp trên cặp chỉ dẫn - trả lời, chỉ tính toán tổn thất cho phần trả lời, và kết hợp mặt nạ PrefixLM, cho phép phần chỉ dẫn chú ý hai chiều, phần trả lời sinh ra theo mặt nạ nhân quả.
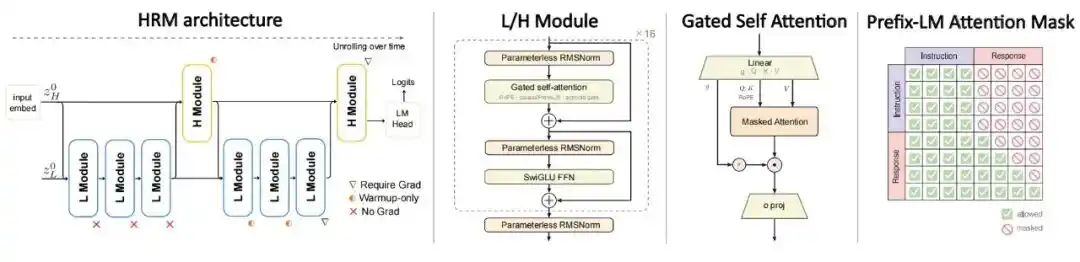
Hình | Kiến trúc HRM-Text.
Để nâng cao tính ổn định của huấn luyện đệ quy, nhóm nghiên cứu đã giới thiệu MagicNorm và Warmup Deep Credit Assignment.
MagicNorm là một chiến lược chuẩn hóa hỗn hợp, tận dụng tính không đối xứng giữa độ sâu tính toán truyền thẳng và truyền ngược trong truyền ngược cắt ngắn (Truncated BPTT), sử dụng PreNorm bên trong mô-đun, và thêm chuẩn hóa ở lối ra mô-đun, từ đó nâng cao tính ổn định của huấn luyện đệ quy sâu.
Warmup Deep Credit Assignment thì trong giai đoạn đầu huấn luyện chỉ truyền gradient ngược cho 2 bước đệ quy cuối cùng, sau đó mở rộng tuyến tính đến 5 bước cuối. Cơ chế huấn luyện này có thể giúp mô hình hội tụ ổn định trên đường dẫn tín dụng ngắn hơn, sau đó từ từ đưa vào quan hệ phụ thuộc dài hơn.
Hiệu quả ra sao?
Kết quả thí nghiệm cho thấy, HRM-Text thể hiện ưu thế rõ ràng về hiệu quả kiến trúc, mục tiêu huấn luyện và hiệu suất tổng thể.
1. Trong điều kiện sức tính toán huấn luyện cố định, kiến trúc tuần hoàn có hiệu quả hơn không
Kết quả cho thấy, trong điều kiện căn chỉnh FLOPs, HRM 1B vượt trội hơn Transformer 1B, Transformer 3B, Looped Transformer 1B và RINS 1B trên hầu hết các bài kiểm tra chuẩn; so sánh với TRM cũng cho thấy, huấn luyện HRM ổn định hơn.
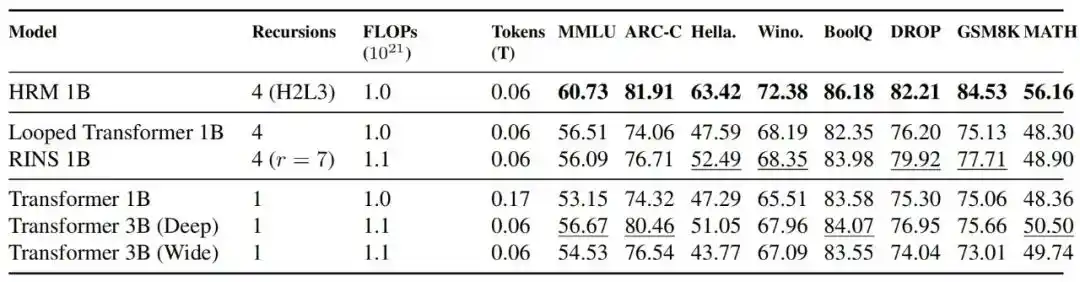
Hình | So sánh hiệu suất và tính ổn định với mô hình Transformer. HRM duy trì động thái huấn luyện ổn định ở tất cả quy mô, trong khi mô hình Transformer ở quy mô 1 tỷ tham số xuất hiện sự bất ổn nghiêm trọng. Ngoài ra, ở quy mô 0.6B, HRM chỉ cần khối lượng tính toán ít hơn 2 lần so với mô hình Transformer, đã có thể đạt được biểu hiện cạnh tranh trên hầu hết các bài kiểm tra chuẩn.
2. Mục tiêu hoàn thành nhiệm vụ và PrefixLM có hữu ích không
Thí nghiệm loại bỏ cho thấy, trong điều kiện căn chỉnh FLOPs, MMLU của Transformer 1B từ mức 40.55 của tự hồi quy tiêu chuẩn, lần lượt tăng lên 47.72 sau khi đưa vào mục tiêu hoàn thành nhiệm vụ, lên 53.15 sau khi thêm PrefixLM, và cuối cùng lên 60.73 sau khi chuyển sang kiến trúc HRM.
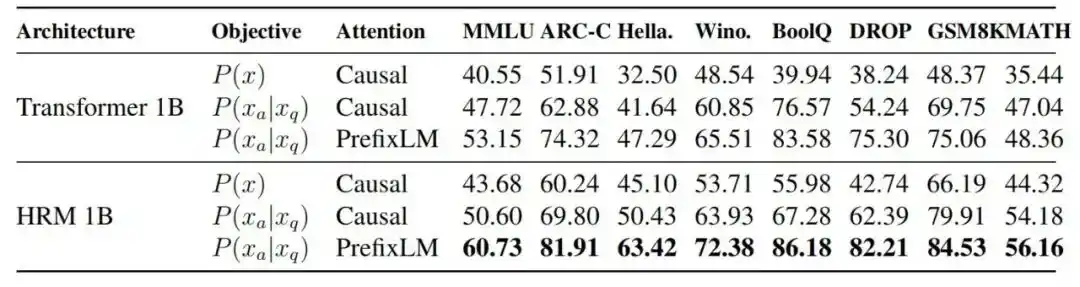
Hình | So sánh hiệu suất giữa các kiến trúc mô hình và mục tiêu huấn luyện khác nhau.
3. HRM-Text so với các mô hình mở đương thời thì hiệu quả ra sao
HRM-Text 1B đạt được 60.7, 81.9, 82.2, 84.5 và 56.2 lần lượt trên MMLU, ARC-C, DROP, GSM8K và MATH. So với các mô hình mở có ngân sách huấn luyện thường lớn hơn, nó chỉ sử dụng 40 tỷ token duy nhất và 1B tham số, đã bước vào khoảng hiệu suất của các mô hình nguồn mở từ 2B đến 7B; số token huấn luyện cần thiết ít hơn tới 900 lần, chi phí tính toán ít hơn tới 432 lần.
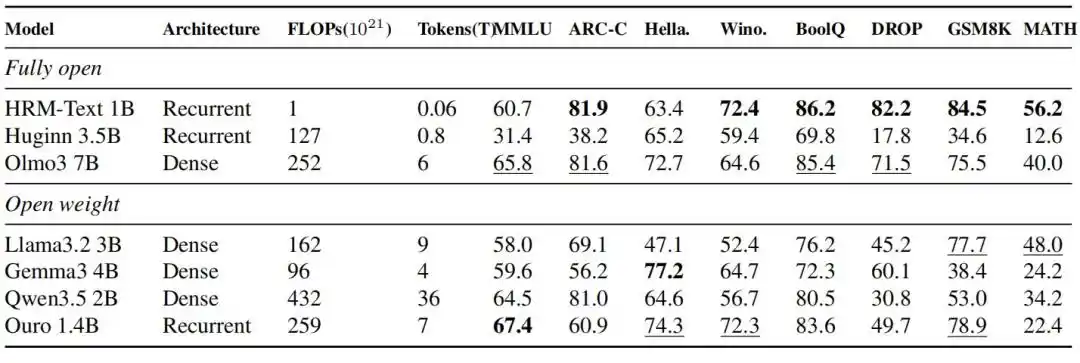
Hình | Kết quả đánh giá HRM-Text 1B so với các mô hình hoàn toàn nguồn mở và mô hình trọng số mở cùng thời kỳ.
4. Cấu trúc tuần hoàn có mang lại độ sâu hiệu quả lớn hơn không
Kết quả cho thấy, Transformer tiêu chuẩn và Looped Transformer có xu hướng ổn định ở tầng nông hơn, trong khi HRM ở tầng sâu hơn vẫn duy trì sự thay đổi biểu diễn giữa các khối rõ ràng hơn, độ tương đồng cosin thấp hơn và giá trị KL logit lens cao hơn.
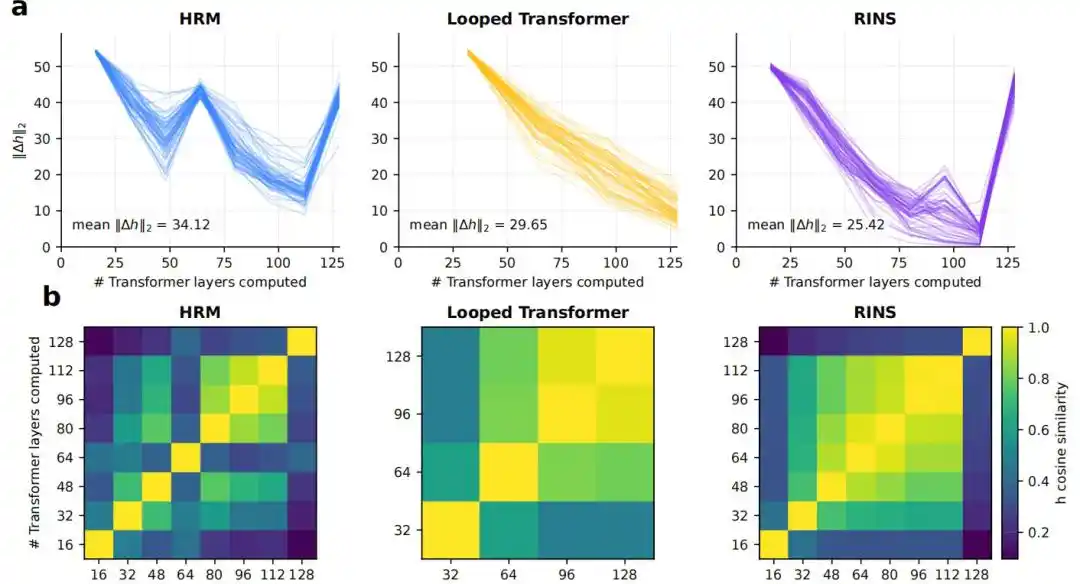
Hình | Phân tích độ sâu hiệu quả.
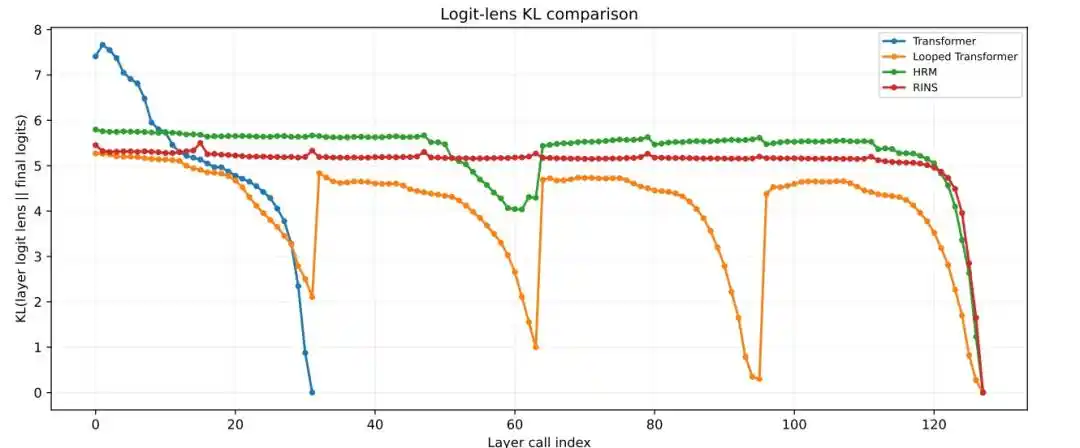
Hình | Phân tích Logit Lens KL theo từng tầng.
Hạn chế và hướng phát triển tương lai
Mặc dù HRM-Text thể hiện biểu hiện mạnh mẽ trong các nhiệm vụ tập trung suy luận, phương pháp này vẫn tồn tại hạn chế và đề xuất các hướng nghiên cứu tương lai.
1. Hướng tới việc tách rời "kiến thức" và "suy luận"
Hiện tại, phủ sóng kiến thức thực tế rộng hơn vẫn phụ thuộc nhiều hơn vào quy mô mô hình và độ rộng dữ liệu. HRM-Text chỉ được huấn luyện trên 40 tỷ token duy nhất, và nguồn kiến thức hiển thị chỉ chiếm một phần trong dữ liệu hỗn hợp định dạng nhiệm vụ. Trong tương lai, các nhà nghiên cứu cần thiết kế riêng biệt lõi suy luận nhỏ gọn với kho lưu trữ thực tế bên ngoài, giao phạm vi kiến thức rộng cho ngữ liệu tinh lọc, mô-đun tăng cường truy xuất hoặc bộ nhớ có thể học.
2. Thời gian tính toán thích ứng
Lịch trình tuần hoàn của HRM-Text mang lại độ sâu nối tiếp hiệu quả lớn hơn, nhưng điều này cũng có nghĩa là mô hình cần thực hiện số bước đệ quy cố định khi suy luận. Trong tương lai, một hướng đáng khám phá là đưa vào cơ chế thời gian tính toán thích ứng, cho phép các mẫu đơn giản dừng tính toán sớm hơn, và dành toàn bộ ngân sách tuần hoàn cho các mẫu khó, giảm chi phí suy luận.
3. Phạm vi xác thực quy mô hóa hiện tại vẫn còn hạn chế
Thí nghiệm scaling hiện tại chỉ bao phủ đến nhóm đối chứng Transformer 3B tham số và HRM-Text 1B tham số. Nhóm nghiên cứu cho biết, liệu ở quy mô mô hình lớn hơn có thể duy trì lợi thế hiệu quả tương tự hay không, vẫn cần được xác thực thêm bởi các công trình tiếp theo.
4. PrefixLM và khung suy luận
Hiện tại, PrefixLM trong triển khai thực tế vẫn đối mặt với một số hạn chế về mặt kỹ thuật triển khai. Mặc dù nó có thể chạy trên các khung suy luận sinh văn bản tiêu chuẩn như vLLM, điều này yêu cầu khung hỗ trợ mặt nạ chú ý tùy chỉnh trong giai đoạn prefill. Nếu mở rộng nó đến các kịch bản hội thoại nhiều vòng, cần phải thiết kế thêm cơ chế KV-cache, vừa đảm bảo các đoạn của người dùng vẫn có thể thấy hai chiều, cũng phải đảm bảo quá trình sinh ra phía trợ lý tiếp tục tuân theo ràng buộc nhân quả.
Chi tiết kỹ thuật thêm, xem bài báo gốc.
Bài viết này đến từ tài khoản công chúng WeChat "Đầu đề học thuật" (ID:SciTouTiao), tác giả: Hạ Thiên Tư








