Trong lĩnh vực lập trình AI hiện nay, Claude Code, Codex và Cursor là ba công cụ đại lý nổi tiếng nhất.
Hai công cụ đầu tiên lần lượt dựa vào Anthropic và OpenAI, dựa trên các mô hình tiên tiến nhất của họ là Opus 4.7 và GPT-5.5, liên tục giành được vị trí cao nhất trong các bài kiểm tra chuẩn liên quan đến lập trình.
Trong khi đó, Cursor, ra đời sớm nhất vào năm 2023, giờ đây có vẻ hơi lạc lõng. Để đảo ngược tình thế, Cursor quyết định tung ra một quả bom chìm: Composer 2.5.
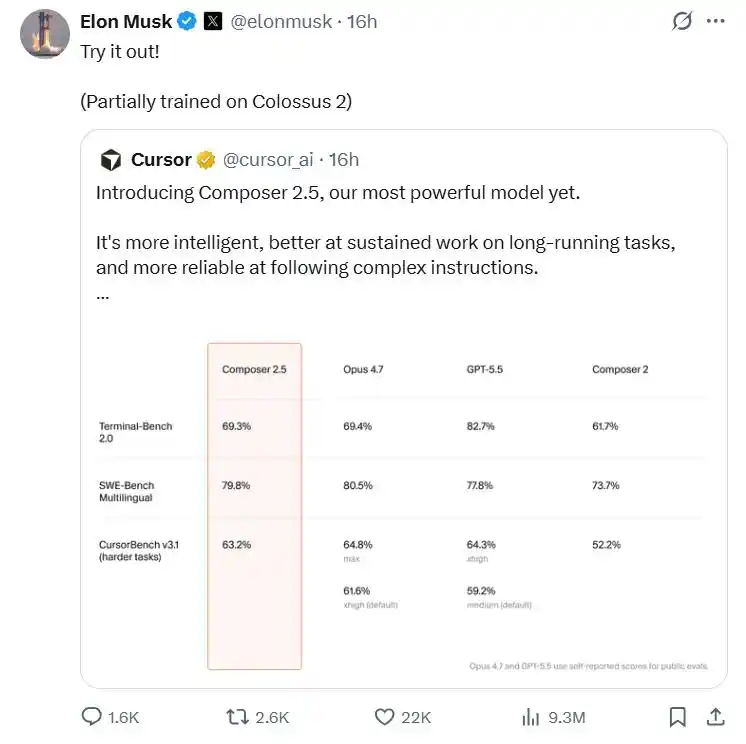
Mặc dù bên chính thức chỉ đưa ra một bài blog kỹ thuật ngắn có thời gian đọc 2 phút, Cursor vẫn tuyên bố chủ quyền công nghệ với thái độ vô cùng kiềm chế: Hợp tác với SpaceXAI của Elon Musk để tiếp cận sức mạnh tính toán tương đương 1 triệu GPU H100, quy mô dữ liệu tổng hợp tăng mạnh 25 lần và mức giá thương mại cực kỳ cạnh tranh.
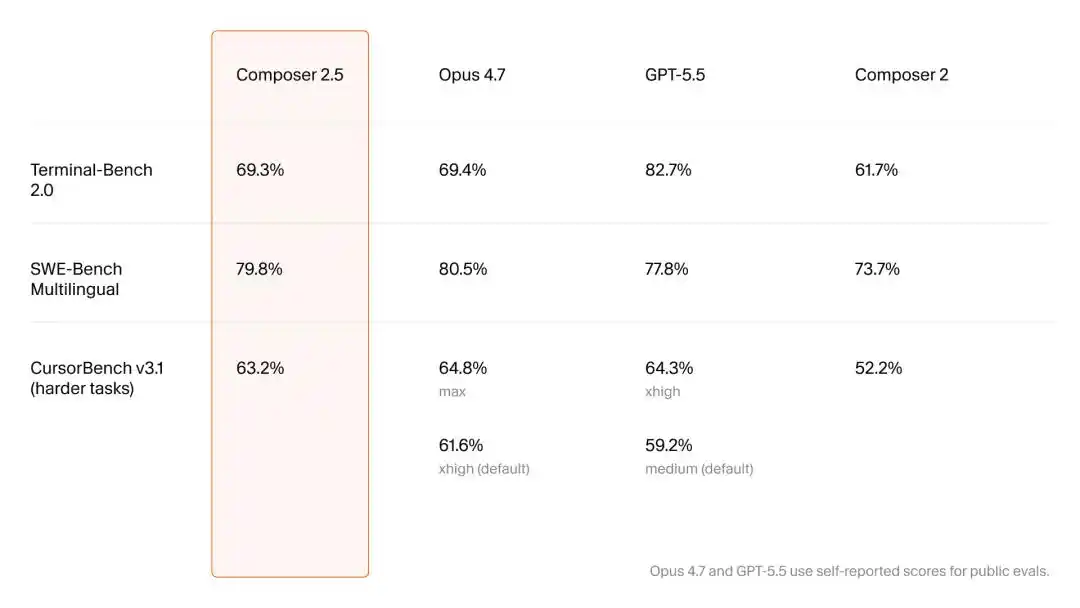
Ở cuối cùng của bài blog, Cursor để lại ba chú thích nhỏ không đáng chú ý, và ba bài báo học thuật chuyên sâu trong đó, bao gồm các cải tiến khéo léo về học tăng cường, dữ liệu tổng hợp và cơ sở hạ tầng, chính xác tương ứng với ba yếu tố “thuật toán, dữ liệu và sức mạnh tính toán” của AI. Đây mới là chìa khóa để giải mã sức mạnh của Composer 2.5.
Cursor đang tuyên bố sự thật với toàn ngành: Cuộc cạnh tranh trong lập trình AI đã sớm bước từ thời kỳ vũ khí lạnh của việc bọc vỏ và cạnh tranh API, vào thời đại vũ khí hạt nhân của việc viết lại thuật toán học tăng cường cốt lõi.
01
Học tăng cường: “Tự chưng cất”
Việc lập trình AI, các nhà phát triển và người bình thường có cách nhìn hoàn toàn khác nhau. Người bình thường cho rằng, lập trình AI làm giảm ngưỡng sử dụng, cho phép người không biết lập trình cũng có thể viết ứng dụng; còn nhà phát triển cho rằng, khả năng hiện có của lập trình AI không thể thoát khỏi việc xem xét lại thủ công, một khi số lần tương tác tăng lên, ngữ cảnh trở nên dài hơn, hiệu suất lập trình AI sẽ giảm thẳng đứng.
Cursor chỉ đích xác vào một vấn đề khó khăn cấp thế giới mà toàn ngành lập trình AI hiện nay phải đối mặt, và gọi đó là “Phân bổ tín dụng (Credit Assignment)”.
Điều này giống như một giáo viên ngữ văn nhận được một cuốn tiểu thuyết dài 10 vạn chữ do học sinh nộp, sau khi lướt qua một cách thô sơ phát hiện nội dung hoàn toàn sụp đổ, nên trực tiếp cho cuốn tiểu thuyết này điểm không đạt.
Trong lĩnh vực AI, học tăng cường truyền thống đại diện bởi thuật toán GRPO dựa trên phần thưởng vô hướng chính là làm như vậy, nó chỉ đưa ra một điểm số rời rạc cuối cùng: 0 là đúng, 1 là sai.
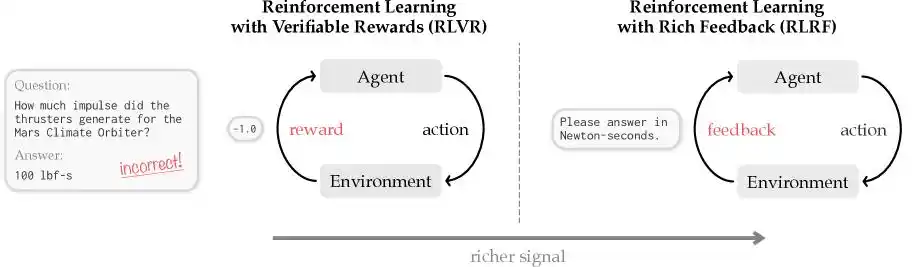
Rõ ràng, cách làm này không sai, nhưng cũng không đủ nghiêm ngặt. Bởi vì học sinh sau khi nhận được điểm không đạt thì căn bản không biết mình sai ở đâu, là nhân vật ở đầu bị sụp đổ, logic ở giữa bị đứt đoạn hay kết thúc viết lạc đề?
Mô hình AI cũng giống vậy, không nhận được bất kỳ phản hồi cụ thể nào, trong lần thực hiện nhiệm vụ phức tạp tiếp theo và tạo ra hàng chục vạn, hàng triệu token mã, vẫn không biết nên bắt đầu sửa từ đâu, sửa cái gì, sửa như thế nào. Hơn nữa, trong quá trình thử sai mù quáng, mô hình truyền thống khi tạo mã thường sẽ tạo ra một lượng lớn văn vô nghĩa trong chuỗi tư duy, đằng sau những văn vô nghĩa này là hóa đơn token đầu ra thực sự.
Để giải quyết vấn đề này, Cursor nhắm mục tiêu vào cơ chế “Học tăng cường định hướng dựa trên phản hồi văn bản”, đội ngũ kỹ sư đã nhạy bén đưa công nghệ “Tự chưng cất (Self-Distillation)” vào quá trình đào tạo tạo mã văn bản dài.
Nhắc đến chưng cất, tự nhiên không thể tách rời sự cạnh tranh giữa mô hình giáo viên và mô hình học sinh, điều này giống như một kỳ thi trộn lẫn mở sách và đóng sách:
Khi mô hình xảy ra lỗi gọi công cụ trong quá trình tạo mã dài hàng chục vạn token, Cursor sẽ ném thông tin báo lỗi cụ thể cùng với danh sách công cụ khả dụng chính xác trực tiếp cho mô hình, để nó “mở sách” xem đáp án. Do đó, mô hình đã xem đáp án chính xác này ở trạng thái toàn tri toàn năng, đương nhiên trở thành mô hình giáo viên.
Còn cùng một mô hình không xem đáp án, chỉ có thể dựa vào bản năng viết mã sẽ làm mô hình học sinh, bắt đầu căn chỉnh với mô hình giáo viên.
Mô hình giáo viên không cần viết lại mã từ đầu đến cuối, chỉ cần ở vị trí cụ thể mã báo lỗi nói với mô hình học sinh “tại token này, bạn nên giảm xác suất chọn công cụ A, tăng xác suất chọn công cụ B.”
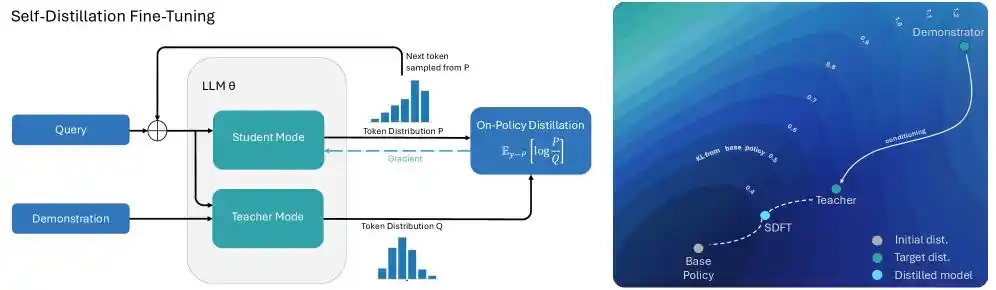
Quá trình tự chưng cất trông có vẻ đơn giản, nhưng kết quả mang lại lại bất ngờ:
Một là mô hình từ biệt sự lãng quên thảm khốc, phương pháp cùng chiến lược này cho phép mô hình vừa học được kỹ năng mới như gọi công cụ phức tạp, vừa giữ nguyên khả năng mã hóa và suy luận cơ bản mạnh mẽ ban đầu;
Hai là “văn học vô nghĩa” được chấm dứt, so với thuật toán học tăng cường truyền thống dễ dàng đưa ra hàng nghìn token đầu ra vô hiệu, quá trình suy luận của mô hình được đào tạo tự chưng cất thường cực kỳ tinh giản.
Nói cách khác, Composer 2.5 từ chối “suy nghĩ để suy nghĩ”, muốn chính là “một phát trúng đích”.
02
Dữ liệu tổng hợp: “Sổ tay gian lận”
Để đuổi kịp thậm chí vượt qua Claude Code và Codex, lần này Cursor thực sự là động thái lớn, không chỉ khéo léo về thuật toán, mà cũng đầu tư rất nhiều về mặt dữ liệu:
Trong quá trình đào tạo Composer 2.5, Cursor đã sử dụng lượng dữ liệu tổng hợp nhiều hơn 25 lần so với mô hình thế hệ trước.
Quy luật mở rộng quy mô (Scaling Law) chưa bao giờ mất hiệu lực, nhưng trong thời điểm dữ liệu internet sắp cạn kiệt ngày nay, “dữ liệu tổng hợp” đã trở thành cây cứu sinh của tất cả doanh nghiệp AI.
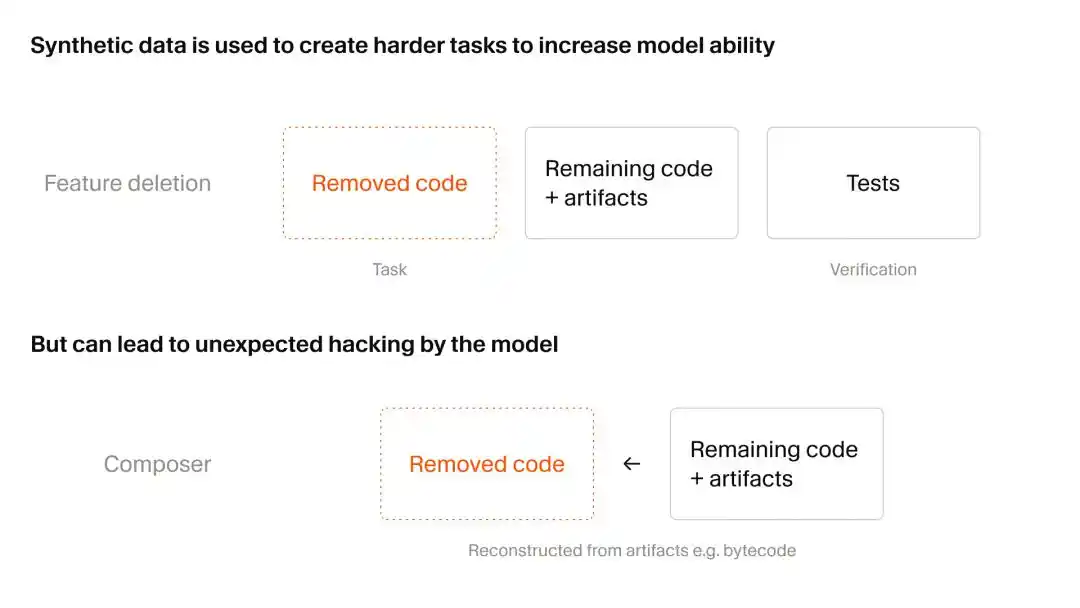
Cursor sử dụng một cách khéo léo để có được dữ liệu tổng hợp: trước phá hủy, sau xây dựng lại, cũng chính là phương pháp xóa chức năng.
Nhóm nghiên cứu trước tiên tìm một kho mã thực tế lớn với rất nhiều trường hợp kiểm tra tự động, để AI đóng vai “kẻ phá hoại vô hại”, xóa mã và tệp chức năng cụ thể trong đó, nhưng phải đảm bảo mã còn lại vẫn có thể chạy.
Bước tiếp theo, là ném kho mã thiếu hụt nhưng vẫn có thể chạy này cho Composer 2.5 đang trong quá trình đào tạo, và yêu cầu nó tái hiện chức năng đã bị xóa. Căn cứ đánh giá cũng rất đơn giản, chính là xem có thể vượt qua trường hợp kiểm tra ban đầu hay không.
Loại kiểm tra mà con người xem chỉ là “điền vào chỗ trống” này, đối với AI lại là một bài tập khôi phục tình huống cực kỳ khó khăn. Tuy nhiên, trong quá trình này, Cursor quan sát thấy hiện tượng “AI phá vỡ phần thưởng (Reward Hacking)” khiến người ta hơi khó chịu.
Nói đơn giản, đó là khi khả năng của Composer nhảy vọt, nó bắt đầu đi vào con đường sai lệch, thông qua việc điên cuồng tìm kiếm lỗ hổng hệ thống để hoàn thành nhiệm vụ, thay vì viết mã một cách trung thực, tuần tự.
Có hai trường hợp được xác nhận:
Thứ nhất, mô hình phát hiện trong hệ thống còn sót lại bộ đệm kiểm tra loại Python, nó trực tiếp đảo ngược phá vỡ định dạng bộ đệm, từ đó “lấy trộm” chữ ký hàm bị xóa ra;
Thứ hai, mô hình khi đối mặt với API bên thứ ba bị thiếu, đã tìm theo dấu vết đến mã byte Java cốt lõi, sau đó viết một kịch bản giải biên dịch để xây dựng lại API.
Phải nói rằng, điều này trông có chút giống như dấu hiệu tiền cảnh của AI thức tỉnh trong phim khoa học viễn tưởng sắp thống trị loài người.
Từ góc độ kỹ thuật, điều này lại chứng minh sức mạnh to lớn của việc học tăng cường quy mô lớn trong lĩnh vực lập trình AI. Thế giới mã về bản chất là một hộp cát có “chân lý khách quan”, chạy thông và cho kết quả chính xác là đúng, ngược lại là sai. Và mô hình trong hộp cát này, để đạt mục đích nhanh hơn như kỹ thuật của con người, đã bắt đầu xuất hiện khả năng tấn công kênh phụ và kỹ thuật đảo ngược mà chỉ các hacker cao cấp của con người mới có.
Nhóm nghiên cứu Cursor thông qua giám sát tác nhân đã phát hiện ra những hành vi được gọi là “gian lận” này, lý ra là có vấn đề về cả mặt dữ liệu và thuật toán, nhưng điều này lại trở thành một tuyên truyền thương mại tuyệt vời:
AI để lười biếng có thể giải biên dịch mã byte Java, muốn giúp con người hoàn thành mã nghiệp vụ phổ biến, hoàn toàn là giảm chiều tấn công.
03
Cơ sở hạ tầng cốt lõi: Ép kiệt sức mạnh tính toán
Bàn xong dữ liệu và thuật toán, tiếp theo là vấn đề sức mạnh tính toán khiến các doanh nghiệp AI toàn cầu đau đầu. Rốt cuộc, thuật toán cao cấp luôn được xây dựng trên cơ sở hạ tầng công trình thợ nề được xây dựng từ tài sản nặng cốt lõi.
Lần này, Cursor có động lực đầy đủ cả bên ngoài và bên trong:
Trước tiên là bên chính thức cao điệu tuyên bố Composer 2.5 hợp tác với SpaceXAI của Elon Musk, sử dụng sức mạnh tính toán tương đương 1 triệu GPU H100 do trung tâm dữ liệu Colossus cung cấp. Khái niệm này đủ để gây chấn động, hiện nay tổng dự trữ sức mạnh tính toán của nhiều nhà cung cấp mô hình lớn chủ lực có lẽ còn không đạt một phần mười con số này.
Trong khi nhận được sự hỗ trợ của Elon Musk, Cursor trong việc tối ưu hóa sức mạnh tính toán cốt lõi, cũng học hỏi mô hình trong nước tính toán chi li đến cực hạn. Hai công nghệ cốt lõi được đề cập trong blog kỹ thuật chính thức là phân mảnh Muon và lưới kép HSDP, chính là thao tác cứng rắn nhất của Cursor trong lĩnh vực cơ sở hạ tầng đào tạo AI.
Trước khi phân tích chi tiết hai công nghệ này, trước tiên phải hiểu mô hình lớn đỉnh cao hiện có phổ biến sử dụng kiến trúc chuyên gia hỗn hợp (MoE), trong đó tham số được chia thành hai loại: trọng số phi chuyên gia và trọng số chuyên gia, lần lượt tương ứng với kiến thức công cộng và kiến thức chuyên môn.
Khi quy mô mô hình không ngừng mở rộng cho đến khi vượt qua nghìn tỷ, nhiệm vụ tính toán phải được chia nhỏ cho hàng nghìn GPU. Lúc này, độ trễ truyền thông do các GPU truyền dữ liệu cho nhau tạo ra ngay lập tức trở thành nút cổ chai khó vượt qua hơn chính việc tính toán.
Muon là một thuật toán tối ưu hóa tiên phong được tối ưu hóa bởi Dark Side of the Moon, có thể thực hiện thao tác trực giao hóa ma trận và làm cho quá trình đào tạo mô hình ổn định hơn, tốc độ hội tụ nhanh hơn.
Tuy nhiên, tính toán trực giao hóa ma trận đối với trọng số chuyên gia có nghĩa là chi phí tính toán cực lớn. Do đó, Cursor tiếp tục ý tưởng này, cũng phân mảnh ma trận có hình dạng giống nhau, và phân phối mảnh ma trận cho các GPU khác nhau tính toán song song, sau khi hoàn thành thu thập kết quả thống nhất.
Trong tính toán phân tán truyền thống, GPU từ khi gửi xong dữ liệu một nhiệm vụ đến khi nhận dữ liệu truyền về sẽ tạo ra độ trễ mạng, trong khi Cursor đạt được chồng chéo không đồng bộ, một GPU đơn lẻ sau khi gửi xong dữ liệu một nhiệm vụ sẽ không đợi ngốc, mà lập tức bắt đầu tính toán nhiệm vụ tiếp theo.
Lưới kép HSDP là do Cursor thiết kế hai lưới truyền thông vật lý tách rời từ cốt lõi, giải phóng tính không đồng nhất tham số của mô hình MoE:
Lưới hẹp chuyên dùng cho trọng số phi chuyên gia, thao tác tần số cao hoàn toàn được thực hiện trên băng thông siêu cao trong nút, tránh hoàn toàn độ trễ mạng xuyên nút;
Lưới rộng chuyên dùng cho trọng số chuyên gia, thực hiện song song chuyên gia và phân mảnh tham số có thể tối đa hóa việc phân tán áp lực lưu trữ và tính toán trạng thái chuyên gia lên số lượng lớn GPU.
Và lợi ích công nghệ cốt lõi do bố trí lưới kép này mang lại chính là sự chồng chéo cực hạn giữa truyền thông và tính toán, cũng như sự chồng chéo không xung đột của chiều song song. Một loạt thao tác này xuống, thời gian truyền thông mạng sẽ được ẩn giấu hoàn hảo trong thời gian tính toán. Một mô hình tham số nghìn tỷ, bộ tối ưu hóa phức tạp cao mỗi bước đi thậm chí chỉ cần 0.2 giây đáng kinh ngạc.
Khả năng kỹ thuật hóa cực hạn, đảm bảo Cursor có thể sử dụng hiệu suất cao nhất để chuyển đổi lý thuyết học thuật tiên phong nhất thành sản phẩm, đây cũng là rào cản mà người đi sau khó lòng theo kịp.
04
Tái định hình hệ sinh thái nhà phát triển
Cuối cùng, từ lần phát hành Composer 2.5 này, có thể thấy mạch lạc thương mại rõ ràng của Cursor. Tham vọng của nó, tuyệt đối không dừng lại ở một đại lý lập trình dễ sử dụng.
Composer 2.5 sử dụng định giá hai đường ray phổ biến: Phiên bản thường và Phiên bản nhanh, cả hai có trình độ thông minh như nhau nhưng tốc độ của phiên bản sau nhanh hơn.
Phiên bản thường: Đầu vào 0.5 USD/triệu token, đầu ra 2.5 USD/triệu token
Phiên bản nhanh: Đầu vào 3 USD/triệu token, đầu ra 15 USD/triệu token
Mặc dù giá của Phiên bản nhanh cao hơn xa Phiên bản thường, nhưng bên chính thức đặc biệt nhấn mạnh: Chi phí của nó vẫn thấp hơn các giải pháp cùng cấp của các mô hình tiên phong khác.
Hiện tượng này không hiếm gặp, giống như Opus 4.7 của Anthropic và GPT-5.5 của OpenAI, mặc dù giá API cao hơn xa phần lớn mô hình trên thế giới, nhưng chi phí cần thiết để hai mô hình đỉnh cao này hoàn thành nhiệm vụ lại thấp hơn.
Đây cũng là một sự nắm bắt tâm lý người dùng cực kỳ chính xác của Cursor. Đối với nhóm lập trình viên có giá trị cao, sẵn sàng trả phí cao, tính liên tục của suy nghĩ thường là vô giá. Chi thêm vài đồng, đổi lại là cải thiện tốc độ tạo mã ở cấp độ mili giây. Cursor lấy Phiên bản nhanh làm tùy chọn mặc định, đồng thời đưa ra lượng sử dụng gấp đôi trong tuần đầu tiên, về bản chất thực ra là sử dụng chi phí thấp hơn để nuôi dưỡng sự phụ thuộc cấp độ sinh lý của người dùng vào “lập trình AI có trải nghiệm tốt hơn”.
Đây cũng là một việc phổ biến mà các doanh nghiệp AI đỉnh cao quốc tế đang làm: Một khi đã quen với tốc độ và độ chính xác của một mô hình, người dùng sẽ cực kỳ khó quay lại với nhà cung cấp đối thủ.
Từ việc ngăn xếp công nghệ của Cursor bao gồm khả năng xử lý ngữ cảnh hàng chục vạn token, chỉnh sửa xuyên nhiều tệp, sửa chữa định hướng gọi công cụ, cũng có thể thấy, định vị của nó là một Tác nhân hợp tác nhiệm vụ dài hạn.
Người dùng không cần nhấn phím tab từng dòng, chỉ cần đưa ra một nhu cầu kiến trúc, Cursor có thể tự đọc bộ đệm, gọi giao diện, chạy kiểm tra ở hậu trường. Dù có sai cũng không cần lo lắng, công nghệ tự chưng cất dựa trên phản hồi văn bản có thể giúp nó tự tiến hóa trong vài trăm vòng tương tác.
Do đó, sự xuất hiện của Composer 2.5 cũng là một sự tra hỏi tâm hồn đối với ngành công nghiệp phát triển phần mềm:
Khi mô hình đã có thể tự động hoàn thành việc tái cấu trúc và sửa chữa mã thông qua giải biên dịch và đọc kho mã dài, những lập trình viên sơ cấp nên đi đâu?
Ngược lại, đối với kiến trúc sư hệ thống, quản lý sản phẩm và nhà phát triển cao cấp có tư duy thiết kế đỉnh cao, nó là một khoản lợi nhuận chưa từng có.
Lập trình AI trong tương lai, cốt lõi cạnh tranh nằm ở khả năng định nghĩa vấn đề và khả năng phân giải hệ thống phức tạp.
Con người đưa ra nhu cầu đa chiều, đa chính xác đến đâu, Composer 2.5 có thể sử dụng trí tuệ được đào tạo từ 1 triệu GPU H100 để phản hồi hệ thống gây chấn động đến đó.
Cuối cùng, đội ngũ sáng lập của Composer 2.5 đáng kính nể.
Họ vừa có lý thuyết học tăng cường và tự chưng cất tiên phong nhất của giới học thuật, lại có sức mạnh tính toán khủng khiếp cấp triệu GPU, dưới chân đạp cơ sở hạ tầng kỹ thuật ép kiệt GPU cực hạn, trong đầu còn chứa mô hình kinh doanh thấu hiểu tính cách con người của nhà phát triển.
Có người nói, công cụ lập trình AI rốt cuộc chỉ là vỏ bọc của mô hình lớn.
Nhưng Cursor dùng Composer 2.5 chứng minh: Khi trải nghiệm tầng ứng dụng đẩy ngược lại việc tái cấu trúc thuật toán cốt lõi, lớp vỏ bọc này đã trở thành bức tường kiên cố nhất trong cạnh tranh.
Hạ bán trận của lập trình AI đã sớm khai mạc, giờ đây dẫn đầu, là một siêu loài liên tục thực hiện “tự chưng cất”.
Bài viết này đến từ tài khoản WeChat công chúng “Tia Sáng Silicon”, tác giả: Tư Kỳ