Văn | Alter
Vào sáng ngày 24 tháng 4, DeepSeek V4 cuối cùng cũng lộ diện.
Cùng ngày, DeepSeek-V4-Pro đã lên ngôi đầu bảng mô hình nguồn mở Hugging Face, với hai "đổi mới đột phá" được bàn tán sôi nổi:
Một là bối cảnh siêu dài hàng triệu từ, nhưng bộ nhớ đệm KV chỉ bằng 10% so với V3.2, được các kỹ sư Amazon ca ngợi sẽ giải quyết vấn đề thiếu hụt HBM;
Hai là khả năng tương thích với chip sản xuất trong nước, hợp tác chặt chẽ với Huawei trong quá trình nghiên cứu và phát triển, và ngay lập tức tương thích với các chip nội địa như Ascend, Cambricon.
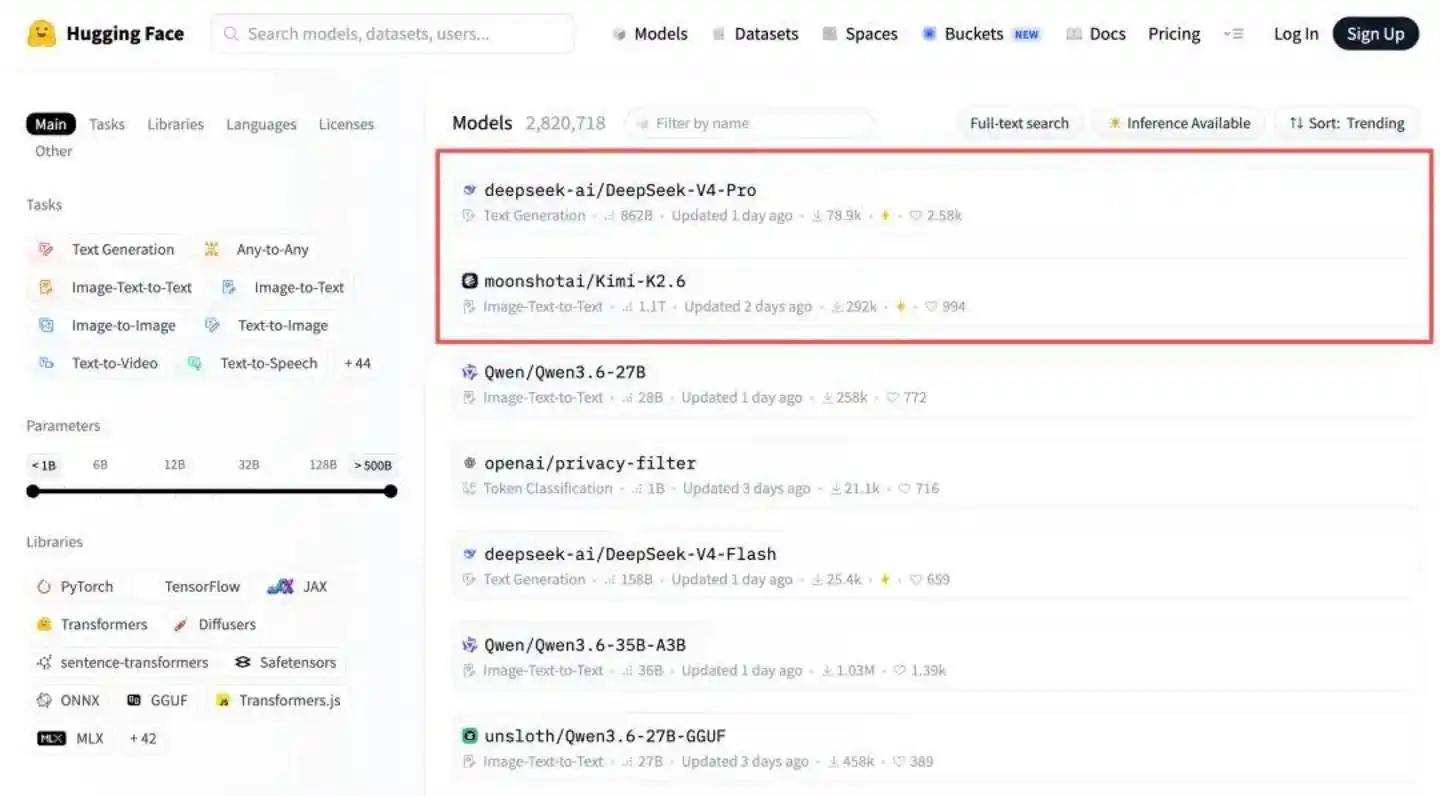
Trùng hợp là, mô hình xếp thứ hai trên bảng xếp hạng nguồn mở Hugging Face chính là Kimi K2.6, được phát hành và mở nguồn vào đêm ngày 20 tháng 4.
Nếu ở bên kia Thái Bình Dương, việc hai mô hình tham số nghìn tỷ "đụng độ" sẽ khó tránh khỏi những tranh cãi về định giá và thương mại, nhưng trong nước lại diễn ra một cảnh tượng hoàn toàn khác: không có những màn tố cáo lẫn nhau, không có cuộc chiến quan hệ công chúng ngầm, thậm chí còn có sự "trao đổi" ở tầng công nghệ.
Đằng sau sự "bất thường" này là sự khác biệt trong lộ trình công nghệ AI giữa Trung Quốc và Mỹ: Thung lũng Silicon đang điên cuồng "dựng lên những bức tường cao", cố gắng bảo vệ lợi ích đã đạt được bằng cách đóng nguồn; trong khi các nhà sản xuất mô hình lớn của Trung Quốc chọn cách "phá bỏ tường rào", tiến tới tiến hóa hợp tác trên mảnh đất nguồn mở.
01 Thung lũng Silicon chìm sâu vào "Trò chơi quyền lực"
Khác với lộ trình nguồn mở trăm hoa đua nở của các mô hình lớn trong nước, những người dẫn đầu về AI tại Thung lũng Silicon như OpenAI, Anthropic, Google Gemini đều là những người ủng hộ đóng nguồn.
Khi những đổi mới công nghệ tiên phong bị khóa chặt trong các trung tâm dữ liệu riêng, đối mặt với áp lực chi phí tính toán và kỳ vọng của thị trường vốn, "tinh thần Thung lũng Silicon" vốn nổi tiếng với sự cởi mở và hợp tác dần biến mất, và các bên tham gia không thể tránh khỏi rơi vào "trò chơi quyền lực" với tổng bằng không.
Trong hai năm qua, "chiến tranh ngầm" công nghệ đã biến thành những cuộc công kích công khai, và thủ đoạn điển hình nhất là "cướp sóng" lẫn nhau: Vào thời điểm then chốt khi đối thủ cạnh tranh ra mắt sản phẩm mới, nhanh chóng tung ra bản cập nhật nặng ký của mình để kiềm chế tiếng tăm của đối phương đã trở thành thao tác thường quy tại Thung lũng Silicon.
Ngay từ tháng 5 năm 2024, OpenAI và Google đã cùng ra mắt sản phẩm AI mới, một bên nói GPT-4o dẫn đầu toàn cầu, một bên nói dòng Gemini có thể bao phủ toàn bộ hệ sinh thái và mọi con đường. Cuối cùng, CEO của cả hai công ty đều không ngồi yên, công khai chế nhạo nhau trên mạng xã hội.
Không chỉ "vật lộn" với Google, cuộc so tài giữa OpenAI và Anthropic cũng đã vào giai đoạn căng thẳng: Vào ngày 16 tháng 4, Anthropic vừa ra mắt mô hình mới Claude Opus 4.7, thì hơn hai giờ sau, OpenAI đã thông báo cập nhật lớn cho Codex, với khẩu hiệu "Codex for (almost) everything". Người sáng mắt đều nhận ra, việc trùng lịch về thời gian không phải là trùng hợp ngẫu nhiên, mà là một cuộc "phục kích" do OpenAI lên kế hoạch kỹ lưỡng nhằm vào Anthropic.
Ngoài "đấu văn" trên mặt trận dư luận, "đấu võ" tố cáo lẫn nhau cũng đã trở thành thường thấy tại Thung lũng Silicon.
Vào ngày 7 tháng 4, Anthropic tuyên bố ầm ĩ rằng doanh thu theo năm đã đạt 30 tỷ USD, vượt qua con số 25 tỷ USD của OpenAI.
Một tuần sau, Giám đốc doanh thu của OpenAI đã thẳng thắn chỉ ra trong thư nội bộ gửi toàn thể nhân viên: Doanh thu theo năm 30 tỷ USD mà Anthropic tuyên bố có nhiều nước, vì họ sử dụng "phương pháp tổng", tính cả phần hoa hồng chia cho các nhà cung cấp dịch vụ đám mây như Amazon, Google vào tổng doanh thu của mình, khiến doanh thu theo năm bị đánh giá cao khoảng 8 tỷ USD.
Việc trong thư nội bộ lại hạ bệ đối thủ không phải là chuyện thường thấy trong ngành công nghệ, mục đích không ngoài việc muốn nói với các nhà đầu tư rằng – thần thoại tăng trưởng của Anthropic là bơm nước.
Và một khi sự thù địch nảy sinh, nó sẽ ảnh hưởng đến mọi quyết định.
Sau khi Anthropic "cãi nhau" với Lầu Năm Góc vì từ chối xóa các điều khoản an ninh cụ thể trong hợp đồng, vài giờ sau OpenAI đã tuyên bố rầm rộ rằng đã đạt được hợp tác với Bộ Quốc phòng Mỹ.
Tại "Super Bowl" năm 2026, Anthropic đã chi nhiều tiền để quảng cáo một đoạn quảng cáo với nội dung "Quảng cáo đang bước vào lĩnh vực AI, nhưng sẽ không vào Claude." Đây có thể nói là một cú "tát thẳng vào mặt" OpenAI vừa mới bắt đầu thử nghiệm tính năng quảng cáo.......
Tại sao những "anh em cùng môn" ngày xưa, lại đi đến chỗ không đội trời chung?
Nguồn gốc nằm ở logic vốn có của mô hình kinh doanh đóng nguồn: Căn cơ tồn tại của đóng nguồn là xây dựng hào thành, và tiền đề để xây dựng hào thành chính là ngăn chặn sự khuếch tán công nghệ, độc quyền lực lượng sản xuất tiên tiến nhất. Thêm vào đó là sự không tương thích về lộ trình công nghệ, sự đối lập trong tường thuật sản phẩm, tự nhiên hình thành một cân bằng Nash: Bên nào "ngừng bắn" trước, tường thuật thương hiệu của bên đó sẽ sụp đổ, cuối cùng càng lún sâu vào vũng lầy hao tổn nội bộ.
02 "Tiến hóa hợp tác" của phe nguồn mở
Chuyển tầm nhìn về trong nước, kịch bản hoàn toàn khác.
Quay trở lại hơn một năm trước, sự xuất hiện bất ngờ của DeepSeek-R1 đã giảm tốc cho cuộc đua khởi nghiệp mô hình lớn đang chạy ào ạt, và "lục hổ" mô hình lớn trong vòng chung kết là nơi chịu ảnh hưởng đầu tiên. Khác biệt lớn nhất với Thung lũng Silicon là, DeepSeek không đóng vai "cá mập" ăn hết tất cả cá trong hồ, mà giống như cá chép kích hoạt toàn bộ hệ sinh thái mô hình lớn của Trung Quốc, mọi người đều ôm lấy nguồn mở.
Ví dụ trực tiếp là quỹ đạo phát triển trùng khớp cao với DeepSeek là Moonlight (tức Moonshot AI) - đều là nhóm khởi nghiệp bắt đầu từ năm 2023, đều duy trì cấu trúc đội ngũ cực kỳ ít người nhưng mật độ nhân tài cao, và đều là tín đồ trung thành của Scaling Law.
Tháng 7 năm 2025, Moonlight ra mắt mô hình nguồn mở tham số nghìn tỷ đầu tiên trên thế giới Kimi K2, trong báo cáo kỹ thuật đã không ngần ngại nói rằng đã sử dụng kiến trúc MLA nguồn mở của DeepSeek. Đối với mô hình lớn, cơn ác mộng lớn nhất khi xử lý văn bản siêu dài là bức tường bộ nhớ, và tính đột phá của kiến trúc MLA nằm ở chỗ, khéo léo nén tỷ lệ nén KV Cache đến mức kinh ngạc trên 93%.
Với "tiêu chuẩn ngành" do DeepSeek đóng góp, các nhóm mô hình lớn như Moonlight không cần phải tạo lại bánh xe, nhanh chóng giảm chi phí suy luận.
Câu chuyện không dừng lại ở đó.
Xem tài liệu kỹ thuật của DeepSeek V4, mô tả chi tiết kiến trúc của mô hình, một nâng cấp quan trọng là thay thế bộ tối ưu hóa của hầu hết các mô-đun từ AdamW sang Muon, đạt được tốc độ hội tụ nhanh hơn, tính ổn định huấn luyện tốt hơn.
Trong tài liệu kỹ thuật của Kimi K2.6, cũng đề cập đến bộ tối ưu hóa Muon, đạt được hiệu suất cải thiện gấp 2 lần với cùng lượng huấn luyện.
Bộ tối ưu hóa Muon được cả hai mô hình đề cập, lần đầu được nhà nghiên cứu độc lập Keller Jordan đề xuất trong blog vào cuối năm 2024. Nhóm Moonlight cũng bị AdamW làm phiền, vào đầu năm 2025 đã cải tiến kỹ thuật quan trọng cho Muon, tăng thêm khả năng Weight Decay, kiểm soát RMS, và đặt tên là MuonClip.
Moonlight đã xác minh tính ổn định của bộ tối ưu hóa Muon trên Kimi K2, đạt được "zero Loss Spike" trong suốt quá trình tiền huấn luyện. DeepSeek khi huấn luyện mô hình lớn V4, cũng sử dụng bộ tối ưu hóa Muon đã được xác minh.
Cần phải nói rằng, "tiến hóa hợp tác" của mô hình lớn nguồn mở không rơi vào đồng nhất hóa, mà đang đi trên con đường "hòa mà không đồng".
Ví dụ, DeepSeek-V4 tập trung vào khả năng cốt lõi của mô hình cơ sở, củng cố thêm trần hiệu suất của mô hình lớn nguồn mở toàn cầu, cung cấp nền tảng cơ sở có hiệu suất ngang bằng với các flagship đóng nguồn cho toàn ngành; Kimi K2.6 đào sâu vào triển khai kỹ thuật Agent, giải quyết điểm đau về thực thi tự chủ đường dài của mô hình lớn, mở ra con đường then chốt để mô hình lớn bước vào các kịch bản sản xuất thực tế.
Trong toàn bộ quá trình, không có đàm phán thương mại kéo dài, không có tranh chấp bằng sáng chế căng thẳng. Trong phe nguồn mở, đổi mới công nghệ đang chảy tự do như nước, ai làm tốt thì mọi người dùng của người đó.
Hấp thụ dưỡng chất từ hệ sinh thái nguồn mở, bổ sung cho nhau về lộ trình công nghệ. Các nhà sản xuất mô hình lớn của Trung Quốc, bằng hành động đã chứng minh cho thế giới thấy một khả năng khác ngoài Thung lũng Silicon.
03 Mỹ "xây tường", Trung Quốc "sửa đường"
Cảm thán về sự tiến hóa hợp tác nguồn mở, đồng thời phải đối mặt với một thực tế thương mại.
Hiện tại doanh thu theo năm của OpenAI và Anthropic đều đạt trên trăm tỷ USD, trong khi doanh thu của các nhà sản xuất mô hình lớn hàng đầu trong nước, vừa mới bước qua cánh cửa một tỷ USD theo năm.
Định giá trên thị trường thứ cấp của OpenAI khoảng 8800 tỷ USD, định giá của Anthropic đã tăng vọt lên khoảng 1 nghìn tỷ USD, trong khi định giá của Kimi và DeepSeek trong vòng gọi vốn mới, lần lượt là 180 tỷ USD và 200 tỷ USD.
Có người kêu gào rằng định giá thị trường của các nhà sản xuất mô hình lớn Trung Quốc bị đánh giá thấp, cũng có người cho rằng: "Liệu có thể chuyển hóa danh tiếng công nghệ thành tiền vàng bạc thật hay không, là kỳ thi sống còn đặt trước mặt các nhà sản xuất Trung Quốc." Trong một thời gian, các thảo luận về "tỷ lệ chi phí - hiệu quả" của nguồn mở đã dậy sóng.
Muốn nhìn rõ kết cục, có thể bắt đầu từ giai đoạn cạnh tranh của mô hình lớn:

Giai đoạn thứ nhất là "tranh tham số, tranh Benchmark". Đến cuối tháng 4 năm 2026, giai đoạn này cơ bản kết thúc, điểm chạy trên bảng xếp hạng của các nhà đã không thể kéo ra chênh lệch thực chất.
Giai đoạn thứ hai là "tranh hiệu suất huấn luyện, tranh chi phí suy luận, tranh đổi mới kiến trúc". Đây chính là chặng đua đang ở hiện tại, cũng là kết quả tất yếu dưới áp lực ngược của chi phí tính toán.
Giai đoạn thứ ba sẽ là "tranh hệ thống Agent, tranh hệ sinh thái, tranh nhà phát triển". Khi Token từ lưu lượng miễn phí trở thành "nhiên liệu" thực thi nhiệm vụ, sự phồn thịnh của hệ sinh thái sẽ quyết định sống chết.
Vậy mô hình lớn nguồn mở trong nước đang ở vị trí sinh thái nào? Chúng tôi tìm được hai nhóm dữ liệu so sánh trực quan.
Một là chi phí huấn luyện.
GPT-5 ra mắt tháng 8 năm 2025, chi phí huấn luyện vượt quá 500 triệu USD; cùng kỳ Kimi K2 Thinking, chi phí huấn luyện khoảng 4.6 triệu USD; DeepSeek không công bố chi phí huấn luyện của mô hình V4, nhưng mô hình V3 chỉ tiêu tốn 5.576 triệu USD...... Các nhà sản xuất mô hình lớn trong nước chỉ sử dụng chưa đến số lẻ zero của OpenAI, đã huấn luyện ra mô hình cùng trình độ.
Hai là lượng gọi.
Bước vào năm 2026, dữ liệu từ nền tảng tổng hợp đa mô hình OpenRouter cho thấy: Dưới sự thúc đẩy của sản phẩm Agent đại diện là OpenClaw, lượng tiêu thụ Token toàn cầu đã thể hiện sự tăng trưởng theo cấp số nhân, "đội mơ nguồn mở" của Trung Quốc, dựa vào danh tiếng "dễ dùng lại rẻ", lượng gọi đã vượt Mỹ nhiều tuần liên tiếp.
Nguyên nhân không khó giải thích.
Phe nguồn mở Trung Quốc đã chạy thông "bánh xe phản hồi tích cực": Công ty A mở nguồn công nghệ cơ sở, công ty B sử dụng và tối ưu hóa kỹ thuật, sau đó phản hồi kết quả và kinh nghiệm tối ưu hóa cho toàn bộ hệ sinh thái. Nếu nói sự tiến hóa của mô hình đóng nguồn là tăng trưởng tuyến tính dựa trên sự chất đống lượng tính toán khổng lồ, thì những gì chờ đợi lộ trình nguồn mở, sẽ là sự khuếch tán theo cấp số nhân do sự va chạm đổi mới công nghệ mang lại.
Theo báo cáo nghiên cứu của J.P. Morgan, trong giai đoạn 2025-2030, tốc độ tăng trưởng kép hàng năm về lượng tiêu thụ token suy luận AI của Trung Quốc sẽ đạt khoảng 330%, sẽ tăng từ 10 nghìn tỷ token năm 2025, lên mạnh lên 3900 nghìn tỷ token năm 2030, quy mô tăng trưởng đạt 370 lần.
Nghĩa là, năm 2026 vẫn đang ở giai đoạn đầu của sự bùng nổ AI, trong 5 năm tới vẫn còn cơ hội tăng trưởng hàng trăm lần, còn lâu mới đến lúc kết luận.
Chính vì tự tin vào cơ hội lâu dài, khi các gã khổng lồ Thung lũng Silicon cố gắng xây tường, các nhà sản xuất mô hình lớn Trung Quốc chọn cách bổ sung vị trí hợp tác, không ngừng củng cố con đường dẫn đến AGI.
04 Viết ở cuối
Trong làn sóng AI rầm rộ này, ai sẽ là người cười cuối cùng? Câu trả lời không chỉ liên quan đến mô hình, mà còn liên quan đến sự tự chủ và kiểm soát của năng lực tính toán. Nếu so sánh mô hình như "bom nguyên tử" thì năng lực tính toán nội địa thoát khỏi phong tỏa công nghệ bên ngoài chính là "tên lửa" đưa bom nguyên tử lên trời.
Đáng mừng là, sự hợp nhất giữa mô hình nội địa và năng lực tính toán nội địa ngày càng chặt chẽ: Trong tài liệu kỹ thuật DeepSeek V4, đã liệt kê NPU Ascend và GPU NVIDIA song song vào danh sách xác minh phần cứng; Moonlight trong bài luận mới nhất đã chạy phần điền trước và giải mã suy luận mô hình lớn trên các chip khác nhau, mở ra cánh cửa cho chip nội địa tham gia quy mô lớn vào suy luận mô hình.
Đầu năm 2025, DeepSeek R1 đã giành được cơ hội lên bàn đấu cho mô hình lớn nội địa; đến năm 2026, phe mô hình lớn nguồn mở của Trung Quốc, đang không ngừng tạo ra thêm vốn cứng định nghĩa quy tắc bàn đấu trong sự hợp tác đồng bộ.








