Sức mạnh tính toán bị hạn chế
Từ cuối năm ngoái, các GPU nội địa Trung Quốc như Moore Thread, MooreX, Biren Technology, và Skywork AI đã tạo ra một làn sóng đầu tư mạnh mẽ. Tuy nhiên, bên dưới bữa tiệc tài sản trên thị trường thứ cấp, một đường dây ngầm không thể bỏ qua ngày càng trở nên rõ ràng, và các vấn đề mà nó gây ra cũng ngày càng cấp bách.
Những năm gần đây, chip AI nội địa Trung Quốc chủ yếu tập trung ở mảng "suy luận" (inference) tương đối an toàn và nằm ở rìa hệ thống, như việc Doubao dự định mua gần đây 50.000 chip Skywork AI cho các nhiệm vụ suy luận để đáp ứng nhu cầu gọi tần suất cao của ứng dụng AI di động lớn nhất Trung Quốc này.
Trong khi ở đỉnh kim tự tháp năng lực tính toán là mảng huấn luyện AI, chip nội địa hiện chỉ có thể tham gia vào các nhiệm vụ "phụ trợ" ở rìa.
Chip huấn luyện AI chủ yếu được sử dụng để đào tạo các mô hình trí tuệ nhân tạo, trong quá trình này sẽ thực hiện một lượng lớn các phép tính ma trận và điều chỉnh tham số, do đó cần có khả năng tính toán mạnh mẽ và hiệu suất năng lượng cao, hiệu năng càng mạnh thì giá càng cao, như dòng A100, H100, H200 của NVIDIA và dòng MI300 của AMD;
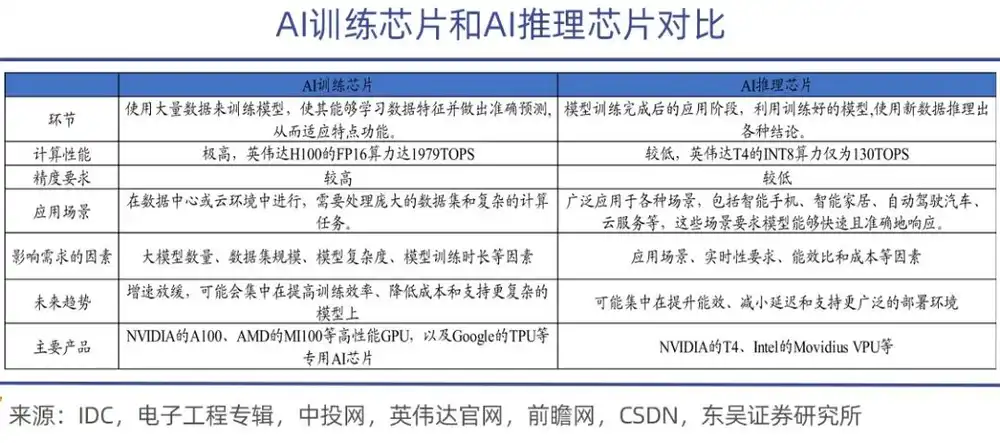
Ngược lại, nhiệm vụ của chip suy luận nhẹ nhàng hơn nhiều. Chúng được sử dụng trong giai đoạn triển khai sau khi mô hình được đào tạo xong, chủ yếu chịu trách nhiệm thực hiện các tác vụ suy luận của mô hình, yêu cầu tính thời gian thực cao, chip suy luận cần có khả năng phản hồi nhanh và tiêu thụ điện năng thấp trong khi đảm bảo độ chính xác.
Một phép so sánh thích hợp là: huấn luyện là để mô hình AI "học kiến thức", còn suy luận là để mô hình lớn "vận dụng kiến thức". Trong giai đoạn học, chip huấn luyện phải gọi một lượng dữ liệu khổng lồ để "nuôi dưỡng" việc cập nhật động các tham số lên tới hàng tỷ, nghìn tỷ thậm chí mười nghìn tỷ, không chỉ cần sức mạnh tính toán cực kỳ mạnh mẽ, mà còn cần được trang bị băng thông và khả năng truyền thông hiệu quả, đồng thời phải đảm bảo tính ổn định trong các cụm máy chạy hàng chục nghìn chip.
Nguồn gốc của khoảng cách mô hình giữa Trung Quốc và Mỹ nằm ở những "điểm không nhìn thấy được" này, đặc biệt là sự vắng mặt của chip huấn luyện cao cấp.
Dưới quy luật Scaling Law của mô hình lớn, tham số mô hình càng lớn, nhu cầu sức mạnh tính toán tăng trưởng tương ứng một cách tuyến tính, trong khi sức mạnh tính toán bùng nổ theo cấp số nhân cùng với chi phí phần cứng khiến việc huấn luyện mô hình lớn trở thành "trò chơi độc quyền" của một số ít gã khổng lồ công nghệ.
Trong số các gã khổng lồ công nghệ Mỹ, chỉ riêng Meta đã lên kế hoạch triển khai hơn 1,2 triệu GPU cao cấp vào cuối năm 2026, với mức đầu tư hàng năm vượt 1450 tỷ USD; Ngoài ra, theo tính toán, tổng sức mạnh tính toán AI mà Google sở hữu tương đương với 5 triệu chip NVIDIA H100, một doanh nghiệp chiếm tới 1/4 tổng lượng toàn cầu.
Chi tiêu vốn của bốn công ty Amazon, Microsoft, Alphabet, Meta trong năm nay lên tới 7250 tỷ USD, tăng mạnh 77% so với cùng kỳ, quy mô này tương đương với 13% tổng đầu tư nội địa tư nhân hàng năm của Mỹ. Morgan Stanley thậm chí dự đoán, đến năm 2027, chi tiêu vốn của các doanh nghiệp công nghệ Mỹ có thể đạt kỷ lục lịch sử 1,1 nghìn tỷ USD.
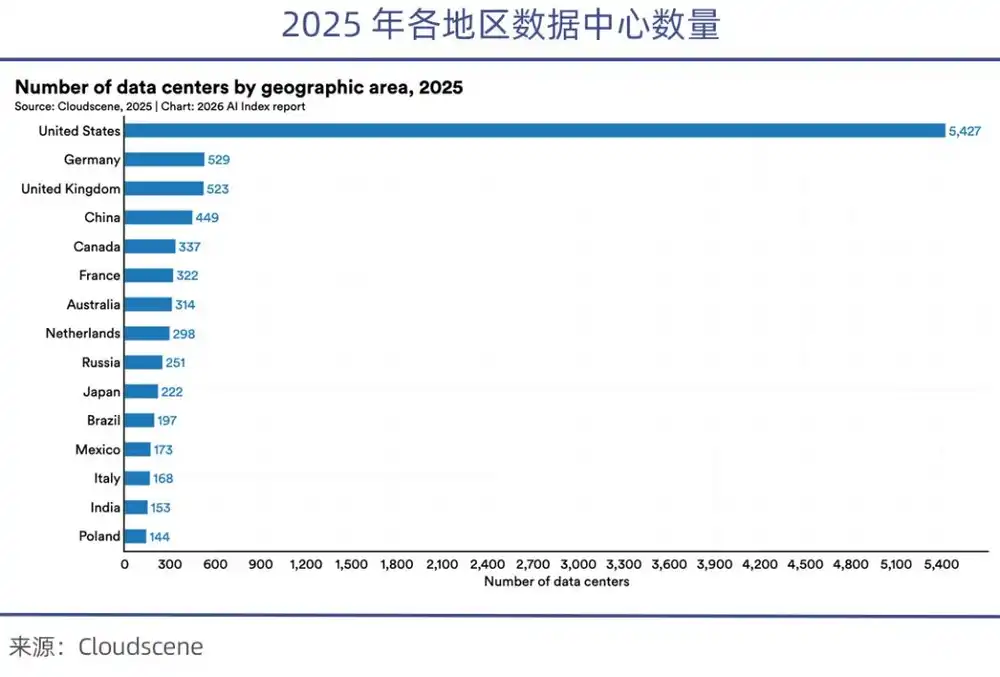
Hiện tại Mỹ kiểm soát hơn 70% GPU cao cấp toàn cầu, sau lệnh cấm chip, số chip cao cấp có thể sử dụng trong nước Trung Quốc chỉ bằng 1/8 của Mỹ. Báo cáo Stanford AI Index Report 2026 chỉ ra rằng, số lượng trung tâm dữ liệu của Mỹ (5427) gấp hơn 10 lần Trung Quốc.
Theo tính toán của Viện Nghiên cứu Thông tin và Truyền thông Trung Quốc (CAICT), tính đến đầu năm 2025, quy mô sức mạnh tính toán của Mỹ là 2400 EFLOPS, Trung Quốc là 1053 EFLOPS, Mỹ gấp hơn 2 lần Trung Quốc.
Quy mô sức mạnh tính toán mà bốn gã khổng lồ công nghệ kể trên nắm giữ, mỗi công ty riêng lẻ đã vượt quá tổng của tất cả các doanh nghiệp AI Trung Quốc cộng lại.
Lợi thế về sức mạnh tính toán áp đảo này cho phép các doanh nghiệp Mỹ hoàn thành hơn chục vòng lặp thử nghiệm mô hình lớn trong một năm.
Thậm chí Elon Musk còn xa xỉ hơn, xAI của ông sở hữu Colossus 2 được mệnh danh là "cụm AI cấp GW đầu tiên trên thế giới". Do đó, ông có đủ tự tin để tuyên bố đang đồng thời huấn luyện 7 mô hình — hai mô hình 1 nghìn tỷ tham số, hai mô hình 1,5 nghìn tỷ tham số, một mô hình 6 nghìn tỷ và một mô hình 10 nghìn tỷ tham số, kiểu "mỹ học bạo lực" này chỉ có thể thực hiện được khi sức mạnh tính toán cực kỳ dồi dào.

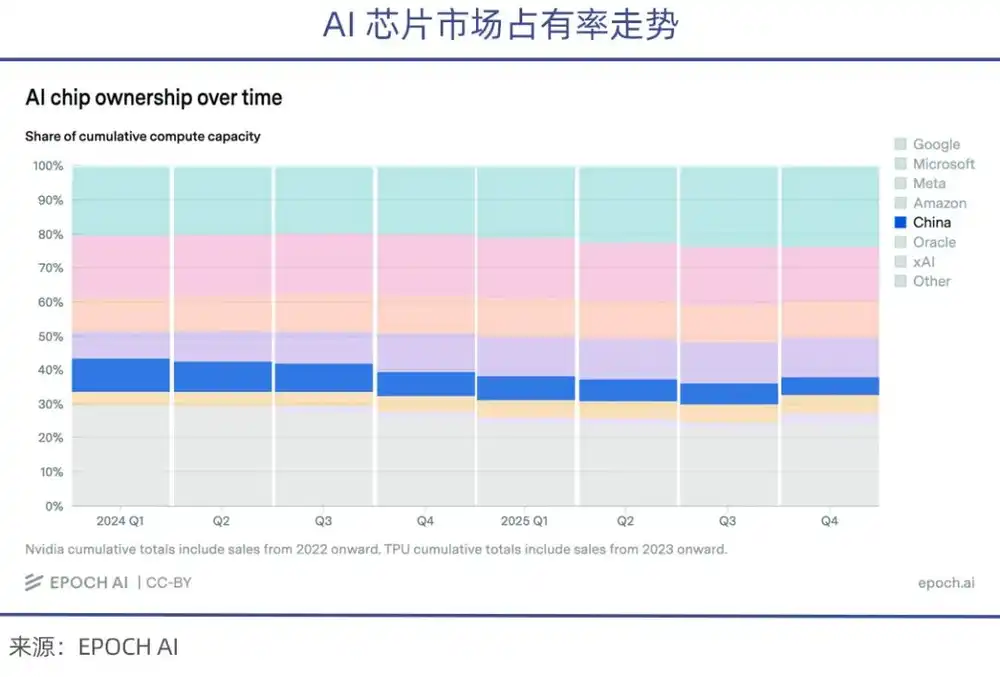
Đồng thời, do Mỹ siết chặt xuất khẩu chip, trong số chip AI cao cấp xuất xưởng những năm gần đây, thị phần mà các doanh nghiệp Trung Quốc nhận được tiếp tục giảm (theo thống kê của epoch.AI).
Có thể nói mà không quá lời rằng, khoảng cách khổng lồ về nền tảng sức mạnh tính toán sẽ khiến AI Trung Quốc lâu dài ở trong giai đoạn đuổi theo, và cũng sẽ khiến quá trình các mô hình lớn nội địa đuổi kịp các đối thủ Mỹ trở nên khó khăn hơn.
Khoảng cách thế hệ
"Bước tiến đổi mới của Trung Quốc không thể ngăn cản", "Ai mà nghĩ rằng Trung Quốc không thể làm ra (chip), thì thực sự đã nhầm. Khoảng cách giữa Trung Quốc và Mỹ chỉ là ở mức nano giây".
Người sáng lập NVIDIA Jensen Huang đã không chỉ một lần khen ngợi sự tiến bộ của ngành bán dẫn Trung Quốc tại các diễn đàn công khai.

Elon Musk cũng thường xuyên bày tỏ quan điểm tương tự trên X — "Trung Quốc chắc chắn sẽ giải quyết được vấn đề bị siết cổ về chip, trong lĩnh vực sức mạnh tính toán trí tuệ nhân tạo, chắc chắn sẽ vượt xa tất cả các quốc gia khác trên toàn cầu", "Trung Quốc sẽ thắng trong cuộc đua AI trên trái đất".
Những lời có cánh của các đại gia lẫy lừng trong giới công nghệ dành cho sự phát triển AI của Trung Quốc rất dễ khiến người ta tin là thật. Những tuyên bố này rõ ràng có dấu hiệu tâng bốc. Một số phương tiện truyền thông Mỹ không ngừng tuyên truyền quan điểm rằng khoảng cách mô hình giữa Trung-Mỹ là cực nhỏ, cố gắng làm mờ sự thật, che giấu một số chân tướng khách quan.
Đối với điều này, các lĩnh vực liên quan đến AI trong nước nên giữ thái độ tỉnh táo và bình tĩnh.
Nếu nói rằng các mô hình lớn tiên tiến của Trung Quốc hiện nay không khác biệt nhiều so với đối thủ Mỹ trong việc giải quyết các vấn đề tiêu chuẩn hóa, thì trong môi trường công nghiệp và doanh nghiệp phức tạp, khoảng cách sẽ càng trở nên rõ ràng hơn.
So với các mô hình tiên phong của các công ty Mỹ như Anthropic, Trung Quốc vẫn thuộc nhóm đuổi theo. Đánh giá của CAISI Mỹ cho rằng, DeepSeek V4 Pro mạnh nhất trong nước Trung Quốc đang tụt sau các mô hình tiên phong của Mỹ khoảng 8 tháng.
Gần đây, khi trả lời phỏng vấn của Wall Street Journal, Kai-Fu Lee đã chỉ ra rằng, lấy các mô hình đỉnh cao của Mỹ như Claude Fable 5 của Anthropic làm tiêu chuẩn, Mỹ hiện đang dẫn trước Trung Quốc khoảng 15 tháng.

Mô hình lớn tuân theo quy luật Scaling Law, tham số mô hình càng lớn, dữ liệu huấn luyện càng nhiều, sức mạnh tính toán đầu tư càng lớn, thì hiệu năng mô hình càng tốt. Ngày nay, mô hình lớn tiên tiến nhất của Mỹ đã bước vào kỷ nguyên mười nghìn tỷ tham số, và tốc độ lặp vẫn đang tăng nhanh.
Mythos mạnh nhất của Anthropic đã đạt 10 nghìn tỷ tham số, việc huấn luyện nó tiêu tốn 100 tỷ USD; Colossus 2 của xAI đang đồng thời huấn luyện 7 mô hình, bao gồm mô hình 6 nghìn tỷ và 10 nghìn tỷ tham số; OpenAI chỉ mất một tháng để lặp một vòng mô hình 4 nghìn tỷ tham số.
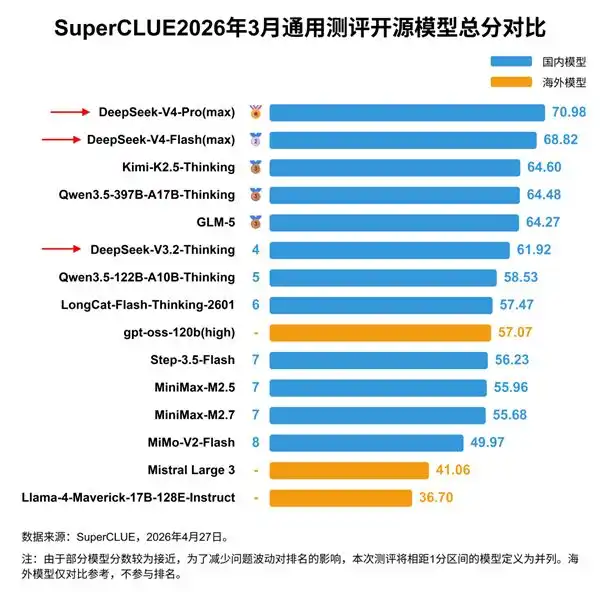
Tổng số tham số của mô hình mạnh nhất Trung Quốc DeepSeek V4 Pro là 1,6 nghìn tỷ, chênh lệch khoảng 6 lần so với mô hình tiên phong mười nghìn tỷ tham số của Mỹ.
Dòng Claude của Anthropic đã được công nhận là mô hình lớn AI lập trình mạnh nhất trong hai năm qua, Mythos một lần nữa làm mới nhận thức của công chúng, hiệu năng của nó thậm chí còn mạnh hơn so với mẫu flagship trước đó Oups 4.6.
OpenBSD nổi tiếng trong ngành là hệ thống an toàn nhất, kết quả Mythos tìm thấy một lỗ hổng 27 năm không bị phát hiện, nó còn tìm ra lỗ hổng trong nhân Linux, FFmpeg vài năm thậm chí hơn chục năm không bị phát hiện, và toàn bộ quá trình phát hiện tự chủ, không dựa vào con người.
Cần biết rằng, "tiền huấn luyện" của mô hình lớn quyết định giới hạn trên của năng lực mô hình, không thể thông qua "hậu huấn luyện" để điều chỉnh mô hình tham số cấp nghìn tỷ đạt đến mức năng lực của mô hình 10 nghìn tỷ tham số. Và nhân tố quyết định của tiền huấn luyện chính là chip sức mạnh tính toán cao cấp, nó quyết định quy mô tham số và tốc độ lặp huấn luyện.
Chủ tịch iFlytek Liu Qingfeng đã thẳng thắn thừa nhận, hiện nay các nhà sản xuất mô hình lớn hàng đầu, đặc biệt là các gã khổng lồ Mỹ, đều đang xây dựng nền tảng sức mạnh tính toán siêu quy mô. Trong khi đó, sức mạnh tính toán nội địa Trung Quốc hiện thực sự đối mặt với thời kỳ đau đớn, dẫn đến gặp hạn chế trong việc huấn luyện văn bản siêu dài.
Có thể thấy, khoảng cách sức mạnh tính toán chính là nguồn gốc của sự chênh lệch mô hình giữa Trung Quốc và Mỹ.
Sự trỗi dậy của sản phẩm nội địa
Một doanh nghiệp độc quyền 90% thị phần chip huấn luyện AI cao cấp toàn cầu — điều này giúp NVIDIA giữ vững ngôi vị công ty có giá trị vốn hóa thị trường lớn nhất thế giới. Tổng giá trị vốn hóa thị trường của nó từng vượt quá GDP năm 2025 của nền kinh tế lớn thứ ba thế giới — Đức.
Số liệu từ TrendForce cho thấy, trong thị trường máy chủ GPU toàn cầu quý I năm 2026, NVIDIA một mình chiếm 68%, AMD chiếm 5%-6%, trong khi các nhà sản xuất GPU nội địa Trung Quốc tổng cộng chưa đạt 4%.
Với lợi thế đi đầu, rào cản công nghệ siêu mạnh, kết nối tốc độ cao, hệ sinh thái phần mềm cùng việc gắn kết với công nghệ sản xuất tiên tiến của TSMC, NVIDIA thống trị thiên hạ. Trong các tình huống huấn luyện cao cấp, NVIDIA GB300 có hiệu năng mạnh hơn AMD MI325, cũng tốt hơn Cambricon Siyuan 690, Moore Thread MTT40, đặc biệt trong huấn luyện mô hình lớn nghìn tỷ tham số, hiệu năng mạnh hơn đối thủ cạnh tranh trên 30%.
Dưới lệnh cấm xuất khẩu, Jensen Huang trước đó đã cho biết, thị phần (tăng mới) của NVIDIA tại Trung Quốc về cơ bản đã về 0, chỉ còn lại thị trường hiện hữu. Được hỗ trợ bởi chính sách thay thế nội địa, các doanh nghiệp bao gồm Huawei Ascend 910, Hygon DCU ShenSuan 2, Cambricon Siyuan 370/590, cùng với Moore Thread, MooreX lần lượt xuất hiện.
Trong đó Ascend 910 là chip sức mạnh tính toán mạnh nhất của Huawei, sức mạnh tính toán của Ascend 910B đạt 640 TOPS (INT8), có thể sánh ngang với chip NVIDIA A100.
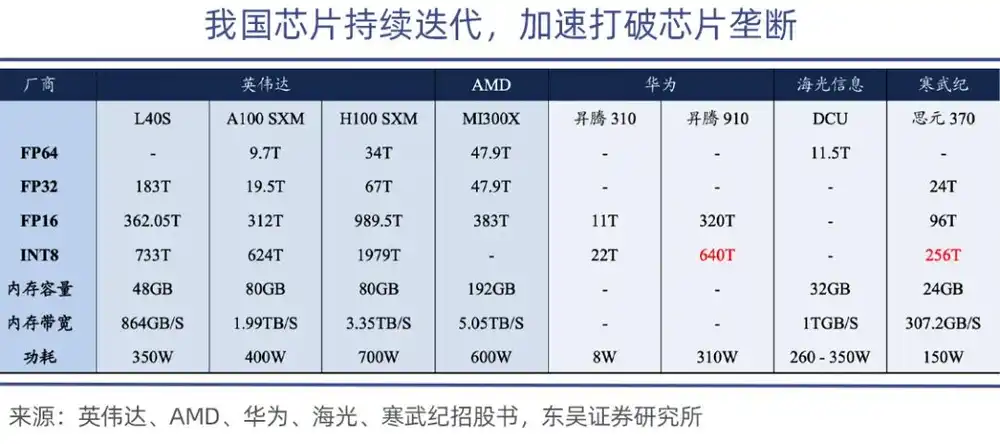
Ở cấp độ hiệu năng tuyệt đối, GPU nội địa tuy vẫn còn khoảng cách, nhưng có thể bắt đầu từ các tình huống suy luận và rìa hệ thống, hiện GPU nội địa về cơ bản đáp ứng nhu cầu suy luận thông dụng của chính phủ và doanh nghiệp trong nước, khoảng cách với sản phẩm trung cấp của NVIDIA thu hẹp xuống còn 15%-20%, có tính khả thi thay thế.
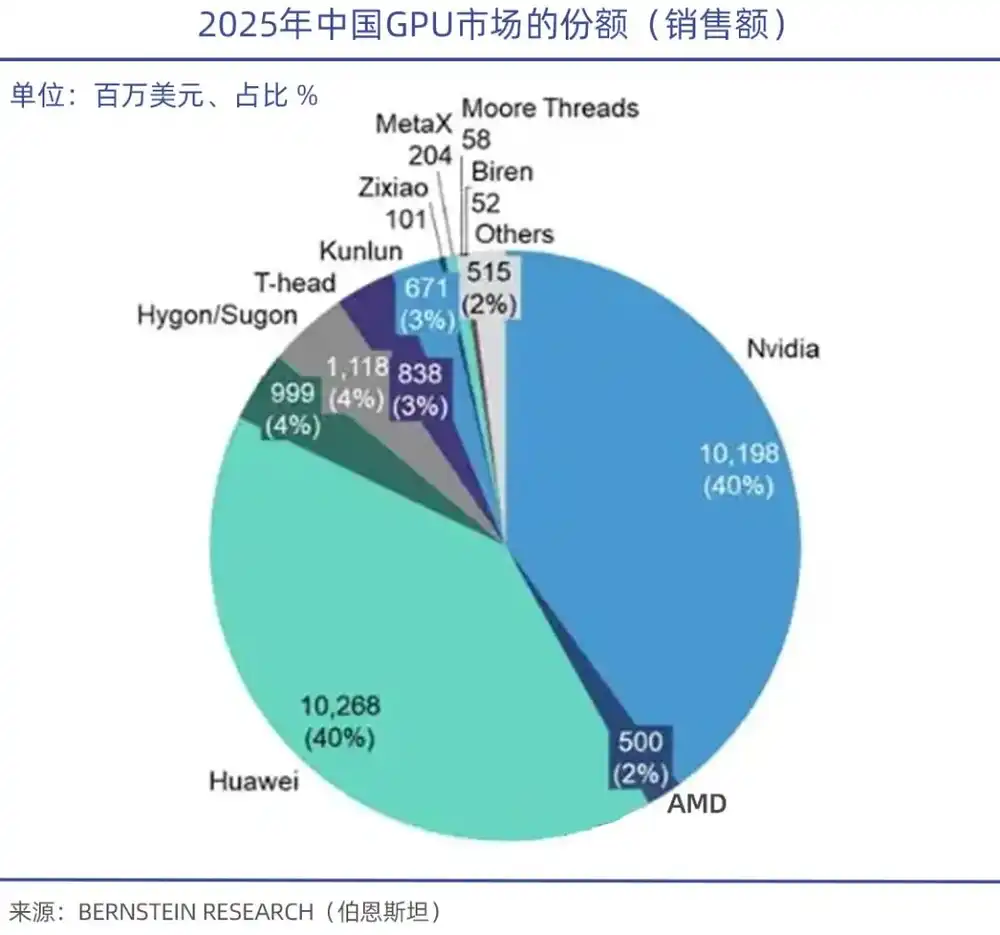
Cần đặc biệt chỉ ra rằng, hiệu năng sức mạnh tính toán tuy quan trọng, nhưng hệ sinh thái phần mềm công nghệ đằng sau mới là điểm yếu của GPU nội địa. Giống như CUDA mới là nền tảng xây dựng đế chế GPU NVIDIA, Viện sĩ Viện Kỹ sư Trung Quốc Zheng Weimin đã chỉ ra, vấn đề cốt lõi của chip AI nội địa là hệ sinh thái chưa đủ tốt, nếu hệ sinh thái tốt, hiệu năng làm được 60% cũng sẽ có người dùng.
Có thể nói, hệ sinh thái phần mềm là rào cản cứng nhất trong lĩnh vực GPU, khả năng của NVIDIA ở khía cạnh này cũng khó thay thế.
Hệ sinh thái CUDA đã được vun đắp hơn mười năm, hiện sở hữu hơn 4 triệu nhà phát triển, hàng chục nghìn mô hình mã nguồn mở, chuỗi công cụ bên thứ ba đầy đủ loại hình, bao phủ huấn luyện AI, suy luận, kết xuất đồ họa, tính toán khoa học, rào cản hệ sinh thái mạnh mẽ vô song.
Số liệu IDC cho thấy, hiện nay hơn 95% mô hình AI toàn cầu được phát triển dựa trên hệ sinh thái CUDA. Trong khi GPU nội địa dựa vào sự hỗ trợ của chính sách, cần có sự hợp tác lâu dài với chuỗi công nghiệp, cần truyền thông, thị trường vốn dành đủ sự kiên nhẫn.
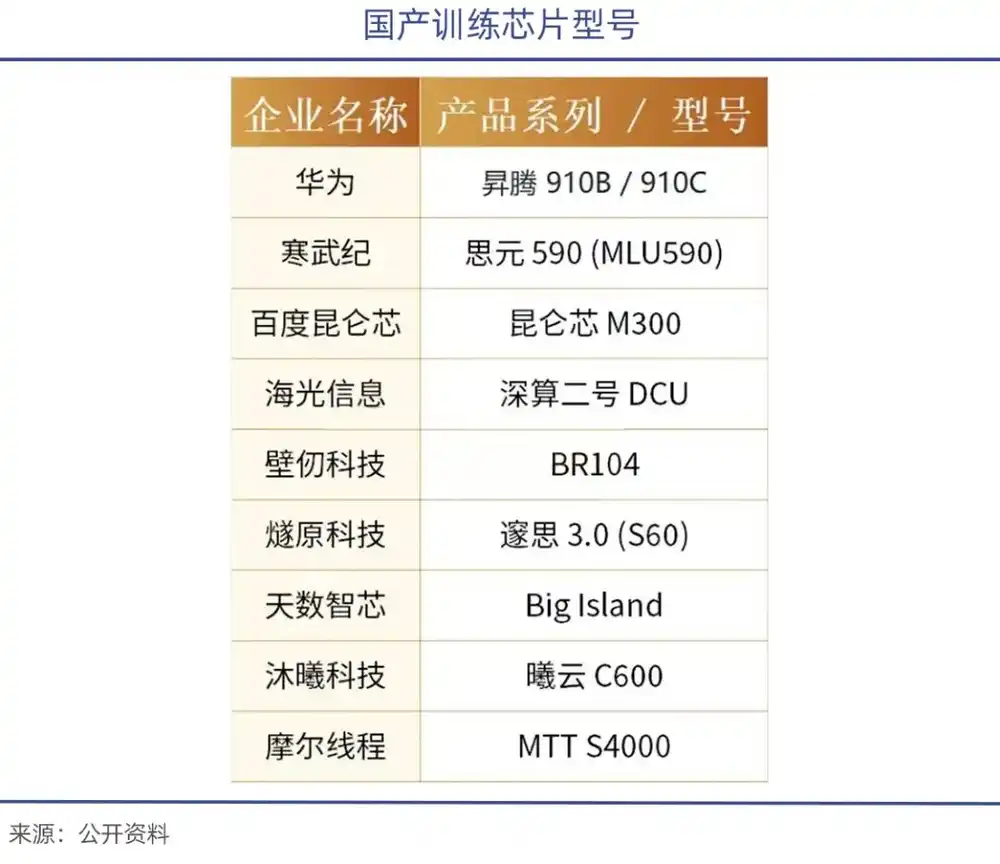
Tháng 1 năm nay, Zhipu đã cùng Huawei mở mã nguồn mô hình tạo ảnh thế hệ mới GLM-Image, mô hình này dựa trên thiết bị Huawei Ascend Atlas 800T A2 và khung AI Ascend MindSpore, hoàn thành vòng khép kín toàn quy trình từ xử lý dữ liệu đến huấn luyện mô hình, là mô hình đa phương thức SOTA đầu tiên thực hiện toàn bộ quá trình huấn luyện dựa vào chip nội địa;
Moore Thread còn cùng Viện Nghiên cứu Trí tuệ Nhân tạo Bắc Kinh (BAAI), dựa trên cụm siêu tính toán MTT S5000 và khung FlagOS-Robo, hoàn thành huấn luyện toàn quy trình cho mô hình não hình hài tự phát triển RoboBrain 2.5. Thành quả này lần đầu tiên xác minh được tính khả dụng của cụm sức mạnh tính toán nội địa trong huấn luyện mô hình lớn hình hài thông minh.
Có thể thấy, GPU nội địa đã có đột phá trong khả năng thích ứng và xây dựng hệ sinh thái, và đang từ "đột phá điểm" ở phía suy luận, tiến tới "thích ứng từng bước" ở phía huấn luyện, đây đã là một bước tiến dài.
Tổng kết
Nhìn tổng thể, trong bối cảnh nhập khẩu chip tiên tiến từ nước ngoài bị cản trở, không ngại kết hợp "Trung-Tây" dùng hai chân để đi, đồng thời trọng điểm hỗ trợ chip sức mạnh tính toán trong nước, để đáp ứng nhu cầu thị trường cấp bách.
Tính chân thực của nhu cầu không còn nghi ngờ gì, "luận bong bóng" vẫn tồn tại, nhưng tiếng nói không ngày càng lớn hơn. Sự nhiệt tình của thị trường toàn cầu đối với xây dựng AI đã vượt qua quá trình phát triển đầu kỳ của bất kỳ ngành công nghiệp nào trước đây.
Từ đầu năm nay, thị trường vốn toàn cầu một lần nữa dấy lên siêu chu kỳ AI, cổ phiếu Samsung, SK Hynix, Broadcom, TSMC liên tục lập đỉnh mới, trên thị trường trong nước Trung Quốc, công nghệ cứng đại diện là Cambricon cũng tăng mạnh, gã khổng lồ module quang Zhongji Innolight giá trị vốn hóa thị trường thậm chí từng vượt qua Moutai.
Nhìn lại lịch sử phát triển bán dẫn Hàn Quốc, Hàn Quốc dốc sức toàn quốc hỗ trợ ngành công nghiệp chip nhớ, vượt qua thời khắc tối tăm nhất, và cuối cùng đánh bại Nhật Bản, trở thành vương giả tuyệt đối của ngành công nghiệp nhớ thế giới.
Cho dù là chip nhớ, chip điện thoại, cho đến chip AI hiện tại, Trung Quốc vẫn đang ở giai đoạn đuổi theo, đây tuyệt đối không phải là công sức một sớm một chiều. Nhưng với thị trường khổng lồ, nhân tài AI không ngừng xuất hiện, sức mạnh vốn to lớn, GPU nội địa đã bắt đầu lộ ra một mức độ thích ứng nhất định, có thể giải quyết nhiều nhu cầu thực tế của các doanh nghiệp AI.
Trong cuộc chơi AI liên quan đến vận mệnh quốc gia này, hai nước Trung Quốc và Mỹ vừa là đối thủ, đồng thời cũng có công nghệ, thị trường và tài nguyên mà đối phương cần.
Bài viết này đến từ tài khoản công chúng WeChat: Jù Cháo WAVE , Biên tập: Dương Húc Nhiên, Tác giả: Tạ Trạch Phong, Tiêu đề gốc:《Thách Thức Về Sức Mạnh Tính Toán Trong Cuộc Chơi AI Giữa Trung Quốc Và Mỹ | Jù Cháo》





